Portable Executable
前置知识
notepad.exe on winXP
首先,win11上的notepad.exe和winXP上的notepad.exe不一样
左是winxp上的notepad.exe,右是win11上的
方便获取核心原理的讲解,还是使用winxp的notepad.exe
直接从虚拟机拽到win11上用010editor分析就可以
PE文件
windows上的目标文件叫做PE
可执行的有.exe,.src(即可执行目标模块,类似于linux上的.out)
库文件有.dll等(动态库,类似于linux上的.so)
驱动程序有.sys等
对象文件有.obj(即可重定位目标模块,类似于linux上的.o文件)
PE文件可以分成两部分,头和身子
头就是PE头,身子就是各节区内容
PE在磁盘中存放时的状态和运行时加载进入虚拟内存的状态不完全相同
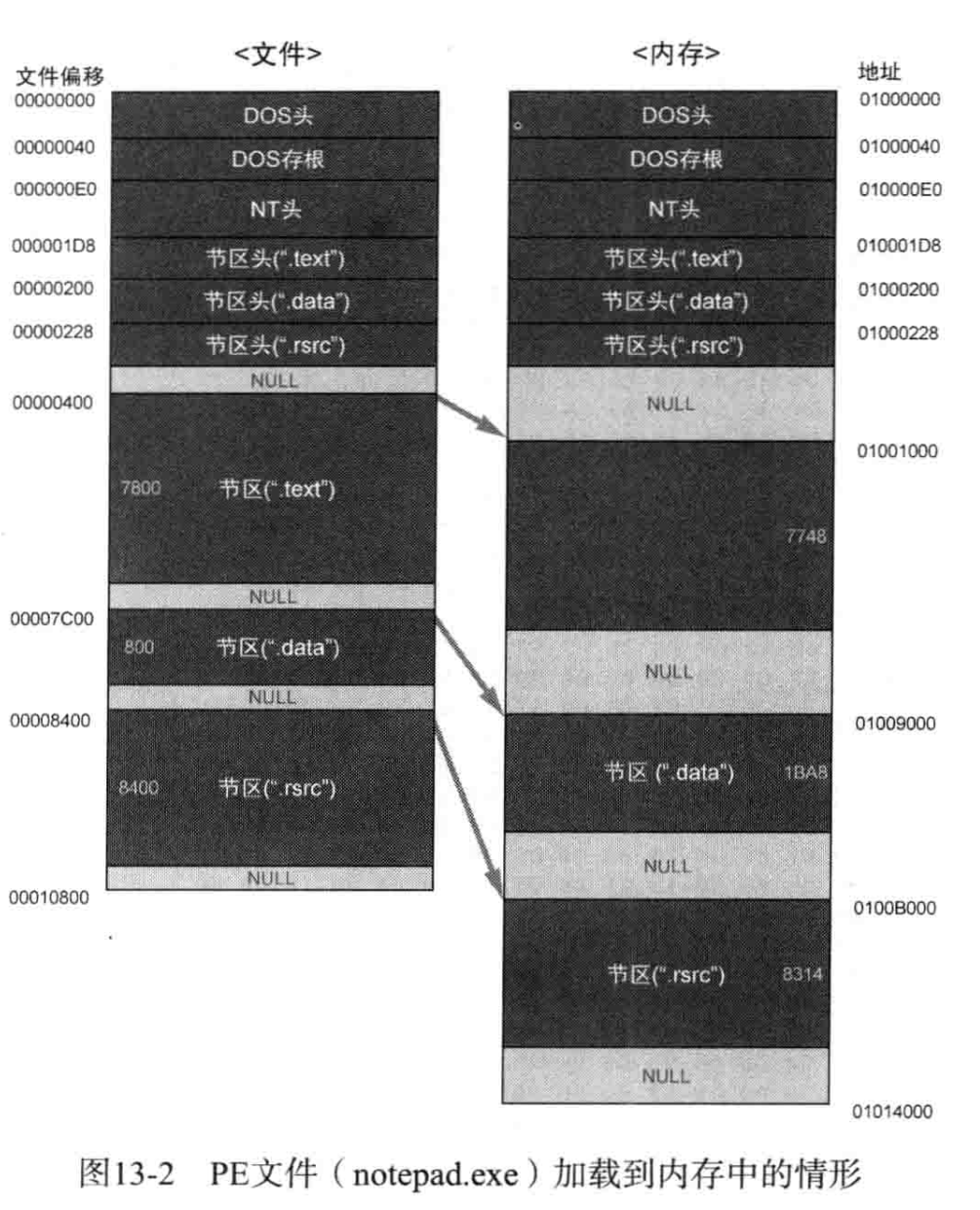
虚拟地址,相对虚拟地址,映像基址,文件偏移
一些符号约定,后面会推导这些量的转化关系
VA(Virtual Address):虚拟地址空间中的地址
RVA(Relative Virtual Address):相对虚拟地址,相对于虚拟地址空间中基地址的偏移量
ImageBase:进程映像在虚拟地址空间中的基地址
关系:$VA=RVA+ImageBase$
文件中保存的都是RVA,实际运行时需要选定一个ImageBase,其他RVA地址基于该ImageBase计算得到运行时的虚拟地址.
RAW:文件偏移,符号在磁盘文件中躺着时,相对于文件开始的偏移量
1 | RAW(x)=RVA(x)-section[i].VirtualAddress+section[i].PointerToRawData |
PE头
DOS头
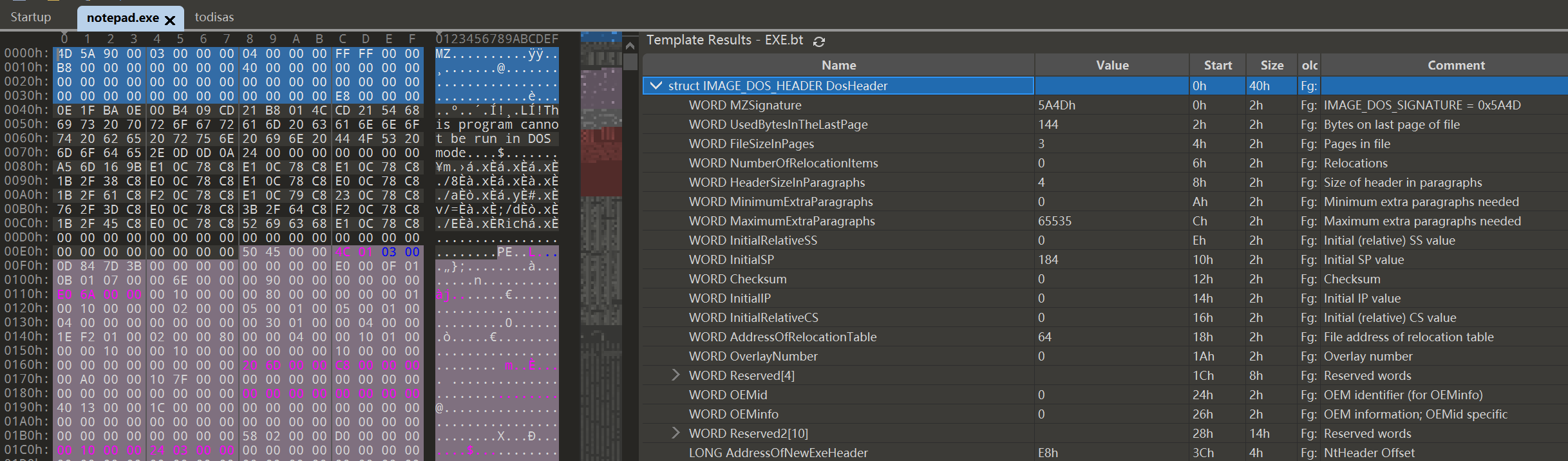
DOS头的最后一个成员是AddressOfNewExeHeader,其值是NT头相对于本文件开始的偏移量
可以看到NotePad.exe中其值为E8h,而本文件的E8h处正好就是NtHeader的起始地址

为啥要设置这么一个值呢?
因为DOS头和NtHeader之间有一个DOS桩,如果这个DOS桩也是定长的,则显然不需要记录Nt头的偏移量
然而DOS桩长度可变,因此为了定位Nt头需要专门记录一下
为啥不在DOS桩里面记录Nt头的位置?DOS桩只有在DOS环境下才会执行,桌面环境下轮不到DOS桩执行
DOS桩
桩,存根, 占位代码,粘合代码,残存代码, 指满足形式要求但没有实现实际功能的占坑/代理代码。

32位PE程序中,由于DOS头是定长的,因此从40h开始是DOS桩,而DOS桩不一定是定长的
winXP上的notepad.exe,其dos桩长度为90h
DOS桩是干啥的呢?在DOS环境下执行PE程序会执行DOS桩内的指令,而不是执行正儿八经的PE程序
为啥呢?DOS环境是16位的,并且没有GUI,当然跑不起来正儿八经的记事本了.
既然DOS桩也可以执行,那么它干了啥事呢?
将DOS桩提出来用ida 16位反编译
发现前D个字节确实可以反汇编成指令
1 | seg000:0000 0E push cs |
此后紧跟着就是有实际意义的字符串
1 | seg000:000E aThisProgramCan db 'This program cannot be run in DOS mode.',0Dh,0Dh,0Ah |
注意到字符串下面有一个美元符号’$’,它也是有作用的,后面就知道了
那么这前D个字节的指令干了啥事呢
首先将cs拷贝给ds,然后将This program cannot be run in DOS mode.$这个字符串的起始地址0Eh放到dx中,目的是为后来的函数调用做准备
1 | seg000:0000 0E push cs |
为啥要把cs拷贝给ds呢?因为这时候cs段寄存器存放的就是当前正在执行的代码段的起始地址,
后面的字符串虽然是数据,但是也是存放在当前代码段的,
访问数据要使用ds:dx两个寄存器,
要想指向这个字符串,ds需要等于字符串的段地址,也就是cs
然后ah=9h决定int 21h做什么工作
1 | seg000:0005 B4 09 mov ah, 9 |
当AH=9的时候,int 21h显示字符串,将DS:DX开始的字符串一直打印到$结束
然后4c01h放在ax中,再次决定int 21h做什么工作
1 | seg000:0009 B8 01 4C mov ax, 4C01h |
当ah=4c时,int 21h决定带返回码返回,返回码就放在al中,显然这里是01h
现在DOS桩的逻辑弄明白了,但是但是,代码和数据只是占了一小部分,桩后半部分那些乱码是啥呢?
010editor给出了一些线索

DOS桩剩下这一部分叫做Rich Header,
单凭其最后一个成员XorKey,一个异或钥匙,就知道这rich_header玩意儿应该是加密的,
既然给了异或钥匙,直接解密试试
1 |
|
运行结果
1 | PS C:\Users\86135\Desktop\PE> g++ main.cpp -O0 -o main |
结果给了一个”DanS”字符串还有一堆乱码
我猜DanS是一个开发者姓名的前缀.但是上网搜不到…
尤其是搜NotePad作者的时候总是铺天盖地的降智辱华话题,凡是能在这种话题上引起讨论的都是大聪明
NT头
1 | typedef struct _IMAGE_NT_HEADERS64 {//64位程序的NT头 |
对于notepad.exe

其NT头从E8h开始,长度为F8h
包括三个成员,一个双字类型的签名魔数4550h,表明NT头开始了
两个结构体成员,一个文件头,一个可选头
Nt文件头
1 | typedef struct _IMAGE_FILE_HEADER { |
notepad.exe的文件头

Machine
Machine是机器码,表征该程序可以在哪种计算机体系上运行
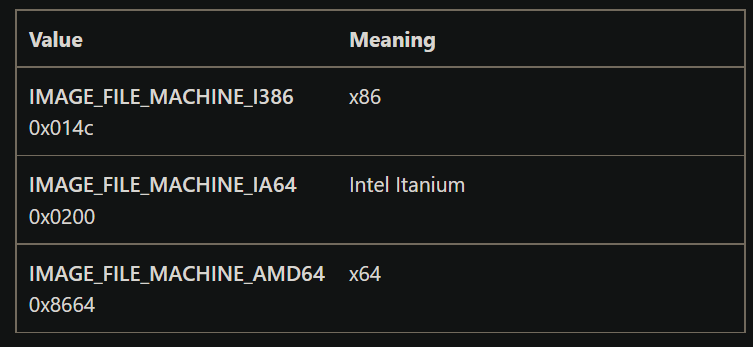
显然winXP上的notepad.exe的Machine值是14Ch,对应x86体系
NumberOfSections
节区数量,该值和节区头表中存在的节区数量一定相等
NotePad.exe中该值为3,其后面的节区数量也确实为3

该值决定了节区头表的大小(每个节都在节区头表中有相同大小的一项)

可以看出节区头表中的项目都是28h字节大小的
TimeDateStamp
链接器生成该文件的时间,该值是从1970年1月1日0时(UTC时间)开始的秒数
notepad.exe中该值为

