CSAPP-chapter8
感觉大一上学期c语言还有下学期基于c语言的基础课程设计学得好失败.
当时一个位图放缩,我既不懂位图格式,也不懂二进制文件,还不熟悉glibc函数.
本学期操作系统,更是云里雾里,对虚拟内存,进程等概念从未听过,却上来就要讲缺页置换算法,调度算法等等各种算法
对于CSAPP这本书,只能说相见恨晚,应当替代大一下的基础课程设计,作为计组和操作系统先修课.
欠的债在大二下才还上,可以说亡羊补牢?
异常
控制流
一个没有跳转,正常执行的程序,其执行过程中程序计数器PC总是连续变化的,
假设指令序列为
$$
I_1,I_2….,I_n
$$
指令对应的地址为
$$
A_1,A_2,…,A_n
$$
由于x86上的指令采用变长编码方式,因此$A_1,A_2,…,A_n$有可能不是等差数列,但是可以啃腚的是他们连续,
程序计数器PC的值构成的序列被称为控制流,如果程序一直顺序进行没有调用跳转返回,并且没有发生异常,则PC的值一直连续,这样的控制流称为”平滑的”
当程序中有跳转,函数调用,函数返回,或者异常时,控制流不再平滑,此时控制流被称为”异常控制流”(ECF)
异常控制流包括跳转,调用,返回,异常等
异常的定义
先说一些必要的废话
定义:异常就是控制流中的突变,按照这个定义,跳转,调用,返回,异常处理程序都是
异常是异常控制流(ECF)的一种,需要硬件和操作系统协同实现.
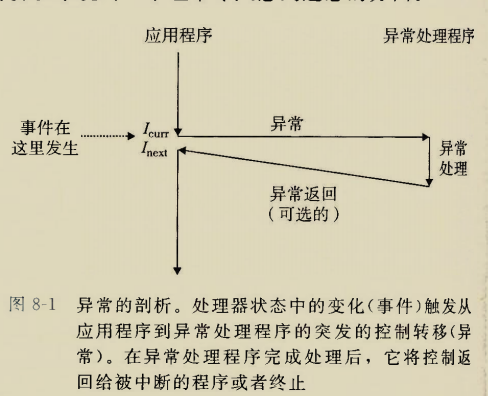
异常处理的过程
序幕:异常的触发
异常是如何触发的呢?
处理器中的重大状态变化,状态可以是某些寄存器中的某些位等,被处理器检测到(检测电平的变化对于处理器来说易如反掌,可以实现)
就好像一个人走着走着感觉低血糖了 ,这人自然就感觉到了,然后对低血糖的对策应该吃点糖.这吃点糖就是异常处理程序
吃完糖然后缓过来了继续走路
这就是控制还给之前正在执行的指令
如果低血糖非常厉害,人直接寄了,相当于发生了终止,先前的进程不再进行
开端:异常的察觉与定性
处理器根据状态位的变化判断,发生甚么事了
就好像这个走路的人走着走着感觉头晕,无力,快要饿死,这三种状态一组合,人就知道发生了低血糖
每种事件在制作处理器时都已经交给处理器一个编号,发生某种事件处理器就可以知道对应哪个编号
就好比从小就教给这个人,
高血糖编号0,
低血糖编号1,
尿急编号2,…
然后有一天这个人犯了低血糖,他就知道自己犯了编号为1的毛病
但是这个人知道了自己犯了1号病有啥意义呢?实践生活中也确实没有这样整,应该是怪没有意义的
那么给事件编号的意义又是啥?
这种编号感觉类似协议,处理器调用异常处理程序的时候只需要根据特定的编号去调用特定的处理程序,而处理程序的代码不是处理器管,是操作系统维护的异常表管的,那么处理器用什么信息去查表调用相关的异常处理程序呢?
如果现实中也是这样,人知道了自己犯了1号毛病,去了门诊直接说”我犯了1号病”,大夫就知道应该开葡萄糖的药,不需要病人费一大堆话描述“我犯了 头晕无力饿 的病”
同样,处理器在查表之前将自己的各种状态量化成一个魔数,把最困难的事自己解决了,然后用这个魔数去查表岂不是轻轻松松
但是现实生活中并没有给低血糖这种病编号,看起来这种方法很简单快捷,为什么不用?
一是人生活中要记的事情已经太多,病的编号记不住,二是病人觉得是1号病但是大夫可能不这样认为,有可能是更大的毛病
但是对机器来说,没有这么多的可能,根据状态位的变化,已经可以清楚地确定发生了甚么,并且每种毛病的编号都已经被写入硬件,永远牢记,因此可以使用这种方式
发展:根据事件号查异常表
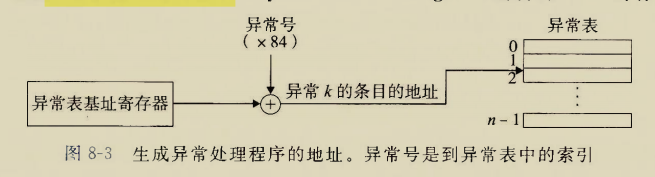
处理器确定事件及事件编号之后,要根据事件编号采取相应的异常处理程序,这时需要去查异常表
异常表是由操作系统启动时分配和初始化的,存放在主存中,事件编号作为下标,异常处理程序的地址作为表项
用事件编号作为下标去查异常表,获得的表项是异常处理程序的地址,然后控制交给该异常处理程序
整个查表的过程与页表的工作方式很像
单级页表的下标是虚拟页号VPN,页表项是物理页号
处理器怎么知道表在哪里的呢?
异常表的起始地址会专门被一个寄存器–异常表基址寄存器(exception table base regsiter)保存,这个寄存器在CPU里
查表的时候
etbr寄存器中存放基址,异常号(可能存放在某个寄存器中)作为偏移量,两个加起来去访问数组项
高潮:异常处理
刚才查完异常表之后处理器已经获得了异常处理程序的首地址,处理器只需要把PC值改为该异常处理程序的首地址
