CSAPP-chapter3 x86-64 Assembly
汇编变种后缀的应用场景
前置知识:
0.C语言数据格式
1 |
|
在64位ubuntu上的运行结果
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# g++ test.cpp -o test.out |
在64位windows上的运行结果稍有不同
2
3
4
5
6
sizeof(short)=2
sizeof(int)=4
sizeof(long)=4
sizeof(long long)=8
sizeof(void*)=8在32位windows上的运行结果
2
3
4
5
6
sizeof(short)=2
sizeof(int)=4
sizeof(long)=4
sizeof(long long)=8
sizeof(void*)=4
| 操作系统\大小(字节) | char | short | int | long | long long | void* |
|---|---|---|---|---|---|---|
| linux64位 | 1 | 2 | 4 | 8 | 8 | 8 |
| windows64位 | 1 | 2 | 4 | 4 | 8 | 8 |
| windows32位 | 1 | 2 | 4 | 4 | 8 | 4 |
1.寄存器规格
大多数的后缀都与寄存器规格有关,下图将会被多次用到

2.寻址方式
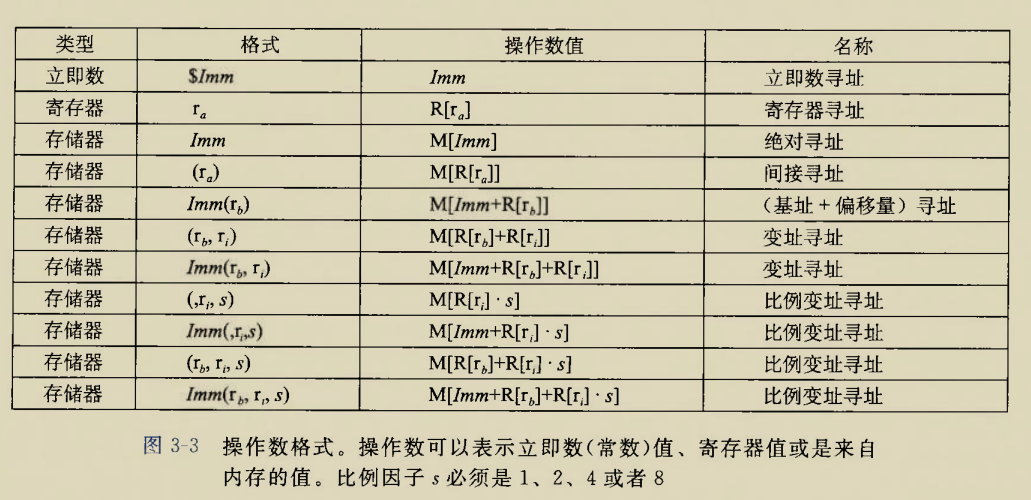
mov类
操作数长度相关后缀b,w,l,q
mov类命令的数据流动方向有五种,
1 | 立即数->寄存器 |
显然立即数->立即数是不可能的,这里立即数相当于右值,就好比说把5存到6上
并且规定不能从主存直接到主存即主存->主存,必须经过寄存器
与数据长度有关的后缀有
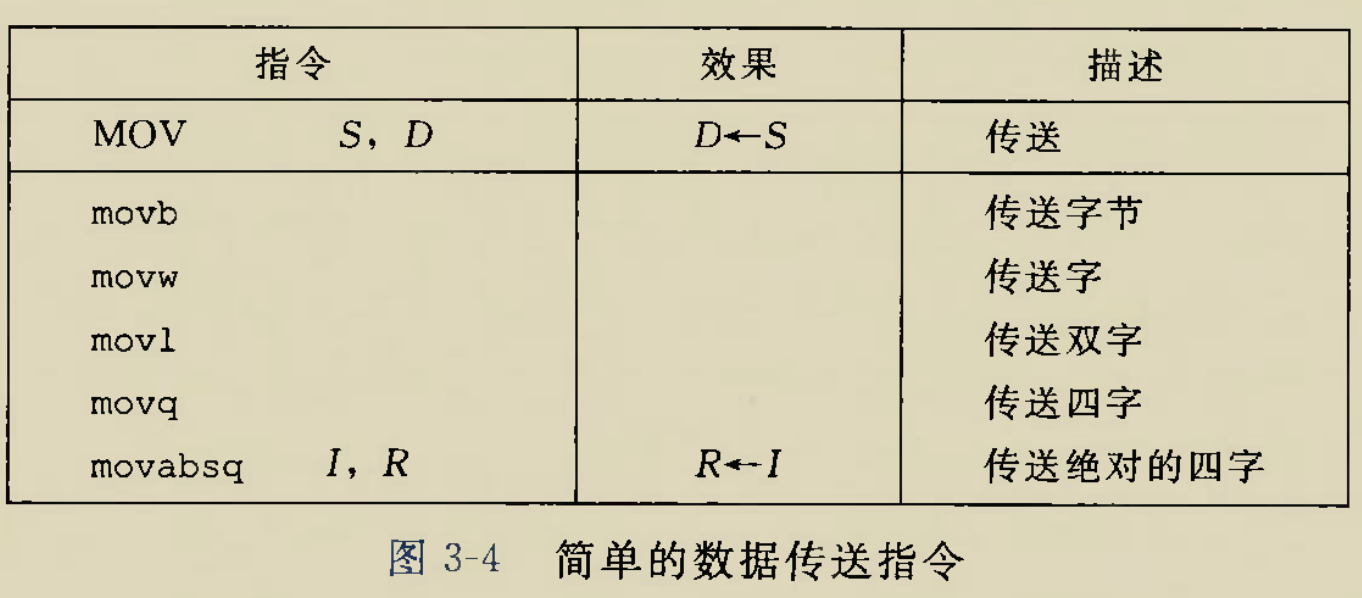
这里两个字节等于一个字
便于记忆,可以了解后缀的含义:
b:byte,一个字节
w:word,一个字(两个字节)
使用哪种后缀需要与数据流动方向一起决定,具体规则是:
1 | 1.主存没有决定后缀的权利 |
记住这三条规则才能完成3.2

1.movl %eax,(%rsp)

源%eax为32位(=4字节=2字)寄存器,
目的(%rsp)是采用简介寻址,实际地址位于内存中,没有发言权,
因此mov的后缀跟随%eav即传送双字,使用l后缀
2.movw (%rax),%dx

源(%rax)在内存中,没有发言权,
目的%dx是一个16位(=2字节=1字)寄存器
因此mov的后缀跟随%dx即传送单字,使用w后缀
3.movb $0xFF %bl

源$0xFF是一个立即字,优先级低
目的%bl是一个字节寄存器,优先级高
mov后缀跟随%bl使用b
4.movb (%rsp,%rdx,4) %dl

源(%rsp,%rdx,4)在内存上,没有发言权
目的%dl是一个字节寄存器
mov后缀跟随%dl使用b
5.movq (%rdx),%rax

源(%rdx)在内存上,没有发言权
目的%rax是一个四字寄存器
mov后缀跟随%rax使用q
6.movw %dx,(%rax)

