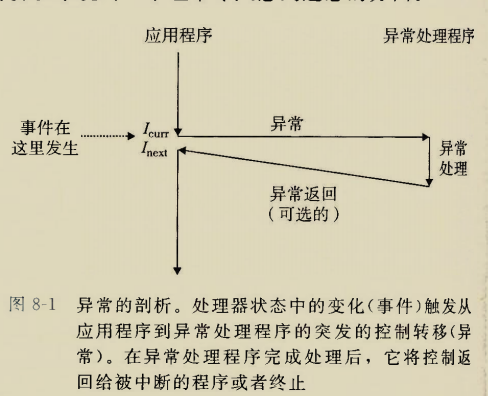
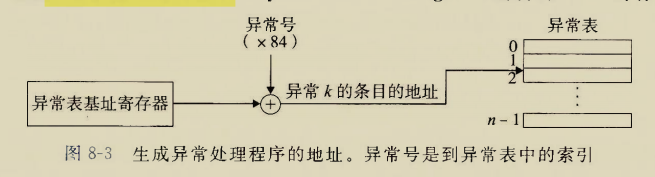
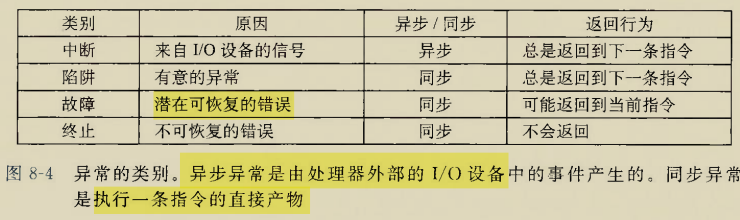
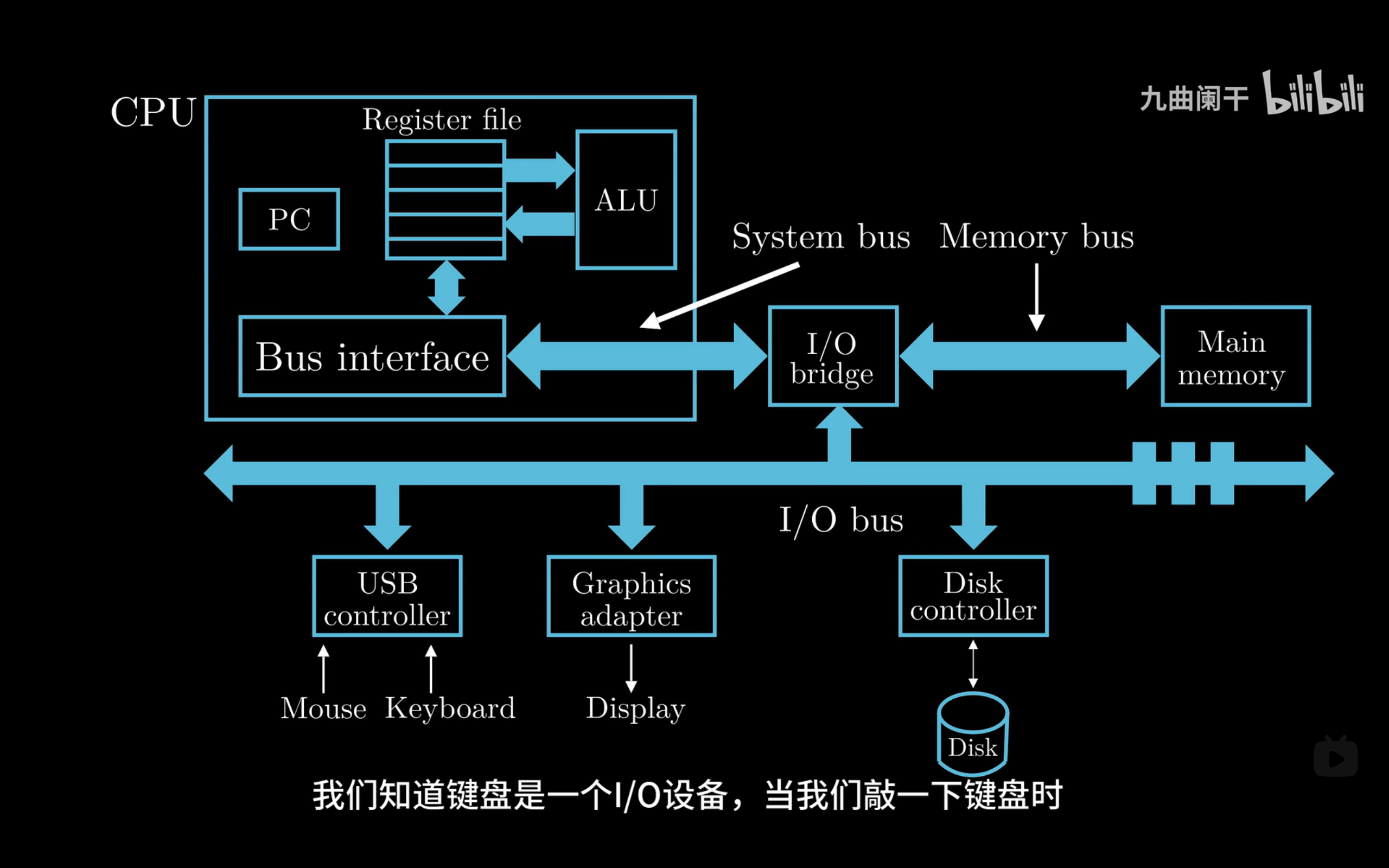
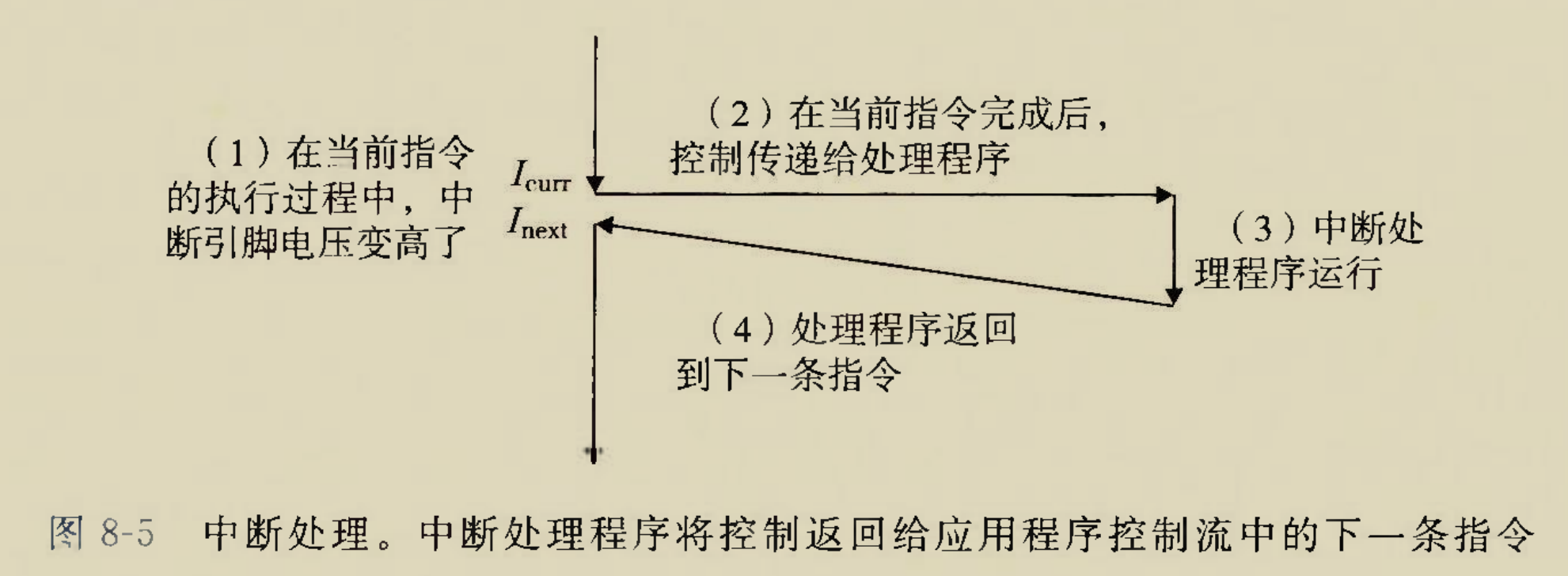
