计算机网络-传输层
传输层
概念
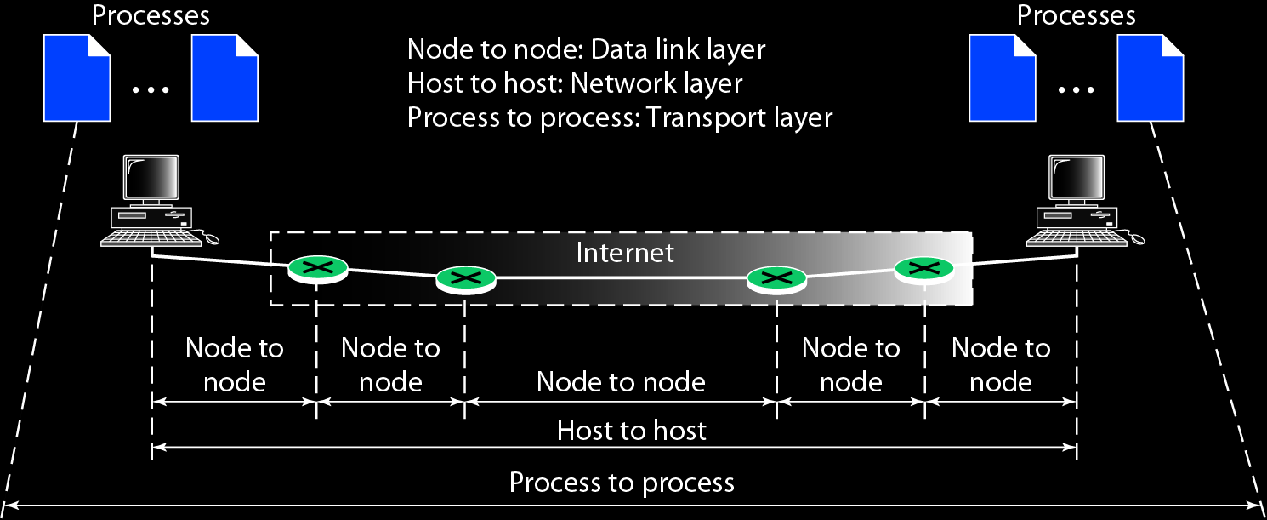
网络层提供点到点服务,也就是主机到主机的服务
传输层提供端到端服务,也就是进程到进程的服务
端口号
| 层 | 寻址方式 | 寻址范围 |
|---|---|---|
| 链路层 | MAC地址 | |
| 网络层 | ip地址 | ipv4地址32位 |
| 传输层 | 端口号 | 端口号16位 |
服务端端口号规定

客户端都是临时端口,不用管到底用的哪个端口
套接字
socket=IP地址+端口号
一个套接字唯一标识了一个进程
一个TCP连接两头是两个套接字,即一个TCP连接被一对套接字决定
差错控制
可靠传输:不错,不丢,不乱
每一层的校验都只校验本层数据
| 层 | 差错控制的目的 | 是否可靠 |
|---|---|---|
| 数据链路层 | 通过CRC校验,保证一个帧中没有比特差错,但不能保证丢不丢帧 | 否,只能保证不错 |
| 网络层IP协议 | 只针对网络层包的头部进行CRC校验 | 否 |
| 传输层TCP协议 | 保证做到无传输差错 | 是 |
应用场景
| 传输层协议 | 应用场景 |
|---|---|
| TCP | 客户端和服务端多次交互入访问页面HTTP 传输文件FTP 电子邮件POP3,SMTP |
| UDP | 实时聊天通信,DNS,多播,广播 对等网络技术P2P 部分路由协议RIP 网络时间管理NTP 简单网络管理SNTP |
UDP
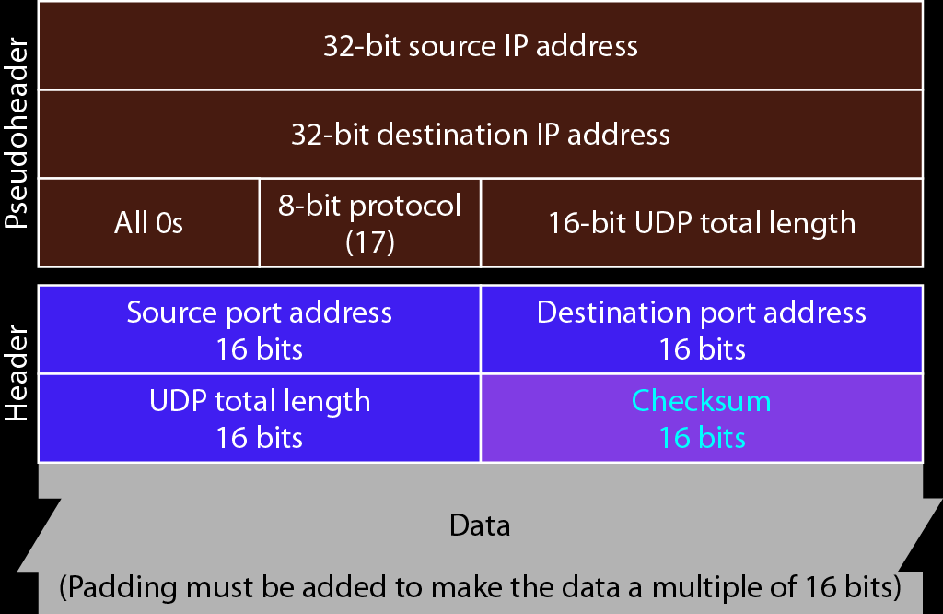