源%dx是一个单字寄存器
目的(%rax)在内存上,没有发言权
因此mov后缀跟随%dx用w
长度类后缀的其他细节差异

1.movb,movw只会修改目标寄存器的对应低位
2.movl不光会修改目标寄存器的对应低位,并且会将高位全部置零
3.对于64位的立即数,1.只能用movabsq2.将其存到寄存器中,movq只能处理32位的立即数
数据拓展相关后缀z,s
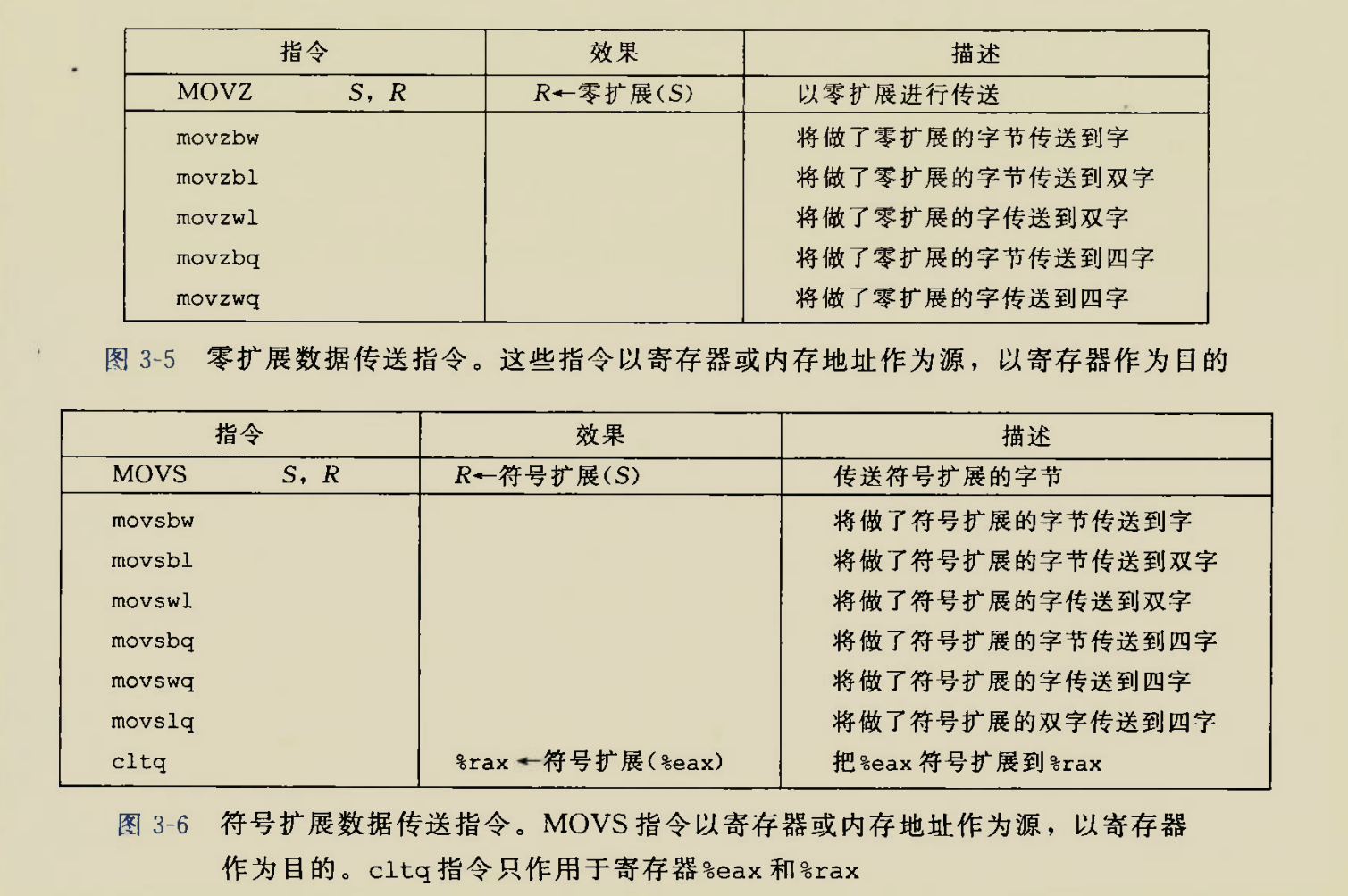
零拓展和符号拓展的区别:
R(%dl)=AA=10101010符号位为1第4行符号拓展直接将高位全都置1得到一串F
第5行零拓展直接将高位全都置0得到一串0
有符号数拓展时使用符号拓展
无符号数拓展时使用0拓展,可以理解为无符号拓展


1.首先,使用指针的目的是,使实际操作的地址在内存中,如此需要在寄存器中过度一次,将转型分成两个阶段,即源内存->寄存器和寄存器->目的内存两个阶段
2.然后一定注意”==当执行强制类型转换即涉及大小变化又涉及C语言中的符号变化时,操作应该先改变大小==”
这里”先改变大小”的意思是,无符号源用z,有符号源用s,然后决定大小的后缀看目的的大小
1.long到long
不涉及大小变化,不涉及符号变化,只需要使用传送四字指令movq,两个阶段相同
2.char到int
只涉及大小变化,首先从字节内存到双字寄存器需要符号拓展指令movsbl
然后从双字寄存器到内存根据寄存器规格决定使用双字传送指令movl
3.char到unsigned
既涉及大小变化,又涉及符号变化
首先改变大小,从有符号字节内存到双字寄存器需要符号拓展指令movsbl
然后从双字寄存器到双字内存根据寄存器规格决定使用双字传送指令movl,即目的符号不起作用
char到unsigned int和char到int形成的汇编语言是相同的
这一点可以实验验证
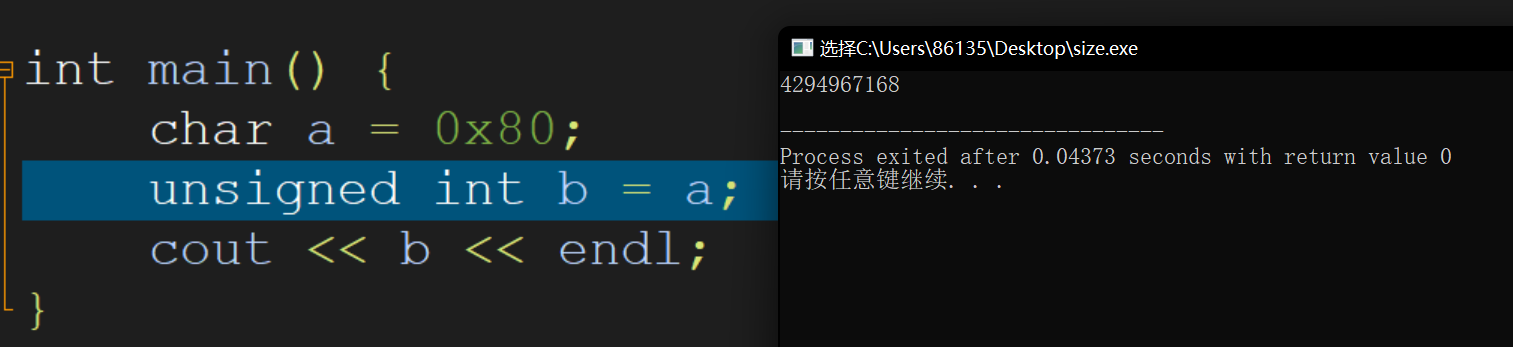
对于char的最小值-128=0x80,如果强制转型到unsigned,可能的结果:
1.首先变化符号,然后变化大小,即首先使用
movzbl,然后movl,这样unsigned的值为0x00000080=1282.首先变化大小,然后变化符号,即首先使用
movsbl,然后movl,这样unsigned值为0xFFFFFF80=4294967168基于上述两种猜想,可以写如下程序验证
证明猜想2是正确的
4.unsigned char到long
既涉及大小变化,又涉及符号变化
首先改变大小,从无符号字节内存到四字寄存器,要使用无符号拓展指令movzbq
然后从四字寄存器到内存,使用四字传送指令movq
然而实际上首先使用的是movzbl
然后官方给出的解释:
(Clarification, not an erratum) Figure 3.5.
Although there is an instruction movzbq, the GCC compiler typically generates the instruction movzbl for this purpose, relying on the property that an instruction generating a 4-byte with a register as destination will fill the upper 4 bytes of the register with zeros.
尽管应该使用movzbq指令,但是GCC编译器通常使用movzbl指令来达到相同的目的,
==这是因为只要是以寄存器为目的并且生成低位4字节的指令都会将高位的4字节置零==
博客上其他人的解释
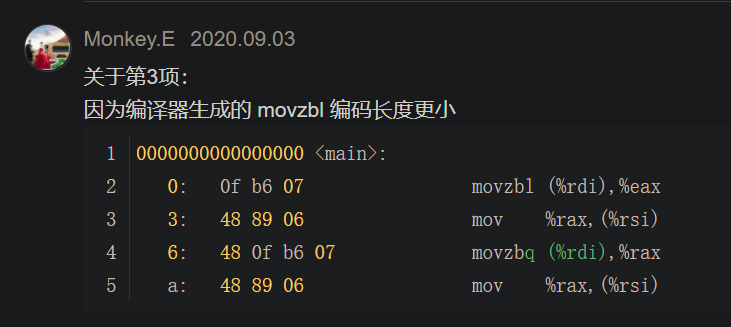
这就很明白了
5.int到char
只涉及大小转换,大变小直接截取
直接从内存中取出双字数据放到寄存器里然后截取低8位传送给内存
即首先使用movl然后movb
6.unsigned到unsigned char
只涉及大小转换,大变小直接截取
直接从内存中取出双字数据放到双字寄存器然后截取低8位传送给内存
即首先使用movl然后movb
7.char到short
只涉及大小变换,小变大需要拓展
首先使用有符号拓展movsbw将字节数据传送到单字寄存器
然后使用movw从单字寄存器传送到内存
汇编语言特殊算术操作
首先纠错

