调用约定
为啥CSAPP第三章x86-64汇编学完了,但是看IDA的反汇编仍然是一头雾水?还得看一大堆东西,其中就有调用约定
为什么windows上和linux上,x86和x64上编译出来的代码有很多不同,为什么和CSAPP说的相差甚远?调用约定不同是一大原因
首先要说明的几点,也是实验中和查阅资料逐渐获得的几点
1.==各种调用约定是相对于x86而言的==,对x64无意义
The keywords
_stdcalland_cdeclspecify 32-bit calling conventions. That’s why they are not relevant for 64-bit programs (i.e. x64). On x64, there is only the standard calling convention and the extended__vectorcallcalling convenction.来自stackoverflow
关键词_stdcall和_cdecl特指32位的调用约定.64位上不一样,64位上只有标准调用约定,还有其拓展__vectorcall
即使在64位的函数前面用__cdecl或者__stdcall修饰,编译结果也是一样的
2.x86和x64汇编有较大出入,windows上和linux上的同一约定也有些许区别
x86上的调用约定
微软给出的==x86系统==上的调用约定:

一定注意是x86系统上的,而我们现在的笔记本大多数都是x64系统了,会有一些出入
c调用约定__cdecl
C Declaration
1 | <return_type> __cdecl <func_name>(para1,para2,...,paran); |
对于x86系统,微软官方文档是这样写的:

维基百科这样写的:

在gcc编译的时候加入-m32选项即可使用32位编译,编译成x86系统的程序
test.c
1 | int _cdecl func(int a,int b,int c,int d,int e,int f,int g,int h){ |
1 | gcc -O0 test.c -c -m32 -o test.o|objdump -d test.o > test.s|code test.s |
使用-m32编译之后然后反汇编
1 | test.o: file format pe-i386 |
32位系统必定不会用到r开头的4字64位寄存器比如rax,rdx,rsp等等,最大用到e开头的寄存器,比如eax,esp
可以发现show函数在调用func函数,传参的时候没有用到一个寄存器,全都是用的堆栈,还可以发现函数名都是由下划线前缀的<_main>,<_func>,<_show>
在为函数参数申请栈空间的时候是一次性完成的,即有8个参数则直接在栈上申请0x20=32字节,然后分别用movl指令向栈上刚才申请的空间写入数据.
关于蜜汁操作参数的压栈方式,是一次性申请足够的空间然后mov还是逐次push?
stackoverflow上的说法:
- Why does x64 use
movrather thanpush? I assume it’s just more efficient and wasn’t available in x86.That is not the reason. Both of these instructions also exist in x86 assembly language.
效率并且是否可实现不是原因.这两种指令(push和mov)在x86汇编语言中都存在
The reason why your compiler is not emitting a
pushinstruction for the x64 code is probably because it must adjust the stack pointer directly anyway, in order to create 32 bytes of “shadow space” for the called function. See this link (which was provided by @NateEldredge) for further information on “shadow space”.编译器对x64不使用push指令的原因是:他需要直接调整栈顶指针,给前四个参数的压栈预留”影子空间”
x86不需要寄存器传递参数但是x64需要寄存器并且在被调用函数的一开始会把寄存器中的参数也压栈,那么这些寄存器中的参数将会压入影子空间.具体见后文的实验
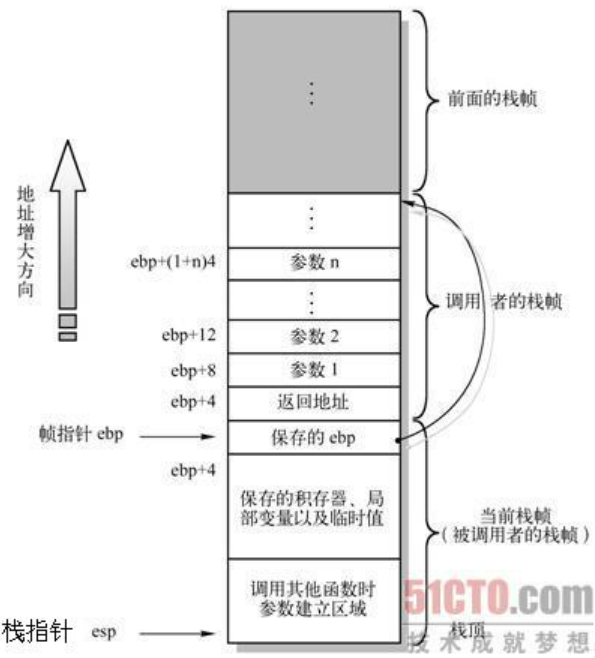
关于蜜汁操作ebp(rbp)寄存器的作用:
行为:在每个函数开始时都会被压入栈中然后拷贝栈顶指针,在有些函数快要结束的时候又会从栈中获取先前压入栈中的值
比如一个典型的结构:
2
3
2c: 89 e5 mov %esp,%ebp
2e: 83 ec 20 sub $0x20,%esp
