本文的typora onedark风格见:linkage
链接
win11+vscode+wsl
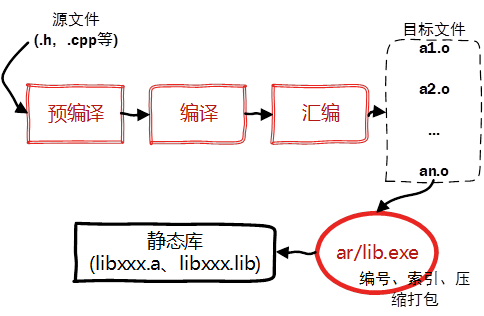
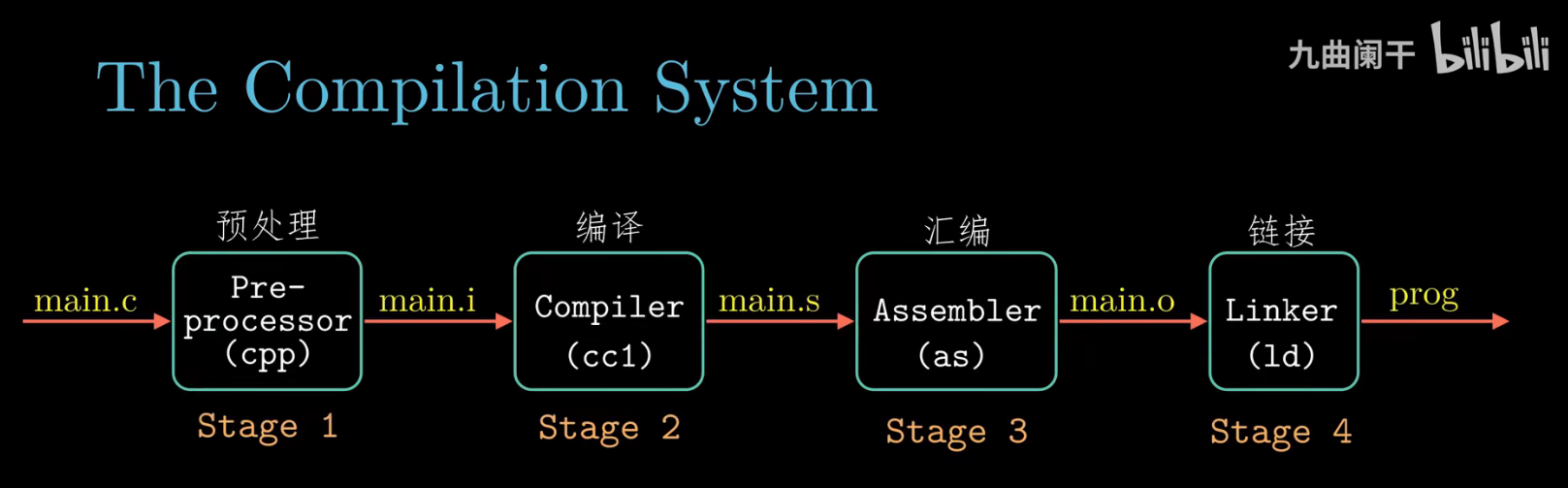
链接是对.o,.a,.so而言的,在此之前要先经过编译,即程序从源代码.c文件编译成目标文件.o
从.c到.o
将要遭遇的概念
GCC:(GNU Compiler Collection)GNU编译器集合
gcc和g++都属于”编译器驱动程序”(driver),实际上编译器是cc1(C语言),cc1plus(C++语言)
2
gcc: /usr/bin/gcc /usr/lib/gcc /usr/share/gcc /usr/share/man/man1/gcc.1.gz在linux系统上自带,可以用whereis 命令查询gcc的位置
我们实际调用的是第一个
/usr/bin/gcc/usr目录:unix system resources缩写,包含了所有共享文件,是unix系统最重要的目录之一
用户的家原来也在这里,但是现在改成了/home
/usr/bin目录:所有可执行文件,比如gcc,g++
GAS:GNU汇编器(GNU Assembler),简称为GAS.使用gcc命令时汇编器(as)和链接器(ld)都是GAS提供的
gcc和g++的区别
包括但是不止下面两条
gcc对于.c文件调用cc1编译器,对于.cpp文件调用cc1plus编译器
g++不管是.c和.cpp都会调用cc1plus编译器
在链接时gcc==不会==传递给链接器链接C++标准库的命令但是g++会
1 |
|
比如这样一个test.cpp文件
使用gcc命令编译则会报错:
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# gcc test.cpp -o test.out |
但是使用g++命令编译则不会报错
如果想让gcc命令编译时让链接器可以链接标准库可以使用命令行参数-lstdc++
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# gcc test.cpp -o test.out -lstdc++ |
但是即使加上该参数,使用gcc和g++对于.cpp的编译还是有区别的.
啥区别我现在不知道,也不想知道
因此现阶段在编译.c源代码时就用gcc命令,编译.cpp源代码时就用g++命令
gcc命令行参数和.c到.exe的过程
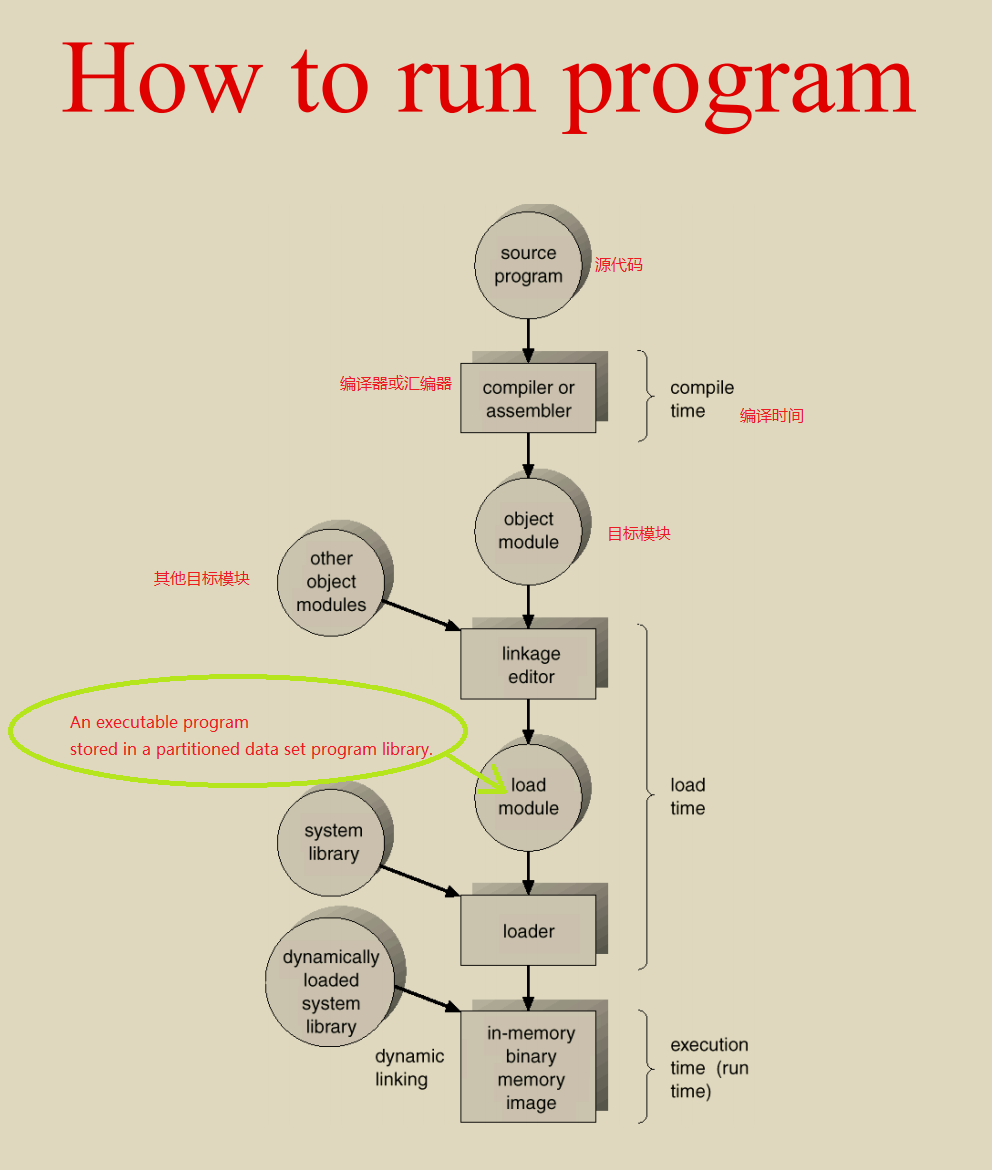

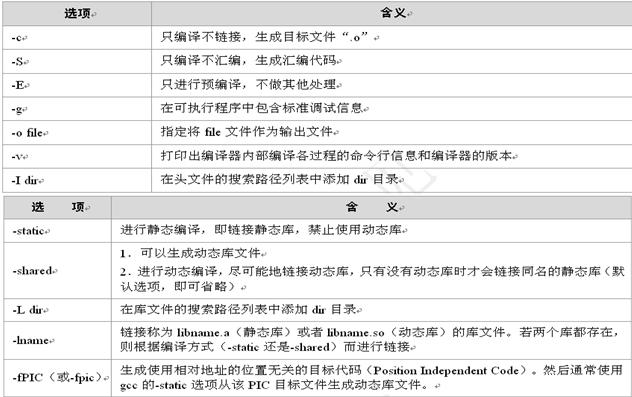
预编译-E
预编译命令只能作用于源代码文件(.c,.cpp)
1 | gcc -E balabala.c |
或者
1 | cpp balabala.c |
1.将所有include(包括库文件和自己写的文件)展开
2.替换所有的宏定义
比如
test.c
1 |
|
使用gcc test.c -E(使用cpp test.c作用相同)之后会将预编译内容打印到屏幕,但是不会生成.i文件
(截图仅为一小部分)
观察到#define N 10消失,N被10替换
typedef起别名并不会被替换
使用-o命令行参数指定预编译生成文件
1 | cpp test.c -o test.i |
然后使用ls -sh -l名令以列表方式查看当前目录下文件大小