010editor已经帮我们换算好了时间,是2001.8.17 20:52:29
PointerToSymbolTable
符号表symbol table的偏移量,如果没有符号表则该值为0
notepad.exe中没有符号表,该值为0
为啥可以没有符号表呢?
符号是给人看的,比如每个函数,每个变量都有一个名字.这是为了方便人记忆与理解
但是机器不需要,要执行哪个函数只会在汇编语言中写上call 地址,只认地址不认名
可能编译链接阶段需要符号解析,用到符号表,但是一旦编译链接完成,生成了可执行目标文件,符号表就纯纯的没用了
NumberOfSymbols
记录符号表中的符号数量
notepad.exe没有符号表,该项也为0
SizeOfOptionalHeader
可选头的大小
在notepad.exe中该值为224D=E0h

紧跟在文件头后面的可选头恰好就这么大

DOS头记录了NT头的偏移量,类比一下,为啥没有记录可选头的起始位置呢?
因为文件头的大小是固定的14h,Characterstics是一些二进制位按位或,其总长度就是一个WORD不变
因此可选头紧接着文件头,只要文件头的偏移量知道了,立刻可以算出
可选头的偏移量=文件头+14h字节
而文件头的偏移量是多少?文件头是Nt头的第二个成员,第一个成员是一个双字类型的NT签名,
因此文件头的偏移量=Nt头的偏移量+4字节
Nt头的偏移量是多少?DOS头的
DWORD AddressOfNewExeHeader会直接给出AddressOfNewExeHeader在哪里?DOS头是PE文件的开始,AddressOfNewExeHeader是其3C偏移处,即AddressOfNewHeader永远是PE文件的3Ch到40h字节
Characteristics
本文件属性,多个属性时按位或
比如0x0002就表示可执行映像,意味本文件可以执行(没有未解析的外部引用),
显然括号里是说给可重定位目标模块听的,因为.obj只是完成了编译,尚未经过链接,外部符号仍未解析
又如0x2000就表示DLL动态库文件,虽然它是可执行文件,但是它不能直接运行.
又如0x4000表示本文件只能在单处理机计算机上运行
| Value | Meaning |
|---|---|
| IMAGE_FILE_RELOCS_STRIPPED0x0001 | Relocation information was stripped from the file. The file must be loaded at its preferred base address. If the base address is not available, the loader reports an error. |
| IMAGE_FILE_EXECUTABLE_IMAGE0x0002 | The file is executable (there are no unresolved external references). |
| IMAGE_FILE_LINE_NUMS_STRIPPED0x0004 | COFF line numbers were stripped from the file. |
| IMAGE_FILE_LOCAL_SYMS_STRIPPED0x0008 | COFF symbol table entries were stripped from file. |
| IMAGE_FILE_AGGRESIVE_WS_TRIM0x0010 | Aggressively trim the working set. This value is obsolete. |
| IMAGE_FILE_LARGE_ADDRESS_AWARE0x0020 | The application can handle addresses larger than 2 GB. |
| IMAGE_FILE_BYTES_REVERSED_LO0x0080 | The bytes of the word are reversed. This flag is obsolete. |
| IMAGE_FILE_32BIT_MACHINE0x0100 | The computer supports 32-bit words. |
| IMAGE_FILE_DEBUG_STRIPPED0x0200 | Debugging information was removed and stored separately in another file. |
| IMAGE_FILE_REMOVABLE_RUN_FROM_SWAP0x0400 | If the image is on removable media, copy it to and run it from the swap file. |
| IMAGE_FILE_NET_RUN_FROM_SWAP0x0800 | If the image is on the network, copy it to and run it from the swap file. |
| IMAGE_FILE_SYSTEM0x1000 | The image is a system file. |
| IMAGE_FILE_DLL0x2000 | The image is a DLL file. While it is an executable file, it cannot be run directly. |
| IMAGE_FILE_UP_SYSTEM_ONLY0x4000 | The file should be run only on a uniprocessor computer. |
| IMAGE_FILE_BYTES_REVERSED_HI0x8000 | The bytes of the word are reversed. This flag is obsolete. |
notepad.exe中该值为010Fh(小端序)

010F=0100 | 0001 | 0002 | 0004 | 0008,即集合了5个属性
包括:
0001:重定位信息被删,本程序必须加载到其可选头中规定的ImageBase处,否则报错
0002:可执行
0004:COFF行号被删
COFF:common object file format.通用对象文件格式,这是Unix的目标文件格式,windows最初的目标文件就是抄的COFF
编译时加入-g选项就会生成,
gcc -g,该选项的作用是生成调试信息,因此COFF行号的作用之一就是调试,之二是啥我目前不知道
0008:COFF符号表被删
符号表是从可重定位目标文件连接到可执行目标文件进行符号解析时需要的.
.o和.obj这种可重定位目标模块必须要有符号表
.exe和.out这种可执行目标模块不需要有
显然notepad.exe已经编译链接好了,不需要符号表了
0100:计算机支持32位的字,意思是CPU可以一次性处理32位宽的数据.
显然x86_32上的大部分寄存器(比如eax,esp)等都是32位宽的,总线宽度也是32位,CPU完全有能力一次性处理32位宽的数据
可选头
1 | typedef struct _IMAGE_OPTIONAL_HEADER { |
Magic
区分本文件是32位还是64位又或者是ROM映像的魔数
magic=0x10B表示32位
magic=0x20B表示64位
magic=0x107表示ROM映像
前两个好理解,这第三个ROM映像是啥呢?
表明本程序是烧录到一个ROM存储器中的固件
比如BIOS中的程序,CD-ROM中的程序等等
winXP上的notepad.exe自然是32位的

010editor也帮我们把枚举类型10Bh翻译成了PE32
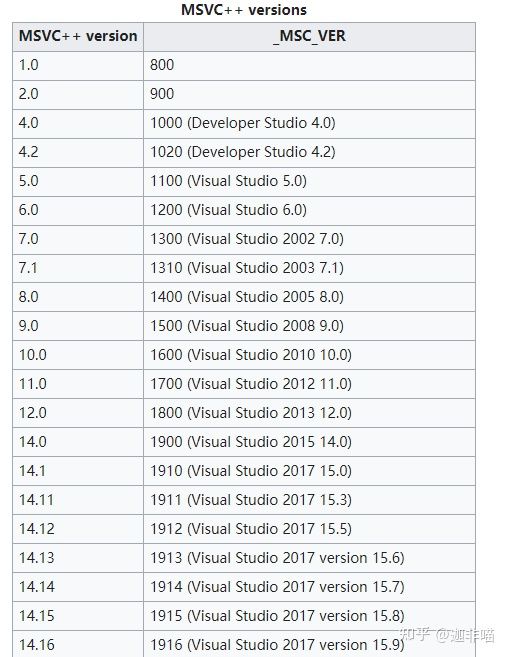
Major/MinorLinkerVersion
主/次链接器版本
对于notepad.exe这种已经编译链接完成的程序来说,自然这两个值白给
这两个值是相对于可重定位目标模块.o,.obj或者库文件.so,.dll这种需要参与链接的目标文件而言的
notepad.exe的这两个值分别是7和0

这个版本号应该是MSVC的版本,不是GCC的ld链接器的版本
根据notepad.exe的开发时间2001年,差不多就是MSVC++ 7.0的时间
而GCC ld到现在才是版本2
就算是gcc本身的版本在2001年左右也才是3,目前在linux上是11,windows上是9
胡乱写了一个main.c用gcc编译链接成main.exe然后用010editor打开观察,
发现主链接器版本确实就是ld的当前版本2
但是次链接器版本就是乱码了,看来这个值不重要


SizeOfCode
code节的大小,然而我从来没有见过叫.code的节,code不就是代码吗,不就是指令吗,不就是.text节咩?
在notepad.exe上SizeOfCode是6E00h

后面.text节区恰好就是6E00h这么大

SizeOfInitializedData
已初始化的数据节
notepad.exe中SizeOfInitializedData=36864D=9000H

.data和.rsrc节合起来才刚好是9000h这么大,看来不光是.data节,还得算上类似性质的节

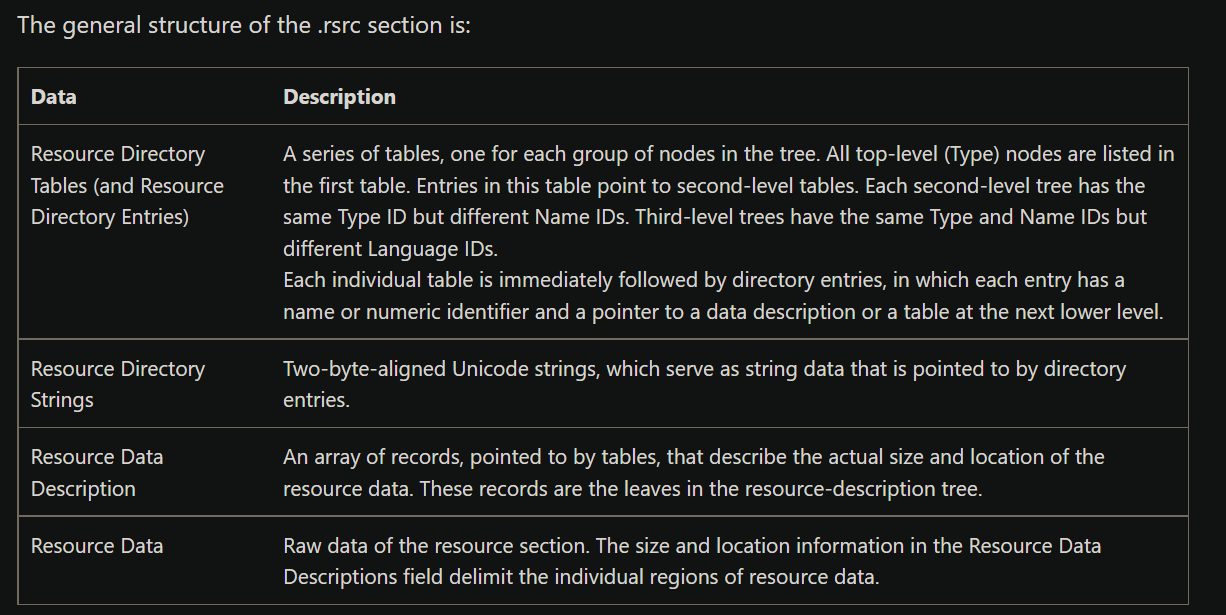
.data节是已初始化的全局变量和静态变量,这容易理解,那么.rsrc是个什么节呢?
查阅PE 格式 - Win32 apps | Microsoft Docs
rsrc节用来存放资源
这里”资源”包括图标等,看介绍是以树形结构组织的,类似于HTML?

SizeOfUninitializedData
未初始化的数据节,应该是指.bss节,然而notepad.exe上该值为0,自然也就没有.bss节
(应该说节区头表中就没有.bss节的记录,真正的节区中永远都没有.bss节,因为它只会在执行时才会形成

AddressOfEntryPoint
入口点函数指针,具体指向谁呢?看看notepad.exe是啥样的
AddressOfEntryPoint=6AE0
这个值是个相对进程映像基地址ImageBase 的偏移量,或者叫RVA

010editor给了提示,.text节中偏移量为0x5EE0的地方,为啥从6AE0变成5EE0了?
先用010editor看看0x5EE0这个地方发生了啥

两个压栈,好像是函数开端的样子,然而两个地址分别是啥,这个问题还没有解决.
用ida打开notepad.exe观察0x1006AE0这个位置
1 | .text:01006AE0 ; __unwind { // __SEH_prolog |
发现这里的指令和在010editor中观察0x5EE0是一模一样的.
到底发生甚么事了?
为啥是0x1006AE0不是0x6AE0?为啥不观察0x5EE0或者0x1005EE0?
ida打开的文件实际上是文件加载到内存之后的映像,不然任务管理器上看IDA为啥会一枝独秀地使用133.3M这么大的内存空间?
而010editor打开的是磁盘文件系统中躺着的静态文件
前面权位指南也讲过,两者是有很大差别的
文件系统中的静态文件都是从0开始计算偏移量RAW
进程映像则从一个指定的基地址开始计算实际虚拟地址空间中的地址,VA=RVA+ImageBase
而notepad.exe的ImageBase就在可选头中规定为1000000h
因此notepad.exe的进程映像就是从1000000h开始的,这就解释了为啥要用ida观察0x1006AE0,而不是0x6AE0
至于另一个问题,这是因为,节区在磁盘文件中存放和加载到内存映像中时,有不同的对齐要求
往往内存中的对齐要求更大,因此对于PE头和text节之间的空隙,进程映像中的更大,
因此text节的RAW(文件偏移 )和RVA(虚拟地址偏移)是不同的,并且有RVA>RAW
更详细的原因需要学习后面的RAW to RVA,将进程从文件装载进入内存的知识


BaseOfCode
代码段在虚拟地址空间中的开始地址
notepad.exe这种BaseOfCode=1000h,即虚拟内存中的相对偏移量RVA=1000h,那么实际虚拟地址为VA=Image+RVA=1000000h+1000h=1001000h