rbpis the frame pointer on x86_64. In your generated code, it gets a snapshot of the stack pointer (rsp) so that when adjustments are made torsp(i.e. reserving space for local variables orpushing values on to the stack), local variables and function parameters are still accessible from a constant offset fromrbp.A lot of compilers offer frame pointer omission as an optimization option; this will make the generated assembly code access variables relative to
rspinstead and free uprbpas another general purpose register for use in functions.In the case of GCC, which I’m guessing you’re using from the AT&T assembler syntax, that switch is
-fomit-frame-pointer. Try compiling your code with that switch and see what assembly code you get. You will probably notice that when accessing values relative torspinstead ofrbp, the offset from the pointer varies throughout the function.rbp是x86_64上的栈帧指针.在我们的代码中,rbp寄存器获取栈顶指针rsp的快照.
当rsp改变时(比如为局部变量预留空间或者通过push指令压栈),我们仍然可以通过使用rbp+偏移量这种方式调用上一个函数(或者说调用者)的局部变量或者函数参数.
很多编译器的优化,会不用上述方式(rbp+偏移量)调用上一个函数的局部变量或者函数参数,而是只用rsp+偏移量.然后省出rbp寄存器去干其他事.对于GCC编译器,使用
-fomit-frame-pointer编译选项达到上述目的按照我的理解,rbp的作用就是调用者的rsp副本,然后rsp为被调用者服务,rbp为调用者服务.
rbp只是在被调用者嗲用调用者的局部变量时,令寻址更方便,完全可以只用rsp达到目的
后来的实践证明我一开始的理解是错误的
rbp指向函数栈帧的高地址,即栈底,rsp指向函数栈帧的低地址,即栈顶
二者都是为当前函数服务的
函数的开端时会将上一个函数的rbp指针压栈保存,然后指向当前函数栈帧的栈底.函数尾声时会将上一个函数的rbp指针退栈还给rbp
2
3
4
5
6
7
8
9
10
d6: 48 83 ec 28 sub $0x28,%rsp
da: e8 00 00 00 00 callq df <main+0x9>
df: e8 ae ff ff ff callq 92 <show>
e4: b8 00 00 00 00 mov $0x0,%eax
e9: 48 83 c4 28 add $0x28,%rsp
ed: c3 retq
ee: 90 nop
ef: 90 nop使用
-fomit-frame-pointer编译选项之后确实ebp不踪影了现在再看这个结构:
2
3
2c: 89 e5 mov %esp,%ebp ;ebp获取上一个函数esp的副本
2e: 83 ec 20 sub $0x20,%esp ;esp为当前函数服务最后将栈中刚才压入的ebp又还给ebp是还原上个函数对上上个函数的esp副本
关于蜜汁指令leave:
百度百科给出的解释:
一定要注意,这里指令的源和目的操作数与我们通篇是相反的
这里百科给出的解释使用的是intel风格的汇编语言,
mov 目的操作数,源操作数寄存器前面有百分号的是AT&T风格的汇编语言,
movq 源操作数,目的操作数leave指令在AT&T风格下相当于:
2
pop %ebp而这刚好和每个函数一开始的
2
mov %esp,%ebp恰好相反
因此leave指令就是还原栈的一个过程

标准调用约定__stdcall
微软官方文档给出的解释:
The
__stdcallcalling convention is used to call Win32 API functions. The callee cleans the stack, so the compiler makesvarargfunctions__cdecl. Functions that use this calling convention require a function prototype. The__stdcallmodifier is Microsoft-specific.