看到这里不禁疑惑,如果异常不是很严重可以被处理,处理完了怎么回到刚才的程序呢?谁来保存刚才进程的执行现场呢?
CSAPP用异常处理和函数调用的对比解决了这个疑惑
执行异常处理程序之前,处理器会将返回时的指令地址,以及其他一些状态(通用寄存器,堆栈指针,程序状态字等等)统统滴压入内核栈,注意不是用户栈
这里从异常处理程序返回时的指令地址只有两种,要么是触发异常的指令地址,要么是下一条指令,
具体是那一条要根据事件类型确定,即根据事件编号确定.
这是后话
为什么要压入内核栈?我的猜测是
异常处理程序要运行在内核状态,访问内核栈方便
为什么异常处理程序要运行在内核状态?我的猜测是
异常处理程序需要请求一些内核的资源,比如缺页异常处理程序会进行磁盘到内存换页的操作,设计了IO操作.而这些在用户状态没有权限做到
上述进程信息都压内核栈保存之后,PC置为异常处理程序的地址,控制交给异常处理程序(或者说异常处理程序占用处理器)
结局:异常处理完了返回
首先考虑一个人大街上走着低血糖了可能怎么处理
一是轻微的,吃块糖缓过来接着走
二是稍微严重,回家歇着了,改天再出来
三是非常严重,人暴毙了(虽然几率不大),这辈子不可能再走路了,也省了处理的麻烦
根据引发异常的事件类型,异常处理完后的返回也可以分成三种
1.返回给当前指令(触发异常的指令),重新进行,比如缺页异常
2.返回给当前指令的下一条指令
下一条指不发生异常时下一条应该执行的指令
3.发生异常的程序被中断,不再执行
异常的类别
异常就四种,中断,陷阱,故障,终止
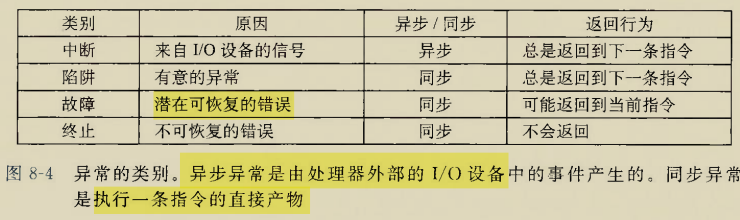
其中只有属于异步异常的中断发生在CPU之外,只能由IO设备产生,比如按下键盘,点击鼠标,打印到屏幕,等等各种事件
陷阱是有意为之的,目的是从是处理器从用户态陷入内核态(通过修改某种标志位),作用是拥有使用任意资源的权限,比如syscall指令
故障和终止都是不希望发生的,区别是故障算是比较轻微的异常,比如缺页,通过牺牲物理页换入缺页就可以解决
但是终止就是比较严重的异常,程序无法继续运行了,比如栈缓冲区溢出被金丝雀检测到
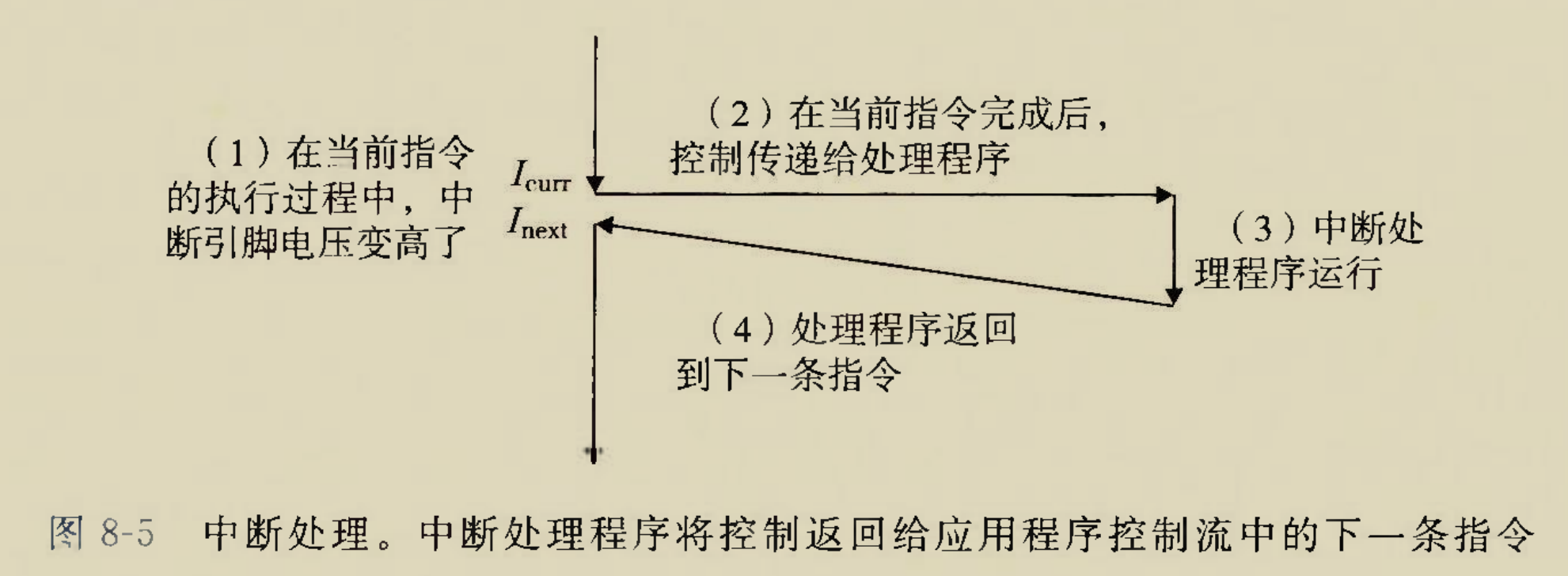
中断
此处的”中断”更确切的是说”外部中断”或者”硬件中断”,即IO外设导致的中断,不是程序有意产生的中断
up九曲阑干举例是键盘输入导致的中断
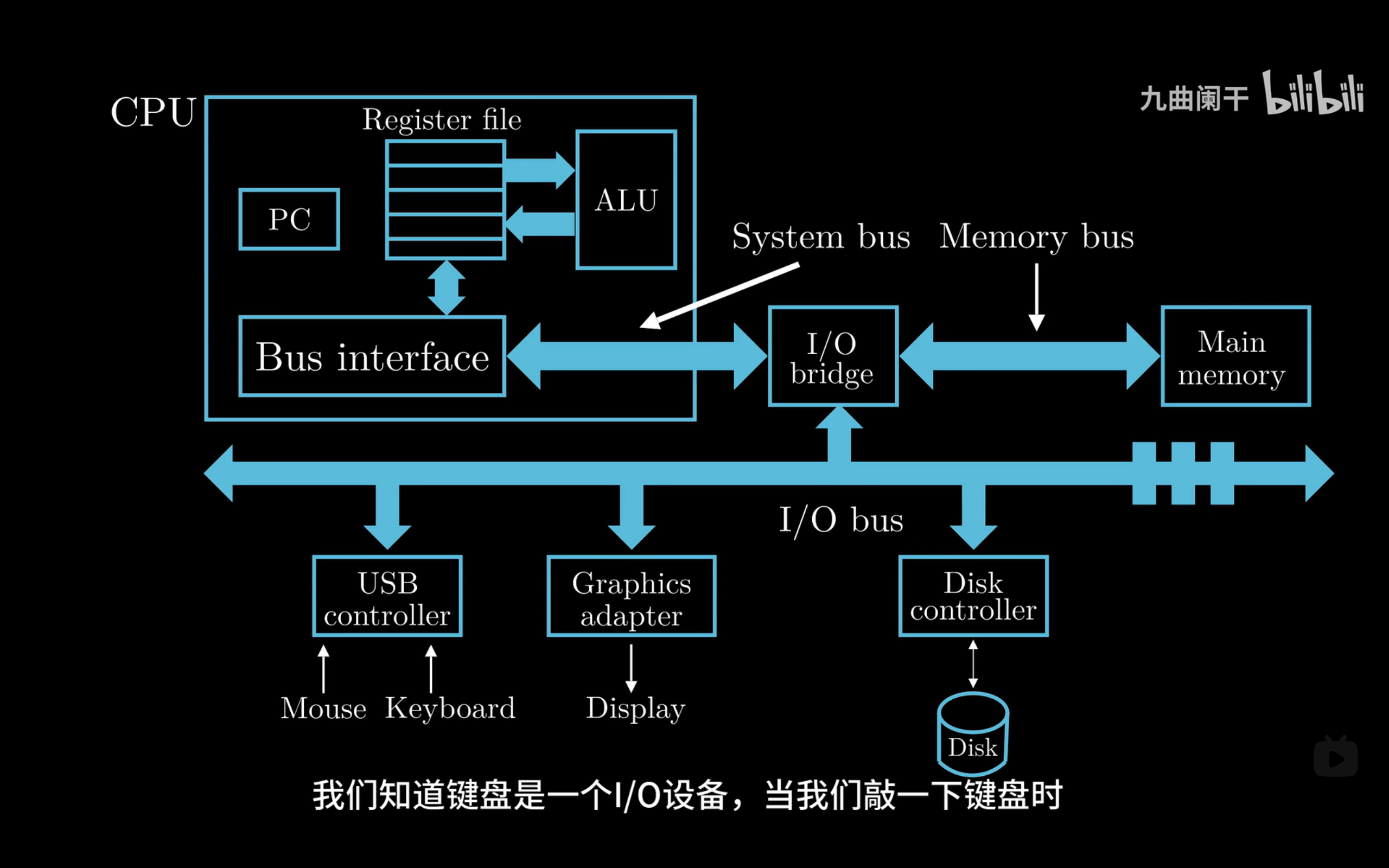
在这个计算机的模型机中,内存总线和IO总线不是一路,但是汇集到IO桥,然后IO桥通过系统总线连接到CPU中的总线接口,总线接口是与CPU内部寄存器相连的
IO总线上挂着的都是IO外设,比如USB,显示器,键鼠,磁盘等等,计算机就算没有这些东西也可以运行
按下键盘的时候,键盘控制器会向处理器的中断引脚发送中断信号,并且会把异常号通过IO总线,IO桥,系统总线传递给CPU,
中断信号的目的是提醒CPU应该处理中断了,异常号的作用是告诉CPU是键盘出现异常,而不是鼠标
中断信号和异常号都是CPU判断异常事件需要用到的信息
由于键盘发送信号和CPU处理指令是异步的,因此当键盘发送中断信号的时候,CPU有可能还在执行一条命令.CPU必须完成了手头上那一条命令之后,才可以处理中断.
完成手头上的指令后,CPU检测到中断引脚那里发生了电位变化,因此知道发生中断了,然后通过异常号知道是哪个IO设备发生了中断,根据这两个信息CPU就能确定发生了什么事,下面就可以异常处理了
异常处理完之后,应该返回什么地方呢?由于刚才手头上的最后一条指令已经被彻底执行了,自然应该返回下一条指令.
这就好比
正在写作业,突然有人敲门,为了防止当前正在解决的数学问题思路被打断重来,我先做完这道题,然后去处理访客的问题
到了门口得先问问是谁在敲门,是熟人就开门
然后得端茶倒水儿,把客人招待好,等客人走了把门一关回去接着做下一道题
这里数学题就相当于CPU正在执行的指令,
敲门这个信号就相当于中断引脚上的电位变化,
做完这道题再去开门就相当于CPU执行完当前一条指令然后再去处理中断,
询问访客姓名和敲门合起来,相当于CPU确定事件号,
招待客人的过程相当于执行中断处理程序
客人走了继续做下一道题相当于中断处理完成之后返回下一条指令
综上,中断处理过程的流程图表示为
从数学作业的角度来说,中间招待客人的时候,数学作业没有被处理,但是作业本子也不知道这个做题的是玩电脑去了还是蹲坑去了还是招待客人去了.反正这不重要.重要的是不管中间干了啥,数学作业都是被完整做完的.