使用ida观察这个1001000h地址
1 | .idata:01001000 ; Section 1. (virtual address 00001000) |
发现是.idata节的开始
ida在该节一开始给出了一块注释:
2
3
4
5
6
.idata:01001000 ; Virtual size : 00006D72 ( 28018.)
.idata:01001000 ; Section size in file : 00006E00 ( 28160.)
.idata:01001000 ; Offset to raw data for section: 00000400
.idata:01001000 ; Flags 60000020: Text Executable Readable
.idata:01001000 ; Alignment : default第一节(相对虚拟地址1000h)
虚拟内存中的大小6D72h
磁盘文件中的大小6E00h
磁盘文件中的基地址400h
标志:60000020,意思是可执行可读 不可写
对齐:默认
这些都和010editor给出的结果相吻合
问题是,idata名字里都带有data了,不应该算是数据吗?怎么就是代码了?
但是观察ida反汇编的结果,这里都是extern声明的函数接口,确实不是数据,但你说它是代码吧,它还没有实现
微软对于该节给出的解释是:
These tables were added to the image to support a uniform mechanism for applications to delay the loading of a DLL until the first call into that DLL. The layout of the tables matches that of the traditional import tables that are described in section 6.4, The .idata Section.” Only a few details are discussed here.
作用是允许DLL库函数在首次被调用是加载
win32exe程序中的idata节非常像linux可执行目标文件中的extern节,
也确实,因为ida给idata节一开始的注释就是
Segment Type:extern
Linux上从
.text到extern的调用顺序为
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
然后是
.plt:00001030 ; int printf(const char *format, ...)
.plt:00001030 _printf proc near ; CODE XREF: main+25↓p
.plt:00001030
.plt:00001030 format = dword ptr 4
.plt:00001030
.plt:00001030 jmp ds:off_400C ; PIC mode
.plt:00001030 _printf endp
.plt:00001030
然后是
.got.plt:0000400C off_400C dd offset printf ; DATA XREF: _printf↑r
然后是
extern:0000402C ; int printf(const char *format, ...)
extern:0000402C extrn printf:near ; CODE XREF: _printf↑j
extern:0000402C ; DATA XREF: .got.plt:off_400C↑o
.text->.plt->.got.plt->extern类比windows上的32位exe是
2
3
4
5
6
7
然后是
.idata:0100100C ; BOOL __stdcall IsTextUnicode(const void *lpv, int iSize, LPINT lpiResult)
.idata:0100100C extrn IsTextUnicode:dword
.idata:0100100C ; CODE XREF: sub_10069BA+12↓p
.idata:0100100C ; DATA XREF: sub_10069BA+12↓r
.text->.idata(extern)windows上对动态库函数的调用貌似比linux上少了got,plt表这一步.
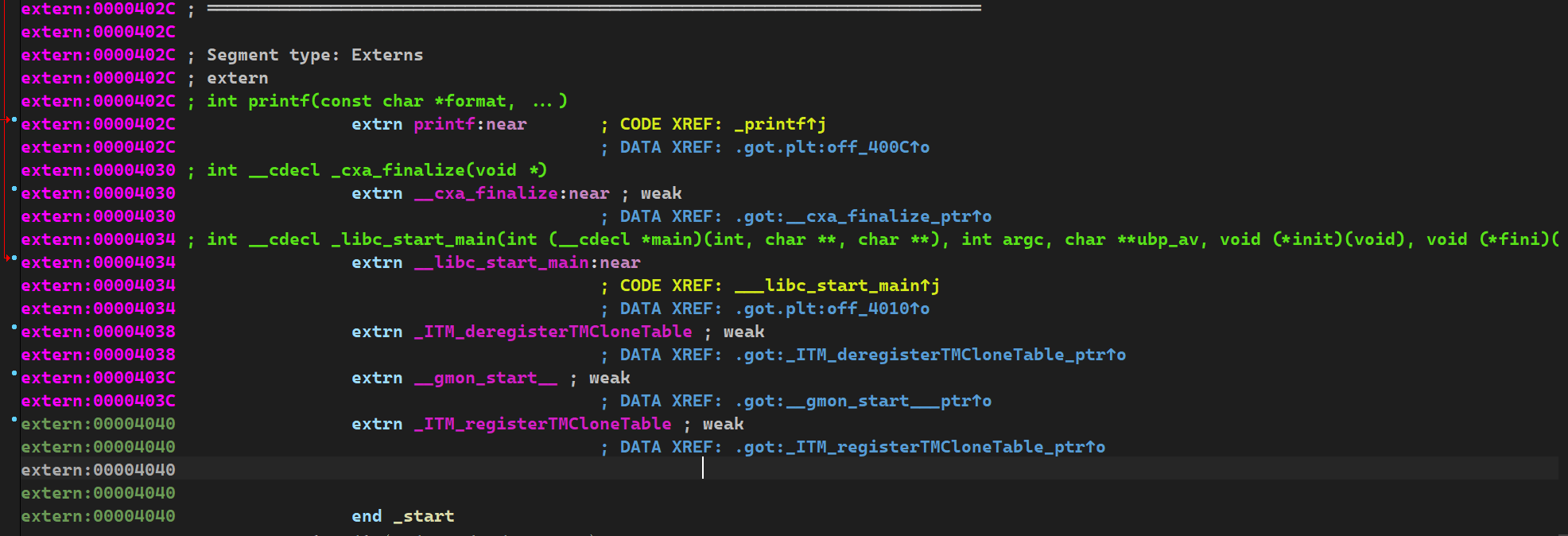
windows上idata具体什么机制呢?这需要学了核心原理后面的IAT才能知道
BaseOfData
数据段的相对虚拟地址RVA
notepad.exe中该值为8000h,那么实际虚拟内存地址就是1000000h+8000h=1008000h

ida跳转该地址观察
1 | .data:01008000 ; Section 2. (virtual address 00008000) |
ida一开始给出的一块注释
2
3
4
5
6
.data:01008000 ; Virtual size : 00001BA8 ( 7080.)
.data:01008000 ; Section size in file : 00000600 ( 1536.)
.data:01008000 ; Offset to raw data for section: 00007200
.data:01008000 ; Flags C0000040: Data Readable Writable
.data:01008000 ; Alignment : default第二节(相对虚拟地址8000h)
虚拟内存中的大小1BA8h字节
磁盘文件中的大小600h字节
磁盘文件中本节的基地址7200h
标志:c0000040,数据段可读写,不可执行
对齐:默认
ImageBase

虚拟地址空间中进程的基地址,也就是PE头将会从0x1000000这个地址开始装载
这一点已经在前面的实验中多次证实了
微软给出的解释是:
The preferred address of the first byte of the image when it is loaded in memory. This value is a multiple of 64K bytes. The default value for DLLs is 0x10000000. The default value for applications is 0x00400000, except on Windows CE where it is 0x00010000.
映像首个字节在装载进内存时最好使用ImageBase这个地址
ImageBase这个值必须是64K(0x10000)的倍数,也就是说,就算装不进0x1000000,下一个有效地址应该是0x1010000,再下一个就得是0x1020000,啃腚不会出现0x1011000这种ImageBase值
DLL动态库该值的默认值是0x10000000
应用程序该值默认为0x400000
应用程序在
windows CE系统上该值为默认为0x10000
显然notepad.exe的ImageBase=0x1000000不是DLL的ImageBase默认值(注意零的个数不一样)
也不是应用程序的,它就非得搞那个特殊
我们自己写一个helloworld然后gcc helloworld.c -O0 -o helloworld -m32编译成一个32为程序,用010editor观察其ImageBase确实是0x400000

为啥ida最上最上只能观察到0x1001000这个位置?不是应当从0x1000000开始吗?
并且就算使用G企图跳转到1000000这个位置,ida也会报告Command “JumpAsk” failed
这是为啥?前面的东西让ida吃了?
原因是ida反汇编显示的只有PE体,即去掉PE头剩下的各节区(注意不是节区头表)
而ollydbg就可以Ctrl+G跳转到0x1000000这个位置
上来是PE魔数0x5A 4D
而ollydbg的反汇编窗口把它也当成指令了
这时候应该看16进制视图
可以看到最开始的MZ魔数



SectionAlignment
节对齐要求,每个节都必须按照该要求装进虚拟地址空间的合适位置
该值必须大于等于FileAlignment的值,这就解释了为啥进程映像在虚拟内存中的大小要比躺在为你文件中时要大
默认的SectionAlignment大小为一个页框的大小(win32上一个页框$4K=2^{12}=0x1000h$)

notepad.exe是满足该对齐要求的
FileAlignment
磁盘文件中的节对齐要求,这个值必须是一个2的幂$[2^8,2^{16}]$
默认是512,如果SectionAlignment的值比页框要小,则FileAlignment必须和SectionAlignment相同

notepad.exe上由于SectionAlignment和页框一样大,因此FileAlignment可以小
实际上是默认值512=200h
Major/MinorOperatingSystemVersion
主要/次要操作系统版本号

这个版本号可以在CMD命令提示符上使用ver命令查询(在powershell上不能用这个命令)
1 | C:\Users\86135>ver |
系统版本号表:
| Operating system | Version number |
|---|---|
| Windows 11 | 10.0* |
| Windows 10 | 10.0* |
| Windows Server 2022 | 10.0* |
| Windows Server 2019 | 10.0* |
| Windows Server 2016 | 10.0* |
| Windows 8.1 | 6.3* |
| Windows Server 2012 R2 | 6.3* |
| Windows 8 | 6.2 |
| Windows Server 2012 | 6.2 |
| Windows 7 | 6.1 |
| Windows Server 2008 R2 | 6.1 |
| Windows Server 2008 | 6.0 |
| Windows Vista | 6.0 |
| Windows Server 2003 R2 | 5.2 |
| Windows Server 2003 | 5.2 |
| Windows XP 64-Bit Edition | 5.2 |
| Windows XP | 5.1 |
| Windows 2000 | 5.0 |
| Windows 98 / Windows Me | 4.0 |
| Windows 95 | 4.0 |
也就是说是最早可以运行notepad.exe的windows系统就是win 2000,
只要版本号比5高的系统都可以运行notepad.exe
Major/MinorImageVersion
主要/次要映像版本

也可以在CMD上用dism /online /get-targeteditions命令查看
1 | C:\Users\86135>dism /online /get-targeteditions |
这个东西是干啥的,没有搜到
Major/MinorSubsystemVersion
主要/次要子系统版本

Win32VersionValue
预留值,必须为0

SizeOfImage
映像大小,即本文件完全装载进入虚拟内存中占用的空间

该值必须是节对齐要求的整数倍
SizeOfHeaders
包括DOS头,Nt头,节头表三个的总大小,然后向上舍入到一个FileAlignment的倍数值

CheckSum
检校和

从程序最开始,以两个字节为单位不断相加,忽略溢出,最后加上文件长度得到校验和
在加载任何驱动程序,启动时任何动态库,任何系统进程加载动态库时
都需要经过检校
SubSystem
这是一个枚举值,每个值对应一个序号,表示运行本镜像需要的子系统
1 |
比如2号就是windows用户图形界面接口子系统,就是窗口程序
比如3号就是windows字符模式用户接口子系统,就是控制台程序
notepad.exe当然需要GUI界面,因此该值为2

自己写的控制台程序helloworld.exe,这个值就是CUI

如果使用010editor将notepad.exe的SubSystem值给他改一下,改成CUI,会发生啥呢?
会同时运行一个控制台和一个窗口程序

在控制台上使用ctrl+C中断进程
1 | [已退出进程,代码为 3221225786 (0xc000013a)] |
窗口也会跟着关闭
同理点选窗口右上角的❌,控制台也会关闭
将SubSystem值再改为其他值都会报错无法在win32环境运行
DllCharacteristics
枚举值,描述本映像加载动态库的属性
| Value | Meaning |
|---|---|
| 0x0001 | Reserved. |
| 0x0002 | Reserved. |
| 0x0004 | Reserved. |
| 0x0008 | Reserved. |
| IMAGE_DLL_CHARACTERISTICS_HIGH_ENTROPY_VA0x0020 | ASLR with 64 bit address space. |
| IMAGE_DLLCHARACTERISTICS_DYNAMIC_BASE0x0040 | The DLL can be relocated at load time. |
| IMAGE_DLLCHARACTERISTICS_FORCE_INTEGRITY0x0080 | Code integrity checks are forced. If you set this flag and a section contains only uninitialized data, set the PointerToRawData member of IMAGE_SECTION_HEADER for that section to zero; otherwise, the image will fail to load because the digital signature cannot be verified. |
| IMAGE_DLLCHARACTERISTICS_NX_COMPAT0x0100 | The image is compatible with data execution prevention (DEP). |
| IMAGE_DLLCHARACTERISTICS_NO_ISOLATION0x0200 | The image is isolation aware, but should not be isolated. |
| IMAGE_DLLCHARACTERISTICS_NO_SEH0x0400 | The image does not use structured exception handling (SEH). No handlers can be called in this image. |
| IMAGE_DLLCHARACTERISTICS_NO_BIND0x0800 | Do not bind the image. |
| IMAGE_DLL_CHARACTERISTICS_APPCONTAINER0x1000 | Image should execute in an AppContainer. |
| IMAGE_DLLCHARACTERISTICS_WDM_DRIVER0x2000 | A WDM driver. |
| IMAGE_DLL_CHARACTERISTICS_GUARD_CF0x4000 | Image supports Control Flow Guard. |
| IMAGE_DLLCHARACTERISTICS_TERMINAL_SERVER_AWARE0x8000 | The image is terminal server aware. |
比如0x0020表示ASLR,地址随机化
比如0x0040表示动态库可以在装载时重定位
0x0080,强迫进行代码完整性检查,作用是防止恶意代码注入等等安全问题
0x0100,NX保护,数据段不可执行
…

notepad.exe上这个值为0x8000(小端)
SizeOfStackReserve
栈区预留空间大小,notepad.exe上栈区的预留了大小是40000h,即256K

