CSAPP-chapter12 线程并发
线程模型
引入线程概念之后,进程的职能只剩下组织资源.线程负责程序的执行
同一个进程的线程之间有共享也有私有资源
线程私有资源:
1.线程ID,tid
2.线程栈及其栈顶指针
3.程序计数器PC,rip
4.程序状态字PSW,flags
5.通用目的寄存器
上述五个合起来叫做 线程上下文
线程共享资源
进程用户虚拟地址空间中除了线程栈的其他部分
1.堆
2.只读代码段
3.全局变量区,.data,.bss
4.共享库
5.打开的文件
实际上同一个进程的各个线程栈之间不设防,即可以通过全局变量指针等方法,使得一个线程可以访问修改另一个线程的栈空间
线程的特点
每个进程执行伊始都是单一线程的,即主线程
从主线程创建的其他线程或者其他线程创建的线程都是对等线程
即一个进程的所有线程都是对等线程.一个进程的线程之间没有父子关系一说.所有线程组成一个线程池.任何一个线程都可以杀死任何一个对等线程.
POSIX线程
POSIX:可移植操作系统接口
线程概念落地实现,后面的实验都基于POSIX线程
源代码可以去看glibc库
在使用POSIX线程库函数时,需要动态链接libpthread.so库,因为gcc不会自动链接该库
比如gcc main.c -lpthread -o main
线程例程
线程是程序的一次执行,更准确的说法是函数的一次执行
线程的代码和局部数据被封装在一个函数中,如果只是从main函数中像以前一样调用改函数,则该函数就是一个普通函数.如果在main函数中创建一个新线程,让该新线程去执行该函数,则该函数此时就是”线程例程”
线程的使用方法与进程大不相同,多进程时,fork之后立刻产生新进程,用起来总是感觉别扭,区分不同的进程甚至需要在进程内部使用getpid等函数获得pid然后进行条件判断.
线程的使用是基于函数的,让一个线程去执行一个函数,使用更加自然.
线程句柄pthread_t
glibc-2.9\nptl\sysdeps\unix\sysv\linux\alpha\bits\pthreadtypes.h
1 | typedef unsigned long int pthread_t; |
线程标识符,本质为无符号长整形unsigned long
pthread_t tid;用于保存线程tid
获取当前线程id,pthread_self
main.c
1 |
|
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/desktop/pthread] |
每次运行,tid都是不同的数值,但是main和func两个函数中打印的tid都是相同的
因为func不是新线程执行的,它仍然是main线程执行的.
创建线程pthread_create
pthread.h
1 | /* Create a new thread, starting with execution of START-ROUTINE |
创建一个新线程,从
START_ROUTINE函数,带着ARG参数 开始执行.线程函数的参数只能有一个,是一个
以参数ATTR为线程属性
新的线程句柄以参数NEWTHREAD返回
如果创建新线程成功则函数返回0,否则返回数字代表错误原因
关于参数的
__restrict修饰符
__restrictLike the
__declspec(restrict) modifier, the__restrictkeyword (two leading underscores ‘_’) indicates that a symbol isn’t aliased in the current scope类似于
__declspec修饰符,__restrict关键字(两个下划线作为前缀),指明本符号在当前作用域内没有别名C/C++关键字之restrict - 知乎 (zhihu.com)
restrict关键字用于修饰指针(C99标准)。
通过加上restrict关键字,编程者可提示编译器:在该指针的生命周期内,其指向的对象不会被别的指针所引用
关于函数属性的
__nonull修饰符Function Attributes - Using the GNU Compiler Collection (GCC)
The
nonnullattribute specifies that some function parameters should be non-null pointers. For instance, the declaration:nonnull 属性表明,一些函数参数应该是非空指针.比如:
2
3
4
my_memcpy (void *dest, const void *src, size_t len)
__attribute__((nonnull (1, 2)));
causes the compiler to check that, in calls to
my_memcpy, arguments dest and src are non-null. If the compiler determines that a null pointer is passed in an argument slot marked as non-null, and the -Wnonnull option is enabled, a warning is issued. The compiler may also choose to make optimizations based on the knowledge that certain function arguments will not be null.
__attribute__((nonnull (1, 2)))将会让编译器检查,对于函数my_memcpy,第一个参数dest和第二个参数src应该是非空指针.如果编译器发现一个被标记为非空的参数实际上传了一个空指针,并且-Wnonnull 编译选项开启,那么编译器将会警告.
编译器还可能根据参数被修饰为非空进行一些优化
If no argument index list is given to the
nonnullattribute, all pointer arguments are marked as non-null.如果没有给nonnull属性指明参数下标表,那么所有函数参数都将被标记为非空.
main.c
2
3
4
5
6
void __attribute__((nonnull)) func(char *s){}
int main(){
func(NULL); //传递空指针作为参数
return 0;
}
2
3
4
5
6
7
8
└─# gcc main.c -Wall -o main #-Wall开启所有警告
main.c: In function ‘main’:
main.c:4:5: warning: argument 1 null where non-null expected [-Wnonnull]
4 | func(NULL);
| ^~~~
main.c:2:31: note: in a call to function ‘func’ declared ‘nonnull’
2 | void __attribute__((nonnull)) func(char *s){}编译警告func的参数应该非空
关于函数属性
__THROW修饰符
The
nothrowattribute is used to inform the compiler that a function cannot throw an exception. For example, most functions in the standard C library can be guaranteed not to throw an exception with the notable exceptions ofqsortandbsearchthat take function pointer arguments. Thenothrowattribute is not implemented in GCC versions earlier than 3.3.nothrow属性用来通知编译器,函数不会抛出异常
比如,C标准库中的大多数函数都保证不会抛出qsort和bsearch使用函数指针作为参数的错误;
在GCC3.3之前没有该属性
Calls to external functions with this attribute must return to the current compilation unit only by return or by exception handling. In particular, leaf functions are not allowed to call callback function passed to it from the current compilation unit or directly call functions exported by the unit or longjmp into the unit. Leaf function might still call functions from other compilation units and thus they are not necessarily leaf in the sense that they contain no function calls at all.
The attribute is intended for library functions to improve dataflow analysis. The compiler takes the hint that any data not escaping the current compilation unit can not be used or modified by the leaf function. For example, the
sinfunction is a leaf function, butqsortis not.Note that leaf functions might invoke signals and signal handlers might be defined in the current compilation unit and use static variables. The only compliant way to write such a signal handler is to declare such variables
volatile.The attribute has no effect on functions defined within the current compilation unit. This is to allow easy merging of multiple compilation units into one, for example, by using the link time optimization. For this reason the attribute is not allowed on types to annotate indirect calls.