因为访客和做作业是异步的,所以招待客人和数学作业玩不玩成一点关系都没有
从正在执行的进程角度看,发生中断被抢占CPU和被其他进程抢占CPU没有区别,进程也没有因为中断被改变什么
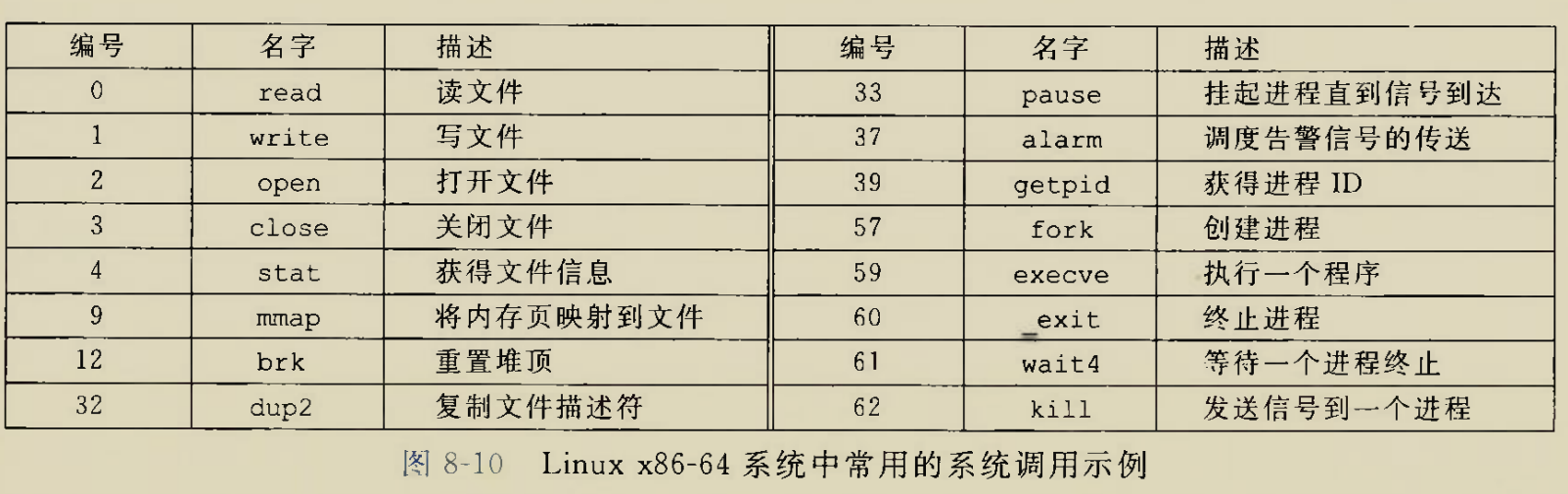
陷阱(系统调用)
陷阱又可以理解为软件主动产生的”软中断”,是有意为之的
系统调用,陷阱最重要的用途是在用户程序和内核之间提供一个像过程一样的接口,又叫做系统调用。
在网上搜索的时候,感觉有一种广义的”系统调用”,表示一整个从用户程序到硬件然后再返回用户程序的过程
感觉还有一种狭义的系统调用,就是导致CPU从用户态改变到内核态那关键的一条汇编指令
int $0x80
系统级函数,比如open(),read(),close()等等,涉及IO操作,显然只在用户态是干不成事情的,需要使用内核的资源,需要陷入内核态,因此需要去执行系统调用
我们写的程序怎么陷入内核态呢?在c源代码层面上只需要调用glibc中的系统级函数
汇编语言层面观察系统级函数write的实现
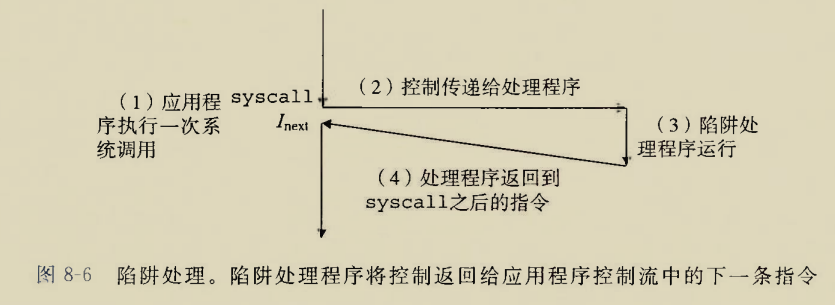
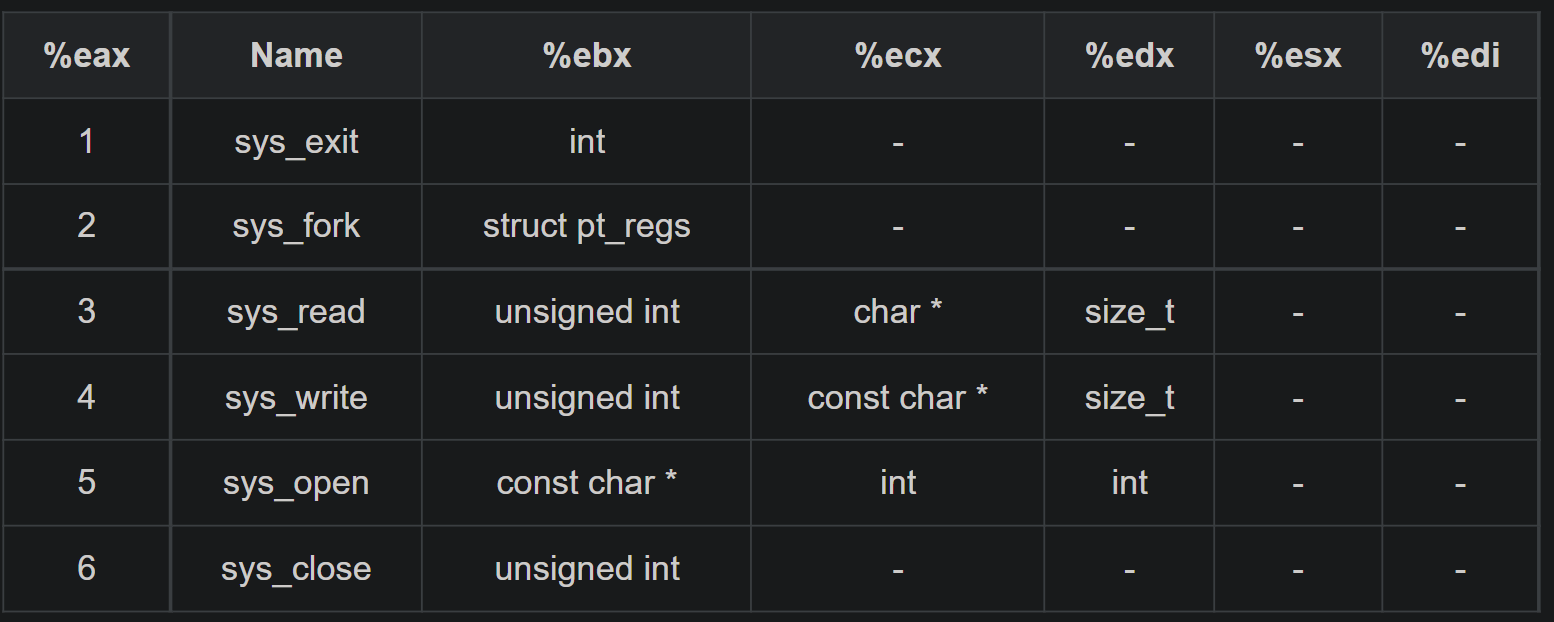
CSAPP上给出的x86-64linux系统调用号表(感觉这里系统级函数和系统调用的概念有些混淆,应该是广义的系统调用)
调用write
系统调用号用rax传递
文件描述符用rdi传递
字符串用rsi传递
字符串长度用rdx传递
syscall即侠义的系统调用

在用户视角下系统调用过程示意图
程序员视角意味着”陷阱处理程序”是一个抽象的概念,程序员知道系统要做这么一个陷阱处理,但是具体做了啥程序员不知道,
程序员可以知道的是自己的程序会调用syscall,然后CPU的使用权就不属于自己的程序了,而是属于陷阱处理.程序员还知道的是陷阱处理之后的结果,比如调用write之后将缓冲区
char buffer[20];中的字符打印到了屏幕上
废话:为什么要有陷阱(系统调用)这种异常?

c库函数,系统级函数,系统调用的关系
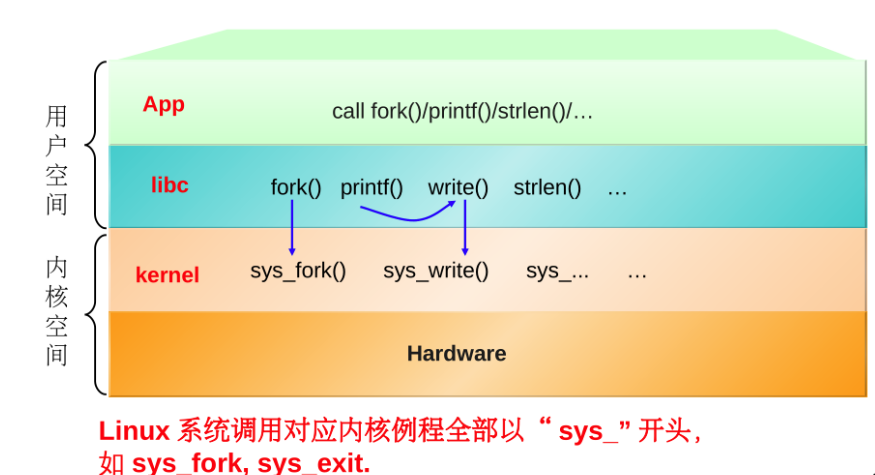
c库函数
libc和glibc都是Linux下的c函数库
glibc是linux下面c标准库的实现,即GNU C Library。glibc本身是GNU旗下的C标准库,后来逐渐成为了Linux的标准c库,而Linux下原来的标准c库Linux libc逐渐不再被维护。Linux下面的标准c库不仅有这一个,如uclibc、klibc,以及上面被提到的Linux libc,但是glibc无疑是用得最多的。glibc在/lib目录下的.so文件为libc.so.6。
c函数库中的函数非常多,可以按照有没有涉及系统调用进行分类
涉及系统调用的
printf,scanf,malloc,free等,这些函数都是系统级函数,这些函数执行系统调用陷入内核不涉及系统调用的
itoa,strstr等
关于库函数和内核函数的区别,这个问题中文站点搜了好多,全在扯淡,最后参考了 stackoverflow
比如内核函数sys_fork就是c库函数fork系统调用入口,即当我们的的代码中使用
fork函数的时候,fork函数会去自己调用sys_fork而不是调用sys_write为啥要这样套娃呢?