该值就是栈区的最大大小,要是本地变量太多或者函数递归太深太多,则发生栈溢出,
这里可以自己写一个程序实验一下,
524288=2^19=2^9K=80000h<800000=2e5那么我们在代码中开一个2e5的int数组,超过了524288字节,看看能否开出来
2
3
4
5
6
7
8
9
int main(){
int arr[200000];//2e5数组
for(int i=0;i<200000;++i){
arr[i]=i;
}
return 0;
}
可以看到,本来预留的 栈空间是200000h=2M是可以放下2e5的数组的,全换算成int是0.5M个,即512K
此时程序正常运行
现在给他穿个小鞋
果然寄了
而这个返回代码0xc00000fd正是栈溢出的状态



SizeOfStackCommit
栈提交大小,notepad.exe上栈提交大小是11000h即68K

啥是”提交大小”?
中文站点下没找到,在stackoverflow上找到了解答
[c++ - What is the Difference between reserve and commit argument to CreateThread? - Stack Overflow](https://stackoverflow.com/questions/24260638/what-is-the-difference-between-reserve-and-commit-argument-to-createthread#:~:text=The reserve argument sets the amount of address,be initially committed to the stack’s reserved region.)
The commit is the size of physical memory that the system should preallocate for the stack
commit就是为栈区预留的物理内存大小
SizeOfStackReserve是栈区最大占用的虚拟内存空间的大小
SizeOfStackCommit是栈区对应虚拟内存实际使用的物理内存大小
SizeOfHeapReserve
堆区预留空间大小,类似于SizeOfStackReserve

SizeOfHeapCommit
堆区实际使用物理地址空间大小

LoaderFlags
已经被官方扬了
NumberOfRvaAndSizes

微软也是春秋笔法,这个值的解释就短短一行
The number of directory entries in the remainder of the optional header. Each entry describes a location and size.
可选头中剩下的部分中,目录条目的个数.
每个条目描述了一个位置和大小
你说你🐎呢,这说了个什么事啊?
这需要联系可选头剩余的部分一起看,确实剩下的部分有16个条目
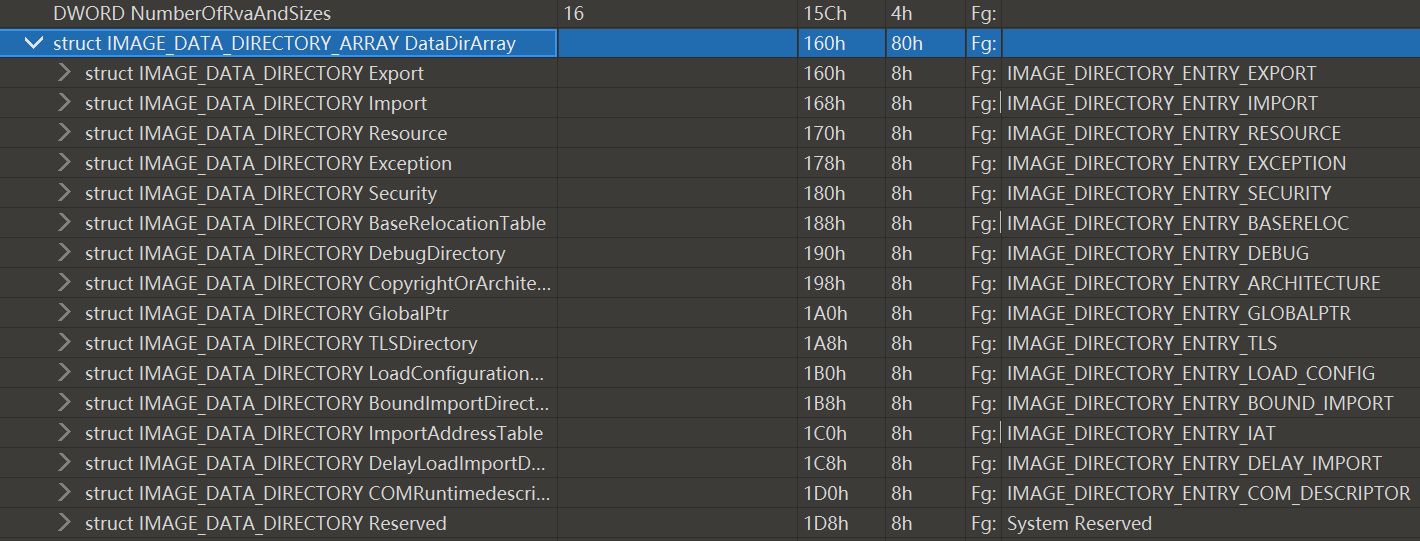
这16个条目顺序是固定的,
如果NumberOfRvaAndSizes=1则只有导出表条目

如果NumberOfRvaAndSizes=2则有导出表和导入表两个条目

…
以此类推
每个条目对应的表是干啥的呢?
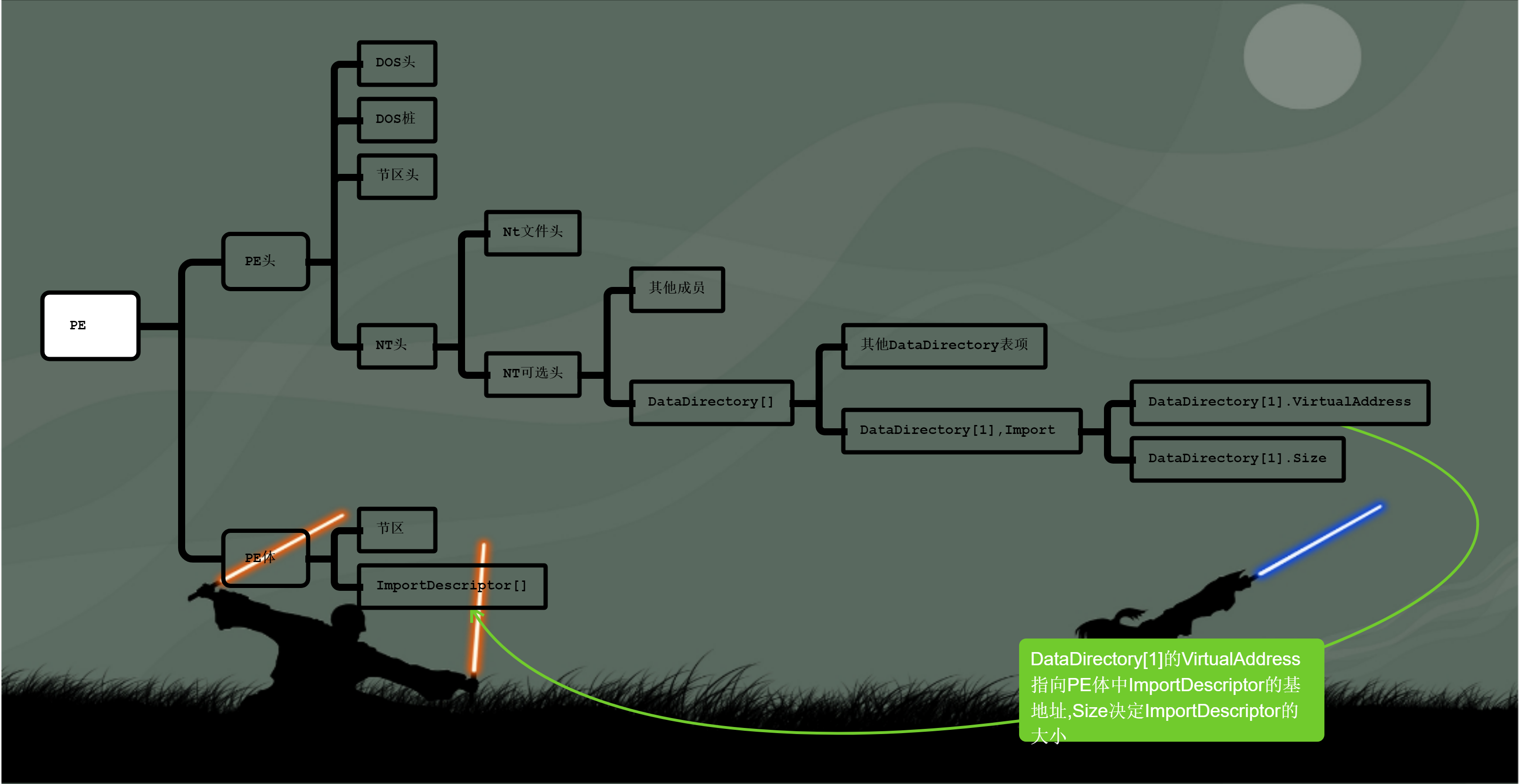
DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES]
其中数组大小#define IMAGE_NUMBEROF_DIRECTORY_ENTRIES 16这个值恒为16不变,
意思是,虽然DataDirectory一直就是16项,但是实际多少项有效,这需要上一个成员NumberOfRvaAndSizes来决定
现在的问题是,DataDirectory数组的元素是什么呢?
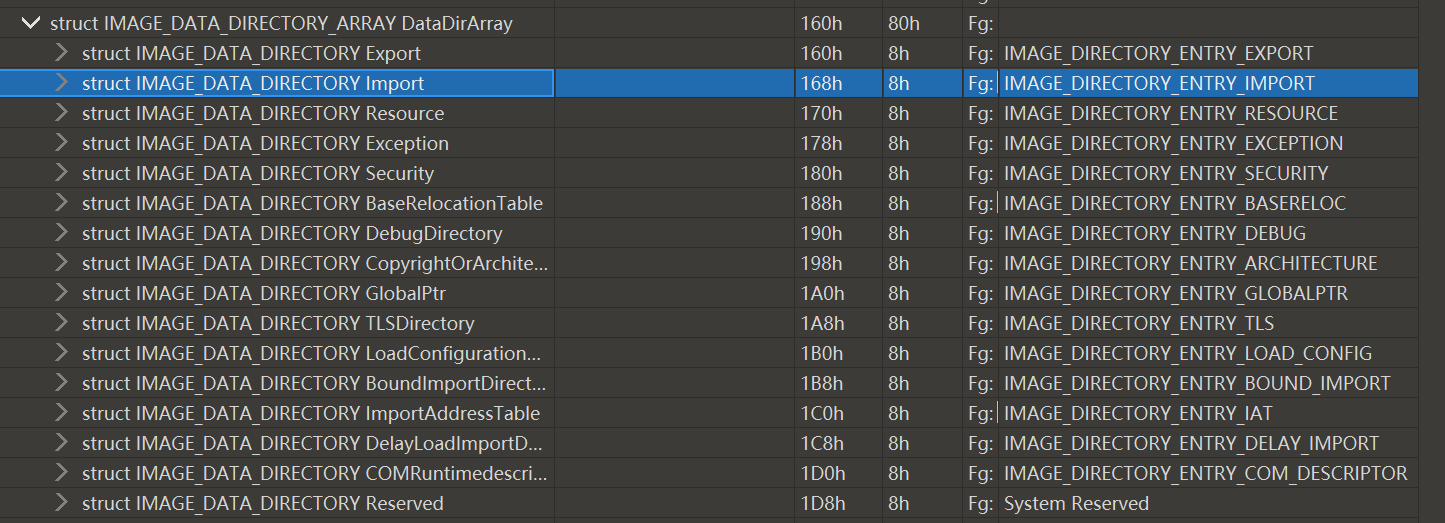
每个数组元素的结构相同
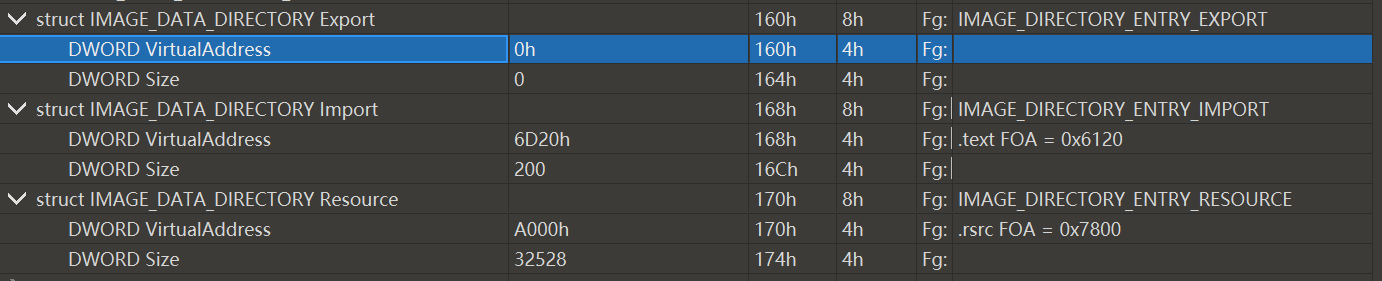
DataDirectory数组中的每项都对应一个重要的技术,包括导入表,导出表,重定位等等
每一个都有一个VirtualAddress,指向一个相对虚拟地址,还有一个size成员,表征一个大小
指向的谁,表征的又是谁的大小呢?
DataDirectory[1]=Import
以其中的导入表Import为例,其VIrtualAddress指向相对虚拟地址6D20h,010editor已经帮我们计算出了文件偏移为0x6120