总之表示声明为leaf的函数不会调用其他函数
综上,pthread_create函数要求,第一个参数tid,第三个参数,例程函数指针非空.四个参数指针指向的内容在本线程执行过程中不能被其他线程引用.pthread_create函数不会抛出异常,pthread_create函数只会调用例程函数,不会调用其他函数(至于例程函数会不会调用其他函数我不管)
1 |
|
1 | ┌──(root㉿Executor)-[/mnt/c/Users/86135/desktop/pthread] |
func和main函数所在的线程id确实不同了
终止线程pthread_exit
线程的终止方式有两种:
一是顶层线程例程return,隐式终止
“顶层线程例程”的意思是,
线程例程是一个函数,该函数可以调用其他函数,这些被调用的函数也属于本线程,但是最高层的那个函数(也就是pthread_create时指定的函数)返回时才算线程的结束
二是显示使用pthread_exit函数结束
如果main函数所在的主线程使用
pthread_exit,则主线程会等待所有对等线程终止之后才会终止主线程和整个进程
线程函数的返回值怎么让其他线程知道呢?
比如main线程创建了一个对等线程去执行func函数,假设func函数有返回值,怎么让main知道这个返回值呢?
使用pthread_exit函数解决
1 | /* Terminate calling thread. |
终止线程
清理程序以异常处理进行,因此我们不能将该函数标记为
__THROW
返回值通过指针参数void *__retval传递
杀死对等线程pthread_cancel
1 | /* Cancel THREAD immediately or at the next possibility. */ |
CSAPP:马上终止线程”或者下一个可能的时候”?没使用过该函数
main.c
1 |
|
运行结果:
1 | ┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/pthread] |
前两次运行没等对等线程开始执行,main线程就将其杀掉了
第三次对等线程执行到i=167左右时,main线程执行到pthread_cancel(tid)将对等线程杀掉了
杀死全部对等进程exit
如果有一个对等线程调用exit函数,则立刻杀死所有对等线程并终止进程
1 |
|
1 | ┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/pthread] |
由于对等线程提前执行exit,此时主线程还没有来得及打印printf("main exit\n");进程就结束了
回收已终止线程资源pthread_join
1 | /* Make calling thread wait for termination of the thread TH. The |
使调用线程等待TH线程的结束
如果指定了
__thread_return参数并且不为空,则使用_thread_return参数承接TH线程的退出状态该函数是一个取消点,因此不用
__THROW标记
1 |
|
1 | ┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/pthread] |
在pthread_join(tid,NULL)处,主线程会等待tid线程结束然后继续执行
后来又创建了线程但是没有等待它结束,主线程率先结束,相当于调用了exit函数,直接结束了所有对等线程,因此后来的对等线程没有执行func中的printf
分离线程pthread_detach
一个线程在创建之后,其相对于对等线程
1.可结合的(joinable)
2.分离的(detached)
注意两种状态的叫法
一个是”可”结合的,而不是说”结合的”,因为结合的意思是被对等进程使用
pthread_join回收掉了“分离的”意思是已经分离,原来的对等线程无法管理它
1 | /* Indicate that the thread TH is never to be joined with PTHREAD_JOIN. |
pthread_detach函数表明,TH线程将永远不会”加入”调用线程因此当TH线程结束时,其资源将会被立刻回收,而不必再等待被对等线程调用
pthread_join回收
初始化线程pthread_once
1 | /* Guarantee that the initialization function INIT_ROUTINE will be called |
初始化线程例程的相关状态
具体作用目前未知
单处理器机器上多线程同步问题
变量在内存中的位置
| 变量类型 | 共享情况 |
|---|---|
| 全局变量或者全局位置的静态变量 | 共享 |
| 线程函数内静态变量 | 共享 |
| 线程函数内的普通局部变量 | 不共享 |
1 |
|
1 | ┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/pthread] |
结果表明&global都是同一个地址,&static_in_func都是同一个地址,&local_in_func是每个线程各有一个地址
同步错误
1 |
|
在单核ubuntu虚拟机上的运行结果

指定命令行参数为1e8则期望的cnt应该被两个线程轮流增加直到2e8,但是实际上cnt=142026321或者153306108甚至两次执行结果都不一样
为什么会发生这种事情呢?
反汇编观察func函数
1 | .text:080484B0 assume cs:_text |
注意这迷人的三句话让男人给我花了十八万
1 | .text:0804857B mov eax, ds:cnt ; 三句话,让位于ds段的cnt加个1 |
假设,现在cnt=10,
线程1执行了.text:0804857B mov eax, ds:cnt之后歇逼了(时间片用完了,发生调度,属于概率事件),保存好线程上下文(包括eax寄存器,保存的eax值为eax=10),然后控制交给线程2
线程2也执行了.text:0804857B mov eax, ds:cnt,之后线程2没有歇逼,又执行完了下面两句话,把三句话说全了,然后歇逼,控制交给线程1
此时cnt=11
线程1恢复了上下文,eax=10,然后执行剩下的两句话
1 | .text:08048580 add eax, 1 ;eax=11 |
执行完了之后发现cnt=11
刚才已经等于11了,这一波操作之后还是11,相当于线程1啥也没干,失去一次增加cnt的机会
如果线程1完全执行完了才执行线程2,自然不会有上述错误
发生错误的原因是,两个线程有机会同时访问修改共享变量(一个躺在共享变量上睡觉,另一个修改共享变量)
那么解决方法也是显然的,让共享变量某一时刻只能被一个线程访问.
