设计模式
https://github.com/DeutschBall/DesignModel
六原则
单一职责原则
一个类负责的职责应该尽可能少,最好是单一功能。类应该只有一个引起自己变化的原因。
否则如果有两个以上功能,当用户只是用其中一个功能时还要导入其他无用功能
✨开放封闭原则
对拓展开放, 对修改关闭
已经写好的代码应该尽可能保持不变,新功能以拓展的形式实现,不应该以修改的形式出现
比如向有些if-else中添加判断条件就不满足改原则
依赖倒置原则
针对接口编程, 不针对实现编程
变量的声明类型尽量是抽象类或接口,这样我们的变量引用和实际对象间,就存在一个缓冲层,利于程序扩展和优化。
✨里氏替换原则
一个软件实体如果使用的是一个父类的话,那么一定适用于其子类,而且它察觉不出父类对象和子类对象的区别。也就是说,在软件里面,把父类都替换成它的子类,程序的行为没有变化.
高层模块不能依赖底层模块, 高层模块和底层模块都应依赖抽象.
考虑这么一个问题: 鸟类能否作为企鹅类的父类?
鸟类必须实现fly接口, 如果企鹅类继承鸟类, 意思就是企鹅也有fly接口, 但是企鹅显然不会飞. 因此这继承就不对.
也就是说, 只有子类可以完全替代父类, 才能使用继承.
迪米特法则
最少知识原则
1.最低访问权限
2.两个类彼此不通信则两个类不应当发生直接的相互作用
✨✨✨合成/聚合复用原则
优先使用对象的合成/聚合关系,而不是类继承关系
聚合(组合):弱拥有关系,A对象中可以包含B对象,也可以不包含。A对象和B对象离开对方都能独立存在。 个体与群组。
合成:强拥有关系,严格的部分和整体关系,两者共存亡。 器官与身体
优点是类的继承层次比较小。保持每个类被单独封装,集中精力面对单个任务。
UML类图
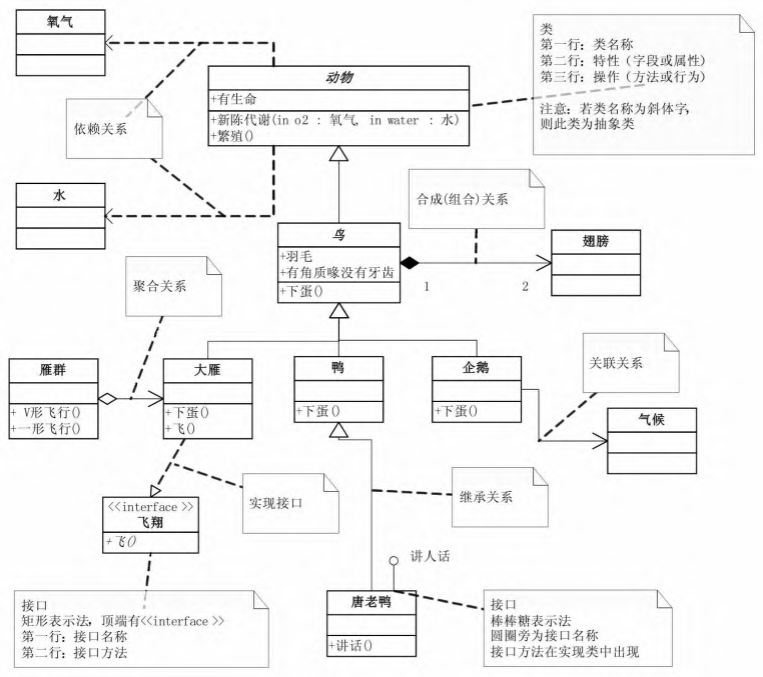
| 类关系 | 解释 | 例子 |
|---|---|---|
| 继承 | 继承一个父类 | 鸟类继承动物类 |
| 实现 | 实现一个接口 | 鸟类实现IFlyAble接口 |
| 依赖 | 类B作为类A方法的参数\局部变量,在A中临时存在 | |
| 关联 | 类B作为类A的成员变量,在A中永久存在 | 链表类中有一个附加头节点类的引用 |
| 聚合 | 个体可以离开整体存在 | |
| 组合 | 个体和整体共存亡,不可分开 | |
设计模式
创建型模式
创建对象同时隐藏创建逻辑,避免直接使用new运算符
工厂模式
简单工厂模式
简单工厂方法的弊端:违反了开放-封闭原则
简单工厂类需要接受一个类型参数,然后通过switch-case判断返回具体对象
如果要加入新的类型,那么就得改写这个switch-case逻辑,这就违反了开放-封闭原则
1 | static CashSuper* createCash(const std::string& type){ |
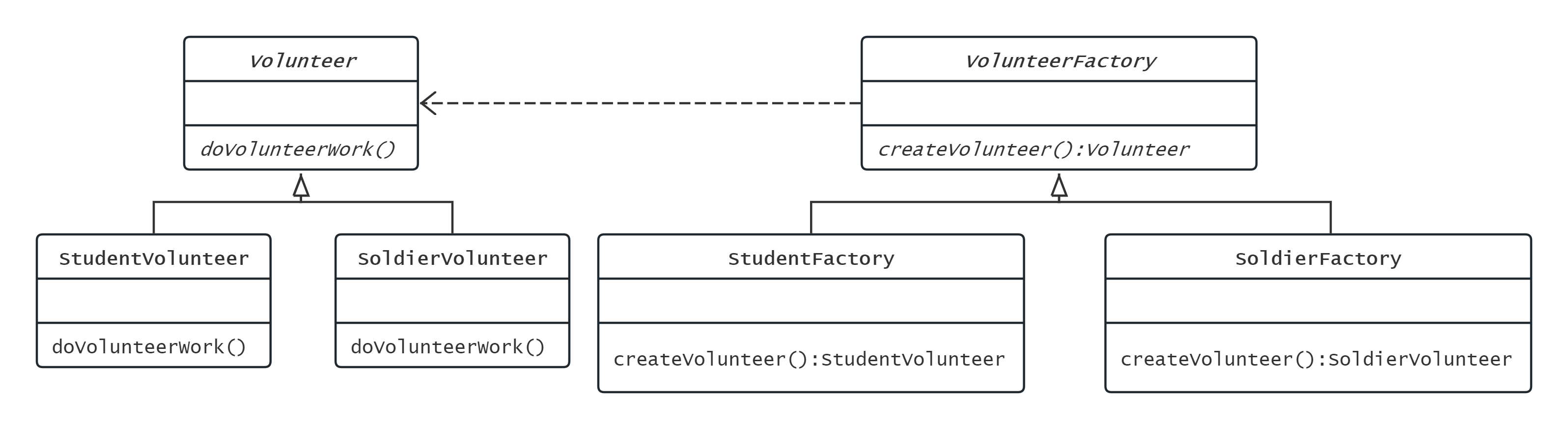
工厂方法模式
工厂方法模式是对简单工厂模式的改进,需要满足开放-封闭原则
抽象工厂模式
适用场景:
考虑这么一种场景
有两家工厂, 苹果工厂和联想工厂
两家工厂都生产计算机, 智能手机等电子产品
用户想要一款苹果手机
就是有多种品牌系统(在这里是联想和苹果),他们都能生产同种类的产品
此时就可使用抽象工厂模式
抽象工厂模式的实现流程:
1.定义抽象产品类, 在本例中是智能手机和计算机基类. 可以规定产品通用的功能接口, 比如手机可以打电话
2.定义具体产品类, 在本例中是苹果手机,苹果电脑, 联想手机,联想电脑
3.定义抽象工厂类, 规定任意工厂都能生产的产品类型, 在本例中是计算机和智能手机.
4.定义具体工厂类, 具体工厂类实现抽象工厂. 在本例中具体工厂就是苹果工厂和联想工厂.
具体工厂中生产具体产品, 实际上是实现抽象工厂规定的生产接口
抽象工厂规定要生产智能手机
苹果工厂中实现生产苹果手机
单例模式
保证一个类只有一个实例, 并提供一个全局访问点
懒汉模式: 在第一次使用单例时才创建它
饿汉模式: 在main函数之前, 也就是程序初始化时创建它
在多线程环境下, 懒汉模式会面临线程安全问题, 但是饿汉不会
因为饿汉创建单例是在main函数之前, 此时绝对不会有多个线程
但是懒汉模式下两个线程可能同时创建单例
1 | static SingletonLazy& getSingletonLazy(){ |
懒汉模式下的线程安全问题
可以使用双重锁解决这个问题
1 | static SingletonLazy& getSingletonLazy(){ |
两次判空的作用是?