因为
sys_call是内核函数,依赖于系统但是
fork是c库函数,要求POSIX可移植这就好似协议分层,
fork所在高层只管调用内核提供的一个叫sys_fork函数,内核具体怎么实现这个函数不关心而内核也不知道上层会有什么,只管根据人的需要涉及
sys_fork的参数返回值,功能等等fork函数大体的调用链(踢皮球链)
内核函数
kernel函数即内核函数
Assembly - System Calls (tutorialspoint.com)给出了一个x86linux上调用write时,在内核函数层面发生的事情
x86linux内核函数表:
2
3
4
5
mov ecx,msg ; message to write ;要打印的信息msg用ecx寄存器传递
mov ebx,1 ; file descriptor (stdout) ;文件描述符,魔数1表示标准输出,即显示器
mov eax,4 ; system call number (sys_write) ;eax存放内核函数号,决定调用sys_write函数
int 0x80 ; call kernel ;陷入内核,根据先前放在eax中的系统调用号决定执行什么命令
系统命令和系统调用的关系
系统命令比如ls,ifconfig,mv,cp等等是由一个或者多个c库函数实现的,可能其中会用到系统调用.系统命令和系统调用之间还有一段距离
CSAPP上就有练习题让我们用<stdio.h>等头文件里面c库函数写一个mv命令之类的
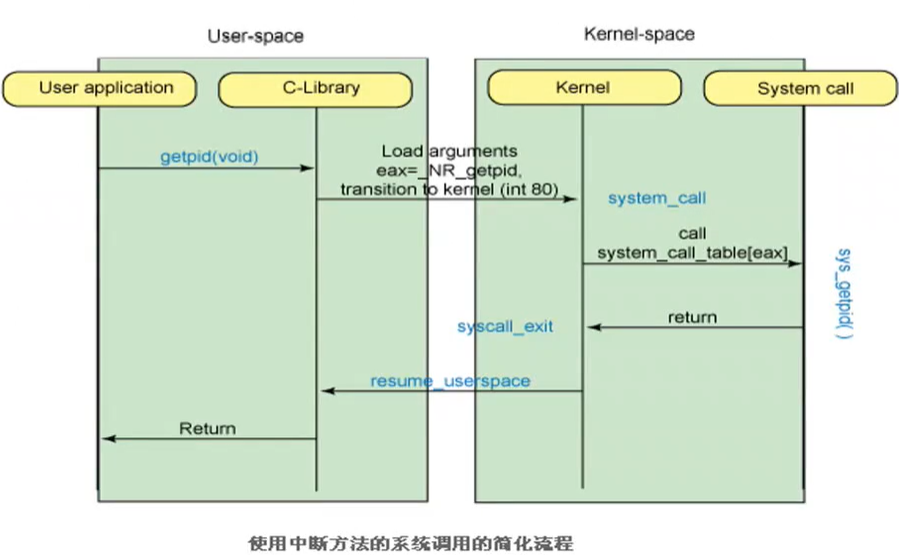
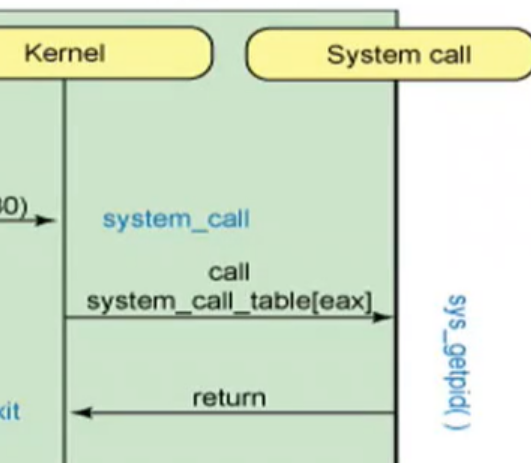
操作系统视角下的系统调用过程
用户进程通过eax寄存器将内核函数号交给system_call函数,这时已经下到kernel模式了
system_call函数的作用是,根据内核函数号去查system_call_table表,执行相应的sys_开头的内核函数,
内核函数执行完毕之后执行syscall_exit返回到system_call函数
system_call函数执行resume_userspace返回用户空间
系统调用的整个过程
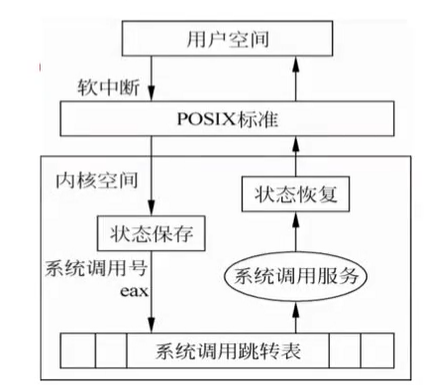
例如getpid函数系统调用的简化过程
1 | getpid() |
实验:添加系统调用
添加一个系统调用不只是向系统调用号表中添加一个表项,要考虑内核中整个系统调用过程
1.根据系统调用类型查系统调用号表获得系统调用号
2.系统调用号查内核函数跳转表找到应该执行的内核函数
3.执行内核函数
各部分的具体作用和位置如下
系统调用号表unistd_32.h
前置知识:c语言宏定义
在我校的操作系统实验中,使用的操作系统内核版本是linux-2.6.32.60
在/usr/src/linux-2.6.32.60/arch/x86/include/asm/unistd_32.h位置
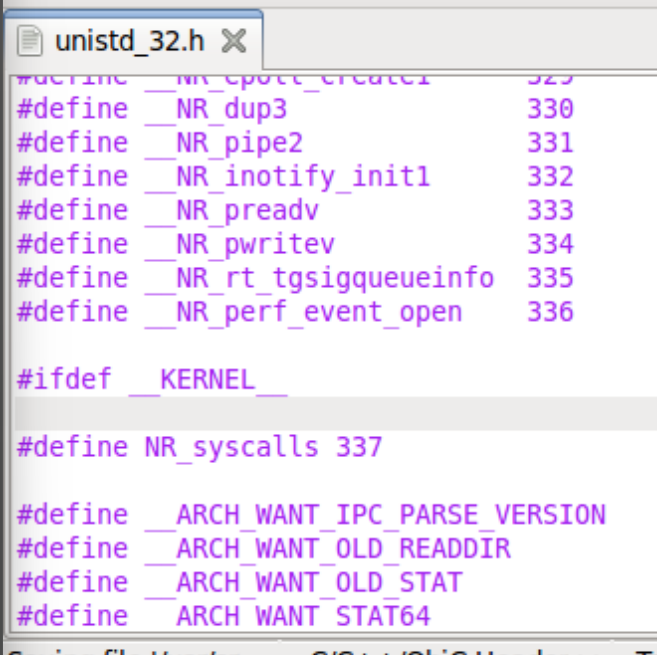
该文件中全是宏定义,形如#define __NR_exit 1,将每一个系统调用号魔数定义为一个有实际意义的字面量
1 |
|
感觉类似于DNS协议
将ip地址号映射到一个方便人类记忆的域名
将一个域名解析到一个ip地址号
内核函数跳转表syscall_table_32.S
前置知识x86汇编语言
.S:汇编语言源程序;预处理,汇编
也就是说该文件是汇编写的
内核函数跳转表以系统调用好表中的系统调用号为下标,总个数也是在unistd_32.h中宏定义的#define NR_syscalls 337
系统调用号和内核函数跳转表项是一个萝卜一个坑的关系,修改系统调用号就得修改跳转表项,因此现有的不要乱改
如果系统调用号没有对应下标的内核跳转表表项,则默认指向函数调用表中,教材中说是sys_ni_syscall()
在我校的操作系统实验课程的安排中,这个内核函数跳转表的位置在/usr/src/linux-2.6.32.60/arch/x86/kernel/syscall_table_32.S
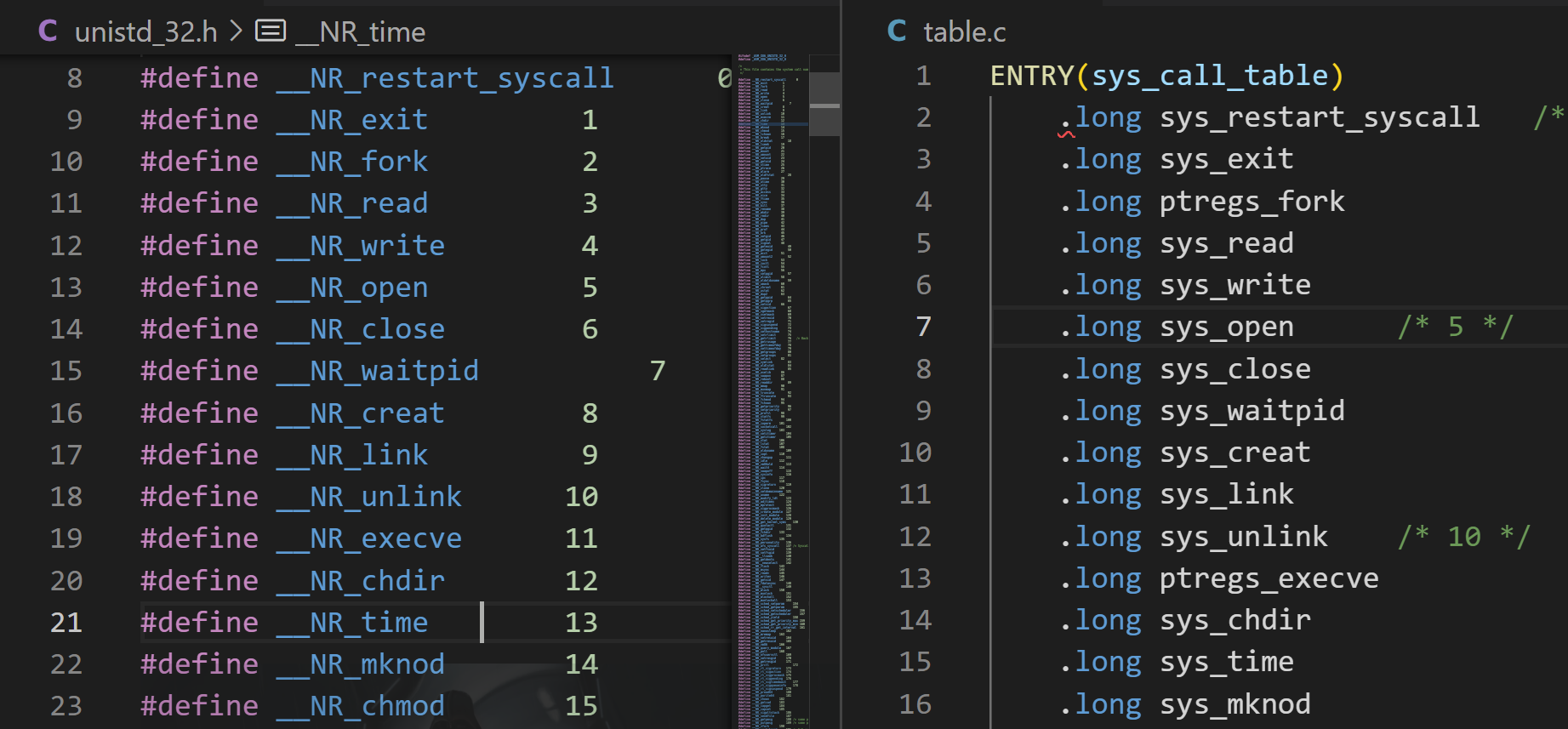
1 | ENTRY(sys_call_table) |
这个跳转表也比较类似CSAPP第三章上介绍的switch跳转表
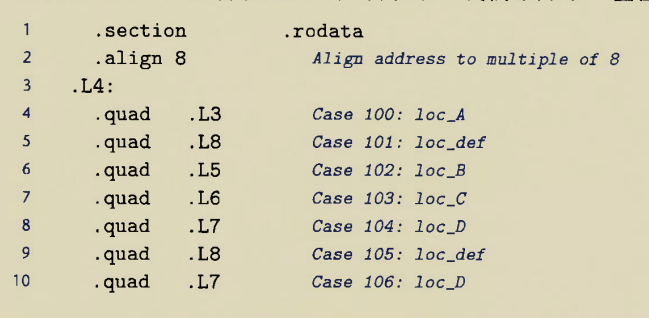
系统调用号表和内核函数跳转表有一一对应关系
内核函数声明syscalls.h
该声明在/usr/src/linux-2.6.32.60/include/linux/syscalls.h中
就是一个头文件,里面都是函数声明,在链接时起到引用的作用
1 | asmlinkage long sys_time(time_t __user *tloc); |
关于asmlinkage修饰符:
需要前置知识,x86汇编语言和调用约定
类似位置的修饰符我们见过
__cdecl,__fastcall,这里asmlinkage也是一种调用约定的修饰符,试想如果不声明该修饰符,则linux上按照System V AMD64 ABI约定的函数传参方法,前六个参数是通过edi,esi,edx,ecx,r8d,r9d这六个寄存器传递的,返回值是通过eax寄存器传递的.而对于内核函数
asmlinkage是一个宏定义#define asmlinkage CPP_ASMLINKAGE __attribute__((regparm(0))),其作用是使用
eax,ebx,ecx传递参数,eax始终传递系统调用号(内核函数号)
比如write函数从用户态下到内核态system_call时的调用过程
2
3
4
5
mov ecx,msg ; message to write ;要打印的信息msg用ecx寄存器传递
mov ebx,1 ; file descriptor (stdout) ;文件描述符,魔数1表示标准输出,即显示器
mov eax,4 ; system call number (sys_write) ;eax存放内核函数号,决定调用sys_write函数
int 0x80 ; call kernel ;陷入内核,根据先前放在eax中的系统调用号决定执行什么命令
内核函数实现sys.c
内核函数的定义实现在/usr/src/linux-2.6.32.60/kernel/sys.c里
该源文件开幕就是版权声明,是龙得卧着,是虎得盘着,我Linus是什么人不用我自己说
1 | /* |
然后include了一大堆头文件,其中就有syscalls.h
1 |
|
然后就见鬼了,一个sys_开头的函数实现都没有找到,这样syscalls.h岂不是include了个寂寞
在syscalls.h的宏定义中我们可以找到答案
1 |
|
即asmlinkage long sys_##name这种格式的函数接口都被统一地宏定义为__SYSCALL_DEFINEx(x, name, ...)