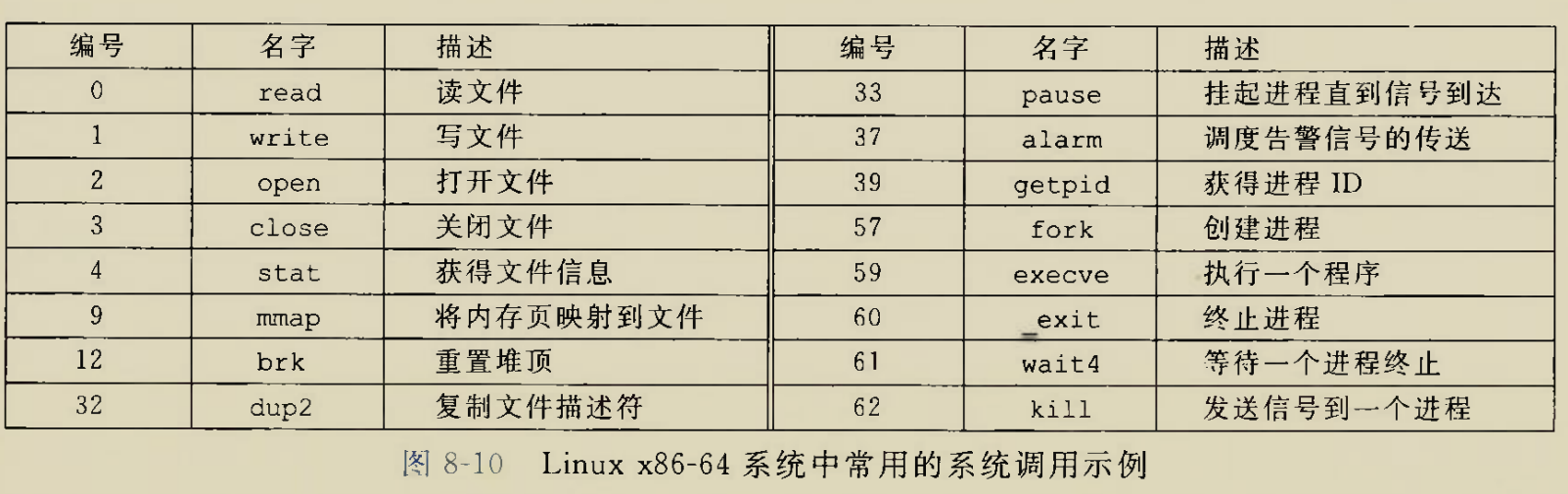
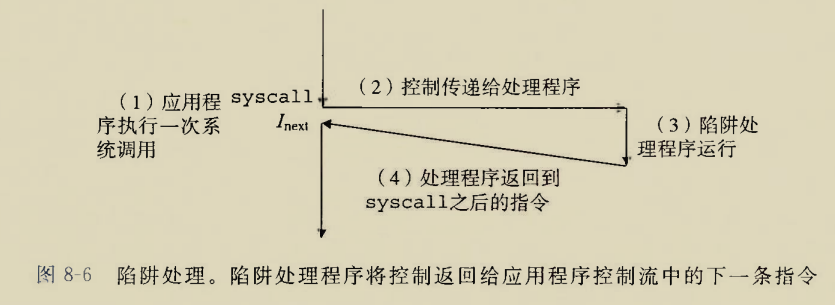
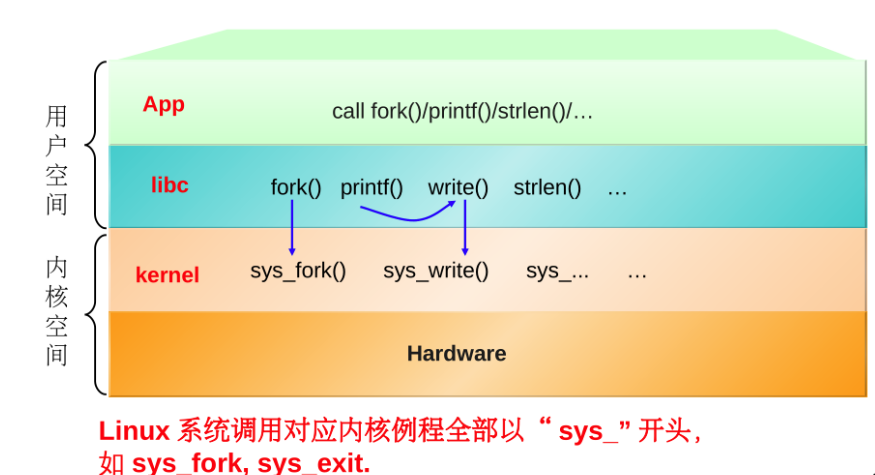
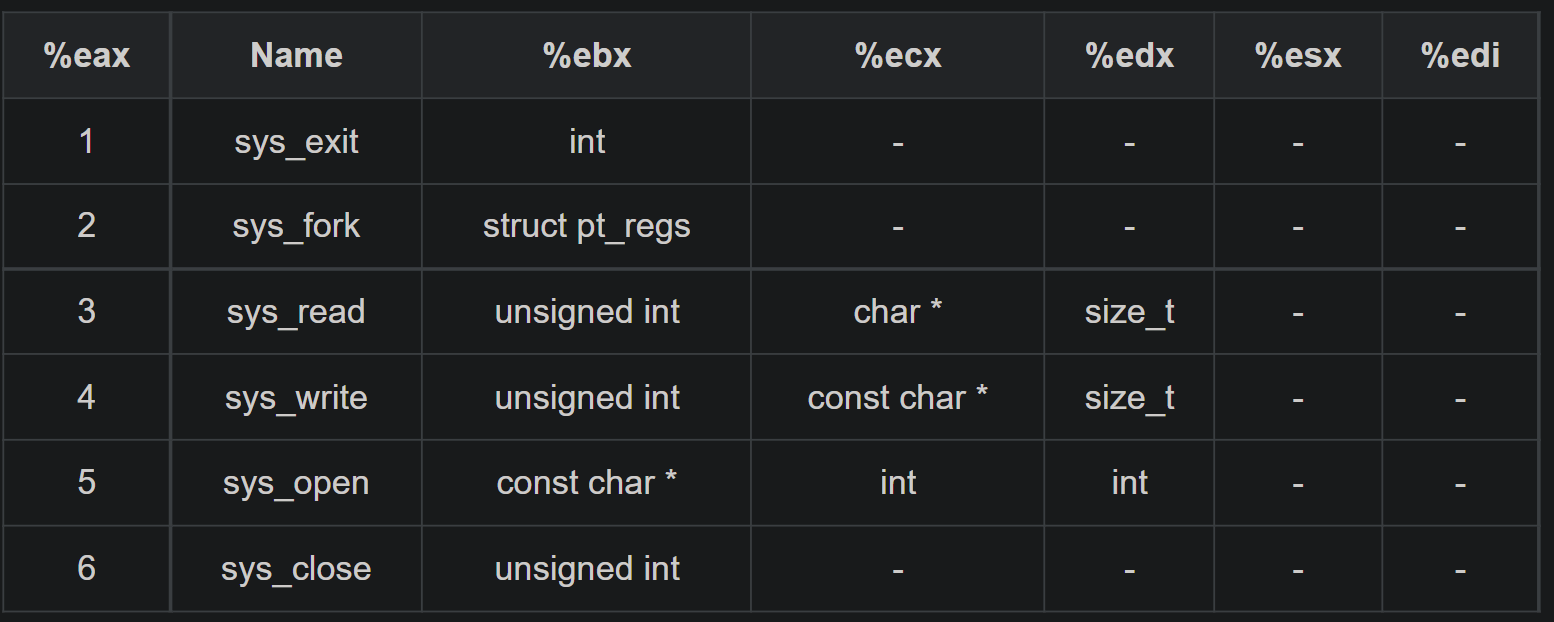
