Antlr4
项目地址DeutschBall/Interpreter-Antlr: Antlr实现的函数绘图语言解释器 (github.com)
环境配置
这种生成命令,实际上这里的antlr执行的命令是
1
| java org.antlr.v4.Tool ./Hello.g4
|
也就是说,org.antlr.v4.Tool应该是在CLASSPATH中的
在windows中需要在变量CLASSPATH中加上jar包的地址

任何一个Antlr源文件,比如Hello.g4,如果语法没有错误,执行antlr4 Hello.g4之后,都会生成六个文件
| 文件 |
作用 |
|
| HelloParser.java |
不想写 |
|
| HelloLexer.java |
|
|
| Hello.tokens |
|
|
| HelloLexer.tokens |
|
|
| HelloListener.java |
|
|
| HelloBaseListener.java |
|
|
词法分析器
词法分析器实现,继承自org.antlr.v4.runtime.Lexer
这个类干了啥呢?
首先,*Lexer.java文件中是没有main函数的,这就意味着,这个类只能作为其他类的组成,或者被其他函数调用
从名字上看,这个类应该得有一个DFA,不管是表驱动的还是有向图驱动的还是硬编码的,得有一个输入,然后从输入中获取符号流,然后在DFA上进行状态转移,每次调用它,都应返回一个识别出的记号token
举个例子,统计单词数量
antlr语法规则文件这样写:
Counter.g4
1
2
3
4
| lexer grammar Counter;
WORD: [a-zA-Z0-9]+;
SPACE: [ \t\n\r]->skip;
|
然后执行命令antlr4 ./Counter.g4
由于g4文件中只定义了词法规则 lexer grammer,因此只会生成词法分析器相关的文件
| 文件 |
作用 |
|
| Counter.interp |
|
|
| Counter.java |
词法分析器类 |
|
| Counter.tokens |
定义符号与到整数的映射 |
|
生成一堆文件,其中就包括Counter.java,也就是词法分析器文件
这里面就一个Counter类,它干了啥呢?
最主要的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public static final String _serializedATN =
"\3\u608b\ua72a\u8133\ub9ed\u417c\u3be7\u7786\u5964\2\4\20\b\1\4\2\t\2"+
"\4\3\t\3\3\2\6\2\t\n\2\r\2\16\2\n\3\3\3\3\3\3\3\3\2\2\4\3\3\5\4\3\2\4"+
"\5\2\62;C\\c|\5\2\13\f\17\17\"\"\2\20\2\3\3\2\2\2\2\5\3\2\2\2\3\b\3\2"+
"\2\2\5\f\3\2\2\2\7\t\t\2\2\2\b\7\3\2\2\2\t\n\3\2\2\2\n\b\3\2\2\2\n\13"+
"\3\2\2\2\13\4\3\2\2\2\f\r\t\3\2\2\r\16\3\2\2\2\16\17\b\3\2\2\17\6\3\2"+
"\2\2\4\2\n\3\b\2\2";
public static final ATN _ATN =
new ATNDeserializer().deserialize(_serializedATN.toCharArray());
static {
_decisionToDFA = new DFA[_ATN.getNumberOfDecisions()];
for (int i = 0; i < _ATN.getNumberOfDecisions(); i++) {
_decisionToDFA[i] = new DFA(_ATN.getDecisionState(i), i);
}
}
|
其中有一个硬编码的static字符串,其中存放了序列化的ATN,ATN是啥?状态转移网络
这里_ATN这个static成员在本类的加载时,就会反序列化_serializedATN,建立ATN网络,
然后static静态代码块中,以ATN网络为基础建立了DFA
至于这个序列化ATN字符串什么含义,我不想研究,相当于硬编码的DFA
本类中害保存了符号名称,比如WORD,SPACE
本类从org.antlr.v4.runtime.Lexer基类中继承了nextToken等函数,nextToken函数每次被调用会识别一个符号
如何使用该类呢?