UDP首部
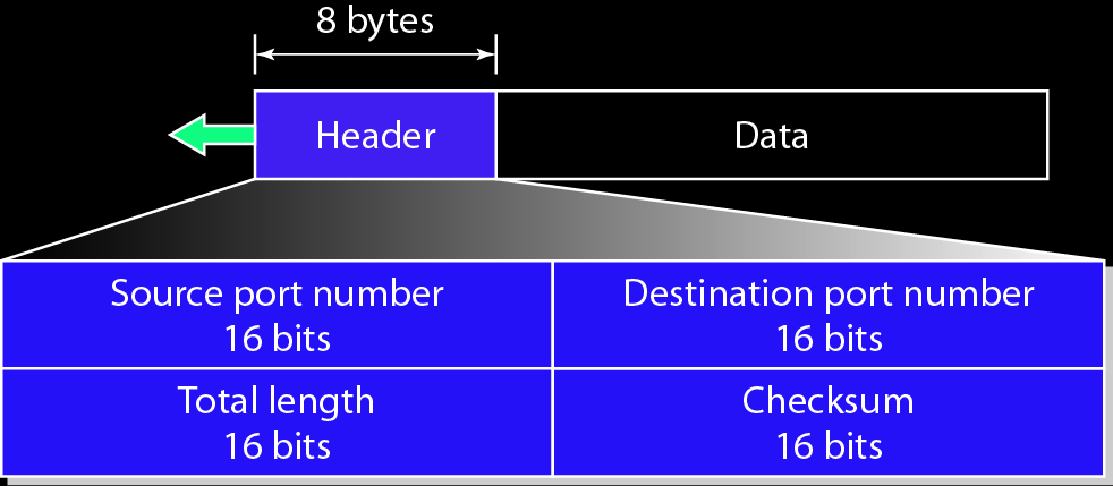
源端口,目的端口各16位,总长度16位,校验和16位
校验和
UDP的校验和=UDP伪首部+UDP首部+数据
这个伪首部指,源地址、目的地址、协议类型(0x11),一个字节的全0,一个字节的UDP数据长度,对齐填充2字节的0,整个伪首部共12个字节。
UDP伪首部是为了计算校验和而临时存在的,在计算之前由主机加上,计算之后立刻扔掉,不会参与传输
UDP伪首部和IP首部无关,不能理解为借用的IP首部
伪首部中的UDP长度就是UDP首部+UDP数据的长度,不需要考虑对齐填充,是多少就是多少
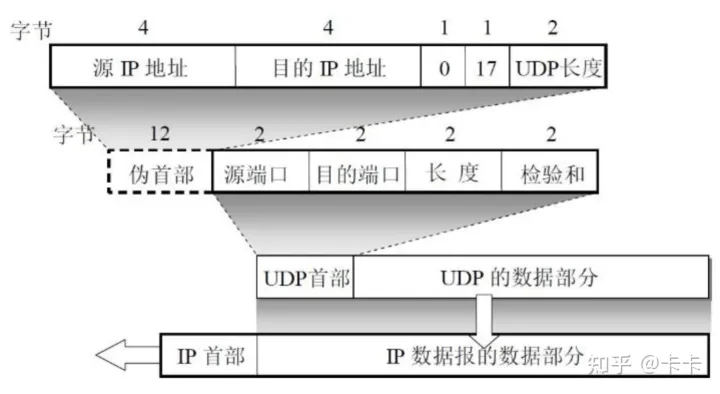
伪首部+UDP首部+数据一起计算校验和。
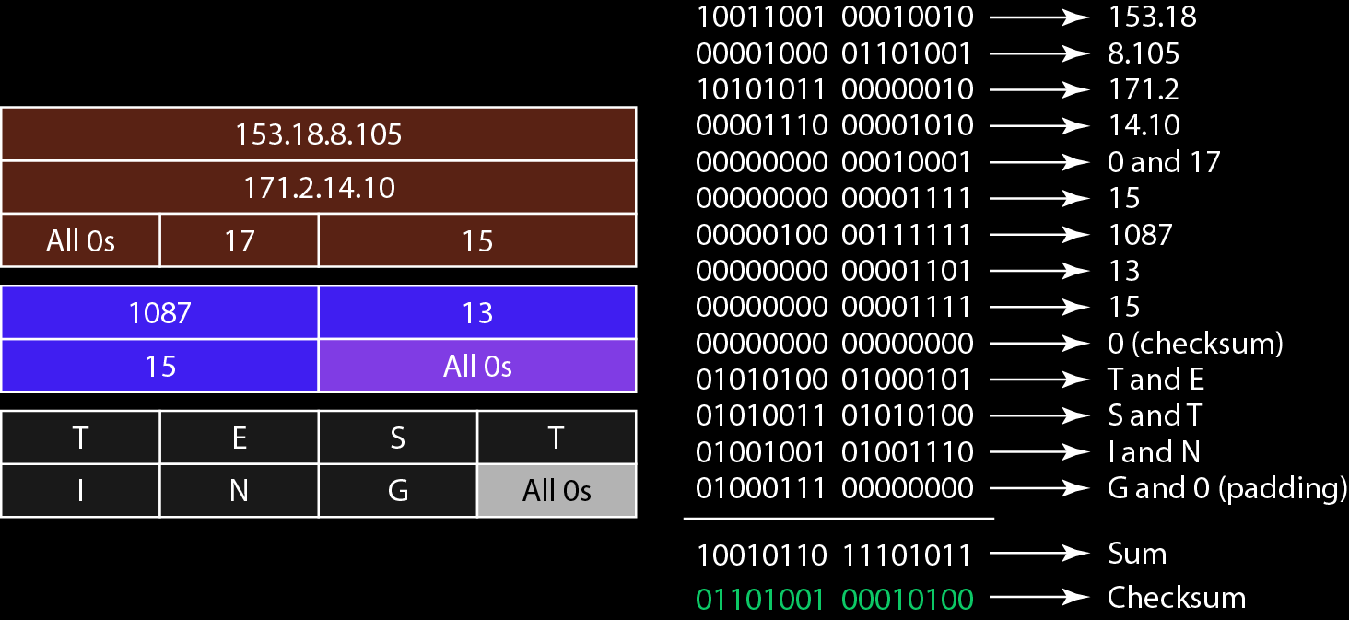
具体计算方法:
16位一组相加,最高位进位回卷,和Sum取反得到CheckSum
在计算校验和时,此时UDP首部的校验和字段先置零,伪首部中的UDP长度就是实际的UDP长度,15,不用考虑对齐填充
UDPの特点
1.报文在发送方这里不会拆分,发送方一次交付一个完整报文.
注意强调了发送方,因为网络层才不会管你拆不拆,大于MTU的报必须拆
比如如果发送方不管三七二十一发了一个巨大的上万字节的UDP报文
如果数据链路层使用以太网,那么每个以太网帧最大是1500字节,也就是说网络层的MTU=1500(Maximum Transmission Unit).
