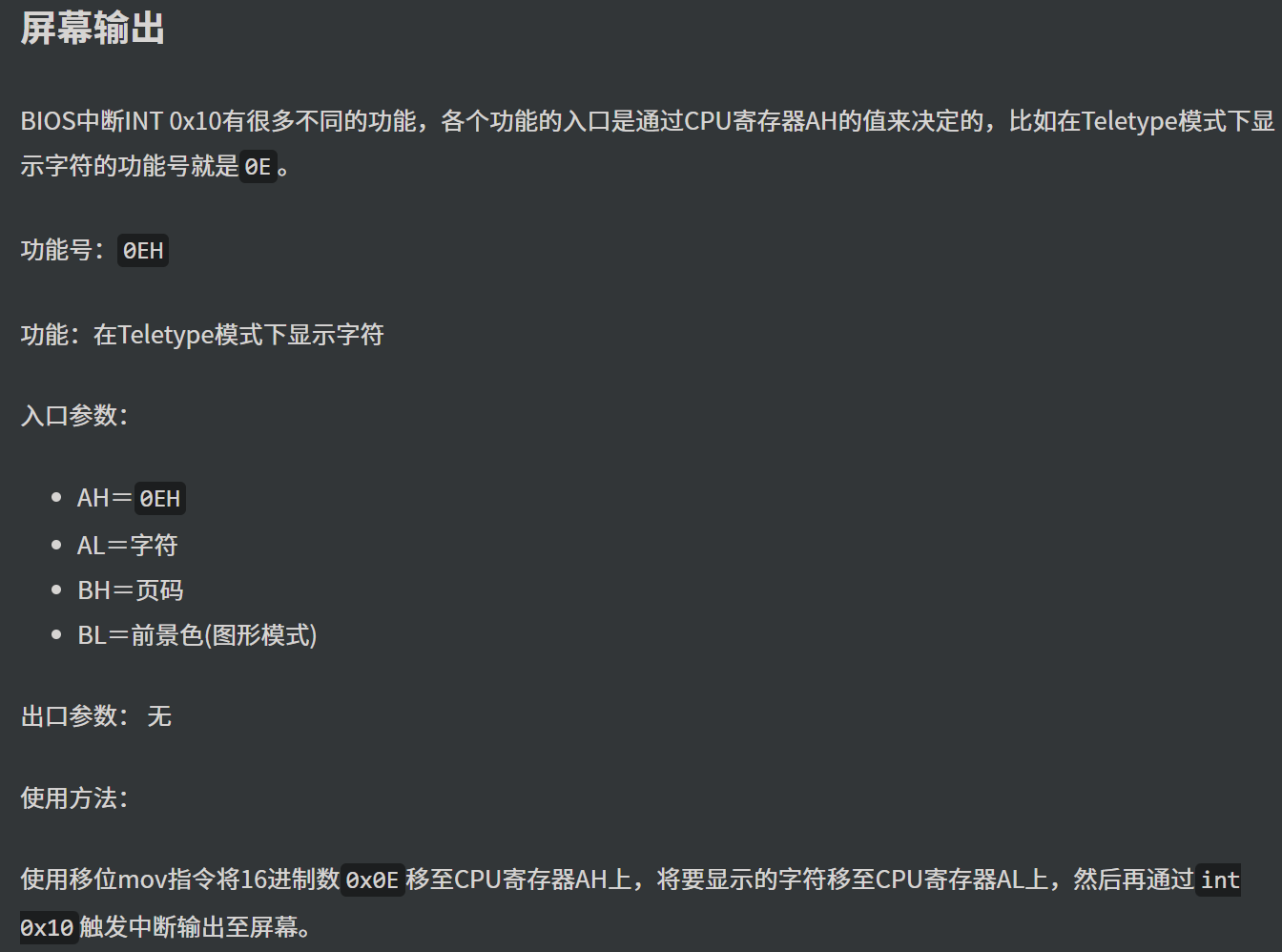
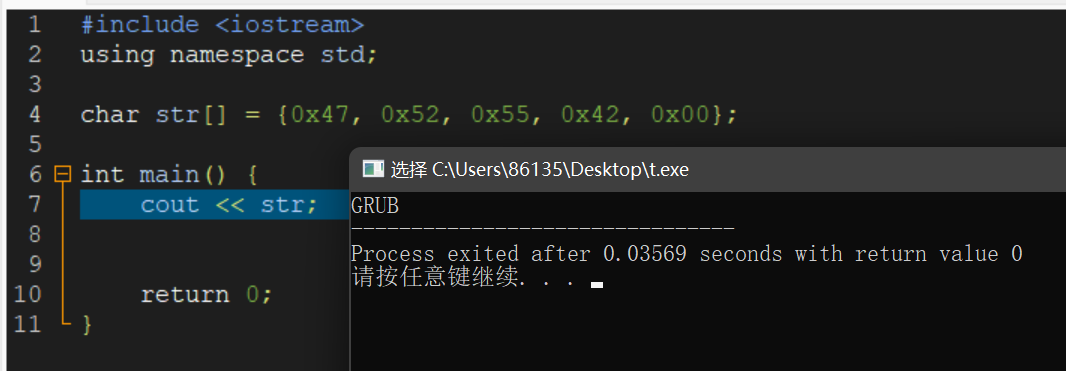
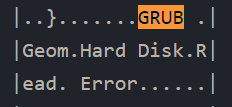
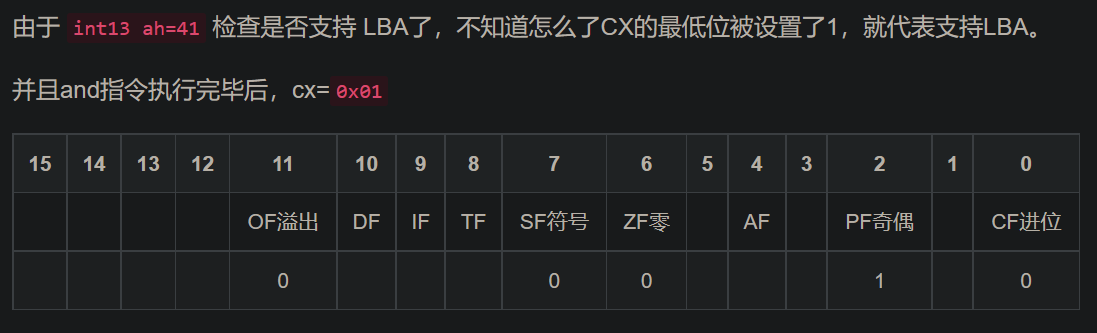
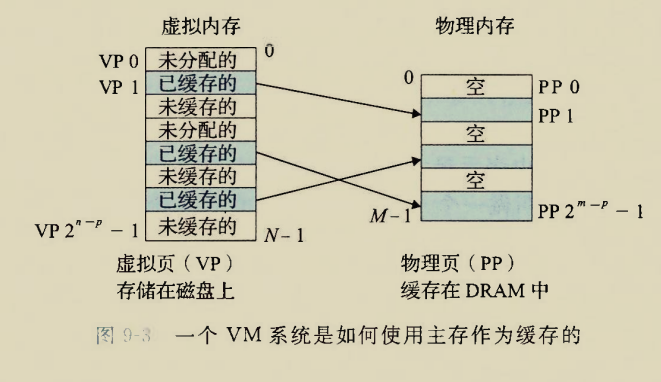
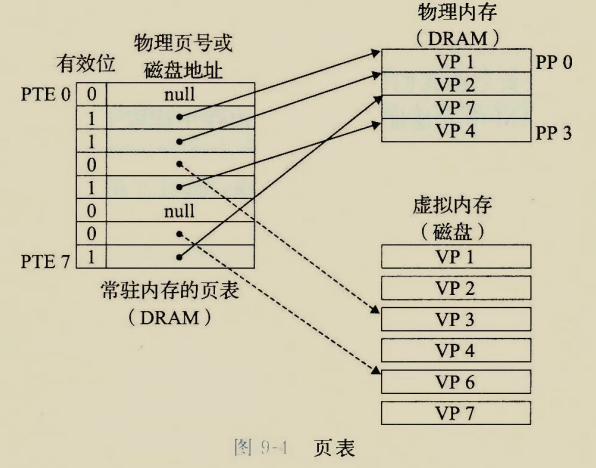
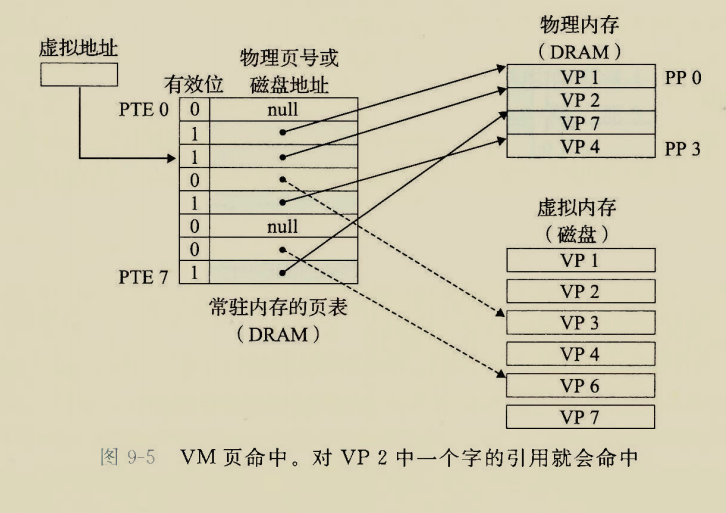
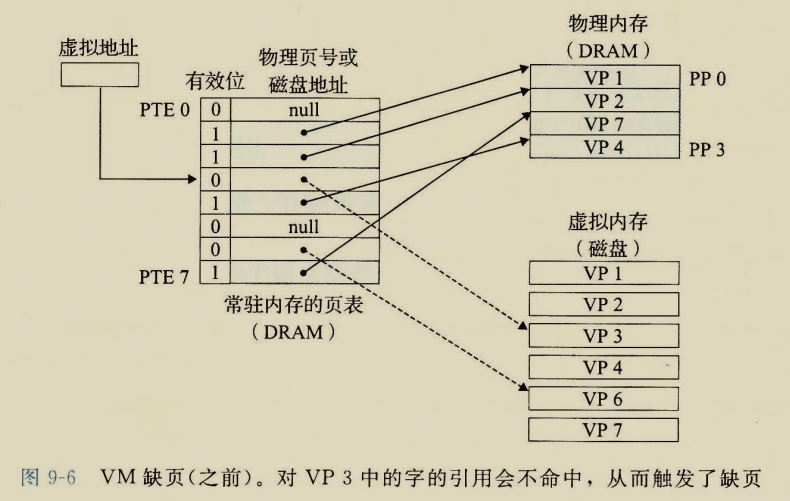
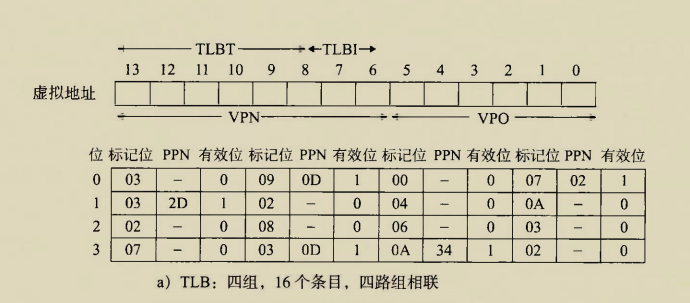
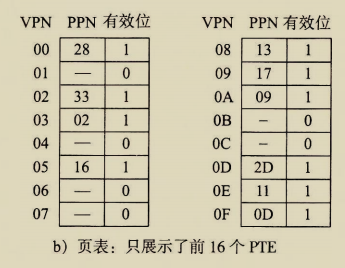
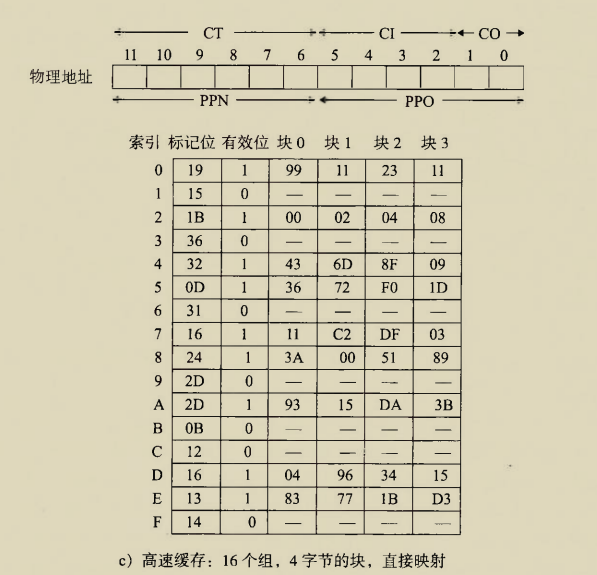
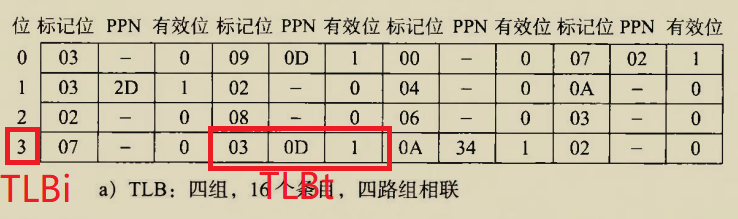