可以写一个测试类TestLexer.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.Token;
public class TestLexer {
public static void main(String[] args) {
int cnt_words=0;
CharStream input = CharStreams.fromString("public static void main");
Counter lexer=new Counter(input);
Token token;
while((token=lexer.nextToken()).getType()!=Token.EOF){
String tokenName=Counter.VOCABULARY.getSymbolicName(token.getType());
String tokenText=token.getText();
System.out.printf("%s: %s%n",tokenName,tokenText);
if(tokenName=="WORD"){
++cnt_words;
}
}
System.out.println("total words="+cnt_words);
}
}
|
从字符串”public static void main”创建一个字符输入流,然后将这个流作为Counter lexer的输入
此后每次调用lexer.nextToken(),lexer都会尝试从该字符输入流中获取一个符号,符号的类型是org.antlr.v4.runtime.Token
语法分析器
以计算器为例
Calculator.g4
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| grammar Calculator;
prog: stat+;
stat: expr NEWLINE
|ID '=' expr NEWLINE
|NEWLINE
;
expr: expr ('*'|'/') expr
|expr ('+'|'-') expr
|INT
|ID
|'(' expr ')'
;
ID: [a-zA-Z]+;
INT:[0-9]+;
WS:[ \t\n]+ ->skip;
NEWLINE: '\r'? '\n';
|
执行命令antlr4 ./Calculator.g4之后,会在本目录下生成
| 文件 |
作用 |
|
| CalculatorLexer.java |
词法分析器类 |
|
| CalculatorParser.java |
语法分析器类 |
|
| CalculatorListener.java |
监听器接口 |
|
| Calculator.BaseListener.java |
监听器基类 |
|
|
|
|
| … |
|
|
写一个测试类Test,测试语法分析器的作用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| import org.antlr.runtime.ANTLRInputStream;
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.Token;
import java.io.FileInputStream;
