C++11特性 迈向现代的第一步
2011年的C++标准,叫c++11
使用gcc编译时,加入编译选项-std=c++11即可使用c++11特性
类型推导 auto&decltype
auto auto 左值=右值;
通过右值的类型推断auto代表的左值类型,必须得有右值才能用auto定义左值
一般用于循环时作为迭代器,比如在解释器遍历符号表时
在lexer.hpp中有这么一个内置符号表
1 2 3 4 5 6 7 static std::vector<Token> build_in_token_table = { {CONST_ID, "PI" , 3.1415926 , NULL }, {CONST_ID, "E" , 2.71828 , NULL }, ... {DRAW, "DRAW" , 0.0 , NULL }, };
在lexer.cpp中有一个queryTokenTable函数,根据参数字符串查找内置符号表,如果找到相应符号返回其引用
传统的方法是定义一个循环变量i,遍历整个符号表
如果使用auto则更加方便,foreach循环
1 2 3 4 5 6 7 8 9 10 static Token* queryTokenTable (std ::string &lexme) { for (auto &build_in_table_token:build_in_token_table){ if (build_in_table_token.getLexme()==lexme){ return &build_in_table_token; } } ... }
这里使用的是auto &,而不是auto,之前我认为auto既然是自动的,应该可以推导出引用类型.
然而实际上不会,auto会忽略引用类型还有cv属性,因此这里需要手工加上引用类型
decltype decltype关键字是用于定义同类型变量,
1 2 3 int a=1 ;decltype(a) b=2 ; decltype(a+b) c=3 ;
decltype和auto不同的是,decltype完全拷贝其操作数的类型,包括引用和cv属性
对于decltype(expression),这里expression如果是函数调用,则decltype与函数返回值类型相同
右值引用 右值引用 通常getter方法是这样定义的:
1 2 3 4 5 6 int x () { return __x; } int y () { return __y; }
其返回值是一个右值,当调用语句结束后,返回值立刻死亡
实际上大多数调用约定(这里是cdecl),函数的返回值放到rax寄存器中
该行源代码的最后的指令可能是
1 2 call point.x() mov [rbp+x],rax
意味着需要在调用者栈帧中给左值int a开4字节空间,然后将函数返回值(存在于rax寄存器)付给他
之后rax的任务就完成了,可以立刻用于其他计算,这就意味着函数返回值这个将亡值不复存在了
显然栈中是找不到这个返回值的,他只会临时存在于寄存器中
右值引用的作用是,在调用者栈帧中给返回值开辟一块空间,将该返回值放到这块空间中,此后在调用者中就可以引用”右值”了,实际上是引用的返回值在调用者栈帧中的拷贝,这一点可以通过反编译观察
比如如下程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> #include <string> using namespace std;class Point { private : int __x; int __y; public : Point (int _x=0 ,int _y=0 ):__x(_x),__y(_y){} int x () return __x;} int y () return __y;} }; int main () Point A (2 ,5 ) ; int &&x=A.x (); int y=A.y (); printf ("%p\n" ,&x); printf ("%p\n" ,&y); return 0 ; }
1 g++ -std=c++11 main.cpp -O0 -o main
然后用ida64反编译观察之
1 2 3 4 5 6 7 8 9 10 11 12 lea eax, [ebp+A] mov ecx, eax ;this指针 call __ZN5Point1xEv ; Point::x(void) mov [ebp+var_10], eax ;返回值首先拷贝给var_10 lea eax, [ebp+var_10] mov [ebp+x], eax ;然后拷贝给x lea eax, [ebp+A] mov ecx, eax ;this call __ZN5Point1yEv ; Point::y(void) mov [ebp+y], eax ;返回值直接拷贝给y
有一个明显区别,
int &&x=A.x();这里貌似在调用者栈帧中产生了两个局部变量,var_10和x
但是int y=A.y();只产生了一个局部变量y
显然x和y两个变量是地位相等,门当户对的
这个var_10就是右值的拷贝,其存在的目的就是代理右值,使其可以进行取地址运算,实际上取得地址是var_10的地址
问题又来了,这样看,使用右值引用的时候多产生了一个局部变量,并且需要四条指令,而不使用右值引用只需要两条指令.那用了个寂寞啊,越用越慢是吧.