显然一个上万字节的UDP数据报无法直接发送,因此路由器会进行报文分割,把该UDP数据报拆分成若干不大于1500字节的包,分开发送
最终在接收方还是需要组装的
2.无流量控制,无差错控制,无拥塞控制
差错控制要求发现错误时要求重传,但是UDP数据报的校验和如果发现错误,直接被路由器或者主机丢弃,不会要求重传
TCP
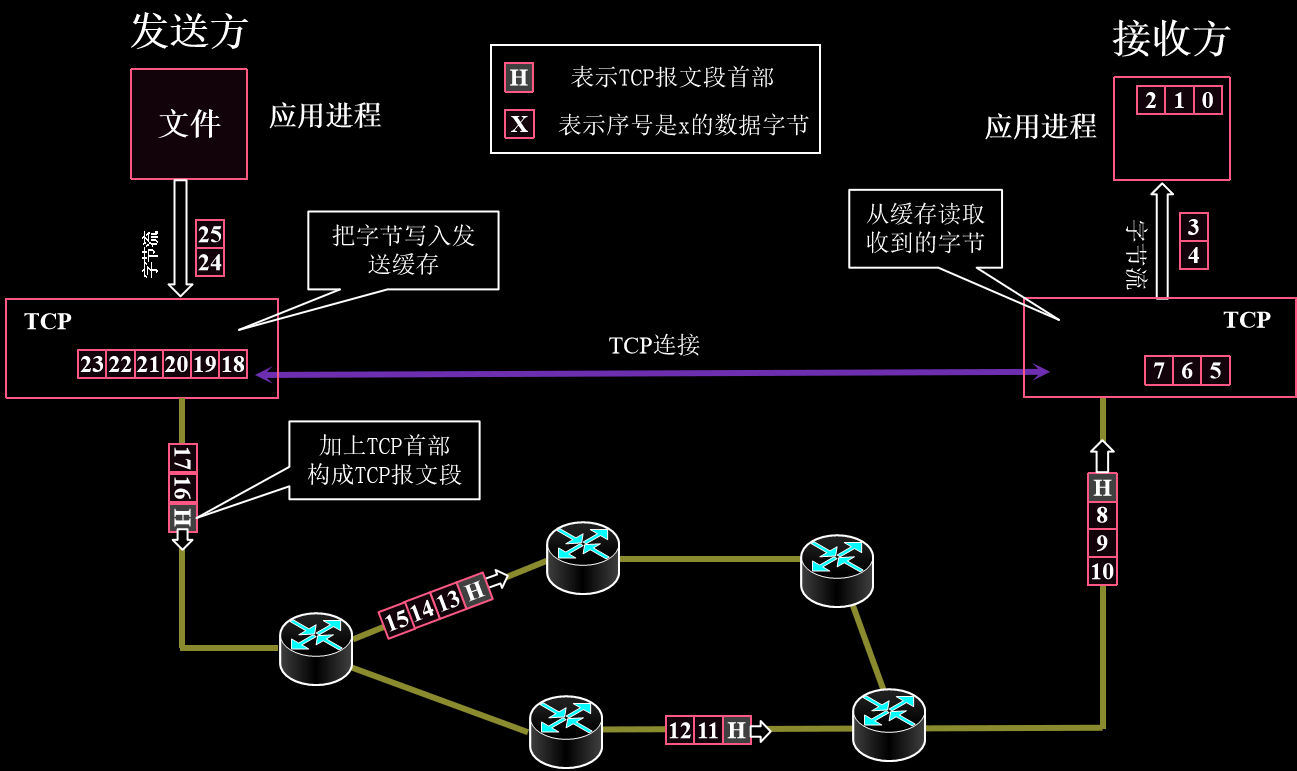
分段传输:虚电路建立之后,看上去TCP协议直接发送和接收字节流,就像访问硬盘一样,但是下层实际上还是数据报实现的
一个图是需要切成好多段,扔给网络层以报文形式交付
TCP协议的熟知端口号
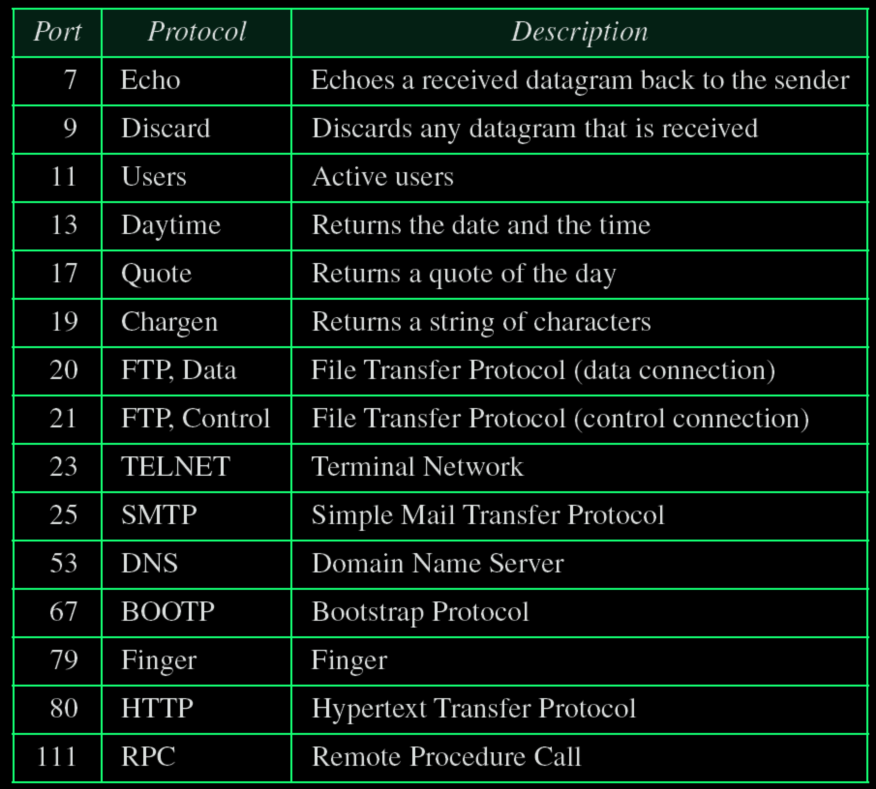
特别注意
20-FTP.Data
21-FTP.Control
53-DNS
字节流
啥玩意叫字节流?
啥玩意叫流?Stream,在计算机里就是顺序读取或者写入的字节序列.
包括从硬盘读取的文件,从键盘输入的字符序列,从网络获取的字符序列.都叫流
叫做字节流,是因为还有一个字符流
两者的区别是,字节流使用8位一个字节为信息单元,一个字节传输一个信息,比如一个字母
而字符流使用16位两个字节作为信息单元,使用unicode编码传输信息
“流”是针对应用层上的应用程序而言的,在应用程序看来,他调用read函数从硬盘读取字节流和调用recv函数从套接字获取字节流没有区别.
反正就是得用while(!read.eof()){read(buf,n,file);...}这样不停地从缓冲区取出字节,因为一个文件的传输,是像水流一样,源源不断地抵达缓冲区的,不可以一下子全部获取
传输层只管给应用程序的缓冲区写入数据,不管应用程序拿着数据干了啥
应用程序只管从缓冲区读取数据,不管传输层从哪里搞来的数据
因此,传输层单蹦个地顺序传送比特位,还是单蹦个顺序传送字节,抑或是分段每次传送成千个字节即分段,应用程序不关心,全靠传输层自由发挥了
显然传输层应该选择分段发送,这样效率高
为什么效率高?