import java.io.InputStream;
import org.antlr.v4.runtime.tree.*;
import org.antlr.v4.tool.ANTLRToolListener;
public class Test {
public static void main(String[] args) {
String inputFile=null;
if(args.length>0){
inputFile=args[0];
}
CharStream input=null;
InputStream is=System.in;
try{
if(inputFile!=null){
is=new FileInputStream(inputFile);
}
input=CharStreams.fromStream(is);
}catch(Exception e){
e.printStackTrace();
}
CalculatorLexer lexer=new CalculatorLexer(input);
CommonTokenStream tokens=new CommonTokenStream(lexer);
CalculatorParser parser=new CalculatorParser(tokens);
ParseTree tree=parser.prog();
System.out.println(tree.toStringTree(parser));
}
}
|
1
2
3
4
5
6
| javac Calculator*.java Test.java
java Test "in.dat"
line 6:14 missing ')' at '\r\n'
(prog (stat (expr 101) \r\n) (stat a = (expr 5) \r\n) (stat b
= (expr 3) \r\n) (stat (expr (expr a) + (expr (expr b) * (expr 2))) \r\n) (stat (expr (expr ( (expr (expr 1) + (expr a)) ))
/ (expr 2)) \r\n) (stat (expr (expr ( (expr (expr 5) + (expr 6)) )) * (expr ( (expr (expr 4) + (expr ( (expr (expr 7) - (expr 8)) ))) <missing ')'>)) \r\n))
|
也可以不写测试类,直接使用grun测试
1
2
3
4
5
| PS C:\Users\Administrator\Desktop\antlr> grun Calculator prog
-gui in.dat
C:\Users\Administrator\Desktop\antlr>java org.antlr.v4.gui.TestRig Calculator prog -gui in.dat
line 6:14 missing ')' at '\r\n'
|
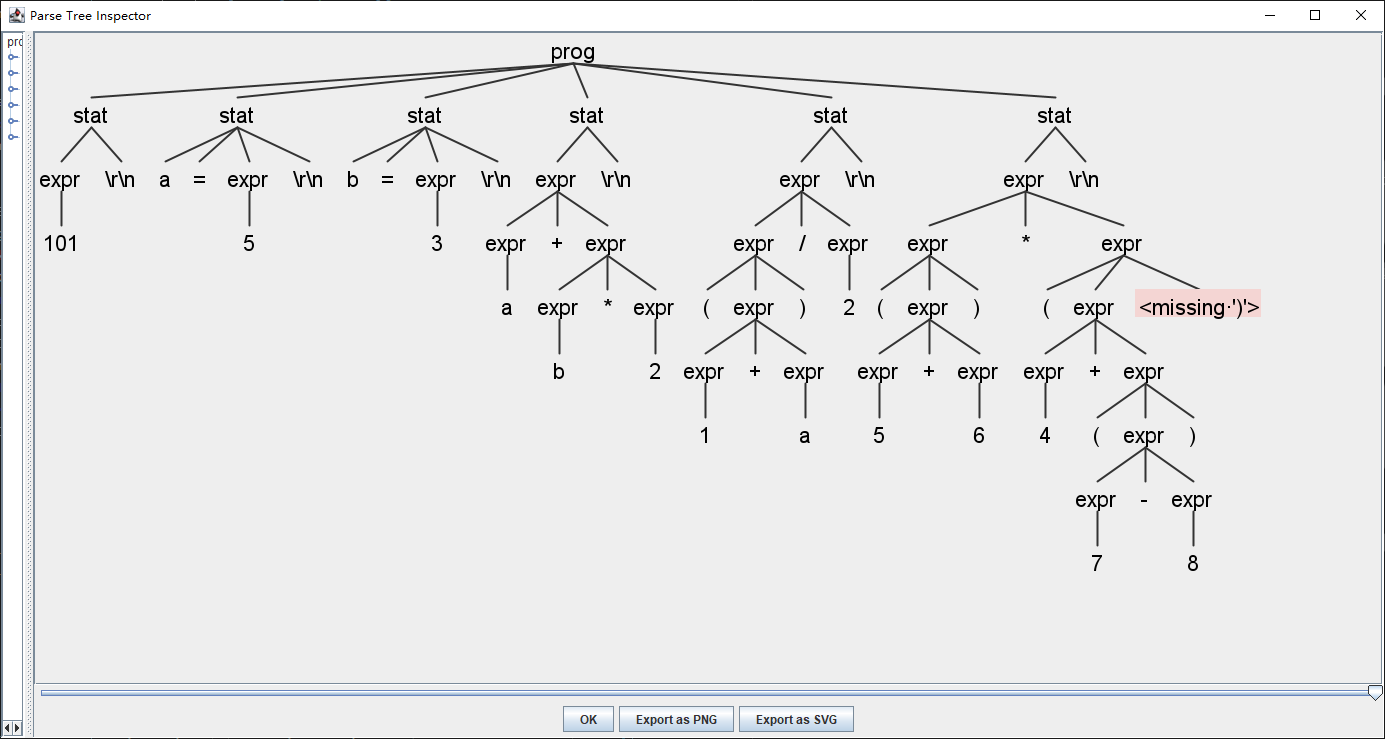
antlr会自动检测语法错误,并且会自动从错误中恢复,继续进行语法分析
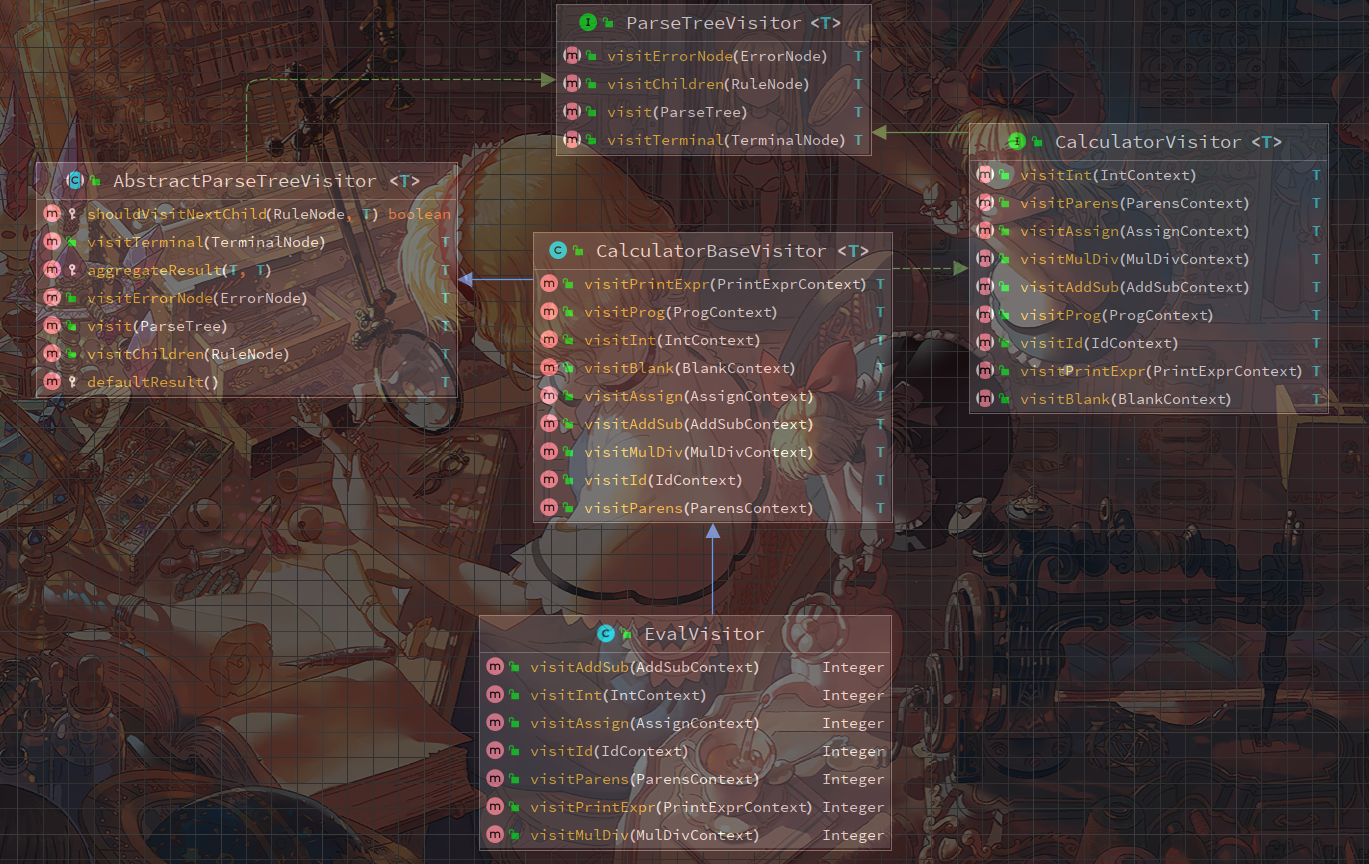