可见.i文件明显比.c文件大
-I命令行参数指定自定义头文件
如果需要包含的头文件和就在当前目录下则自动包含,
比如当前目录(mydir/)下
有一个自定义头文件myheader.h里面只有一个变量a的定义
有一个test.c里面没有定义a直接拿来用
此时预编译是可以通过的
1 | root@deutschball-virtual-machine:/home/deutschball/mydir |
如果在其他目录则需要- I <directory>指定包含文件所在的目录
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# ls -l |
将原本与test.c同目录的myheader.h移动到上级目录(..)中,此时使用cpp命令则在当前目录下找不到myheader.h报错了
此时使用-I <directory>指定上级目录(..)为包含路径则预编译通过
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# cpp test.c -I .. |
编译(Compilation)-S
编译命令可以应用于前面所有类型的文件(.c,.i)
1 | gcc -S balabala.c |
作用是将源代码(或者说预编译之后的源代码)编译成汇编语言
将一个全空的c程序(一个字都没写的,这样写当然不对,但是是在后来的某一阶段报错)test.c编译成汇编语言,会在同一目录下生成test.s文件
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# gcc test.c -S |
关于汇编语言后来会学,但不是现在
汇编(Assembly)-c
1 | gcc balabala.c -c |
或
1 | as balabala.c |
汇编命令可以应用于前面过程中生成的所有文件(.c,.i,.s)
汇编过程将上一步的汇编代码转换成机器码(machine code),这一步产生的文件叫做目标文件,是二进制格式
对于一个啥也没写的test.c文件,预编译,编译,汇编都是可以通过的
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# echo > test.c |
到此为止,我们完成了下图中红框中的部分
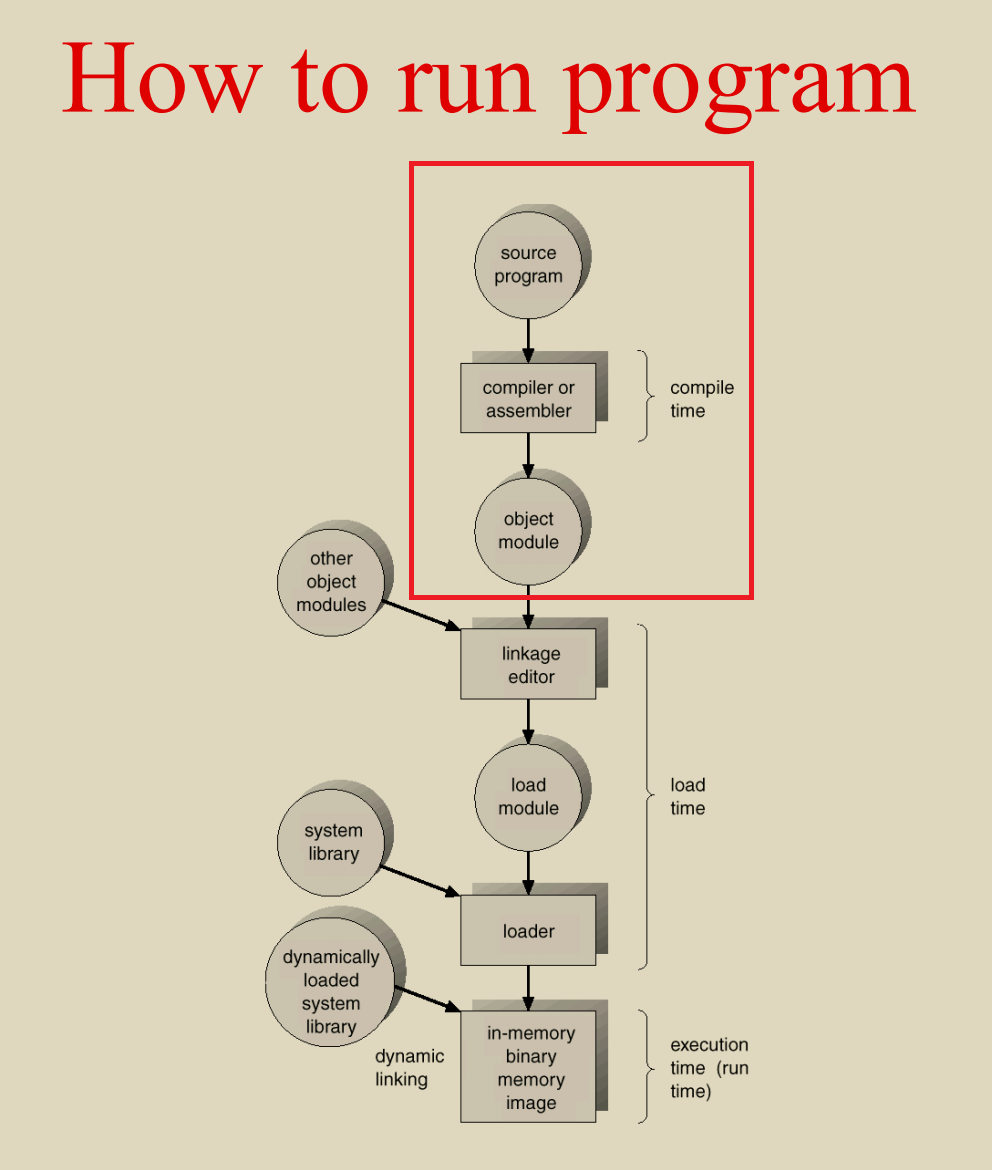
下面来到了链接阶段对应图中load time
链接(Linking)
ld负责将程序的目标文件与所需的所有附加的目标文件连接起来,最终生成可执行文件。
附加的目标文件包括==静态连接库和动态连接库==。
还是一个字也没写的test
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# gcc test.o -o test.out |
在链接阶段终于报错了
报错原因是程序总要有一个main函数入口,一个空的test自然没有main函数
库
库就是现成的可以复用的”代码”.
这里”代码”加了引号,因为库不是我们使用的高级语言代码,而是机器码
一看到”库”我第一反应是包含的头文件
#include <stdio.h>之后使用-E编译命令可以看到预编译生成的.i文件,里面全都是声明,没有实现,函数也都是一些接口,没有函数体,显然只通过include头文件是没法运行这些函数的,那么这些函数的实现在哪里呢?程序怎么找到的函数实现呢?从前道听途说的是在.cpp文件中,在cpp源文件中我们确实可以看到函数的实现,但是我们在编译过程中一直没有与cpp文件发生关联啊?只有.cpp文件包含了.h但是没有见.h包含.cpp啊?从前我幼稚可笑的想法是会根据文件名自动找,比如
#include "balabala.h"之后编译器会自动在同目录下找同名的balabala.cpp.但是通过gcc -E命令可以清楚的看到并没有.并且从来没有规定说头文件和源文件的文件名相同.我原来的想法纯属胡扯库,头文件,源文件的区别和联系,参考https://www.runoob.com/w3cnote/cpp-header.html
可以得到几点结论:
1..cpp这种拓展名不是必须的
2.寻找函数实现是在链接阶段完成的,而引入只有声明的头文件是为了使得编译可以通过
3.函数实现以.o或.obj格式参与到链接中
4.unix下即使不引入头文件,只指明链接阶段需要的.o文件,也可以通过编译,但不是一个好习惯
5.我们程序中使用到符号(函数名,变量名等)会在==参与链接的所有.o文件==中寻找,重复定义报错发生在该阶段
经过前面的学习,我们自己了解到的知识
1..o是.s文件经过汇编生成的,我们自己写的程序也会经历该阶段
2.链接时会连接多个.o文件,包括==自己的==和==库中的==
那么虽然菜鸟教程里没有提到”库”,==我们也可以推测,预定义的.cpp编译生成的.o文件就是库==
.a是多个.o合在一起,和.o是一个性质的文件
还有一个问题,makefile是啥?
记得在上学期用Dev-cpp写一卡通乘车系统项目时,建立项目后会在项目目录下生成一个makefile文件
现在用devcpp建立一个空白项目
项目根目录下有这么几个文件
其中Makefile.win
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# Makefile created by Dev-C++ 5.15
CPP = g++.exe -D__DEBUG__
CC = gcc.exe -D__DEBUG__
WINDRES = windres.exe
OBJ = main.o
LINKOBJ = main.o
LIBS = -L"D:/Dev-Cpp/TDM-GCC-64/x86_64-w64-mingw32/lib32" -static-libgcc -m32 -g3
INCS = -I"D:/Dev-Cpp/TDM-GCC-64/include" -I"D:/Dev-Cpp/TDM-GCC-64/x86_64-w64-mingw32/include" -I"D:/Dev-Cpp/TDM-GCC-64/lib/gcc/x86_64-w64-mingw32/9.2.0/include"
CXXINCS = -I"D:/Dev-Cpp/TDM-GCC-64/include" -I"D:/Dev-Cpp/TDM-GCC-64/x86_64-w64-mingw32/include" -I"D:/Dev-Cpp/TDM-GCC-64/lib/gcc/x86_64-w64-mingw32/9.2.0/include" -I"D:/Dev-Cpp/TDM-GCC-64/lib/gcc/x86_64-w64-mingw32/9.2.0/include/c++"
BIN = project.exe
CXXFLAGS = $(CXXINCS) -Og -m32 -g3
CFLAGS = $(INCS) -Og -m32 -g3
RM = del /q
.PHONY: all all-before all-after clean clean-custom
all: all-before $(BIN) all-after
clean: clean-custom
${RM} $(OBJ) $(BIN)
$(BIN): $(OBJ)
$(CC) $(LINKOBJ) -o $(BIN) $(LIBS)
main.o: main.c
$(CC) -c main.c -o main.o $(CFLAGS)
2
CC = gcc.exe -D__DEBUG__这里好像把
g++.exe -D__DEBUG__命令重新起名CPP后来
2
$(CC) -c main.c -o main.o $(CFLAGS)在这里带入的话相当于
用gcc执行了命令,==并且用-I参数指定了链接阶段需要加入链接的库文件的目录==
由此可见,Makefile不过是一个脚本罢了,是我们不用在命令行在==链接阶段==输入冗长的命令
如果在项目中加入源文件比如
test.cpp并且编译运行main.c
之后会在Makefile.win里面增加一条记录
2
3
$(CC) -c test.cpp -o test.o $(CFLAGS)但是向项目中加入头文件比如test.h然后编译运行main.c则不会在Makefile.win中增加记录
说明Makefile只管.cpp和.c文件时如何编译为.o文件的,头文件.h它毫不关心



到此我们知道了多个文件是如何互相找到,在何时互相找到的,也就是链接要做的事情
下面为了更清楚地理解库的作用,我们需要亲自写几个库试试
然后我查阅了这个博客https://www.cnblogs.com/skynet/p/3372855.html
库有两种,一种是静态库,一种是动态库
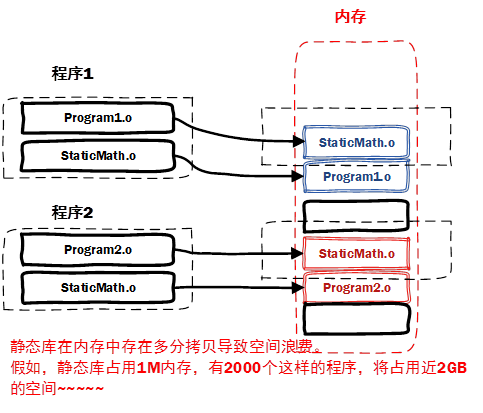
静态库(.a,.lib)
静态库会在链接时与我们自己编译生成的.o文件一起链接打包到可执行文件,这种链接方式称为”静态链接”
静态库可以看作一组目标文件(.o)的集合
静态库对函数库的链接是在编译链接时期完成的
程序运行时与函数库已经没有关系,方便移植
浪费空间,不容易更新
动态库(.so.dll)
windows上的动态库.dll我们早就见过了
比如红警3根目录下面就可以见到