这是因为这里的调用情况是很简单的,有些复杂情况,var_10会发挥重要作用,详见右值引用
完美转发 没看明白
返回值优化 类似于传参时是直接传递引用还是调用拷贝构造函数给形参赋值
返回时也面临相似的局面,比如
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <iostream> #include <string> #include <vector> #include <iomanip> using namespace std;class Point { private : int __x; int __y; public : Point (int _x = 0 , int _y = 0 ) : __x(_x), __y(_y) { cout << "constructor called" << endl; } Point (const Point &point) { __x = point.__x; __y = point.__y; cout<<"copy constructor called" <<endl; } static Point Origin () cout<<"generating origin point..." <<endl; Point origin (1 ,1 ) ; cout<<hex<<&origin<<endl; cout<<"origin point generated!" <<endl; return origin; } int x () return __x; } int y () return __y; } }; int main () Point O=Point::Origin (); cout<<&O<<endl; return 0 ; }
主函数里定义了一个Point O,按照之前的认识,Point O=Point::Origin();这句话应该是这样执行的:
首先调用Point::Origin(),这个函数中会调用构造函数
接着Point O=返回值这里要对O调用拷贝构造函数
总共有两次调用构造函数,然而实际上只调用了一次
1 2 3 4 5 6 7 PS C:\Users\86135\Desktop\cpp> g++ -std=c++11 main.cpp -O0 -o main PS C:\Users\86135\Desktop\cpp> ./main generating origin point... constructor called 0x60fe88 origin point generated! 0x60fe88
从两次地址的打印来看,两个对象实际上是一个对象,因此Origin函数可以认为返回的是这个对象的指针,从反汇编看确实如此
1 2 3 4 5 6 7 8 9 10 11 main中: lea eax, [ebp+var_10] mov [esp], eax ; this call __ZN5Point6OriginEv ; Point::Origin(void) lea eax, [ebp+var_10] mov ecx, eax Point::Origin中: mov dword ptr [esp+4], 1 ; int mov dword ptr [esp], 1 ; this mov ecx, [ebp+this] call __ZN5PointC1Eii ; Point::Point(int,int)
列表初始化 在写词法分析器的时候有这么一个符号类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct Token { TokenType type; std::string lexme; double value; Func func; Token (TokenType t = ERRORTOKEN, std::string l = "" , double v = 0.0 , Func f = NULL ) : type (t), lexme (l), value (v), func (f) { } };
现在需要建立一个内建符号表,如果使用老式的写法
1 2 3 4 5 6 vector<Token> built_in_token_table={ Token (CONST_ID,"PI" ,3.1415926 ,NULL ), Token (CONST_ID,"E" ,2.71828 ,NULL ), ... Token (DRAW,"DRAW" ,0.0 ,NULL ) };
每个条目都要显式调用构造函数Token(...)
而如果使用初始化列表
1 2 3 4 5 6 static std ::vector <Token> build_in_token_table = { {CONST_ID, "PI" , 3.1415926 , NULL }, {CONST_ID, "E" , 2.71828 , NULL }, ... {DRAW, "DRAW" , 0.0 , NULL }, };
这样效果和上面一模一样,也会调用构造函数,但是不用写Token(...),实际上也是调用相应参数个数的构造函数
Lambda表达式 在实验室电脑上,开学乎上
智能指针 之前C++和C的堆内存管理责任全在程序员,new了不delete会内存泄漏,new了delete两次会造成二次释放漏洞.