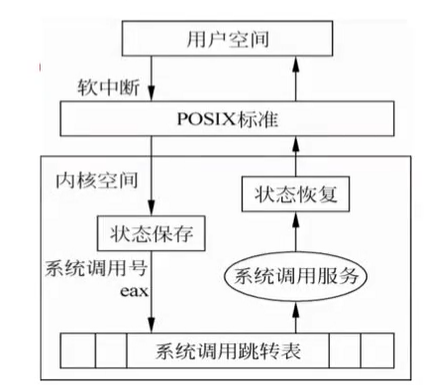
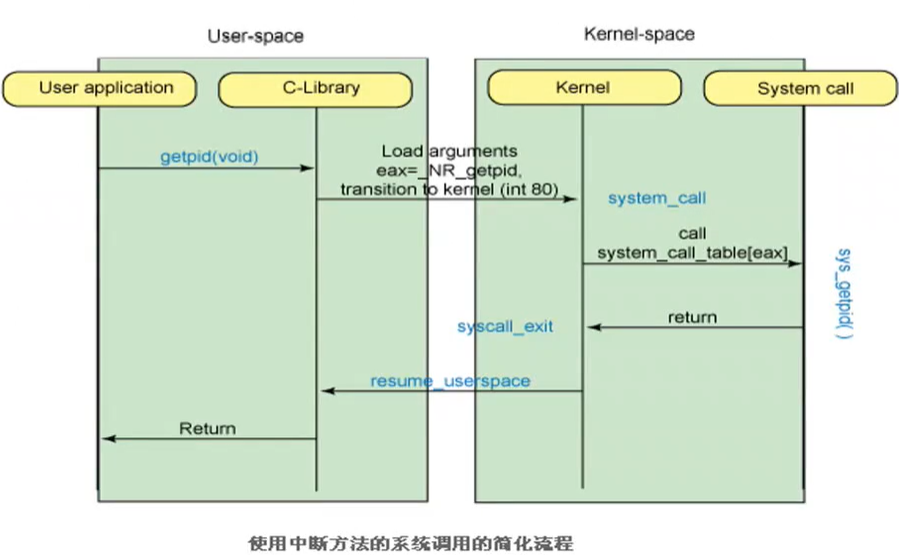
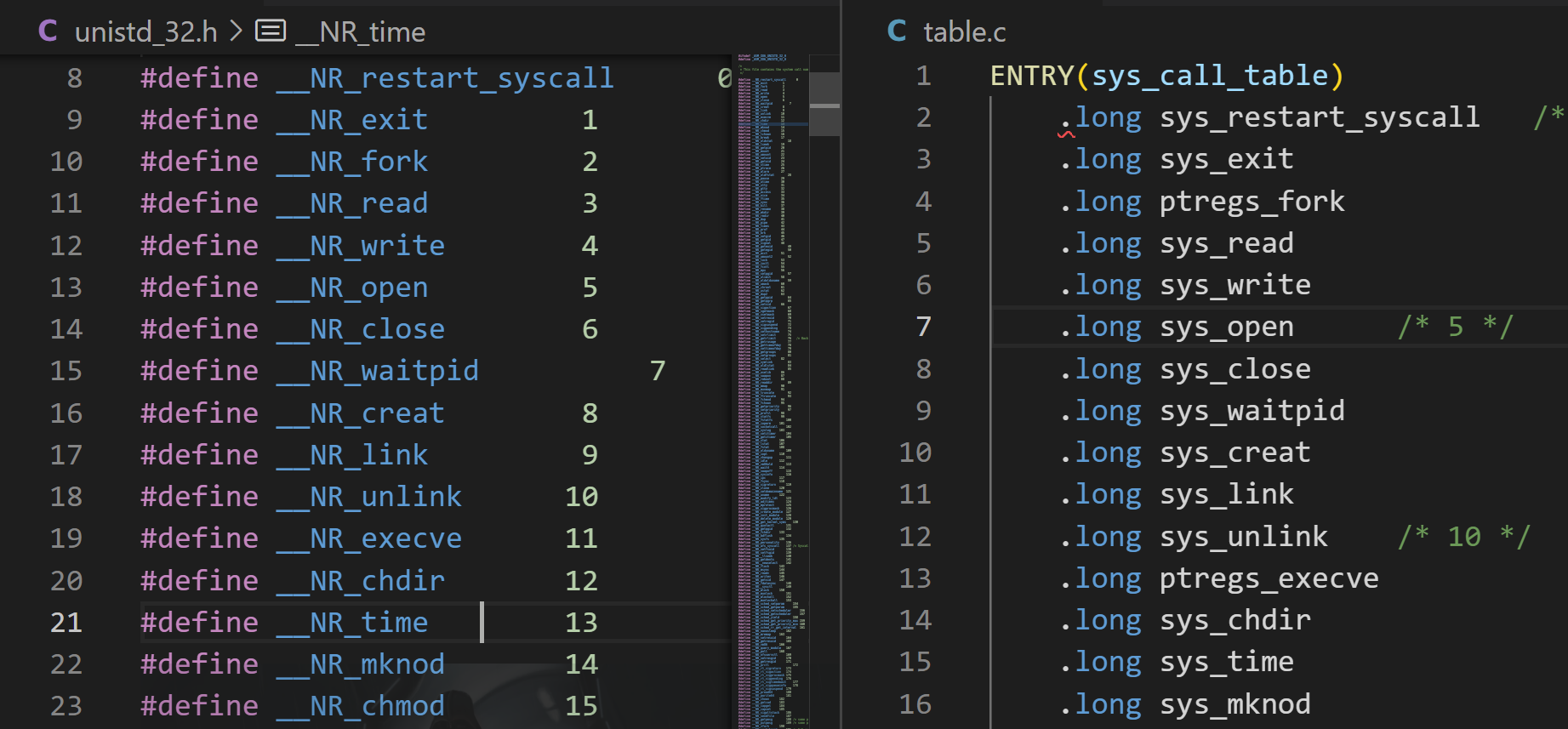
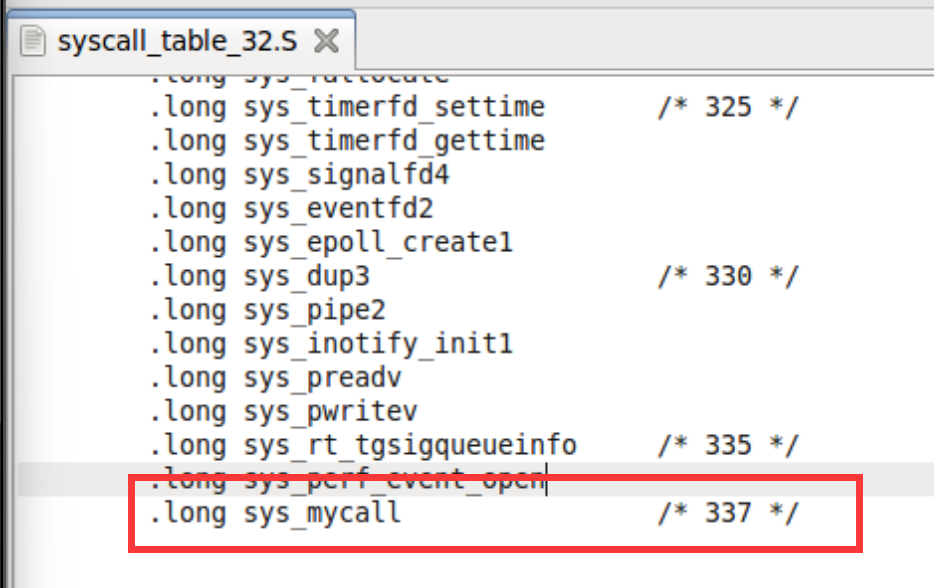
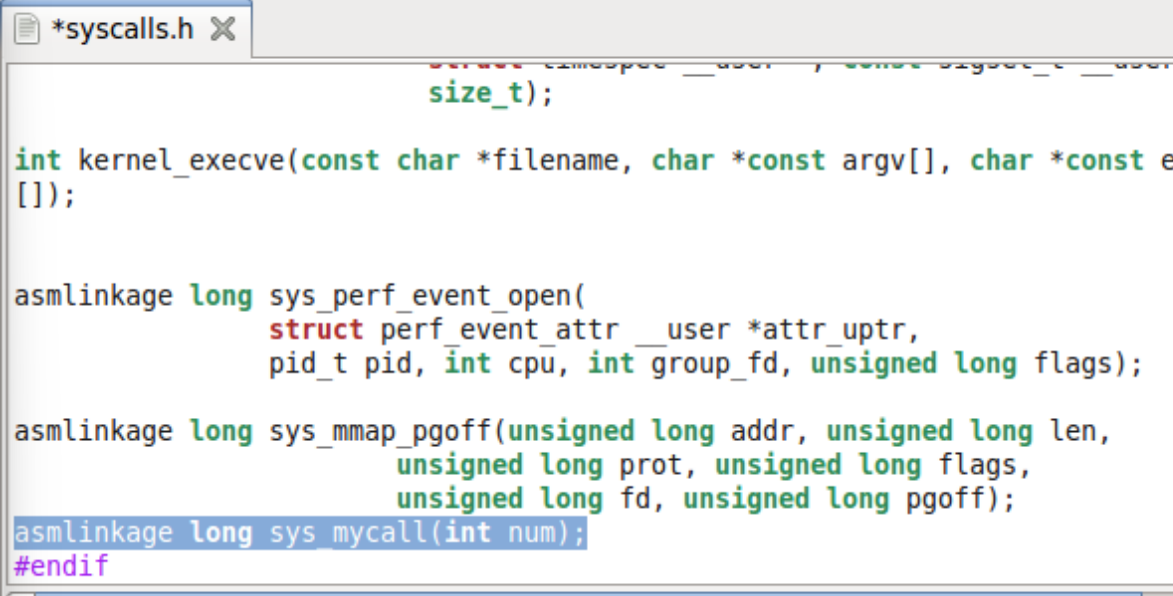