书上除法这里是有错误的,商和余数都放在了R[%rdx]这显然是不合理的,我觉得应该写为:

乘法
c源文件
1 |
|
汇编语言
1 | movq %rsi, %rax |
逻辑分析:
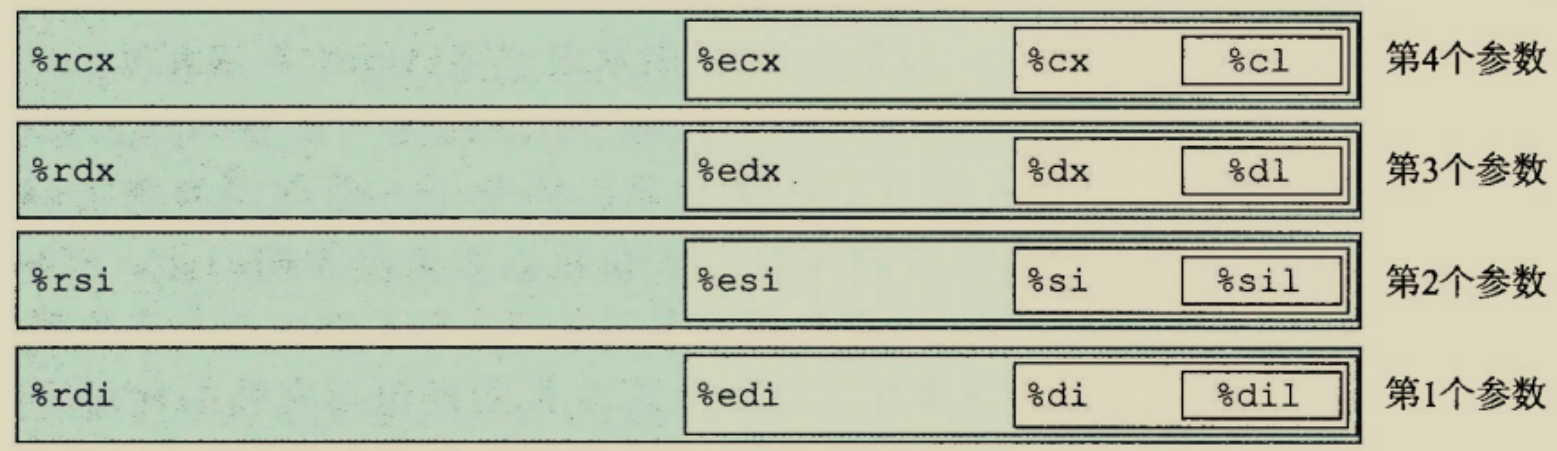
首先三个参数分别存放在

即
1 | R[%rdi]=dest//这里%rdi寄存器中存放的是dest这个位置 dest这个位置 dest这个位置 |
1.movq %rsi, %rax
即令R[%rax]=R[%rsi]=x将x放在了%rax寄存器中
2. mulq %rdx
R[%rdx]=y

看似只有一个操作数,实际上隐含着另一个操作数在%rax寄存器中
即令R[%rdx]*R[%rax],两个64位数的计算机结果是一个128位数,显然单独一个64位寄存器是放不下的,因此计算结果被分成两部分
低64位放在%rax寄存器,高64位放在%rdx寄存器
3. movq %rax, (%rdi)
R[%rdi]=dest这是指针指向内存中的位置
M[R[%rdi]]=M[dest]对内存中的位置dest应用解引用函数$M[dest]$得到的是该地址上的实际数值
令M[R[%rdi]]=R[%rax],将%rax寄存器中刚刚算出的低64位结果放在内存中,位置为R[%rdi](间接寻址)
4. movq %rdx, 8(%rdi)
刚才在第3步时存放了低64位,那么此时应该做到就是存放高64位
令M[R(%rdi)+8]=R[%rdx],将%rdx寄存器中刚刚算出的高64位结果放在内存中,位置为R(%rdi)+8(基址+偏移量寻址)
此处的+8为偏移8个字节,因为低地址恰好占用这8个字节
在小端机器上低地址存放低位,高地址存放高位
到此乘法的计算结果已经被分成两个64位数存进了一个uint128_t *指针指向的地址
除法
c源文件
1 | void remdiv(long x,long y,long *qp,long *rp){//希望计算x/y将商存到指针qp指向的地址,将余数存到指针rp指向的地址 |
汇编语言
1 | movq %rdi, %rax |
1 | R[%rdi]=x |
1. movq %rdi, %rax
令R[%rax]=R[%rdi]=x将x存放在%rax寄存器里
2. movq %rdx, %r8
令R[%r8]=R[%rdx]=qp将商==在内存中的地址==存放在%r8寄存器里

对于一个128位数的除法运算,被除数的低64位存放在%rax寄存器中,高64位存放在%rdx寄存器中
刚才在第1步时已经将64位数x放在%rax寄存器中了,但是高64位所在的%rdx现在被第三个参数qp占用,因此将qp放在另一个寄存器%r8中,然后将%rdx腾出来方便存放高64位
3. cqto

为什么要进行符号拓展?
被除数应该是一个128位数,但是目前我们只是确定了其低64位为x,高64位还是第三个参数的值没有修改,如果此时直接计算则高64位的值可以认为是乱码,那么怎么消除高64位的乱码呢?置零或者置符号,我们将要进行符号除法,因此高64位置符号
即高64位按照R[%rax]=x的符号位拓展
4. idivq %rsi
R[%rsi]=y
R[%rdx]=x mod y
R[%rax]=x/y
5. movq %rax, (%r8)
R[%r8]=qp
M[R[%r8]]=M[qp]=*qp=R[%rax]=x/y
6.movq %rdx, (%rcx)
R[%rcx]=rp
M[R[%rcx]]=M[rp]=*rp=R[%rdx]=x mod y
习题3.12

首先四个参数的存放位置为:
执行除法的时候只会提供一个操作数S作为除数,表示被除数的另两个操作数是隐含的%rax,%rdx
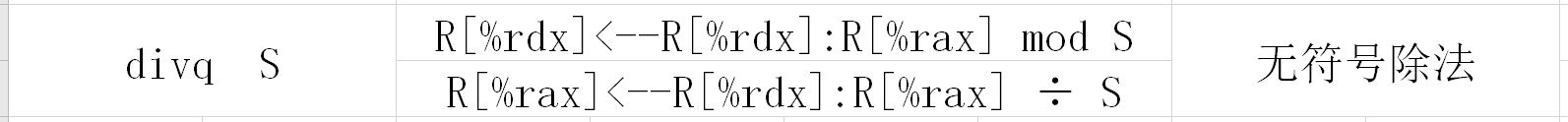
那么在执行除法命令之前,应该把被除数先安置好
1.首先128位被除数的低64位存放在%rax中,即R[%rax]=x
2.然后高64位存放在%rdx中,无符号除法时应当全置0,
但是由于第三个参数qp已经占据了%rdx,因此在将其全都置零之前应当请三个参数挪个地方,比如%r8
movq %rdx,%r8
3.此时就可以将被除数的高64位%rdx寄存器置0了,最直接的置零方法是movq $0,%rdx,还可以利用异或的性质xorq %rdx,%rdx
至于应该选择哪一个?应该选择二进制长度最短的指令
2
3
4
0: 48 c7 c2 00 00 00 00 mov $0x0,%rdx
7: 48 99 cqto
9: 48 31 d2 xor %rdx,%rdx由此可见为什么刚才有符号除法时要用cqto,因为其长度最短
然后xor也是不错的选择
最迫不得已才会选择movq指令
当发现实际编译器使用的命令与我们理想的不一样时,可以写一个.s文件然后将自己理想的汇编指令和实际的汇编指令各写一行
然后使用
gcc -Og -c命令,使其编译成为.o文件,注意必须指定-c选项,否则直接编译成.exe或者.out会发生链接错误,因为刚才我门写的.s文件是非常不完整的,连main函数都没有然后对.o文件使用objdump命令反编译 ,就可以观察指令及其二进制编码长度了
一般理想与现实不同都是由于有更加短但是可以完成同样目的的指令我们没有考虑到
在本题中我不知道类似cqto但是是无符号拓展的指令,可以先用异或指令达到相同的目的
4.被除数在3中已经准备好了,可以进行除法了
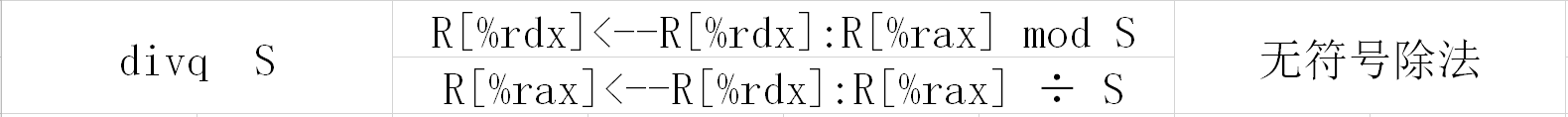
这里S是除数,本题中除数是第二个参数y存放在%rsi寄存器中,即R[%rsi]=y
那么除法指令为divq %rsi
5.除法进行完毕,瓜分商和余数
商位于%rax寄存器中,希望传送到内存中的qp位置,而内存中的qp位置存放在寄存器%r8中(即R[%r8]=qp,M[R[%r8]]=*qp)因此使用指令movq %rax,(%r8)
余数位于%rdx寄存器中,希望传送到内存中的rp位置,而内存中的rp位置存放在寄存器%rcx中(即R[%rcx]=rp,M[R[%rcx]]=*rp)因此使用指令movq %rdx,(%rcx)
标志与条件控制
标志位
标志位的作用都是为了表征刚刚进行过的算术运算的结果,比如是否有溢出,是否有进位,结果是否为0等等,
设置这些标志的目的之一是方便判断错误
之二是决定后面的程序走向,是实现条件,==循环等控制语句的基础==