而有些对象到底啥时候释放,可能人也把握不准,比如这次编译原理实验中,词法分析器的getToken函数总是返回一个Token*指针,函数内部会在堆上开一块内存放对象
然而parser在使用完了这个Token之后没有立刻释放,因为我也不知道啥时候一个Token才会真正使用完,比如一个T类型的Token,它作为变量可能会存在一段时间,提前析构了后来就会访问非法内存
于是Token几乎都存在内存泄漏,而我也不知道咋处理
智能指针就解决了这个困扰
智能指针实际上是对普通指针的包装,但是他会对对象有一个引用计数
每当有一个智能指针指向同一块内存的时候,引用计数就会加一,当一个智能指针消亡或者不再指向该内存的时候,引用计数减一,最后一个不再指向该内存的智能指针会发现引用计数从1到0,于是它会自动析构这个对象
显然就不用人操心在啥时候释放对象了
到底咋用呢?写一个链表类意思意思
关键词:make_shared,shared_ptr
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 #include <iostream> #include <string> #include <vector> #include <iomanip> #include <memory> using namespace std;struct LinkedNode { int __key; shared_ptr<LinkedNode> __next; LinkedNode (int _key=0 ,shared_ptr<LinkedNode> _next=nullptr ){ __key=_key; __next=_next; cout<<"LinkedNode ctor called" <<endl; } ~LinkedNode (){ cout<<"LinkedNode dtor called" <<endl; } shared_ptr<LinkedNode> getNext () { return __next; } int getKey () return __key; } void setNext (shared_ptr<LinkedNode> _next) __next=_next; } void setKey (int _key) __key=_key; } string toString () const { return to_string (__key); } LinkedNode operator =(const LinkedNode &)=delete ; LinkedNode (const LinkedNode&)=delete ; }; class LinkedList { shared_ptr<LinkedNode> head; public : LinkedList (){ head=make_shared <LinkedNode>(0 ,nullptr ); } void pushHead (const int &key) auto node=make_shared <LinkedNode>(key,head->getNext ()); head->setNext (node); } void popHead () head->setNext (head->getNext ()->getNext ()); } bool empty () const return nullptr ==head->getNext (); } string toString () { auto p=head->getNext (); string buffer; while (p!=nullptr ){ buffer+=p->toString ()+" " ; p=p->getNext (); } return buffer; } }; int main () LinkedList list; for (int i=0 ;i<10 ;i++){ list.pushHead (i); } cout<<list.toString ()<<endl; list.popHead (); cout<<list.toString ()<<endl; return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 PS C:\Users\86135\Desktop\cpp> g++ -std=c++11 main.cpp -O0 -o main PS C:\Users\86135\Desktop\cpp> ./main LinkedNode ctor called LinkedNode ctor called LinkedNode ctor called LinkedNode ctor called LinkedNode ctor called LinkedNode ctor called LinkedNode ctor called LinkedNode ctor called LinkedNode ctor called LinkedNode ctor called LinkedNode ctor called 9 8 7 6 5 4 3 2 1 0 LinkedNode dtor called 8 7 6 5 4 3 2 1 0 LinkedNode dtor called LinkedNode dtor called LinkedNode dtor called LinkedNode dtor called LinkedNode dtor called LinkedNode dtor called LinkedNode dtor called LinkedNode dtor called LinkedNode dtor called LinkedNode dtor called
没有任何手动delete的地方,但是dtor依然被调用了
shared_ptr<LinkedNode>和LinkedNode *,在用法上一模一样,都是使用箭头调用成员函数
但是shared_ptr<LinkedNode>实际上封装了一个LinkedNode *,前者还有其他功能
比如