加锁和上锁操作开销比较大, 应该尽量避免
假设有两个线程A,B同时通过了第一次判空
A线程首先持有m锁, 并通过了第二次判空, 创建了对象
B线程等A释放m锁后再持有, 此时B判空发现对象已经创建好了, 自己就不用再创建了
如果去掉外层判空, 依然是线程安全, 但是这样会导致, 不管对象是否被创建, 每个线程来了都先等锁, 即使不需要创建对象, 也要无意义等锁
如果去掉内层判空, 就不是线程安全的了, 考虑上述AB两个线程都经过了外层判空, A首先持有锁创建对象, 然后B持有锁看, B都不看是否有对象了就创建.还是会造成线程安全问题
静态局部变量的线程安全性
c++11之后静态局部变量的初始化是线程安全的
因此懒汉模式直接这样写, 也是线程安全的:
1 | static SingletonLazy& getSingletonLazy(){ |
实现原理:
1 | 0x00000000004012cf <+23>: lea rax,[rip+0x2ed2] # 0x4041a8 <_ZGVZN13SingletonLazy16getSingletonLazyEvE8instance> |
在第11行调用构造函数的前后, 编译器自动加上了guard
guard底层由SYS_futex系统调用实现
✨建造者模式
设计n个类表现汽车:
- 所有汽车都具备”行驶”的功能
- 汽车的”车门数量”可能不同
- 汽车按照能源类型分为”燃油车”和”电动车”,燃油车具备”加油”的能力,电动车具备”充电”的能力
- 汽车按照用途分为”轿车”和”卡车”,轿车没有额外功能,卡车具备”装载货物”的功能最终一辆4门电动卡车是如何表达的
车的组成 - 桥接模式
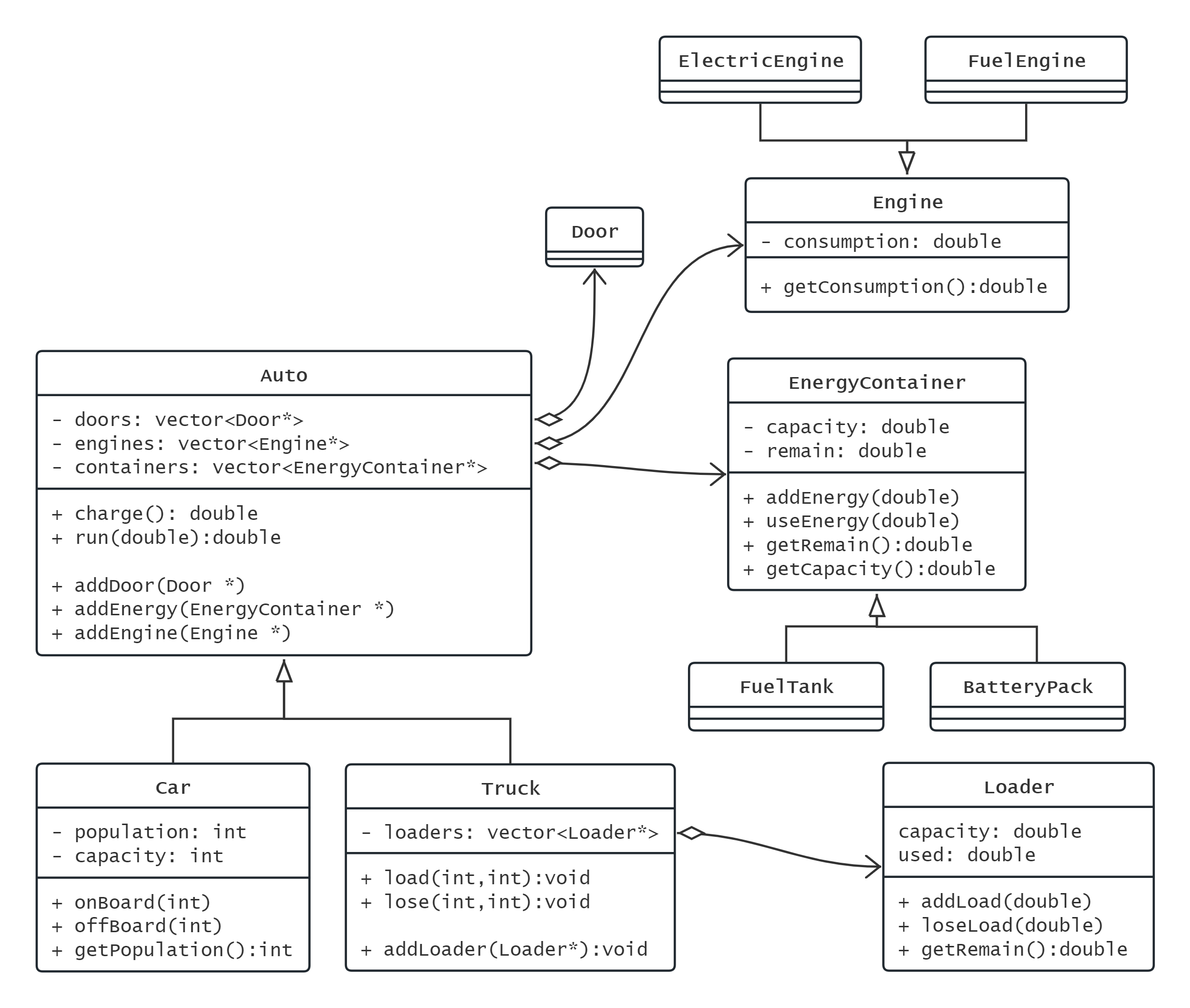
所有车辆共有的车门, 引擎, 能源等组件, 均以槽位的形式虚位以待 , 也就是车与这几个组件都是组合关系
车相关的类按照用途划分为卡车类和轿车类, 其中卡车类多一个loaders槽, 用于组合集装箱类
车的生产 - 建造者模式
用户实际上不关心车辆的构造, 用户只需要关心charge充能和run耗能行驶就够了
用户只需要提出需求“四门电动卡车”, 然后等着提货就完了
对于每种用户需求, 可以建立一个专门的Builder来满足需求