动态库的出现是为了解决两个问题
1.静态库占用空间,多个程序可能有相同的静态库
2.更新时,静态库即使静态库稍微改动一点,也需要全部重新编译(全量更新)
动态库相对这两点的特性
1.多个程序复用同一个库
2.增量更新,哪里更新就编译哪里
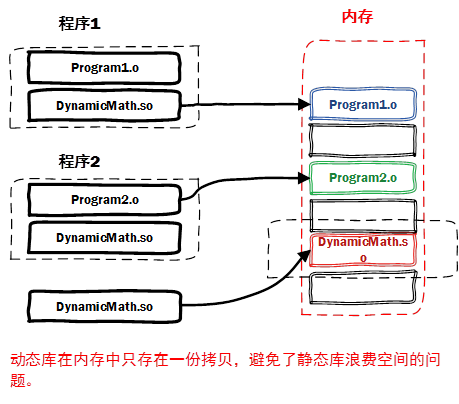
这就要求动态库在运行时才会装载
静态库的使用
在/home/deutschball/mydir文件夹下写了三个文件
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# ls -l |
point.h
1 |
|
point.cpp
1 |
|
main.cpp
1 |
|
准备工作完毕,下面开始创建静态库
main.cpp为入口,Point.h是头文件,我们需要将Point.cpp创建为静态库
1.将Point.cpp编译成目标文件.o
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# g++ Point.cpp -c |
2.使用ar工具将刚才生成的目标文件打包成.a静态库文件
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# ar -crv libpoint.a Point.o |
linux下静态库的命名规范是lib开头
我们没有指定libpoint.a的目录,因此在当前文件夹下形成
到此,静态库libpoint.a建立完毕
下面我们在编译main.cpp时使用静态库
-L指定静态库目录
-l指定静态库和动态库的名字
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# g++ main.cpp -L ./ -l point -o main |
可执行文件main.out就生成了
-L指定静态库目录,由于我们的静态库就在当前文件夹,于是-L ./
-l指定静态库名字,会自动在名字前面加上lib,在后面加上.a后缀,于是指定-l point就找到了libpoint.a
动态库的使用
linux上动态库的命令规则libbalabala.so,前缀lib后缀.so
windows上动态库使用比较复杂,不管他了
创建动态库
首先生成目标文件,注意使用-fPIC命令行参数
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# g++ -fPIC -c Point.cpp |
-fPIC(position independent code)作用是创建==地址无关==代码
与地址无关?
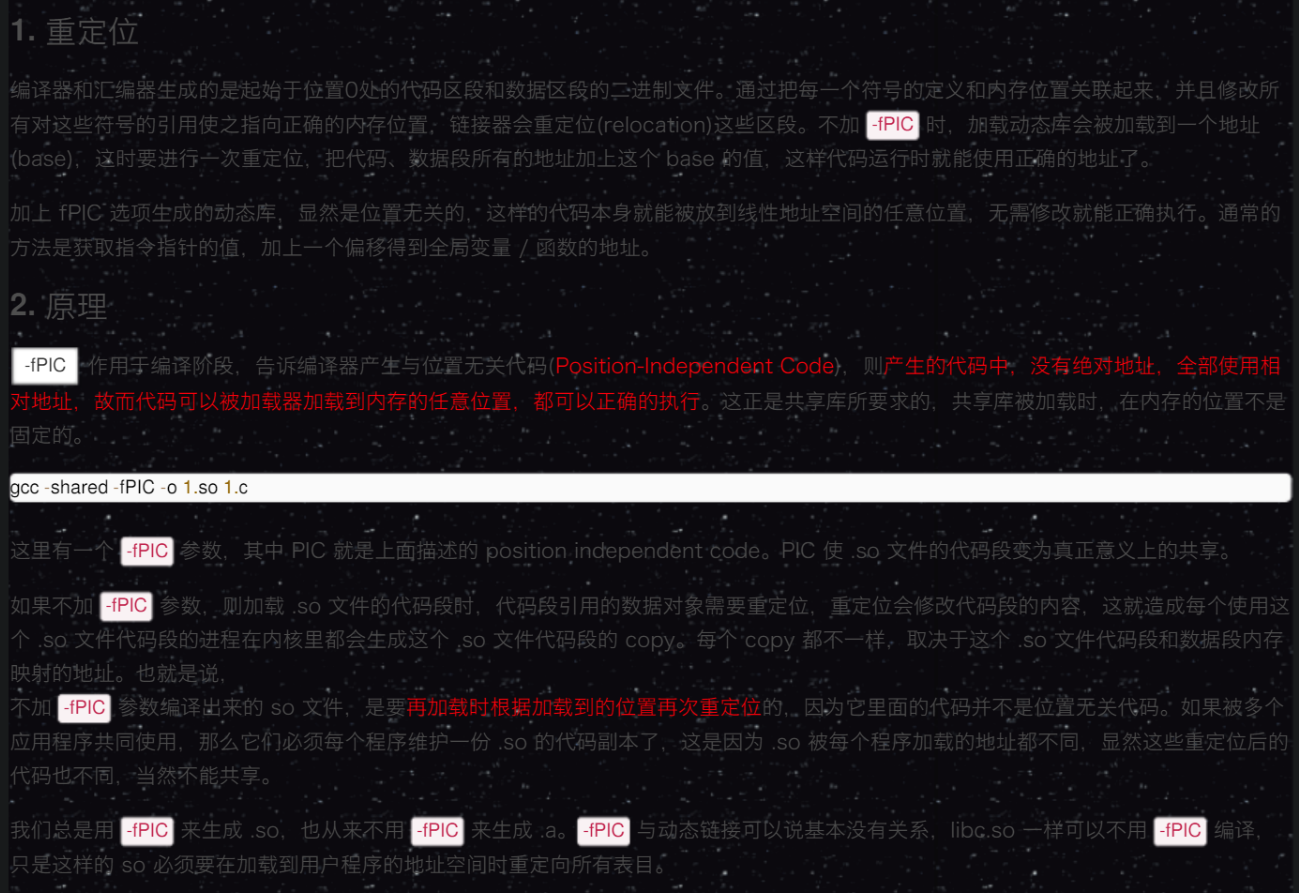
然后生成动态链接库
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# g++ -shared -o libpoint.so Point.o |
生成了libpoint.so
到此动态库创建完毕,下面使用动态库
尝试用使用静态库的方法使用动态库
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# g++ main.cpp -L ./ -l point -o main.out |
可以通过编译但是out文件执行出错,说是找不到libpoint.so
==那么动态库到底在哪里呢?==

使用第一种方法,将我们自己编写的动态库放在/usr/lib下面
1 | root@deutschball-virtual-machine:/home/deutschball/mydir# cp libpoint.so /usr/lib |
发现可以正常运行了
参考文档
How programs are prepared to run on z/OS
参考博客
https://www.cnblogs.com/skynet/p/3372855.html
https://www.runoob.com/w3cnote/cpp-header.html
目标文件
又称为elf文件
executable and linkable file
ELF文件有三种:
可重定位目标文件
.o共享目标文件
.so可执行目标文件
.out编译器和汇编器生成可重定位目标文件和共享目标文件(
.o),连接器生成可执行目标文件(.out)
可重定位目标文件.o
.o文件的结构

一个.c源文件就是一个模块
.c源文件使用编译器和汇编器得到.o可重定位目标文件
readelf命令的使用
对于main.c
1 | int sum(int *a,int n);//在使用其他模块中定义的函数前,要先引用该函数,否则报编译错 |
使用gcc main.c -Og -c -o main.o将其编译成为可重定位目标文件main.o
下面对main.o使用readelf的一系列命令进行观察

-h打印elf文件头信息
1 | ELF Header: |
1.Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00

魔数,表明本文件类型等基本信息
| 16进制 | 7f | 45 | 4c | 46 | 02 | 01 | 01 |
|---|---|---|---|---|---|---|---|
| ascii码或意义 | DEL符 | ‘E’ | ‘L’ | ‘F’ | 01表示32位 02表示64位 |
01表示小端法 02表示大端法 |
ELF版本号 通常为1 |
后面9个字节==ELF标准==中无定义,用0填充,和前面的7f 45 4c 46 02 01 01凑成16个字节
2. Start of program headers: 0 (bytes into file)
程序头开始位置,对于.o文件来说,它距离可执行还缺链接这一大步,程序头对他来说没意义
3. Start of section headers: 776 (bytes into file)
节头开始时的字节,即本文件的第776字节开始时节头
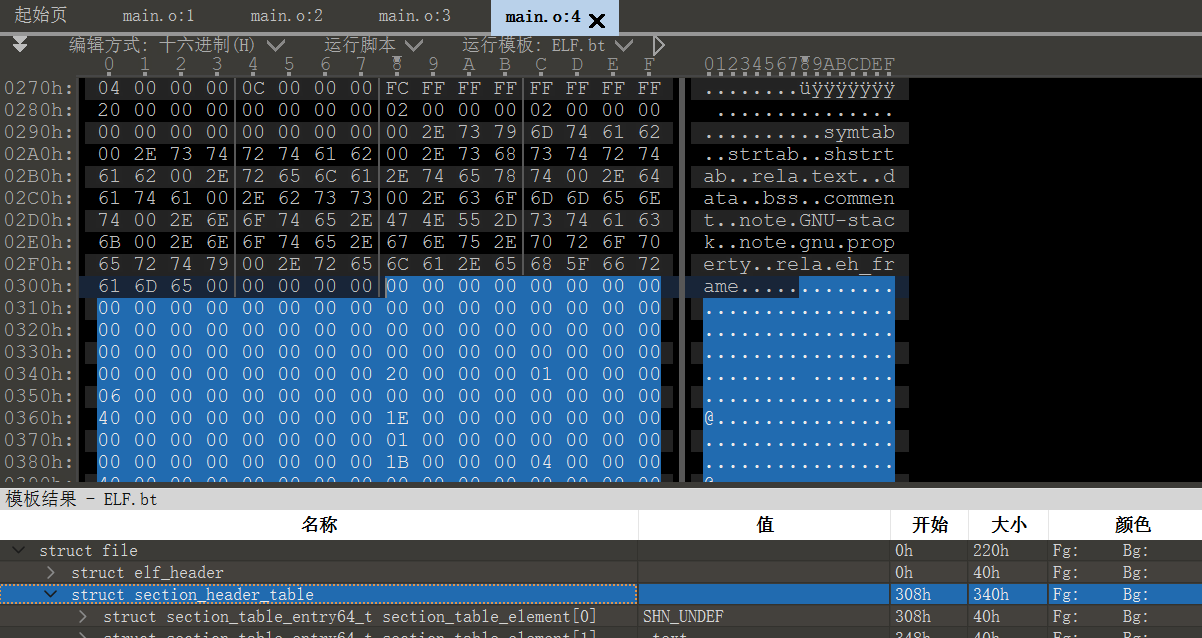
使用010editor观察,section header table的起始位置是0300h+8=776字节
4.Size of this header: 64 (bytes)
本头(elf文件头)的大小为64字节(16进制表示为0x40)即本elf头部分占用本文件的0到63字节,则下一部分即sections部分从0x40开始

5. Size of section headers: 64 (bytes)
section header table中,每个section表项的大小
6. Number of section headers: 13
section header table中的表项数
5和6合计可以计算出section header table的大小为13*64=832字节
又知道section header table 的起始位置为776(10进制)字节处,加上该部分大小832字节可以计算得到本.o文件总大小为1608
使用wc命令可以验证刚才计算(wordcount统计文件大小(字节数))
1 | root@Executor:/mnt/c/Users/86135/Desktop/Linker# wc main.o |
7.Section header string table index: 12
-S打印整个section header table表信息
| 表头 | Name | Type | Address | Offset | Size | EntSize | Flags | Link | Info | Align |
|---|---|---|---|---|---|---|---|---|---|---|
| 含义 | 节名 | 节类型 | 在本文件中的偏移量 | 节大小 |
1 | There are 13 section headers, starting at offset 0x308: |
以.text节为例子
1 | [ 1] .text PROGBITS 0000000000000000 00000040 |
Offset=0x40即本节在本文件中的0x40位置,又elfheader占用了前64个字节(0~0x3F),因此.text节是紧接着elfheader存放的,大小为0x1e=30字节
那么下一个节的起始位置就应该是0x40+0x1e=0x5e
然而下一个节.data的Offset=0x60
1 | [ 3] .data PROGBITS 0000000000000000 00000060 |
用010editor观察发现0x5e和0x5f全是0,估计是考虑了对齐的原因

用objdump -s观察
1 | Contents of section .text: |
可以断定0x5e和0x5f的0是对齐方式导致的
观察某一节
只需要在参数上指定该节的首字符,比如要观察.rel开头的节
1 | root@Executor:/mnt/c/Users/86135/Desktop/Linker# readelf -r main.o |
观察符号表节
1 | root@Executor:/mnt/c/Users/86135/Desktop/Linker# readelf -s main.o |
可重定位目标文件的常用节
1 |
|
.text
存放指令
使用objdump -d main.o可以观察.text的反汇编
1 |
|
.data
1 | [ 1] .text PROGBITS 0000000000000000 00000040 |
存放已经初始化(且不为零)的全局变量或者局部变量
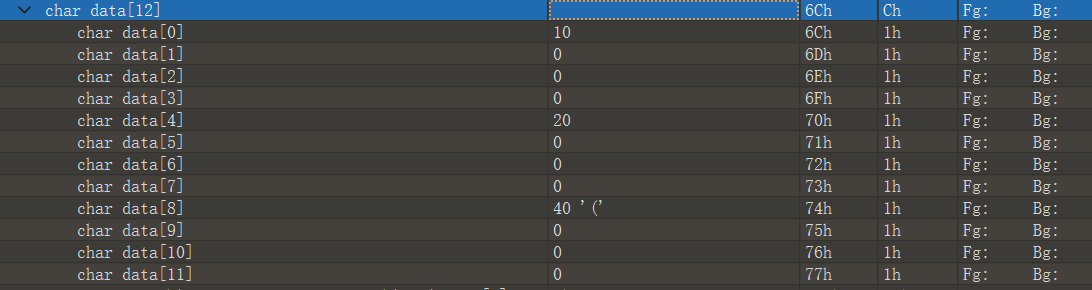
如图被data节表管理的data节中只有10,20,40这三个已经赋值的全局或者静态变量
.bss
1 | [ 4] .bss NOBITS 0000000000000000 00000068 |
该部分只有一个节表表项,在节中实际不存在,只是起一个占位符的作用
未初始化的静态变量或者初始化为0的全局或静态变量,当程序运行时才会给bss变量在内存分配空间并赋值0
COMMON存放未初始化的全局变量,这和链接有关
.rodata
printf要打印的字符串字面值就存放在该区域
.rel开头的节及其他节
.rel的节和重定位有关

