玩具内核V0.2
LDT和TSS
0.1内核版本时内核只用到了GDT,没有用到LDT.
这就导致内核和所有用户任务占用的内存空间是放到一起存储的
内核当然不愿意和肤浅的用户程序在同一层上
于是使用LDT让用户任务成为人下人

TSS:Task Segment State,任务状态表,当任务被切换时,本次执行到最后的堆栈指针,程序计数器,各种通用寄存器等都要保存,方便下一次继续执行本任务的时候恢复状态
TSS结构
这里除了ESP指向的堆栈,还额外定义了三个堆栈,即ESP0,1,2分别指向的堆栈
这是因为堆栈段的权限必须始终保持和当前代码段权限相同
用户程序权限最低,它可能调用2,1,0环上的代码,那么就得跟着切换堆栈
多个附加堆栈段都会在程序自己的LDT中注册,在TSS中只会保留这些附加堆栈的选择子和段内偏移量

LDT:局部段描述符表,只维护一个任务的分段,比如堆栈段,数据段,代码段
LDTR:LDT寄存器,负责记录当前正在执行的任务的LDT基地址,LDTR只有一个,哪个任务正在执行就用LDTR记录哪一个的LDT基址
TR:任务状态表寄存器,也是只有一个,指向当前正在执行的任务
在段选择子中第三位(位2)

就是区分该索引是指向GDT的还是LDT的,由于这个段选择子是当前任务给出的,因此此时的LDT必然是当前任务的LDT,此时LDTR必然爆粗的是当前任务的LDT基地址,只需要拿着索引去查LDT就可以获得段地址了
LDT和GDT还有一点不同是,GDT[0]是空的不使用,但是LDT[0]是可用的
私有空间和公有空间

每个程序都有自己的代码段数据段堆栈段等私有空间,多个程序共享内核的系统调用还有运行库,这属于公有空间
一般情况下程序运行在私有空间,只有需要系统调用的时候或者需要调用库函数的时候,才会转到公有空间去执行
特权级
特权级定义
CPL:当前正在执行的代码的权限
RPL:段选择子权限
实际由于CS总是指向当前正在执行的代码段你,大多数时候RPL和CPL是一个东西
只有低级函数调用高级依存代码段函数时有别,后面会提到
DPL:段描述符权限
IOPL:IO当前代码段你得IO特权级
权限占用两位,能够标识的特权级就是0,1,2,3,数字越大则权限越低,0环为最高权限.

操作系统内核一般运行在0环,权限最高.
用户程序的权限最低,在3环
一个位于三环的用户程序,不管访问什么段,其设置的段选择子中RPL只能是3
比如
如果其使用系统调用则cs中Index设置为操作系统代码段,RPL=3
如果其引用了运行库的一个全局数据,则ds中的Index设置为运行库数据段,RPL=3
而一个位于0环的段,其段描述符中的DPL就是0
特权指令:只能由特权级0的代码执行的指令,比如停机指令HLT,还有对控制寄存器CR0的写操作的指令,lgdt,lldt,ltr等等
IOPL:IOPL是处理器中程序状态字的两位,用来表征当前正在执行的代码段的IO权限

严禁低级代码段访问高级数据段
数据段的特权级规则
数据段的DPL决定了其最低访问权限,只允许权限至少相同或者更高的代码段访问
0环的数据段只能被0环的代码段访问(门当户对)
3环的数据段可以被0,1,2,3环的代码段访问(DPL=3,RPL=0,1,2,3)
内核数据段是在0环上的,用户程序的代码段是在3环上的,显然用户程序是没法访问内核数据段的
严禁控制向低特权级转移
代码段的特权级规则
代码段有依从的和非依从的之分
非依从的代码段讲究一个门当户对,2环的代码段只允许被2环的代码段啊调用,0,1,3都不行.也就是权限高的不行,权限低的也不行
依从的代码段还允许被特权低的代码段调用,即2环的依从的代码段可以被2,3环的代码段调用,不允许被0,1环的代码段调用.这是因为特权级越高的代码段,其安全性越高,0环的代码段基本都是写死的不会出事.从3环调用0环是系统调用的方向,安全性只能是越来越高
但是0环不敢随意调用3环,如果用户自己写一个3环的病毒,被操作系统调用了就寄了
这貌似根数据段的特权规则正好相反,
数据段只允许权限同级或者更高的代码段调用.
而代码段顶多允许同级或者权限更低的代码段调用.
这就好比将校可以任意获取军士的情报,但是军士不能获取将校的情报
军士可以执行将校的命令,但是将校不能执行军士的命令
显然一个将军相比于一个士兵是更不容易叛变的,并且保密等级更高的
如何区分一个代码段是不是依从的呢?
代码段描述符的TYPE字段有一个C位,
如果C=0则是非依从的,只能被同级调用.
如果C=1则是依从的,允许同级和下级调用