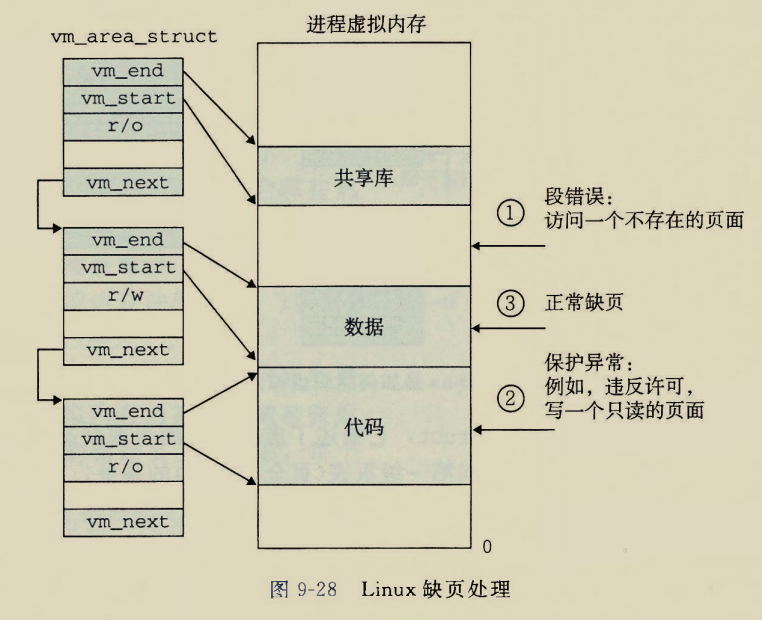
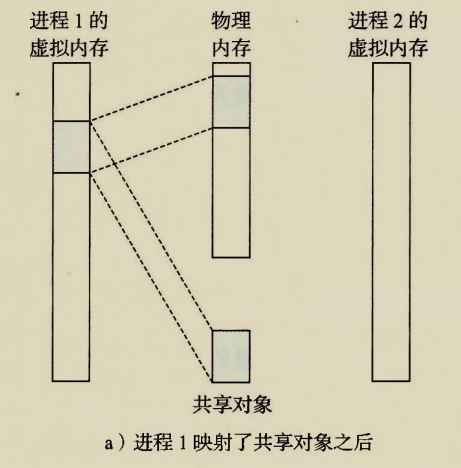
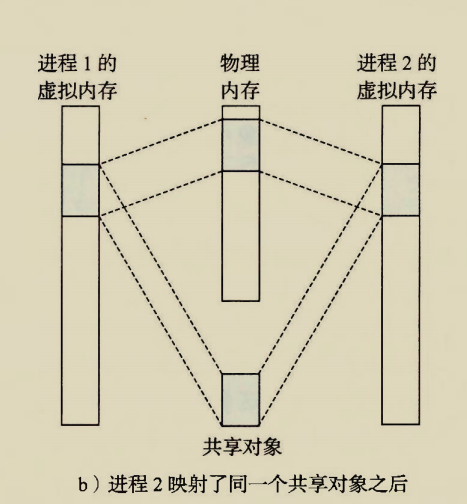
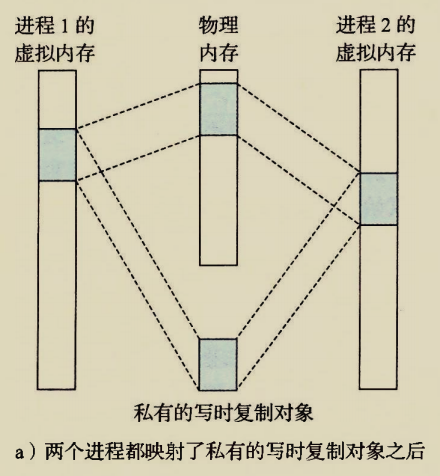
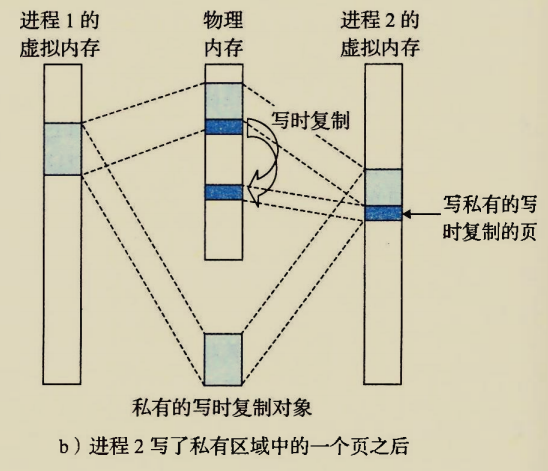
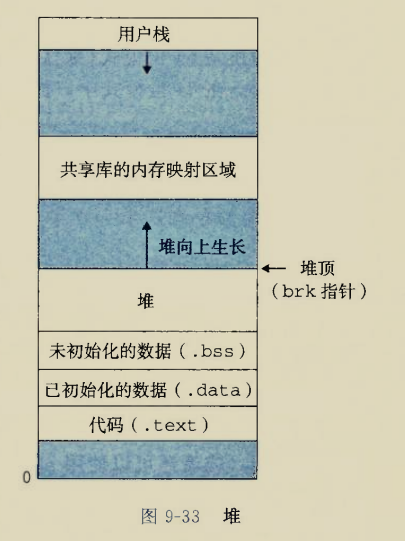
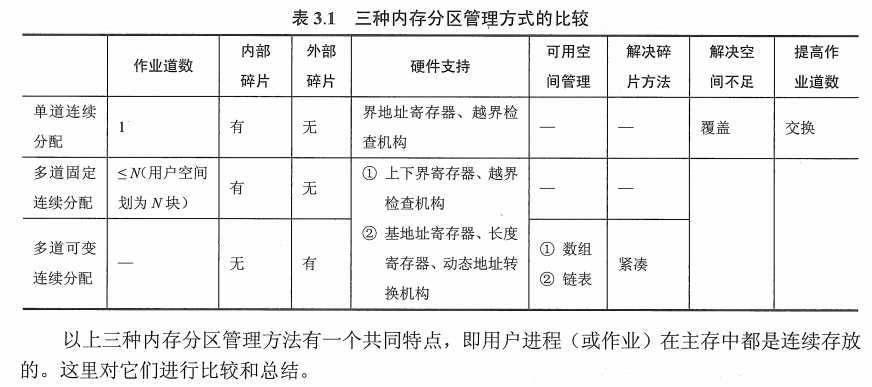
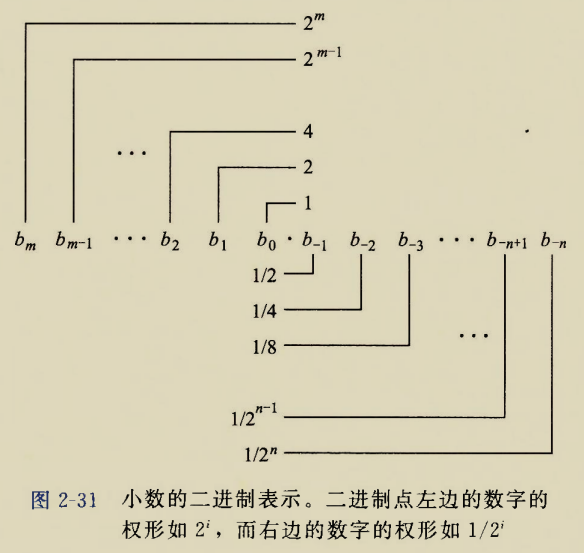
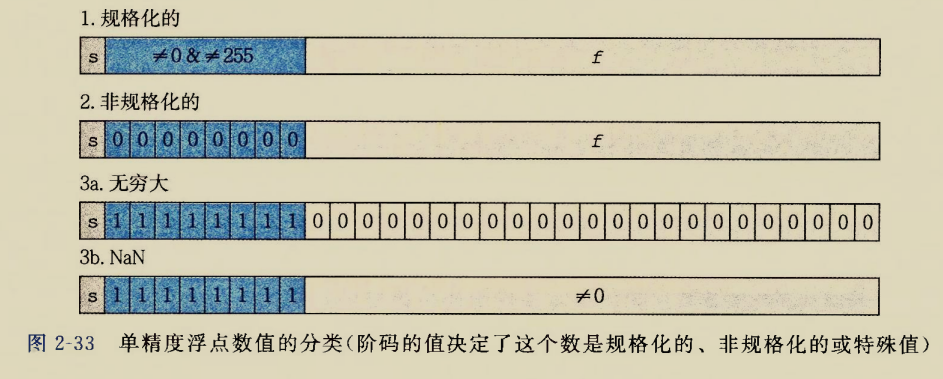
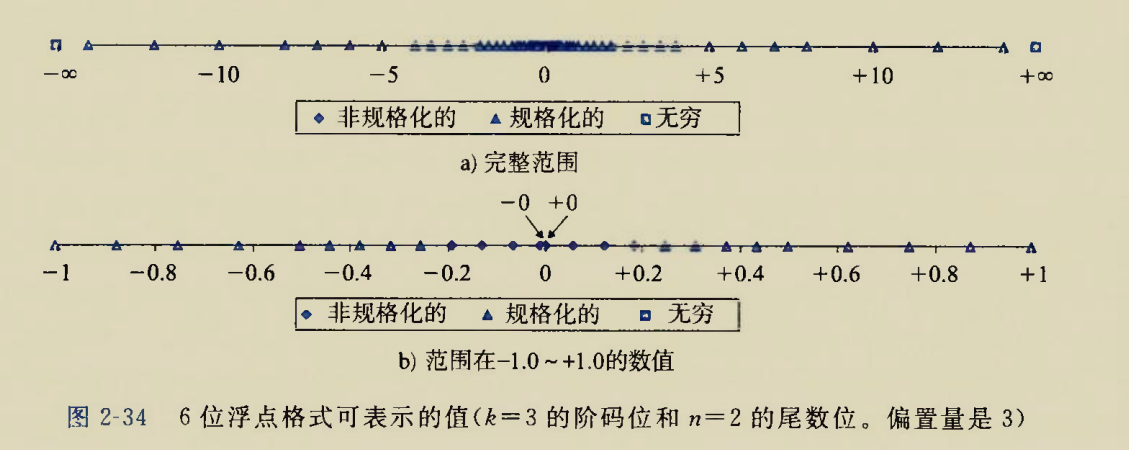
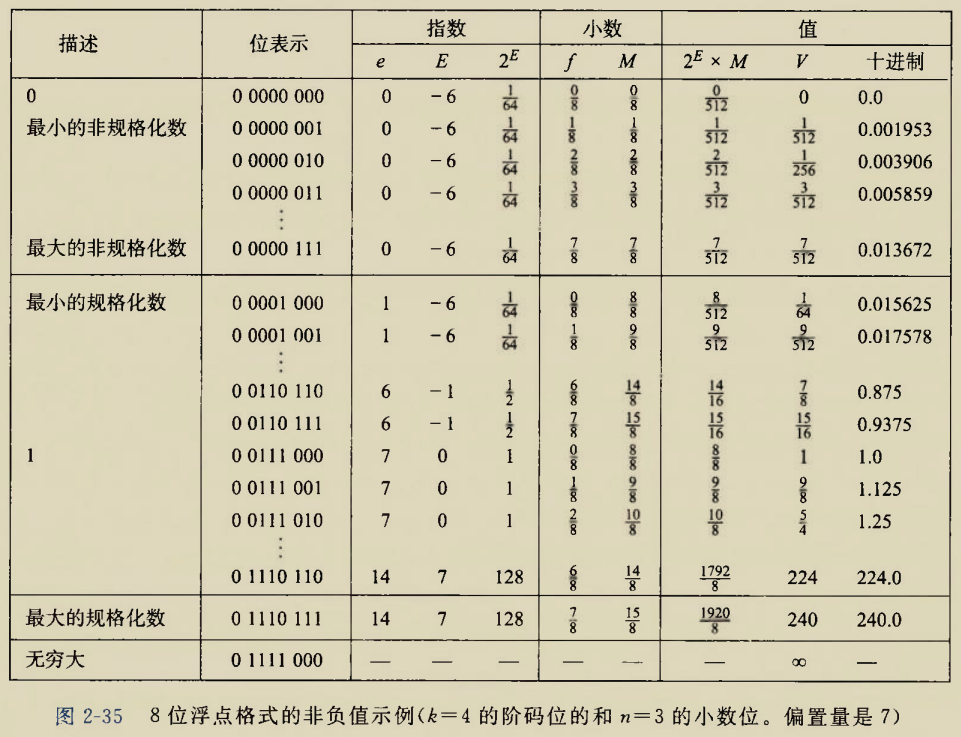
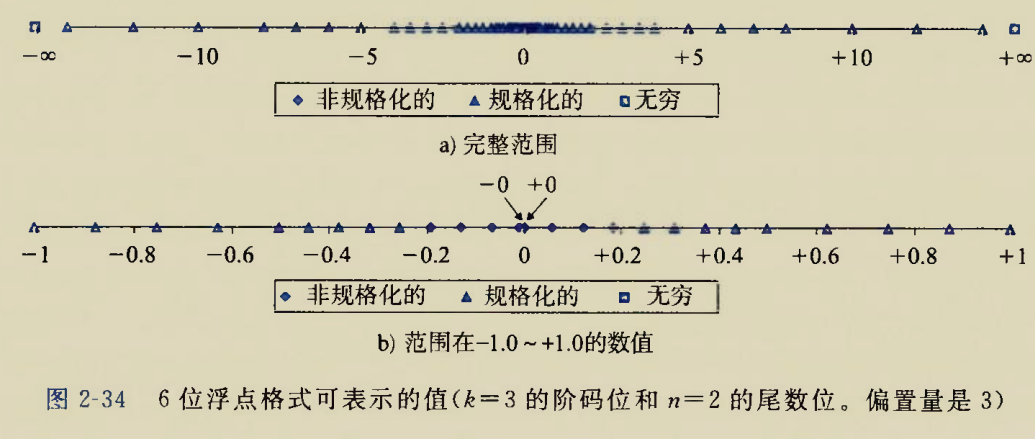
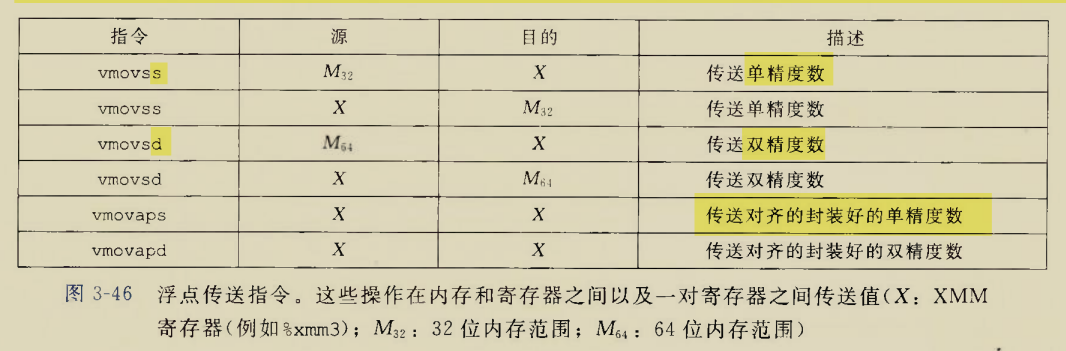