链接依赖于符号.symtab节管理符号
.symtab节
main.c
1 | int sum(int,int); |
sum.c
1 | int sum(int a,int b){ |
只将main.c编译成main.o可重定位目标
1 | gcc main.c -Og -c -o main.o |
然后readelf -s观察符号表节
1 | root@Executor:/mnt/c/Users/86135/Desktop/Linker# readelf -s main.o |
| 项目 | Num | Value | Size | Type | Bind | Vis | Ndx | Name |
|---|---|---|---|---|---|---|---|---|
| 意义 | 编号 | 符号在其所在节中,举例节首地址的偏移量 | 大小 | 类型(函数/对象等等) | 属性,本地还是全局 | section节索引,在section header table中确定 | 名称,这个字符串名称放在.strtab节中 |
Ndx中的值是该符号在本文件中的哪一节,UND则为本模块中引用的其他模块的符号
符号和符号表
.o目标模块都有一共符号表,其中包含该目标模块中定义和引用的符号信息
对于连接器来说有三种符号
1.本模块定义的全局符号,对其他模块可见
2.其他模块定义的全局符号,对本模块可见
3.本模块定义的静态符号,只对本模块可见
static的作用类似于java中的private或者protected,而全局变量则相当于public修饰
函数栈中的局部变量不会出现在符号表中,其符号由堆栈维护,或者说不需要符号.
每个符号都属于一个节
比如函数就属于text节,已初始化且不为0的全局变量属于.data节,未初始化的静态变量属于.bss节等等
只有.o可重定位目标模块中存在的,并且节头表.symtab中没有条目的三个伪节:
.ABS 不该被重定位的符号
.UNDEF 本模块中只有引用没有定义的符号
.COMMON 未初始化的全局变量
注意存放全局变量时,放在.COMMON和.bss的区别,static变量不会涉及链接问题,但是全局变量会
将未初始化的全局变量放到.COMMON,将已初始化为0的全局变量放到.bss,将已初始化不为零的全局变量放在data
这样做的目的和链接时符号的强弱性质有关,这都是后话了
链接形成可执行目标文件之后这三个伪节就不复存在了
符号解析
多个目标文件或者库还有命令行参数构成链接器的输入
连接器在链接时,会给每个引用在其输入的一个模块的符号表中找到与该引用对应的符号定义
关键在于全局符号的引用解析
如果编译器遇到了一个引用并且在本模块中没有找到定义,则编译器会假设其定义在其他模块中,生成一共链接器符号表条目
如果链接器在所有输入的目标模块中都没有找到该引用的定义则报错
2
3
4
5
6
7
void func();//func只是一个引用,在本模块中没有定义
int main(){
func();
return 0;
}链接报错:
2
collect2.exe: error: ld returned 1 exit status
2
3
4
5
6
7
8
void func();
int main(){
func();
return 0;
}
void func(){}//func在本模块中有定义此时链接不会发生报错
如果链接器找到了多个定义,则按照下面三条规则处理多重定义符号名
强符号:函数,已初始化的全局变量(data或者bss节)
弱符号:未初始化的全局变量,放在COMMON伪节
int a;这就是一个弱符号
int a=0;这就是一个强符号

因此将全局变量按照是否初始化,被分到common还是data或者bss节
common中符号的在链接时会被作为弱符号
重定位
重定位的两个步骤
1.重定位节
将所有输入的目标文件合并成一个文件,由于每个目标文件都有.data等节,因此需要合并每个目标文件中的相同节,形成一个文件
如此,所有的符号定义相对于该文件都有一个确定的偏移量位置,此时就可以给每个符号一个虚拟内存地址了
**2.**重定位节中的符号引用
在1中我们已经给每个符号定义确定了一个绝对的虚拟内存地址,但是怎么让该符号的引用也知道应该引用这个绝对的虚拟内存地址?
本步骤就是让所有符号引用都有着落
举个例子,
main.c是这样写的:
2
3
4
5
6
void func();//声明一个函数符号引用
int main(){
func();
return 0;
}让编译停止在链接前,此时
func函数对于main模块来说还只是一个符号引用,对
main.o反汇编之后
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
PS C:\Users\86135\desktop\os\Linker> objdump main.o -d
main.o: file format pe-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 20 sub $0x20,%rsp
8: e8 00 00 00 00 callq d <main+0xd>
d: e8 00 00 00 00 callq 12 <main+0x12>
12: b8 00 00 00 00 mov $0x0,%eax
17: 48 83 c4 20 add $0x20,%rsp
1b: 5d pop %rbp
1c: c3 retq
1d: 90 nop
1e: 90 nop
1f: 90 nop发现反汇编的代码中并没有出现func函数的影子,并且有两条很诡异的call指令
2
d: e8 00 00 00 00 callq 12 <main+0x12>明明就在本函数之中,却还要
call一下这样写的原因是,目前本模块并不知道
func的地址,因此指令中根本没法写call谁e8 00 00 00 00这里后面8个0就是未知地址,e8是只是call指令的操作码这里写了两个不明所以的
call指令,原因是,上面这个8: e8 00 00 00 00 callq d <main+0xd>在链接后调用的是__main函数,作用是进行一些初始化
2
3
4
5
6
7
8
9
10
11
401650: 8b 05 da 59 00 00 mov 0x59da(%rip),%eax # 407030 <initialized>
401656: 85 c0 test %eax,%eax
401658: 74 06 je 401660 <__main+0x10>
40165a: c3 retq
40165b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
401660: c7 05 c6 59 00 00 01 movl $0x1,0x59c6(%rip) # 407030 <initialized>
401667: 00 00 00
40166a: e9 71 ff ff ff jmpq 4015e0 <__do_global_ctors>
40166f: 90 nop
...下面这个才是
call func,调用func函数
2
3
4
5
6
7
8
9
10
11
12
13
401560: 55 push %rbp
401561: 48 89 e5 mov %rsp,%rbp
401564: 48 83 ec 20 sub $0x20,%rsp
401568: e8 e3 00 00 00 callq 401650 <__main>
40156d: e8 0e 00 00 00 callq 401580 <func>
401572: b8 00 00 00 00 mov $0x0,%eax
401577: 48 83 c4 20 add $0x20,%rsp
40157b: 5d pop %rbp
40157c: c3 retq
40157d: 90 nop
40157e: 90 nop
40157f: 90 nop
链接器依赖可重定位模块(.o)中的重定位条目实现该步骤
重定位条目
汇编器在遇到一个本模块中没有定义的符号引用时,就会为该符号引用创建一个重定位条目
代码的重定位条目存放在.rel.text节中
已初始化数据的重定位条目存放在.rel.data节中
重定位条目结构定义:

offset:引用的节偏移量
type:重定位类型(着重关心其中的两种)
symbol:符号表的下标
addend:修正参数
R_X86_64_PC32重定位一个使用32位PC相对地址的引用
PC相对地址:某地址与当前PC值的距离
32位相对地址加上当前PC值得到有效地址
2
3
4
5
6
7
8
9
10
11
12
13
1139: 48 83 ec 08 sub $0x8,%rsp
113d: 48 8d 3d c0 0e 00 00 lea 0xec0(%rip),%rdi # 2004 <_IO_stdin_used+0x4>
1144: b8 00 00 00 00 mov $0x0,%eax
1149: e8 e2 fe ff ff call 1030 <printf@plt>
114e: 48 83 c4 08 add $0x8,%rsp
1152: c3 ret
0000000000001153 <main>:
1153: 48 83 ec 08 sub $0x8,%rsp
1157: b8 00 00 00 00 mov $0x0,%eax
115c: e8 d8 ff ff ff call 1139 <func>
1161: b8 00 00 00 00 mov $0x0,%eax比如当执行115c处的
115c: e8 d8 ff ff ff call 1139 <func>时此时程序计数器指向下一条指令
PC=0x1161操作码
e8表示call相对地址
d8 ff ff ff按照小端模式存放,写成16进制数应该为0xff ff ff d8=-40=-0x28PC加上相对地址即
0x1161-0x28=0x1139恰好为0000000000001139 <func>:的首条指令的地址
R_x86_64_32重定位一个使用32位绝对地址的引用
绝对寻址,直接在指令编码中给出有效地址
重定位算法

重定位算法也是比较容易理解的,
说了一个啥事呢?
现在各个模块的text合并成一个text节,所有符号都有一个重定位条目,记录了自己在本节中的偏移量(相对于节基地址的位置)
然后本节中的一个符号想要找另一个符号的位置
这就相当鱼一个数组arr中,要计算arr[20]和arr[200]的举例,直接用200-20=180,这里下标就是数组元素相对于数组基地址的偏移量
数组就相当于这一整个text节,元素相当于text节中的一个符号,下标相当于该符号相对于text
所有引用符号重定位之后,此时所有引用,所有符号 都有址可循,链接完全完成,形成可执行目标文件.out
可执行目标文件.out
可执行目标文件通常以.out作为拓展名,或者根本就不写拓展名,反正linux上对拓展名没有windows上那么严格
文件视图
完全链接之后,所有的目标模块都融洽地形成一个可执行目标文件,原来每个目标模块中都有text,data等节,在可执行目标文件中,每种节有且只有一个
可执行目标文件的格式:
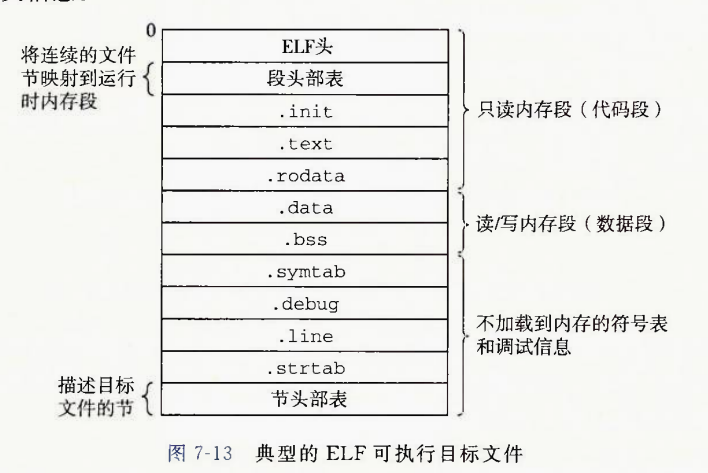
ELF头从0开始,这并不意味着ELF在真正执行的时候,起运行地址空间从0开始.
.init节是一个小型的代码段,里面就一个小函数_init作用是进行一些初始化,具体初始化了啥我不知道,也不是学这一部分所应关心的重点
用010editor elf模板观察一个可执行目标文件