这种可能被多个线程访问的共享变量叫做”临界区“,怎样解决单处理机上的同步错误呢?使用信号量
进程图
刚才发生的同步错误,用进程图描述更加直观
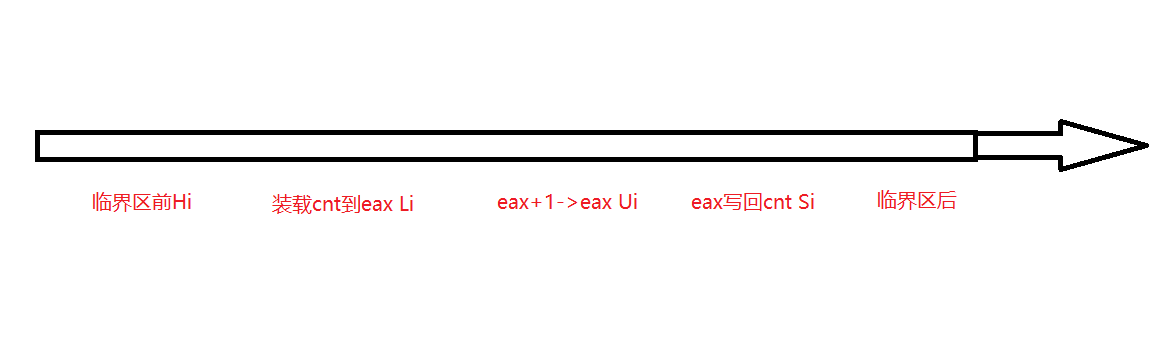
func干的事情可以描述为这么几部分:
1 | 临界区前 Hi |
分别编上号,角标i表示线程i
那么一个线程的执行过程可以用数轴表示,正方向表示时间推移
那么两个线程并发执行过程可以用二维坐标系表示,x轴和y轴各表示一个线程的时间轴
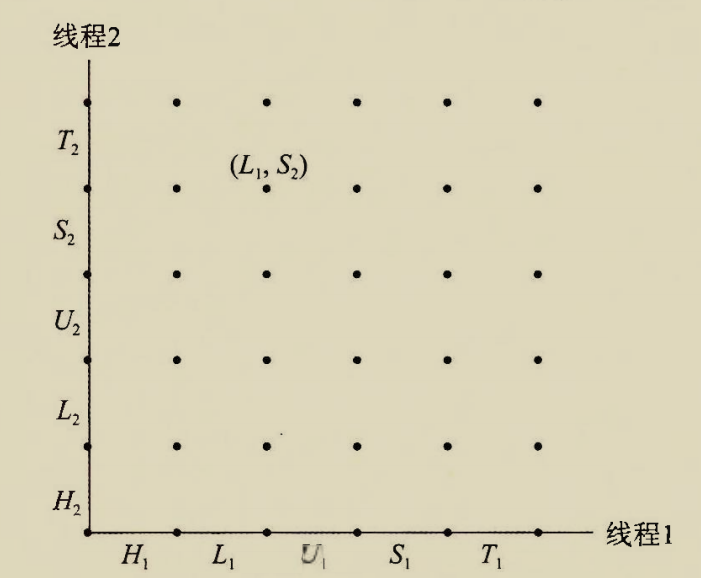
其中节点均表示两个线程完成某些步骤之后的状态,线段表示状态转移
在临界区中的状态标记为危险区
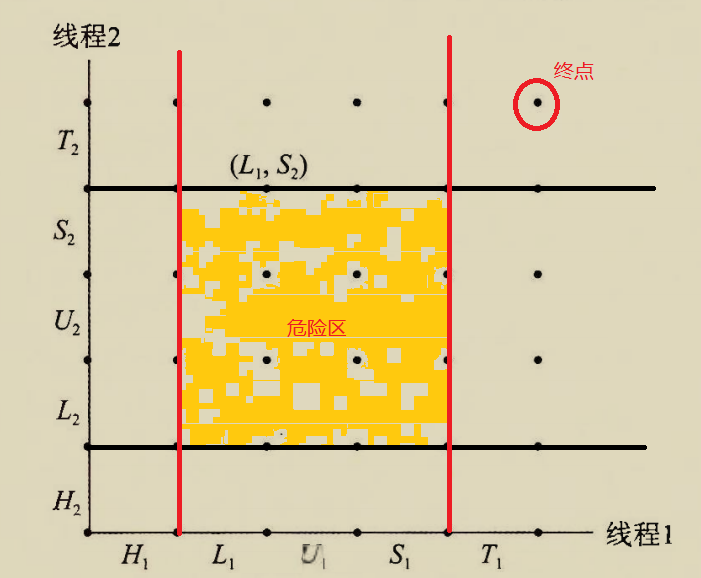
危险区的意思是,两个线程同时访问临界区
要状态转移到终点位置并且不能经过危险区,贴着危险区的边走也是可以的
信号量
semaphore
信号量是非负整数值的全局变量,只能由两种特殊操作来处理,P(proberen测试)操作和V(verhogen增加)操作

P和V中的操作都是一条龙,不允许中断
P和V保证信号量是一个非负值,这个性质叫做”信号量不变性”
Posix接口
sem_t
信号量的定义
/bits/semaphore.h
1 |
|
sem_t是一个32字节的字符数组和长整型的联合体
初始化信号量sem_init
semaphore.h
1 | /* Initialize semaphore object SEM to VALUE. If PSHARED then share it |
信号量以指针sem_t *__sem传参,
int __pshared总是0,
unsigend int __value表示信号量的初始值(最大值)
PV操作sem_wait&sem_post
1 | /* Wait for SEM being posted. |
其中
sem_wait相当于P操作
sem_post相当于V操作
信号量实现互斥
信号量,互斥锁的区别
每个共享变量与一个信号量s联系起来,当线程访问共享变量时,用sem_wait(&s)和sem_post(&s)包裹访问临界区的操作.
如果这样用信号量则s的值要么是0(表示临界区没有被访问)要么是1(表示已经有线程在临界区中睡觉或者执行了)
由于s的值只有两种因此s又叫做”二元信号量binary semaphore“
用于临界区互斥的二元信号量叫做”互斥锁mutex“
信号量还可以统计资源数量
比如某种设备有8个,就用s=8表示该种资源的最大值,这种用法的信号量叫做”计数信号量“
信号量解决同步错误
还是同步错误时的例子,用信号量应该这样修改
1 |
|
关键步骤
1 | sem_wait(&mutex);//进入临界区之前首先访问并修改互斥锁 |
举个例子推导互斥锁的工作原理
假设线程1在访问临界区cnt时睡觉了,此时线程1已经执行过
sem_wait(&mutex),这是一个一条龙操作,即保证一旦线程1开始执行sem_wait(&mutex)则线程1对cpu的控制至少要持续到该操作结束.