比如ElectricTruckBuilder
Builder也可以有类体系:
AutoBuilder表示所有车辆通用的建造者, 用于组装车辆共有部分比如门
TruckBuilder表示卡车类建造者, 用于组装集装箱
ElectricTruckBuilder表示电卡车, 在卡车基础上组装电动力
只有具体的建造者类才能实例化, 任何父类都含有抽象方法, 有抽象函数未实现的类实例化无法通过编译.
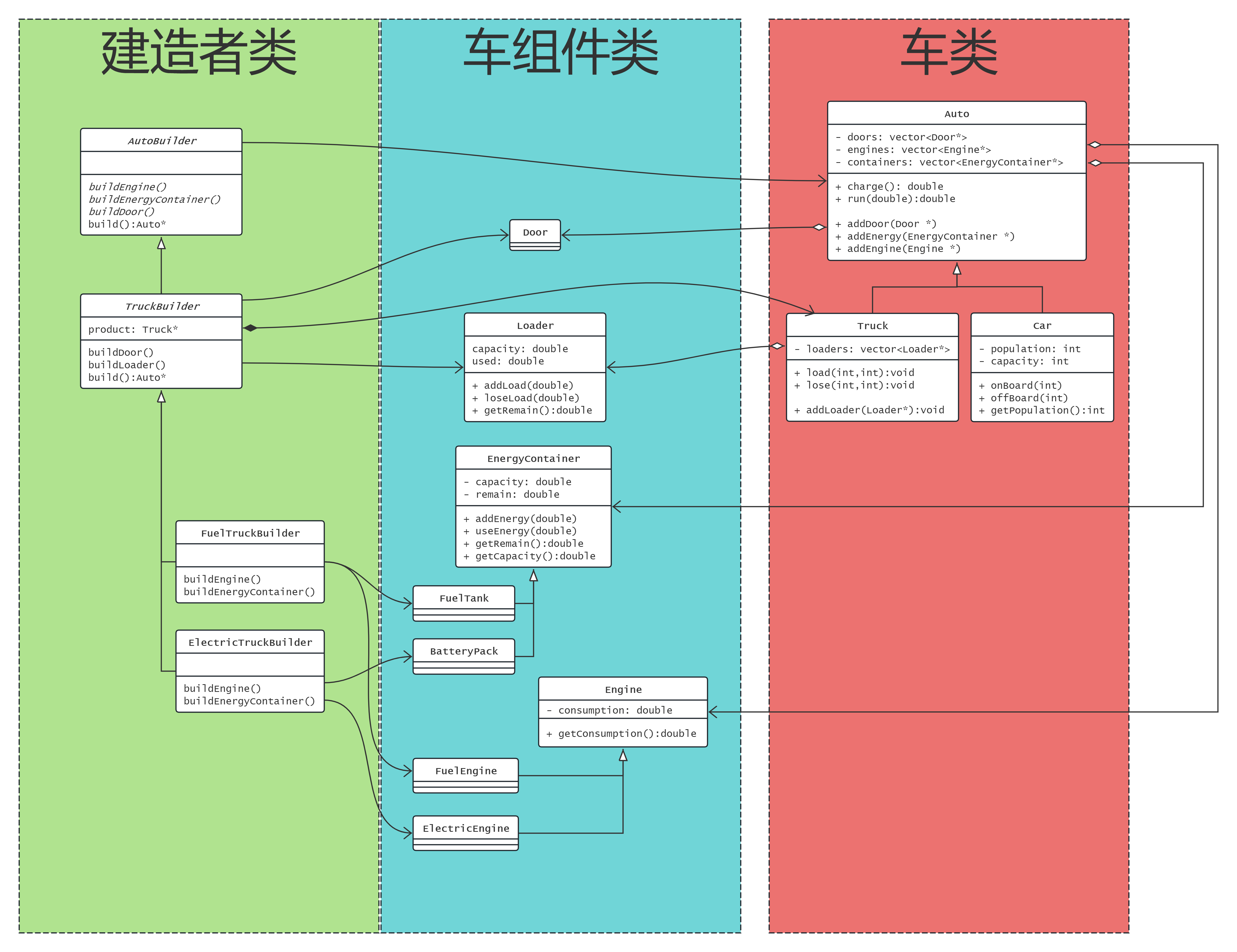
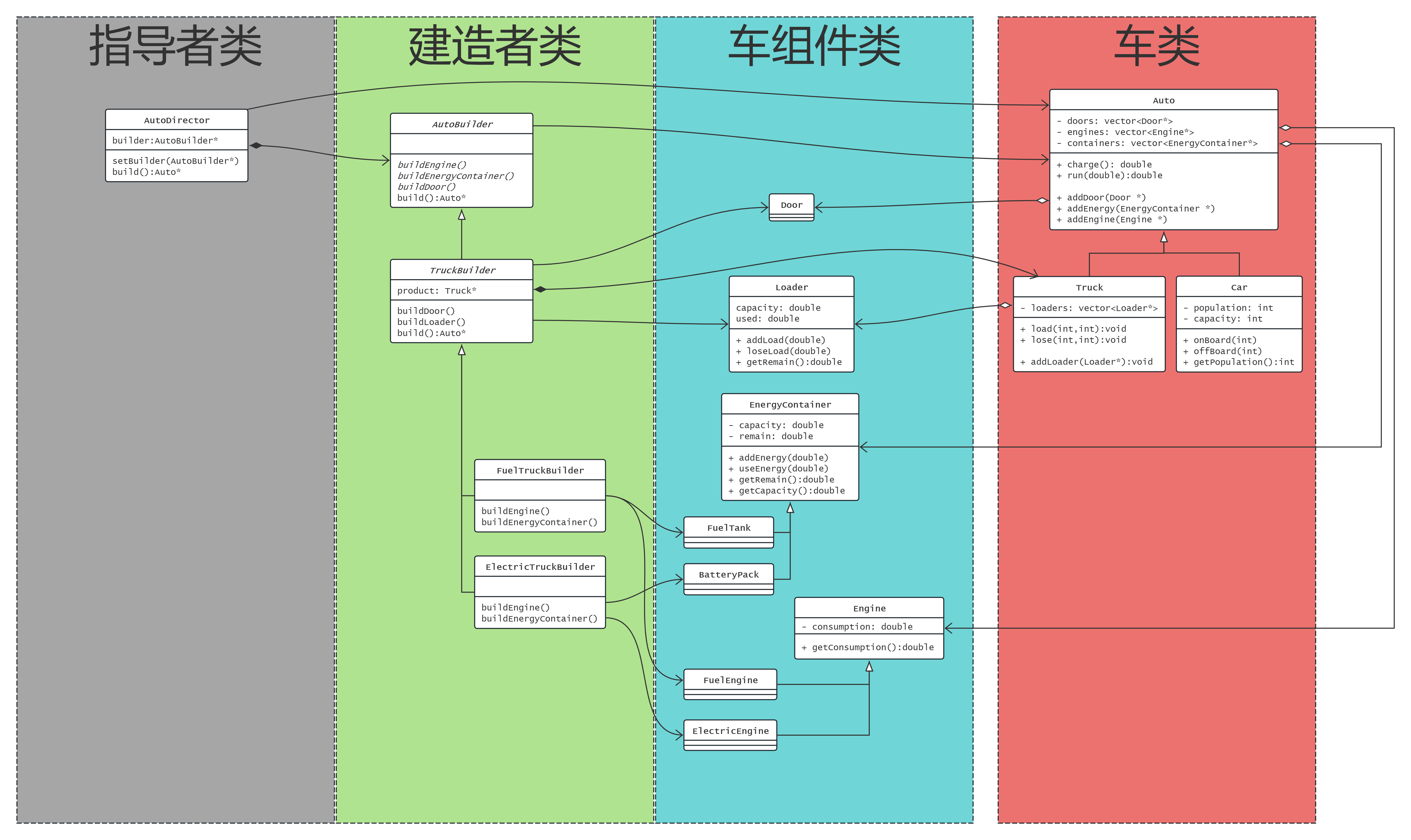
所有建造者应该由一个指导者管理, 决定到底采用哪个构造者,
用户只需要跟指导者说自己想要什么样的车, 指导者去找对应的建造者
原型模式
通过一份原型,克隆出多个副本
比如简历,可以打印一份,复印多份
就是继承一个Cloneable接口,实现一个clone函数
根据需要实现深拷贝和浅拷贝
结构型模式
关注对象之间的组合和关系, 构建灵活且可复用的类和对象结构
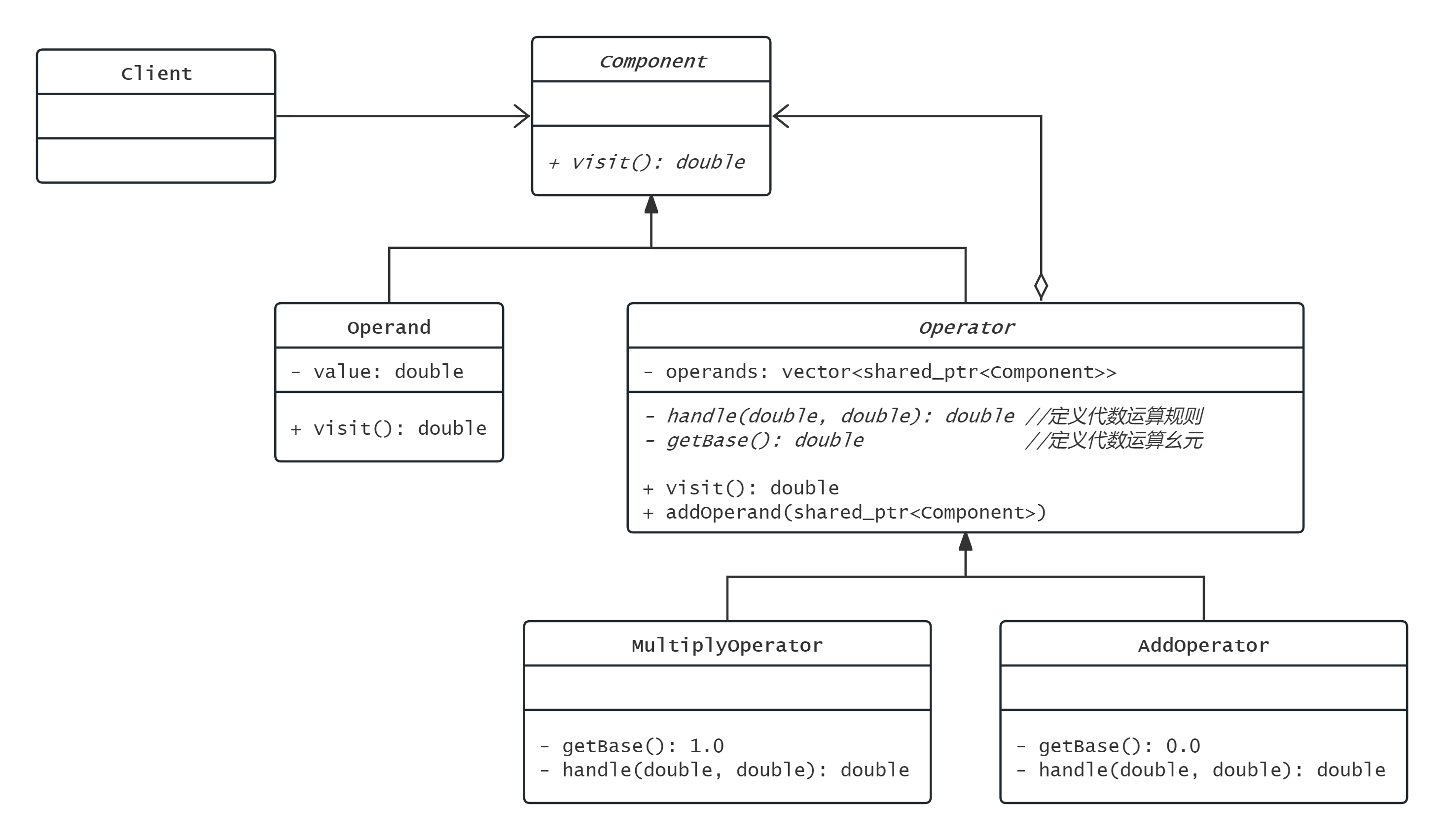
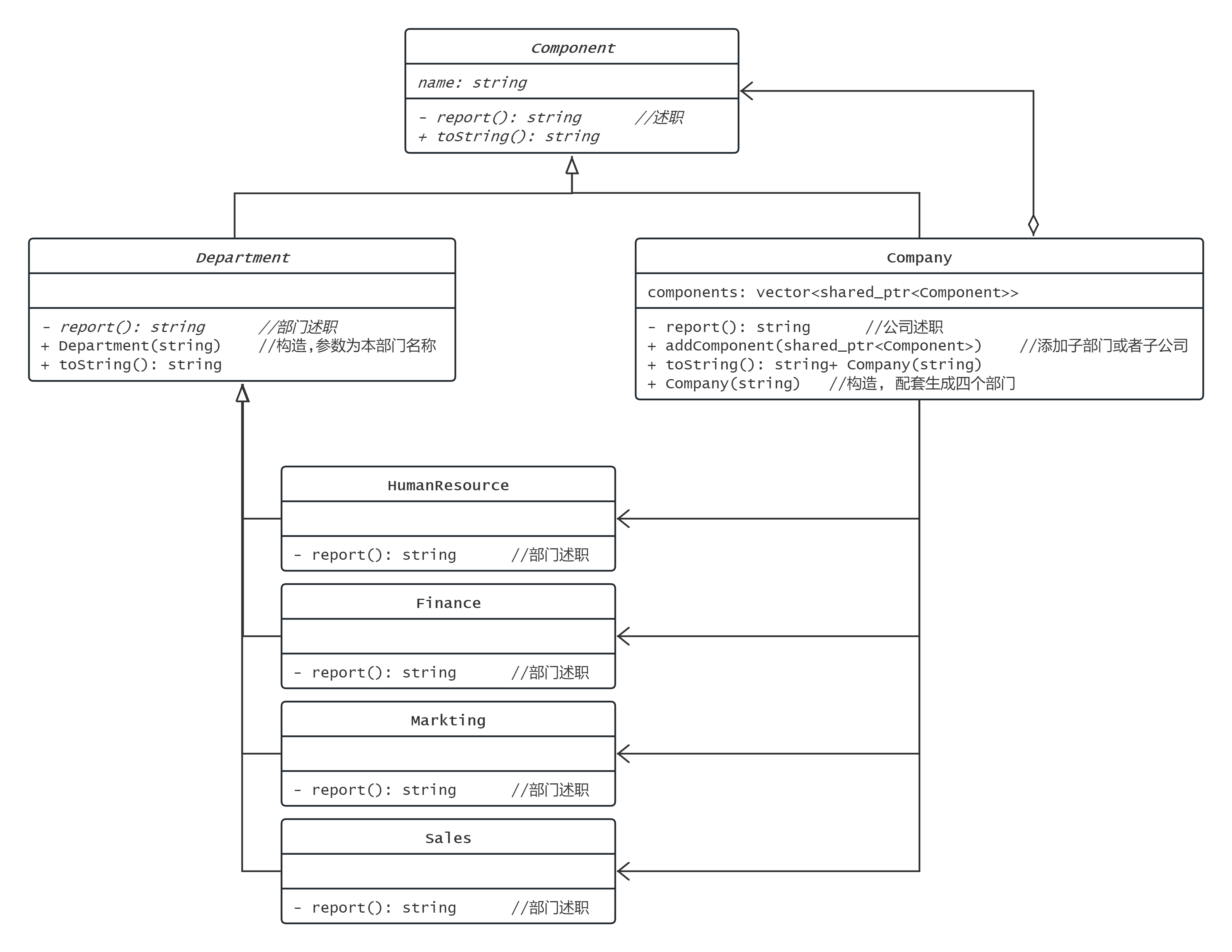
组合模式
用树形结构管理系统
用户对父节点的操作和对子节点的操作具有一致性
以语法分析树为例, 各个节点均实现visit接口
Operand就是叶子类
Operator就是内部节点类
这样将内部节点和叶子节点分类讨论, 是安全模式
如果将叶子节点也归为内部节点, 不再分类讨论, 则变成了透明模式, 此时实际上的叶子节点的handle和getBase等函数没有意义
问题场景:
描述如下公司结构
总部有自己的人力和财务, 总部还管理多个分公司
分公司也有自己的人力和财务,分公司管理多个办事处
办事处也有自己的人力和财务
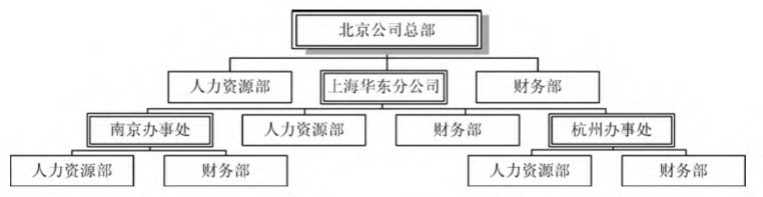
透明模式
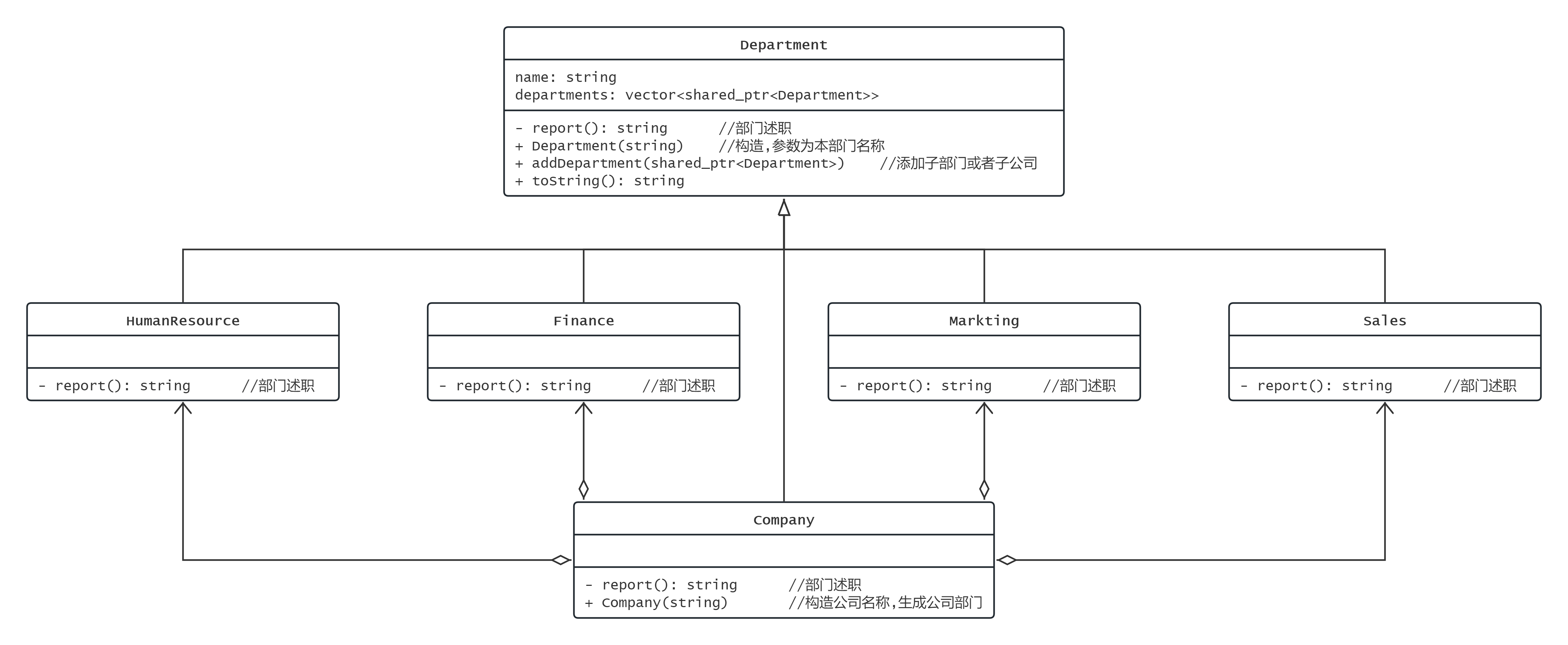
这样实现的不足之处是, 人力, 财政等部门, 没有子部门或者子公司,
departments成员和addDepartment方法不应该被继承. 违反了里氏替换原则