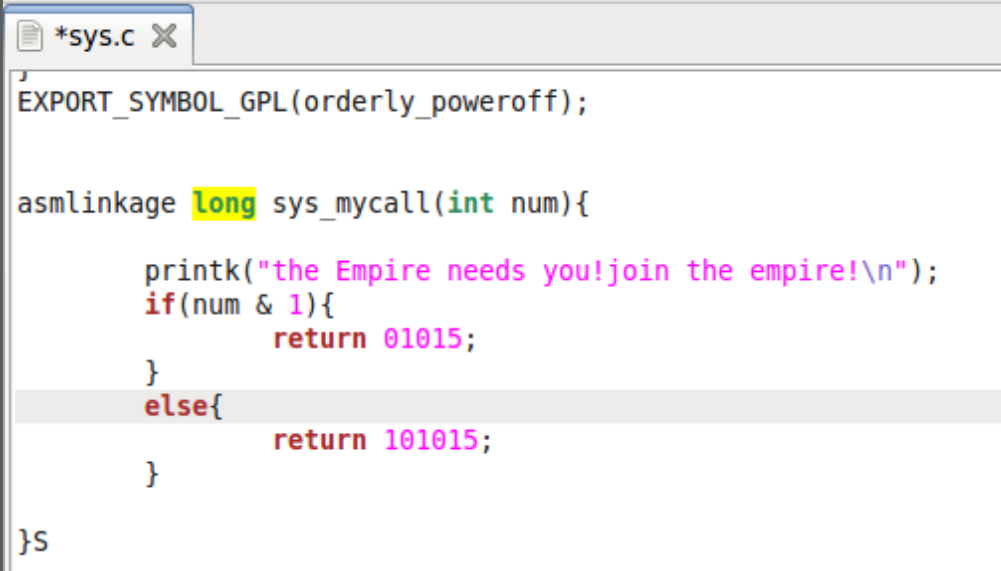
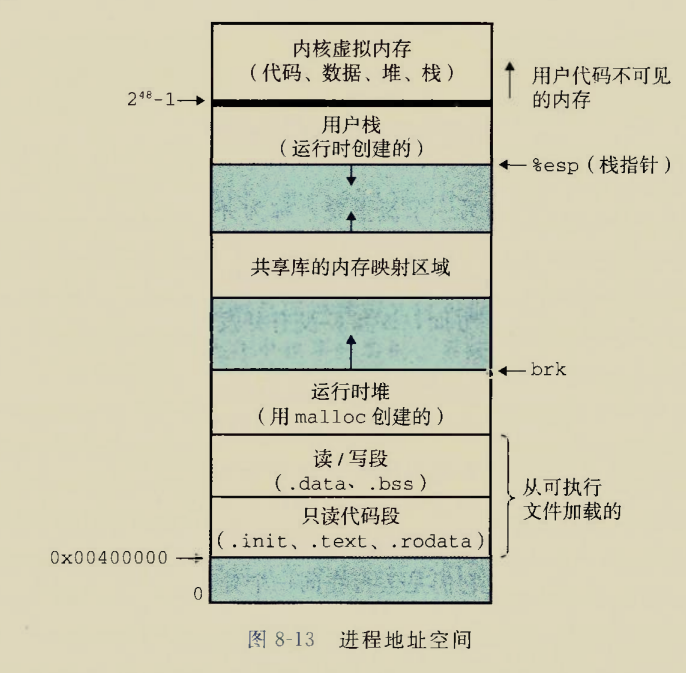
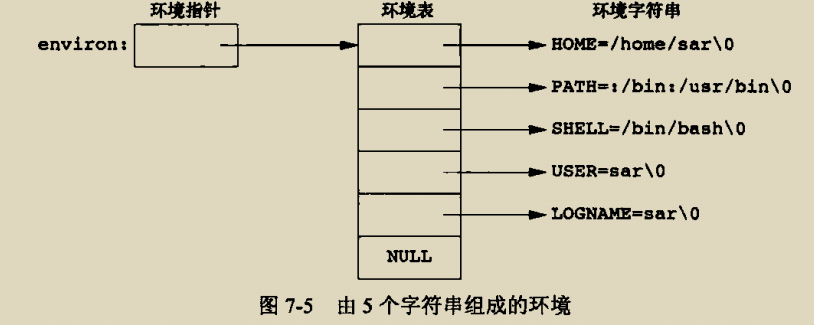
glibc是linux下面c标准库的实现,即GNU C
Library。glibc本身是GNU旗下的C标准库,后来逐渐成为了Linux的标准c库,而Linux下原来的标准c库Linux