对于网络来说头部长度固定,数据部分越长有效信息比例越高,需要发送的数据报越少,网络负载也就轻
对于主机来说,每个字节就发送一次,需要频繁地系统调用(显然访问网络这种外设需要系统调用),开销太大
首部格式
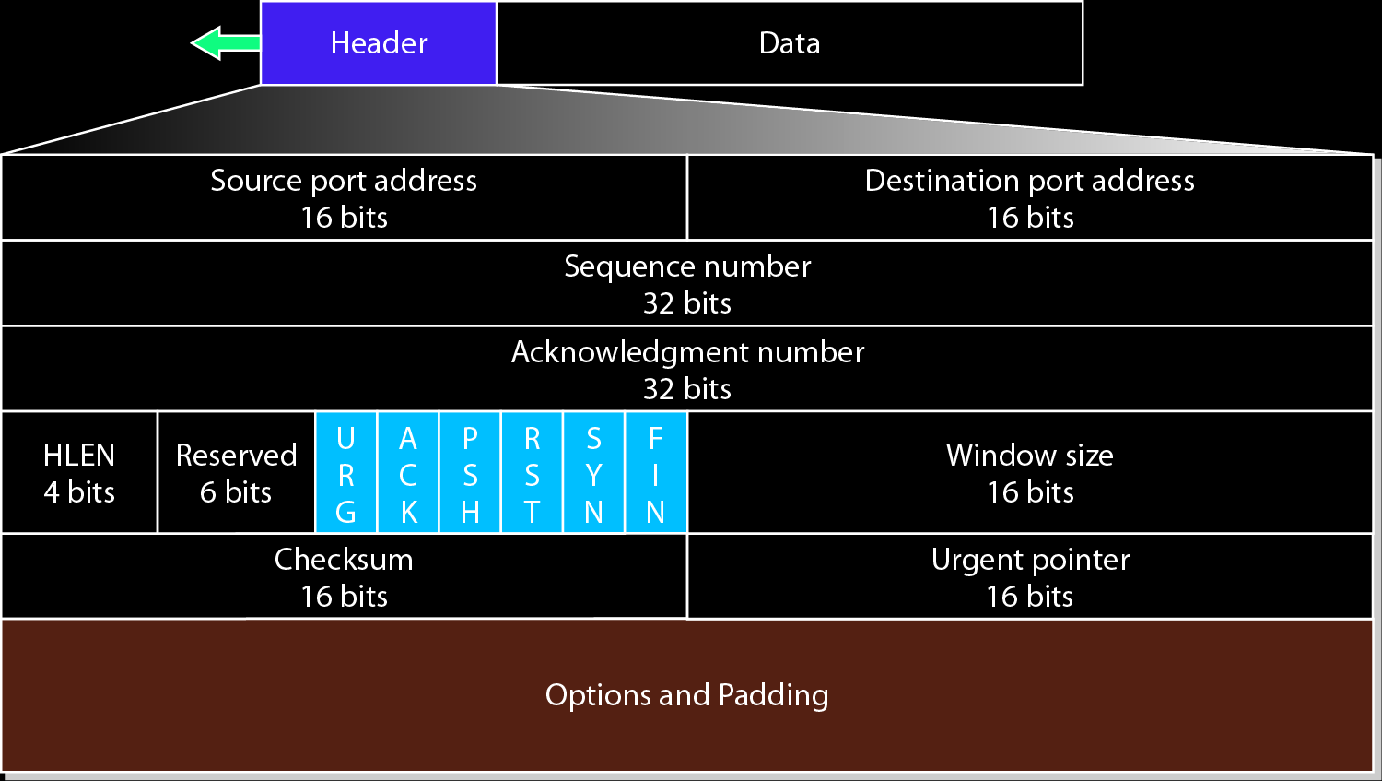
Source/Destination port address
源/目的端口地址
sequence number
字节序列号,一个TCP包可以发送若干数据字节,每一个数据字节都编一个字节序列号,
在首部中sequence number表明本TCP报文中第一个数据字节的编号
本字段用于分段系统
acknowledgment number
确认号字段,期望收到的,对方下一个报文段数据的,第一个字节的序号
本字段用于分段系统
HLEN
header length首部长度,其单位是4字节
比如HLEN=5=0101b,表示首部长度为5*4=20字节
Reserved
保留字段,6位,目前全置零
控制字段
6位
用于TCP连接的流量控制,连接建立终止,连接失败和数据传送方式
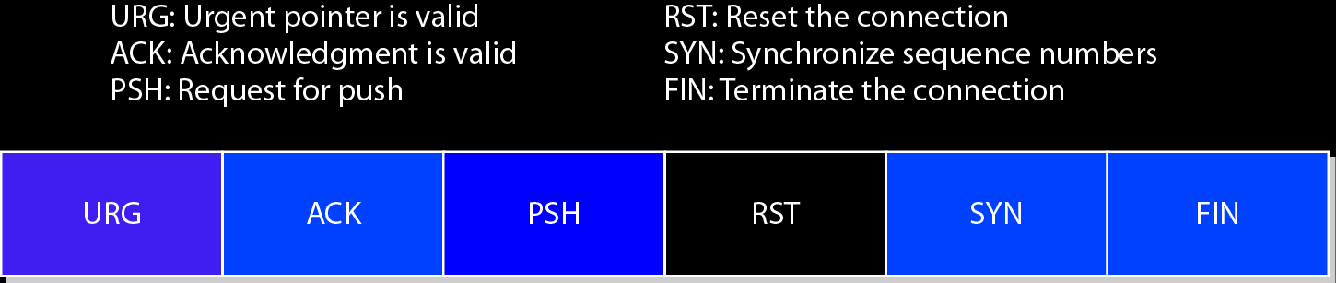
当URG=1时,紧急指针Urgent pointer才有效
如何体现紧急?
正常情况下一个TCP报文段会拆分重组
整个重组利索之后才会交付给应用程序
而紧急数据无需等待重组,直接交给应用程序
ACK,确认,1代表acknoledgment number字段有效
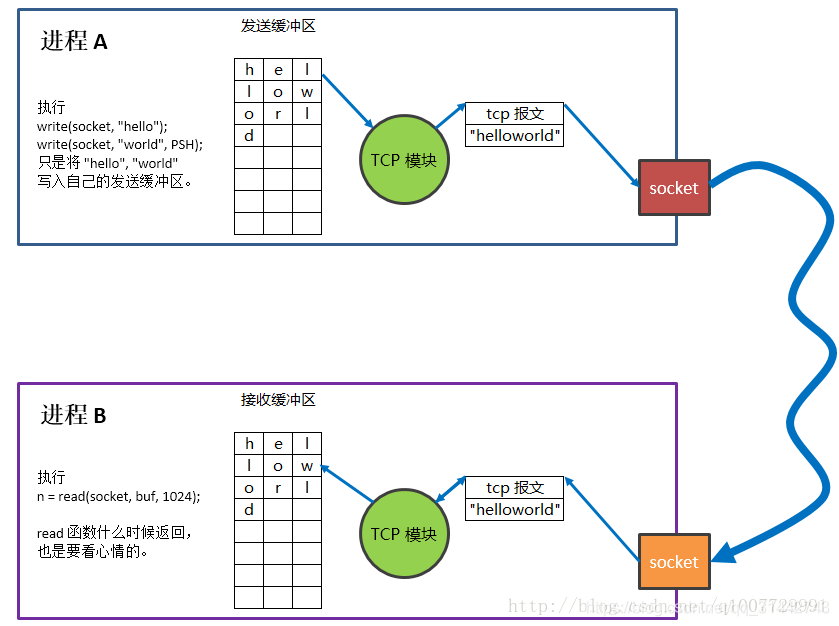
PSH,请求急迫,发送端不需等待窗口填满才发送
PSH用于什么情况?