sem_wait(&mutex)之后,mutex=0,表征当前临界区中已有线程访问.那么线程2会在
sem_wait(&mutex)这一步等待,直到线程1释放互斥锁
在单处理器机器(虚拟机给一个只有一个核的处理器)上的运行结果:

治好了老咳喘
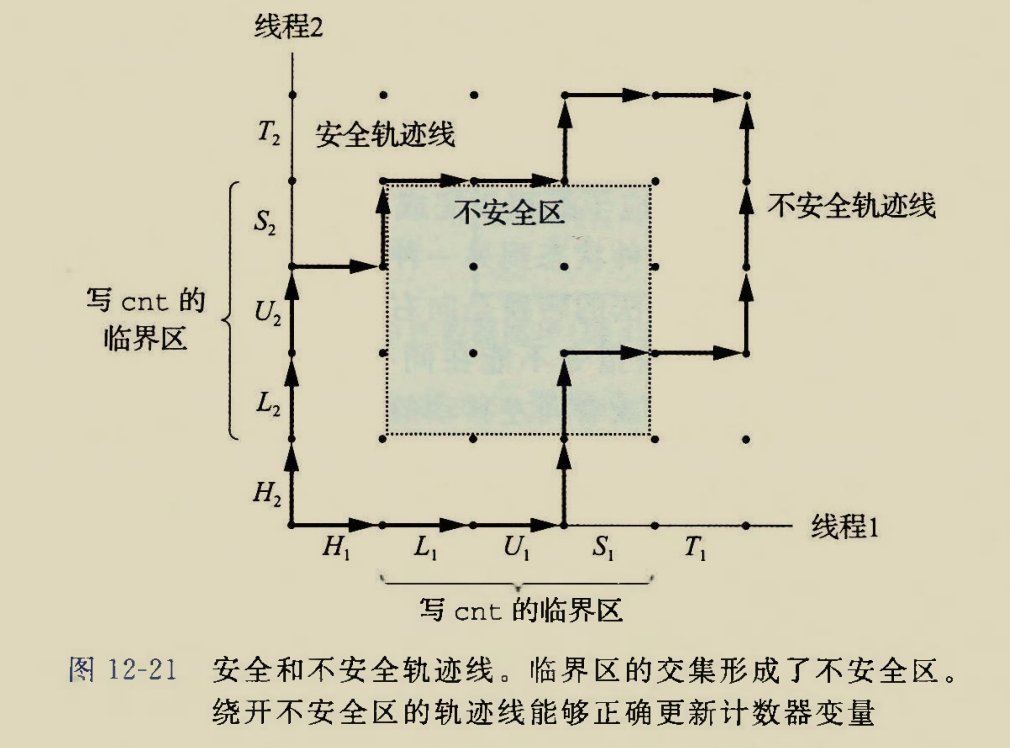
使用信号量(互斥锁)之后的进程图
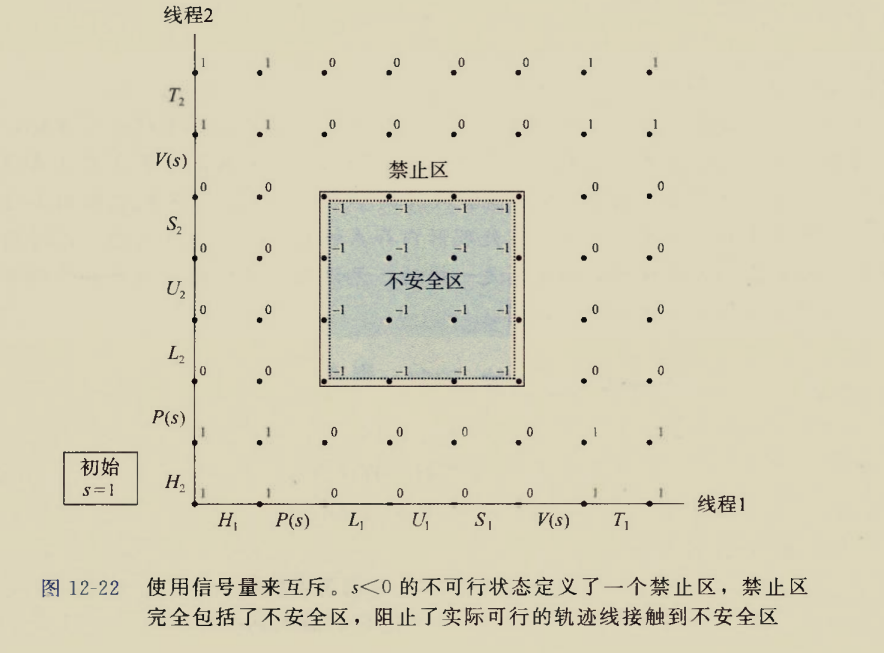
刚才我们分析过,贴着不安全区的边也是可以的,但是使用信号量解决互斥问题时,贴着不安全区的边也不行.因为临界区中的状态点处互斥锁值为-1,表示两个线程都获得了互斥锁,这意味着
sem_wait(&mutex)可以被两个线程”同时”执行,
这意味着其中一个线程首先执行sem_wait(&mutex)到一半的时候睡觉了,轮到另一个线程执行sem_wait(&mutex)
而sem_wait(&mutex)被实现为一个不可中断的一条龙操作
因此不可能出现mutex=-1的情况
经典IPC问题
哲学家就餐问题(还没想明白)
要我说,都饿死才好,thus我就不用考一个67分的马原儿了
说了这么一个事情
五个憨批哲学家在一起吃面条子,圆桌子上只有五根儿筷子.人要吃饭的时候要用两根筷子.人不吃饭的时候要么在胡思乱想,要么在挨饿.
哲学家的三种状态:
1.进食,正在占用左右的筷子
2.思考,进食完毕之后立刻放下筷子,思考,思考状态不需要进食
3.饥饿,思考完毕之后立刻进入饥饿状态,一旦条件允许应立刻进食
哲学家会做的事情:
1.首先思考
2.获得桌面控制权mutex锁,这个控制权某时刻只允许做多由一个人掌控.如果获得不了则在mutex的等待队列挂着.
这里mutex的作用是只允许某时刻桌子上有一个人放下或者拿起筷子
3.获得mutex之后,立刻设置自己为饥饿状态
4.检查左右是否有人在吃饭,如果有则自己不能吃.否则设置自己的状态为进食,并且给
不管有没有吃到饭,检查一次就立刻放开mutex锁
5.如果第4步
2.然后设置自己为饥饿状态
3.检查左右是否有人进食,如果有则说明自己的筷子不够,保持饥饿状态,放权
怎么安排让吃饭不打架并且让效率最高呢?
假算法
2
3
4
5
6
7
8
9
10
11
void philosopher(int i){
while(1){
think();
take_fork(i);//线程不安全的take_fork函数
take_fork((i+1)%N);
eat();
put_fork(i);
put_fork((i+1)%N);
}
}显然是存在同步问题的,三号线程执行
take_fork(3)和二号线程执行take_fork(3)是存在线程同步问题的.有可能被同时执行,这就相当于一根筷子被两个人拿着改进
方便安排期间,整个桌子看成一个大临界区,某一时刻只允许一个哲学家进食.用一个互斥锁
mutex就可以实现
2
3
4
5
6
7
8
9
10
11
void* philosopher(void*para){
int i=*(int*)para;
while(1){
think();
sem_wait(&mutex);//桌子上锁
eat();
sem_post(&mutex);//桌子下锁
}
}可是这时候桌子上无根筷子的拜访就没有意义了,反正只允许一个哲学家进食,他想用哪根就用哪根
这样可以保证不打架,但是实际上5根筷子最多允许同一时刻两个哲学家进食,因此这种方法的并行性并不好
生产者消费者问题
生产者线程和消费者线程共享一个n个槽的有限缓冲区,生产者反复产生新的项目并将其插入缓冲区中.
消费者不断从缓冲区按照FIFO规则取出这些项目,然后消费之
缓冲区用一个大小为n的int型队列表示,每个int表示一个空槽
那么可以实现一个队列,push相当于生产者动作,pop是消费者动作.用信号量保证互斥问题
缓冲区数据结构
1 |
|
函数实现
1 |
|
测试非同步队列
1 |
|

如果queue是线程同步的,一定不会出现两个相同的length
出现这种情况的原因是
1 | void push(Queue* this,int x){ |
length=90时
线程1取得this->rear并放到寄存器之后并没有立刻自增写回,而是在此时睡觉,
导致线程2也取得和线程1相同的this->rear放到寄存器,
线程2将寄存器中的this->rear快照自增后写回到临界区buf中,此时length=91,线程2打印91
线程1醒了,其睡觉前保存的线程上下文中this->rear是一开始的状态,线程1也将寄存器中的this->rear快照自增然后写回临界区buf,此时length=91,线程1打印91
这时两个线程对寄存器中this->rear的快照自增然后写回,实际上写到了buf的同一位置,并且导致this->rear只增加了1
测试同步队列
1 |
|
用同步队列就不会有刚才的错误
多个信号量?