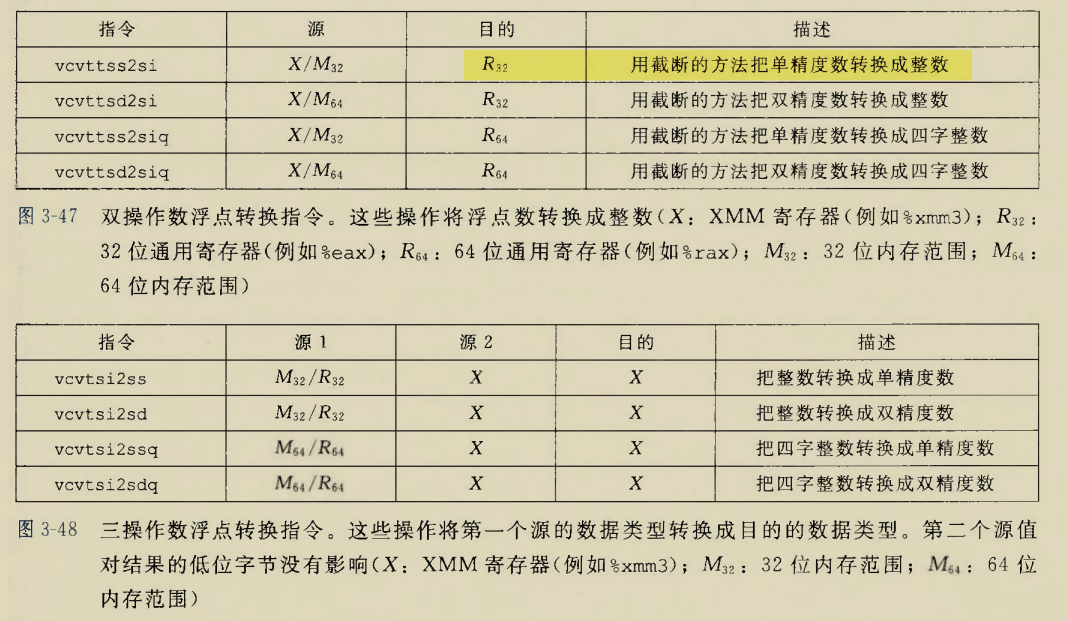
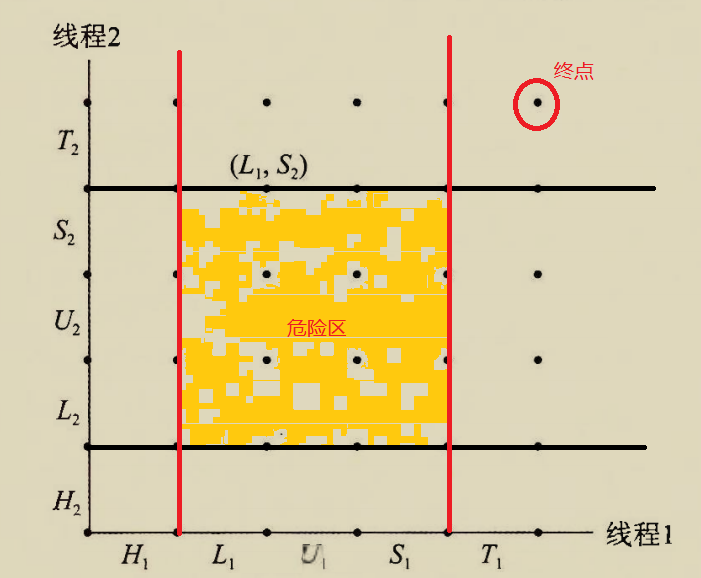
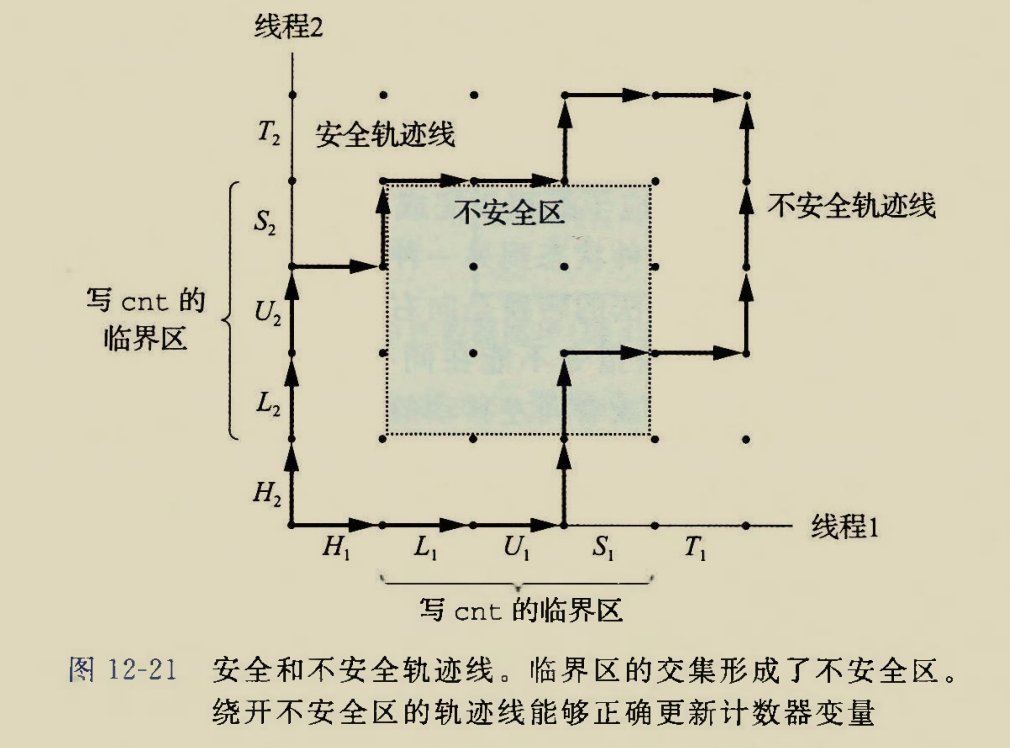
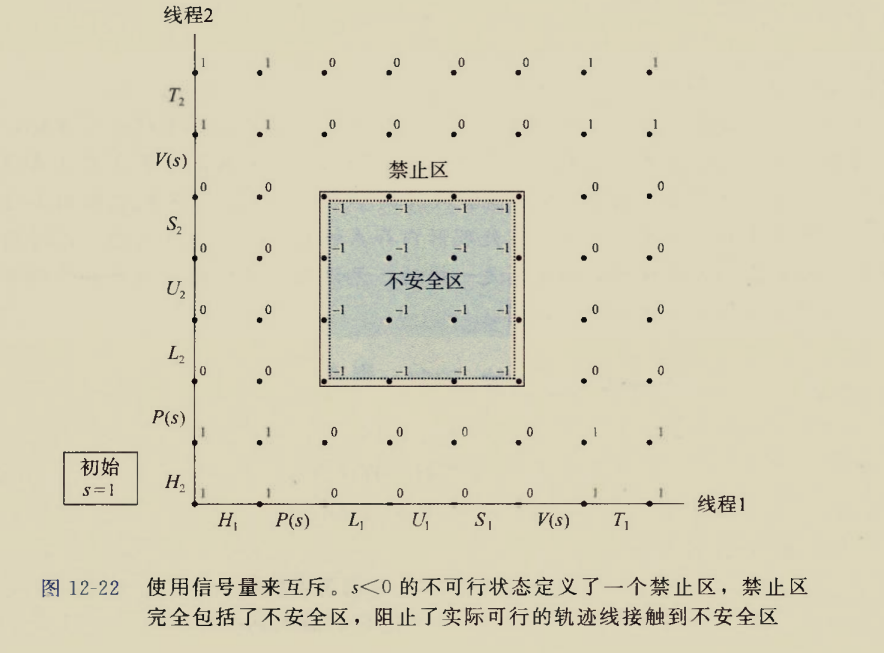
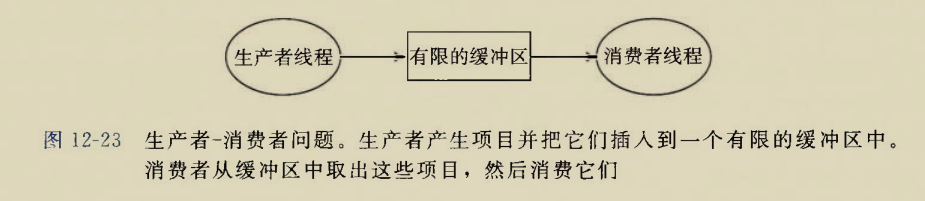
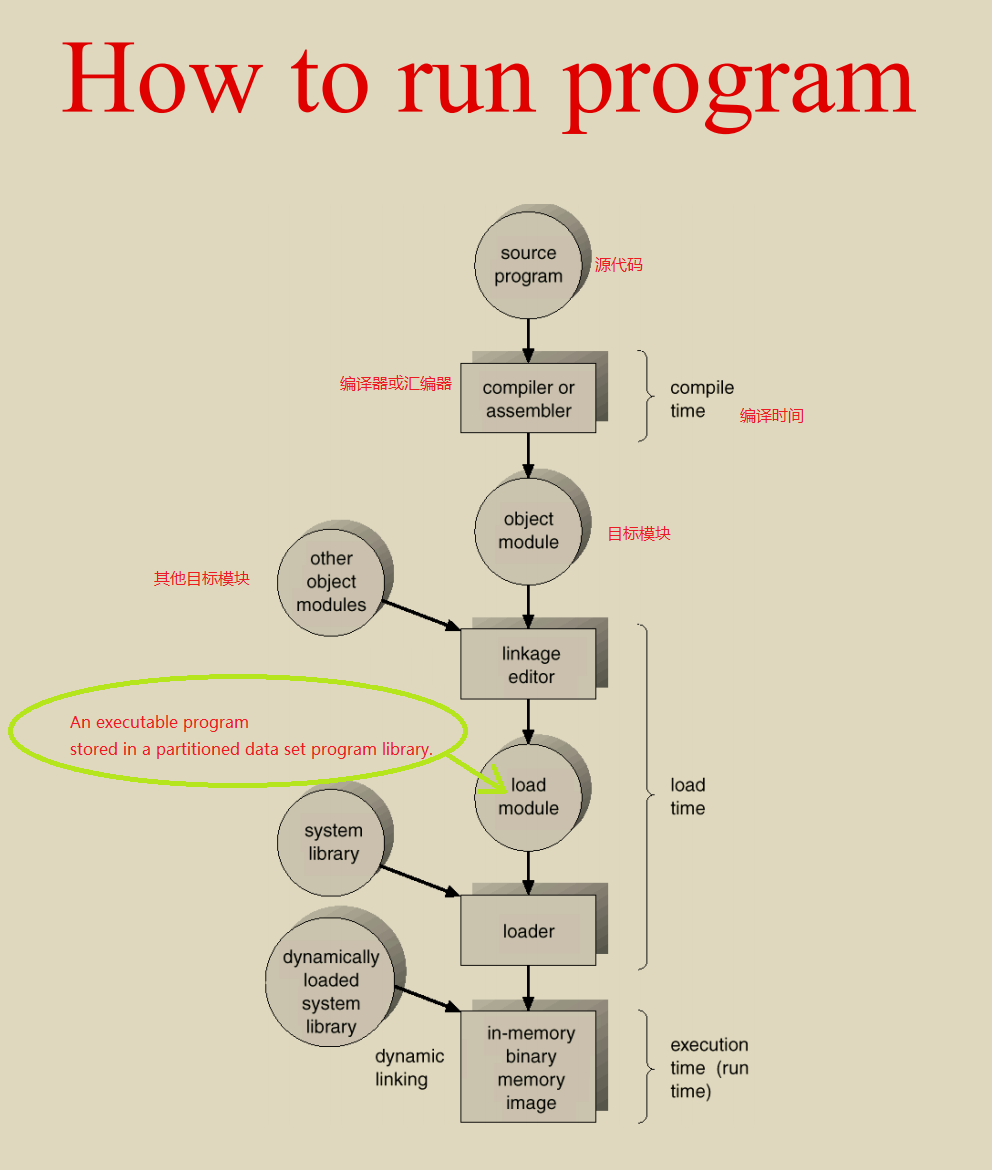
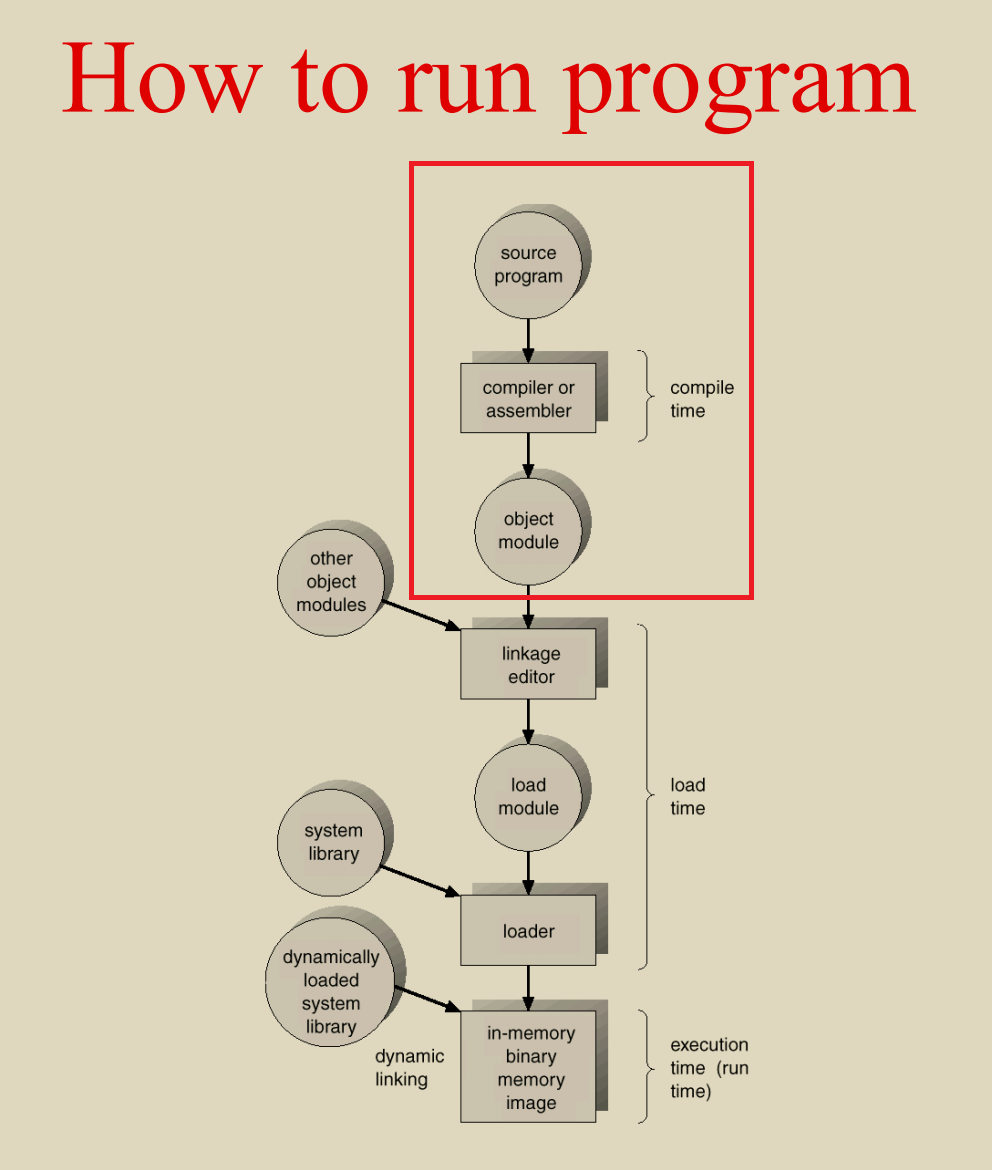
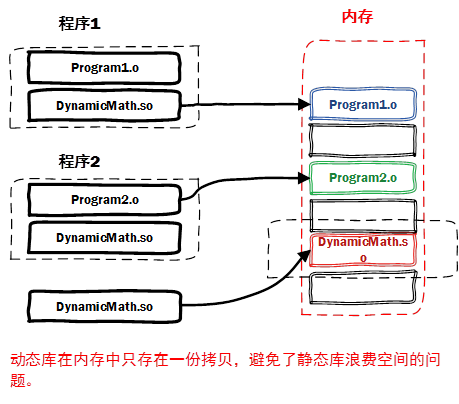
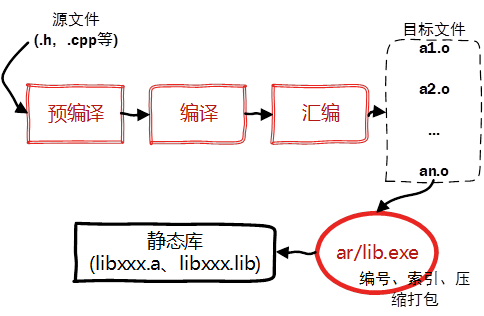
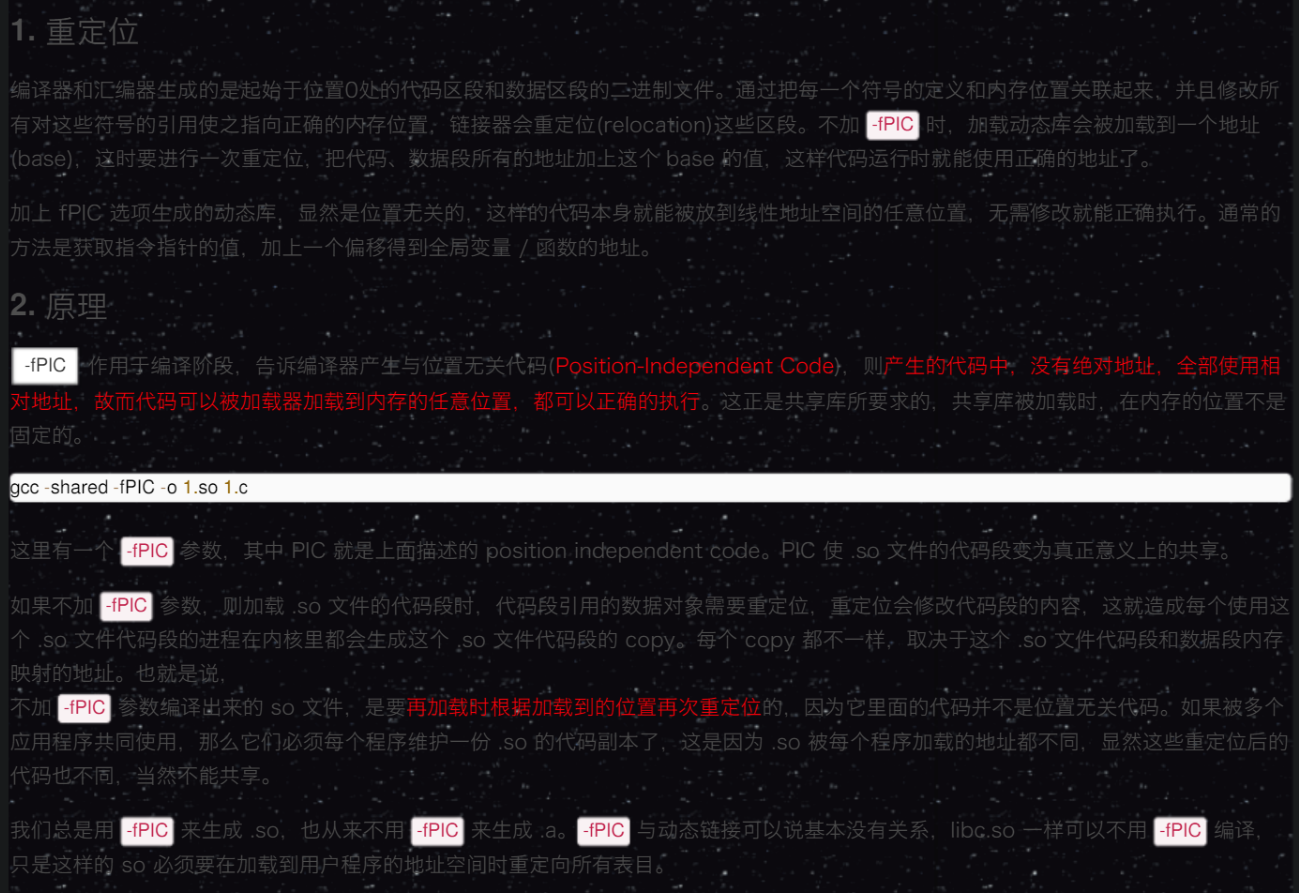
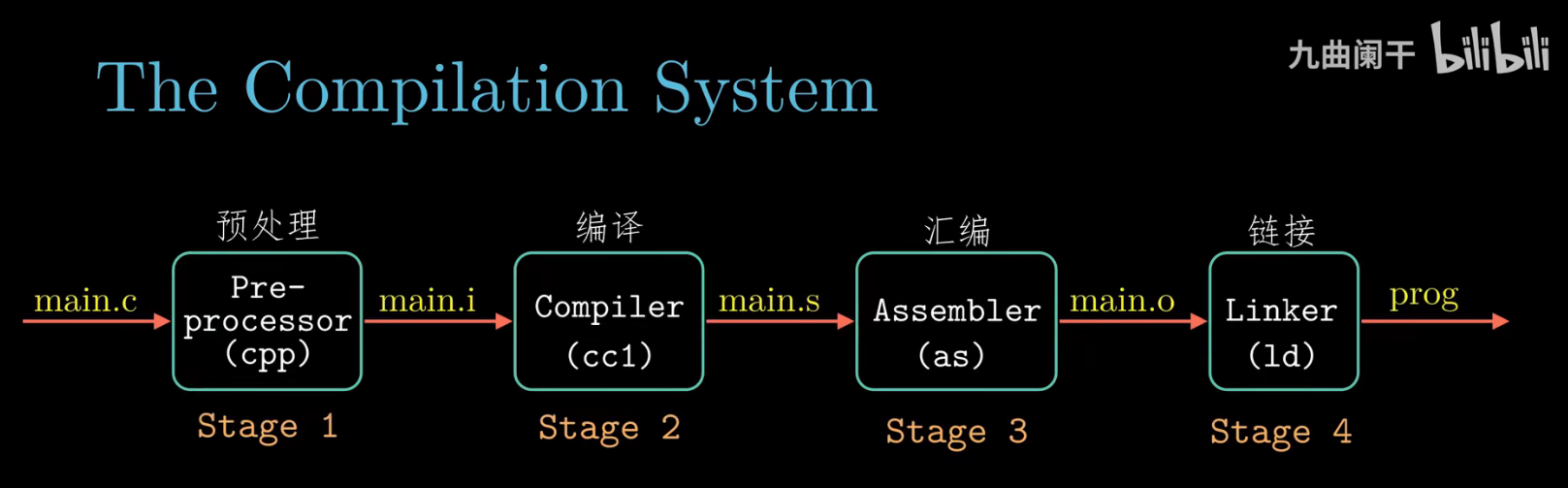
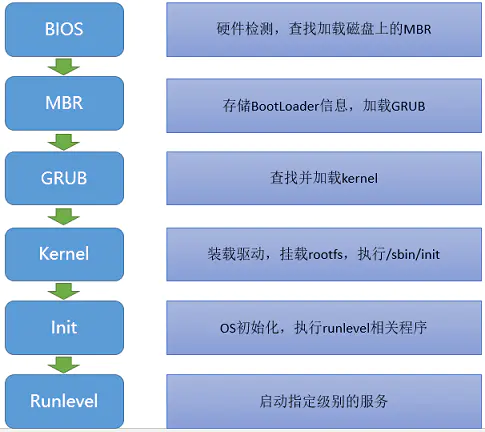