进程A向socket写东西,实际上就是写到发送缓冲区中,此时并没有实际往网络上发送,啥时候发送呢?得等到缓冲区满了才发,这就像是机场包车的包不满不走一样
而PSH位就是要强迫发送,即使车没有坐满人,也把枪夹到司机头上给我立刻发车
有意义吗?急着发车干啥?还真有意义
有的乘客不在乎自己坐车多花的开销,他急着办事.
正如有些服务的及时性比效率更优先
比如ssh服务
客户端这会急着想看服务端根目录下有啥,于是客户端想发送一个ls命令,如果不加psh位,好吧你等着吧,啥时候缓冲区满了才发送.实际上ssh服务是psh=1的
RST,重置连接
SYN,同步信号,建立连接时使用
FIN,结束
window size
窗口大小,单位字节
用于控制对方发送的数据量
根据自身缓冲区剩余空间大小,决定接收窗口大小,通知对方发送窗口上限
checksum
检验和
TCP检验和=TCP伪首部+TCP首部+TCP数据
其中TCP伪首部和UDP伪首部一模一样
urgent pointer
紧急指针字段,
如果有紧急数据,则一定放在TCP数据的最开始
紧急指针表明紧急数据的大小,单位字节
option
选项字段,长度可变
通常不用这个字段
TCP之规定一种选项,MSS,最大报文段长度,即TCP数据的最大长度
序号系统
由于TCP报文需要分段,因此需要引入一套编号机制,让分段和重组有序
TCP首部的sequence number,acknowledgment number两个字段和ACK,SYN两个标志位就是为序号系统服务的
需要牢记的是:
编号是给每个字节的编号,不是给分段的编号!
编号是给每个字节的编号,不是给分段的编号!
编号是给每个字节的编号,不是给分段的编号!
所有数据的第一个字节是一个$[0,2^{32})$内的随机数
sequence number,该TCP报文段段第一个数据字节的编号
acknowledgment number,希望接收的下一个报文段的第一个数据字节的编号.也表明接收方已经正确接收该编号-1之前的所有字节
比如这么一个问题
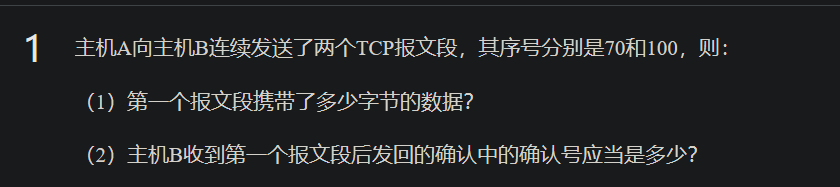
显然第一问是100-70=30
第二问,主机B接收到的字节序列应该是$[70,99]$,因此ack number=100,表明希望接收编号为100的字节,并且告知发送方,编号为99及之前的所有字节都已经正确接收了
连接建立&终止
三次握手建立连接
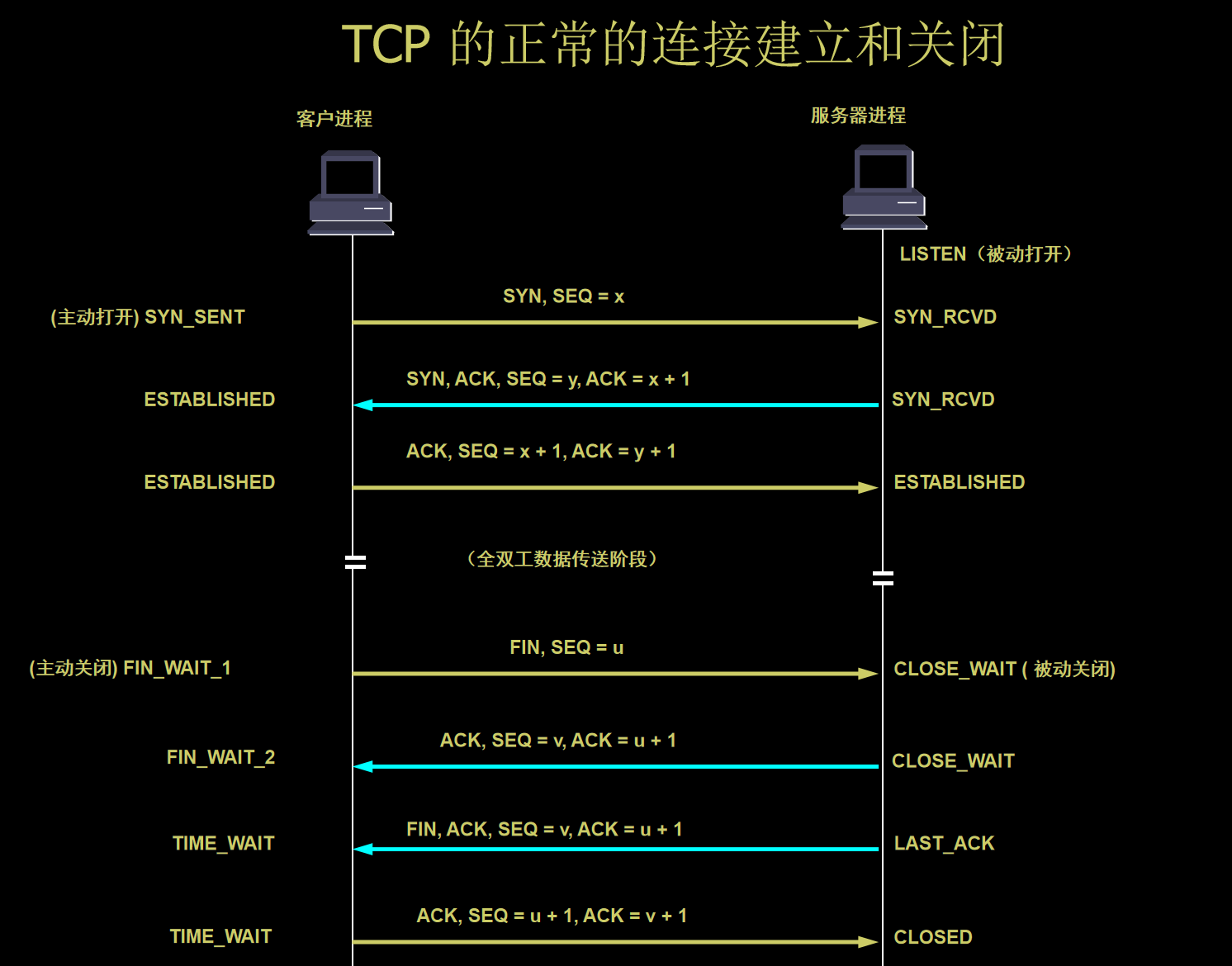
服务端是被动打开的,而客户端是主动打开的
三次握手建立连接的目的是,证明通信双方的收发都正常
第一次握手,客户端啥也不知道,但是服务端知道客户端不哑,自己不聋
第二次握手,客户端知道了服务端收到了自己的消息,证明自己不哑,这次收到消息证明自己不聋.