统一定义成
SYSCALL_DEFINE0到SYSCALL_DEFINE6这7种宏定义,作用是是实现起来方便
而sys.c中就有__SYSCALL_DEFINEx(x,name,...)这类函数的实现
1 | SYSCALL_DEFINE3(setpriority, int, which, int, who, int, niceval) |
我们自定义的内核函数又少又简单,没有必要也遵守这种宏定义,直接在sys.c中按照syscalls.h中的函数声明去实现函数即可.反正宏定义只是起别名,叫绰号和叫原名都不会错
我们需要做的
考虑上述各部分的作用,我们需要做的
1.添加系统调用表unistd_32.h项
修改之前:
格式比着葫芦画个瓢,修改之后
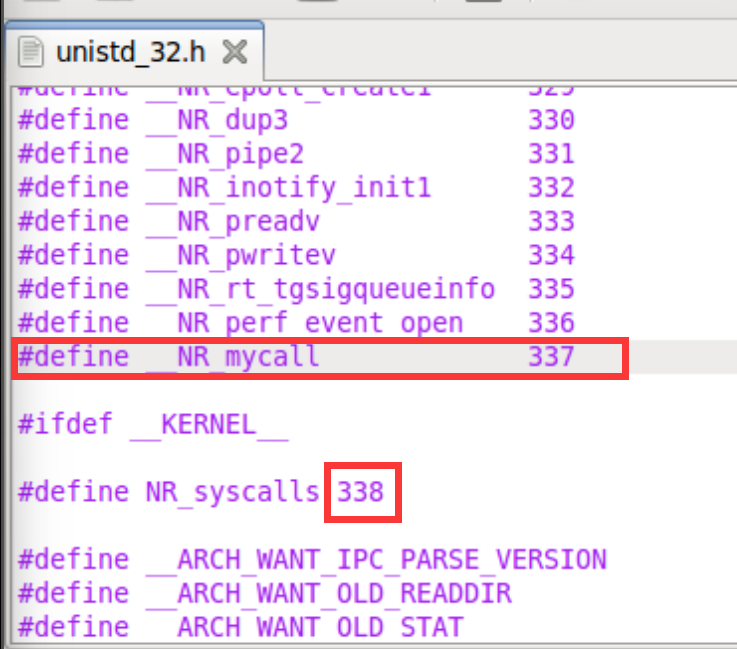
注意下面#define NR_syscalls 338也得跟着改,
这个值表示的是系统调用的总数,由于系统调用号从0开始编号,因此当我们新增一个337号时,总数有338个
2.添加内核函数跳转表syscall_table_32.S表项
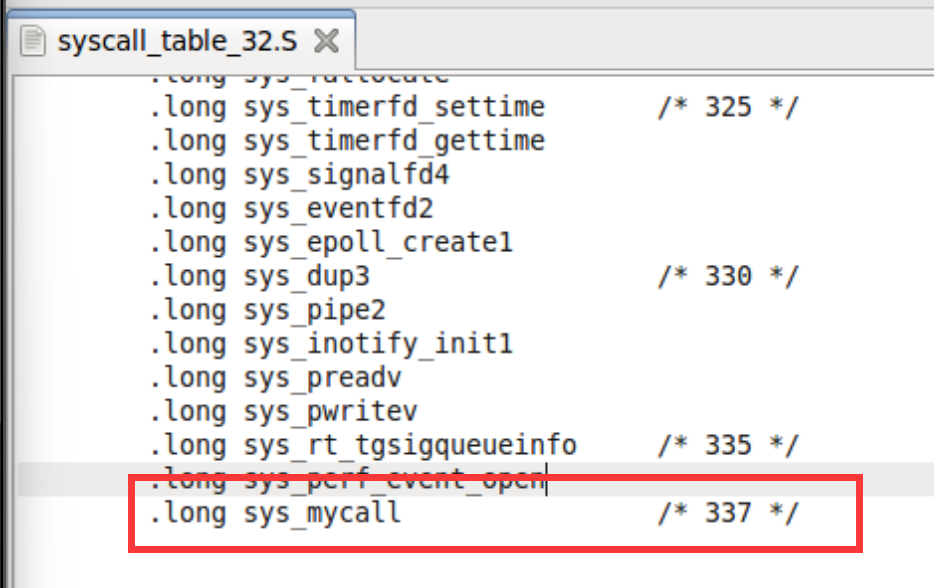
只需要在最后一行添加一项,格式比着葫芦画个瓢
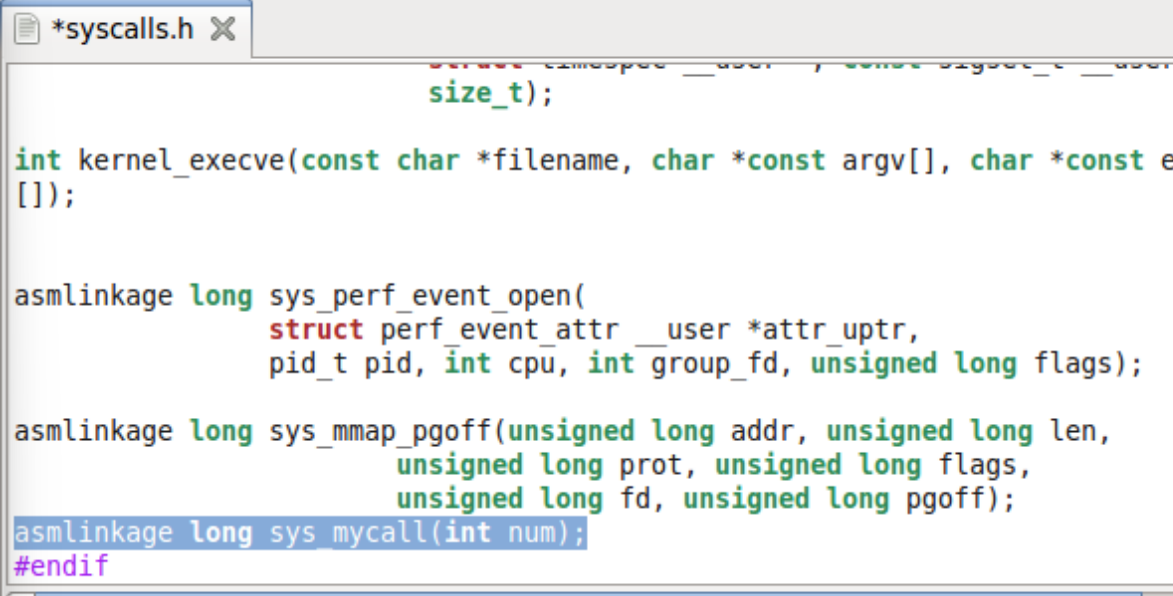
3.在syscalls.h中增加一条函数声明
注意以root打开文件才有权限修改
4.在sys.c中增加内核函数的实现
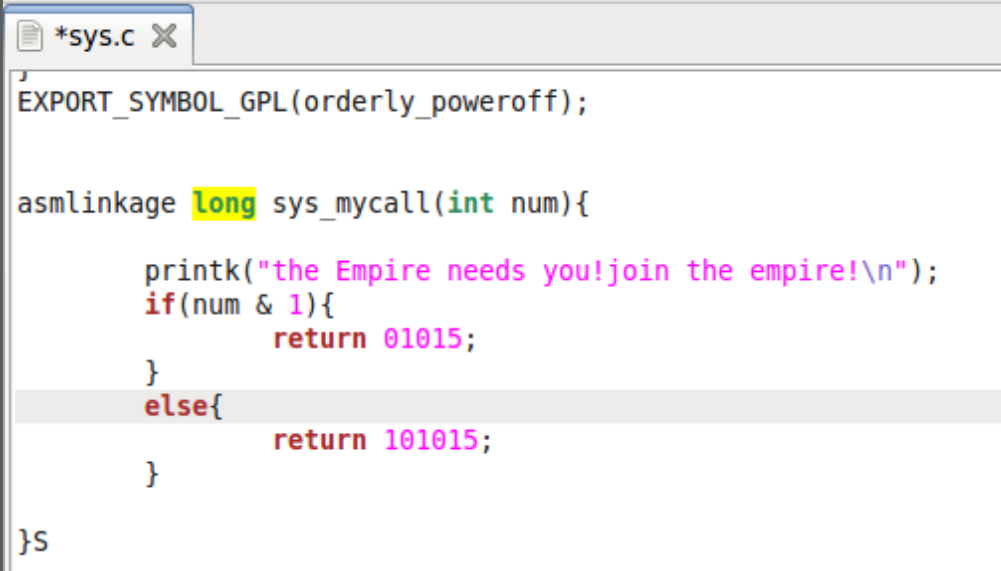
这里最后手残写了一个S一开始没发现,编译就是不通过,在形成sys.o时报错,回来看笔记才发现多一个S
5.编译内核
前置知识
linux内核
链接
makefile的编写
我几乎都不会
学校给的实验环境中写好了makefile,好长一个,整个内核的编译,我唧己啃腚写不出来.