在Safe_Queue的push函数的实现中用到了多个信号量
1 | void safe_push(Safe_Queue* this,int x){ |
为什么不能直接写成
1 | void safe_push(Safe_Queue* this,int x){ |
这样只考虑了临界区有没有线程在访问,没有考虑临界区还有没有空槽,如果临界区都写满了,即使没有线程在临界区中,也不应该继续写入
那为啥记录空槽数要用信号量?用一个普通的整数变量不可以吗?
即
1 | void safe_push(Safe_Queue* this,int x){ |
假设cnt_unused=1,
此时while(!cnt_unused);完全有可能被两个线程同时判定失效,跳过循环,执行--cnt_unused;,导致cnt_unused=0或者-1
显然空槽数量为一个非负数,这是不合法的
因此要限制某时刻最多只有一个线程访问cnt_unused,因此用信号量实现
读者写者问题
同一个文件(或者说共享变量,临界区)被两种性质的线程访问:
只读线程:该种线程只是读取共享变量,不做修改
读写线程:该种线程会修改共享变量
显然共享变量允许被多个线程观摩但是只能允许同一时刻被一个线程修改.在被修改的时候不允许被其他任何读或者写的线程访问.
还要考虑一个读和写优先级的问题
如果读优先
如果当前有只读线程正在访问临界区,则后来的只读线程无需等待,直接进入临界区
如果当前有只读线程正在访问临界区,则后来的读写线程需要等待所有的只读线程读取完毕,临界区没有任何线程时才能进入临界区.即使在等待前面的只读线程时被后面的只读线程插队并被迫增加等待时间也没办法
如果当前有读写线程正在访问临界区,则当其读写完毕之后,首先允许只读线程进入临界区,如果没有只读线程才会允许读写线程进入临界区
如果写优先
如果当前有只读线程正在访问临界区,当其读完毕后首先允许读写线程进入临界区,如果没有读写线程在排队才会允许只读线程进入临界区
如果当前读写线程正在访问临界区,当其写完毕退出临界区后,立即允许下一个读写线程进入临界区,如果没有读写线程在排队,才会允许读线程进入临界区
读优先
1 |
|
作家
1 | sem_wait(&w); |
w是一个针对作家的互斥锁,不光读者用w来排挤作家,作家也用w排挤作家
当w为0的时候作家打死也不允许进入临界区.
读者和作家都有权力修改w的值,
作家修改w避免其他作家进入临界区这个好理解,就是防止同一个临界区有两个作家打架
当有一个读者进入临界区时就会修改w为0,此时只允许其他读者进入临界区,不允许作家进入
当最后一个读者退出临界区时才会放开w=1,允许卑微的作家进入临界区
读者
1 | sem_wait(&mutex);//此处上锁的作用是,要修改cnt_reader的值和作家的锁 |
读者有两次关于mutex的上锁和开锁,其作用可以举一个例子进行类比
坐地铁时我们要刷卡或者刷二维码过闸机,每次只允许一个人刷卡过闸机,一人一杆,过了闸机就意味着有权力做地铁了,
++cnt_reader就相当于把自己放到了地铁上这里的mutex就起到了闸机的作用,限制读线程一个一个修改
cnt_reader,防止两个线程同时修改cnt_reader但是最终cnt_reader只增加了1这种情况.更直观的,如果不用mutex锁
2
3
4
5
6
7
8
9
10
11
12
13
if(cnt_reader==1){//第一位进入临界区的读者
sem_wait(&w);//给作家上锁,不让作家进来胡扯
}
do_read();//读取临界区
//走的时候也是闸机限流,一人一杆
--cnt_reader;
if(cnt_reader==0){
sem_post(&w);
}线程1将
cnt_reader放到寄存器中还没来得及将自增写回到cnt_reader就睡了一觉,线程2读取到的是线程1写回之前的cnt_reader,两个线程读取到了相同的cnt_reader,自增后写回的也是相同的cnt_reader,导致两个线程同时挤进临界区但是读者计数器只增加了1
这种情况下写者可能用数量灌死读者,让读者永远没有读的机会
试想如果只有一个读者线程,成百上千个写者线程,假设读者线程首先进入临界区,此时读者持有w锁,这使得所有写者无能狂怒,均卡在sem_wait(&w);这个位置
然后读者终于出了临界区,释放了w锁,此时在等待w锁的写者1已经成百上千,其中有一个幸运儿被选中获得了w锁进入临界区,这又使得剩下的写者和这一个读者无能狂怒,都卡在sem_wait(&w);这个位置
当写者1写完出了临界区,他释放了w锁,此时w锁的等待队列中有成百上千的写者和一个读者.但是sem_wait(&w);并不知道是读者还是写者在等待w,它会随便挑一个正在等待w的线程分配w锁.
显然一个读者是抢不过成千上万个写者的.
这个可怜的读者只有很小的几率能够进入临界区去读这些作家的著作了
但是只要读者数量多点儿,稍微有点儿规模就没有作家的事了
读者1进入临界区之后给所有读者开了绿色通道,读者鱼贯而入,当首先进入临界区的读者1出了临界区时,还会有读者2守着临界区的大门不让作家进来.
甚至当读者1兜兜转转又站在临界区大门口时,临界区中还有读者n把这门.如此形成一道密不透风的墙,作家永远没有进入临界区的机会
这让我想到保卫萝卜中用冰花阵一直冻住怪物直到刮痧刮死
冰花绽放的一秒相当于读者持有w锁,冰花凋谢相当于读者释放w锁
冰花的cd相当于读者本次出了临界区到下一次进入临界区之前的时间空当
冰花阵无间隙绽放相当于w锁一直被众多读者线程持有,永远轮不到写者持有w锁
写优先
作家
1 | void *writer(void*p){ |
一个作家线程要考虑的事情:
1.首先要作家线程一个一个经过闸机,记录已经通过闸机,站在临界区门口的作家数量
2
3
4
cnt_writer++;//记录过了闸机的写者数量
...
