[AFL V] afl-analyze
本工具用于尝试理解输入文件的结构
举个🌰
假设有这么一种结构:

1
2
3
4
5
6
7
| ┌──(root㉿Destroyer)-[/home/dustball/myfile]
└─# xxd dustland
00000000: 6475 7374 3400 0000 6161 6161 6161 6161 dust4...aaaaaaaa
00000010: 6161 6161 6161 6161 6161 6161 6161 6161 aaaaaaaaaaaaaaaa
00000020: 6262 6262 6262 6262 6261 6161 6161 6161 bbbbbbbbbaaaaaaa
00000030: 6161 6162 6162 6162 6162 6161 6c61 6e64 aaababababaaland
00000040: 3f14 1d10 ?...
|
该结构前后有两个元数据块, 中间是数据块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#ifndef FORMAT_DSTB_H
#define FORMAT_DSTB_H
#define DSTB_HEADER_MAGIC 0x74737564
#define DSTB_FOOTER_MAGIC 0x646e616c
typedef struct{
unsigned magic;
int data_size;
}DSTB_Header;
typedef struct {
unsigned magic;
unsigned check_sum;
}DSTB_Footer;
#endif
|
构造器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
#include "format_dstb.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc, char *argv[]){
char *input = argv[1];
char *output = argv[2];
FILE * fp = fopen(input, "rb");
fseek(fp, 0, SEEK_END);
int file_size = ftell(fp);
int data_size = (file_size + 3) & ~3;
char *data = malloc(data_size);
memset(data, 0, data_size);
fseek(fp, 0, SEEK_SET);
fread(data, 1, file_size, fp);
fclose(fp);
DSTB_Header header = {
.magic = DSTB_HEADER_MAGIC,
.data_size = data_size
};
DSTB_Footer ender = {
.magic = DSTB_FOOTER_MAGIC,
.check_sum = 0
};
unsigned check_sum = 0;
check_sum = header.magic ^ header.data_size;
for(int i = 0; i < data_size; i++){
check_sum ^= data[i];
}
check_sum ^= ender.magic;
ender.check_sum = check_sum;
FILE * out = fopen(output, "wb");
fwrite(&header, sizeof(DSTB_Header), 1, out);
fwrite(data, 1, data_size, out);
fwrite(&ender, sizeof(DSTB_Footer), 1, out);
fclose(out);
return 0;
}
|
为其编写parser
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| #include "format_dstb.h"
#include <stdio.h>
#include <unistd.h>
int main(int argc, char *argv[]){
char input[300];
int file_len = read(0,input,300);
DSTB_Header *header = (DSTB_Header*)input;
if(header->magic!= DSTB_HEADER_MAGIC){
printf("Invalid header magic\n");
return 0;
}
int data_size = header->data_size;
char *data = input + sizeof(DSTB_Header);
char *footer = data + data_size;
DSTB_Footer *f = (DSTB_Footer*)footer;
if(f->magic!= DSTB_FOOTER_MAGIC){
printf("Invalid footer magic\n");
}
int check_sum = 0;
check_sum = header->magic ^ header->data_size;
for(int i=0;i<data_size;i++){
check_sum ^= data[i];
}
check_sum ^= f->magic;
check_sum ^= f->check_sum;
printf("Data size: %d\n",data_size);
printf("Check sum: %d\n",check_sum);
if(check_sum != 0){
printf("Invalid check sum\n");
}
puts("accepted");
return 0;
}
|
接下来用afl-analyze分析文件结构
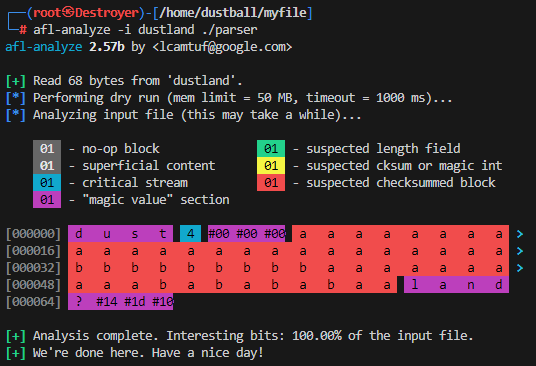
afl发现了两个魔数、数据块
虽然没有发现校验和, 但是能发现这已经很神奇了
并且这界面花花绿绿的, 着实豪堪
🧄法原理
首先保持输入不变, dry_run一次 ,记录执行路径共享内存校验和为orig_cksum