1 2 auto node=make_shared <LinkedNode>(0 ,nullptr );cout<<hex<<node<<" " <<node.get ()<<endl;
node可以使用点号调用shared_ptr类的成员函数,使用箭头符号调用的是其托管对象类的成员函数
继承构造函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <iostream> #include <string> #include <vector> #include <iomanip> using namespace std;class Point { private : int __x; int __y; public : Point (int _x , int _y ) : __x(_x), __y(_y) { cout << "constructor called" << endl; } int x () return __x; } int y () return __y; } string toString () const { return "(" +to_string (__x)+"," +to_string (__y)+")" ; } }; class TaggedPoint :public Point{ string __tag; using Point::Point; public : TaggedPoint (int _x,int _y,string _tag):TaggedPoint (_x,_y){ __tag=_tag; } string toString () const { return __tag+Point::toString (); } }; int main () TaggedPoint A (1 ,2 ) ; cout<<A.toString ()<<endl; return 0 ; }
nullptr 之前表示空指针都使用NULL,而实际上这是个int 0
c++11之后表示空指针的常量是nullptr
1 2 3 4 5 6 7 8 9 10 11 12 13 void func (void *ptr) cout<<"ptr func called" <<endl; } void func (int value) cout<<"value func called" <<endl; } int main () func (nullptr ); func (NULL ); return 0 ; }
1 2 3 4 5 6 7 8 PS C:\Users\86135\Desktop\cpp> g++ -std=c++11 main.cpp -O0 -o main main.cpp: In function 'int main()' : main.cpp:57:14: warning: passing NULL to non-pointer argument 1 of 'void func(int)' [-Wconversion-null] func(NULL); ^ PS C:\Users\86135\Desktop\cpp> ./main ptr func called value func called
final关键字 final修饰的类不允许被继承,不允许虚函数重载
override关键字 override关键字修饰子类成员函数,保证是在重写父类同名函数,否则报错
default构造函数 在之前的c++中,如果一个类没有显式写构造函数,那么编译器会自动加上一个无参的隐式构造函数,这个构造函数几乎啥也不干(在汇编层面上会哦用子类虚表覆盖父类虚表,算是干了点东西,但是源代码层面无法体现)
假如显示定义了一个带参数的构造函数,则编译器不会再隐式添加无参构造函数,这时候就不能无参构造了
比如这样就会报编译错:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <iostream> using namespace std;struct Point { int __x; int __y; Point (int _x,int _y):__x(_x),__y(_y){ cout<<"ctor called" <<endl; } }; int main () Point A; return 0 ; }
解决方法是另写一个无参的构造函数
在c++11中的解决方法是Point()=default;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <iostream> using namespace std;struct Point { int __x; int __y; Point ()=default ; Point (int _x,int _y):__x(_x),__y(_y){ cout<<"ctor called" <<endl; } }; int main () Point A; return 0 ; }
这个构造函数不允许有函数体,其作用就相当于缺省构造函数
delete关键字 之前在一个C++类中,即使啥函数没写,编译器也会自动生成至少俩函数
operator=和copy ctor
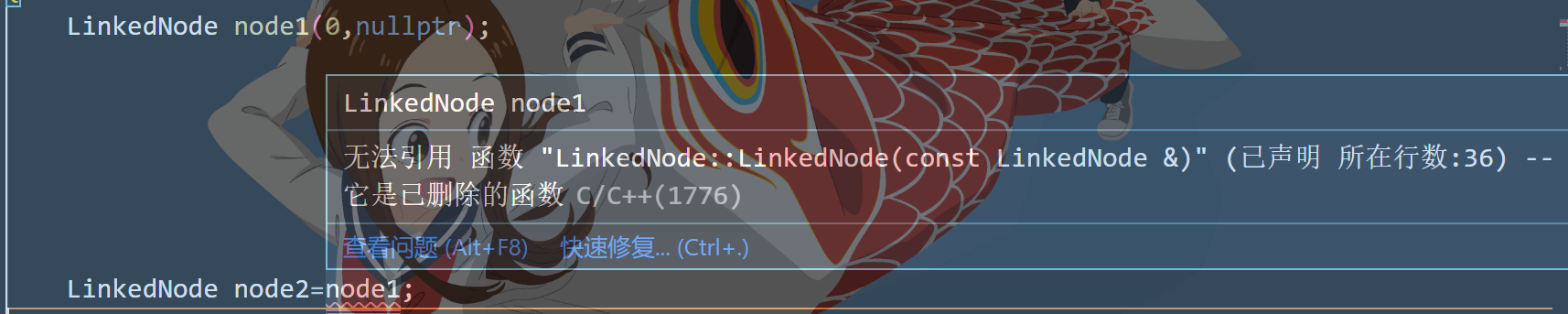
然而我就不想让他生成这俩函数,禁止对象拷贝
1 2 3 in class LinkedNode : LinkedNode operator =(const LinkedNode &)=delete ; LinkedNode (const LinkedNode&)=delete ;
此时主函数中想用一个节点拷贝另一个节点,编译报错
实际应用比如在basic_ostream中,delete用来禁用对char8_t*类型的流输出运算
1 2 3 4 5 6 7 #ifdef __cpp_char8_t template <class _Traits >basic_ostream<char , _Traits>& operator <<(basic_ostream<char , _Traits>&, const char8_t *) = delete ; template <class _Traits >basic_ostream<wchar_t , _Traits>& operator <<(basic_ostream<wchar_t , _Traits>&, const char8_t *) = delete ;