其中常用的标志位有:

作用:
CF
进位标志
作用于无符号数,比如对于八位无符号数
加法结果进位溢出:0xFF+0x01=0x100溢出了,此时CF=1表明刚才的算术运算有溢出
减法借位溢出:0x00-0x01=0x100-0x01=0xFF,被减数需要向他不存在的高位借位,此时CF=1表示被减数不够减的
对于有符号整数的加减法,忽略进位标志CF
比如有符号整数0x00-0x01=0x00+0xFF=0xFF表示的是0-1=-1,
0xFF为-1的补码表示.显然这是合乎情理的
同样的两个数如果是无符号数则计算结果为0xFF=255这两个正数相减越减越多显然不合理,因此CF=1标志有进位溢出
OF
溢出标志
对有符号整数(即补码)运算有效,比如
两个八位二进制数正数01000000(B)=0x40(H)=64相加,
0x40+0x40=0x80(H)=10000000(B)=怎么就成了一个负数-128?
这显然不符合情理,此时OF=1标志有符号数溢出
又或者:
两个八位二进制负数10000000=0x80=-128相加
0x80+0x80=0x100=0x00=0怎么就成了0?
这也是不符合情理的,此时OF=1
怎样检验有符号数加减是否有溢出?
计组上我们学过双标志位法,计算结果的两个符号位如果不同则说明有溢出
OF标志对于无符号整数运算无效
ZF
零标志
如果运算结果为0则ZF=1
SF
符号标志
如果运算结果为负数则SF=1
可以修改标志位的指令
除了leaq外的逻辑运算指令
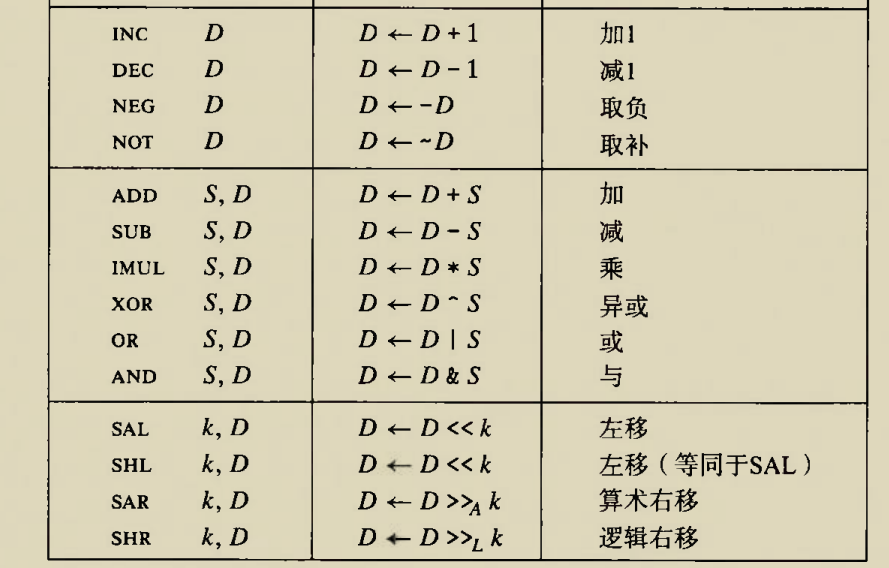
比较和测试指令
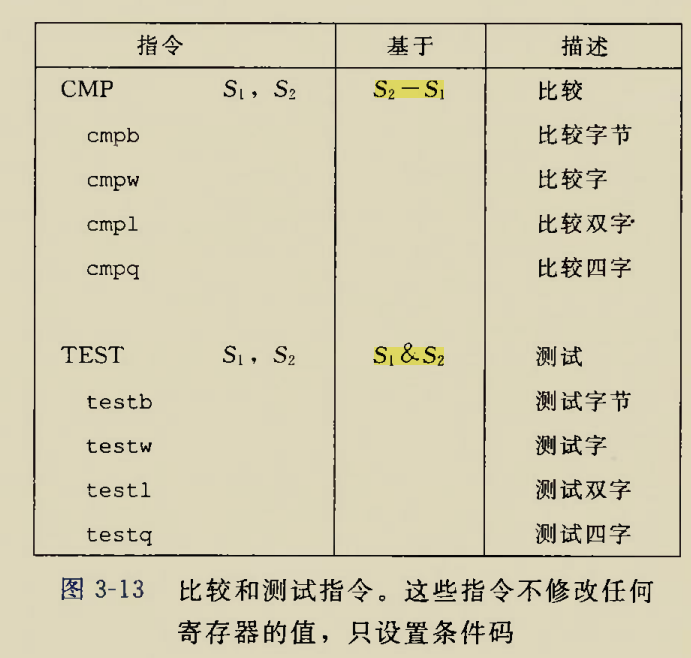
一条指令可能会修改多个标志位,具体规则为:
MOV NOT JMP*
does not affect flags
MOV,NOT,JMP指令不会修改标志位
NEG
The CF flag set to 0 if the source operand is 0; otherwise it is set to 1. The OF, SF, ZF, AF, and PF
flags are set according to the result.
NEG取反指令:如果NEG的操作数是0则CF=1,否则CF=0.
OF,SF,ZF,AF,PF标志根据结果设定
AND OR
The OF and CF flags are cleared; the SF, ZF, and PF flags are set according to the result. The state
of the AF flag is undefined
AND,OR指令的OF和CF前面已经给出;SF,ZF,PF根据结果而定,AF状态无所谓
DEC INC
The CF flag is not affected. The OF, SF, ZF, AF, and PF flags are set according to the result
DEC,INC自增自减指令的CF位不受影响,其他标志位都视结果而定
ADD ADC SUB SBB
The OF, SF, ZF, AF, PF, and CF flags are set according to the result.
ADD,ADC,SUB,SBB指令的所有标志位都视结果而定
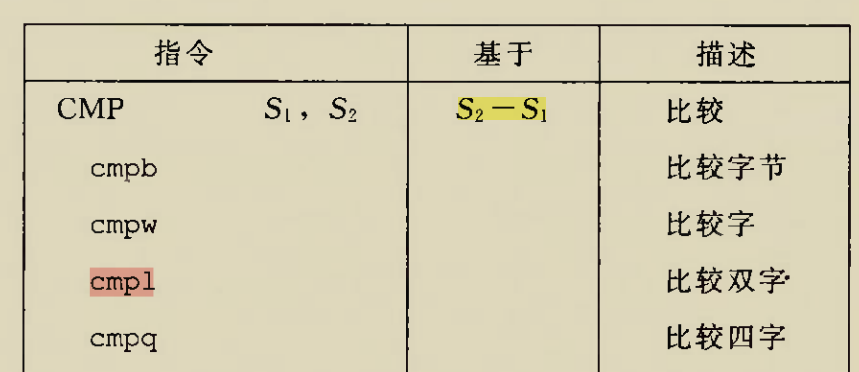
CMP
Modify status flags in the same manner as the SUB instruction
CMP与SUB指令对于标志位的效果相同
以两个有符号八位2进制数运算为例子
0x00-0x01=0x00+0xFF=0xFF,OF=0无溢出
0x40+0x40=0x80=10000000=-128,OF=1有溢出减法也有可能溢出,一个负数减去一个正数时