严禁控制向低特权级转移
严禁控制向低特权级转移
严禁控制向低特权级转移
针对这句话貌似可以找很多茬:
一是,当系统调用返回到用户函数时,不就是从0环的内核代码段返回到3环的用户程序代码段了吗?实际上依存的代码段执行时,当前特权级CPL不会改变,即保持用户程序的权限3环.那么这样系统调用整个过程都是在3环上的,没有涉及控制匆匆高级到低级转移.
二是,win32程序设计时,操作系统是可以主动调用窗口过程回调函数的,这种情况是否属于0环的操作系统调用了3环的用户函数?有了茬一的解释,茬二也可以解释
消息循环
2
3
4
5
{
TranslateMessage(&msg);
DispatchMessage(&msg);
}DispatchMessage是被3环程序调用的3环API,往后即使调用0环的依存内核函数,CPL也一直保持3环不变.回调函数wndproc是在啥时候调用的呢?可以理解为:
用户程序,with CPL=3->DispatchMessage->内核高DPL函数->回调函数wndproc->返回
从一开始用户程序,CPL就是3了,这条链上一直是3,因此没有违背”严禁控制向低特权级转移”这条规则
门描述符
在特权级之间转移控制的另一种方法,即使用门
每一个符号都需要一个调用门,之所以叫做”门”是因为它确实就像一个门,在调用一个符号之前需要先经过它的门,让门来检测第一关,能否调用该符号
调用门:
jmp far 将控制转移到高级代码段,不改变CPL
call far 将控制转移到高级代码段,改变CPL
也是不允许从将控制从高级转移到低级,但是允许从高级返回到低级,即call far之后的返回是从高级转移到低级的
IO操作比如访问硬盘,必须使用调用门
门实际上是一个段描述符,在LDT或者GDT中,占用的大小和普通的段描述符一样,都是32字节,但是每一位的意义和普通的段描述符不同
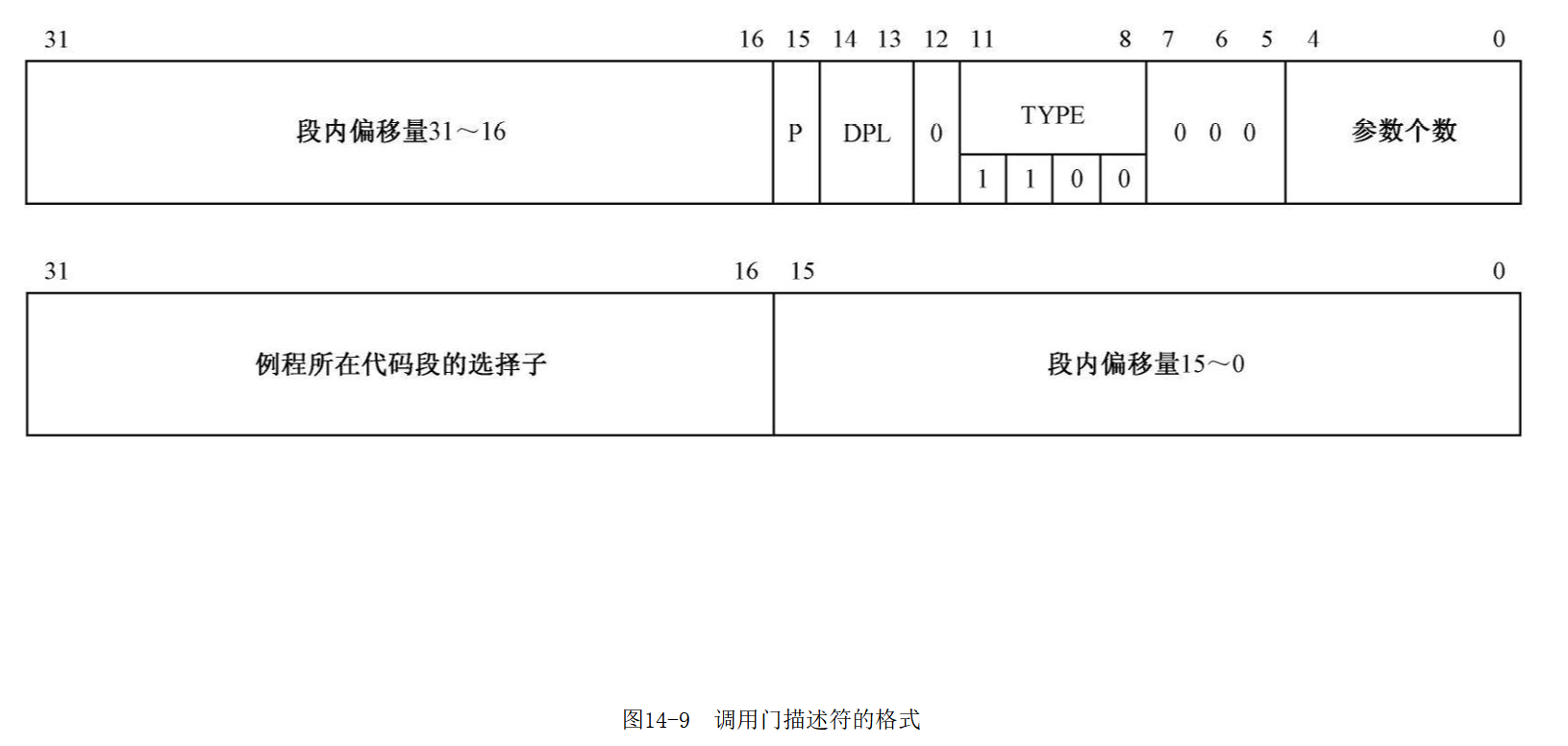
最低和最高的两个字是段内偏移量的低字和高字