访问器
前面的语法分析器中,我们并没有定义语义规则,语法树是antlr自动帮我们生成的,现在需要定义语义动作,实现计算器功能
antlr不推荐在g4规则文件中定义语义动作,而是在本文件中定义标签,然后在Visitor类中实现标签相关的函数
定义语义规则标签
比如Calculator.g4
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| grammar Calculator;
// import LexerRule;
// 语法定义
prog: stat+;
stat: expr NEWLINE #printExpr
|ID '=' expr NEWLINE #assign
|NEWLINE #blank
;
expr: expr ('*'|'/') expr #MulDiv
|expr ('+'|'-') expr #AddSub
|INT #int
|ID #id
|'(' expr ')' #parens
;
MUL: '*';
DIV: '/';
ADD: '+';
SUB: '-';
ID: [a-zA-Z]+;
INT:[0-9]+;
WS:[ \t\n]+ ->skip;//多余的空格回车忽略
NEWLINE: '\r'? '\n';//\r\n是win上的换行符,\r是linux上的换行
|
这里的#printExpr,#assign等就是标签
然后使用下述命令生成
生成访问器基类
1
| antlr4 -visitor Calculator.g4
|
额外生成了两个文件
| 文件 |
作用 |
| CalculatorVisitor.java |
访问器接口 |
| CalculatorBaseVisitor.java |
访问器基类 |
这个访问器接口定义了一些函数
1
2
3
4
5
6
7
8
9
10
11
|
import org.antlr.v4.runtime.tree.ParseTreeVisitor;
public interface CalculatorVisitor<T> extends ParseTreeVisitor<T> {
T visitProg(CalculatorParser.ProgContext ctx);
T visitPrintExpr(CalculatorParser.PrintExprContext ctx);
...
}
|
每个Calculator.g4中的标签都会对应一个接口函数,比如#printExpr对应到visitPrintExpr
即使是没有写标签的文法,也会对应一个接口函数,比如prog对应到visitProg
既然这样,为啥还要定义标签?使用默认的文法名
1
2
3
4
5
6
| prog: stat+;
stat: expr NEWLINE #printExpr
|ID '=' expr NEWLINE #assign
|NEWLINE #blank
;
|
对比一下,prog只有一条规则,但是stat有三条规则,因此需要给每个规则定义一个标签,方便给该规则上语义动作
也就是说,每一个翻译规则对应一个标签
1
2
3
| stat -> expr NEWLINE #printExpr
stat -> ID '=' expr NEWLINE #assign
stat -> NEWLINE #blank
|
要怎么用这个访问器呢?