安全模式
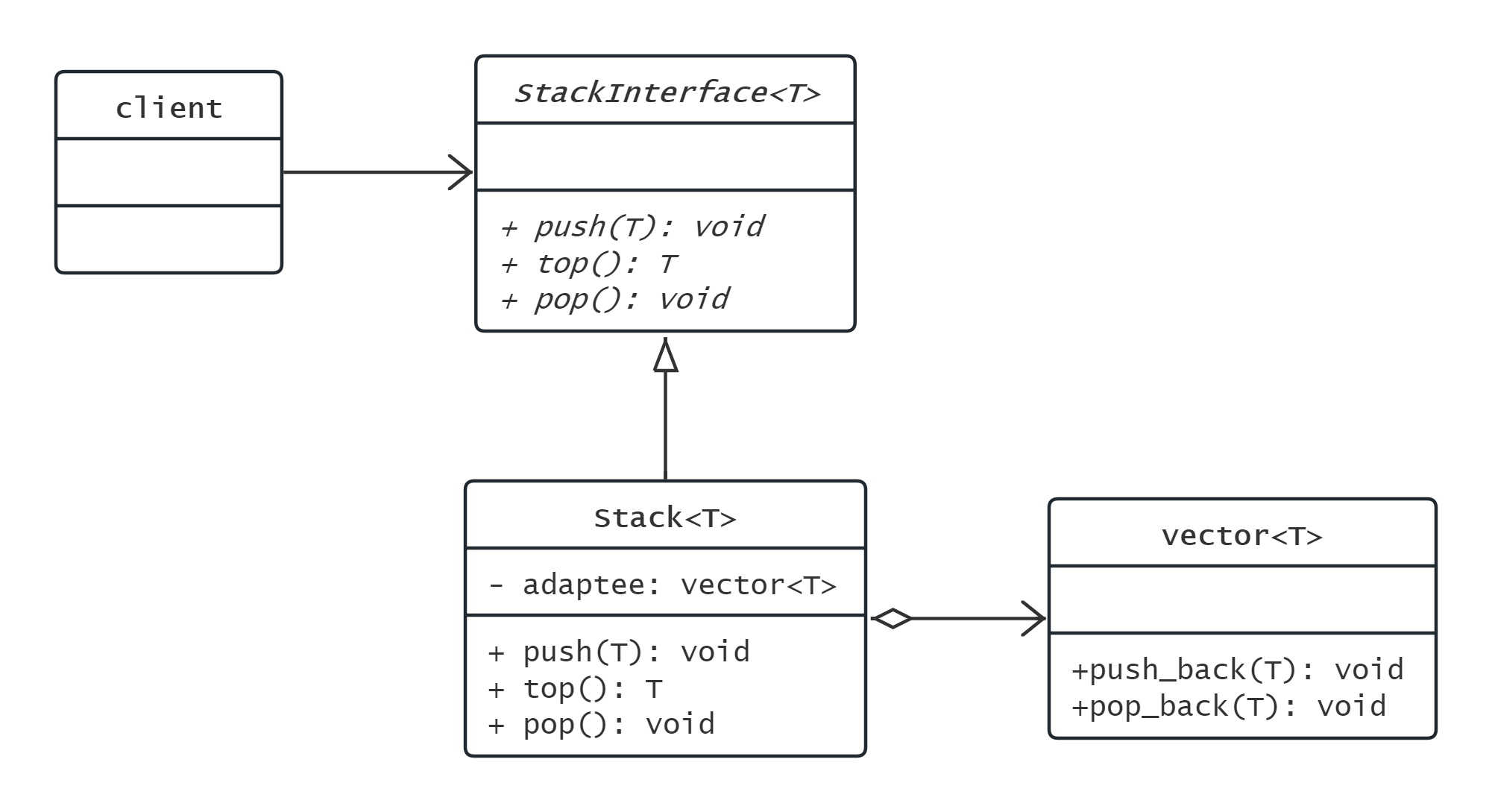
适配器模式
将一个类的接口按需求转换为另一个类的接口
电源适配器:不管入户电压多少伏都转换为需要的电压比如36v
deque改成queue
vector改成stack
用户需求的接口以Target接口给出
Adapter类实现Target接口
Adapter类内部封装一个Adaptee类
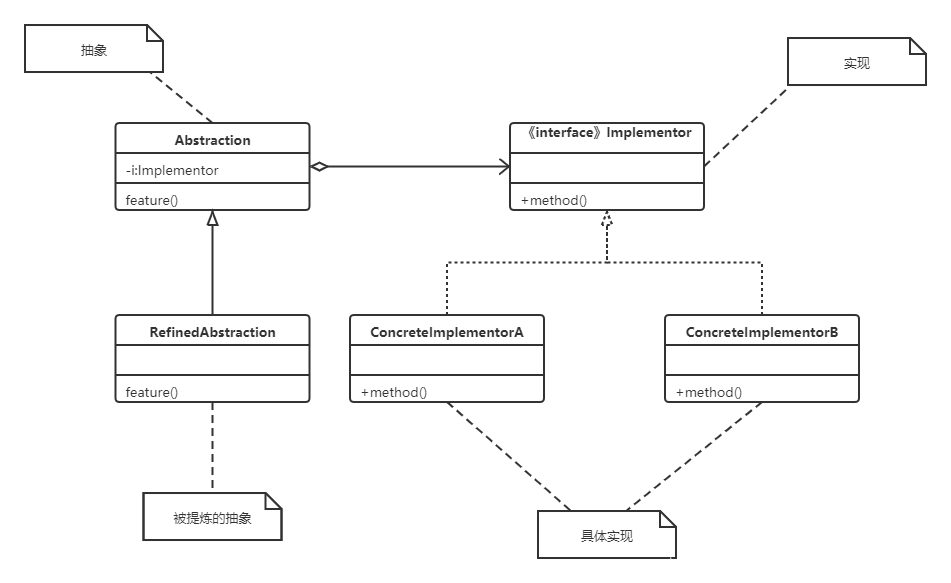
✨桥接模式
本节最初描述了这么一件事情:
1.不同品牌的手机
2.每种手机都有mp3,游戏,通讯录等等功能
最初的设计方式是纯使用继承实现
有两种继承设计方案, 一个是品牌在高层,一个是功能在高层
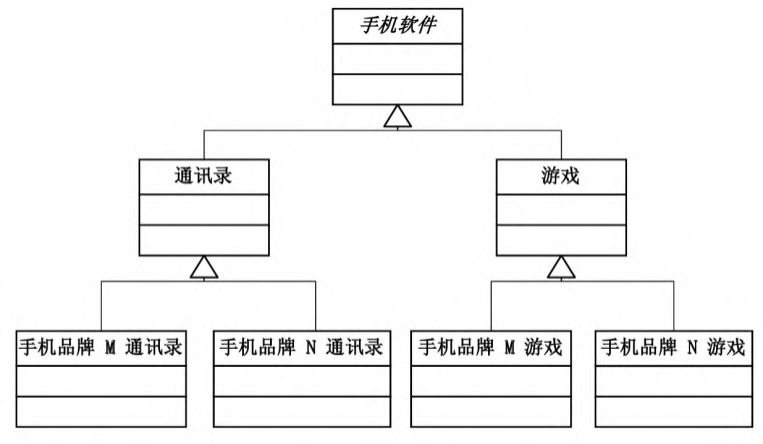
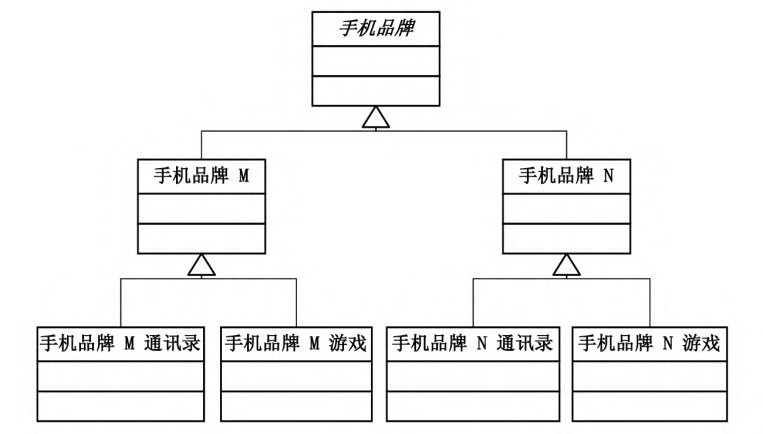
但是这样设计就会面临一个问题:
当有新品牌手机出现, 或者新手机功能出现时, 会导致类的数量急剧膨胀
书上是这样说的:
“是呀,就像我刚开始学会用面向对象的继承时,感觉它既新颖又功能强大,所以只要可以用,就都用上继承。这就好比是‘有了新锤子,所有的东西看上去都成了钉子。”
这说的太对了。
然而仔细考虑这种继承关系的缺点:
编译时就确定了子类和父类的继承关系,导致子类和父类必然有紧密的依赖关系,父类的改动必然导致子类的改动。
因此设计模式中的另一条设计原则:合成/聚合复用原则
仔细考虑还违反了单一职责原则,通过继承增加的新功能,就是在增加类的职责。
因此这个情景应该用聚合解决
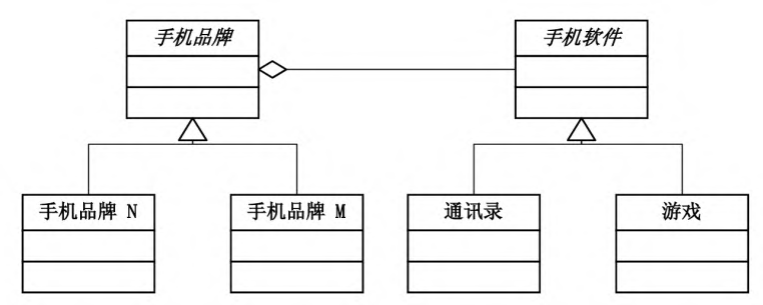
手机是主体, 不管什么品牌, 都可以安装不同的软件, 软件可以视为主体上的空槽,可以任意安装
考虑四门电动卡车问题时,实际上也是这个情况
按照能源继承后按照用途继承或者按照用途继承后按照能源继承,都是滥用继承设计
应该将车看成主体,将动力系统,运载系统等等看成槽位。空槽可以自定义添加模块.
这里Auto表示汽车类, Car和Truck表示汽车品牌
将Door,Engine,Container等等视为汽车的配件槽