__stdcall用于修饰==Win32 API函数==.被调用者负责情理自己的函数栈,(因此编译器会把变参函数修饰为__cdecl(调用者清理栈容易实现变参)).使用__stdcall的函数需要一个函数原型(即接口)
1 | return-type __stdcall function-name[( argument-list )] |
| Element | Implementation |
|---|---|
| Argument-passing order 参数传递顺序 |
Right to left. 从右向左 |
| Argument-passing convention 参数传递规则(值传递/引用传递) |
By value, unless a pointer or reference type is passed. 除非参数是指针或者引用类型,否则采用值传递 |
| Stack-maintenance responsibility 栈维护 |
Called function pops its own arguments from the stack. 被调用者自己清理自己用到的栈 |
| Name-decoration convention 命名修饰规则 |
An underscore (_) is prefixed to the name. The name is followed by the at sign (@) followed by the number of bytes (in decimal) in the argument list. Therefore, the function declared as int func( int a, double b ) is decorated as follows: _func@12下划线开头,然后@,然后是十进制表示的参数表字节大小. 因此 int func(int a,double b)将会被修饰为_func@12(int四个字节+double八个字节) |
| Case-translation convention 大小写转换规定 |
None 无 |
| 返回值位置 | 放在eax,rax寄存器中 |
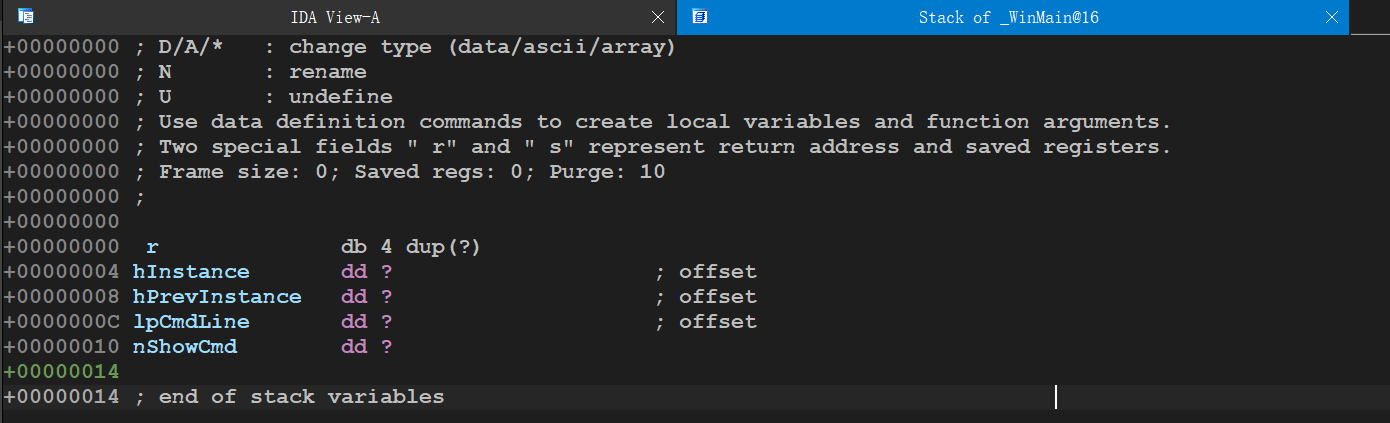
用ida打开一个win32程序,其Winmain函数是这样分析的
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
.text:00401000 __stdcall WinMain(x, x, x, x) proc near ; CODE XREF: start+C9↓p
.text:00401000
.text:00401000 hInstance = dword ptr 4
.text:00401000 hPrevInstance = dword ptr 8
.text:00401000 lpCmdLine = dword ptr 0Ch
.text:00401000 nShowCmd = dword ptr 10h
.text:00401000
.text:00401000 mov eax, [esp+hInstance]
.text:00401004 push 0 ; dwInitParam
.text:00401006 push offset DialogFunc ; lpDialogFunc
.text:0040100B push 0 ; hWndParent
.text:0040100D push 65h ; 'e' ; lpTemplateName
.text:0040100F push eax ; hInstance
.text:00401010 mov hInstance, eax
.text:00401015 call ds:DialogBoxParamA
.text:0040101B xor eax, eax
.text:0040101D retn 10h ;retn指令可以带参数
.text:0040101D __stdcall WinMain(x, x, x, x) endp可以明显观察到,参数只使用栈传递,从右向左压栈,Winmain函数的栈帧:
有一点与
__cdecl不同的是retn 10h,并且貌似与官方文档不同的是,被调用者没有自己清理自己的堆栈,比如Winmain到结束了也没有看见退栈指令.实际上这就是
retn 10h要做的事情
10h=16字节然而四个参数刚好每个4字节,即retn XXh就是被调用者的退栈指令,和返回指令合并成一条指令了如此减少了清理堆栈需要使用的指令
还是test.c
1 | int _stdcall func(short a,short b,short c,short d,short e,short f,short g,short h){ |
使用gcc,objdump,vscode素质三连
1 | PS C:\Users\86135\Desktop\reverse\test_call> gcc test.c -O0 -m32 -c -o test.o |
反汇编如下:
1 |
|
<<ida权威指南>>上给出的建议

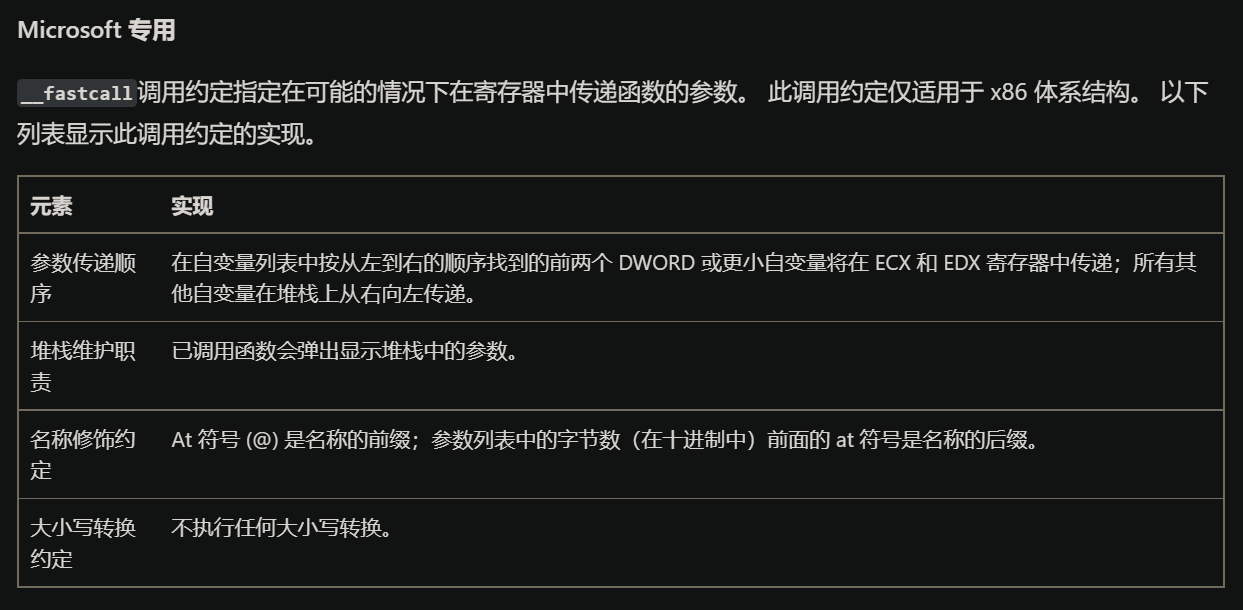
微软__fastcall
<<ida权威指南>>是这样写的:

微软官方文档:
同样的程序,除了main函数之外,其他函数都用_fastcall修饰
1 | int _fastcall func(short a,short b,short c,short d,short e,short f,short g,short h){ |
使用MSVC编译
1 | C:\Users\86135\Desktop\reverse\test_call>cl test.c |
然后反编译
1 | objdump test.obj -d >test.s |
1 |
|
微软__thiscall
微软官方文档:
The Microsoft-specific
__thiscallcalling convention is used on C++ class member functions on the x86 architecture. It’s the default calling convention used by member functions that don’t use variable arguments (varargfunctions).微软特有的
__thiscall调用约定用于x86体系上C++的成员函数.定参函数默认使用该种调用约定Under
__thiscall, the callee cleans the stack, which is impossible forvarargfunctions. Arguments are pushed on the stack from right to left. Thethispointer is passed via register ECX, and not on the stack.如果函数有
__thiscall修饰则被调用者清理自己的栈,因此变参函数难以实现.函数参数从右向左压栈.this指针通过ECX寄存器传递
On ARM, ARM64, and x64 machines,
__thiscallis accepted and ignored by the compiler. That’s because they use a register-based calling convention by default.在ARM,ARM64还有x64机器上,
__thiscall会被编译器直接忽略.因为编译器默认使用一种基于寄存器的调用约定
<<ida权威指南>>

x64上的调用约定
Microsoft x64 calling convention