并且makefile涉及链接操作,在CSAPP第七章有比较详细的介绍,这是后话了
然后就是makefile的语法,这我目前也不会,这也是后话了
总之就是
1 | make menuconfig #修改一下内核名称这种无关紧要的东西,其他的不敢改也不会改,在这里我 |
如果上述四步都能完整执行,真的烧高香了
编译完了会形成一个vmlinux.o目标模块,链接后会形成vmlinux这么一个32位ELF可执行文件

后面两步完了之后会在/lib/modules下面生成

2.6.32-28-generic是系统原来自带的
2.6.32.60XXXXXXXXXXXXh是实验一生成的
2.6.32.60XXXXXXXXXXXXf是本次实验生成的
然后使用update-initramfs -c -k 2.6.32.60XXXXXXXXXXf生成”虚拟盘文件”
我们正在玩一个大型橙光游戏,动辄编译个把小时,以防万一,此时拍一个快照吧
6.修改grub.cfg
grub.cfg在/boot/grub/grub.cfg
比着葫芦画瓢,照抄一个稍微改一下
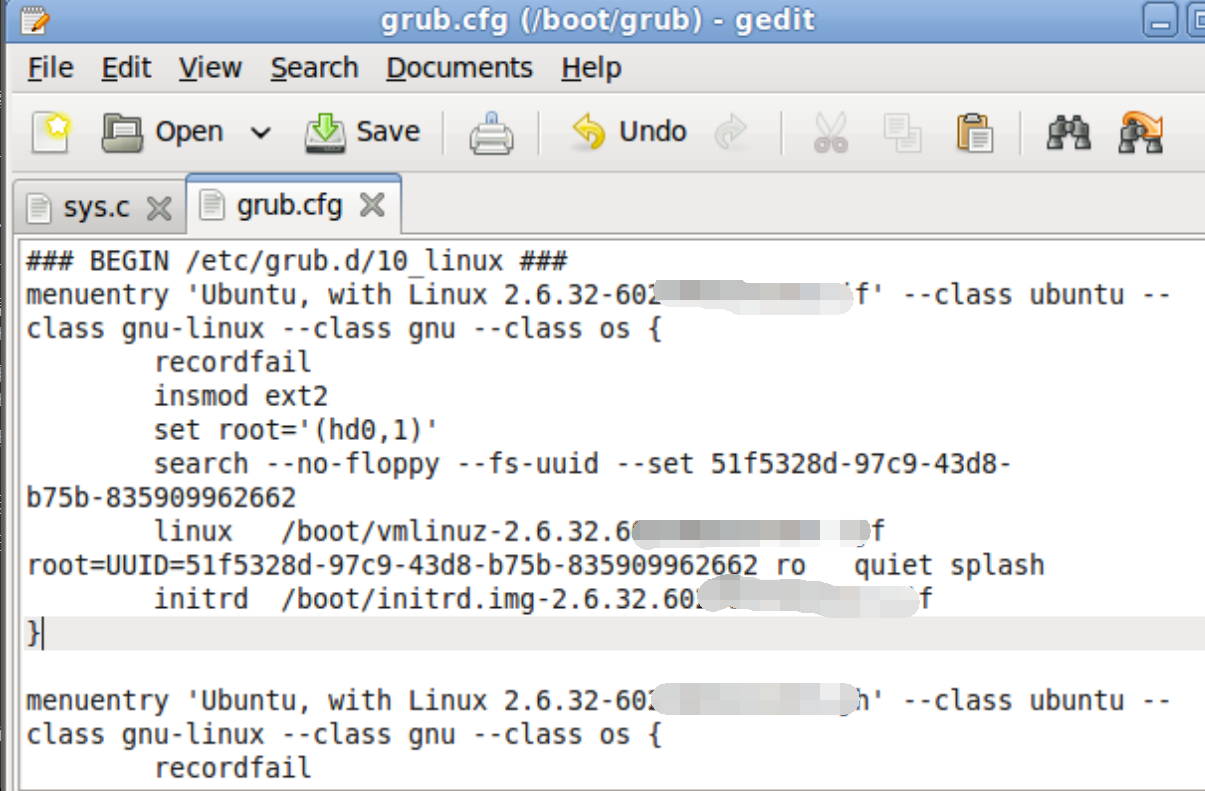
完了保存重启
7.验证
/mnt/hgfs/share/test.c中这样写
选这么一个位置纯粹是因为共享文件夹,可以在本机直接用vscode编写,虚拟机输入个字符都卡的要死
1 |
|

然后使用dmesg命令查看我们在自定义的内核函数中的输出printk,最后一行是这样的

这与我们编写的是相同的,证明我们自己新增的系统调用的整个过程奏效了
故障
由错误情况引起,可能被故障处理程序修正.
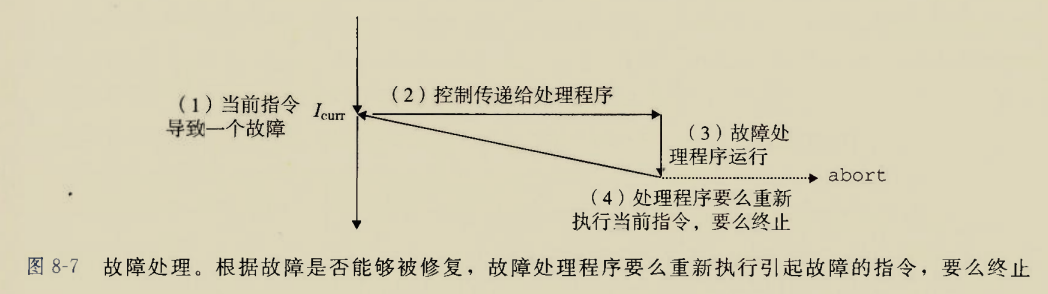
比如缺页异常
终止
发生致命错误,程序直接寄掉,处理程序将控制返回abort历程
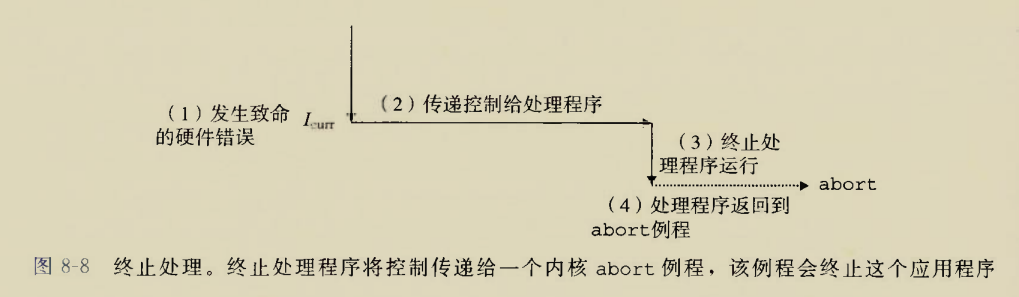
异常号
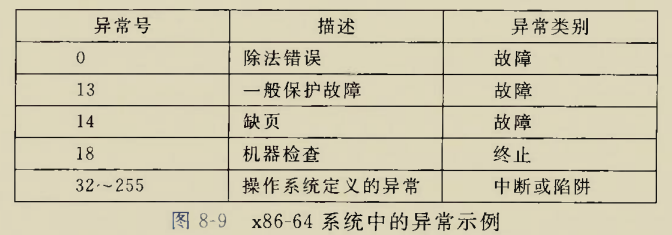
发现异常的时候会用事件号查事件表.这里的异常号不是事件号,而是对每个异常都进行编号
0~31号异常由Intel架构师定义
32~255号异常由操作系统设计师定义
进程
进程上下文:程序正确运行所需的状态组合,包括堆栈,代码和数据,通用寄存器,程序计数器,环境变量,打开的文件描述符集合
私有虚拟地址空间
用户栈往下的部分都是进程独立的虚拟地址空间
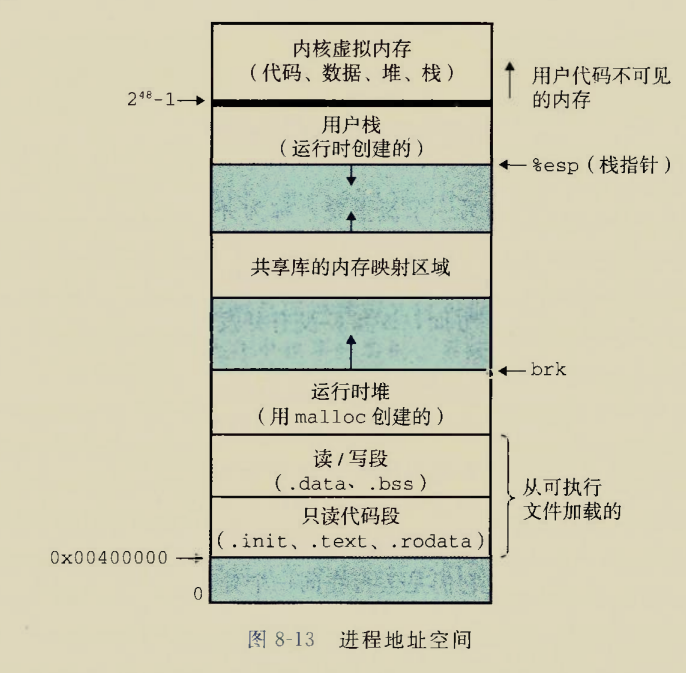
私有虚拟地址空间,不是私有物理地址空间.
共享库在主存中只有一块物理地址空间,但是在两个进程虚拟地址空间中映射到不同部分
用户态和内核态
设置两种状态的作用是,限制进程对内核数据结构的访问修改,只有操作系统进程可以运行在内核态.用户应用进程永远不可能运行在内核态,用户应用进程只能通过系统调用,请操作系统去完成目的.