实现系统可能有多角度分类,每一种分
类都有可能变化,那么就把这种多角度分离出来让它们独立变化,
减少它们之间的耦合
装饰模式 - 咖啡点单
考虑如下场景:
形象设计, 人有多种衣服可以穿, 可以只穿一条裤衩子, 也可以穿地全副武装, 也可以裤衩子外穿装超人.
最初我的设计是这样的:
1 | class Wear{}; |
然而这样设计的问题是:
1.人不一定只穿一件上衣, 可能穿了秋衣然后又穿了外套, 甚至可以不穿上衣
2.没法体现穿衣服的先后顺序
3.假设现在有一种新的装饰, 戒指Ring类, 那么Avator类无法表示
也就是说, 我们不能预估人会穿多少装饰物, 可能一件不穿, 可能穿的雍容华贵
我们不能站在人自己的角度来聚合装扮
应该站在装扮的角度往一个木偶身上套娃
1 | (木偶) |
对于每个装饰物来说, 他只需要知道目前套娃什么样, 然后自己套上去, 成为新的套娃
类似的思想也可以用于咖啡点单
1 | (美式) |
那么这种模式应该如何表示呢
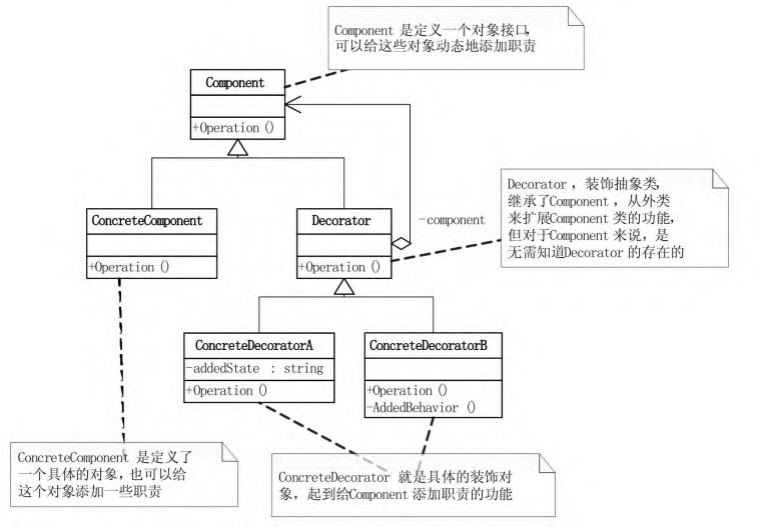
这里ConcreteComponent就是最初的美式, 也就是套娃的核
然后加糖加冰加牛奶都是Decorator的子类, 每个表示一层套娃
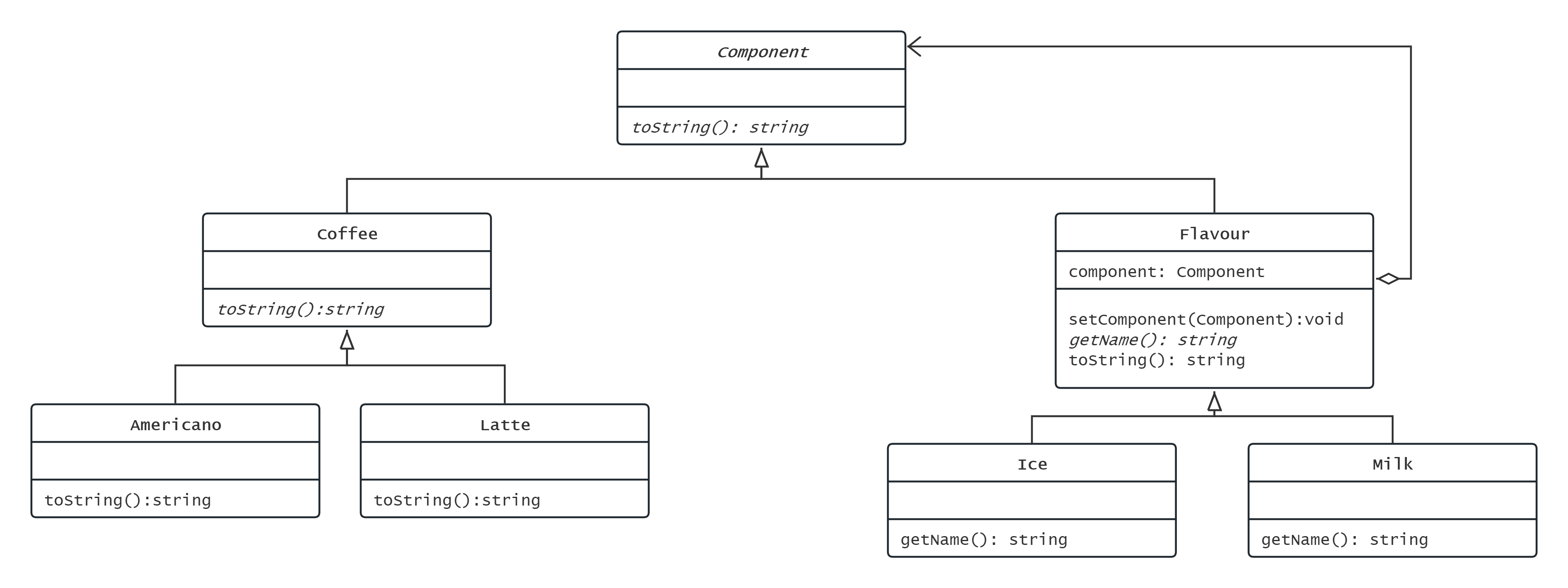
此后如果有新的咖啡,比如卡布奇诺,继承Coffee兵实现toString即可
如果有新的口味,比如椰果,继承Flavour并实现getName即可
外观模式
子系统对外不可见, 由外观类Facade对外提供接口提供访问, 客户不需要关心子系统细节
Facade相当于一个高级代理
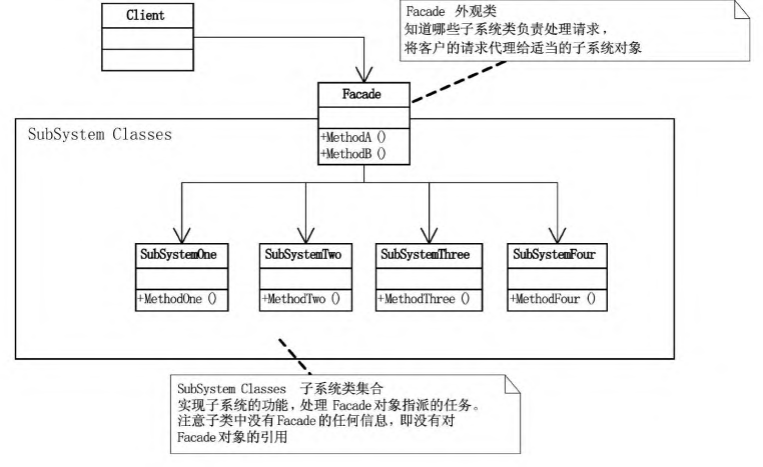
外观模式和代理模式的区别:
代理类只对一个实际对象进行代理, 更加专一
但是外观类中管理了很多子系统, 并提供不同方法组合对一个或多个子系统的调用
外观模式可以用在基金和股票场景中
客户是白痴理财人
股票是子系统
基金是外观类
基金经理会挑选几只股票押宝, 不再一棵树上吊死. 对应到外观类可以组合子系统的调用
客户只需要和基金经理打交道, 买入或者卖出. 对应到客户类只需要访问外观类提供的接口
享元模式