此时只剩最后一步,此时服务端不知道自己是否哑巴
第三次握手,服务端收到客户端对第二次握手的确认,因此证明服务端不哑
第三次握手时,实际上客户端已经可以在TCP数据中,写上对服务端请求什么了
然而实际上HTTP协议中,三次握手不涉及任何有效数据传输,三次握手建立之后,客户端会另外发送GET请求

四次挥手断开连接的目的是:
首先客户端主动提出FIN分手,表明客户端没有要求了
服务端收到客户端的分手请求后,立刻回复ACK收到,但是如果服务端还有没说完的话,还可以继续说.
这个阶段叫做半关闭阶段,客户端只能回复收到,不会再有新的请求
如果服务端也说完了,没有其他话要说了,就发送FIN
然后客户端收到FINI之后知道服务端也没得说了,回复收到
到此整个连接关闭
流量控制
区分流量控制和拥塞控制:
流量控制是避免接收方来不及接收,缓冲区溢出
拥塞控制是避免网络拥塞
为啥要进行流量控制?
接收方的缓冲区大小有限,要保证接收方来得及接收消息并腾出缓冲区
如果发送方发的过快,接收方处理慢,缓冲区满了,那么后来的消息就会被直接丢弃
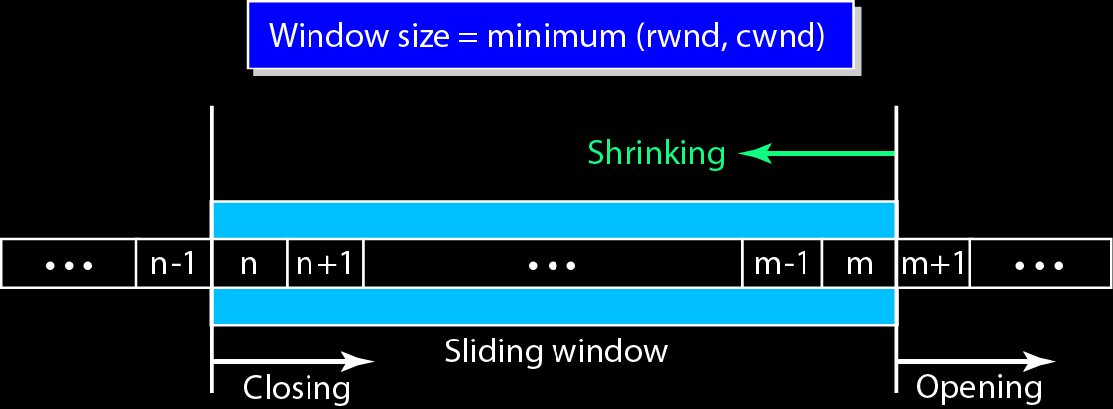
如何进行流量控制?滑动窗口算法
滑动窗口算法
$$
发送方滑动窗口大小swnd=min(接收方滑动窗口大小rwnd,拥塞窗口大小cwnd)
$$
其中rwnd是接收方缓冲区剩余空间大小
比如接收方缓冲区本身4KB,发送方发了一个1K的报文,填到接收方缓冲区中,此时接收方rwnd=3000,接收方就得在ACK报文中报告自己的rwnd大小,让发送方心里有数,后面该法多少
cwnd是发送方自己维护的,发送方根据接收方的回应报文丢失情况,推测网络的拥塞程度,动态调整cwnd的大小
TCP滑动窗口和数据链路层滑动窗口的区别:
TCP滑动窗口的单位是字节,而数据链路层滑动窗口的单位是帧
数据链路层的滑动窗口大小是固定的,而TCP滑动窗口大小根据实时情况改变
如图所示的滑动窗口(只是一个例子,实际上一个滑动窗口有成百上千字节)中,cwnd=20,rwnd=9,
这就意味着接收方此时的缓冲区只有9个字节的空间了,发送方顶多再发送9字节
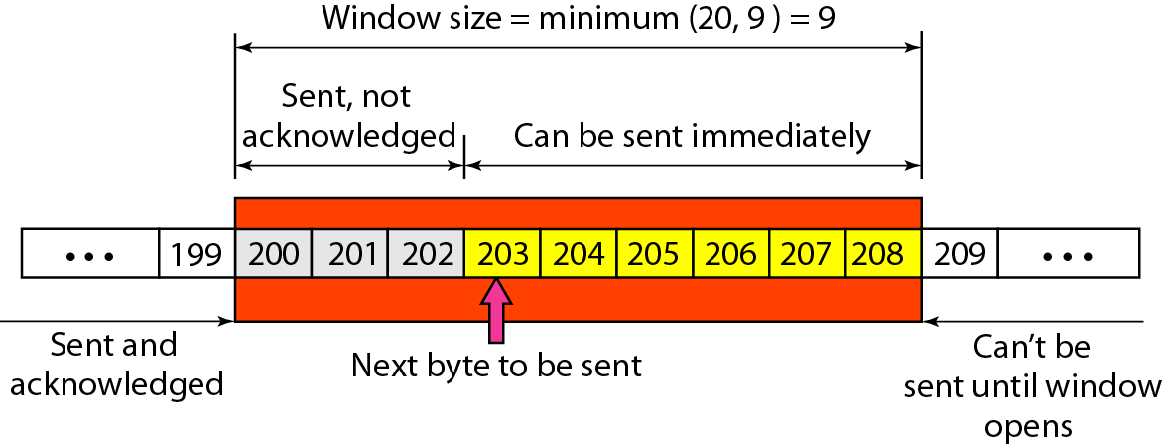
此时发送方啥状态呢?目前滑动窗口中的200,201,202三个字节都已经发送,可能是一个报文同时发走的,也可能是分批发走的,但是这不重要,重要的是,目前尚未得到接收方的ACK回复.发送方现在还可以接着发送203~208这6个字节.