异常处理程序都运行在内核态
用户态和内核态怎么区分的?通过CPU中某个控制寄存器中的某个模式位
上下文切换
高层次的异常
进程上下文包括堆栈,数据和代码,各种寄存器,程序状态字,内核栈,内核各种数据结构比如页表
上下文切换的意思是,挂起当前正在运行的进程,保存其运行现场,然后执行其他进程.当该进程再次被调度时还原其运行现场
发生上下文切换时,操作系统会1.保存当前进程的上下文(放在内存里),2.恢复先前某个被挂起的进程执行现场3.控制交给该进程
上下文切换发生的时机:
1.系统调用可能引发上下文切换,比如当前进程使用系统级函数write向标准输出打印,这个过程对于CPU来说非常漫长.CPU会切换到执行另一个进程,不会等待数据写到显示器.更加明显的是sleep系统调用,不妨把话说得更明白些,直接让进程睡觉.
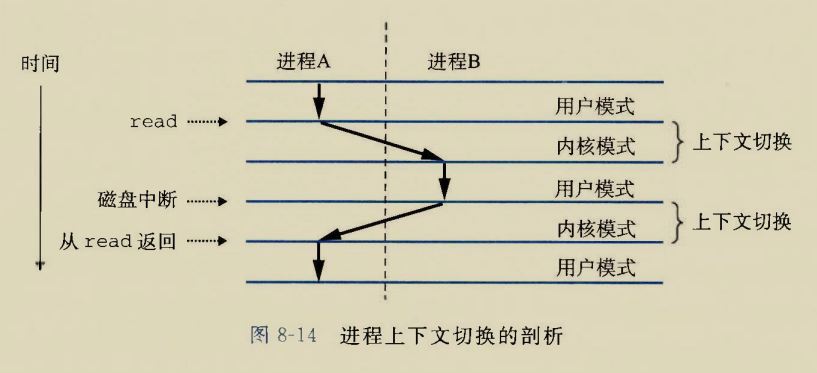
2.软件中断,进程时间片用光了,该让给另一个进程执行了.
在程序员视角,进程的状态只有三种

进程控制
控制进程的函数都是系统级函数
获取进程ID
1 |
|
proc.c
1 |
|
在bash shell命令行上编译运行
1 | ┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] |
bash调用ps程序,因此bash是ps的父进程
由于proc进程是由bash创建的,因此bash是proc的父进程
进程号只会越来越大,不会重复利用一个已经完成的进程的进程号
创建进程
1 | pid_t fork(void);//子进程返回0,父进程返回子进程pid |
非常疑惑的一点是为什么一个函数调用可以返回两次
对两个进程分别返回一次
proc.c
1 |
|
运行结果:
1 | ┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] |
不管什么进程,其进程号都是正数,不可能是0.fork对子进程的返回值为0并不代表一个进程号,而是区分子进程和父进程的标志
根据fork的返回值不同,这是一模一样的代码区分是父进程在执行还是子进程在执行的唯一标志
这里c风格fork创建进程和C++中使用thread创建线程差别很大
thread创建线程,只需创建一个thread对象,对其构造函数传递一个函数,后面该函数就会自己开一条线程执行,thread对象就是线程的句柄.可以在函数线程之外,比如主线程处,通过thread对象,很自然地操作线程的行为比如detach或者join
而在这里唯一能区分线程的句柄就是一个整数pid,并且这个pid位于进程之中,只能在运行时通过pid判断是哪一个进程.不能在进程之外操作进程的行为
fork之后原来的进程照旧执行,一个新的进程会拥有原进程的一模一样的虚拟地址空间的拷贝,包括代码数据寄存器堆栈等等.子进程和父进程的虚拟地址空间相互独立
proc.c
1 |
|
1 | ┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] |
父进程和子进程都打印到屏幕说明父子进程共享父进程已经打开的文件描述符1
用进程图描述fork是比较直观的

进程图如何实现
1.main上多个分支
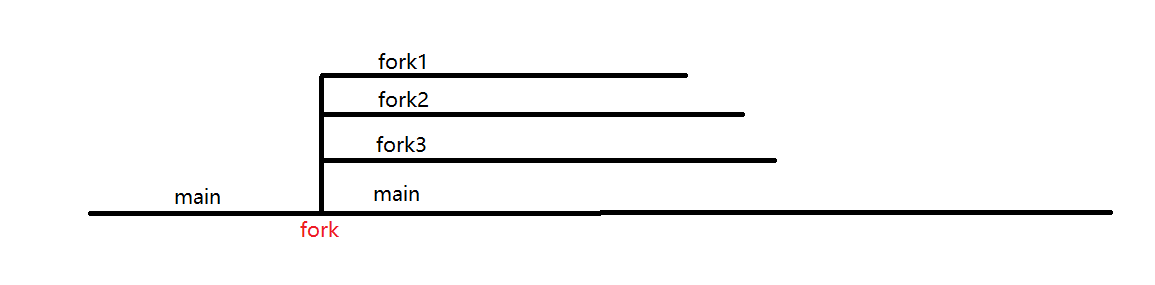
1 |
|
这样实际上的进程图
运行结果:
1 | ┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] |
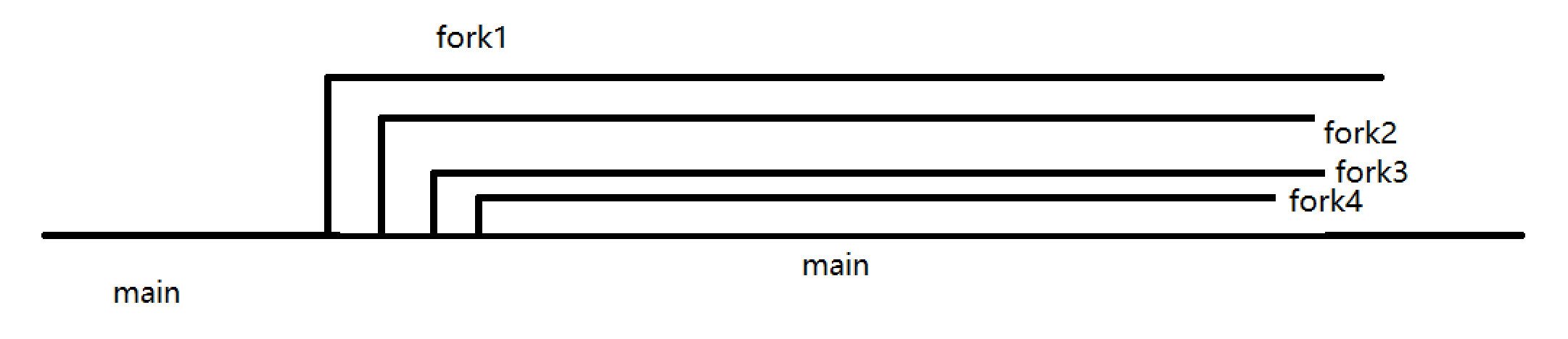
2.main和第一个子进程同时分支
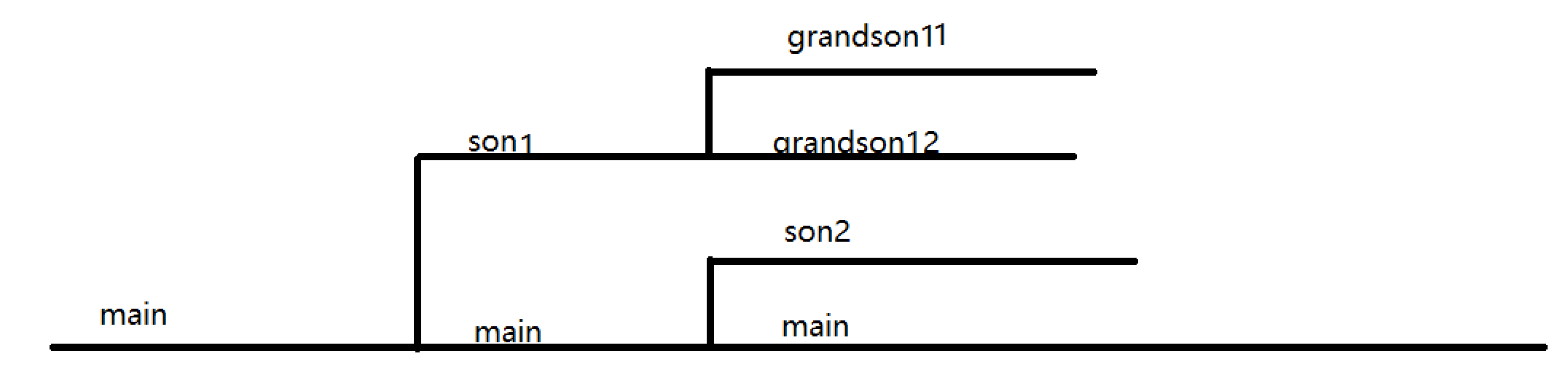
这个很容易实现
1 | fork(); |
fork前后
proc.c
1 |
|
运行结果:
1 | ┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] |
不管是父进程还是子进程,pid0=116相同,而pid1却不同,这是因为,pid0是fork之前执行的,当fork执行时,pid0已经被计算出了,作为一个局部变量压栈了,子进程不会再去计算pid0,而是从父进程堆栈的拷贝上直接拿.