libc逐渐不再被维护。Linux下面的标准c库不仅有这一个,如uclibc、klibc,以及上面被提到的Linux
libc,但是glibc无疑是用得最多的。glibc在/lib目录下的.so文件为libc.so.6。
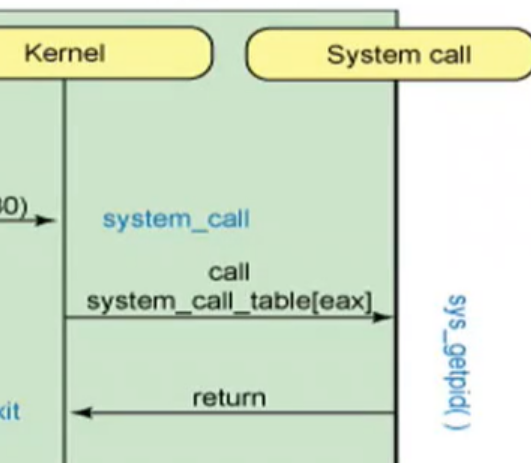
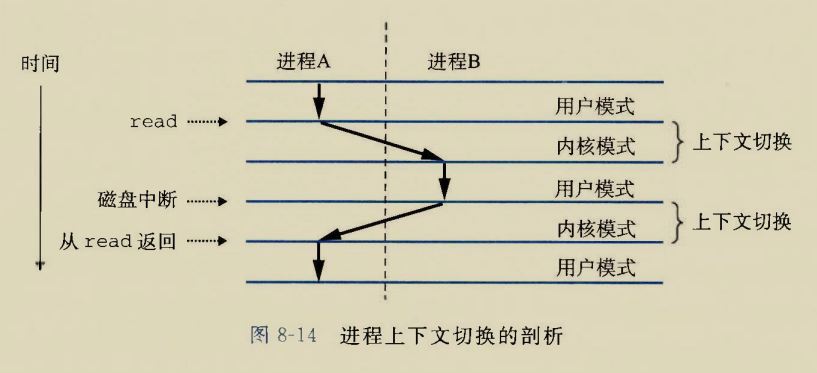
类似位置的修饰符我们见过__cdecl,__fastcall,这里asmlinkage也是一种调用约定的修饰符,试想如果不声明该修饰符,则linux上按照System
V AMD64
ABI约定的函数传参方法,前六个参数是通过edi,esi,edx,ecx,r8d,r9d这六个寄存器传递的,返回值是通过eax寄存器传递的.
