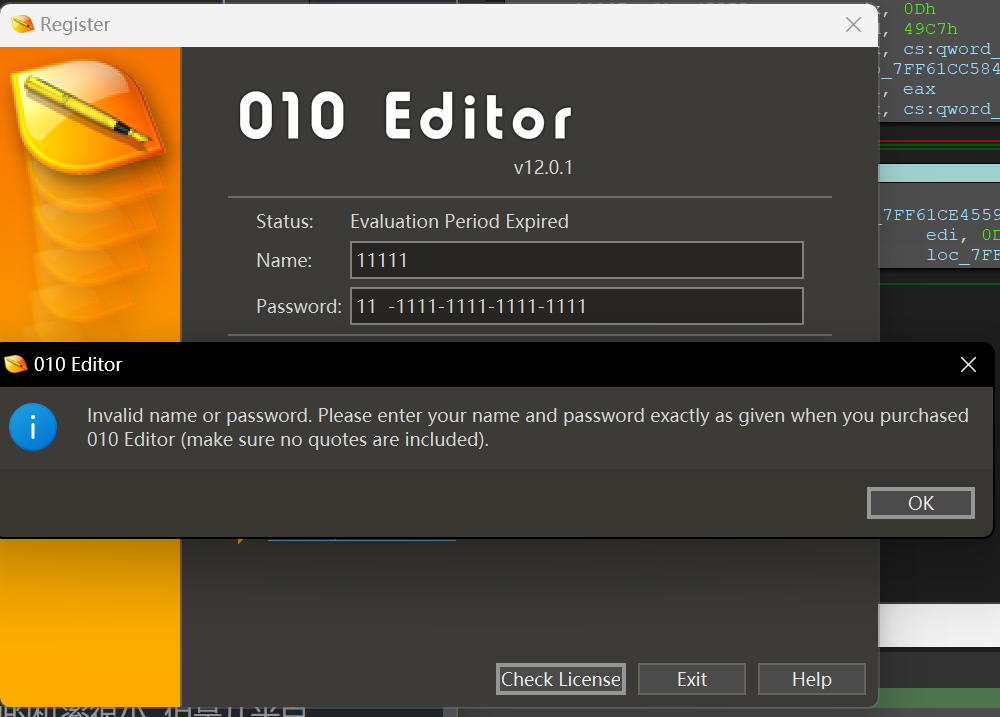
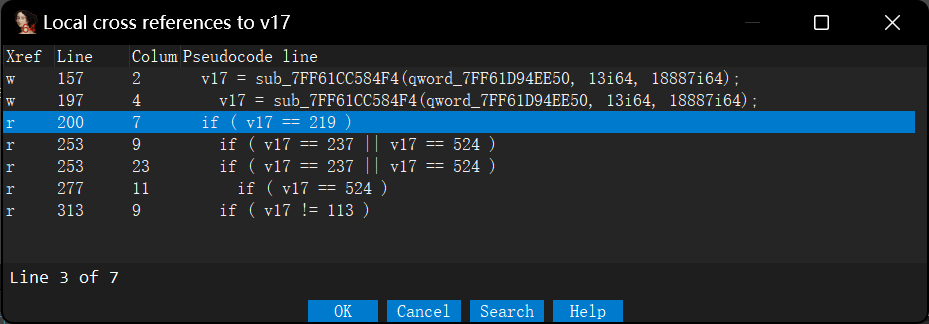
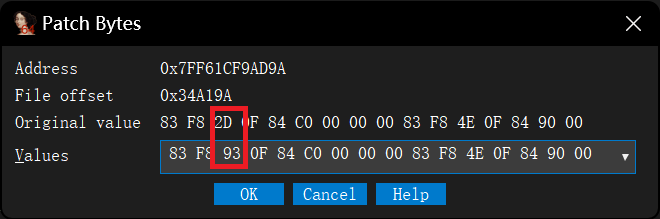
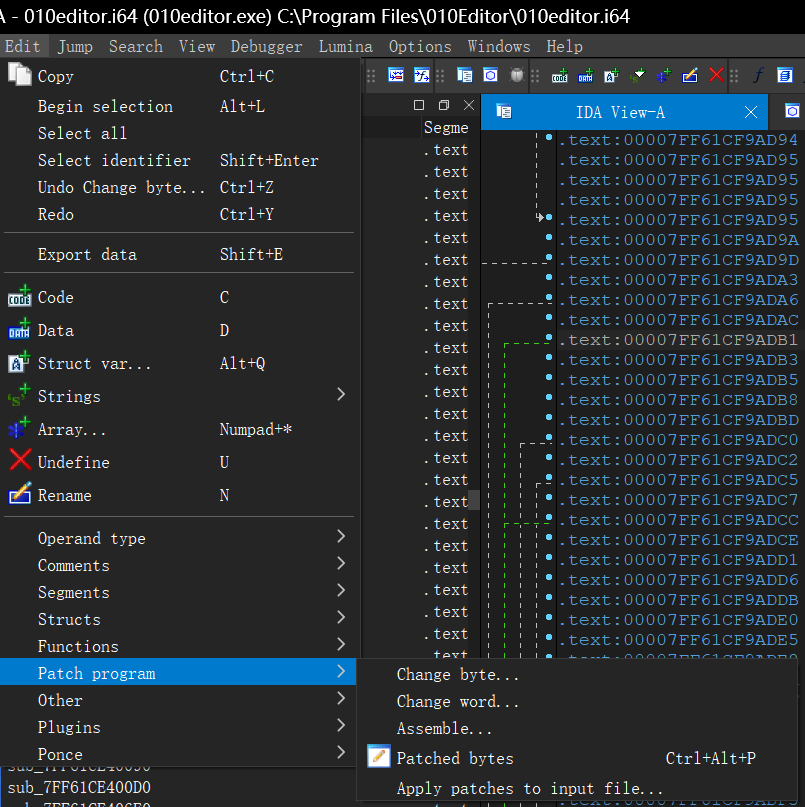
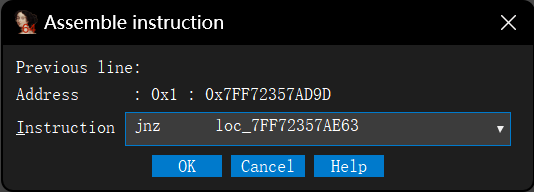
if ( v16 != 147 ) { v48 = QString::fromAscii_helper( "Invalid name or password. Please enter your name and password exactly as given when you purchased 010 Edit" "or (make sure no quotes are included).", 144i64); sub_7FF61CC55065(&v48); v25 = (char *)&v48; goto LABEL_68; } if ( v17 != 113 ) { v48 = QString::fromAscii_helper("Password accepted but the trial period is already over.", 55i64); sub_7FF61CC55065(&v48); v25 = (char *)&v48; goto LABEL_68; } v48 = QString::fromAscii_helper("Password accepted. Your trial period has been extended.", 55i64); sub_7FF61CC55065(&v48); v32 = &v48;
case IDM_FILE_PRINT://打印 if (!PopPrntPrintFile (hInst, hwnd, hwndEdit, szTitleName))//桩函数,尚未实现 OkMessage (hwnd, TEXT ("Could not print file %s"), szTitleName) ; return0 ;
IDM_APP_EXIT
1 2 3
case IDM_APP_EXIT://关闭窗口 SendMessage (hwnd, WM_CLOSE, 0, 0) ; return0 ;
case IDM_FORMAT_FONT://字体格式 if (PopFontChooseFont (hwnd)) PopFontSetFont (hwndEdit) ;//PopFontChooseFont和PopFontSetFont属于同一模块,模块内部会有通信 return0 ;
帮助&&关于
1 2 3 4 5 6 7 8
case IDM_HELP://帮助 OkMessage (hwnd, TEXT ("Help not yet implemented!"), TEXT ("\0")) ; return0 ; case IDM_APP_ABOUT: //关于 DialogBox (hInst, TEXT ("AboutBox"), hwnd, AboutDlgProc) ;//使用AboutDlgProc作为模态对话框的窗口过程 return0 ;
关闭