如果发完了这6个字节仍热没有收到回复,就不能发了,得等等
时序图

首先发送方得等接收方告知自己的接收窗口大小
拿到这个数之后,发送方就可以在这个接收窗口大小和拥塞窗口大小中娶一个最小值,然后放心地发送这么多字节
这些字节不必是一个报文发走的,这要看链路层对一个数据帧的限制,比如以太网帧中的数据不能超过1500字节.因此,即使swnd=min(cwnd,rwnd)=2400,也得分成多个报文发送
接收方会对发送方的每一个报文都进行回复,回复内容包括:
1.期待接收的下一个字节编号
2.当前接收方窗口剩余大小
当接收方的回复报文中,swnd=0时,发送方就得停下等接收方消化消化.
接收方消化一阵子之后,缓冲区有比较大的空间,能够容纳一个大帧时,才会主动发送更新报文.告知发送方,可以继续灌输了
等待缓冲区有较大空间的目的是,防止糊涂窗口综合征
这个更新报文的内容包括:
1.期待接收的下一个字节编号
2.当前接收方窗口剩余大小
为了防止这个更新报文丢包,发送方有一个坚持计时器.当发送方接到swnd=0的回复报文就开始了.如果在到时之前收到更新报文自然最好.如果没有收到,则发送方认为更新报文在路上丢了,于是发送方发送一个1字节的探测报文,提醒接收方更新报文丢失了.
差错控制
TCP的差错控制有三个手段
1.校验和,接收方收到坏段,丢弃并要求重传,通过ACK+坏段序号 要求重传
2.确认
发送方发出的每一个数据段都需要ACK确认
不携带数据但是占用序号的控制段也需要确认
ACK段不需要确认,因为ACK本身就是确认用的
3.重传
当段损坏,丢失或者超时,需要重传
ACK段不需要重传
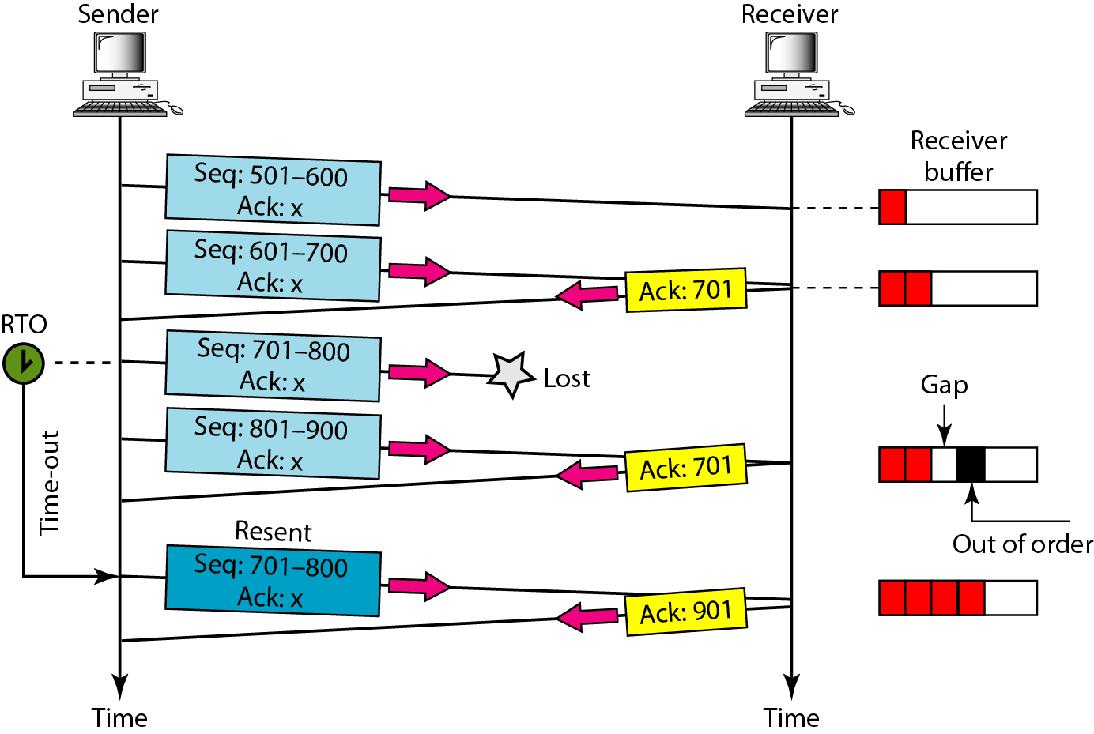
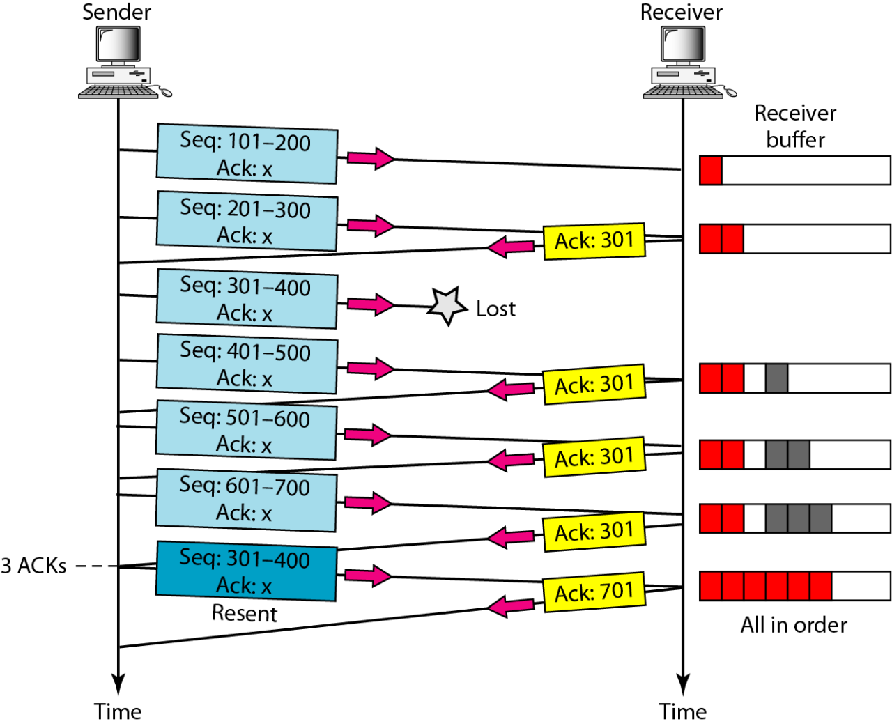
重传的情形:
1.丢失段
2.3ACK快速重传
拥塞控制
拥塞控制可以理解为网络流问题
一条主干道的带宽是1000Mbps,其支线的带宽和是1500Mbps,如果所有支线都满载传输,则骨干路由器就得缓存支线的数据报文,满满地往主干道发.