elf_header的作用和.o可重定位目标模块中的类似,作用是声明ELF魔数,规定后续各部分的偏移量和大小
program_header程序头
作用是规定
1.各节在本可执行目标文件中的偏移,
2.虚拟内存地址,
3.对齐要求,
4.本目标文件中的段大小,
5.实际执行时内存中的段大小,
6.运行时的读写执行权限
1 | ┌──(kali㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] |
运行视图
在shell上,./prog命令即可加载并执行可执行目标文件prog
实际上是shell调用execve函数来调用加载器,加载器是操作系统的组成部分.
加载器把prog的所有代码和数据从磁盘拷贝到内存,然后跳转到程序的第一条指令,然后控制转移到该程序,程序执行.这个过程叫做加载
至于加载器究竟干了啥,我不知道,现在也不想知道
加载完成后,程序在内存中的映像图是这样的
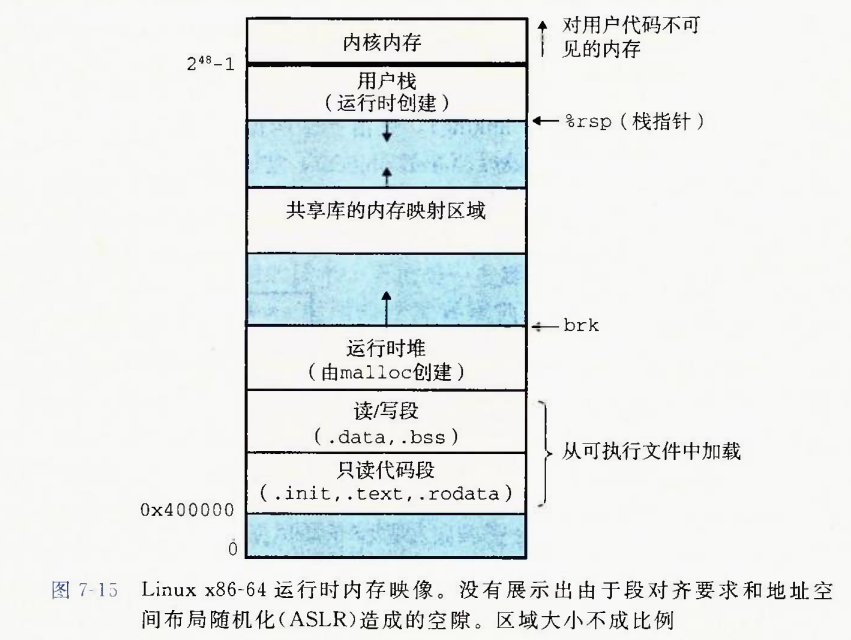
其中忽略了一些无关紧要的信息,比如
1.各段都有自己的对齐要求,但是图上都画的紧挨着.实际上有可能”相邻”两段之间有一些没有意义的空隙,当程序错误执行到这些空当时就会触发段错误
2.没有表现出地址空间布局随机化.ASLR的作用是对抗pwn攻击的,在做一些简单的pwn题目时,一个变量,一个函数的地址都是确定的,使用ida打开看到了,那么就可以确定下一次运行时那个函数,那个变量还是在那个位置.而开启ASLR之后每次运行,同一个变量会有不同的地址.
但是仍然可以确定的是,两个变量,变量和函数,函数之间的相对位置都是不变的,就相当于把整个村从城南搬到城北,李四还是知道张三住哪里,走多远到张三家
运行时视图没有”section“这种说法了,类似的概念叫”segment“
比如只读代码段(由原来的.init,.text,.rodata节组成)
性质类似的节(比如只读数据和代码都不可执行,合并到一个段
段也有类似于节的属性,比如读写执行权限
如果企图在只读代码段修改或写入东西
或者在开启了NX保护(堆栈不可执行)之后在堆栈上写shellcode并ret2shellcode
都会引起段错误
库文件.a & .so
CSAPP中将静态库放在静态链接讲完之后,动态链接开始讲之前.
但实际上讲动态链接时并没有涉及到静态库.
现在改变一下思路把静态库和动态库这两种库文件放在一起阐述
源头之”争”
去年的历史遗留问题
**1.**在大一学习c语言时我们就知道,如果要使用
printf和scanf函数,必须#include <stdio.h>,如果使用
srand(time(0)),其中的time(0)要求#include <time.h>然而实际上去观察一下
<stdio.h>这种.h头文件,其中并没有函数的实现,只有函数的接口.那#include <xxx.h>的目的是啥呢?**2.**在大二上学习C++时,函数,类的定义和声明分别写在源还是头文件中,给我们带来了巨大麻烦
头文件既然妹有写实现,源文件中声明和实现相当于都有,那么头文件还有存在的意义吗?难道是只写接口看起来干净整洁好看吗?
非也
头文件提供一个引用
啥意思呢?下面以一个例子说明,在这个例子中虽然不涉及头文件,但是实际上包括了头文件要做的事
注意一些文字游戏
“定义”和”实现”是一个说法,都是带函数体的函数,比如
int func(){/*花括号里是函数体*/}“声明”和”接口”是一个说法,都是不带函数体,只有一个函数声明,比如
int func();//分号结尾,妹有函数体
考虑这么一个程序main.c
1 | int main(){ |
在main.c中,func函数既没有定义也没有实现,直接在main函数中调用
现在我们把编译和链接分别执行
编译阶段
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] |
这里报了一个警告,意思是func没有直接言明
编译器很懵逼,func是个啥啊,你妹有定义实现也就罢了,竟然连声明都不打招呼,
上来就用,玩意func有参数,万一func根本就不是函数,是个变量咋整?func有没有返回值啊>_<,返回啥类型值啊?
我编译器只能联系上下文,按照func是一个返回int的无参函数来编译了
链接器你就自求多福吧,我摆烂了
那么怎么才能让编译器知道关于func的信息呢?在使用之前声明一下这个函数接口
2
3
4
5
int main(){
int a=func();
return 0;
}此时编译就妹有警告了,这意味着编译器此时已经非常自信地认为自己的工作很perfect
链接阶段
链接的作用是给每个引用都找到实现,让所有悬而未决的议案落地
在同文件夹下有一个func.c,其中有func()函数的实现
1 | int func(){ |
此时
main.c这样写
2
3
4
5
int main(){
int a=func();
return 0;
}
main.c和func.c都已经正确经过编译,生成了可重定位目标文件main.o和func.o
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] |
根据前面章节的学习,main.o中有一个func函数的引用悬而未决,如果要形成main.out,需要让这个引用落地
如果直接写gcc main.o -o main不用想都知道会报错
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] |
链接器报错:func引用未定义
考虑如下场景
这里printf未定义的报错是不是和刚才func妹有定义的报错是同一种错误?
给gcc怎样传递命令行参数,才能不让链接器报错呢?
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] |
这句话的意思是,将main.o和func.o进行链接,(如果妹有链接错误的话)形成可执行目标文件main
整个过程
现在考虑编译到链接整个过程,怎样才能不报错不报警告?
1.编译时引用要提前声明一下
2.链接时要包含所有引用实现的模块
回到源头之”争”
#include <stdio.h>是一条宏定义,在预编译阶段会被展开,也就是将stdio.h中的所有东西都加在main.c的一开始,形成main.i
main.i实际上还是ASCII文本文档,和main.c几乎妹有区别
还记得<stdio.h>中都是写的啥吗?函数声明
那么main.i是个啥?
一伙子函数引用+我们自己写的main函数,
which调用了printf,
which在前面一伙子函数引用中有一席之地.
可见<stdio.h>帮我们完成了声明函数引用的工作.
为什么要用一个头文件来做这个工作?我们程序员是傻吗?自己声明一个printf的引用不行吗?
其一,printf是个变参函数,这一下子就限制了很多人写函数引用,变参函数的函数接口长啥样啊?我也不知道
其二,printf的返回值是啥,
int?long?unsigned?size_t?调用约定是啥?__cdecl?__fastcall?即使我记性好,这些都记住了,那么scanf,sprintf,fgetc,fwrite....等等函数的接口又长啥样?难道每次调用一个库函数都要去查手册吗?手册得多厚啊,新华字典见了都怕
在预编译阶段过后,宏定义被展开,此时头文件就完成了自己的使命
奇怪的是,即使我们用到了glibc库中的函数printf
1 |
|
但是在编译链接时,也没有指定printf在哪里实现啊?
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] |
按照我们在”链接阶段”举的例子,这里就应该链接报错"undefined reference : 'printf' "
而实际上程序链接地好好的
这是因为,printf 的实现在glibc.so动态库中,而该动态库会被链接器自动且隐式地链接
printf实现所在的源文件去哪了?
源文件被编译成glibc.so动态库了,从一个ASCII文档变成二进制文件了,源文件的灵魂已经装进glibc.so
如果想要看printf源文件怎么实现的,去哪里找呢?
谷歌或者百度glibc-2.9或者其他版本,去官网下载吧
明确分工
在大二上学面向对象C++的时候,曾经费尽心思记什么东西应该写到头文件里,什么东西应该写到源文件里(到考试,到现在也没记住)
其实学了链接时符号解析规则,这些问题根本就不是问题
刚才已经举例说明了,头文件的作用就是声明一下函数接口,起引用作用
头文件可以写函数实现吗
现在基于对链接的了解,考虑头文件里可以写函数实现吗?
貌似可以,并且可以说出歪歪理儿,举一个有模有样的例子:
func.h
2
3
return 510;
}
main.c
2
3
4
5
int main(){
int a=func();
return 0;
}这样
gcc main.c -o main不会报错,并且连链接时指定可重定位目标文件或者库文件都省去了,岂不美哉?当然不会报错,这样写
func.h改名为func.balabala都可以,.h后缀妹有意义实际上相当于写了
main.c
2
3
4
5
6
7
return 510;
}
int main(){
int a=func();
return 0;
}
这里不报错的原因是,整个编译链接就涉及到两个模块,并且只有main引用了func,这关系简单明了
可如果这样写呢?
func.h
1 | int func(){ |
func1.c
1 |
|
func2.c
1 |
|
程序入口这样写:
main.c
1 | int func1(); |
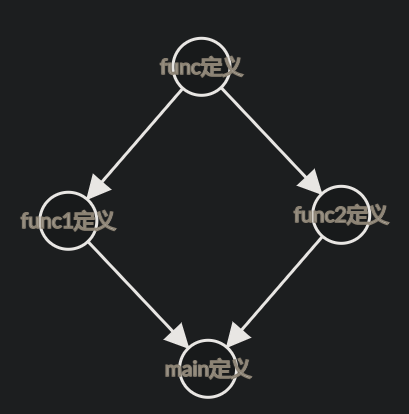
main中相当于有两个func的定义
使用gcc main.c func1.c func2.c -o prog企图编译链接
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] |
发现编译是可以通过的,报错全是链接错,func有多重定义
为啥会报错呢?
第一次预见func的定义是在func1.c中,竟然在func2.c中又预见了func的定义
实际上相当于写了这么一个程序:
1 | int func(){ //func第一处定义 |
func被定义了两次,函数名字和参数表一模一样,不是重载也不是重写,必然会报错
用前面章节的知识解释,函数定义是硬符号,符号解析时硬符号最多有一个,如果链接器发现有两个以上的同名硬符号则报错
有人在往linux内核里添加系统调用的时候就在
syscalls.h里面写了内核函数的实现,我不说是谁
那么为了防止上述多重定义的情况发生,应该怎么办呢?
不允许多重定义,还能不允许多重引用吗?
头文件里只写函数声明或者说函数接口,源文件里写函数实现呗
正确写法
main.c
1 |
|
func.h & func.c
func.h
1 |
|
func.c
1 |
|
func1.h & func1.c
func1.h
1 |
|
func1.c
1 |
|
func2.h & func2.c
func2.h
1 |
|
func2.c
1 |
|
通过链接
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] |
头文件可以写全局变量吗
还是以geometry的例子(见下文静态库->使用静态库),假如在geometry.h中,我们定义了一个全局变量PI
geometry.h
1 |
|
我们的目的是,只要引用了该头文件就可以直接使用PI,比如
在main.c中:
1 |
|
结果却报告链接错误了
1 | ┌──(kali㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] |
意思是PI有多重定义了
为啥会报链接错:有多重定义?
line.c和point.c,main.c中都有#include "geometry.h"
前面我们也分析了头文件的作用,头文件中的东西在预编译宏展开之后会直接加到源文件前面.
那么预编译之后,line.i,point.i,main.i中各有一次const double PI=3.1415926的定义,这是硬符号,然后三个文件都被编译成可重定位目标文件.o准备链接
链接时同名的全局符号只允许有至多一个硬符号,而对于PI符号,链接器可以发现两个(找到第二个就报错了,不管第三个了)因此报链接错,多重定义
可是我们头文件中宏定义是条件展开的啊,已经定义过就不会被定义了啊?
考虑宏定义的展开是在预编译阶段,远没到链接,等到链接的时候,早就都展开了 .条件展开的作用是防止同一个头文件被多次include
比如
2这两个头文件是包含关系,完全可以只
#include <cstdio>,但是这时#include <stdio.h>之后再#include <cstdio>时,会引入<cstdio>中除了包含的的<stdio.h>之外的其他内容.当然,如果再引入一遍<stdio.h>也不会报错,因为都是引用但是有时候去重的作用就很重要,比如
"a.h"中会#include "b.h"同理"b.h"会#include "a.h",即两个头文件会互相引入,如果此时不使用条件展开去重,则预编译器会不停引入两个文件,直到崩溃
正确写法
方法一:宏定义PI
在geometry.h中
1 |
|
这也是glibc库的头文件中使用的方法
比如
stdio.h中
2
3
4
5我们自己写一个
main.c,#include <stdio.h>之后就可以直接使用这些宏定义
为什么可以使用宏定义呢?
各组成模块宏定义展开之后可能会有多条同样的宏定义,宏定义允许多次定义,在调用时使用最后一次的宏定义
比如
2
3
4
5
6
7
8
9
10
using namespace std;
int main() {
cout << PI;
return 0;
}运行结果
但是会报告编译警告
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
3 | #define PI 3.142
|
testGlobal.c:2: note: this is the location of the previous definition
2 | #define PI 3.14
|
testGlobal.c:4: warning: "PI" redefined
4 | #define PI 3.1416
|
testGlobal.c:3: note: this is the location of the previous definition
3 | #define PI 3.142
|
testGlobal.c:5: warning: "PI" redefined
5 | #define PI 3.14159
|
testGlobal.c:4: note: this is the location of the previous definition
4 | #define PI 3.1416
|而如果多次宏定义一模一样
2
3
4则不会报告编译警告
方法二:使用extern引用
比如在point.c中全局位置写入const double PI=3.1415926;
main函数中要使用PI值,那么在main.c中找一个使用PI之前的位置(不管是局部还是全局位置),extern double PI;
作用是,声明一下PI是一个外部符号(本模块中妹有定义),编译时产生一个引用,至于引用的解析,让链接器去找
实际上用
extern声明一个变量和声明一个函数引用的作用是类似的,都是声明引用.但是为啥函数引用不用
extern声明,但是变量就一定得用extern声明呢?函数只要不写函数体,在参数表小括号后面一个分号,立刻就可以断定这是一个函数引用.
而全局变量即使不赋值直接写分号,
int a;编译器就认为这是一个应该放在.bss节的本模块中的数据.为了突出是个引用,因此使用extern关键字
extern的作用
如果一个程序这样写
2
3
4
5
6
7
8
using namespace std;
double PI; //试图声明一个引用,并在main函数之后赋值
int main() {
cout << PI;
return 0;
}
double PI = 3.14;会报错
[注解] 'double PI' previously 被声明于此处.同一个模块中存在多重定义了正确的写法应该是
2
3
4
5
6
7
8
using namespace std;
extern double PI;
int main() {
cout << PI;
return 0;
}
double PI = 3.14;运行结果:
3.14对于函数
2
3
4
5
6
7
8
9
10
11
12
13
using namespace std;
void func();
extern void func();//这两种写法都可以
int main() {
func();
return 0;
}
void func() { //实现
cout << "helloworld";
}
2
extern int open (__const char *__file, int __oflag, ...) __nonnull ((1));
extern double PI;能否写入头文件
既然可以将extern double PI;写入main.c,那么写入geometry.h不一样吗?被main.c引入之后不就相当于在main.c中写了这句吗
这样写可以通过编译链接,感觉上妹有问题,但是用CLion搜索了整个glibc库,所有头文件中都没有这么写,只在configure.in中有这么一句
1 | extern int glibc_conftest_frobozz; |
静态变量
静态变量的作用是,将”全局位置”的变量的访问权限限定在本模块中.
啥意思呢?
point.c
1 |
|
被static修饰的变量即使放在本模块的”全局位置”,也是相对于本模块中的函数而言的”全局位置”
此时如果在main.c中想要使用PI
1 |
|
然而此时会报链接错
1 | ┌──(kali㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] |
static修饰的变量就类似于java和C++中
private修饰的变量只不过static限制模块之间的访问权限
private限制类之间的访问权限这是两种编程范式,模块化编程和面向对象编程
静态库.a
静态库static library实际上是一伙子可重定位目标模块.o的集合
起源
现在假设我们一个工程有成百上千个目标模块.o,
在其中一个目标模块引用了其他若干个目标模块中的符号.
如果引用的其他目标模块不多,尚且看不出问题,只需要gcc main.o module1.o module2. ... -o prog即可完成链接
如果引用的其他目标模块成百上千,那么可以想象到gcc main.o module1.o module2. ... -o prog这条编译命令能有多长
“可以编写makefile完成链接”
即使用makefile,还是存在难以解决的问题
引用的符号在哪个模块里,是在module1.o还是在module2.o?程序员记得住吗?每次编译都要查表吗?
静态库也是可重定位目标文件.o吗?
最容易想到的是,将一些工具性质的,经常被调用的一些目标模块,编译成一个大目标模块.o,注意还是可重定位目标模块.o
当程序员自己写一个源文件test.c并编译成目标模块test.o,其中要用到一些库函数时,只需要将刚才生成的大.o文件链接进来
诚如是,则链接时该包含成千上万函数的大.o文件将会在运行时全部加载进入进程的地址空间,即使test.o只引用到了一个或者几个函数.
这就好比要去图书馆接一本书,却把图书馆整个儿搬回家了
能不能真正像借书一样,用到哪本书拿哪本,用到一个函数就只加载该函数所在的模块?
于是归档文件(archieve).a产生了,即静态库
.o可重定位目标模块可能是静态库.a的组成,也可能是源代码test.c编译后链接前的中间文件.也就是说,.o中有可能有程序的入口点main函数.
.a作为一个库文件,只能起到支持的作用,它就相当于一个服务器被动地给客户端服务.也就是说,只有用户的程序中有入口点,.a是不会主动执行的.直接试图将静态库编译链接为可执行目标文件是不可能的,因为库中没有main函数
使用静态库ar rcs <静态库名>.a <组成目标1>.o <组成目标2>.o ....
举一个比较有实际意义的例子,模拟平面几何中的点和线
工作目录下有五个文件
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] |
geometry.h
1 |
|
这里面的函数声明被分在两个源文件实现,point.c实现有关点计算的函数,line.c实现有关线计算的函数
point.c
1 |
|
line.c
1 |
|
main.c
1 |
|
注意main函数中只用到了和点有关的函数,与线有关的函数一个也妹有用到
下面编写bash脚本进行编译,制作静态库,链接,运行
shellscript.sh
1 | gcc point.c -c -o point.o |
执行该shell脚本
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] |
同时在工作目录下生成了
1 | libgeometry.a |
这么几个文件
现在好奇的是,这个libgeometry.a到底有没有用啥拿啥的功能,也就是说,line.o有没有被链接进入可执行目标文件prog.用ida64打开prog,搜一下function看看newLine函数存不存在即可
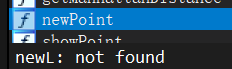
结果证明它不存在,也就是说line.o妹有链接进入prog
还有就是main中妹有用到point.c中的getManhattanDistance函数,它有没有随着point.o一起被链接进入prog呢?
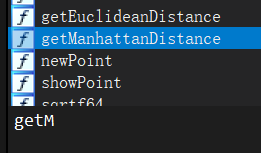
事实上是有的,也就是说,从归档文件.a中用啥拿啥是以模块为单位的,而不是以函数为单位的,
归档文件中的一个模块,不管有多少个函数,只要有其中之一被引用,该模块中的所有函数都会随着该模块链接进入可执行目标文件
.a如何链接
前面章节中符号解析重定位等等都是.o的链接方法.现在对于一个静态库.a,应该如何链接呢?
**1.**当输入gcc f1 f2 ... fn之后,编译器首先将各个源文件编译为可重定位目标文件.o,已经是.o或者.a文件则跳过不编译,得到一个全都是.o或者.a的参数序列
**2.**链接器从左向右扫描这些.o或者.a文件,这两种文件有不同的待遇.
链接器会维护三个集合:
可重定位目标文件集合E
未解析符号集合U(undefined)
已定义符号集合D(defined)
**3.**如果链接器当前扫描到的文件是一个.o,则
本.o文件添加到E集合
本.o文件中的定义放到D集合
本.o文件中的引用放到U集合
**4.**如果链接器当前扫描到的文件是一个.a,则
遍历本.a文件中所有组成模块,寻找U中引用的定义模块,
如果找到则将该模块放到E,将该引用从U中去掉,将定义放到D中
遍历完后本.a文件不再发挥作用
**5.**当链接器扫描完了参数,此时检查U集合是否为空
如果U非空则有未解析的引用,报错
undefined reference如果U为空则连接成功,合并并重定位E中的模块,形成可执行目标文件
链接结束
注意第4条最后的”遍历完后本.a文件不再发挥作用“
这就要求命令行上的参数有顺序了
如果都是.o妹有.a,则所有.o的所有定义和引用都会被放在D和U中,不怕有遗漏的定义
但是如果有.a,则链接器扫描.a时,只负责解析先前存在在U中的引用,后面的目标模块它现在看都不看
比如假如参数序列是这样的:
gcc a.o b.o lib.a c.o其中a,b,c中都有
lib.a中的引用,并且
a.o引用了lib.a中的a模块,
b.o引用了lib.a中的b模块,
c.o引用了lib.a中的c模块,当链接器扫描到
lib.a时,链接器会依据lib.a,解析a.o和b.o中的引用,但是链接器此时并不知道后面还有啥参数,在用lib.a解析了a.o和b.o之后就丢弃了lib.a的其他部分,然后扫描
c.o又有了新的引用,而此时链接器已经扫描到头了,找不到一个能给出定义的模块了链接出错
这样设计虽然会因为顺序问题导致链接出错,但是注意一下或者多写几遍.a就可以克服.并且能够做到尽量少引入目标模块,非用不引.并且时间最优
动态库.so
动态库又叫做共享目标文件
起源
静态库的缺点:
试想现在要同时运行多个进程,每个进程都要调用库函数
printf,按照静态库的链接方法,每个进程的虚拟地址空间都会有一个printf 的拷贝,并且会物理地址空间上建立相应物理页而实际上
printf就是一段只读的代码,给定参数就可以当作黑盒用.就像办公室的打印机,不同的用户只需要给定自己想要打印的材料,用同一台打印机就可以获得不同的输出
在兼容静态库拿啥用啥的思想上,让只读的代码和数据不需要有多份拷贝,一份足矣,这就是动态库的思想.
动态库在运行或加载时,可以加载到任意地址
在linux上动态库后缀.so,在windows上动态库后缀.dll
动态库的链接
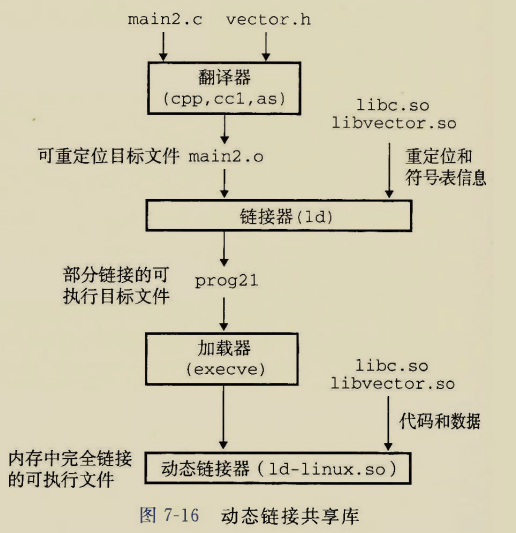
在链接阶段,动态库传递给链接器的只有重定位和符号表信息,并没有让只读代码段参与链接.
啥时候动态库中的只读代码才会参与链接呢?在执行过程中,首次用到了动态库中的引用时,不得不动态加载了,此时动态链接器才会将动态库映射到进程的地址空间,并进行重定位让悬空引用落地
这个过程我没有亲眼见证,都是道听途说,暂且认为它是这样的
为了让不同的进程都能将共享库的物理地址空间映射到自己的虚拟地址空间,有好多种办法
1.物理地址空间为共享库专门留出空间,一个萝卜一个坑,就算妹有萝卜,坑也得留着,其他代码数据都往后稍稍.用到该共享库的时候就一定加载到给他预留的物理地址空间.
缺点是,程序不一定会用到该共享库,或者程序刚开始时只用到该共享库的一小部分代码,共享库只有一小部分加载进入物理地址空间.然后是其他代码,占用了为共享库预留的剩余空间,现在又要调用共享库中的其他代码,这时一开始预留的空间已经被占用,不够用了.又得重新找一个空旷的地方放动态库.这样重复多了,物理地址空间就变得呲离破碎,全是下脚料空间
这可能比静态库还要浪费物理内存,这不就废了吗
2.位置无关代码
动态库可以任意加载进入物理地址空间,由动态链接器完成程序中动态库引用的解析
使用动态库
还是使用静态库时举的geometry的例子
makedynamiclib.sh
1 | gcc -shared -fpic -o libgeometry.so line.c point.c #制作代码位置无关的共享库libgeometry.so |
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/desktop/linkage] |
同时在工作目录下生成了
1 | libgeometry.so |
两个目标文件
使用ida64打开prog观察,发现函数少的可怜
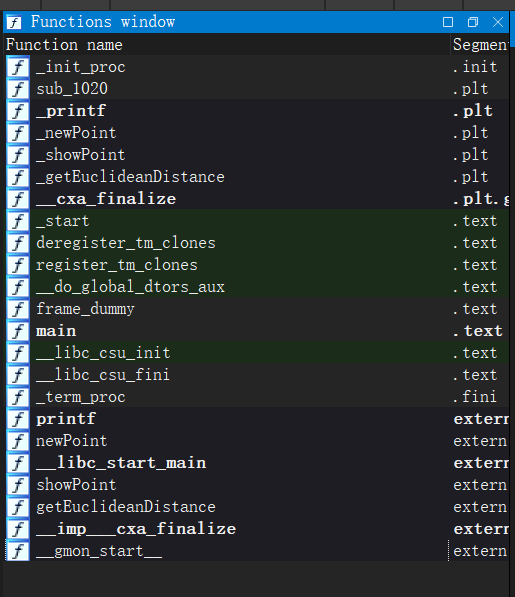
并且可以发现,在point.c中定义的getManhattanDistance并没有被解析.
即,使用动态库时引用解析是以函数为单位的,相对于以模块为单位进行解析的静态库更加灵活
以getEuclideanDistance为例,观察该函数引用是如何被解析的
在main函数中
1 | .text:00000000000011EB call _getEuclideanDistance |
跟踪_getEuclideanDistance
1 | .plt:0000000000001060 _getEuclideanDistance proc near ; CODE XREF: main+82↓p |
跟踪cs:off_4030
1 | .got.plt:0000000000004030 off_4030 dq offset getEuclideanDistance |
跟踪offset getEuclideanDistance
1 | extern:0000000000004078 extrn getEuclideanDistance:near |
此时已经跟踪到头了,点谁都不会跳转了.但是自始至终妹有看见该函数的实现,好像一直在踢皮球
这涉及到位置无关代码PIC的理论
位置无关代码PIC
Position-Independent Code
共享库在编译时要求必须使用位置无关选项-fpic
PIC数据引用
全局偏移量表global offset table,GOT
GOT位于数据段的开始
编译时使用-static选项得到的可执行目标文件中是妹有GOT表的
只有使用位置无关代码的动态链接才会生成GOT表,即使就写一个空壳子main函数啥也不干,什么头文件也不导入,动态链接之后的可执行目标文件也是会有GOT的
GOT表结构:
GOT表项八字节一个,表项内容是引用指向的地址,即一个位置无关代码在运行时的实际地址
为什么是八字节?
八个字节即64位,考虑进程的虚拟地址空间有64位吗?
图片来自Linux内存管理:虚拟地址空间 - 知乎 (zhihu.com)
用户的虚拟地址空间只有48位,从
0x0到0xFFFF FFFF FFFF内核的虚拟地址空间也是48位,从
0xFFFF 0000 0000 0000到0xFFFF FFFF FFFF FFFF
2
3
4
5
6
7
8
9
10
11
12
13
14
15
-----------------------------------------------------------------------
0000000000000000 0000ffffffffffff 256TB user
ffff000000000000 ffff7fffffffffff 128TB kernel logical memory map
ffff800000000000 ffff9fffffffffff 32TB kasan shadow region
ffffa00000000000 ffffa00007ffffff 128MB bpf jit region
ffffa00008000000 ffffa0000fffffff 128MB modules
ffffa00010000000 fffffdffbffeffff ~93TB vmalloc
fffffdffbfff0000 fffffdfffe5f8fff ~998MB [guard region]
fffffdfffe5f9000 fffffdfffe9fffff 4124KB fixed mappings
fffffdfffea00000 fffffdfffebfffff 2MB [guard region]
fffffdfffec00000 fffffdffffbfffff 16MB PCI I/O space
fffffdffffc00000 fffffdffffdfffff 2MB [guard region]
fffffdffffe00000 ffffffffffdfffff 2TB vmemmap
ffffffffffe00000 ffffffffffffffff 2MB [guard region]如果GOT表项可以指向一个内核中的函数或者变量,则显然需要8字节的表项,
如果GOT表项只是指向用户模块中的变量或者函数,则只需要6字节(48位)的表项
因此问题转化为一个进程是否会访问内核
显然是可以的,比如系统调用
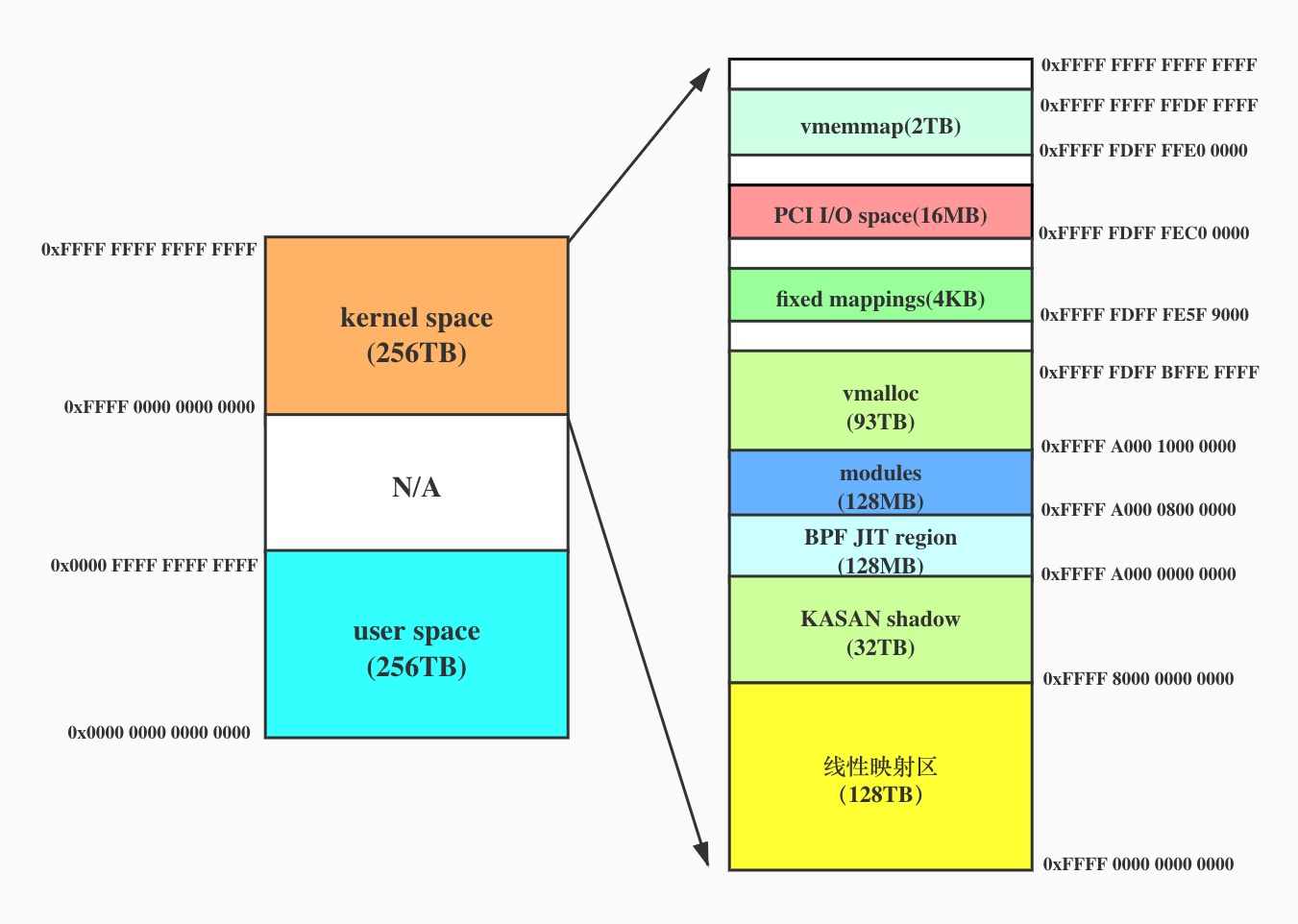
GOT表怎么干活的?
CSAPP上举了这么一个例子