享元模式,FlyWeight,实际上是轻量级的意思
1 |
|
实际上编译器在rodata段只会生成一个“helloworld”字符串,而不是两个
a和b指针实际上指向相同的内存地址
类似的场景有写时复制:
写时复制(Copy-on-write,简称COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
享元模式实际上是工厂模式的改进, 工厂会记忆用户的需求
如果相同的需求之前已经满足过了, 那么直接返回之前构建的对象
如果是新需求则创建新对象
代理模式
书上举得这个例子实在不怎么样,别天天折磨人家女娃了,纯人机
意思就是给RealSubject类裹了一层Proxy代理类,代理类实现相同的Request接口
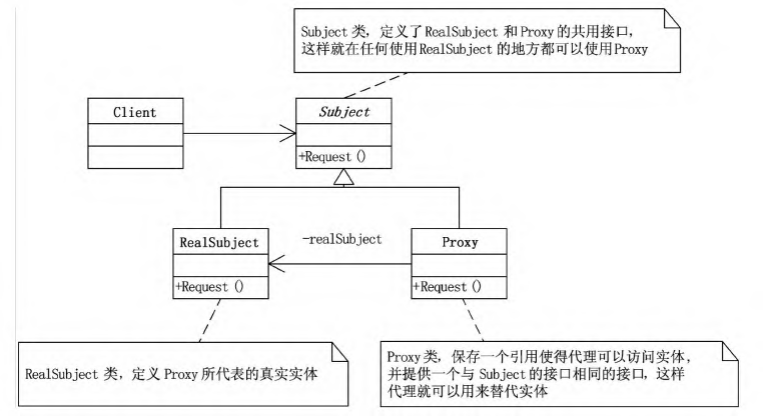
这个代理类在执行Request动作前后可以自己增加pre和post操作
行为型模式
关注对象之间的通信与交互,解决对象之间的责任分配与算法封装
模板方法模式
不变的部分搬到父类
去除子类中的重复代码
1 | class Flavour :public Component{ //Decorator |
这里getName就是模板方法
观察者模式
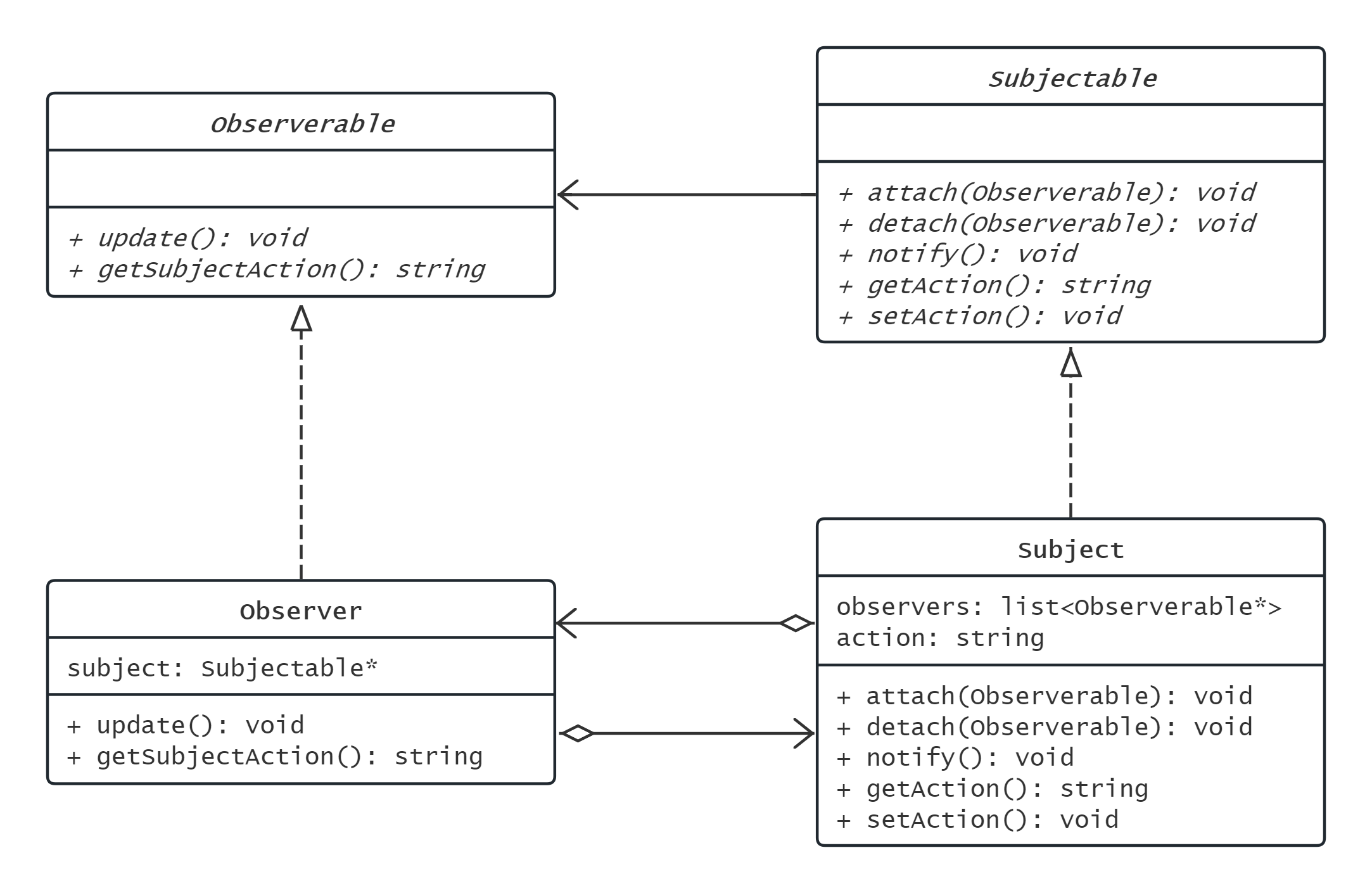
发布者-订阅者模式
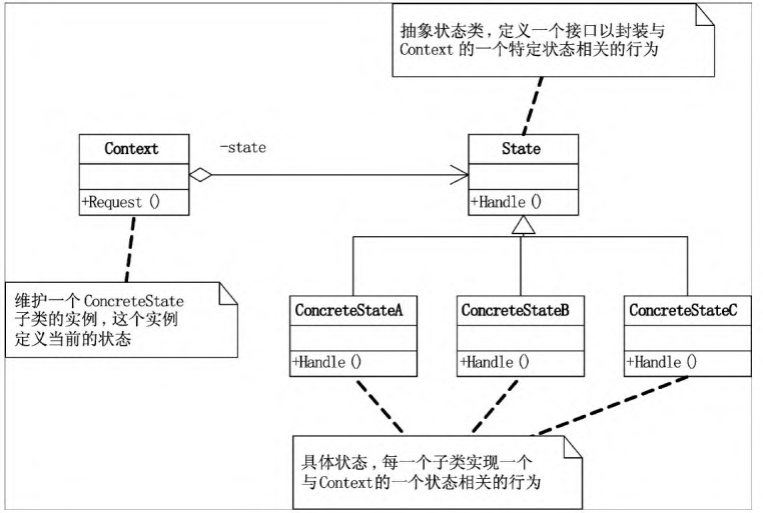
状态模式
控制一个对象状态转移的表达式过于复杂时(如果简单就不需要用状态模式)
将状态判断的if-else逻辑, 转移到表示不同状态的一系列类中表示
备忘录模式
迭代器模式
命令模式
命令模式将一个请求封装为一个对象, 对象数组就能模拟请求队列, 可以实现延迟请求, 请求排队
同时, 将请求对象化, 方便了记录请求日志, 对象记录请求内容, 也就支持了撤销操作
Receiver: 实际执行命令的对象
Command: 命令类型父类, Command可以有不同子类定义实际的命令类型
Invoker: 使用Command的入口, 也就是封装命令的对象
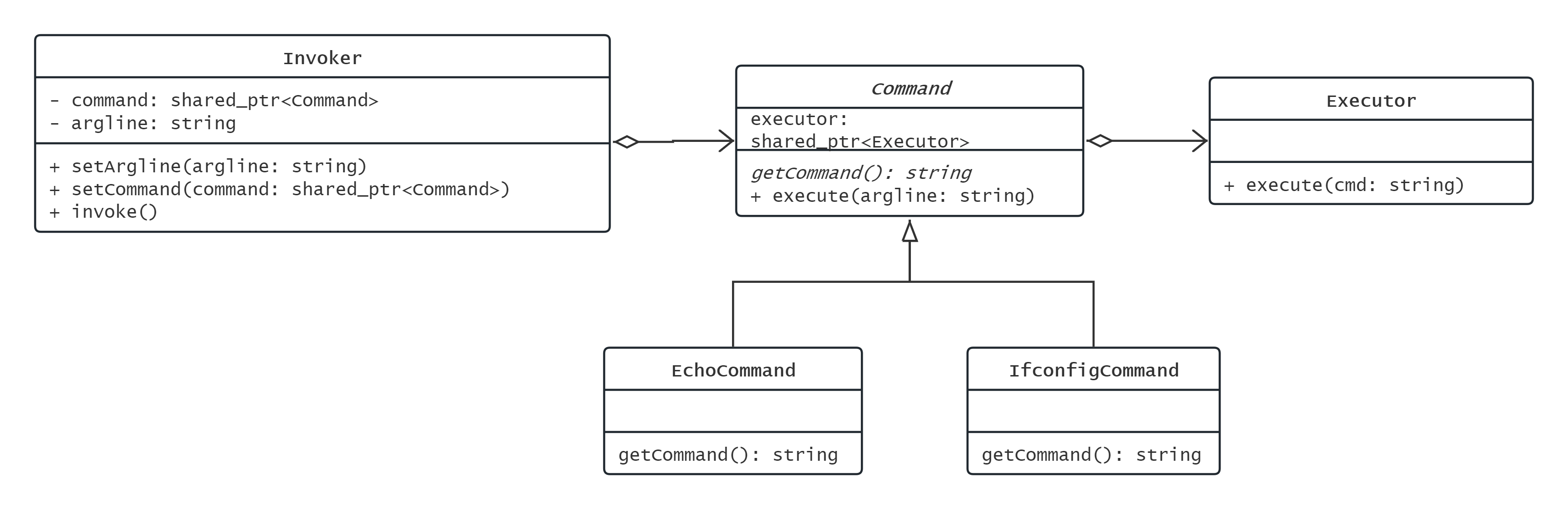
如图所示, 这是一个shell命令执行器.