The Microsoft x64 calling convention[18][19] is followed on Windows and pre-boot UEFI (for long mode on x86-64). The first four arguments are placed onto the registers. That means RCX, RDX, R8, R9 for integer, struct or pointer arguments (in that order), and XMM0, XMM1, XMM2, XMM3 for floating point arguments. Additional arguments are pushed onto the stack (right to left). Integer return values (similar to x86) are returned in RAX if 64 bits or less. Floating point return values are returned in XMM0. Parameters less than 64 bits long are not zero extended; the high bits are not zeroed.
微软x64调用约定适用于Windows和UEFI.
前四个参数,如果是整数或者结构体或者指针类型,则放在寄存器RCX,RDX,R8,R9寄存器里,如果是浮点数则放在XMM0到XMM3里
额为的参数放在栈里(从右向左压栈)
返回值如果小于等于64位则放在RAX寄存器里(类似于x86的情形)
浮点返回值放在XMM0里
小于64位的参数进行有符号拓展
Structs and unions with sizes that match integers are passed and returned as if they were integers. Otherwise they are replaced with a pointer when used as an argument. When an oversized struct return is needed, another pointer to a caller-provided space is prepended as the first argument, shifting all other arguments to the right by one place.[20]
结构体和联合体如果大小与整形匹配则被当作整形进行参数传递还有返回.否则,当他们作为参数时,会被一个指针替代
当需要一个超大的结构体需要返回时,指向调用方提供的空间的另一个指针将作为第一个参数,将所有其他参数向右移动一个位置
When compiling for the x64 architecture in a Windows context (whether using Microsoft or non-Microsoft tools), stdcall, thiscall, cdecl, and fastcall all resolve to using this convention.
不管使用的编译器是不是微软的工具,对于x64体系,stdcall,thiscall,cdecl,fastcall都会被忽略,然后使用上述方法处理
In the Microsoft x64 calling convention, it is the caller’s responsibility to allocate 32 bytes of “shadow space” on the stack right before calling the function (regardless of the actual number of parameters used), and to pop the stack after the call. The shadow space is used to spill RCX, RDX, R8, and R9,[21] but must be made available to all functions, even those with fewer than four parameters.
在微软x64调用约定中,调用者在调用其他函数之前,有义务在栈上分配32字节的”影子空间”,并且忽略实际上参数占用的大小,并且在调用结束后由调用者清理被调用者的堆栈.