一定时刻记住以下几点:
1.代码段是c源代码经过编译得到的,与链接无关
2.本模块中引用了一个位于其它模块中的符号addcnt,本模块中妹有定义,因此编译器会为其生成一个GOT表项,又从代码段到数据段GOT的跳转需要重定位,因此汇编器会生成一个重定位条目,为静态链接器(相对动态链接器的说法)进行重定位做准备
3.编译阶段是不知道GOT表在哪里的(即使GOT表和代码段在同一模块中),汇编器只会生成重定位条目
4.静态链接阶段才会将代码段中对GOT的引用重定位,
5.静态链接后,在代码段只需要对GOT表的PC相对寻址,在实际运行时,由动态链接器去实际填充该表项应该指向的地址
注意这里有两次引用,一是代码段引用数据段的GOT表,二是GOT表引用其他模块中的符号
GOT表的存在,相当于编译器和静态链接器给动态链接器减轻了负担,动态链接器不需要去代码段找需要解析的引用,只需要看看数据段的开头,就知道哪些引用需要解析
至于动态链接器是个啥,怎么工作的,现在不关心,就当是一个黑盒,它在程序运行阶段发挥作用,结果是给GOT表中的引用找到实际地址,填充到GOT表项
1 | R[%rax]<---R[%rip]+0x2008b9=&GOT[3] //主存中GOT[3]的地址放到rax寄存器中 |
PIC函数调用
GOT和PLT协作
CSAPP教材上给出了看起来不长,却信息量巨大的图文,下面就这一段文字进行解读