The BIOS runs a program called Power-On Self Test, which determines
how much memory the computer has and then confirms that critical
low-level hardware is operating correctly. Any errors are indicated by
sequences of audible beeps. After this, the BIOS disables all
configurable devices.
The BIOS identifies all of the computer's peripheral devices, such
as hard drives and expansion cards. It first looks for plug-and-play
devices and assigns a number to each, but it doesn't enable the devices
at this time.
The BIOS locates the primary boot or initial program load (IPL)
device. This is usually a storage device such as a hard drive, floppy
drive or CD-ROM that holds the operating system, but it can be a network
card connected to a server. The BIOS also locates all of the system's
secondary IPL devices.
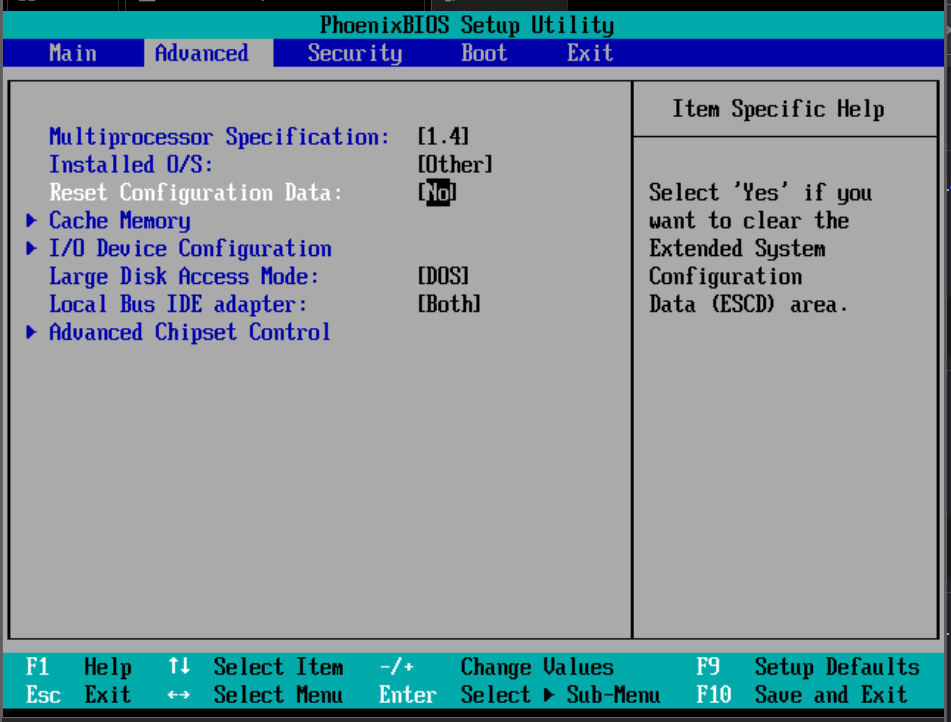
The BIOS builds a system resource table, assigning conflict-free
resources according to which devices it found and the configuration data
stored in nonvolatile RAM.
It selects and enables the primary input (keyboard) and output
(monitor) devices, so that if trouble occurs during the boot process,
the BIOS can display a recovery screen and allow the user to select a
stored configuration of system settings that are known to work. The BIOS
captured these settings the last time the computer booted successfully,
and it stores them in nonvolatile RAM.
It scans for non-plug-and-play devices, including the Peripheral
Component Interconnect (PCI) bus, and adds data from their ROMs to its
resource table.
The BIOS resolves device conflicts and configures the chosen boot
device.
It enables plug-and-play devices by calling their option ROMs with
appropriate parameters.
It starts the bootstrap loader. If, for some reason, the default IPL
fails to load the operating system, the BIOS tries the next IPL device
in the list.
The IPL device loads the operating system into memory.
The BIOS hands over control to the operating system, which may make
other resource assignments.