其中Executor就是实际命令执行器, 也就是Receiver, 其execute参数接受一个shell命令字符串, 并调用system函数执行之
Command是命令类型基类, 其getCommand类型汇报自己对应的shell命令, 其execute负责拼接shell命令与参数 ,并交由Executor执行. Command类中持有一个Executor的引用executor
Invoker是封装的一次命令执行, 在Invoker中设置好参数与对应命令类, 即可在任意时刻调用invoke执行命令
invoke和call的区别:
两者都用于表示“调用”
call通常指直接的函数调用, 直接使用函数名调用
invoke通常指动态上下文中,使用反射/委托/回调等场景
职责链模式
过滤器和拦截器均采用职责链模式
以过滤器为例, 过滤器通常应用于用户权限检查/防止乱码/设置响应编码等场景
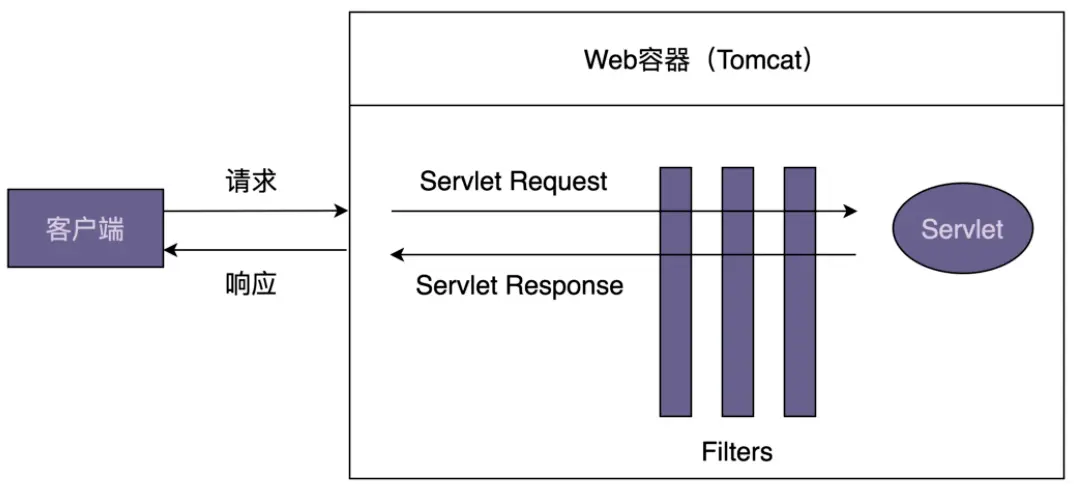
在javaweb编程中注册一个过滤器非常方便:
1.实现过滤器类
2.在web.xml中注册过滤器映射
1 | <filter> |
完美符合开放-封闭原则
看一下时序图, 可以发现各个Filter是递归调用的, 而不是平行地遍历了一遍
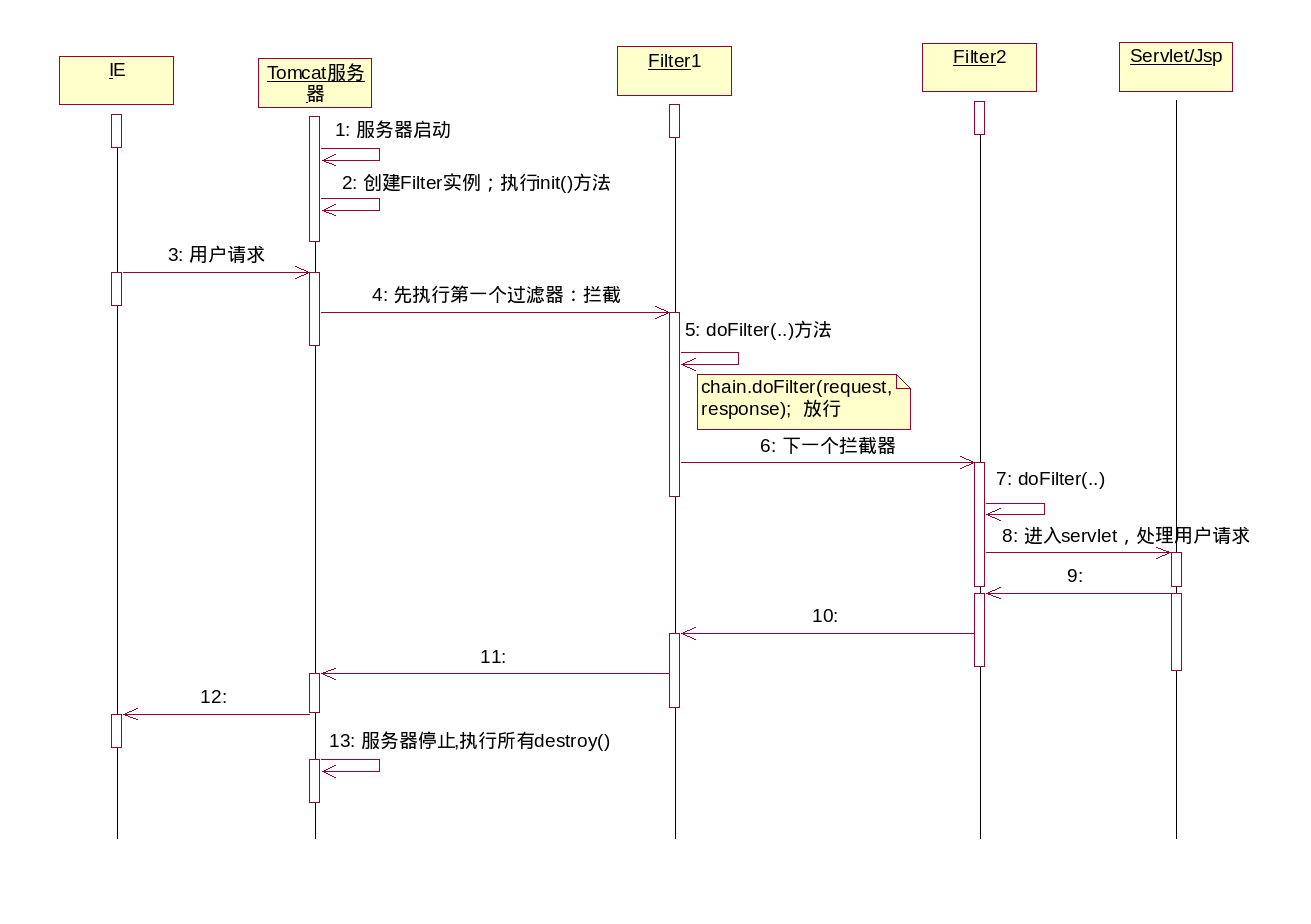
1 |
|
UML类图表示为:
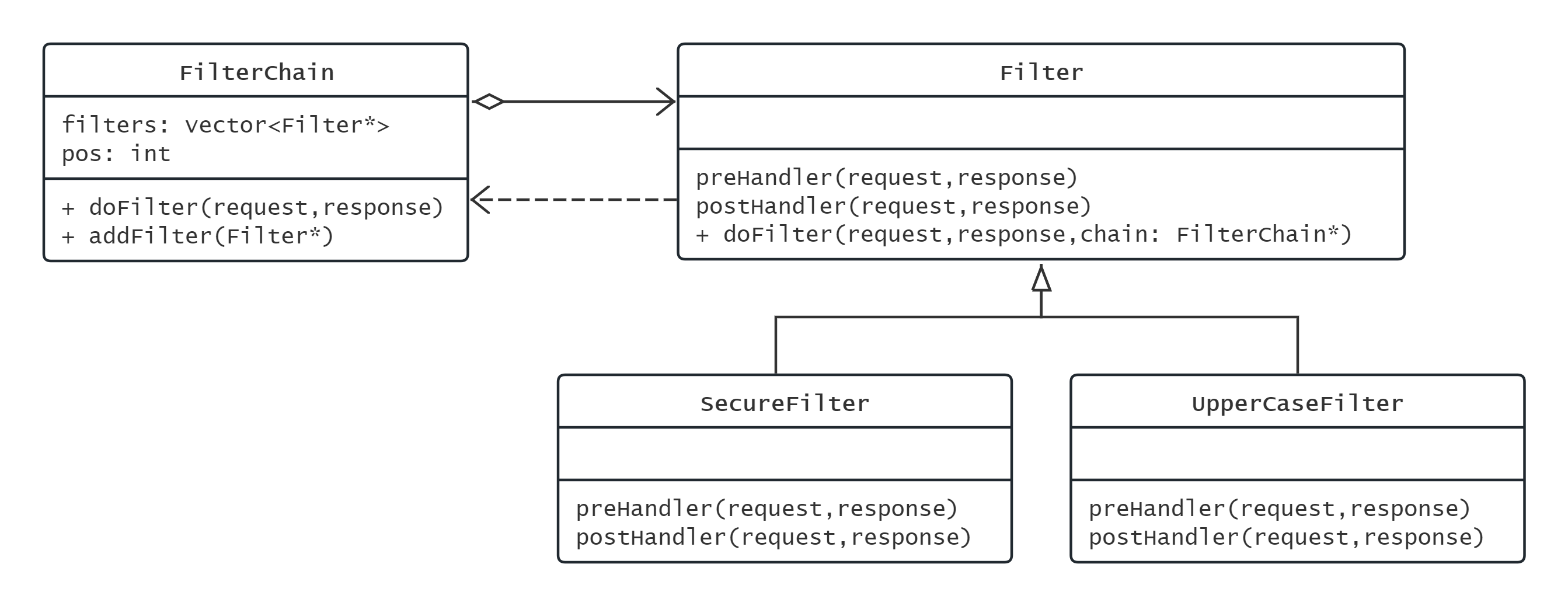
职责链模式有一个链管理器, 也就是FilterChain, 其中可以有多个职责类, 理想状态下每个指责类只负责一种职责, 比如字符过滤器只负责过滤输入中的危险字符, 大写过滤器只负责将输出中所有小写字符转化成大写
各个职责可以采用递归嵌套, 也可以平行遍历.