0x80-0x7F=0x80+0x81=0x101=0x01成了一个正数,此时OF=1
比较指令
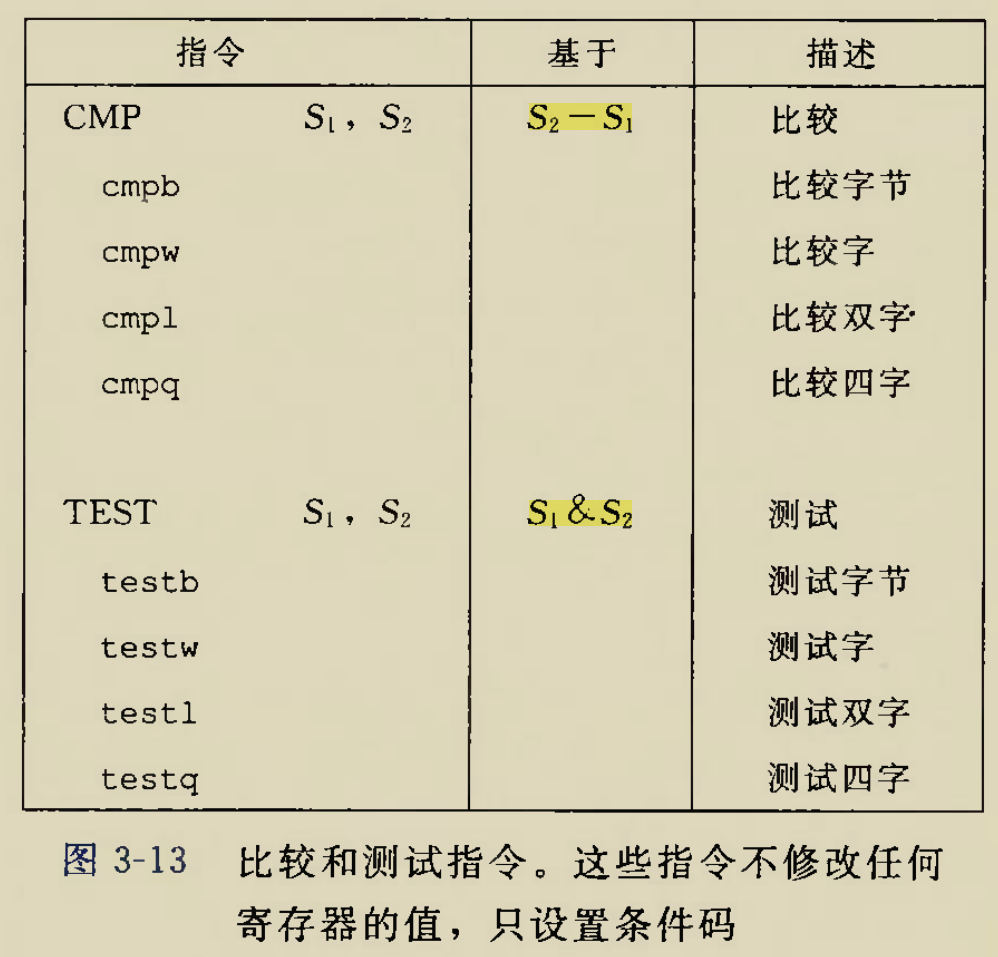
执行比较指令后通过==标志位组合==判断比较结果
cmp s1,s2指令基于S2-S1,意思是首先对S2-S1求值,然后结果放在s2原来的地方
如果为负数则SF=1,否则(非负数)SF=0,
后面的程序只需要访问一下Flag Register中的SF值就”可以????”知道S2,S1谁大谁小了
==注意这里”可以”是假的==,
因为如果结果是一个比较大的负数,造成溢出,截断之后成了一个正数,此时
SF=0,此时只凭借SF值会造成误判,就比如
0x80-0x7F=0x80+0x81=0x101=0x01结果成了一个正数,那么符号标志位SF=0只凭SF值就会认为0x80>=0x7F而
0x80=-128<0x7F=127因此只凭借SF标志位是无法判断两个操作数的大小的,==还应当考虑是否有溢出==.
==考虑什么时候会发生溢出?==
两个正数相减显然结果绝对值小于两者中的任何一个,不会溢出
两个负数相减同样
两个正数相加显然可以,比如
0x7F+0x01=0x80成了负数两个负数相加也可以,比如
0x80+0x80=0x100=0x00成了0正数-负数也可以,比如
0x7F-0xFF=0x7F+0x01=0x80成了负数负数-正数也可以,比如
0x80-0x7F=0x80+0x81=0x101=0x01成了正数==现在考虑如何完善判断两个数的大小==
两个数做差有四种情况
1.正-正
2.负-负
3.正-负
4.负-正
前两种情况没有溢出,
OF=0,直接看SF后两种可能有溢出,如果没有溢出则看
SF,如果有溢出则SF取反而区分前两种和后两种的方法也很容易观察得出,即两个操作数的符号是否一致
令
F=[A-B],A为被减数,B为减数,[X]表示对X取符号,X≥0则[X]=0,否则[X]=1列出真值表
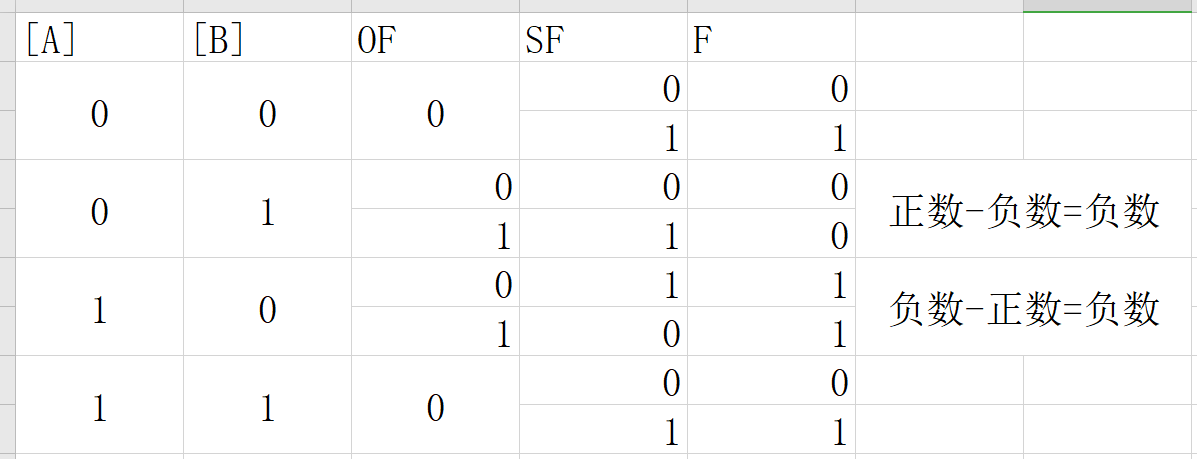
我们想要得到F的值,并且我们已经知道
OF和SF的值,而大小判断与A,B无关,只与Flag Register中的标志位组合有关,那么问题转化为
从真值表上我们可以观察得出,当OF=0时,F和SF是一致的,当OF=1时,F和SF是相反的
那么怎么用一条表达式写出F与OF,SF的关系呢?
根据F=1的项可以立刻得到
$F=\overline {OF}SF+OF\overline {SF}=OF\oplus SF$
到此可以总结如何判断两个有符号数的大小了
如果$OF\oplus SF$异或值为1则前小后大,否则前大后小
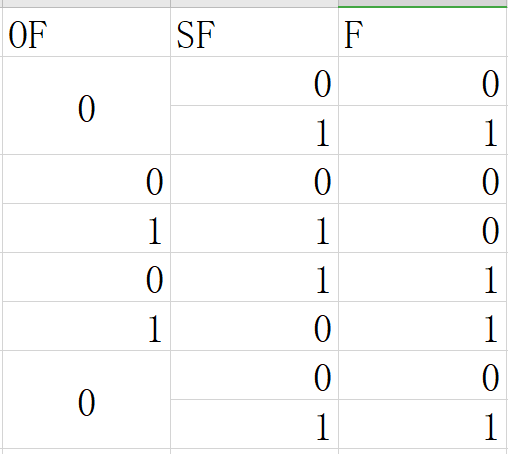
test S1,S2指令基于S1&S2,意思是首先对S1&S2求值,按位与只有两个操作数一模一样才会是真,否则为假.如果为假即0,则ZF=1,否则ZF=0,后面的程序只需要访问一下Flag Register中的ZF值就可以知道S2,S1是否相同了
访问条件码的方式
在刚刚进行完一次逻辑运算之后,此时Flag Register的各个标志位已经设置完毕,下面就要根据其中一个或者几个标志位的组合进行决策,选择执行或者不执行一些命令
1)可以根据条件码的某种组合, 将一个字节设置为0或者1
2)可以条件跳转到程序的某个其他的部分
3)可以有条件地传送数据
1.根据FlagRegister的情况将一个字节设置为0或者1
SET指令
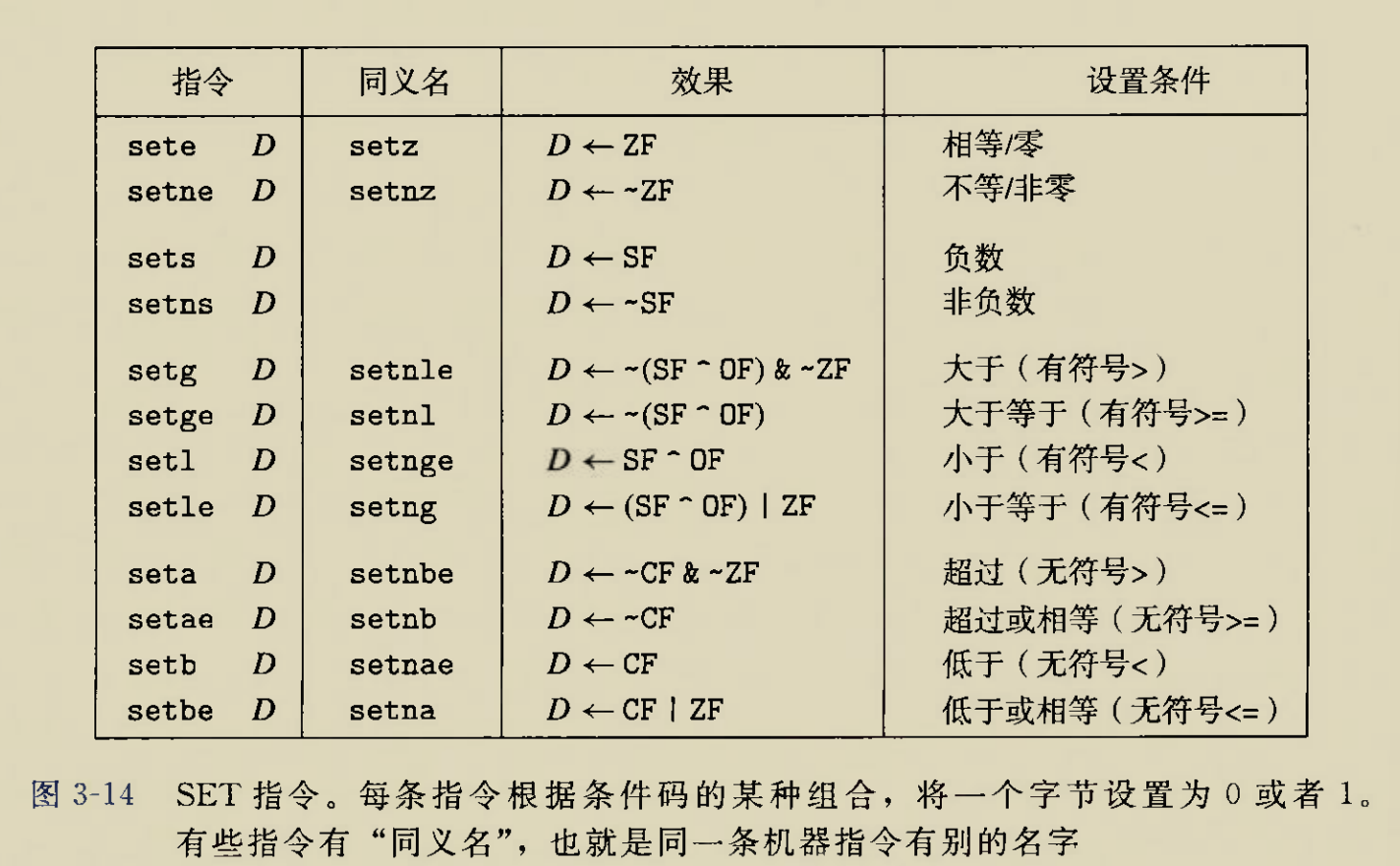
这种指令怎么发挥作用呢?
以sete为例子,
假设刚刚进行的运算是a-a=0,此时ZF=1表示刚才的计算结果为0,
此时使用sete 目标寄存器,满足设置条件(相等/零),于是向目标寄存器存放ZF值即1
练习3.13