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
case WM_CLOSE://关闭窗口 if (!bNeedSave || IDCANCEL != AskAboutSave (hwnd, szTitleName))//不需要保存或者询问保存点选的否 DestroyWindow (hwnd) ;//销毁父窗口 return0 ; case WM_QUERYENDSESSION ://结束对话或者系统关闭时询问 if (!bNeedSave || IDCANCEL != AskAboutSave (hwnd, szTitleName)) return1 ; return0 ; case WM_DESTROY: PopFontDeinitialize () ;//清理逻辑字体 PostQuitMessage (0) ;//发送退出消息,结束消息循环 return0 ;
// Get file size in bytes and allocate memory for read. // Add an extra two bytes for zero termination. iFileLength = GetFileSize (hFile, NULL) ; //iFileLength获取文件总长度 pBuffer = malloc (iFileLength + 2) ;//pBuffer动态在内存上申请iFileLength+2的空间,意思是最后要放\0
// Read file and put terminating zeros at end. ReadFile (hFile, pBuffer, iFileLength, &dwBytesRead, NULL) ; //从hFile读取至多iFileLength个字节放到pBuffer中,实际读取了多少个放到dwBytesRead CloseHandle (hFile) ;//关闭文件句柄 pBuffer[iFileLength] = '\0' ;//pBuffer缓冲区以两个\0结尾 pBuffer[iFileLength + 1] = '\0' ;
// Open the file, creating it if necessary if (INVALID_HANDLE_VALUE == (hFile = CreateFile (pstrFileName, GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, 0, NULL))) return FALSE ;
// Get the number of characters in the edit control and allocate // memory for them. iLength = GetWindowTextLength (hwndEdit) ; pstrBuffer = (PTSTR) malloc ((iLength + 1) * sizeof (TCHAR)) ; if (!pstrBuffer) { CloseHandle (hFile) ; return FALSE ; }
// If the edit control will return Unicode text, write the // byte order mark to the file.