第二个字是例程所在代码段的选择子
第三个字是属性
| 属性 | 意义 |
|---|---|
| P | 1有效,如果是0则调用该门导致处理器异常中断 |
| DPL | 访问目标代码段需要的权限下限(目标代码段的DPL决定的是上限) |
| 0 | 未使用固定为0 |
| TYPE | |
| 000 | 未使用,固定为0 |
| 栈传递的参数个数 | 存放该门对应的代码调用需要几个函数, 方便切换堆栈的时候把参数从老栈搬到新栈上来 由于参数个数一共有5位,因此最多可以传31个参数 |
当栈切换时,SS:ESP会被自动更新成新的堆栈,然后根据调用门的栈传递参数个数从老栈顶上取下相同字节数来拷贝到新栈上作为参数.这个事是处理器自动干的,程序员不用管
如果是用寄存器传递参数则根本不需要拷贝
关于
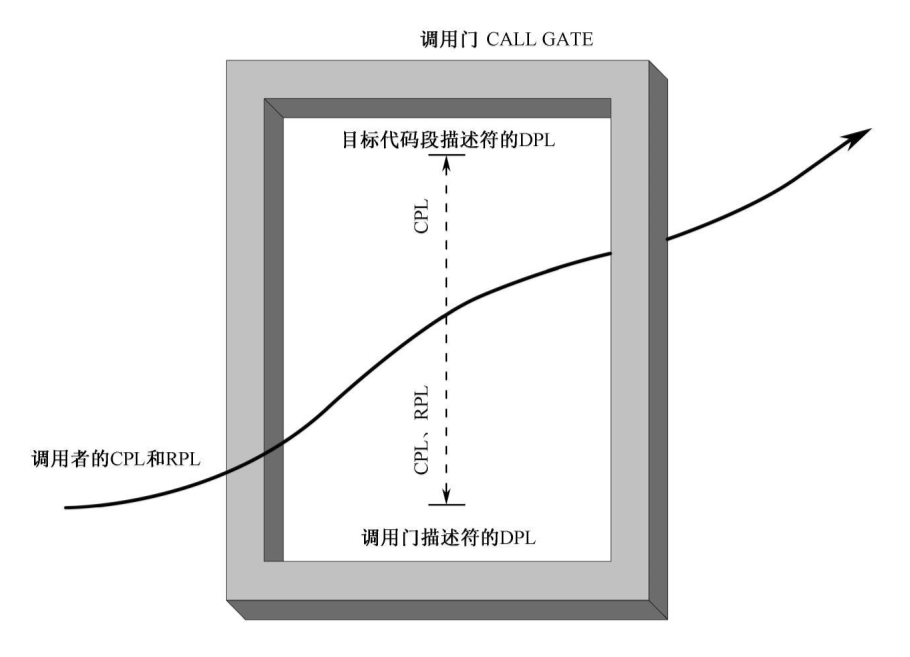
如果一个调用门的DPL=2,这是一个下限,那么只有同级或者更高权限的特权级为0,1,2的代码可以通过该门.
钻法律空子
现在已经有了一些游戏规定
1.在不使用调用门时
数据段只能被同级或者高级代码段访问
代码段只能被同级或者低级代码段调用,但是CPL不变
2.在使用调用门时
call far将控制转移到高级代码段时,会将CPL从低级改成高级,并且允许从高级返回到低级并再修改CPL为低级
3.有一个0环的系统调用read_hard_disk(logicalnumber,selector,offset),为用户程序提供读取磁盘到内存的服务
它接收三个参数,逻辑扇区号logicalnumber,写入内存的段选择子selector,写入内存的段偏移量offset
意思是读取指定logicalnumber扇区,拷贝到内存的selector:offset这个位置
上述游戏规则看似完备,实际上还是存在漏洞,这样想:
操作系统开发者希望的用户这样使用该系统调用:
1 | read_hard_disk(逻辑扇区号,用户程序数据段选择子,用户程序数据段偏移量); |
翻译到图上就是