A项第一行使用了cmpl比较双字命令,说明两个操作数都是双字(int,unsigned),第二行使用setl有符号小于运算,因此操作数只能是int类型
B项第一行使用cmpw比较字命令,说明两个操作数都是字(short,unsigned short),第二行使用setge有符号大于等于,因此操作数只能是short
C项第一行使用了cmpb比较字节命令,说明两个操作数都是字节(char,unsigned char),第二行使用setbe无符号小于等于,因此操作数只能是unsigned char
D项第一行使用了cmpq比较四字命令,说明两个操作数都是四字(long,unsigned long),第二行 使用setne不等/非零,因此操作数无法确定有无符号,long或者unsigned long均可
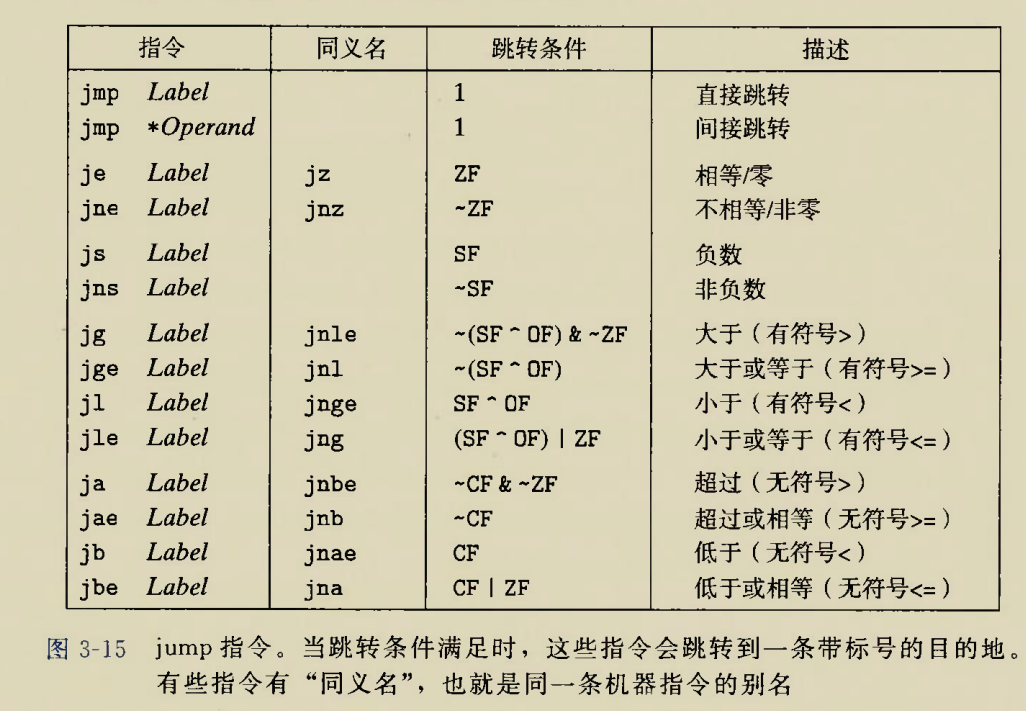
2.条件跳转
条件跳转表
该表在后来会经常用到
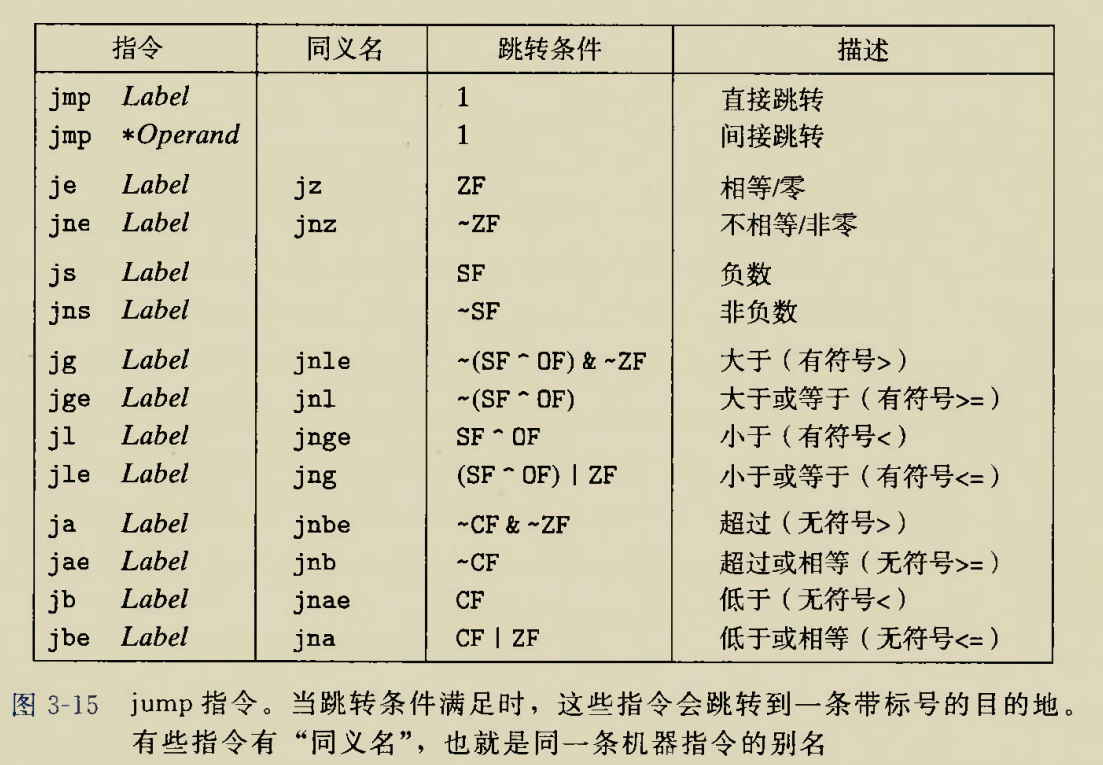
条件跳转指令实现if-else语句
c源代码:
1 | long absdiff_se(long x,long y){ |
给定参数x,y如果x<y,则返回y-x,否则返回x-y,即返回两个数的差的绝对值
汇编代码
1 | absdiff_se: |
分析其汇编语言都干了什么
首先两个参数的位置