sem_post(&y);//写者闸机
2.第一个站在临界区门口的作家需要给读者使个绊,上读者锁,不允许读者再进入临界区,目前在临界区中的读者就得过且过吧
2
3
sem_wait(&rsem);//只要是有一个写者,写者就要控制读者的锁
}
3.本作家写作的时候不允许其他作家打扰
2
3
4
5
my_write(temp);//访问临界区
sem_post(&wsem);//本写者释放写者锁,允许下一个写者进入临界区,但是读者不可以,因为rsem锁尚未被释放
4.本作家写完了首先允许其他作家继续写作,直到最后一个离开临界区的作家放开读者锁,允许读者进入.作家离开时也要经过闸机严格计数
2
3
4
5
6
cnt_writer--;
if(cnt_writer==0){
sem_post(&rsem);//最后一个写者离开时才放开读者锁rsem,此时读者才被允许进入临界区
}
sem_post(&y);//写者闸机
读者
1 | void *reader(void *p){ |
这里
1 | sem_wait(&z) |
&rsem信号量被嵌套在&z里面,其目的是什么呢?需要完整分析一遍步骤
1.试想如果已经有写者给读者上了锁,
2.第一个读者会持有z锁并等待rsem锁,在rsem的等待队列上挂着
3.第二个及以后的读者无法获得z锁,都在z的等待队列上挂着
4.当所有写者退出临界区,最后一个写者释放了rsem锁,此时第一个读者终于获得了rsem锁,它执行了下面步骤
1 | sem_wait(&x);//读者闸机 |
如果在即将执行
sem_wait(&wsem)时,如果来一个写者,由于读者1已经持有了rsem锁,因此该写者会卡在sem_wait(&rsem);,写者根本没有可能抢到wsem锁.因此这里担心写者是多余的
5.读者1释放rsem锁
此时读者1仍然没有释放z锁,因此其他读者依旧进不来.并且wsem锁也没有被放开,写者也进不来
7.读者1释放z锁,从一群读者中挑选了一个幸运儿读者2获得z锁,剩下的读者仍然挂在z的等待队列上
8.读者2持有z锁之后还要经过rsem闸机.
此时读者2可能面临两种情况:
(1)如果在 “读者1获得
rsem时到读者2企图持有rsem锁” 期间,有一个写者站在临界区门口,读者1已经释放rsem锁也有可能会分配给写者,该写者会持有rsem锁,导致读者2过不了rsem闸机诚如是,则读者2只持有z一个锁,不会影响写者.读者1后来也只会用到x锁,因此读者2也不会影响读者1.
实际上此时读者2的状态和读者1一开始的状态相同.
(2)如果期间没有写者到达,或者读者2足够幸运被分配了rsem锁
此时读者2的状态和读者1拿到rsem锁之后的状态相同
此时读者1最慢还在访问临界区,最快已经通过x闸机走人了
(1)如果读者1走人了那么读者2面临的状态和读者1完全相同
(2)读者1刚出临界区,马上要执行下面语句
2
3
4
5
6
--cnt_reader;
if(cnt_reader==0){
sem_post(&wsem);
}
sem_post(&x);或许读者2和读者1会因为x发生互斥,但是这都是两个读者一个要进闸机一个要出闸机或者两个都出闸机的矛盾,对于其他锁无影响,此时写者最靠近临界区也得挂在
sem_wait(&wsem);只有当读者1和2都离开时,wsem才会释放,写者才会获得锁
到此可以得到z锁的作用:
当有写者持有rsem锁时,z锁保证,rsem等待队列上只允许最多有一个读者,该读者持有z锁导致其他读者无法挂到rsem等待队列上
写者对读者的影响:
当至少有一个写者在排队时,写者就会锁上rsem,让顶多一个读者挂在rsem上,其他读者挂在z上.
该挂在rsem上的读者一定是所有读者中最早进入临界区的.
只有当最后一个写者离开临界区时才会释放rsem锁,此时rsem上的读者获得rsem锁,
此时该读者持有rsem,z,其他读者依然得挂在z上
多线程提高并发性
CSAPP上勉强举了一个例子,什么例子呢?
计算
$$
\sum_{i=1}^n i
$$
即正整数前n项和
为了使用并发,这里不用等差数列求和公式
CSAPP上说了这么一个意思,要开四个线程计算的话,每个线程负责计算10个数的和
假设n=40,
线程1就负责计算$\sum_{i=1}^{10}i$
线程2就负责计算$\sum_{i=11}^{20}i$
以此类推
各个线程的计算结果求和也是有讲究的
大体上有这么三种情况:
1.开一个全局变量global_sum,每个线程的每次循环直接将数加到global_sum上
2.开一个全局数组global_sums[4],线程1每次循环将i加到global_sums[0]上,线程1每次循环将i加到global_sums[1]上,以此类推.最终在主线程中循环累加一下global_sums
3.每个线程开一个局部变量local_sum,每次循环将i加到local_sum上,每个线程返回局部变量值交给主线程累加
第一种显然是不可以的,global_sum是一个临界区,不加保护被多线程访问会出现同步错误,解决方法是每个线程每次向global_sum加数的时候都要上锁下锁,但是这个时间代价非常大
第二种可以,但是全局数组是开在虚拟内存中的.data节上的,线程需要频繁地访问内存,时间代价也相对较大
第三种局部变量local_sum可能会优化为寄存器变量,诚如是,则速度会很快.即使local_sum被放在线程栈区,也比去data节访问内存快
CSAPP还给出的建议是,有几个处理器最多就开几个线程.每个处理器分别负责一个线程这时最大效率,如果线程数比处理器多则处理器会有线程调度,线程上下文的切换也会有时间开销
线程安全问题
线程不安全函数
不保护临界区的函数
1 |
|
1 | ┌──(root㉿Executor)-[/mnt/e/share/mydir] |
期望的运行结果应该是cnt=2000000,实际上cnt=1024846,即同步错误
保持跨越多个调用状态的函数
啥意思呢?本次函数调用的返回值依赖于先前的结果或者中间结果
比如伪随机数函数rand
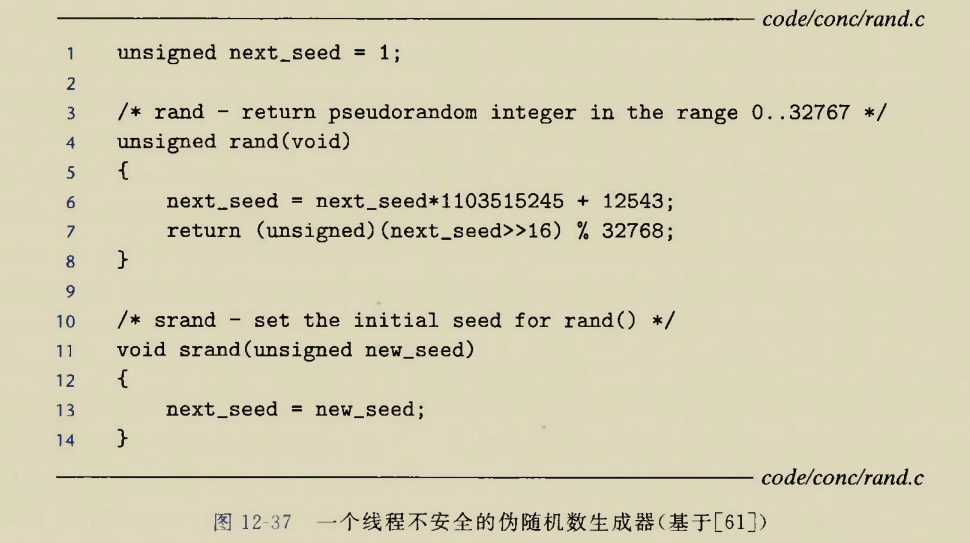
本次形成的next_seed会用在下一次伪随机数的生成.