定制访问器
只需要用一个EvalVisitor继承这个CalculatorBaseVisitor,然后在EvalVisitor中实现函数功能即可
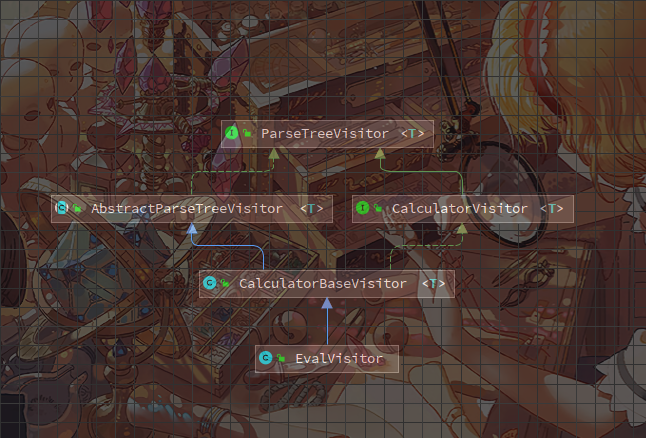
不需要全都实现,因为CalculatorBaseVisitor中已经帮我们实现了默认方法
1
2
3
4
| @Override
public T visitPrintExpr(CalculatorParser.PrintExprContext ctx) {
return visitChildren(ctx);
}
|
以visitAssign的实现为例
1
2
3
4
5
6
| public Integer visitAssign(CalculatorParser.AssignContext ctx) {
String id=ctx.ID().getText();
int value=visit(ctx.expr());
memory.put(id,value);
return value;
}
|
CalculatorParser.AssignContext ctx是个什么玩意儿,都有啥成员?
visit函数干了啥?
首先,CalculatorParser是antlr4命令生成的语法分析器类,AssignContext是其内部类
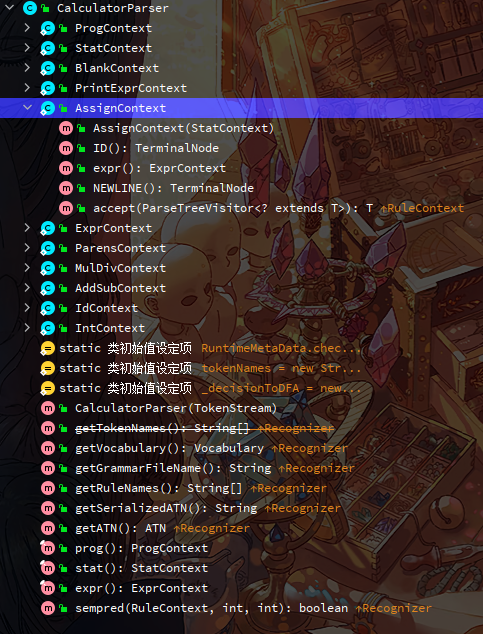
CalculatorParser中有众多内部类,每个标签分别对应一个内部类
1
2
3
4
5
6
7
8
9
10
11
12
13
| public static class AssignContext extends StatContext {
public TerminalNode ID() { return getToken(CalculatorParser.ID, 0); }
public ExprContext expr() {
return getRuleContext(ExprContext.class,0);
}
public TerminalNode NEWLINE() { return getToken(CalculatorParser.NEWLINE, 0); }
public AssignContext(StatContext ctx) { copyFrom(ctx); }
@Override
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof CalculatorVisitor ) return ((CalculatorVisitor<? extends T>)visitor).visitAssign(this);
else return visitor.visitChildren(this);
}
}
|
每个这种*Context内部类的实例,都是语法树上的节点,这一点可以观察*Context的类体系验证
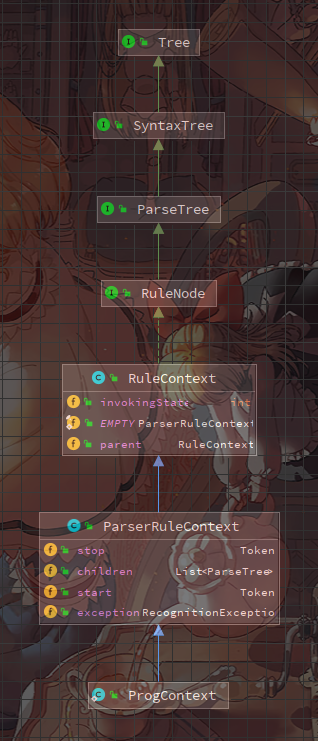
任何*Context的直接父类都是ParseRuleContext类,该类中有一个List<ParseTree> children数组,用来存放子节点的句柄
无需置疑,这就是节点类
EvalVisitor,CalculatorParser,ParserTree三者是如何交互的?