影子空间的作用是用于将来存放RCX,RDX,R8,R9中的前四个参数,但是即使是没有不够四个参数的函数,也会预留一个32字节的影子空间
The registers RAX, RCX, RDX, R8, R9, R10, R11 are considered volatile (caller-saved).[22]
RAX, RCX, RDX, R8, R9, R10, R11这些寄存器都是volatile修饰的
The registers RBX, RBP, RDI, RSI, RSP, R12, R13, R14, and R15 are considered nonvolatile (callee-saved).[22]
RBX, RBP, RDI, RSI, RSP, R12, R13, R14, and R15不用volatile修饰
For example, a function taking 5 integer arguments will take the first to fourth in registers, and the fifth will be pushed on top of the shadow space. So when the called function is entered, the stack will be composed of (in ascending order) the return address, followed by the shadow space (32 bytes) followed by the fifth parameter.
举个例子,一个有5参数的 函数,其前四个参数将会被放在寄存器里然后第五个参数竟会别压入栈顶,并且在影子空间之上.
因此当进入被调用函数时,栈中的组成按照从栈顶到栈底将是:返回值,影子空间,第五个参数
这里影子空间就是给前四个参数腾空,前四个参数使用寄存器传递之后在被调用者中会被重新压栈,即压入这个预留的影子空间

维基百科这样写的:

x86 x64调用约定及传参顺序 - 一瓶怡宝 - 博客园 (cnblogs.com)
同样的程序test.c
1 | int func(int a,int b,int c,int d,int e,int f,int g,int h){ |
使用如下命令gcc -O0 test.c -c -o test.o|objdump -d test.o > t.s|code t.s
首先不用编译优化,将test.c编译成目标文件test.o,
然后使用objdump反编译得到反汇编代码t.s
1 | test.o: file format pe-x86-64 |
1.函数名没有下划线前缀
2.show和main函数都有固定的格式:
1 | push %rbp ;rbp是被调用者保存的寄存器,当前函数可以使用,但是最后结束的时候要还原rbp的状态,因此压栈存储先前状态 |
3.关于show函数在调用具有8个参数的func函数时,参数如何安排
关于蜜汁操作参数安排
1.后面第5到8个参数使用栈传递,5位于0x20+rsp,8位于0x38+rsp,即约靠左的参数越靠近栈顶rsp
2.前面1到4个参数==使用寄存器传递==
3.在进入被调用者函数后,将刚才调用者通过寄存器传递的参数也放进栈里,
并且x64上调用者在为子函数申请栈空间的时候也会有意申请很大,为待会儿寄存器中的参数也压栈做准备
实际上这三条都完成之后和x86上的结果是相同的,
2
func(ecx,edx,r8d,r9d,远离栈顶的地方,...,靠近栈顶的地方);
关于蜜汁操作四字节的int在栈上分配8字节空间:
在64位不管是windows还是linux系统上int都是4字节的,long long都是8字节的
上面这段程序中各个参数改成short,int,long,long long类型之后反编译得到的汇编语言,在为子函数申请栈空间的时候都是0x40=64个字节
即参数不管什么类型都是以8字节传递的,这一点可以从使用r9d寄存器传递int参数看出
2
68: 41 b8 03 00 00 00 mov $0x3,%r8dr开头的寄存器都是4字寄存器,理论上是放long long 的,但是这里int也用了r9d传递
关于蜜汁操作就在下一行的指令还要call
案发现场:
2
3
4
5
8b: e8 00 00 00 00 callq 90 <main+0xd> ;蜜汁操作,90行就在下面,为啥要call一下
90: e8 a5 ff ff ff callq 3a <show>
95: b8 00 00 00 00 mov $0x0,%eax
...写一个更短的程序观察这个事
test.c
2
3
4
int main(){
foo();
}
2
不开任何编译优化,反汇编反编译得到
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 90 nop
5: 5d pop %rbp
6: c3 retq
0000000000000007 <main>:
7: 55 push %rbp
8: 48 89 e5 mov %rsp,%rbp
b: 48 83 ec 20 sub $0x20,%rsp
f: e8 00 00 00 00 callq 14 <main+0xd>
14: e8 e7 ff ff ff callq 0 <foo>
19: b8 00 00 00 00 mov $0x0,%eax
1e: 48 83 c4 20 add $0x20,%rsp
22: 5d pop %rbp
23: c3 retq
24: 90 nop
...