然后遍历输入, 对于每个字节, 分别进行如下四个变异操作:
1.整体取反, 执行 , 记录执行后的共享内存校验和xor_ff
2.末位取反, 执行 , 记录校验和xor_01
3.减去0x10, 执行 , 记录校验和sub_10
4.加上0x10, 执行 , 记录校验和add_10
1
2
3
4
5
6
7
8
9
10
11
12
| in_data[i] ^= 0xff;
xor_ff = run_target(argv, in_data, in_len, 0);
in_data[i] ^= 0xfe;
xor_01 = run_target(argv, in_data, in_len, 0);
in_data[i] = (in_data[i] ^ 0x01) - 0x10;
sub_10 = run_target(argv, in_data, in_len, 0);
in_data[i] += 0x20;
add_10 = run_target(argv, in_data, in_len, 0);
in_data[i] -= 0x10;
|
这四个变异操作是单独执行的, 互相不影响, 每次操作之后都会当前字节还原
这样四个结果会有16种情况,afl-analyze只关心其中几种情况
1.四个检校和均和orig_cksum一致, 意味着对该字节任何变动不会影响执行路径 ,字微节轻
2.这四个检校和中有至少一个不等于orig_cksum, 认为该字节可以变异, 但是也就那样吧, 不太重要
3.四次变异后的检校和相同, 但是不等于orig_cksum, 则认为这个地方不能改, 比如文件魔数,检校和等等, 这里如果不对了则parser直接丢弃文件
4.四次变异之后的检校和与orig_cksum均不相同, 并且这四个检校和也各不相同, 说明该位置会显著影响控制流, 可能是一个switch case位置或者一个if的条件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| xff_orig = (xor_ff == orig_cksum);
x01_orig = (xor_01 == orig_cksum);
s10_orig = (sub_10 == orig_cksum);
a10_orig = (add_10 == orig_cksum);
if (xff_orig && x01_orig && s10_orig && a10_orig) {
b_data[i] = RESP_NONE;
boring_len++;
} else if (xff_orig || x01_orig || s10_orig || a10_orig) {
b_data[i] = RESP_MINOR;
boring_len++;
} else if (xor_ff == xor_01 && xor_ff == sub_10 && xor_ff == add_10) {
b_data[i] = RESP_FIXED;
} else b_data[i] = RESP_VARIABLE;
|
考虑到一个字段可能是连续的四个字节(int类型), 或者八个字节等等, afl-analyze会在给当前字节下结论之后, 再联系上一个字节看看
如果上一个字节和当前字节的四种检校和, 每种都各自不一样, 说明这相邻的两个字节的作用大不相同, 应该是不同的字段.
1
2
3
4
5
6
7
8
9
| if (prev_xff != xor_ff && prev_x01 != xor_01 &&
prev_s10 != sub_10 && prev_a10 != add_10) seq_byte ^= 0x80;
b_data[i] |= seq_byte;
prev_xff = xor_ff;
prev_x01 = xor_01;
prev_s10 = sub_10;
prev_a10 = add_10;
|
等所有的字节都变异一遍了, 下面要打印装👃界面了, 这里除了装👃还是有一些推理的
刚才已经初步给每个字节有一个判断, 并且也划分了字段, 现在利用上述信息:
对于字段的首字节是非常重要不能改的, 也就是上述变异结果中的第3个, “四次变异后的检校和相同, 但是不等于orig_cksum,”
如果这个字段长2字节字节
并且字段上的值的小端序或者大端序值, 比输入数据长度小, 那么认为这个字段是一个长度值
否则如果这个字段的首字节值和次字节值相差超过32, 那么认为这个字段是一个检校和
否则如果这个字段长4字节,
并且字段上的值的小端序或者大端序值, 比输入数据长度小, 那么认为这个字段是一个长度值
否则如果该字段的首字节最高位, 不等于其他字节之一的首字节最高位, 则认为该字段是一个校验和
其他长度就不得而知了
此部分代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| if (rtype == RESP_FIXED) {
switch (rlen) {
case 2: {
u16 val = *(u16*)(in_data + i);
if (val && (val <= in_len || SWAP16(val) <= in_len)) {
rtype = RESP_LEN;
break;
}
if (val && abs(in_data[i] - in_data[i + 1]) > 32) {
rtype = RESP_CKSUM;
break;
}
break;
}
case 4: {
u32 val = *(u32*)(in_data + i);
if (val && (val <= in_len || SWAP32(val) <= in_len)) {
rtype = RESP_LEN;
break;
}
if (val && (in_data[i] >> 7 != in_data[i + 1] >> 7 ||
in_data[i] >> 7 != in_data[i + 2] >> 7 ||
in_data[i] >> 7 != in_data[i + 3] >> 7)) {
rtype = RESP_CKSUM;
break;
}
break;
}
case 1: case 3: case 5 ... MAX_AUTO_EXTRA - 1: break;
default: rtype = RESP_SUSPECT;
}
}
|