下面用010editor观察00x6120这个位置

发现这是一个名为ImportDescriptor[]的数组的位置
该位置在节区之后,显然已经出了PE头了
这个数组一共有9项,下标0到8,每项大小相同都是14h=20d,这样算下来这个数组大小是20*9=180字节
然而刚才DataDirectory的Import项中,Size=200.这表明ImportDescriptor[]应该有10项.
回到010editor观察ImportDescriptor[8]之后的编码
发现ImportDescriptor[8]后面还有20个自己都是0
也就是说ImportDescriptor[9]全空


现在的问题是,ImportDescriptor[]数组是干啥的呢?
DataDirectory[1].VirtualAddress->&ImportDescriptor[]
DataDirectory[1]是数据目录 的 第二项,或者说导入目录表项
DataDirectory[1].VirtualAddress指向ImportDescriptor导入描述符表的基址
_IMAGE_IMPORT_DESCRIPTOR结构体数组ImportDescriptor[],也可以叫做IMPORT Directory Table
各种叫法还有指针瞎j8值的关系,一定要分清
ImportDescriptor[]在节区之后,不属于PE头.
权威指南:
IMAGE_IMPORT_DESCRIPTOR结构体ImportDescriptor[],
其中记录着PE文件要导入哪些库文件,程序需要多少导入个库,就需要有多少个ImportDescriptor项目,这些项目组成数组,数组最后一项全空
这和我们刚才观察到的是相吻合的
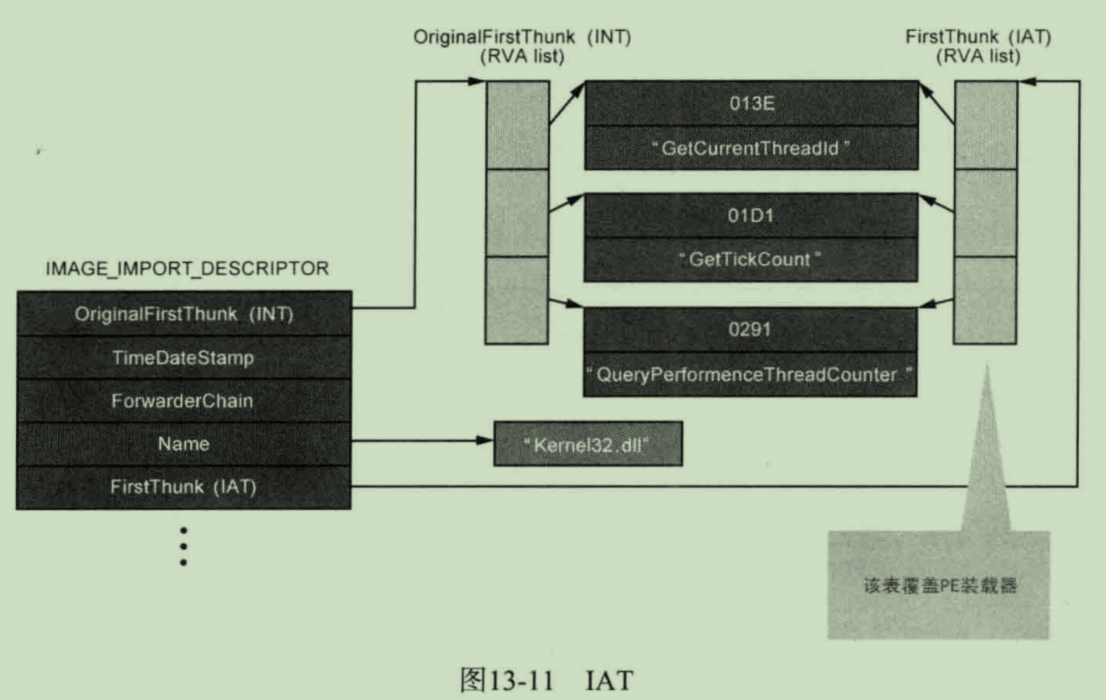
IID是给PE装载器用的,先贴上PE装载器的干活步骤
其中IID是
_IMAGE_IMPORT_DESCRIPTOR的缩写INT是
import name table导入名称表的缩写,也就是IID中OriginalFIrstThunk指向的地址IAT是import address table 导入地址表,也就是ida反汇编之后的.idata区
关于INT和IAT,权位指南也给了一张图,但是属于”会的一看就明白,不会的看了还是不会(出自祭祖老师顾新)”那种
这个图怎么看呢?
最左边这个是一个IID结构体,也就是ImportDescriptor[]的一项
其中Name=”Kernel32.dll”,这是一个DLL库名,表明本IID的作用是导入DLL库中的函数
OriginalFirstThunk指向INT表基址,这个INT表实际上是
_IMAGE_IMPORT_BY_NAME结构体数组,每一项都由一个Hint和一个字符串名组成,每个库函数都有自己的名字,比如GetCurrentThreadld,也有在库中的唯一的编号放在Hint中FirstThunk指向IAT表基址,这个IAT表就是用ida观察时,.idata区中extern声明的函数.
对于一个库,其对应INT和IAT表中的表项应该是一样多的,意思就是需要使用几个函数就解析几个函数地址,多一个也不干
程序text正文代码段调用库函数时就是call idata区中的”函数”,就像
call ds:DragFinish.那么idata区的”函数”应当是一个地址,然而动态库是在程序装载时,运行前装载的,此时已经经过了编译链接,显然即使动态库已经映射进入进程的虚拟地址空间了,但是调用库函数的地方还是不知道库函数在哪里.
这就好比我虽然和058班同学在同一所大学,但是我不知道sjf在哪个宿舍住,我想上门拜访一下却不知道应该去哪里
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
WORD Hint;//按照Hint编号加载函数
CHAR Name[1];//
} IMAGE_IMPORT_BY_NAME,*PIMAGE_IMPORT_BY_NAME;
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
__C89_NAMELESS union {
DWORD Characteristics;
DWORD OriginalFirstThunk;//指向INT数组基地址
} DUMMYUNIONNAME;
DWORD TimeDateStamp;
DWORD ForwarderChain;
DWORD Name;//动态库名称,注意不是函数名称
DWORD FirstThunk;//指向IAT数组基地址
} IMAGE_IMPORT_DESCRIPTOR;
typedef IMAGE_IMPORT_DESCRIPTOR UNALIGNED *PIMAGE_IMPORT_DESCRIPTOR;下面根据权威指南中给出PE装载器导入函数的步骤,跟踪观察一下
1.读取IID的Name成员,获取库名称
以ImportDescriptor[0]为例,其Name成员指向RVA=71A4,用ida观察0x10071A4这个位置
确实是comdlg32.dll字符串
2.LoadLibrary(“comdlg32.dll”),返回值是comdlg32.dll库的句柄,该句柄将会用于库中查函数
3.读取IID的OriginalFiristThunk成员,获取INT表地址
OriginalFiristThunk=0x7088h,用ida观察0x1007088这个位置
2
3
4
5
6
7
8
9
10
11
12
13
.text:01007088 ; Import names for comdlg32.dll
.text:01007088 ;
.text:01007088 off_1007088 dd rva word_1007172 ; DATA XREF: .text:__IMPORT_DESCRIPTOR_comdlg32↑o
.text:0100708C dd rva word_1007156
.text:01007090 dd rva word_1007196
.text:01007094 dd rva word_1007148
.text:01007098 dd rva word_1007134
.text:0100709C dd rva word_1007182
.text:010070A0 dd rva word_1007162
.text:010070A4 dd rva word_100710C
.text:010070A8 dd rva word_100711C
.text:010070AC dd 0ida也给出了注释”comdlg32.dll库需要导入函数的名称”,
需要注意的是INT表的最后一项是0,也就是NULL,它的作用是判断INT表是否结束
4.对于INT表的第i项,
第0项就是
.text:01007088 off_1007088 dd rva word_1007172第1项就是
.text:0100708C dd rva word_1007156…
根据
_IMAGE_IMPORT_BY_NAME结构体的Name值,PE装载器调用GetProcAddress(<动态库句柄>,"<函数名>")获取该名称对应函数的地址(此地址为在整个进程虚拟地址空间中的地址,也就是绝对虚拟地址,不是相对于动态库基址的偏移量)比如其中word_1007172指向一个_IMAGE_IMPORT_BY_NAME结构体
2
.text:01007174 db 'PageSetupDlgW',0
Hint=0Fh
Name="PageSetupDlgW",一个函数名然后PE装载器调用
GetProcAddress(comdlg32.dll句柄号,"PageSetupDlgW");就获得了该函数的虚拟地址5.根据IID的FirstThunk成员,获取对应IAT表地址
comdlg32.dll的FirstThunk=12A0,用ida观察0x10012A0这个地址
2
3
4
5
6
7
8
9
10
.idata:010012A0 ;
.idata:010012A0 ; BOOL __stdcall PageSetupDlgW(LPPAGESETUPDLGW)
.idata:010012A0 extrn PageSetupDlgW:dword
.idata:010012A0 ; CODE XREF: NPCommand(x,x,x)+29F↓p
.idata:010012A0 ; GetPrinterDCviaDialog()+2C↓p ...
.idata:010012A4 ; HWND __stdcall FindTextW(LPFINDREPLACEW)
.idata:010012A4 extrn FindTextW:dword ; CODE XREF: NPCommand(x,x,x)+471↓p
.idata:010012A4 ; DATA XREF: NPCommand(x,x,x)+471↓r
...每项占4个字节,也就是一个int,一个指针类型,显然要写入一个函数地址
6.将4中获取到的PageSetupDlgW的地址写到5中的相应IAT表项中去
假设PageSetupDlgW的地址为0x12345678,四个字节,写到.idata区的
0x10012A0开始的四个字节
地址 数据 0x10012A0 0x78 0x10012A1 0x56 0x10012A2 0x34 0x10012A3 0x12 小端模式
这里PageSetupDlgW的地址是我们假设的GetProcAddress的返回值,其实际值可以用ollydbg动态调试观察
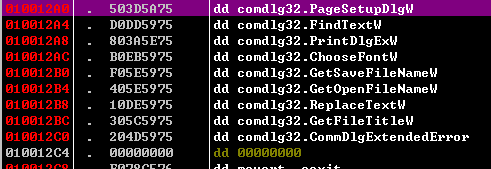
实际上PageSetupDlgW被装载在进程虚拟地址空间的
0x503D5A75.7.重复4-6直到遭遇INT最后一项0
到此貌似了解了整个库函数符号解析的过程,回忆整个过程
编译器和链接器不会解析动态库的符号,
在text节正文代码上call的是ds:[库函数名],实际上是call这个地址上存放的地址,
ds:[库函数名]是.idata区的IAT表,每个IAT条目四个字节,将来要存放一个实际的库函数地址
编译器和链接器会记录没有解析的外部符号,放到DataDirectory[1]指向的
_IMAGE_IMPORT_DESCRIPTOR数组中,每一个需要导入的库都在本数组中建立一个表项,每个表项记录要装载哪个库(Name),还有要装载这个库的哪些函数(指向
_IMAGE_IMPORT_BY_NAME数组即INT表的指针).还有哪个地方需要解析这个库里的函数(指向.idata段IAT表基址的指针)每个INT表表项都要记录,要装载哪个函数,该函数的Hint
但是但是,PE装载器是怎么从DLL库中找到函数地址的呢?