/* * Ugh. To avoid negative return values, "getpriority()" will * not return the normal nice-value, but a negated value that * has been offset by 20 (ie it returns 40..1 instead of -20..19) * to stay compatible. */ SYSCALL_DEFINE2(getpriority, int, which, int, who) { ... }
#include<unistd.h> #include<stdio.h> #include<stdlib.h> intmain(){ printf("in father process 0\n"); //fork之前只会被父进程执行一次 int pid=fork(); //此处子进程和父进程并行 if(pid==0){ //对于子进程来说,它确实有一个正整数进程号,但是fork返回的不是 printf("in son process 1\n"); } if(pid!=0){ printf("in father process 1\n"); } }
运行结果:
1 2 3 4 5
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] └─$ ./proc in father process 0 in father process 1 in son process 1
#include<unistd.h> #include<stdio.h> #include<stdlib.h> int global=10; intmain(){ int local=20; int pid=fork(); if(pid==0){ printf("in son process: "); } else{ printf("in father process: "); } printf("global=%d,local=%d\n",global++,local++);//这里有修改
}
1 2 3 4
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] └─$ ./proc in father process: global=10,local=20 in son process: global=10,local=20 #两个打印相同说明global有两个,local有两个
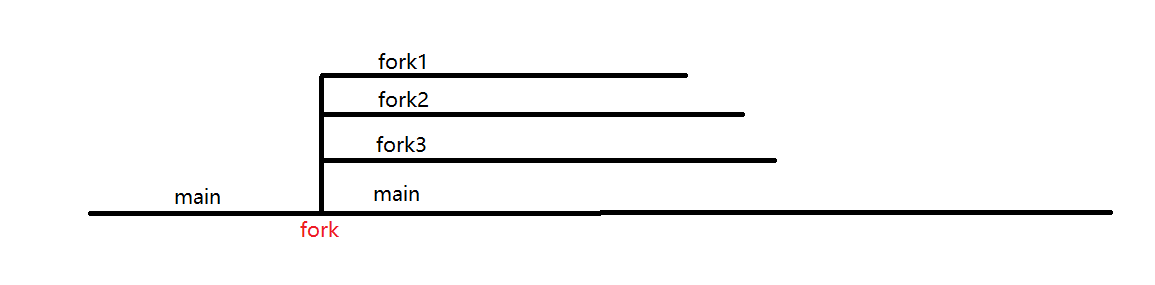
#include<unistd.h> #include<stdio.h> #include<stdlib.h> intmain(){ int pids[5]; int fpid=getpid();//fpid在fork之前先计算好,此后即使所有子进程都拷贝,也只是拷贝的父进程号 if(fpid==getpid()){//getpid在每个进程都不同,只有父进程中才会有fpid=getpid for(int i=0;i<5;++i){ pids[i]=fork();//实际上后来的子进程的pids也会存有数据,原因是父进程在创建第i个子进程时,pids已经写入前i-1个子进程号了 } } if(fpid==getpid()){//getpid在每个进程都不同,只有父进程中才会有fpid=getpid printf("in father process,pid=%d\n",fpid); for(int i=0;i<5;++i){ printf("pid%d=%d,",i,pids[i]); } printf("\n"); } return0;
}
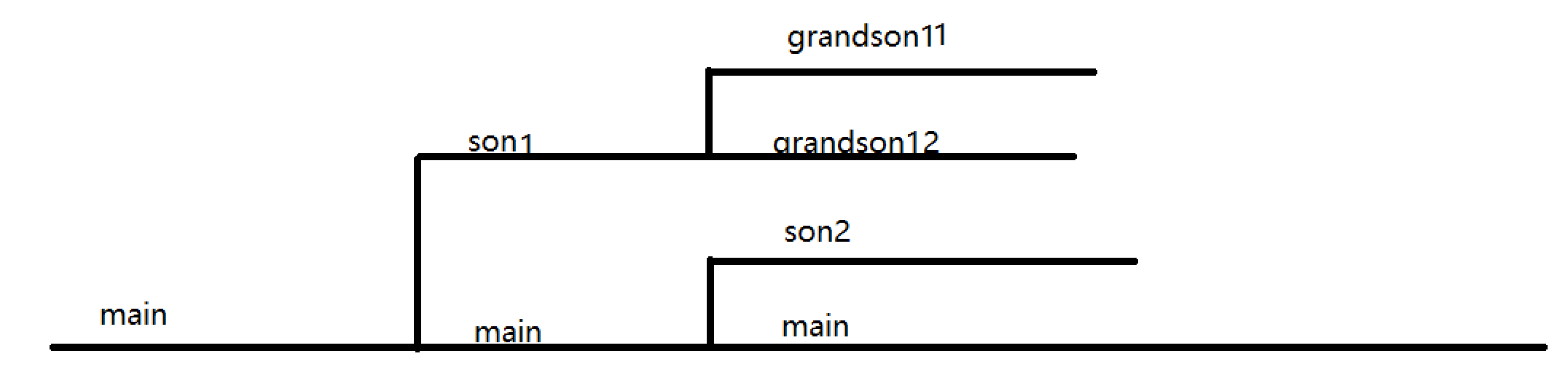
这样实际上的进程图
image-20220519093748088
运行结果:
1 2 3 4
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] └─$ ./proc in father process,pid=222 pid0=223,pid1=224,pid2=226,pid3=230,pid4=235,
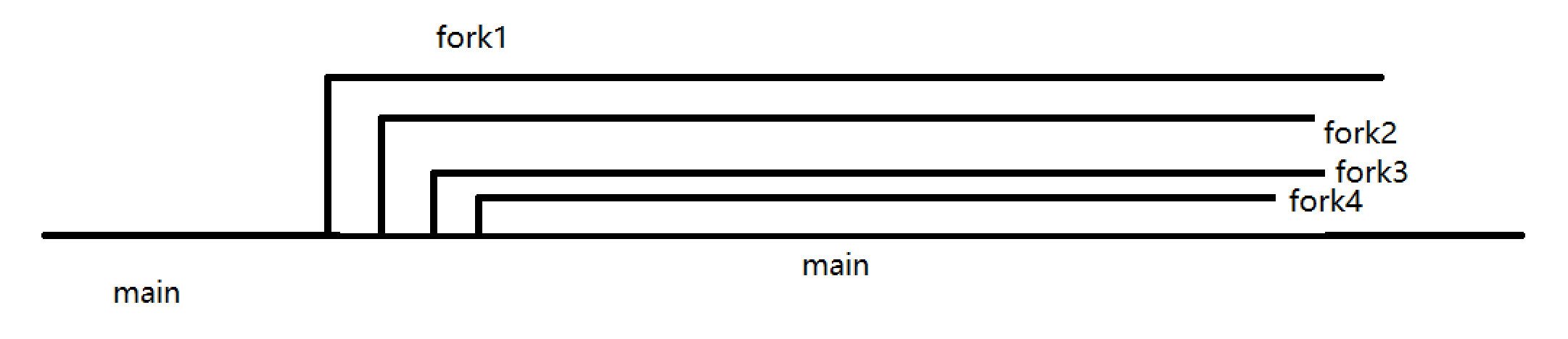
2.main和第一个子进程同时分支
image-20220519093425314
这个很容易实现
1 2
fork(); fork();
fork前后
proc.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
#include<unistd.h> #include<stdio.h> #include<stdlib.h> int global=10; intmain(){ int local=20; int pid0=getpid(); //fork之前getpid int forkid=fork(); //forkid只是用来 int pid1=getpid(); //fork之后getpid if(forkid==0){ printf("in son process,pid0=%d,pid1=%d,forkid=%d\n",pid0,pid1,forkid); } else{ printf("in father process,pid0=%d,pid1=%d,forkid=%d\n",pid0,pid1,forkid); } return0;
}
运行结果:
1 2 3 4
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] └─$ ./proc in father process,pid0=116,pid1=116,forkid=117 in son process,pid0=116,pid1=117,forkid=0