但是pid1的情况不同,fork之后,子进程已经获得了父进程堆栈的拷贝,此后两个进程地址空间独立,后来的pid1就是分别计算之后分别存放在自己的堆栈里
看起来像是数据不管是fork前后都会被复制,实际上只复制了fork前的数据,此后进程各自维护自己的数据
终止进程
1 | void exit(int status);//以status状态码返回 |
proc.c
1 |
|
1 | ┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] |
回收子进程
进程终止之后并不会立刻消失地无影无踪,而是处于一种等待被父进程回收的状态,父进程回收终止子进程时,内核将子进程的exit状态传递给父进程.子进程被回收后才会消失地无影无踪
如果父进程一直没有回收已经终止的子进程,子进程就一直存在,称为”僵死进程”
如果父进程提前结束呢?内核会安排init进程成为孤儿进程的父进程
这就好比未成年的孩子父母双亡,被警察局送给孤儿院收养
这里起孤儿院作用的init进程,其pid=1,在系统启动时被内核创建,除非关机,否则永不终止.是所有进程的老祖宗.孤儿进程终止后,init会回收之
waitpid
1 | pid_t waitpid(pid_t pid,int *statusp,int options); |
**Attention!!!**当第三个参数options不设置的时候,函数的默认行为是:挂起调用进程,直到有满足条件的子进程终止。
参数意义:
1.
pid_t pid如果
pid>0则等待该指定pid的子进程终止如果
pid=-1则等待该进程的所有子进程,如果有其中的一个终止则waitpid返回该终止子进程的pid
proc.c
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
int main(){
int fpid=getpid();
int forkid=fork();
if(forkid==0){//子进程中
printf("in son process,id=%d\n",getpid());
int n=1000000;
while(n--);//拖延时间
exit(0);
}
else{//父进程中
printf("in father process,id=%d\n",fpid);
waitpid(forkid,0,0);//指定等待唯一的子进程返回 //只指定第一个参数,其他使用缺省值
printf("son process %d exit\n",forkid);
}
printf("process %d is still running\n",getpid());
return 0;
}运行结果:
2
3
4
5
6
└─$ ./proc
in father process,id=273
in son process,id=274 #父进程需要等待子进程完成
son process 274 exit
process 273 is still running2.
int *stausp如果statusp非空,则waitpid就会在statusp中记录子进程的exit status,使用指针引用传递
proc.c
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
int main(){
int fpid=getpid();
int forkid=fork();//区分父子进程
if(forkid==0){//子进程中
printf("in son process,id=%d\n",getpid());
int n=1000000;
while(n--);//拖延时间
exit(1);//子进程以status=0状态终止
}
else{//父进程中
int status=999;//设置status初始值
printf("in father process,id=%d\n",fpid);
waitpid(forkid,&status,0);//使用status承载子进程的exit状态值 //缺省第三个参数
printf("son process %d exit with status= %d\n",forkid,status);
printf("WIFEXITED(status)=%d\n",WIFEXITED(status));
printf("WEXITSTATUS(status)=%d\n",WEXITSTATUS(status));
printf("WIFSIGNALED(status)=%d\n",WIFSIGNALED(status));
printf("WTERMSIG(status)=%d\n",WTERMSIG(status));
printf("WIFSTOPPED(status)=%d\n",WIFSTOPPED(status));
printf("WSTOPSIG(status)=%d\n",WSTOPSIG(status));
printf("WIFCONTINUED(status)=%d\n",WIFCONTINUED(status));
}
printf("process %d is still running\n",getpid());
return 0;
}运行结果:
2
3
4
5
6
7
8
9
10
11
12
13
└─$ ./proc
in father process,id=41
in son process,id=42
son process 42 exit with status= 256
WIFEXITED(status)=1
WEXITSTATUS(status)=1 #这是exit(status)中的status
WIFSIGNALED(status)=0
WTERMSIG(status)=0
WIFSTOPPED(status)=0
WSTOPSIG(status)=1
WIFCONTINUED(status)=0
process 41 is still running解释status的几个宏定义
奇怪的是,status明明是一个整数,为什么还能使用类似函数调用的宏,得到不同的结果?
推测status这个双字整形的每一位都携带着某种信息,实际上相当于一个布尔值的返回值集合,这些宏定义通过按位运算相当于在这个返回值集合中取了一部分值做运算
3.
int options修改子进程的处理方式在
waitflags.h中有这么几个宏定义
2
3函数的默认行为是:挂起调用进程,直到有满足条件的子进程终止
指定options之后,函数的行为:
options 作用 WNOHANG如果指定的子进程或者等待集合中的子进程都没有终止则立即返回0 WUNTRACED挂起父进程,直到等待集合中的一个进程变成已终止或者被停止,返回该子进程pid WCONTINUED挂起父进程,直到等待集合中一个正在运行的进程终止或者等待集合中一个被停职的进程收到SIGCONT信号重新开始 `WNOHANG WUNTRACED`

如果调用waitpid的进程没有任何子进程则waitpid返回-1,并设置errno=EINTR
wait
1 |
|
wait(&status)等价于waitpid(-1,&status,0)
父进程挂起,等待子进程之一终止则返回其pid
sleep
1 |
|
休眠secs秒,睡够了觉则sleep返回0否则返回还要睡多久
pause
1 |
|
让调用者进程休眠,直到该进程接收到信号
加载并运行程序execve
1 |
|
执行filename指向的文件,参数为argv,环境为envp
例如:
execve.c
1 |
|
1 | kali@Executor:/mnt/c/Users/86135/desktop/os$ gcc execve.c -O0 -o execve |
执行之后shell由bash换成了sh
关于参数
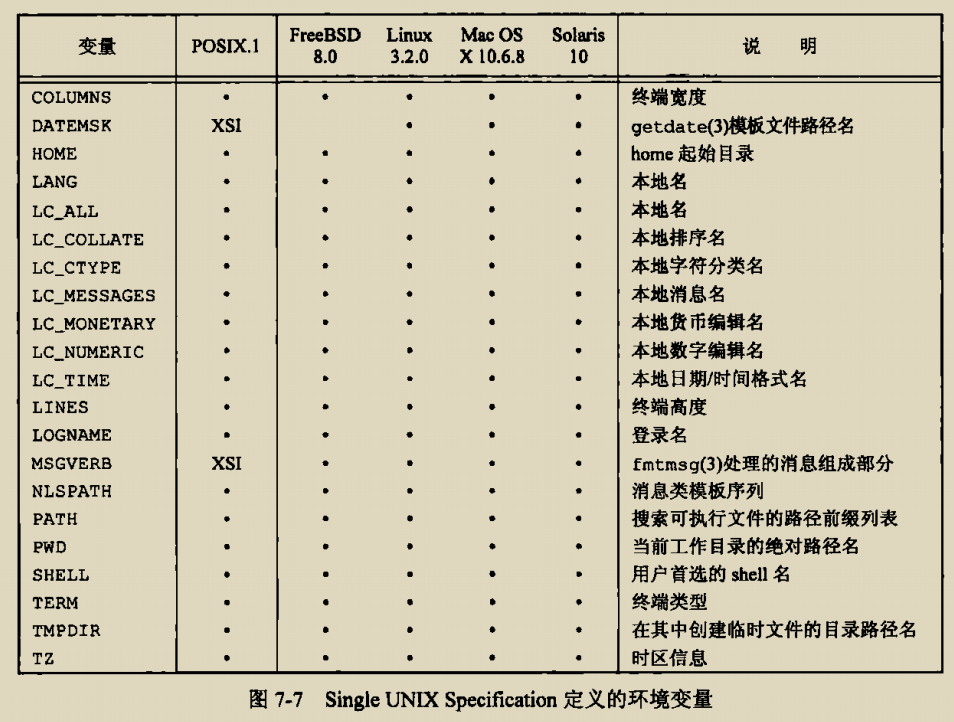
const char *envp[]
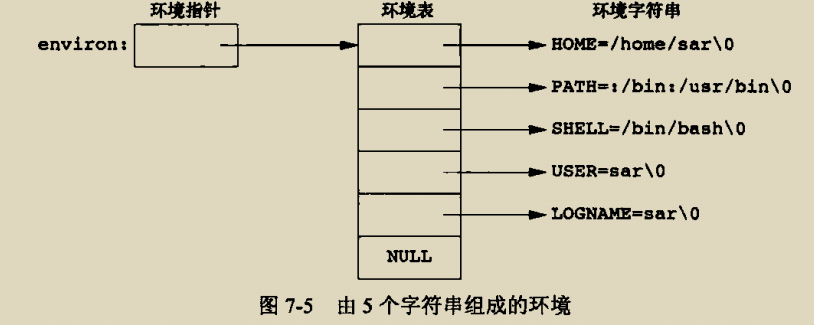
必须使用get或者set方法访问或者修改环境
2
3
4
5
char *getenv(const char *name);//返回name键对应的value值
int putenv(char *str);//这里str的格式为name=value,将[name,value]键值对放在环境表中,如果name键存在则覆盖之
int setenv(const char *name,const char *newvalue,int overwrite);//[name,newvalue]键值对放在环境表中,如果name键存在则根据overwrite是否为1决定是否覆盖
int unsetenv(const char *name);//清除环境表中的[name,value]键值对,如果name键不存在则什么都不会发生
myecho.c
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int main(int argc,char *argv[]){
printf("%s\n",getenv("HOME"));//home起始目录
printf("%s\n",getenv("SHELL"));//用户首选shell名
printf("%s\n",getenv("PWD"));//当前工作目录绝对路径
setenv("SHELL","/bin/sh",0);//将用户首选的shell改成/bin/sh,overwrite=0表示如果已经存在name=SHELL的键则啥也不干
printf("%s\n",getenv("SHELL"));
setenv("SHELL","/bin/sh",1);//将用户首选的shell改成/bin/sh,overwrite=1表示如果已经存在name=SHELL的键则覆盖原来的value
printf("%s\n",getenv("SHELL"));
return 0;
}
2
3
4
5
6
7
8
9
10
└─$ gcc myecho.c -Og -o myecho
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os]
└─$ ./myecho
/home/kali
/bin/bash
/mnt/c/Users/86135/desktop/os
/bin/bash
/bin/sh
setenv还可以新建环境变量,如果name键没有找到则新建环境变量环境变量表
在当前进程中修改环境变量对当前进程无效,但是对该进程后续建立的子进程有效
这里注意
putenv和setenv在overwrite=1时的区别一是参数的格式,
putenv中char *str让写的是name=value这种格式,而setenv中name和value分开成为两个参数二是参数的类型,
putenv中的参数没有const修饰,这就意味着str是可以被修改的而
setenv中的name和newvalue都带有const修饰,不可修改实际上
putenv不会为新的环境变量另外开空间,而是直接把传入的参数(不管是堆上还是栈上还是全局的)填入环境表
setenv则会另开空间拷贝一份环境变量放进环境表比如下面例子
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
int main(int argc,char *argv[]){
char str[]="myid=deutschball";
putenv(str);
printf("%s\n",getenv("myid"));
strcpy(str,"myid=dustball"); //此处修改str将会导致环境表中键myid的值变化
printf("%s\n",getenv("myid"));
char name[]="myunit";
char value[]="empire";
setenv(name,value,0);
printf("%s\n",getenv(name));
strcpy(value,"rebel");
printf("%s\n",getenv(name));
return 0;
}
2
3
4
5
6
7
8
9
└─$ gcc myecho.c -Og -o myecho
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os]
└─$ ./myecho
deutschball
dustball #此处值发生了变化
empire
empire #此处值不发生改变
此处应有一个编个shell的实验,但是工程量太大,现在不想写,留作后话吧