如果两个线程同时获取了本次next_seed,那么可以预见的是,下一次两个线程生成的伪随机数是相同的
解决方法是,每次的随机数种子都有调用者传递,不同线程保存不同的种子.避开使用共享变量

这种不使用共享变量的线程安全函数叫做可重入函数
返回指向静态变量的指针的函数
啥函数会返回静态变量呢?或者说为啥要返回静态变量呢?
首先glibc库中就有这种返回静态变量的函数,比如ctime函数.其存在是有合理性的

一个函数要返回一个字符串,该字符串在内存上应该放在哪里呢?
如果函数这样写:
2
3
4
char str[] = "dustball";
return str;
}会报告警告:局部变量str作为返回
为啥会警告呢?str作为函数栈上变量,当函数返回之后,函数栈会被退掉.那么此时str指针指向的是一块没有被分配的内存区域.或者当主函数又调用新函数,新函数的函数栈覆盖掉getstr的函数栈时,此时str指针就指向了新函数的函数栈区.
即指针要么指向NULL,要么指向一个在生存期内的对象.否则就会成为野指针
那么应该怎么写才能保证一个函数下才定义的变量在函数退出后依然存活呢?使用静态变量
2
3
4
static char str[] = "dustball";
return str;
}这是因为静态变量会存放在.data或者.bss全局变量区,而不是放在函数栈下
返回静态变量为什么就线程不安全了?比如下面程序mythread.c
1 |
|
我们期望的是分别从两个线程中获得两个字符串,在主线程中交给s1,s2保管
实际上s1,s2指向的是同一块内存地址,即都是.data区域的静态变量buffer,多线程不会拷贝全局变量区
1 | ┌──(root㉿Executor)-[/mnt/e/share/mydir] |
怎么解决 这类错误呢?
我们现在指望的是函数主动返回一个值供我们引用,但是函数的局限性就是它多次调用只能返回一个值,实际上这个静态变量还是临界区
我们现在给函数提供一个内存区域,让函数把数据写到我们指定的区域,在不同的线程中指定不同的区域.这样就可以避免多个引用指向同一块内存区域,即不使用共享变量
比如:
1 |
|
1 | ┌──(root㉿Executor)-[/mnt/e/share/mydir] |
调用线程不安全函数的函数
线程调用的所有函数都是线程执行流的一部分,不光最高层的线程例程函数需要考虑线程安全性,只要是线程执行流上的所有涉及临界区的函数都应当考虑线程安全问题
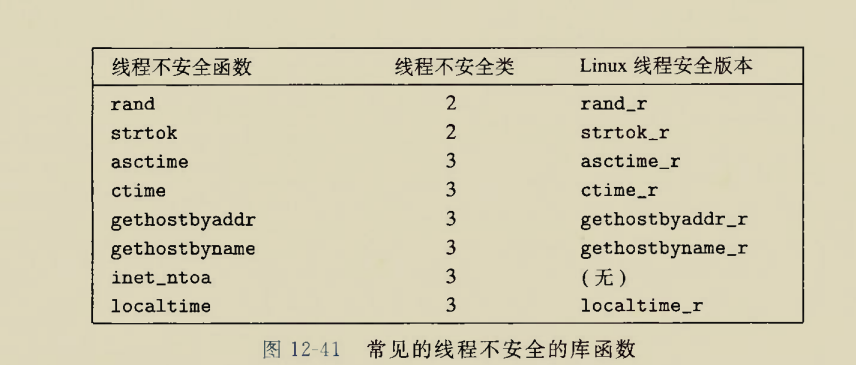
库函数的线程安全性
大多数库函数都是线程安全的
死锁问题
死锁问题大概是指:
线程1想要资源2但是资源2被线程2掌握
线程2想要资源1但是资源1被线程1掌握
没有获得资源则两个线程都需要中断或者忙等待.每个线程都不愿主动放弃已经获取的资源
注意这里资源数量默认为1,也可以大于1,但是还是用1理解比较方便
更规范的定义:
如果一个进程集合中的每个进程都在等待只能由该进程集合中的其他进程才能引发的事件.那么该进程集合就是死锁的
死锁是对一个进程集合而言的
显然死锁的概念也适用于线程集合上
建模表示
线程图建模
用线程图表示这个事情:
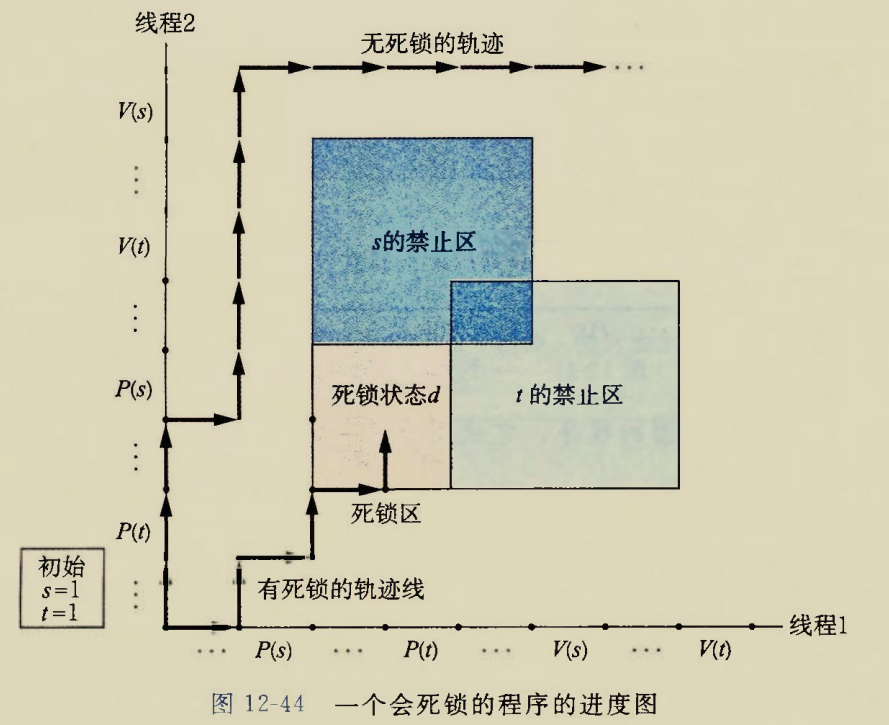
禁止区即s,t资源剩余数量为-1的区域,这显然是不可能的
当两个线程都互补想让争抢资源,并且争抢资源 的顺序不对时,就容易发生死锁
图中死锁区域的状态就是:
线程1已经抢到了s,并且吃里扒外想要抢夺t
线程2已经抢到了t,并且吃里扒外想要抢夺s
双方都有对方想要的东西但是双方都不打算交出自己的资源,于是两个线程都无限忙等
在线程图上由于状态转移只能向右或者向上转移(时间的推移方向)
而死锁区就是右侧核上侧被禁止区完全挡住的区域
有向图建模
图片来自<<MOS>>
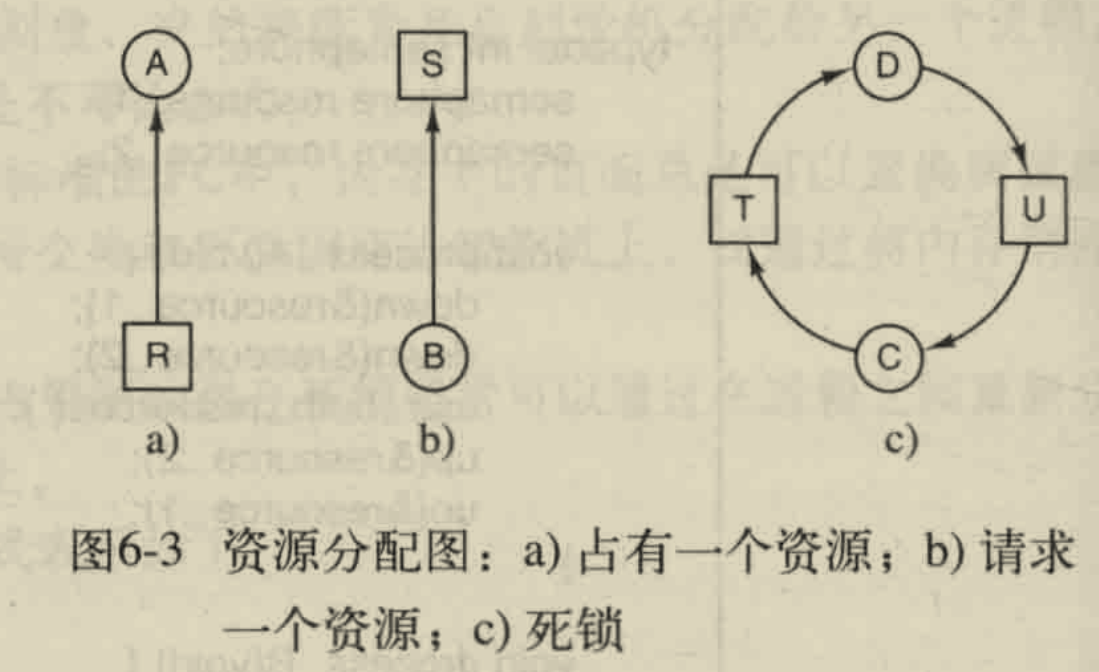
圆圈⭕节点表示的是进程(或者说线程),
方框节点表示的是资源,
资源R指向进程A的有向边,表示进程A已经占有资源R
进程B指向资源S的有向边,表示进程B需要得到资源S
这里的最大资源数量就可以不只有1个了,比如T资源有两个就可以画两个方框,通过合理安排(也不用安排,显然的事情)就可以解决死锁