explicit关键字 explicit修饰的构造函数,不允许参数隐式类型转换
constexpr关键字 const和constexpr的区别
之前使用的const名为”常量”实际上是”常变量”
const修饰的变量和未经其修饰的变量只有源代码层面的级别,想要修改const变量会被编译器安全检查阻止.然而一旦通过了编译,到了汇编层面,
两者的底层存储没有任何区别
反汇编根本看不出const属性,顶多可以发现对b只有read操作,没有任何write操作
constexpr是真的常量
在编译阶段,编译器把所有能够计算得出的constexpr替换成字面量,constexpr修饰的函数会用其返回值字面量替换函数调用
实在计算不出来的,比如需要链接其他模块函数才能算出来的,编译器就会忽略constexpr修饰,视为普通变量或者函数
enum class 之前的c++中,枚举类型实际上就是给int类型起了个别名
比如
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <iostream> using namespace std;enum Color { WHITE,BLACK,RED }; enum Direction { SOUTH,NORTH,EAST,WEST }; int main () cout<<WHITE<<" " <<SOUTH<<endl; if (WHITE==SOUTH){ cout<<"yes" <<endl; } return 0 ; }
编译链接时会警告不同类的枚举相比较
1 2 3 4 5 6 7 8 PS C:\Users\86135\Desktop\cpp> g++ -std=c++11 main.cpp -O0 -o main main.cpp: In function 'int main()' : main.cpp:14:15: warning: comparison between 'enum Color' and 'enum Direction' [-Wenum-compare] if (WHITE==SOUTH){ ^ PS C:\Users\86135\Desktop\cpp> ./main 0 0 yes
也就是说不同的枚举没有严格的类型区别
c++11就修正了这一点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <iostream> using namespace std;enum class Color { WHITE,BLACK,RED }; enum class Direction { SOUTH,NORTH,EAST,WEST }; int main () cout<<Color::WHITE<<" " <<Direction::SOUTH<<endl; if (Color::WHITE==Direction::SOUTH){ cout<<"yes" <<endl; } return 0 ; }
非受限联合体 感觉用处不是很大,了解一下POD类型吧
POD类型 Plain Old Data,平凡的老的数据
C的所有数据类型,包括基本数据类型和任何结构体,都是POD,
可以这样理解POD:其内存布局是很规则的,两个同类的POD之间可以直接用memcpy拷贝数据.啥意思呢?
比如
1 2 3 4 5 6 7 8 9 10 typedef struct { int __x; int __y; }Point; Point A; Point B; A.__x=10 ; A.__y=20 ; memcpy (B,A,sizeof (B));
B和A是同类型的POD,那么A直接拷贝给B,A的第一个字节给B的第一个字节,A的第二个字节给B的第二个字节…显然组装起来的B,其前四个字节就是__x,后四个字节就是__y`,毋庸置疑的
c++11中可以使用std::is_trivial<T>::value来检查一个类型是否是POD
比如
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <iostream> using namespace std;typedef struct STRUCTPOINT { int __x; int __y; STRUCTPOINT ()=default ; }Point; struct MyPoint { int __x; int __y; MyPoint (int _x,int _y):__x(_x),__y(_y){} }; int main () cout<<is_trivial<Point>::value<<endl; cout<<is_trivial<MyPoint>::value<<endl; return 0 ; }
1 2 3 4 PS C:\Users\86135 \Desktop\cpp> g++ -std=c++11 main.cpp -O0 -o main PS C:\Users\86135 \Desktop\cpp> ./main 1 0
如果一个类有非缺省构造函数,或者有虚函数,虚基类,或者成员变量有不同的访问修饰或者第一个成员不是自己的,或者有父类并且父类本类都有成员变量,他就是非POD
这一点好理解
有虚函数的类,其基地址开始的4个字节是虚表指针,不是其成员,使用memcpy也会拷贝虚表指针
assertion 编译阶段的断言
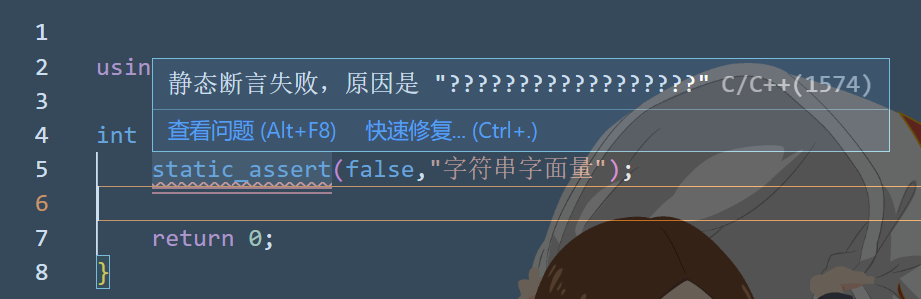
static_assert(bool,string_literal)如果前面的bool表达式为真,则通过编译
否则报告后面的字符串字面量,然后终止编译
1 2 3 4 5 using namespace std;int main () static_assert (true ,"字符串字面量" ); return 0 ; }
这样可以通过编译,啥也不会发生
如果这样写就不让通过:
正则表达式