但是还有外门邪道的用法,如果用户通过一些手段知道了内核数据段的选择子,比如通过wingdb内核调试等方式,反正只要想,就能获取,它这样使用该系统调用
1 | read_hard_disk(逻辑扇区号,内核数据段选择子,内核数据段偏移量); |
画到图上

你不是不允许3环上的用户程序访问0环上的内核数据段吗?
我想办法让0环上的代码访问0环的内核数据段不就可以了吗?
我得先想办法让我的CPL从3环的用户应用提升到0环,怎么提升呢?显然只有一个call far可以做到
而该系统调用恰好就是call far调用的,自然而然就把CPL提升到0了,此时0环上的内核例程代替3环上的用户程序,向0环的内核数据段写入了磁盘扇区数据
如果该用户提前将恶意数据写到该扇区,或者说用一个没用的扇区覆盖了该内核数据段的所有,如果该数据段是比较重要的比如内核堆栈,内核就寄了
那么能否禁用
call far呢?使用jmp far调用不行吗?还真不行,如果可以使用jmp far,就意味着CPL一直在3环保持不变,内核例程去访问磁盘时还是在3环上,
显然这是不可以的,因为访问磁盘的函数必须是非依存0环权限的,
否则如果是0环依存权限,则用户程序可以不通过系统调用,而是直接调用该访问磁盘的函数了,这样0环就没有存在的意义了
完善法律
可以先用jmp far跳转到依存的内核检查例程,
该检查例程作为入口在call far进入0环的访问磁盘例程呢,
访问磁盘例程把数据先读到内核入口例程的缓冲区,
等磁盘例程返回后,内核例程回复到3环权限再把缓冲区尝试写到目标内存中.
这样在3环上是不可能往0环的内核数据段写东西的
这个猜想正是现行的解决方案,即”再增加一道门卫”,这个检查例程就是门卫
1 | graph LR |
如果是应用程序调用该系统调用,则读写内存的时候一定CPL=3,如果参数selector是一个内核段的选择子,则CPL=3显然是无法访问的
1 | graph LR |
如果是系统函数调用该系统调用则全程在ring0,不需担心任何问题
1 | graph LR |
也就是说,调用者调用该系统调用的时候,操作系统会根据调用者的段选择子中的RPL设置CPL,每当发生mov ds,ax这种指令的时候,处理器就会检查

编程实现
主引导扇区和上一个内核时相同,内核的头部也是相同的,这属于内核和主引导扇区之间的协议,理论上是永远不变的
两个内核都是从start标号处开始执行,内核开始执行时,主引导扇区中已经给内核准备好了代码段,数据段,堆栈段,并且处理器也运行在保护模式了
然后两个内核都打印了CPU信息,之后的逻辑就不同了
在进入内核start之前,GDT是这样的

start
内核开始的标号
上来先打印字符串还有CPU信息,不再分析了
安装调用门
遍历符号表,给每个符号(不管是函数还是变量符号)都在GDT中建立一个门描述符
为啥要建立门描述符?
内核中公用例程段的符号权限都是0,也就相当于系统调用,如果想让用户程序也使用他们,那就必须安装调用门
1 | mov ecx,core_data_seg_sel ;使ds指向核心数据段 |
这里调用了sys_routine_seg_sel:make_gate_descriptor函数,该函数的调用约定是:
eax存放门代码的段偏移量
bx存放门代码的段选择子
cx存放段属性,按照段描述符高16位的格式存放
返回值edx:eax表示完整的调用门描述符
然后调用set_up_gdt_descriptor在GDT中注册调用门,用cx返回该GDT描述符的段选择子
该选择子被回填到原来的符号选择子位置(原来存放的是符号所在段选择子)
这里回填只改变了选择子,没有改变偏移量
调用门描述符中会保存该符号的段选择子和段内偏移,原来该符号也会保存一个段内偏移
因此段内偏移会被保存两次
内核符号表表项的变化:
| 符号成员 | 段内偏移 | 大小 | 原意义 | 新意义 |
|---|---|---|---|---|
| 符号名 | 0(edi指向该处) | 256Bytes | 符号名 | – |
| 符号偏移量 | 256 | 4Bytes | 符号段内偏移量 | – |
| 符号段选择子 | 260 | 2Bytes | 符号所在段选择子 | 符号调用门的选择子 |
现在要调用一个符号,查符号表获得的是其调用门选择子,
用该调用门选择子查GDT获得的是调用门描述符
用调用门描述符中的段选择子查GDT获得符号所在段地址
加上调用门描述符中的符号段内偏移才得到符号的线性地址
循环为每一个内核符号建立调用门后,GDT表长这样