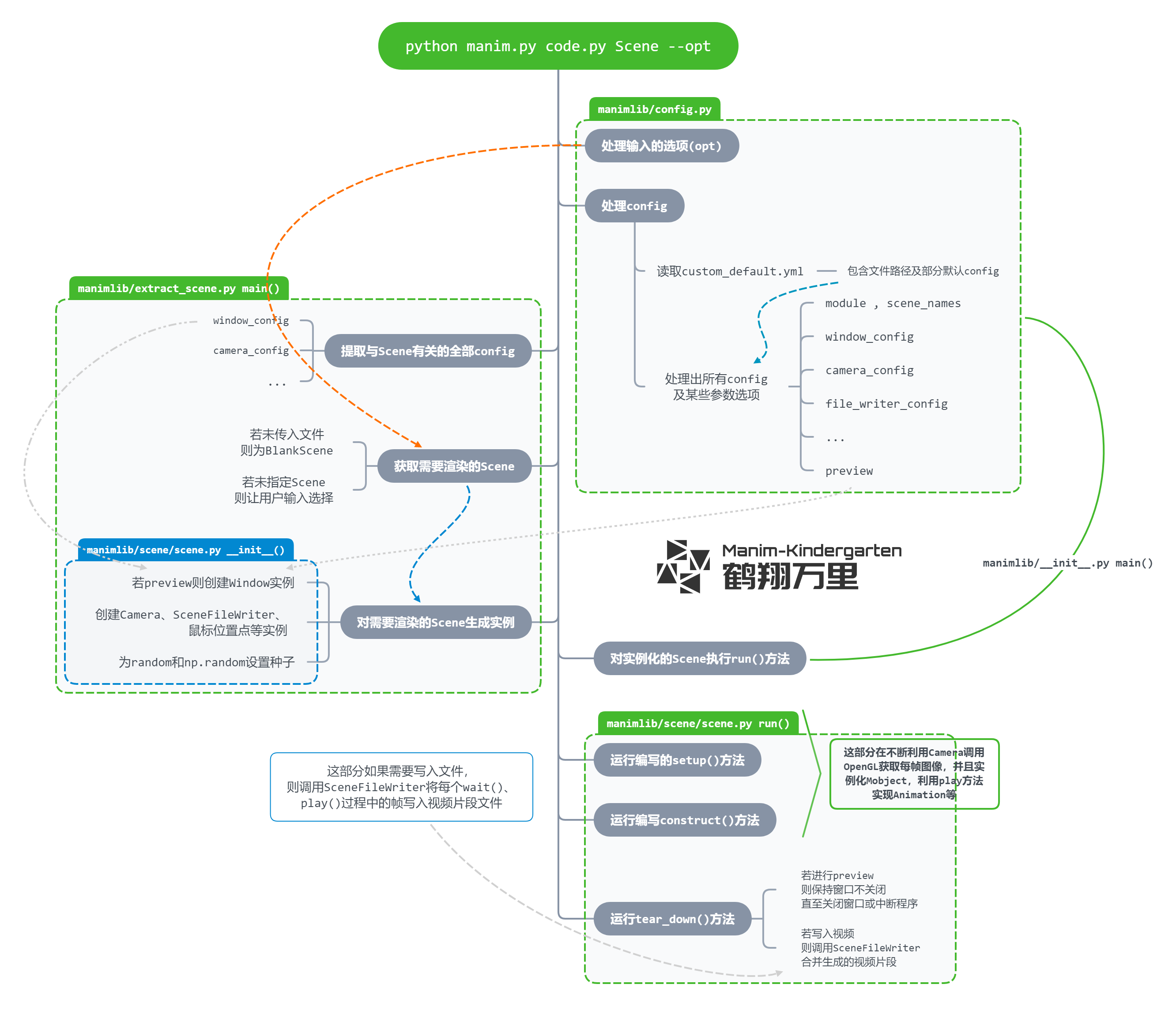
args = manimlib.config.parse_cli()#命令行语法分析 if args.version and args.file isNone:# return if args.log_level: manimlib.logger.log.setLevel(args.log_level)
if args.config: manimlib.utils.init_config.init_customization() else: config = manimlib.config.get_configuration(args) scenes = manimlib.extract_scene.main(config)
defparse_cli(): try: parser = argparse.ArgumentParser() module_location = parser.add_mutually_exclusive_group() module_location.add_argument( "file", nargs="?", help="Path to file holding the python code for the scene", ) parser.add_argument( "scene_names", nargs="*", help="Name of the Scene class you want to see", ) parser.add_argument... parser.add_argument( "--log-level", help="Level of messages to Display, can be DEBUG / INFO / WARNING / ERROR / CRITICAL" ) args = parser.parse_args() return args
defmain(config): module = config["module"] scene_config = get_scene_config(config) if module isNone: # If no module was passed in, just play the blank scene return [BlankScene(**scene_config)]
defsurround( self, mobject: Mobject, dim_to_match: int = 0, stretch: bool = False, buff: float = MED_SMALL_BUFF ): # Ignores dim_to_match and stretch; result will always be a circle # TODO: Perhaps create an ellipse class to handle singele-dimension stretching
graph LR A(ring3应用程序) B(ring0检查例程,依存) C(ring0磁盘读写例程,非依存) D(ring0内存读写例程,依存) subgraph ring 3 A--"jmp far,CPL=3"-->B D end subgraph ring 0 B--"1.call far,CPL=0"-->C C--"2.return,CPL=3"-->B B--"3.jmp far,CPL=3"--->D end
如果是系统函数调用该系统调用则全程在ring0,不需担心任何问题
1 2 3 4 5 6 7 8 9 10 11 12 13
graph LR A(ring0系统函数) B(ring0检查例程,依存) C(ring0磁盘读写例程,非依存) D(ring0内存读写例程,依存) subgraph ring 0 A--"jmp far,CPL=0"-->B B--"1.call far,CPL=0"-->C C--"2.return,CPL=0"-->B B--"3.jmp far,CPL=0"--->D end