即
1 | R[%rdi]=x |
1.movq %rsi, %rax
1 | R[%rax]=R[%rsi]=x |

将x搬到%rax寄存器中,猜测有可能以后的变化都在x身上进行最后返回%rax寄存器中的值
2.cmpq %rsi, %rdi
注意是==后减前==
做差R[%rdi]-R[%rsi],(一定注意是后减前)SF和OF标志位根据结果确定
3. jge .L2

根据刚才我们推导的R[%rdi]-R[%rsi]<0时$OF\oplus SF=1$,那么R[%rdi]-R[%rsi]≥0就应该有$!(OF\oplus SF)=1$
这里jge=jump if greater即R[%rdi]-R[%rsi]≥0的情况
联系前两句,第三句可以理解为:如果$R[%rdi]-R[%rsi]=y-x≥0$则跳转到.L2
此后程序分叉了,如果3没有满足执行没有跳转则顺序执行subq %rdi, %rax即R[%rdi]=R[%rax]-R[%rdi]=x-y
如果3满足条件并且跳转则跳到.L2执行subq %rsi, %rdi即R[%rsi]=R[%rdi]-R[%rsi]=y-x一定是非负的
不管是否跳转,3保证了后面的减法一定是大数-小数
汇编语言的程序结构类似于
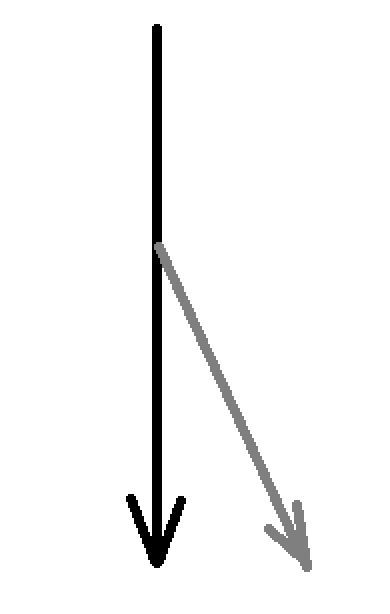
而c源程序的结构类似于
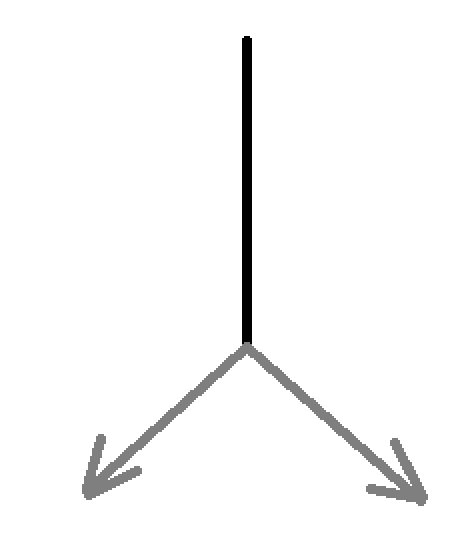
条件跳转指令实现循环
求一个数n的阶乘,c源文件用while和for分别这样写
1 | int fact_while(int n){ |
根据前面学过的标志位的用法,大体可以推测一下汇编语言可能怎么写
参数
int n放在edi寄存器
一开始
int ans=1;要从一个寄存器里放一个1,由于最后返回的也是ans,因此可以直接用eax(int32位,需要双字寄存器eax,不用四字寄存器rax)寄存器方便返回然后循环临时变量i也需要一个寄存器存储其值,用
edx循环判断就是i和n的大小判断
cmp %edx,%edi,这个式子基于R[%edi]-R[%edx]=n-i当i<=n时,cmp指令执行完毕之后
SF=0恒成立,表示cmp运算结果非负然后进入循环体
ans*=i;,其中R[%eax]=ans,R[%edx]=i,翻译成汇编语言,
imul %eax,%edx计算R[%eax]*R[%edx]然后将结果存放到%eax循环体执行完毕,下面应该循环变量i自增
inc %edx下面要回头执行下一次循环,此处应当使用无条件跳转命令,跳到循环判断语句
考虑当循环判断语句不满足时,应当跳转到何处?
使用条件跳转到循环下面的语句
总的来说,推测的汇编逻辑是这样的:
1.安置好形参n,ans,临时变量i在寄存器中的位置
2.循环判断
3.根据刚才的循环判断,决定是否条件跳转出循环
如果没有出循环则执行循环体(乘法),然后自增临时变量i,然后无条件跳转到2
如果跳出了循环则继续执行后面的语句,循环不再考虑

下面实验观察汇编器是如何做的
编译成.o文件之后用objdump反汇编得到
1 | Disassembly of section .text: |
这样两种循环的写法在机器层面是一模一样的.现在研究其汇编语言的逻辑,以fact_while的汇编语言为例分析其汇编语言的逻辑
1 | 0000000000000000 <fact_while>: |
1.mov $0x1,%eax
R[%eax]=0x1
这里我们可能会这样分析:eax寄存器是返回值的一部分,因此可以推断,这一句对应c源代码中的int ans=1;
但是实际上这里对应的是int i=1
==这一点可以从下文中分析得出==
2.mov $0x1,%edx
R[%edx]=0x1,对应的是int ans=1
3.cmp %edi,%eax
这里就可以看出1和2中,或者说%edx,%eax中到底谁放了ans,谁放了i
比较指令,基于R[%eax]-R[%edi],如果与c源程序while(i<=n)对应的话
R[%edi]=n是可以肯定的,因为第一个参数放在edi中
那么R[%eax]=i随之确定了
(感觉可以把i和ans的寄存器换一换,这样返回的时候可以直接返回rax,其中正好存放ans,但是当前不知道为啥,编译器没有这样做,而是在最后将edx拷贝到eax)
4.jg 1a <fact_while+0x1a>
jg:jump if greater,