测试调用门
1 | ;对门进行测试 |
如果想要使用调用门,要么是jmp far,要么是call far
打印message_2时,使用call far调用[salt_1+256] 这个位置,正好是put_string符号的段内偏移量起始地址
call far会将其目的操作数开始的低32个字节作为段内偏移量,将高16字节作为段选择子,如果这是个调用门则忽略段内偏移量,因为调用门描述符中还会记录这个符号的段内偏移量
打印message_3时,没有使用call far或者jmp far指令,也就是说不会使用调用门.实际上确实如此,这里直接用段选择子:段内偏移量进行调用,根本没有访问符号表.因为内核代码本来就是最高权限0环,内核代码调用内核公用例程段是门当户对的
这里提示我们即使一个符号有调用门,也不一定非要使用调用门调用该符号,老方法对于内核代码调用内核代码还是可用的
创建任务控制块
TCB,Task control Block,任务控制块(可以理解为进程控制块),这个玩意纯粹是我们为了维护程序执行状态,比如各种通用寄存器,堆栈指针,程序计数器等设置的,不是处理器的硬性要求.
对于一个允许多任务轮转的操作系统,必须要有数据结构维护任务执行上下文,方便下一次调度到该任务的时候可以继续执行下去
1 | ;创建任务控制块。这不是处理器的要求,而是我们自己为了方便而设立的 |
allocate_memory函数使用ecx作为希望分配的字节数,使用ecx返回申请地址空间的线性首地址
这里申请了0x46字节的内存空间,接着给append_to_tcb_link注册为TCB
append_to_tcb_link是一个近函数,它使用ecx作为TCB(Task control Block)的线性地址,将该TCB加到已有任务链上
这个玩具内核使用链表维护所有的TCB数据,每个TCB的最开始的4个字节是指向下一个TCB的指针,剩下0x42个字节是存放本任务控制信息的
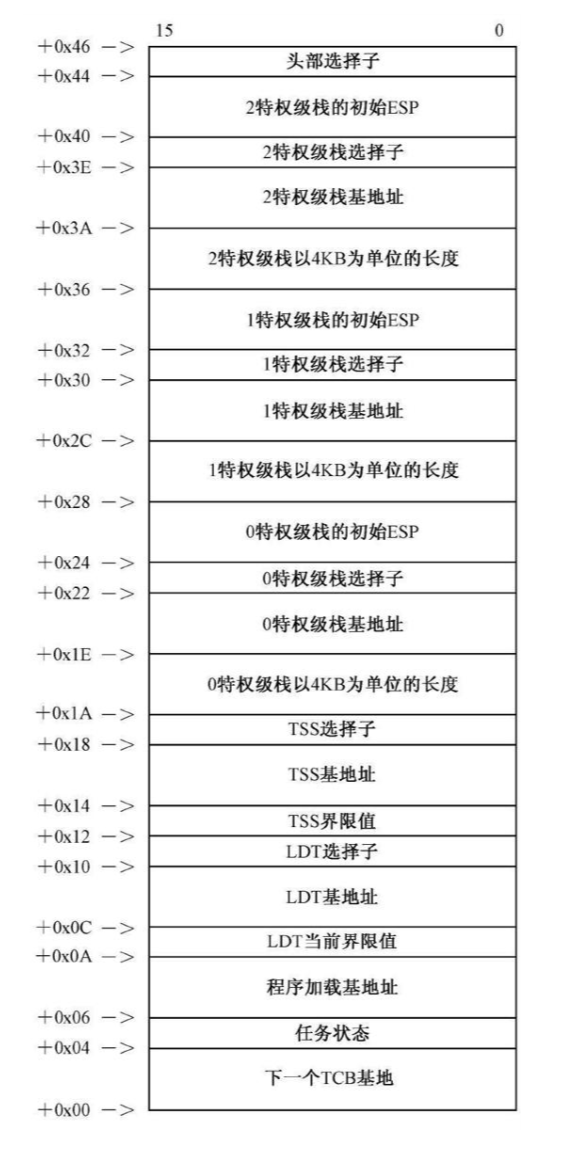
多个TCB以链表形式连接,这就是append_to_tcb_link函数的工作了