message_1 db ' If you seen this message,that means we ' db 'are now in protect mode,and the system ' db 'core is loaded,and the video display ' db 'routine works perfectly.',0x0d,0x0a,0 ... mov ebx,message_1 call sys_routine_seg_sel:put_string
data_seg dd section.data.start ;数据段位置#0x1c data_len dd data_end ;数据段长度#0x20 ;------------------------------------------------------------------------------- ;符号地址检索表 salt_items dd (header_end-salt)/256 ;#0x24 salt: ;#0x28 PrintString db '@PrintString' times 256-($-PrintString) db 0 TerminateProgram db '@TerminateProgram' times 256-($-TerminateProgram) db 0 ReadDiskData db '@ReadDiskData' times 256-($-ReadDiskData) db 0 header_end:
mov ebx,eax and ebx,0xfffffffc add ebx,4 ;强制对齐 test eax,0x00000003 ;下次分配的起始地址最好是4字节对齐 cmovnz eax,ebx ;如果没有对齐,则强制对齐 mov [ram_alloc],eax ;下次从该地址分配内存,更新下一次分配地址 ;cmovcc指令可以避免控制转移 pop ebx pop eax pop ds
<bochs:6> creg CR0=0x60000010: pg CD NW ac wp ne ET ts em mp pe
此时的pe=0表明处理器工作在实模式
然后s单步执行之后creg观察CR0
1 2 3 4 5
<bochs:7> s Next at t=17179024 (0) [0x000000007c76] 0000:0000000000007c76 (unk. ctxt): jmpf 0x0008:0000007e ; 66ea7e0000000800 <bochs:8> creg CR0=0x60000011: pg CD NW ac wp ne ET ts em mp PE
flowchart A %%声明三个节点 B G click B "https://www.baidu.com/""linkage to baidu" %%给B节点上一个到百度的链接,点击跳转 click G "http://www.github.com""linkage to github" %%给G上一个到github的链接
1 2 3 4 5 6
flowchart A B G click B "https://www.baidu.com/" "linkage to baidu" click G "http://www.github.com" "linkage to github"
jmp near start;跳过数据区 mytext db 'L',0x07,'a',0x07,'b',0x07,'e',0x07,'l',0x07,' ',0x07,'o',0x07,\ 'f',0x07,'f',0x07,'s',0x07,'e',0x07,'t',0x07,':',0x07 number db 0,0,0,0,0