符号解析可以分为三个阶段
1.编译时
编译器负责将本文件中的引用解析到本文件中的实现,比如
2
3
4
5
6
7
void main(){
func();
}
void func(){
//do something...
}main前面这个func就是一个引用,它的作用是给编译器说,有这么一个func函数,但只是有,func具体干了啥,编译器不知道.
编译器会首先发现第一行的引用,然后在本文件中找实现,显然可以找到实现,于是就有了func的PC相对地址,再main中调用func时就可以
汇编成
call 相对地址的格式这个引用是必须的,去掉之后会发生意想不到的运行时错误
比如
2
3
4
5
6
7
void main(){
int a=func();
}
void func(){
//do something...
}这样可以通过编译,但是显然func没有返回值.提前声明void func();再编译会直接编译报错.
2.链接时
一个模块可能会引用其他模块中的符号,比如全局变量或者函数
比如下面这个程序
2
3
4
5
6
void func();
int main(){
int a=other;
func();
}编译器发现other是个外部符号,func虽然没有表明extern但是本模块中找不到实现.
而编译器只负责将一个一个孤立的模块编译,将他们链接起来不是编译器的事,
于是编译器就为other和func都生成一个符号链接表项,把这个皮球踢给链接器完成
链接器首先进行符号解析,它会遍历每个模块,每找到一个全局符号就看看符号链接表中有没有他的引用,有则这个引用就可以落地.全遍历一遍之后还有不能解析的引用则报链接错
符号解析完毕之后就是重定位,将多个参与链接的目标模块合并成一个大目标模块
3.运行时
这就是IAT或者说GOT,PLT发挥作用的时候
DataDirectory[0]=Export
类比DataDirectory[1]导入表,导入表的作用是将动态库中的函数导入
那么导出表就应该把本模块中的函数向外导出,提供给其他模块使用,也就是本模块作为动态库
notepad.exe是一个引用程序,显然不是动态库,自然没有导出的函数,那么DataDirectory[0]就是个空记录

可以通过观察kernel32.dll动态库,了解Export表怎么干活
notepad.exe和kernel32.dll都是直接从windowsXP虚拟机的C:/Windows/System32下面拽出来的
notepad.exe和kernel32.dll的整体对比
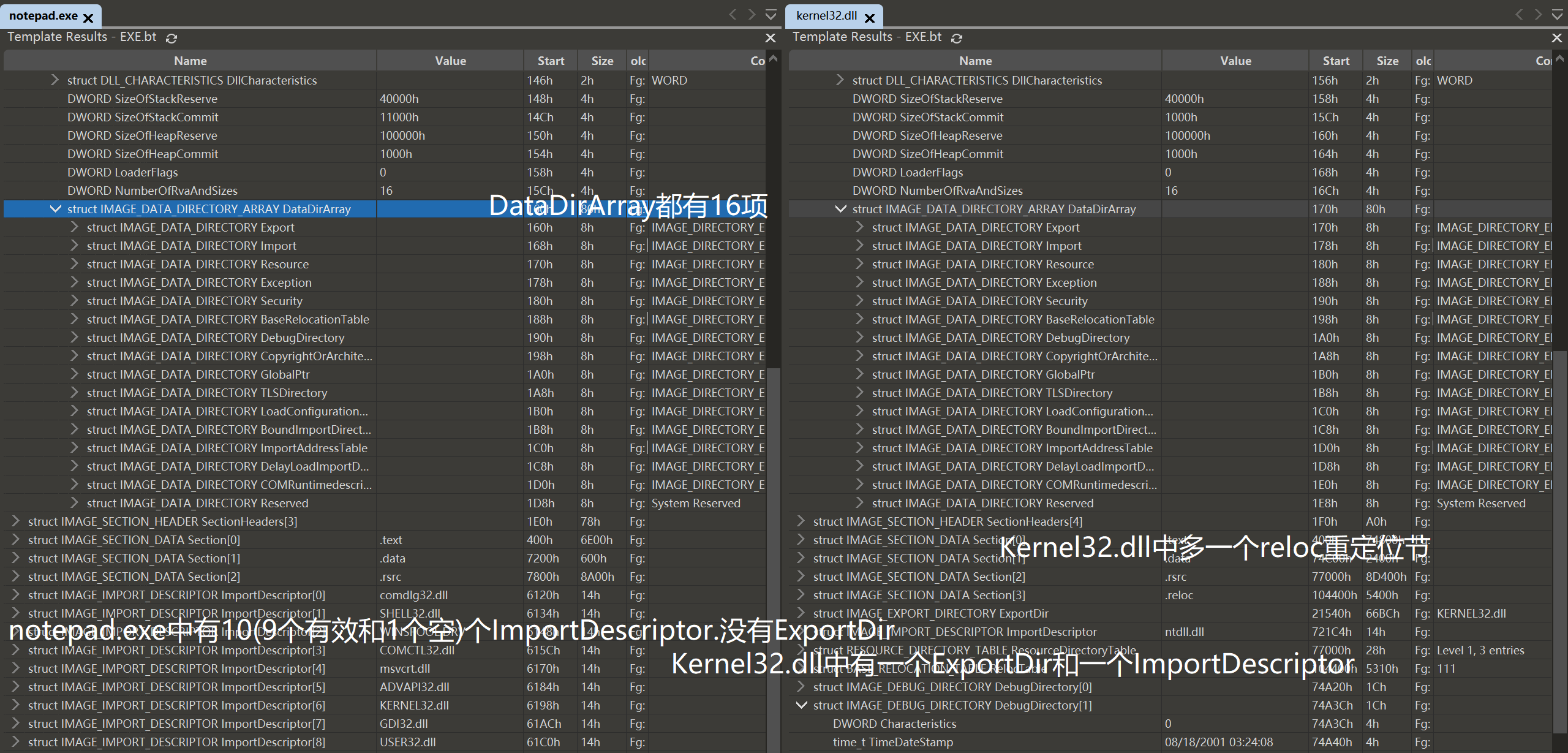
导出表ExportDir至多有一个,但是导入表可以有多个
因为一个应用程序可能需要多个动态库支持,而一个动态库只需要一个导出表导出自身函数
kernel32.dll
1 | PE头 |

两个表项,分别是相对虚拟地址0x22140h和十进制表示的大小27016
由于ImageBase为0x77e40000h,因此实际虚拟地址就是0x77e62140

如果使用ida就观察0x77e62140这个位置
如果使用010editor就观察0x21540这个位置
这个位置就是IMAGE_EXPORT_DIRECTORY结构体的起始地址,这个结构体是干啥的呢?
1 | typedef struct _IMAGE_EXPORT_DIRECTORY { |
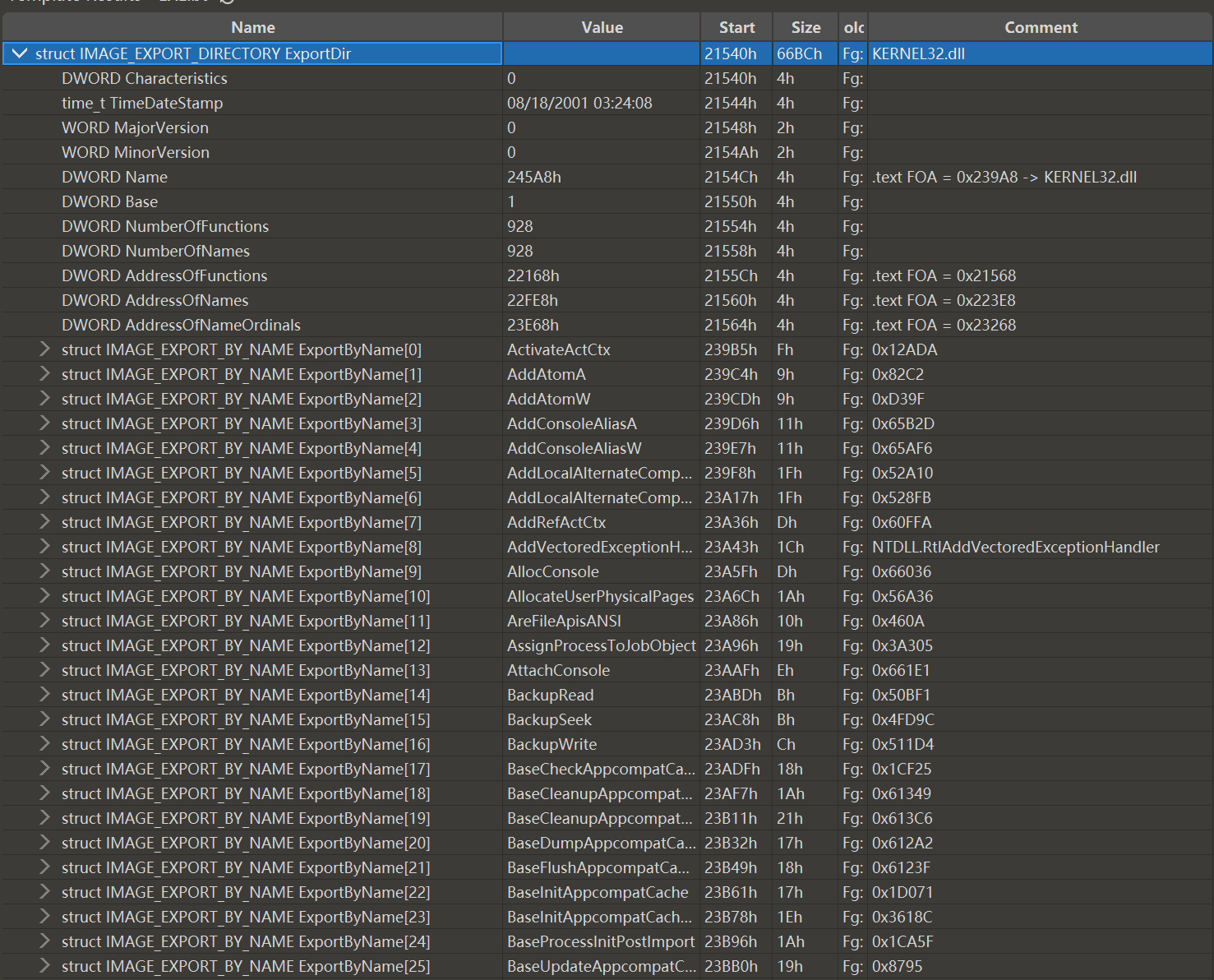
NumberOfFunctions和NumberOfNames,在kernel32.dll中数量相同,都是928,也就是说导出了928个函数,每个函数都有名字

这就很奇怪了,
一是为啥函数要有名字?
二是,为啥每个函数都有名字了还要记录一个名字数量和一个函数数量,两个不相同吗?
在可执行目标文件exe中,确实不需要函数有名字,要调用函数,只需要call 函数地址.函数名字就是一个写源代码时的助记符
但是库文件不一样,库需要为别的exe文件或者库提供支持.
动态库在exe装载时才会映射进入进程虚拟地址空间,然后进行动态链接.
我们已经在自己的模块源代码中写了”MessageBox”这种动态库中的函数符号,显然静态解析解决不了这个符号.
那么动态链接的时候怎么解析这个事情呢?
我的想法是,在exe中保留需要调用的库函数的名字,在dll中导出库函数的名字,并且和地址挂钩.动态链接器在解析exe中动态库函数名字时,就像查字典一样,exe中看一眼,要解析MessageBox,再去dll中遍历所有[库函数名,地址]键值对,查到就把地址写到exe的相应位置.
但是如果库函数很多,库函数名很长,匹配库函数名还是字符串匹配,那么遍历库函数表的效率会很低.并且这样做完全没有必要
可以给每个函数编一个号,比如MessageBox编号1,MessageBoxW编号2,以此类推,这就好比建立了一个协议,exe需要一个一号函数,动态解析器就去dll库中索要1号函数,dll库和exe都知道1号函数是MessageBox.而动态链接器相当于中间信道,它没必要知道MessageBox->1->MessageBox这个过程
而实际上人家是怎么解决这个问题的呢?
回顾notepad.exe导入表的情形,_IMAGE_IMPORT_BY_NAME有两个成员,
第一个Hint,就是函数编号.
第二个,Name,函数名

和它门当户对的ExportByName是啥样的呢?只记住了一个函数名

奇怪了,ExportByName比ImportByName少一个Hint成员,这是为啥呢?
观察一下notepad.exe的ImportByName[0]:

这里Hint是489,这不禁让人浮想联翩,这个数是怎么来的呢?
会不会是ExportByName数组的下标?回家看看吧

还真是,ImportByName[0].Hint就是GlobalUnlock函数在ExportByName中的下标
显然在notepad.exe这种应用程序中使用函数名Name或者函数下标Hint导入动态库的函数都可以达到链接目的
到此貌似就了解了动态链接干活的过程,然而还有两个问题没有解决,
1.为啥NumberOfNames和NumberOfFunctions值相同,但是要记两个
2._IMAGE_EXPORT_DIRECTORY的AddressOfNameOrdinals成员貌似还没有发挥作用
核心原理给出的动态链接器的工作过程:
1.动态链接器从exe的ImportByName[x]拿到函数名Name
2.动态链接器遍历dll的ExportByName[]数组,用Name匹配每一项的函数名
3.如果匹配到,记录此时在ExportByName中的下标i
4.用i去查dll的AddressOfNameOridinals指向的数组,用刚才得到的下标i作为下标查AddressOfNameOridinals数组,得到AddressOfNameOridinals[i]=INDEX,这是下标
5.用新下标INDEX(AddressOfNameOridinals[i])去查AddressOfFunctions,得到AddressOfFunctions[INDEX]得到Name函数的相对虚拟地址
如果按照之前认为的hint就是函数下标的方法,那么这个想象的过程应该是
1.动态链接器从exe的ImportByName[x]拿到函数名Name
2.动态链接器遍历dll的ExportByName[]数组,用Name匹配每一项的函数名
3.如果匹配到,记录此时在ExportByName中的下标i
4.用下标i去查AddressOfFunctions,得到AddressOfFunctions[i]得到Name函数的相对虚拟地址
而实际的方法多查了一个AddressOfNameOridinals表,这是为啥呢?
还又得回到NumberOfFunction和NumberOfName,这俩值一定一样吗?
重新考虑动态库的导出函数一定要有名字吗?
如果exe能够根据ImportByName.hint找到该函数,完全可以不用名字
那么动态库导出的函数就可以有匿名函数.
这时匿名函数就不能使用ExportByName机制了,因为它根本没名字.
如果每个函数都有名字,那么显然AddressOfNameOrdinals,AddressOfFunctions,AddressOfNames都有相同数量的表项
如果有一个匿名函数,那么AddressOfNames就得少一项.
AddressOfFunctions数组啃腚记载了所有数组的地址,包括匿名的和有名的
AddressOfNameOrdinals从名字上看,名称序列,它实际完成了一个下标转换.一个有名字的函数,在所有函数中的下标是多少
而AddressOfNames是记录,一个函数名对应的下标是多少
整个映射过程是这样的:
1 | 函数名 ->查AddressOfNames->函数在AddressOfNames中的下标 |
那么AddressOfNameOrdinals的项数应该和AddressOfNames相同,有多少个具名函数,ordinal就得提供多少个映射服务
用ida观察kernel32.dll的AddressOfOrdinals表,由于所有函数具名,因此AddressOfOrdinals实际上完成了一个$f(x)=x$的映射,
第一个具名函数就是kernel32中所有函数的第一个函数
第n个具名函数就是kernel32中所有函数的第n个函数
2
3
4
5
6
7
8
9
10
11
.text:77E63E68 ;
.text:77E63E68 byte_77E63E68 db 2 dup(0), 1, 0, 2, 0, 3, 0, 4, 0, 5, 0, 6, 0, 7, 0
.text:77E63E68 ; DATA XREF: .text:77E62164↑o
.text:77E63E68 db 8, 0, 9, 0, 0Ah, 0, 0Bh, 0, 0Ch, 0, 0Dh, 0, 0Eh, 0
.text:77E63E68 db 0Fh, 0, 10h, 0, 11h, 0, 12h, 0, 13h, 0, 14h, 0, 15h
.text:77E63E68 db 0, 16h, 0, 17h, 0, 18h, 0, 19h, 0, 1Ah, 0, 1Bh, 0, 1Ch
.text:77E63E68 db 0, 1Dh, 0, 1Eh, 0, 1Fh, 0, 20h, 0, 21h, 0, 22h, 0, 23h
.text:77E63E68 db 0, 24h, 0, 25h, 0, 26h, 0, 27h, 0, 28h, 0, 29h, 0, 2Ah
.text:77E63E68 db 0, 2Bh, 0, 2Ch, 0, 2Dh, 0, 2Eh, 0, 2Fh, 0, 30h, 0, 31h
.text:77E63E68 db 0, 32h, 0, 33h, 0, 34h, 0, 35h, 0, 36h, 0, 37h, 0, 38h显然对于一个所有函数都具名的动态库kernel32,AddressOfNameOrdinals是纯纯的five.
但是总是得照顾一些搞特殊的动态库
AddressOfFunctions又叫EAT,export address table
节区头表
节区头表,或者叫做”节头表”,实际上是节区头结构体数组
数组的每个元素都是一个节区头
1 | typedef struct _IMAGE_SECTION_HEADER { |
Name[IMAGE_SIZEOF_SHORT_NAME]
节区名称,其中#define IMAGE_SIZEOF_SHORT_NAME 8,即名称最长不得超过8字节

010editor给出的注释是”可以不以0结尾”,这与我们平时使用的字符串以'\0'结尾不同
原因是Name无足轻重,机器不关心节叫啥,只关心节的排列顺序
PhysicalAddress&VirtualSize
哥俩生异型啊,连体婴儿是吧
1 | union { |
VirtualAddress
节在进程加载进入虚拟地址空间之后的相对虚拟地址
SizeOfRawData
节大小
根据相对虚拟地址和节大小就可以确定节在虚存中的范围