下面详细研究一下append_to_tcb_link干了啥
1 | tcb_chain dd 0 ;内核数据段定义的TCB链条首地址指针 |
教材上把这个过程总结成了流程图

加载器加载用户程序
1 | push dword 50 ;用户程序位于逻辑50扇区 ;栈次顶函数 |
加载器使用栈传递参数,栈顶作为加载目标地址,栈次顶作为用户程序所在的逻辑扇区号
由于加载器要给用户程序建立LDT,而原来的加载器只是将用户程序的各段一并注册到GDT,
因此两章的加载器会有较大不同,下面研究一下本章的加载器干了啥
栈传参数
加载器使用栈传递参数,执行call命令之后,栈上是这样的

开端
函数开端时又压栈保护调用者寄存器
1 | pushad |
这三步执行完毕之后,栈的状态

在加载器返回直线,ebp就一直指向调用者寄存器的最顶上,局部变量的最底下的位置,也就是加载器正儿八经的栈帧底部
设置es段选择子
设置es段选择子指向4G数据段
1 | mov ecx,mem_0_4_gb_seg_sel |
申请LDT空间,写入TCB
1 | mov esi,[ebp+11*4] ;从堆栈中取得TCB的基地址 |
ecx=160向allocate_memory申请160字节的内存空间,用于存放本任务的LDT表,由于一个LDT表项占用8字节,并且0号表项可用,因此该LDT表最多放20个描述符
返回该内存空间的首地址放到[es:esi+0x0c],实际上是一个线性寻址,es段基址为0
es:esi保存的是TCB的内存基地址
[es:esi+0x0c]即TCB的0x0c偏移处,LDT基地址
[es:esi+0x0a]即TCB的0x0a偏移处,LDT当前界限值
也就是说把allocate_memory申请的空间作为LDT,然后将其基地址写到TCB中.并且将LDT当前界限值设为最大0xffff
读取用户程序头
1 | ;以下开始加载用户程序 |
ds指向内核数据段
ebp+12*4指向之前作为加载器的参数压栈的逻辑扇区号