main+0xf处的callq,将下一条指令也就是main+0x14压栈,然后修改程序计数器为main+0xf,即执行jmp main+0xf
main+0x14处的callq,将下一条指令地址也就是main+0x19压栈,然后修改程序计数器为foo地址,即执行jmp foo
foo执行到最后有一个retq作用是将栈顶刚才压入的main+0x19还给程序计数器rip,然后退栈,即pop %rip这样看起来程序已经出错了,栈顶还有一个
main+0xf没有弹出,但是main+0x22处有一个退栈将位于栈顶main+0xf弹给了%rbp寄存器,然而实际上%rbp寄存器应当获取次栈顶的值,即在main+0x7压入的值出错的原因是
main+0xf处的call指令调用的不是一个函数,没有与该call指令相对应的ret指令,这导致了call前压栈但是call后不退栈.下面正向编译观察这个事情
使用
gcc -S选项正向编译成汇编语言
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
pushq %rbp
.seh_pushreg %rbp
movq %rsp, %rbp
.seh_setframe %rbp, 0
subq $32, %rsp
.seh_stackalloc 32
.seh_endprologue
call __main
call show
movl $0, %eax
addq $32, %rsp
popq %rbp
ret
.seh_endproc
.ident "GCC: (tdm64-1) 9.2.0"第9行有一个
call __mainstackoverflow上的说法
Calls the ___main function which will do initializing stuff that gcc needs. Call will push the current instruction pointer on the stack and jump to the address of ___main
调用
__main函数,初始化gcc需要的材料.该调用将当前程序计数器压栈然后跳转__main函数显然我们
gcc -c生成的目标文件.o是没有__main函数的 ,该函数应当是链接阶段加上去的那么我们编译成exe文件之后再反编译进行观察
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
401633: 55 push %rbp
401634: 48 89 e5 mov %rsp,%rbp
401637: 48 83 ec 20 sub $0x20,%rsp
40163b: e8 c0 00 00 00 callq 401700 <__main> ;此call确实调用了__main函数
401640: e8 a5 ff ff ff callq 4015ea <show> ;此call调用了show函数
401645: b8 00 00 00 00 mov $0x0,%eax
40164a: 48 83 c4 20 add $0x20,%rsp
40164e: 5d pop %rbp
40164f: c3 retq
0000000000401700 <__main>:
401700: 8b 05 2a 59 00 00 mov 0x592a(%rip),%eax # 407030 <initialized>
401706: 85 c0 test %eax,%eax
401708: 74 06 je 401710 <__main+0x10>
40170a: c3 retq ;有ret语句
40170b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
401710: c7 05 16 59 00 00 01 movl $0x1,0x5916(%rip) # 407030 <initialized>
401717: 00 00 00
40171a: e9 71 ff ff ff jmpq 401690 <__do_global_ctors>
40171f: 90 nop此时可以看到,两个call都是调用的函数,并且调用的函数都有ret语句与call匹配
还要补充的是关于对齐:申请栈空间时要按照16字节对齐申请
System V AMD64 ABI

CSAPP写道,参数传递时可以用到六个寄存器,多余的参数用栈传递,是指在64位linux环境下,
而windows上只能用四个寄存器传递参数,多余的用栈传递

还是刚才的c程序,在ubuntu上的情况
main.c
1 | int _cdecl func(int a,int b,int c,int d,int e,int f,int g,int h){ |
其反汇编代码
1 | main.o: file format elf64-x86-64 |
1 | func(para1,para2,para3,para4,para5,para6,para7,...,paran) |