跟随测试类的控制流观察
1
2
3
| ParseTree tree=parser.prog();
EvalVisitor eval=new EvalVisitor();
eval.visit(tree);
|
ParserTree以parser.prog()入口,可以推测该函数应该是整个递归下降语法分析的入口,其返回值是一个 以prog节点为根的语法树,然后将该树根交给句柄tree
根据我们自己写的文法,整个程序确实只有一个prog,然后是prog->stat+,也就是推导成若干stat
下面验证一下这个prog函数是否如我们所料
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public final ProgContext prog() throws RecognitionException {
ProgContext _localctx = new ProgContext(_ctx, getState());
enterRule(_localctx, 0, RULE_prog);
int _la;
try {
enterOuterAlt(_localctx, 1);
{
setState(7);
_errHandler.sync(this);
_la = _input.LA(1);
do {
{
{
setState(6);
stat();
}
}
setState(9);
_errHandler.sync(this);
_la = _input.LA(1);
} while ( (((_la) & ~0x3f) == 0 && ((1L << _la) & ((1L << T__1) | (1L << ID) | (1L << INT) | (1L << NEWLINE))) != 0) );
}
}
catch (RecognitionException re) {
_localctx.exception = re;
_errHandler.reportError(this, re);
_errHandler.recover(this, re);
}
finally {
exitRule();
}
return _localctx;
}
|
正如我们所料,prog函数的do-while循环中调用了stat函数
prog= stat \n stat \n stat…
这个prog函数中的do-while循环,每循环一次,递归下降分析一次stat
为啥do-while循环的继续条件是”下一个待解析的词法符号的类型是 T__1、ID、INT 或 NEWLINE 中的任意一种,就执行循环体中的语句”
所有的词法符号类型都被定义在CalculatorLexer.tokens中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| T__0=1
T__1=2
T__2=3
MUL=4
DIV=5
ADD=6
SUB=7
ID=8
INT=9
WS=10
NEWLINE=11
'='=1
'('=2
')'=3
'*'=4
'/'=5
'+'=6
'-'=7
|
T__1==’(‘
也就是说,下一个符号必须得是’(‘,或者ID,INT,NEWLINE
然而再看我们的语法规则定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| prog: stat+;
stat: expr NEWLINE #printExpr
|ID '=' expr NEWLINE #assign
|NEWLINE #blank
;
expr: expr ('*'|'/') expr #MulDiv
|expr ('+'|'-') expr #AddSub
|INT #int
|ID #id
|'(' expr ')' #parens
;
|
对stat求一下First集合
1
| first(stat)=first(expr)+{ID}+{NEWLINE}={'(',INT,ID,NEWLINE}
|
正好就是do-while循环的条件
根据编译原理的理论,只有当下一个符号在当前文法的First集合中时,才会从当前文法开始进行递归下降语法分析
还有一个问题,prog节点是何时把诸多stat节点设为自己的字节点的,也就是说stat节点是何时挂到语法树上的?
Stat节点何时挂到Prog树根上去的?
到stat函数中看一看,第一行就创建了stat节点,和prog的第一行结构几乎一样,StatContext构造函数的第一个参数_ctx,这是一个全局变量,时刻维护当前节点的父节点.这样创建出的节点就知道自己的父节点是谁了
1
2
| public final StatContext stat() throws RecognitionException {
StatContext _localctx = new StatContext(_ctx, getState());
|
这一点也可以在StatContext的构造函数中验证
1
2
3
4
| public StatContext(ParserRuleContext parent, int invokingState) {
super(parent, invokingState);
}
|
那么stat知道自己的父节点是谁了,prog又是如何知道自己的子节点是谁的呢?