将逻辑扇区号放到eax,将core_buf内核缓冲区地址放到ebx,作为参数调用read_hard_disk_0函数
该函数读取eax指定的逻辑扇区,将数据拷贝到ds:ebx指定的内内存地址上
判断程序大小
1 | ;以下判断整个程序有多大 |
效果是获取程序占用的扇区对应的总内存数,最后一个扇区如果占不满则向上取整为一个扇区
由于刚才已经将程序头512字节放到了core_buf指向的内核缓冲区上,现在core_buf指向的就是用户程序头的基地址,用户程序头上是啥又涉及到协议了
| 项目 | 值 | 大小(bytes) | 文件偏移(bytes) | 原意义 | 新意义 |
|---|---|---|---|---|---|
| program_length | program_end | 4 | 0 | 程序总大小 | – |
| head_len | header_end | 4 | 4 | 程序头大小 | 程序头段选择子 |
| stack_seg | – | 4 | 8 | 接收栈段选择子 | 程序堆栈段选择子 |
| stack_len | – | 4 | 12 | 程序建议的栈长度 | – |
| prgentry | start | 4 | 16 | 入口点文件文件偏移 | – |
| code_seg | section.code.start | 4 | 20 | 代码段文件偏移 | 程序代码段选择子 |
| code_len | code_end | 4 | 24 | 代码段长度 | – |
| data_seg | section.data.start | 4 | 28 | 数据段文件偏移 | 程序数据段选择子 |
| data_len | data_end | 4 | 32 | 数据单长度 | – |
| salt_items | (header_end-salt)/256 | 4 | 36 | 符号表项数 | – |
| 符号1… | 符号值(字面量) | 256Bytes | 40 | 第一个符号 | – |
| 符号2… | 符号值(字面量) | 256Bytes | 40+256 | 第二个符号 | – |
| … | |||||
[core_buf+0x00]即程序总大小
为整个程序申请空间并注册
1 | mov ecx,eax ;实际需要申请的内存数量 |
eax中放的是向上取整之后的程序总大小字节数,通过ecx传递给allocate_memory申请相应大小的内存,
然将该内存基地址后写到[es:esi+0x06],即TCB的程序加载基地址处
读取整个程序
1 | mov ebx,ecx ;ebx -> 申请到的内存首地址 |
edx:eax除以512得到总扇区数放到ecx作为循环变量,下面要循环读入这些扇区
起始扇区号还是使用压栈传递给加载器的参数
循环读入这些扇区到ebx指定的内存中
获取程序基地址
1 | mov edi,[es:esi+0x06] ;获得程序加载基地址 |
[es:esi+0x06] 是之前给整个程序申请空间之后写到TCB中的
建立程序头部段描述符
edi指向程序基地址
1 | ;建立程序头部段描述符 |
程序头部段基地址放到eax
[edi+0x04]在协议中一开始是程序头段长度(后来被改成程序头段选择子)
段长度-1得到段界限放到ebx
属性0x40f200放到ecx
调用make_seg_descriptor,eax,ebx,ecx作为参数传递
edx:eax作为返回值,返回完整的段描述符
esi从加载器函数开始时就被设置指向TCB基址,ebx获得其拷贝
调用fill_descriptor_in_ldt,它使用edx:eax作为描述符,ebx作为TCB基地址,该函数将描述符安装在LDT中(LDT基地址通过查TCB表得知),更新LDT界限.返回CX作为描述符选择子.
注意fill_descriptor_in_ldt并没有lldt,即没有更新ldtr,其更新需要等整个LDT建立完毕之后
将cx返回的段选择子加上特权级3,分别写到TCB和程序头部的程序头部段选择子中
建立程序代码段描述符
1 | ;建立程序代码段描述符 |
过程类似建立程序头部段描述符,但是最后没有将代码段写到TCB中,因为TCB不需要记录,这是TSS需要干的,而对于TSS的设置还在后面
建立程序数据段描述符
1 | ;建立程序数据段描述符 |
建立程序堆栈段描述符
1 | ;建立程序堆栈段描述符 |
与前面的段不同的是,程序堆栈段是需要另申请空间的
重定位用户程序符号
用户程序的符号表,在链接之前保存的是符号名,现在遍历用户程序符号表,将用户符号引用解析到内核符号
算法和上一章相同,对于每个用户程序符号,遍历整个内核符号表
1 | ;重定位SALT |
建立并注册各特权级堆栈
1 | mov esi,[ebp+11*4] ;从堆栈中取得TCB的基地址 |
esi指向TCB基地址
esi+0x1a指向的0环栈以4KB为单位的长度
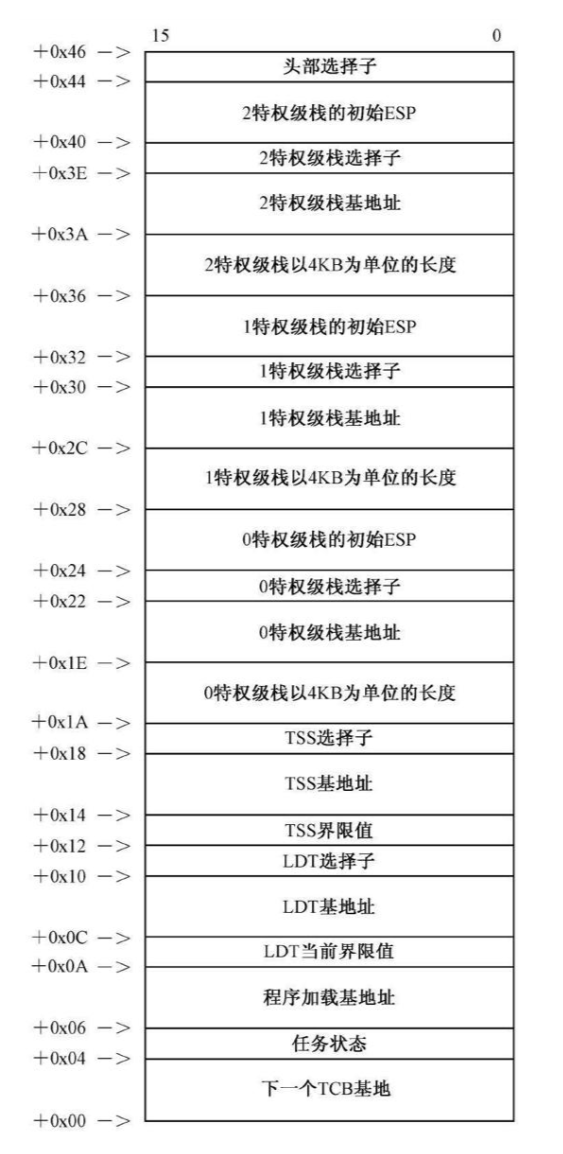
这里将4096放到该位置,然后右移12位,意思是4096右移12位得到1,即0环栈的大小是1×4K
ecx=4096B交给allocate_memory,为该堆栈申请空间
然后ecx保存返回地址,加上eax先前保存的空间大小,达到该空间的最大地址,由于堆栈往小地址生长,因此该地址就作为基地址了
写到esi+0x1e位置,即0特权级堆栈基地址
段大小是4KB那么段界限就是0xffffe
0x00c9600作为属性放到ecx准备制作段描述符
make_seg_descriptor用edx:eax返回完整的段描述符
然后调用fill_descriptor_in_ldt,该函数使用edx:eax作为段描述符,使用ebx作为TCB基地址,将该段描述符写入TCB指向的LDT中
cx返回该段的选择子,该选择子将权限置为0后,放到TCB+0x22,即0环栈选择子上
然后将0环栈初始esp置为0
这就建立好了0环栈,下面1,2环栈类似
1 |
|
GDT中注册LDT
1 | ;在GDT中登记LDT描述符 |
TCB+0x0c指向LDT线性基地址,放到eax
TCB+0x0a指向LDT当前界限值,放到ebx
0x00408200作为属性,放到ecx
调用make_seg_descriptor,set_up_gdt_descriptor将LDT描述符注册到GDT,并将该LDT的选择子写到TCB+0x10位置
创建TSS