但是在Filter这里由于有pre和post两个处理函数, 只能采取递归
中介者模式
中介者模式通过引入中介者类,将原本模块之间互相调用的关系, 转化为经过中介者沟通的模式, 实现了模块间解耦
房地产交流平台是“房地产中介公司”提供给“卖方客户”与“买方客户”进行信息交流的平台,比较适合用中介者模式来实现。
聊天室中server作为中介者
实际上是星状结构
解释器模式
再别多说, 给定一个语言, 定义其语法表示, 并定义解释器, 用解释器来解释该语言中的句子
访问者模式
以Antlr4的实现为例, 学习其访问者模式的实现
访问者模式的作用时机
编译器前端由词法分析器lexer和语法分析器parser组成, 前端的作用时, 输入一段目标语言的源代码, 输出语法树
1 | source code ====> front end ====> grammer tree |
编译器后端就是语义分析, 在antlr4中语义分析可以采用访问者模式 或者 监听者模式实现. 后端的作用是, 输入一个语法树, 进行语义分析, 也就是解释
1 | grammer tree ====> back end ====> semantic analyze |
其中visitor就在编译器后端====>语义结果这一步发挥作用
语法树节点结构
那么visitor的参数就是语法树的root节点
所有语法树节点的接口:
1 | public interface ParseTree extends SyntaxTree { |
所有语法节点类的抽象父类:
1 |
|
具体的语法节点类由.g4规则文件给出, 这个g4文件就是人工撰写的词法语法规则文件, 比如:
1 | program : ( statement SEMICO )* EOF ; |
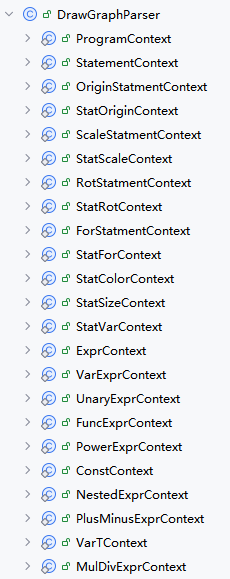
antlr4会在处理g4文件时, 将program语法对应建立一个ProgramContext语法树节点类
同样statement语法也会建立一个StatementContext语法树节点类
语法树节点的accept接口
在ParseTree接口中规定, 为了能够使用visitor模式, 需要每个语法树节点实现accept接口
1 | <T> T accept(ParseTreeVisitor<? extends T> var1); |
比如ProgramContext节点类是这样实现的:
1 | public static class ProgramContext extends ParserRuleContext { |
也就是直接调用了DrawGraphVisitor.visitProgram()
又比如StatScaleContext节点类这样实现:
1 | public static class StatScaleContext extends ScaleStatmentContext { |
也就是直接调用了DrawGraphVisitor.visitStatScale()
整个过程是这样的:
访问者: 节点, 我能访问你吗? 我应该怎么访问你呢?
StateScaleContext节点: 同意访问, 你得去用你的visitStatScale方法来访问我.
为什么访问者不能直接调用自己的visitStatScale方法, 而是先调用节点的accept方法呢?
这是因为, 当访问者来到当前节点家门口时, 访问者并不知道当前节点是个什么具体类型的节点, 访问者只知道节点的多态基类.
因此访问者不知道应该对当前节点进行什么操作, 因此节点需要在自己的accept函数中, 告知访问者访问协议, 也就是由节点指引访问者访问当前节点的方法
那么接下来的问题是, visitProgram这种具体的访问协议是如何实现的?
| 类型 | 类名 | 职责 | 位置 |
|---|---|---|---|
| 接口 | ParseTreeVisitor | 声明visit接口, visitChildren接口等 | jar库 |
| 抽象类 | AbstractParseTreeVisitor | 实现visit接口, visitChildren接口等 | jar库 |
| 类 | DrawGraphBaseVisitor | 实现默认的visitStatScale等具体协议 | antlr4命令生成 |
| 类 | EvalVisitor | 自定义visitStatScale等具体协议 | 程序员撰写 |
DrawGraphBaseVisitor由antlr4自动生成, 其中定义了默认的访问协议方法
1 | public class DrawGraphBaseVisitor<T> extends AbstractParseTreeVisitor<T> implements DrawGraphVisitor<T> { |
可见默认的方法是直接访问子节点去, 走马观花
真正的访问协议需要程序员撰写, 继承DrawGraphBaseVisitor重写同名函数
1 | public class EvalVisitor extends DrawGraphBaseVisitor<Double> |
访问者控制流
下面跟随访问者的控制流, 看一下accept和visit是如何配合的
1 | //BackEnd入口: |
1 | //in class AbstractParseTreeVisitor |
1 | // in class ProgramContext |
1 | //in class DrawGraphBaseVisitor |
1 | //in class AbstractParseTreeVisitor |
到此程序控制流又进入了accept方法中, 只不过这次应该是StatementContext.accept方法
1 | //in class StatementContext |
…
也就是说在具体的访问协议, 比如visitStatement或者visitStatScale等等, 如果程序员有在EvalVisitor中重写, 则调用程序员自定义的
否则调用antlr4在DrawGraphBaseVisitor中生成的默认的
访问器模式总结
1.访问者类的visit接口, 用于与语法树节点类accept接口建立连接, 协商针对该节点的具体访问协议
2.访问者类要知道所有可能的语法树节点类型, 并实现所有具体的访问协议
3.语法树的节点类要实现accept接口, 用于与访问者的visit接口协商本节点的具体访问协议, 告知访问者本节点的具体类型
1 | visitor.visit(node) |
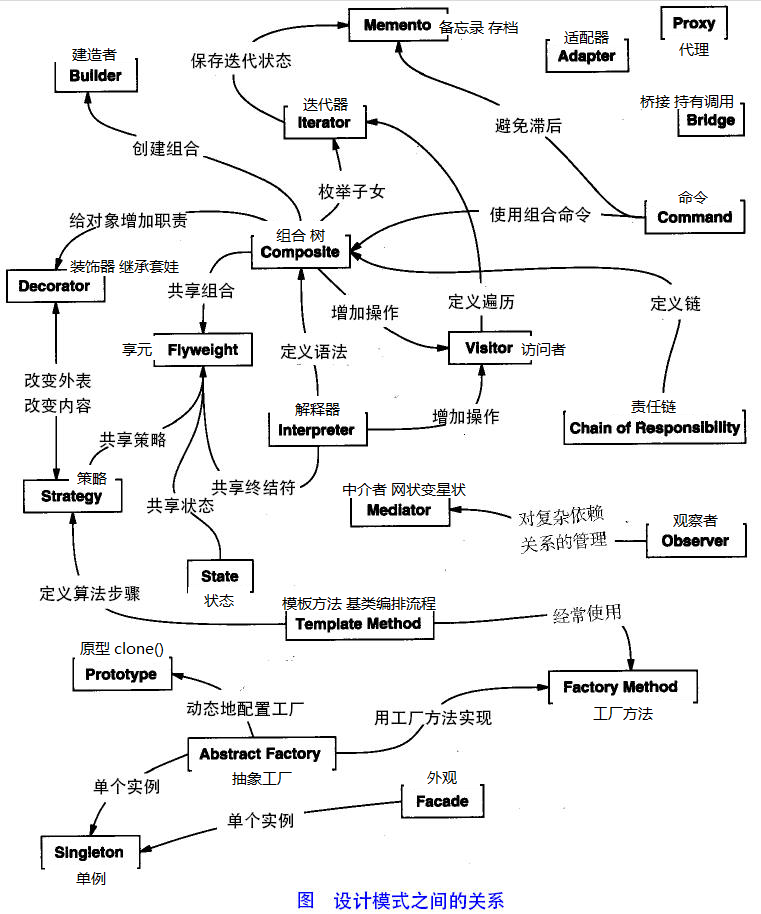
设计模式关系
图片来自菜鸟教程