当一个资源分配图上的一些圆圈方框连接成一个圈时(圈上的箭头同逆时针或者同顺时针),就产生了死锁
如果资源数量为1时,发生死锁就是一辈子的死锁
如果资源数量大于1,则死锁有可能是暂时的,比如本例中的T资源,要是存在另一个T资源,就可以解燃眉之急
死锁的判断
互斥锁死锁的判断
无死锁的充分条件

<<MOS>>上举的例子

啥意思呢?比如线程(或者进程)A和线程B都要使用1和2两种资源
那么线程A和B都应该按照申请1,申请2,释放2,释放1或者申请2,申请1,释放1,释放2这种顺序
否则如图b,可能会产生A申请到1同时B申请到2,此后两个进程就都没有进展了.注意这里说法是可能,也有可能A进程执行完毕才轮到B进程执行,此时就没有死锁
充要条件
资源图上只要没有强联通分量(圈上的箭头同方向)则不是死锁
资源图上只要是有强连通分量就有死锁
甚至可以复习一下塔杨算法求scc
计数锁死锁的判断
存在死锁的充分条件
<<MOS>>给出的算法

符号意义:
现有资源数量表示某种资源的最大数量,包括已用的和没用的
可用资源数量表示某种资源还没有被进程占用的资源
设共有n种资源,编号1到n
现有资源向量$\bold{E}={E_1,E_2,…,E_n}$,其中$E_i$表示第i种资源的总数量(包括已占用的和未占用的)
可用资源向量$\bold{A}={A_1,A_2,…,A_n}$,其中$A_i$表示第i种资源的可用数量(尚未被占用的数量)
当前分配矩阵
$$
\bold{M}=
\begin{bmatrix}
\bold{C_1}\
\bold{C_2}\
…\
\bold{C_n}
\end{bmatrix}\begin{bmatrix}
C_{11}\ C_{12}\ …\ C_{1n}\
C_{21}\ C_{22}\ …\ C_{2n}\
…\
C_{n1}\ C_{n2}\ …\ C_{nn}
\end{bmatrix}
$$
其中每一行都是一个向量$\bold{C_i}$表示第i个进程已经占有的资源向量请求矩阵
$$
\bold{Q}=
\begin{bmatrix}
\bold{R_1}\
\bold{R_2}\
…\
\bold{R_n}
\end{bmatrix}\begin{bmatrix}
R_{11}\ R_{12}\ …\ R_{1n}\
R_{21}\ R_{22}\ …\ R_{2n}\
…\
R_{n1}\ R_{n2}\ …\ R_{nn}
\end{bmatrix}
$$
其中每行都是一个向量$\bold{R_i}$表示第i个进程还需要的资源向量(资源请求向量)定义两个向量的抽象代数关系:
$$
\bold{U}@ \bold{V}\Leftrightarrow \forall i\in[1,n],U_i@ V_i
$$
比如小于等于关系
$$
\bold{U}\le \bold{V}\Leftrightarrow \forall i\in[1,n],U_i\le V_i
$$
即U的每一项都要小于等于V的每一项,则向量$\bold{U}\le\bold{V}$
死锁检查算法:
遍历$\bold{Q}$矩阵,用$\bold{A}$向量与$\bold{Q}$的所有行向量进行比较,如果存在$\bold{R_i}\le \bold{A_i}$,则$\bold{A}=\bold{A}+\bold{C_i}$,并且将$\bold{R_i}$置0,下一次遍历时不再考虑第i行
重复上述步骤,
如果$\bold Q$矩阵的所有行都可以被消去,则通过消去的方法分配资源是不存在死锁的.不按照消去方法就有可能产生死锁
如果$\bold{Q}$矩阵就是有几行消不去,则一定有死锁产生
死锁的避免
银行家算法:
单个资源的银行家算法:
总是挑选当前需要资源数最少的进程先分配资源并执行,待该进程执行完毕后回收其资源,壮大银行资本
如果资源需求量最少的进程都没法满足,那么已经产生了死锁
多个资源的银行家算法
实际上该算法刚才我们已经学习过了,计数锁的判断时的消去方法就应用了银行家算法:
总是挑软柿子捏
总是挑选当前能够满足资源要求的进程首先执行,并在其执行完后获取其原本占有的资源,壮大银行资本
MOS的段子手
“似乎只是为了让一些图论家有事可做罢了”