·过程链接表(PLT)
1.PLT是一个数组,其中每个条目都是16字节的代码.
PLT表:
2
3
4
5
6
7
.plt:0000000000001020 ; Segment type: Pure code ;段类型:纯代码
.plt:0000000000001020 ; Segment permissions: Read/Execute ;段权限:读/执行/不可写
.plt:0000000000001020 _plt segment para public 'CODE' use64
.plt:0000000000001020 assume cs:_plt ;令cs段寄存器指向plt段
.plt:0000000000001020 ;org 1020h
.plt:0000000000001020 assume es:nothing, ss:nothing, ds:_data, fs:nothing, gs:nothingPLT表的表项16字节一个,表项内容是代码(指令)
比如:
2
3
4
5
6
7
8
.plt:0000000000001030 _isPrime proc near ; CODE XREF: main+D↓p
.plt:0000000000001030 FF 25 E2 2F 00 00 jmp cs:off_4018
.plt:0000000000001030 _isPrime endp
;10字节
.plt:0000000000001036 68 00 00 00 00 push 0
.plt:000000000000103B E9 E0 FF FF FF jmp sub_1020为什么是16字节?
有些指令长,有些指令短,有些plt条目中有多条指令
16字节应该是存在的最长的plt表项
2.PLT[0]是一个特殊条目,它跳转到动态链接器中.
1.动态链接器本身就是一个动态库中的函数,是位置无关代码.因此也需要借助GOT和PLT表跳转.
2.PLT表中不只有用户显示引用的动态库中的函数,还有用户妹有显示引用却不可或缺的动态库函数,比如动态链接器
3.每个被可执行程序调用的库函数都有自己的PLT表条目.每个条目都负责一个具体的函数
不光调用glibc.so动态库中的函数比如printf时有PLT条目,调用自定义的动态库也会有PLT条目
main.c
2
3
4
5
6
7
8
extern int isPrime(int);//isPrime为自定义动态库libfunc.so中的函数
int main(){
int ans=isPrime(510);
printf("%d",ans); //printf为glibc.so中的函数
return 0;
}
func.c
2
3
return a&1;
}制作动态库并链接,执行
2
3
gcc -g main.c ./libfunc.so -O0 -o prog使用ida64打开prog观察反汇编视图
2
3
4
5
6
7
8
.plt:0000000000001030 _printf proc near ; CODE XREF: main+29↓p
.plt:0000000000001030 jmp cs:off_4018
.plt:0000000000001030 _printf endp
...
.plt:0000000000001040 _isPrime proc near ; CODE XREF: main+D↓p
.plt:0000000000001040 jmp cs:off_4020
.plt:0000000000001040 _isPrime endp都生成了plt条目
·全局偏移量表(GOT)
初始时,每个GOT条目都对应PLT条目的第二条指令
这其实不是GOT的特性了
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: bf fe 01 00 00 mov $0x1fe,%edi
d: e8 00 00 00 00 call 12 <main+0x12> //此处call的地址就在下一行啊
12: 89 45 fc mov %eax,-0x4(%rbp)
15: 8b 45 fc mov -0x4(%rbp),%eax
18: 89 c6 mov %eax,%esi
1a: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 21 <main+0x21>
21: 48 89 c7 mov %rax,%rdi
24: b8 00 00 00 00 mov $0x0,%eax
29: e8 00 00 00 00 call 2e <main+0x2e>//此处call的地址就在下一行
2e: b8 00 00 00 00 mov $0x0,%eax
33: c9 leave
34: c3 ret由于编译器和静态链接器不能决定引用函数的具体地址,因此他俩只能摆烂.
动态链接器会把GOT指向的地址修改为动态库函数地址
举个例子
CSAPP举的例子