在notepad.exe中VirtualAddress=1000h,则绝对虚拟地址就是1001000,
大小是6E00h,则节的范围就是0x1001000h~0x1007E00h
这个范围中,最开始是.idata节,然后是.text节
PointerToRawData
节在磁盘文件中的起始地址
PointerToRelocations
重定位使用,在exe中该值无用,在可重定位目标模块.
obj中该值指向IMAGE_RELOCATION 结构体,重定位要用
具体怎么重定位,需要学习核心原理第16章
PointerToLinenumbers
行号表指针,调试使用
NumberOfRelocations
obj中该值作为下标,指向重定位表对应该节的表项
Characteristics
枚举值,节属性,起保护作用,多个属性则按位或
| Flag | Meaning |
|---|---|
| 0x00000000 | Reserved. |
| 0x00000001 | Reserved. |
| 0x00000002 | Reserved. |
| 0x00000004 | Reserved. |
| IMAGE_SCN_TYPE_NO_PAD0x00000008 | The section should not be padded to the next boundary. This flag is obsolete and is replaced by IMAGE_SCN_ALIGN_1BYTES. |
| 0x00000010 | Reserved. |
| IMAGE_SCN_CNT_CODE0x00000020 | The section contains executable code. |
| IMAGE_SCN_CNT_INITIALIZED_DATA0x00000040 | The section contains initialized data. |
| IMAGE_SCN_CNT_UNINITIALIZED_DATA0x00000080 | The section contains uninitialized data. |
| IMAGE_SCN_LNK_OTHER0x00000100 | Reserved. |
| IMAGE_SCN_LNK_INFO0x00000200 | The section contains comments or other information. This is valid only for object files. |
| 0x00000400 | Reserved. |
| IMAGE_SCN_LNK_REMOVE0x00000800 | The section will not become part of the image. This is valid only for object files. |
| IMAGE_SCN_LNK_COMDAT0x00001000 | The section contains COMDAT data. This is valid only for object files. |
| 0x00002000 | Reserved. |
| IMAGE_SCN_NO_DEFER_SPEC_EXC0x00004000 | Reset speculative exceptions handling bits in the TLB entries for this section. |
| IMAGE_SCN_GPREL0x00008000 | The section contains data referenced through the global pointer. |
| 0x00010000 | Reserved. |
| IMAGE_SCN_MEM_PURGEABLE0x00020000 | Reserved. |
| IMAGE_SCN_MEM_LOCKED0x00040000 | Reserved. |
| IMAGE_SCN_MEM_PRELOAD0x00080000 | Reserved. |
| IMAGE_SCN_ALIGN_1BYTES0x00100000 | Align data on a 1-byte boundary. This is valid only for object files. |
| IMAGE_SCN_ALIGN_2BYTES0x00200000 | Align data on a 2-byte boundary. This is valid only for object files. |
| IMAGE_SCN_ALIGN_4BYTES0x00300000 | Align data on a 4-byte boundary. This is valid only for object files. |
| IMAGE_SCN_ALIGN_8BYTES0x00400000 | Align data on a 8-byte boundary. This is valid only for object files. |
| IMAGE_SCN_ALIGN_16BYTES0x00500000 | Align data on a 16-byte boundary. This is valid only for object files. |
| IMAGE_SCN_ALIGN_32BYTES0x00600000 | Align data on a 32-byte boundary. This is valid only for object files. |
| IMAGE_SCN_ALIGN_64BYTES0x00700000 | Align data on a 64-byte boundary. This is valid only for object files. |
| IMAGE_SCN_ALIGN_128BYTES0x00800000 | Align data on a 128-byte boundary. This is valid only for object files. |
| IMAGE_SCN_ALIGN_256BYTES0x00900000 | Align data on a 256-byte boundary. This is valid only for object files. |
| IMAGE_SCN_ALIGN_512BYTES0x00A00000 | Align data on a 512-byte boundary. This is valid only for object files. |
| IMAGE_SCN_ALIGN_1024BYTES0x00B00000 | Align data on a 1024-byte boundary. This is valid only for object files. |
| IMAGE_SCN_ALIGN_2048BYTES0x00C00000 | Align data on a 2048-byte boundary. This is valid only for object files. |
| IMAGE_SCN_ALIGN_4096BYTES0x00D00000 | Align data on a 4096-byte boundary. This is valid only for object files. |
| IMAGE_SCN_ALIGN_8192BYTES0x00E00000 | Align data on a 8192-byte boundary. This is valid only for object files. |
| IMAGE_SCN_LNK_NRELOC_OVFL0x01000000 | The section contains extended relocations. The count of relocations for the section exceeds the 16 bits that is reserved for it in the section header. If the NumberOfRelocations field in the section header is 0xffff, the actual relocation count is stored in the VirtualAddress field of the first relocation. It is an error if IMAGE_SCN_LNK_NRELOC_OVFL is set and there are fewer than 0xffff relocations in the section. |
| IMAGE_SCN_MEM_DISCARDABLE0x02000000 | The section can be discarded as needed. |
| IMAGE_SCN_MEM_NOT_CACHED0x04000000 | The section cannot be cached. |
| IMAGE_SCN_MEM_NOT_PAGED0x08000000 | The section cannot be paged. |
| IMAGE_SCN_MEM_SHARED0x10000000 | The section can be shared in memory. |
| IMAGE_SCN_MEM_EXECUTE0x20000000 | The section can be executed as code. |
| IMAGE_SCN_MEM_READ0x40000000 | The section can be read. |
| IMAGE_SCN_MEM_WRITE0x80000000 | The section can be written to. |
比如notepad.exe中的text节
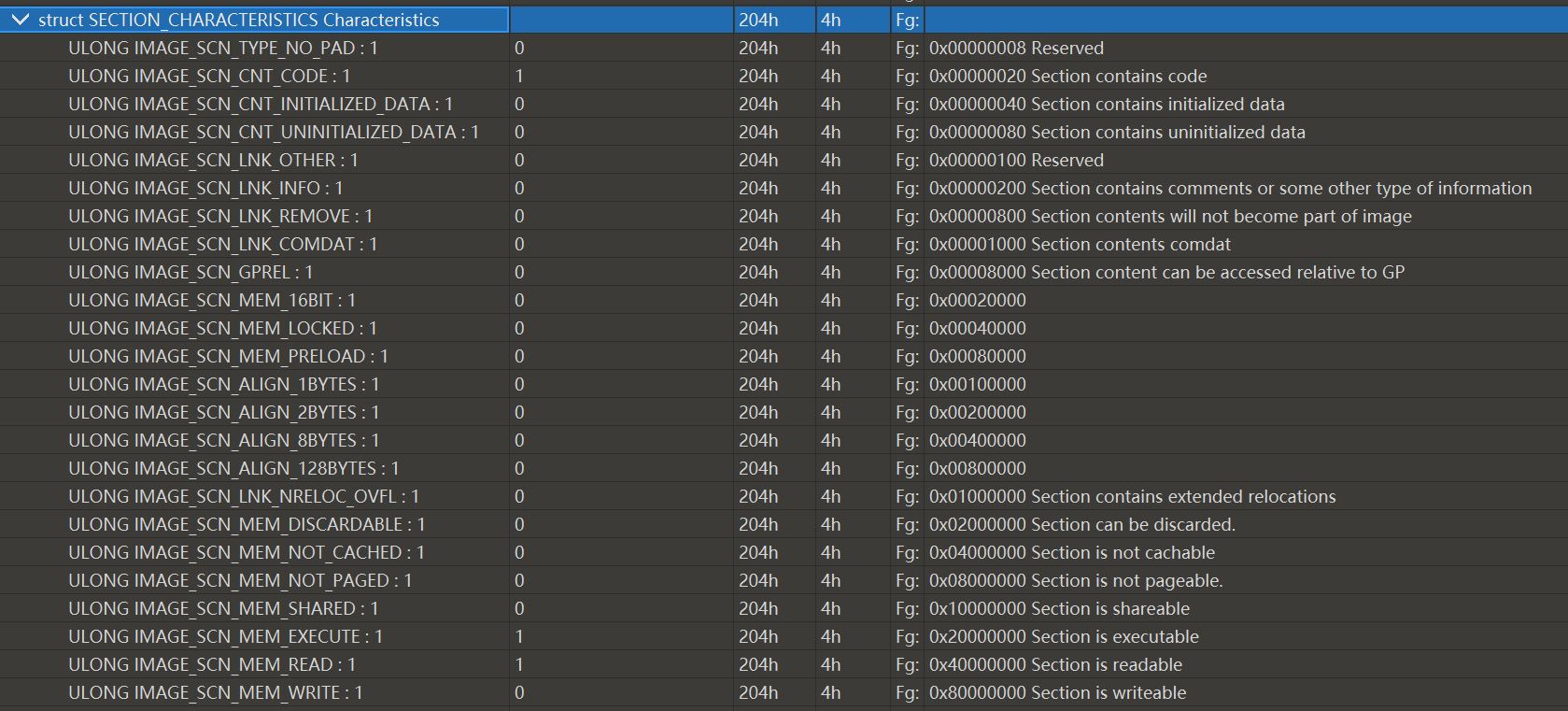
其中开启了三个标志
节包含代码,节可执行,节可读
其他的都不可,比如节不可写
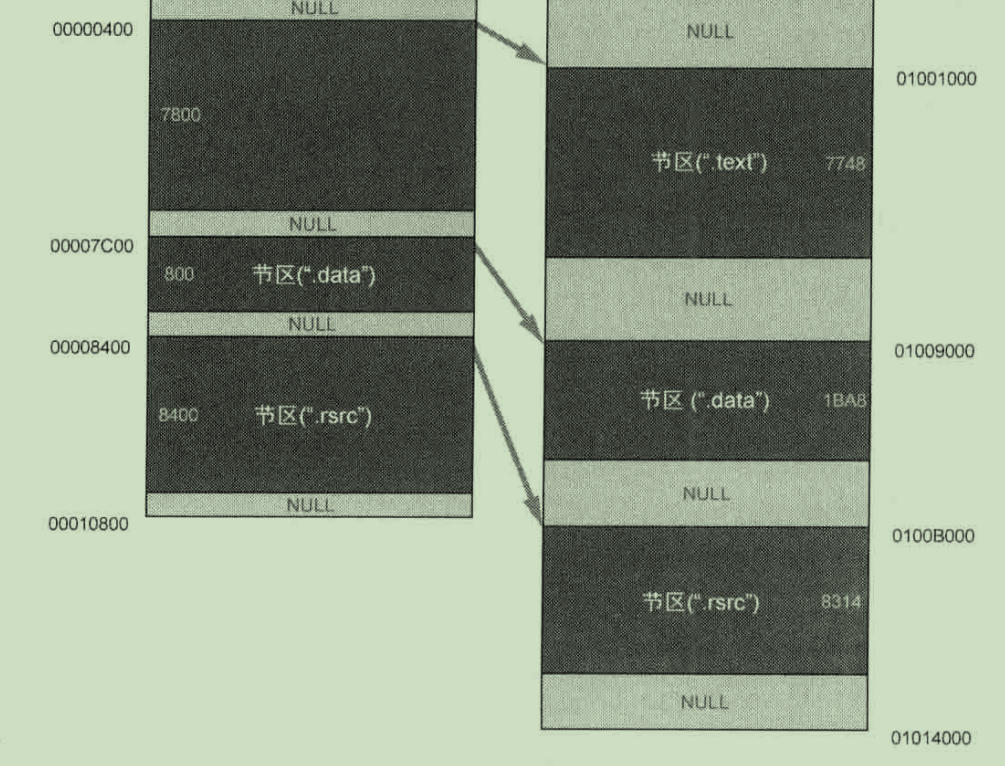
RVA to RAW
这一部分010editor已经帮我们算好了
可执行文件要运行时,首先要装载进入虚拟内存.
这个映射过程不是简单的找一个ImageBase然后照搬磁盘中的文件到虚拟内存就完了
诚如是则文件中和内存中该文件应该一样大.
而实际上节区有各种对齐要求,因此虚拟内存中的文件映像往往更大
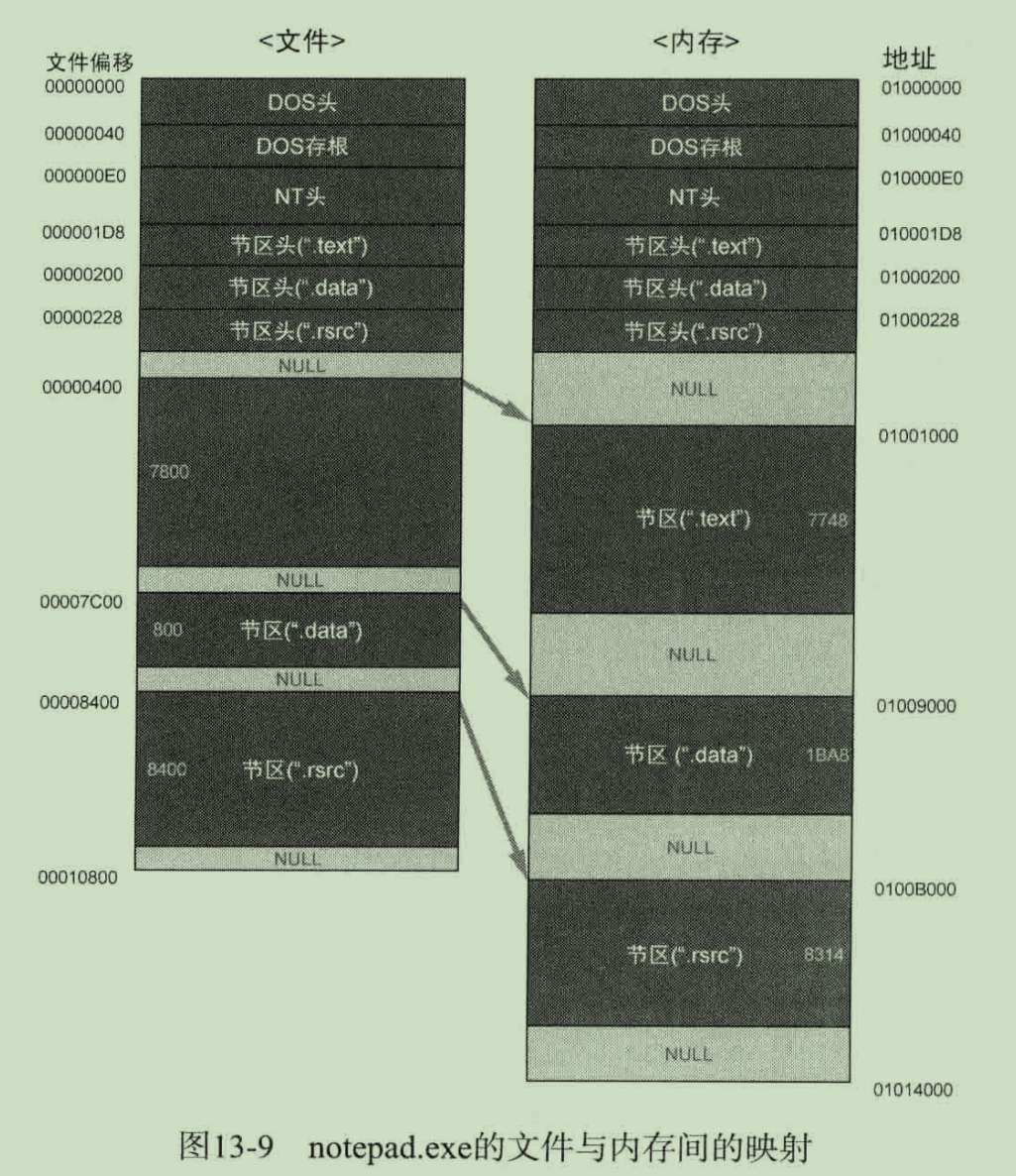
从notepad.exe的例子上可以看出,PE头部分确实是找一个ImageBase然后原封不动照搬的
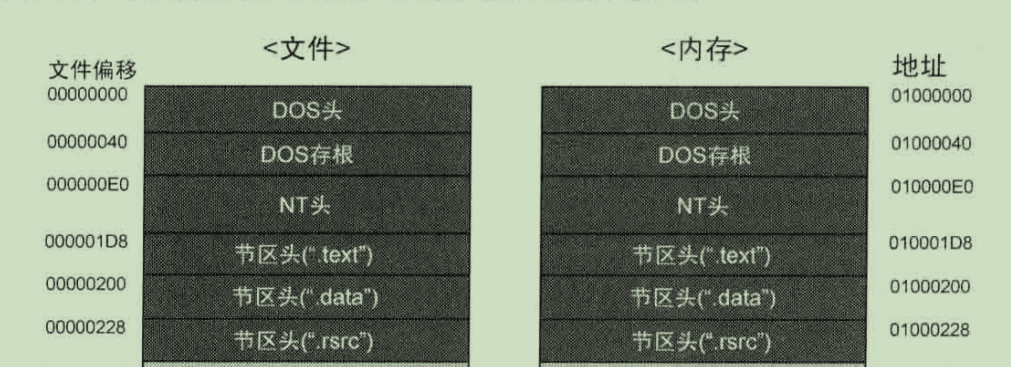
文件在磁盘中存放时,基地址是0,搬到内存中假设映像基地址是ImageBase=0x1000000
可想而知,NT头如果在文件中的偏移量是0xE0则映射到进程地址空间中的虚拟地址就是ImageBase+0xE0=0x10000E0
可是后来的节区就得根据对齐要求来了
这个转化关系是什么呢?
权位指南上给出的算法是

我看了好半天没看明白,
原因一是VirtualAddress和书上先前给出的符号意义不同造成了混淆,
二是对符号的定义没有完全理解,
下面复习一下这几个符号的意义并推导这个计算公式
要利用到_IMAGE_SECTION_HEADER头中的PointerToRawData,VirtualAddress,SizeOfRawData这几个值
复习一下这几个值的含义
PointerToRawData:磁盘文件中节区的起始位置,由于文件的起始地址为0,那么PointerToRawData也就是节区基地址相对于0的偏移量,也就是RAW
VirtualAddress(不要被名字迷惑):RVA,即虚拟地址空间中相对于映像基址ImageBase的偏移量
这里一定要区分清楚VirualAddress和VA
VirtualAddress是定义在节头中的成员,实际上表示的是RVA,因为进程不到装载是不知掉其ImageBase在哪里的
VA=RVA+ImageBase=VirtualAddress+ImageBase
SizeOfRawData:本节区的大小
不管是躺在文件中还是站在内存里,SizeOfRawData大小永远不变,即一个节中间不会随便插入空隙
比如对于data节,
PointerToRawData=0x7C00
ImageBase=0x1000000
VA=0x1009000=ImageBase+RVA得到VirtualAddress=RVA=0x9000
那么对于任意一个节区在虚拟内存中的起始地址,减去其节头中的成员VirtualAddress就得到ImageBase,
假设
VA(x),RVA(x)分别表示符号x在虚拟地址空间中的实际地址和相对于ImageBase的偏移量
RAW(x)表示符号x在文件中的偏移量
假设section表示任意节
section.VirtualAddress表示该节节头中的VirtualAddress成员
section.PointerToRawData表示该节节头中的PointerToRawData成员
显然对于节区有
RVA(section)=section.VirtualAddress
RAW(section)=section.PointerToRawData
现在考虑对于任意符号x,给定其虚拟地址空间中的实际地址VA(x),其RVA和RAW怎样计算呢?
ImageBase装载后就知道了,因此可以轻松得到RVA(x)=VA(x)-ImageBase
由于每个节的RVA(section)=section.VirtualAddress也是已知的,该节的大小section.SizeOfRawData也是已知的,那么可以得到
第i个节(假设节按照地址递增编号0到n)section[i]管理的相对虚拟地址范围是
[section.VirtualAddress, section.VirtualAddress+section[i].SizeOfRawData)
如果RVA(x),说明x根本没有落在节区,甚至还没有出PE头,
而前面分析过了,PE头装载进入虚拟内存就是加了一个ImageBase,因此此时RAW(x)=RVA(x)
否则,x落在了节区,需要先判断x落在了哪个节,咋判断呢?
1 | for i in [0,n] |
这就好比一层楼高3米,我闭着眼爬楼爬了8米,问我现在的位置?
一楼[0,3),二楼[3,6),三楼[6,9)
8在[6,9)这个范围内,因此我在3楼
假设根据刚才的算法,已经知道了x落在section[i],
那么x相对于该节起始位置的偏移量就是RVA(x)-section[i].VirtualAddress
显然在文件中,x相对于其所在节的偏移量也是这个数,这就好比058班的sjf考数据结构时班内考号是4,换个教室考C++时班内考号还是4
因此得到
1 | RAW(x)-section[i].PointerToRawData=RVA(x)-section[i].VirtualAddress |
移项有
1 | RAW(x)=RVA(x)-section[i].VirtualAddress+section[i].PointerToRawData |
这就和权威指南给出的公式很像了

上述过程可以总结为:
1.查x落在哪个节区
2.查x相对于该节区的偏移量
3.节区相对于文件基地址的偏移量+x相对于该节区的偏移量=x相对于文件基地址的偏移量