如果!(i<=n)即i>n,则cmp %edi,%edx=R[%edx]-R[%edi]=i-n>0,ZF=0,并且显然这里没有溢出和进位,即满足~(SF^OF)&~SF,jg跳转条件成立,发生条抓
这里和while(i<=n)成立的条件是相同的,都是在进入循环之前首先进行条件判断
注意跳转位置:1a <fact_while+0x1a>
1 | 18: eb f4 jmp e <fact_while+0xe> |
1a位置恰好为无条件跳转的下一句,表明出了循环
5.imul %eax,%edx
==注意后者为目的==
R[%edx]=R[%eax]*R[%edx]
对应循环体ans*=i
6.add $0x1,%eax
R[%eax]=R[%eax]+0x1
对应临时变量i自增
7.jmp e <fact_while+0xe>
无条件跳转,跳转位置是fact_while开始向后偏移0xe字节

实际跳转到判断指令cmp,意思是重新进行循环
8.mov %edx,%eax
如果程序执行到此句,它上一句又是无条件跳转,说明程序是从更早的条件跳转过来的,对应jg 1a <fact_while+0x1a>
这一句的逻辑是把edx寄存器中的东西拷贝给eax一份
edx我们分析过存放的是ans
eax我们分析过存放的是i
然而函数希望返回ans,并且返回值是以eax寄存器为准
因此这里需要把ans搬到eax中
9.retq
函数返回
3.条件传送数据
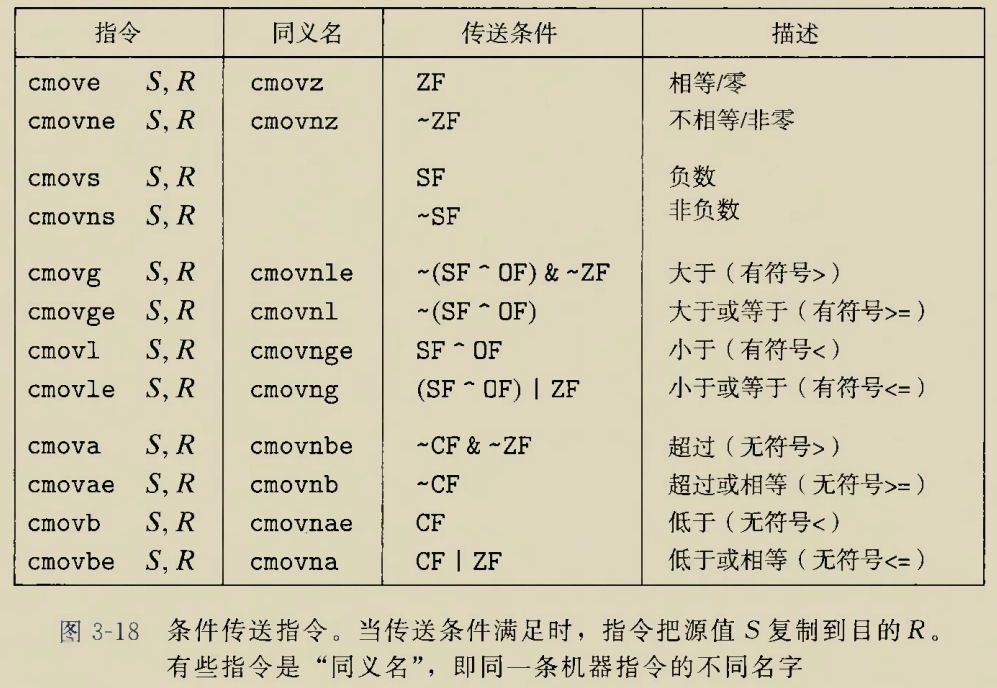
条件传送数据指令,意思就是当满足某些条件时,才会将数据从哪里拷贝到哪里,还是比较容易理解的
跳转指令
PC相对寻址跳转
首先分析CSAPP给出的例子

1.movq %rdi,%rdx
R[%rdx]=R[%rdi]=x将传入的参数放进rax寄存器
2.jmp .L2
无条件跳转到.L2
.L2:
首先testq %rax,%rax作用是置符号标志,方便判断R[%rax]是负数还是非负数
然后jg .L3 ,jump if greater 即如果R[%rax]>0则跳转.L3
.L3:
sarq %rax,寄存器%rax中的值右移一位,即除以二下取整
显然当R[%rax]=0时.L2中的jg不再满足条件,执行第八行 的返回语句
因此可以推断,源c程序是这样写的:
1 | void func(int x){ |
对.o文件使用objdump反汇编得到

第一行和刚才相同
第二行jmp 8这里8怎么来的?左侧的机器码为eb 03,即实际操作数是0x03,然后程序进行到loop+0x3位置即该指令时,首先要做的就是程序计数器移动到下一条指令的位置,即移动loop+0x03这条指令的长度2,此时PC=5,然后jmp 8的8就是PC+0x03=5+3=8,这样得到的
习题3.15

A.当执行4003fa条指令时,PC=4003fc,然后74 02表明要跳转的位置是PC+0x02=0x4003fc+0x02=0x4003fe,即je 0x4003fe
B.当执行40042f条指令时,PC=400431,然后74 f4表明要跳转的位置时PC-0x0C=0x400431-0x0C=0x400425,即je 0x400425
C.执行前一条指令的时候,程序计数器指示下一行的指令位置,即为PC,0x400547=PC+0x02得到PC=0x400545,则第一行的指令地址为0x400545-2=0x400543
D.执行4005e8条指令时,PC=4005ed,字节按照从最低位到最高位的顺序列出为0xff ff ff 73=-141=-0x00 00 00 8D
PC-0x8D=0x4005ed-0x8d=0x400560
因此jmpq 0x400560
习题3.18

程序逻辑分析如下:
1 | R[%rax]=R[%rdi]+R[%rsi]=x+y |
1 | int func(int x,int y,int z){ |
但是这样写会有4条return语句,答案只有一条return语句,在完成所有条件判断之后返回val

首先改写成:
1 | int func(int x,int y,int z){ |
然后x>=-3,x<=2下面是没有东西的,考虑不写这一条
1 | if(x>=-3){ |
这样写还是与给定的格式不一样
第一个if下面应该有一个if,有一个else,最后不应该有else
1 | if(x<-3){ |
此时就和给定的格式相同了

testq %rsi之后各标志位的情况
R[%rsi] |
testq %rsi=R[%rsi]+R[%rsi] |
SF | ZF | OF | CF |
|---|---|---|---|---|---|
| 正数 | 无溢出 | 0 | 0 | 0 | 0 |
| 0 | 无溢出 | 0 | 1 | 0 | 0 |
| 负数 | 无溢出 | 1 | 0 | 0 | 0 |
| 正数 | 溢出 | 1 | 0 | 1 | |
| 负数 | 溢出 | 0 | 0 | 1 |
用testq如何判断一个数是正数还是负数?
正数时SF^OF=0andZF=0
负数时SF^OF=1
0时ZF=1
非负数SF^OF=0
那么配合jge
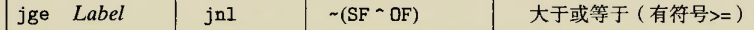
跳转成立条件即$!(SF\oplus OF)=1$即$SF\oplus OF =0$

1 | long loop_while2(long a,long b){ |

1 | long loop_while2(long a,long b){ |
递归过程
需要了解一下过程,调用约定


汇编第6行如果跳转实现的话(rdi中存放的x=0)则到11行将被调用者保存的rbx还原,之前又把eax置0,因此返回0,相当于啥也没干
对应rfun函数中的条件判断
1 | if(x==0)return 0; |
c程序下面的递归过程对应汇编中不满足条件跳转的语句(7到12行)
第7行将rdi中存放的x右移两位
第8行就调用rfun了,rdi是调用者保存的,用来给rfun传递参数,
rfun(x)将会调用rfun(x>>2)
这样一直递归调用到最内层的函数时x==0不满足跳转条件了,返回0,rbx值不变,还是调用者给的值,
1 | 假设上级函数rbx=y |
rax中累计的是历次x的值
rbx保存”本次”x 的值
rdi也是本次x的值啊?为什么还要rbx保存一下?在将本次的x累加到
rax中之前rdi中的x已经右移两位了,应该用rbx记住x之后再右移
rbx的作用就是记住本次本次本次的x值,可以这样理解:
如果不用
rbx,可以开一个数组,比如第一层函数的参数x放到数组第一位
第二层函数的参数x1放到数组的第二位
…
然后在返回的时候只需要将下一层函数的返回值与本层在数组中存放的参数值乘起来然后返回
但是实际上寄存器很有限,被调用者寄存器只有六个,如果递归层数很多了则这种数组是不现实的
只用一个的话就是滚动数组的思想了
在返回之前,由于要返回的值已经用完了,rbx的暂时存放使命完成,可以还给上一层函数了,继续承担上一层函数的暂时存放使命