动态调试发现,stat函数执行后,ProgContext的Chindren数组就会多一个StatContext节点,具体怎么知道的,不想深究
回到正题,visit函数干了啥
1
2
3
| ParseTree tree=parser.prog();
EvalVisitor eval=new EvalVisitor();
eval.visit(tree);
|
到现在位置,这三条的第一条分析完毕,目前tree是一个ProgContext句柄,语法树的树根
下面分析eval.visit(tree)干了啥
这个visit是AbstractParseTreeVisitor实现的
1
2
3
| public T visit(ParseTree tree) {
return tree.accept(this);
}
|
这个tree.accept也是一个接口方法,每一个*Context类都有实现
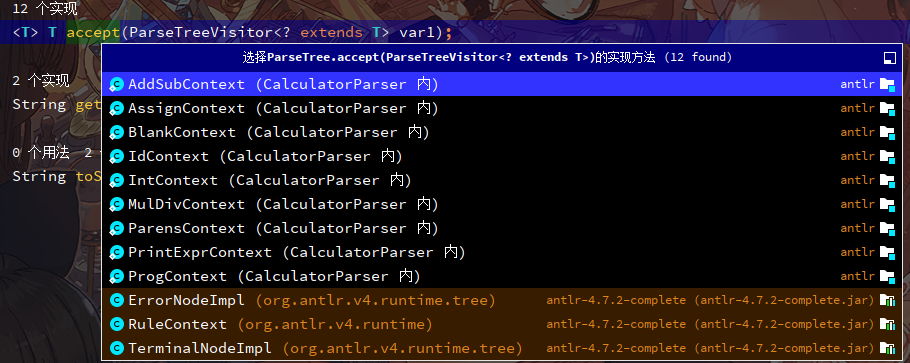
就以AssignContext.accept()为例
1
2
3
4
5
| public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof CalculatorVisitor )
return ((CalculatorVisitor<? extends T>)visitor).visitAssign(this);
else return visitor.visitChildren(this);
}
|
如果当前节点visitor是CalculatorVisitor接口的实例,则返回visitor.visitAssign(this),也就是assign标签对应的语义动作
1
2
3
4
5
6
| public Integer visitAssign(CalculatorParser.AssignContext ctx) {
String id=ctx.ID().getText();
int value=visit(ctx.expr());
memory.put(id,value);
return value;
}
|
现在知道了A.visit函数会调用EvalVisitor中当前节点对应的visitA函数
但是我们没有给prog->stat+定义标号,在EvalParser中并没有找到一个visitProg这样的函数,那么eval.visit(tree);到底调用了谁?动态调试发现调用的是CalculatorBaseVisitor类中的vistProg函数
1
| @Override public T visitProg(CalculatorParser.ProgContext ctx) { return visitChildren(ctx); }
|
而在该类中的所有vist*函数,都只是简单的递归visitChildren,访问子节点
1
2
3
4
| @Override public T visitPrintExpr(CalculatorParser.PrintExprContext ctx) { return visitChildren(ctx); }
@Override public T visitAssign(CalculatorParser.AssignContext ctx) { return visitChildren(ctx); }
@Override public T visitBlank(CalculatorParser.BlankContext ctx) { return visitChildren(ctx); }
...
|
其中vistAssign等被我们在EvalVisitor重写,因此不会调用父类中的简单实现
也就是说eval.visit(tree);就是中心开花了,递归访问树根ProgContext的每个子节点StatContext,然后每个stat都会再递归调用自己的子节点的visit函数,文法翻译的过程就对应了这个递归调用的过程,其中语义动作的翻译,被我们重写在EvalVisitor中,会执行我们自定义的函数.其中没有语义动作的翻译,直接调用基类中的默认实现,直接递归子节点
到此理清了CalculatorParser,EvalVisitor,ParserTree等几个类之间的关系和控制流的流向
总结用antlr访问器实现计算器的步骤
1.写Calculator.g4词法,语法规则文件,留标签为定义语法做准备
2.用antlr -visitor命令生成Calculator*.java一众文件
3.EvalVisitor类继承CalculatorBaseVisitor类
4.在EvalVisitor类中重写标签相对应的语义规则
5.编写测试类Test,于其中指定输入流,组装lexer,组装 parser,建立ParserTree,用EvalVisitor实例,访问语法树实例