#include<unistd.h> #include<stdio.h> #include<stdlib.h> intmain(){ int forkid=fork(); int pid=getpid(); if(forkid==0){ printf("in son process,pid=%d\n",pid); exit(0); //让子进程结束运行 } else{ printf("in father process,pid=%d\n",pid); }
printf("process %d is still running\n",pid); //此句打印表明还在运行的进程
return0; }
1 2 3 4 5
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] └─$ ./proc in father process,pid=134 process 134 is still running in son process,pid=135
#include<unistd.h> #include<stdio.h> #include<stdlib.h> intmain(){ int fpid=getpid(); int forkid=fork(); if(forkid==0){//子进程中 printf("in son process,id=%d\n",getpid()); int n=1000000; while(n--);//拖延时间 exit(0); } else{//父进程中 printf("in father process,id=%d\n",fpid); waitpid(forkid,0,0);//指定等待唯一的子进程返回 //只指定第一个参数,其他使用缺省值 printf("son process %d exit\n",forkid); } printf("process %d is still running\n",getpid()); return0; }
运行结果:
1 2 3 4 5 6
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] └─$ ./proc in father process,id=273 in son process,id=274 #父进程需要等待子进程完成 son process 274 exit process 273 is still running
#include<unistd.h> #include<stdio.h> #include<stdlib.h> intmain(){ int fpid=getpid(); int forkid=fork();//区分父子进程 if(forkid==0){//子进程中 printf("in son process,id=%d\n",getpid()); int n=1000000; while(n--);//拖延时间 exit(1);//子进程以status=0状态终止 } else{//父进程中 int status=999;//设置status初始值 printf("in father process,id=%d\n",fpid); waitpid(forkid,&status,0);//使用status承载子进程的exit状态值 //缺省第三个参数 printf("son process %d exit with status= %d\n",forkid,status); printf("WIFEXITED(status)=%d\n",WIFEXITED(status)); printf("WEXITSTATUS(status)=%d\n",WEXITSTATUS(status)); printf("WIFSIGNALED(status)=%d\n",WIFSIGNALED(status)); printf("WTERMSIG(status)=%d\n",WTERMSIG(status)); printf("WIFSTOPPED(status)=%d\n",WIFSTOPPED(status)); printf("WSTOPSIG(status)=%d\n",WSTOPSIG(status)); printf("WIFCONTINUED(status)=%d\n",WIFCONTINUED(status)); }
printf("process %d is still running\n",getpid());
return0;
}
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] └─$ ./proc in father process,id=41 in son process,id=42 son process 42 exit with status= 256 WIFEXITED(status)=1 WEXITSTATUS(status)=1 #这是exit(status)中的status WIFSIGNALED(status)=0 WTERMSIG(status)=0 WIFSTOPPED(status)=0 WSTOPSIG(status)=1 WIFCONTINUED(status)=0 process 41 is still running
/* Bits in the third argument to `waitpid'. *///waitpid的第三个参数 其中的一些位 #define WNOHANG 1 /* Don't block waiting. *///01 #define WUNTRACED 2 /* Report status of stopped children. *///10