TSS是一个大块头,详细保存了程序上下文,共需要占用104字节
貌似TCB和TSS有很多重复保存的地方
确实两者都保存了附加堆栈的段选择子,LDT段在GDT中的选择子
但是TSS是一个动态变化的结构,TCB在进程创建之后就不再发生变化了
TSS中的各种寄存器都是会随着进程的执行发生变化
1 | ;创建用户程序的TSS |
esi还是指向TCB基地址
esi+0x12是TSS界限,设为104-1=103
然后调用allocate_memory给TSS申请104字节空间,将该空间的首地址放到TCB+0x14即TSS基地址上
登记基本TSS内容
由于进程开始执行之前,TSS和TCB中的很多内容都是重复的,因此TSS建立时,可以从TCB抄作业
1 | ;登记基本的TSS表格内容 |
GDT中注册TSS
为啥要在GDT中注册TSS?
TSS也是一块内存区域,在保护模式下,每块内存区域都需要现在GDT或者LDT中注册之后才能访问.在内核中可以使用4G的数据段访问全部内存,但是控制切换到用户程序之后就不能使用4G数据段了,要想还能访问TSS,内核就必须给用户程序准备好TSS
TSS描述符长这样

其中TYPE.B位,表征任务当前状态,是”忙”还是”不忙”,忙就是正在执行或者挂起,处理器会自动修改该位
1 | ;在GDT中登记TSS描述符 |
注册TSS时用到的基址和界限信息还是从TCB中抄来的
加载器函数尾声
1 | pop es ;恢复到调用此过程前的es段 |
ret 8退栈8个字节,正好给加载器传递参数时是两个4字节参数
这样加载器返回后堆栈平衡
加载ldtr,tr寄存器,ds段寄存器
1 | mov ebx,do_status |
假装从调用门返回
我们之前一直是在0环的内核上工作的 ,而现在竟然让我们将控制放权给一个三环上的应用程序,显然正常情况下这是不可容忍的.
不使用调用门时,即使是依存的代码段也只允许从3环代码段调用0环代码
使用调用门时,也只允许控制向高级代码段转移,顶多有一个改不改CPI的区别
貌似各种情况都不允许控制从0环向3环转移
但是但是,call far调用之后,允许使用retf从0环返回到3环
即虽然不允许0环主动调用3环,但是允许从0环返回3环
这就是下面retf的作用
1 | ;以下假装是从调用门返回。摹仿处理器压入返回参数 |
压栈时操作数的段寄存器ds指向用户程序头段
ds:0x08指向用户程序段选择子
ds:0x14指向用户程序代码段选择子
ds:0x10指向用户程序入口点

retf指令干了啥呢?
retf用于段间返回,将此时栈顶低32位作为段内偏移量,高32位作为段选择子(实际只使用了高16位,再高16位置零忽略)
retf执行之后会将栈顶的入口点段内偏移退栈交给eip,将程序段选择子退栈交给cs

然后接着处理器就根据eip取指令继续执行了,就相当于从内核”返回”到用户程序了,虽然这是用户程序的第一次执行
此时栈顶是程序堆栈段,自然而然地被作为程序的
图解TSS,TCB,LDT


有些地方还是没有彻底明白