如果骨干路由器缓冲区溢出,就有数据丢包了
拥塞控制还是滑动窗口算法,并且和流量控制兼容,体现在
$$
swnd=min(cwnd,rwnd)
$$
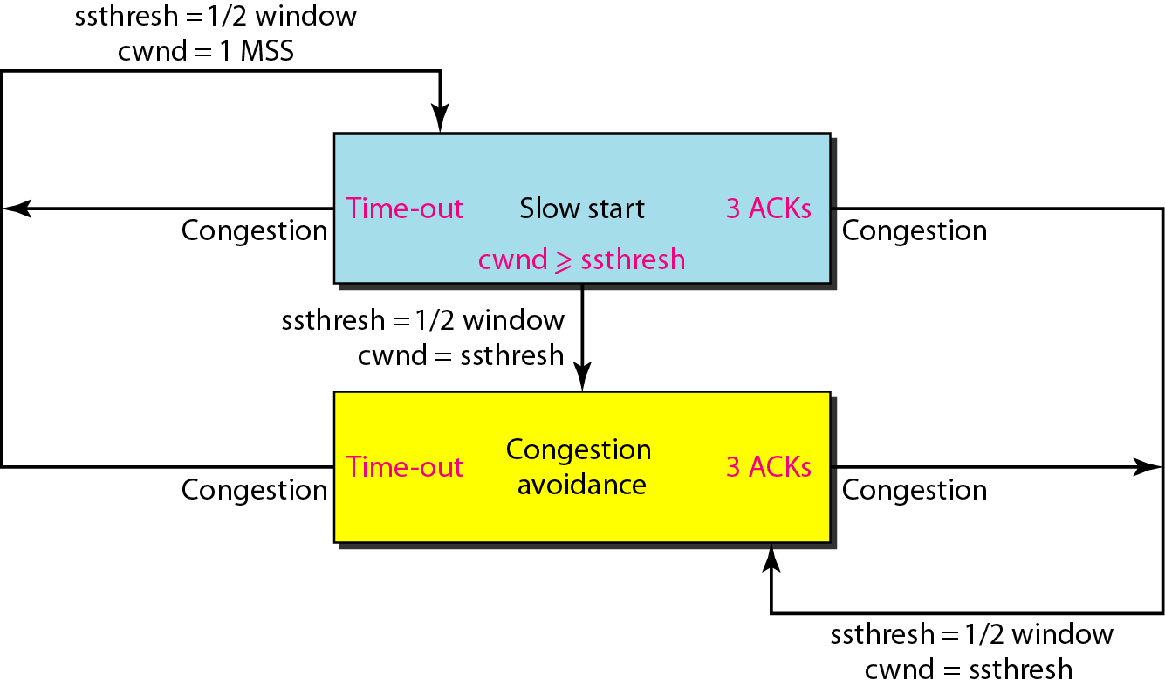
慢启动和拥塞避免
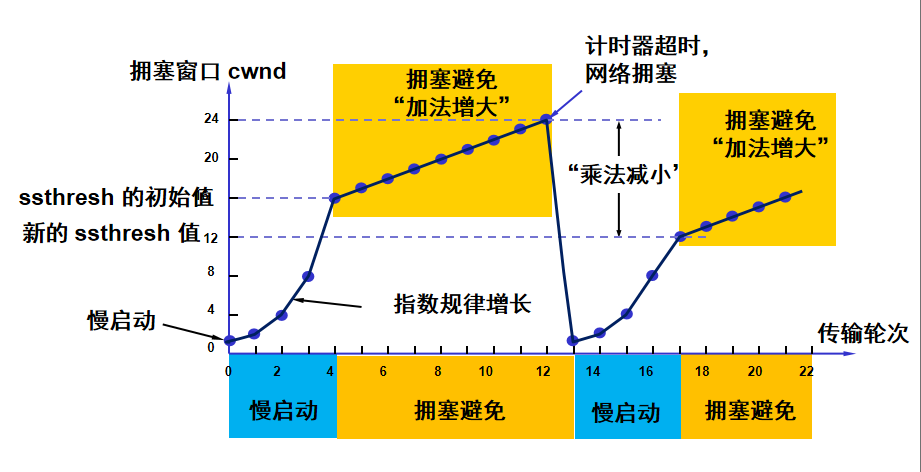
最初慢启动阶段,cwnd=1,发一个报文,收到ACK,这就意味着一次发一个包,网络可以承受,于是蹬鼻子上脸,cwnd=2,发俩报文,等俩ACK,如果又都受到了,那就更加猖狂
一直到慢启动阈sstresh,之后就不能指数扩大cwnd了,需要加性增大,也就是发一个包收到ACK就cwnd扩大1,一直这样直到计时器超时,说明达到网络流量上限了,
此时立刻回到慢启动阶段,cwnd=1,并重新设置ssthresh阈值为超时cwnd的一半
之后重复上述过程
3ACK快速恢复
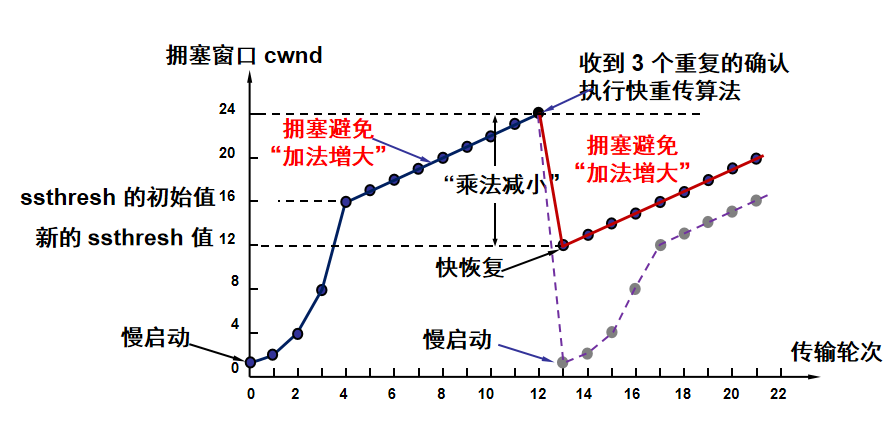
能够收到3ACK说明网络只是轻度拥塞
此时直接ssthresh降为收到3ACK时cwnd的一半,然后设置cwnd=ssthresh,然后重复加性增大阶段
状态转移图