首次调用addvec
1.callq 0x4005c0 #call addvec()
该指令执行时会将该call指令的后一条指令的地址作为返回时的地址压栈,然后置PC=0x0x4005c0,然后转移控制
2.0x4005c0 jmpq *GOT[4]
这里*GOT[4]不是汇编语言的写法,是编者方便读者理解,使用了C语言中数组的表示方法
这里的意思是,跳转到GOT[4]指向的地址(即GOT[4]表项中存放的地址),而不是跳转到GOT[4]的地址
实际上是这种写法:
2
...间接跳转
在第一次调用addvec时,GOT[4]=0x4005c6即0x4005c0的下一条地址
3.pushq $0x1
CSAPP上对这条指令的解释是”把addvec的ID(0x1)压栈”
啥意思呢?
我的理解是,addvec是用户指定调用的第一条库函数(不包括编译器自己写上的动态链接器等隐式调用的函数),因此把1这个魔数压栈,压栈的目的是作为参数,接下来就要调用动态链接器了,因此传递1作为参数,告诉动态链接器应该动态链接的是用户调用的第一个库函数addvec
4.pushq *GOT[1]
GOT[1]存放的是.reloc节的首地址
联系刚才的push $0x1,可以猜测,.reloc是一个表,每一个表项对应一个需要重定位的库函数,其中第一条就是addvec的表项,然后动态链接器要用这个0x1去查.reloc表
5.jmpq *GOT[2]
GOT[2]存放的是动态链接器的地址,
用jmpq GOT[2]会跳转到GOT[2],啥也不会发生
用jmpq *GOT[2]会跳转到GOT[2]的内容,也就是动态链接器的地址
为啥不用call指令调用,却用jmpq直接跳转到函数的开始呢?
call指令需要将跳转前的下一条指令压栈作为返回地址,返回地址将会覆盖栈顶上用于动态链接器的参数.
而jmpq直接跳转到动态链接器,栈顶此时就是他要使用的参数
6.动态链接器会确定.reloc表中第一个库函数即addvec的运行时地址,然后用该地址改写GOT[4]
具体怎么查的addvec运行时地址,怎么改写的GOT[4],那是后话了,现在当成黑盒子用
7.动态链接器将控制交给addvec,此时才开始真正执行call addvec
第二次调用addvec
由于第一次调用addvec时,动态链接器已经将GOT[4]改写为正确的addvec运行时地址,现在调用就不会在请动态链接器出马了
在jmpq *GOT[4]之后就跳转到了addvec的首地址
这里不用call的原因是,这里就是想把控制交给addvec,不需要记录PLT表中的返回地址
在主函数调用addvec时已经call addvec了
这有点类似于记忆化搜索
记忆数组对应GOT表
搜索函数对应动态链接器
第一次搜索前记忆数组都是空的,对应GOT表返回地址不正确
搜索到之后搜素函数会改写记忆数组相应元素,对应动态链接器会修改GOT表项为函数运行时地址
第二次搜索时如果记忆数组不为空则直接使用数组内容,不调用搜索函数,对应第二次调用函数时直接根据GOT表跳转
库打桩
打桩:打桩,指把桩打进地里,使建筑物基础坚固。–百度百科
很纳闷为什么library interpositioning要翻译成打桩
library interpositioning 库 插入
就是程序本来应该调用一个库函数却被劫持调用一个包装函数或者其他逻辑的函数.甚至不如叫”库劫持”更直观
预编译时打桩
使用宏定义劫持库函数
main.c
1 |
|
如果只是有这么一个main.c文件, 用gcc main.c -o main命令,编译链接之后所有都按部就班地发生,真正调用glibc库的malloc函数申请堆内存
下面给他劫持喽
malloc.h
注意本头文件和库函数malloc声明所在的头文件malloc.h同名
1 |
|
mymalloc.c
1 |
|
命令:
1 | gcc -c mymalloc.c |
gcc搜索头文件的规则
当#include <headerfile.h> 时,编译时按照”
编译命令指定目录--->系统预设目录--->编译器预设“的顺序搜索头文件。当#include “headerfile.h”,编译时按照”
源文件当前目录--->编译命令指定目录--->系统预设目录--->编译器预设“的顺序搜索头文件。我们在使用glibc库函数时一般使用
<malloc.h>,在不加编译命令时,编译器根本不会在当前工作目录下搜索这种尖括号头文件而我们现在就想给他劫持到搜索当前工作目录,这就是编译时打桩
怎么实现这个头文件劫持呢?编译时加入
-I选项,意思是告诉编译器,在搜索系统预设目录前,先按照编译命令指定目录(-I.这里的点号.就是当前目录)搜索头文件.当前文件夹下恰好有我们自己写的同名头文件malloc.h,只要能找到,编译器就不会再在其他目录找这个头文件
然后在链接时需要给出我们自己写的
malloc.h中的两个函数引用mymalloc和myfree,这就是mymalloc.c要做的事情了
运行结果:
1 | malloc啥也不干malloc啥也不干 |
实际上glibc中的malloc从未被调用过
总结预编译时打桩的步骤:
1.修改库函数头文件搜索位置
2.链接新的实现
但是吧,PWN的题目都是给出一个已经编译链接完成的可执行目标文件.谁会让你在预编译阶段做手脚呢?
只能说,没用的知识又怎加了
链接时打桩
main.c
1 |
|
此时main.c看起来还是非常正常的,使用gcc main.c -o main可以编译链接得到一个正儿八经的程序
下面用链接时打桩给他劫持喽
mymalloc.c
1 |
|
为啥函数名前面要假设__real,__wrap这种前缀?
命令
shellscript.sh
1 | gcc -c mymalloc.c |
comma-separated 用逗号分开的
给链接器传递用逗号分开的<选项>
--wrap,malloc的作用是,链接器将malloc这个符号解析为__wrap_malloc这个符号,并且将__real_malloc这个符号解析为malloc那么在
main.c中调用malloc时会被链接器重定位到__wrap_malloc的定义,真正的glibc库中的
malloc需要使用__real_malloc调用
运行结果:
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/link] |
同样的道理,CTF题也不会让在链接阶段办手续,又是没用的知识
运行时打桩
运行时加载链接共享库
Linux系统为动态链接器提供的系统调用:]
dlopen
1 |
|
加载链接共享库filename
flag参数值含义:
RTLD_GLOBAL用其他用该选项打开的库解析filename库中的外部符号
RTLD_NOW,链接器立刻解析外部符号引用
RTLD_LAZY,链接器不得不解析外部符号时才进行解析
dlsym
1 |
|
handle是dlopen的返回值,即指向共享库句柄的指针
symbol是handle指向的共享库中的符号,比如一个全局变量或者一个符号
如果存在则返回该symbol的地址,否则返回NULL
dlclose
1 |
|
卸载handle指向的共享库
dlerror
1 |
|
返回字符串,内容是最近调用前面三个函数时发生的错误,如果妹有错误则返回NULL
举个例子
由于gcc会隐式加载链接glibc.so库,我们需要自己写一个动态库,比如geometry
geometry.h
2
3
4
5
6
7
8
9
10
11
12
typedef struct{
double x;
double y;
}Point;
double getEuclideanDistance(Point,Point); //计算两点之间的欧几里得距离
double getManhattanDistance(Point,Point); //计算两点之间的曼哈顿距离
Point newPoint(double,double); //构造新点
void showPoint(Point); //打印点坐标
geometry.c
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
static const double PI=3.1415926;
double getEuclideanDistance(Point a,Point b){
return sqrt((a.x-b.x)*(a.x-b.x)+(a.y-b.y)*(a.y-b.y));
}
double getManhattanDistance(Point a,Point b){
return abs(a.x-b.x)+abs(a.y-b.y);
}
Point newPoint(double x,double y){
Point a;
a.x=x;
a.y=y;
return a;
}
void showPoint(Point p){
printf("(%.2f,%.2f)",p.x,p.y);
}编译成动态库
libgeometry.so
main.c
1 |
|
声明一个返回值为Point类型,双参数都是double类型的函数指针
编译命令:
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/runtimelink] |
-rdynamic 却是一个 连接选项 ,它将指示连接器把所有符号(而不仅仅只是程序已使用到的外部符号)都添加到动态符号表(即.dynsym表)里,以便那些通过 dlopen() 或 backtrace() (这一系列函数使用.dynsym表内符号)这样的函数使用。
添加-rdynamic选项后,.dynsym表就包含了所有的符号,不仅是已使用到的外部动态符号,还包括本程序内定义的符号,比如bar、foo、baz等。
参考博客gcc或g++的编译选项 -shared -fPIC 与 -g -rdynamic 部分转载_字正腔圆的博客-CSDN博客_rdynamic
-ldl的作用是链接dlfcn库,是我们能够使用dlopen这种函数
运行结果
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/runtimelink] |
运行时打桩
运行时打桩的思想是,自己写一个家的malloc函数,该函数使用dlopen等函数在运行时加载glibc
奇怪,我按照CSAPP的说法做的实验,结果会报告段错误,留作后话吧