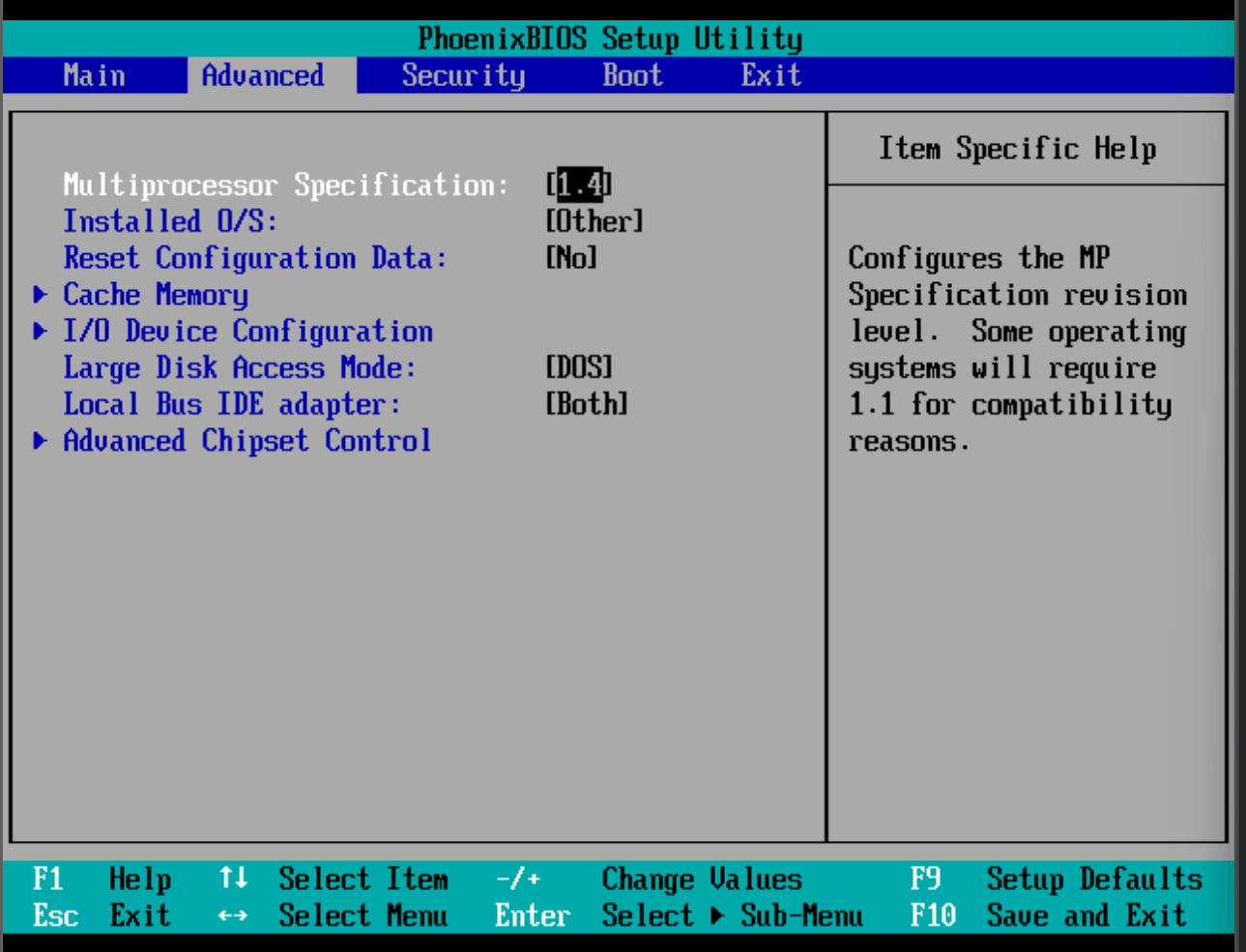
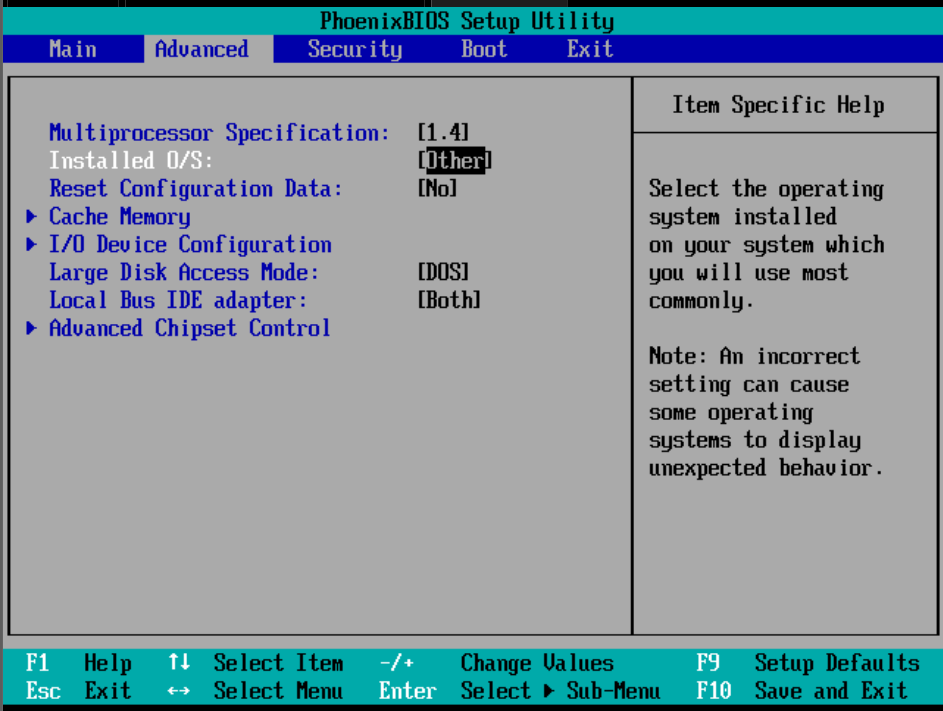
Version 1.1 of the specification was released on April 11, 1994.
Version 1.4 of the specification was released on July 1, 1995, which
added extended configuration tables to improve support for multiple PCI
bus configurations and improve expandability.
The Linux
kernel and FreeBSD are known to
support the Intel MPS. Windows NT are known
to support MPS 1.1 and Windows 2000 or
higher are known to support MPS 1.4. OS/2 are known to support
MPS 1.1 only. Mac OS
X are known to support MPS 1.4 only.
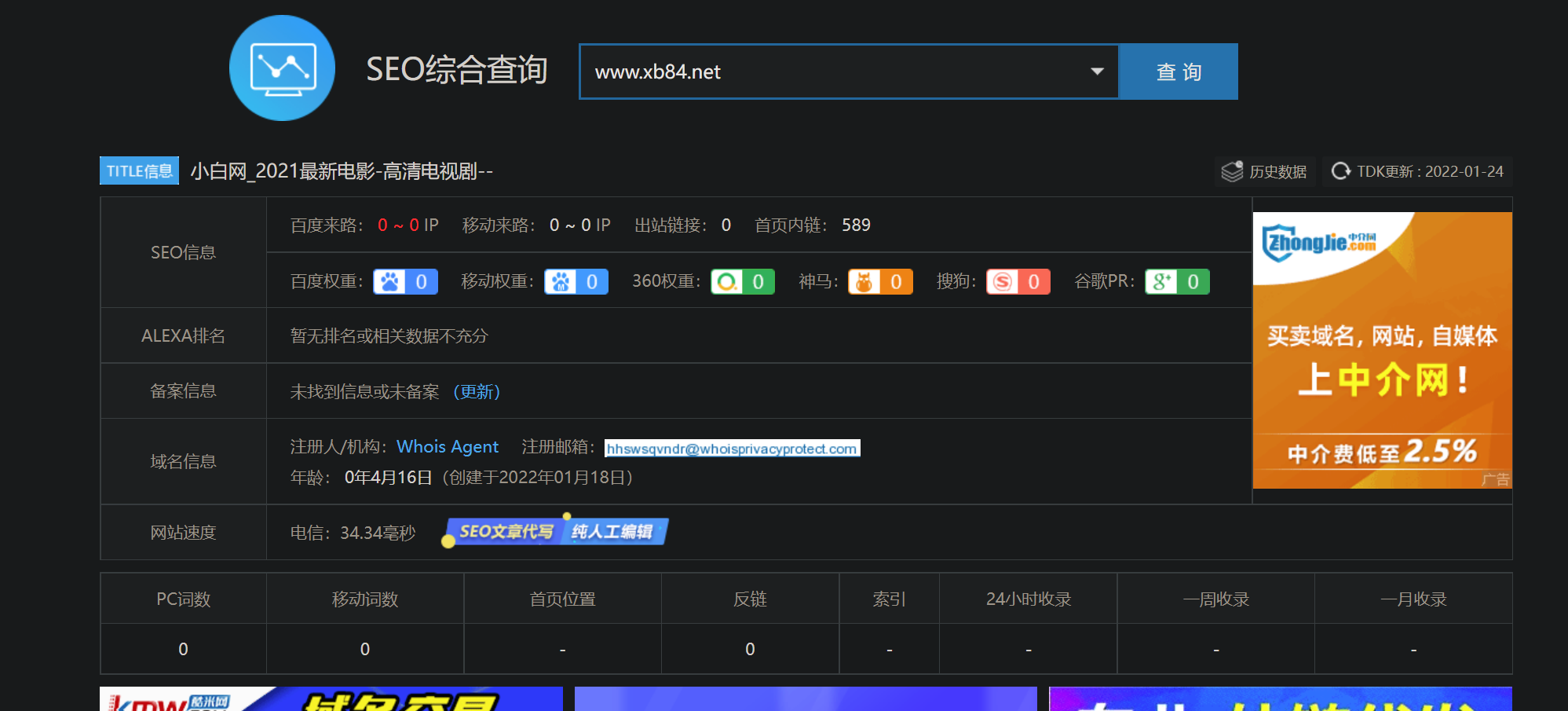
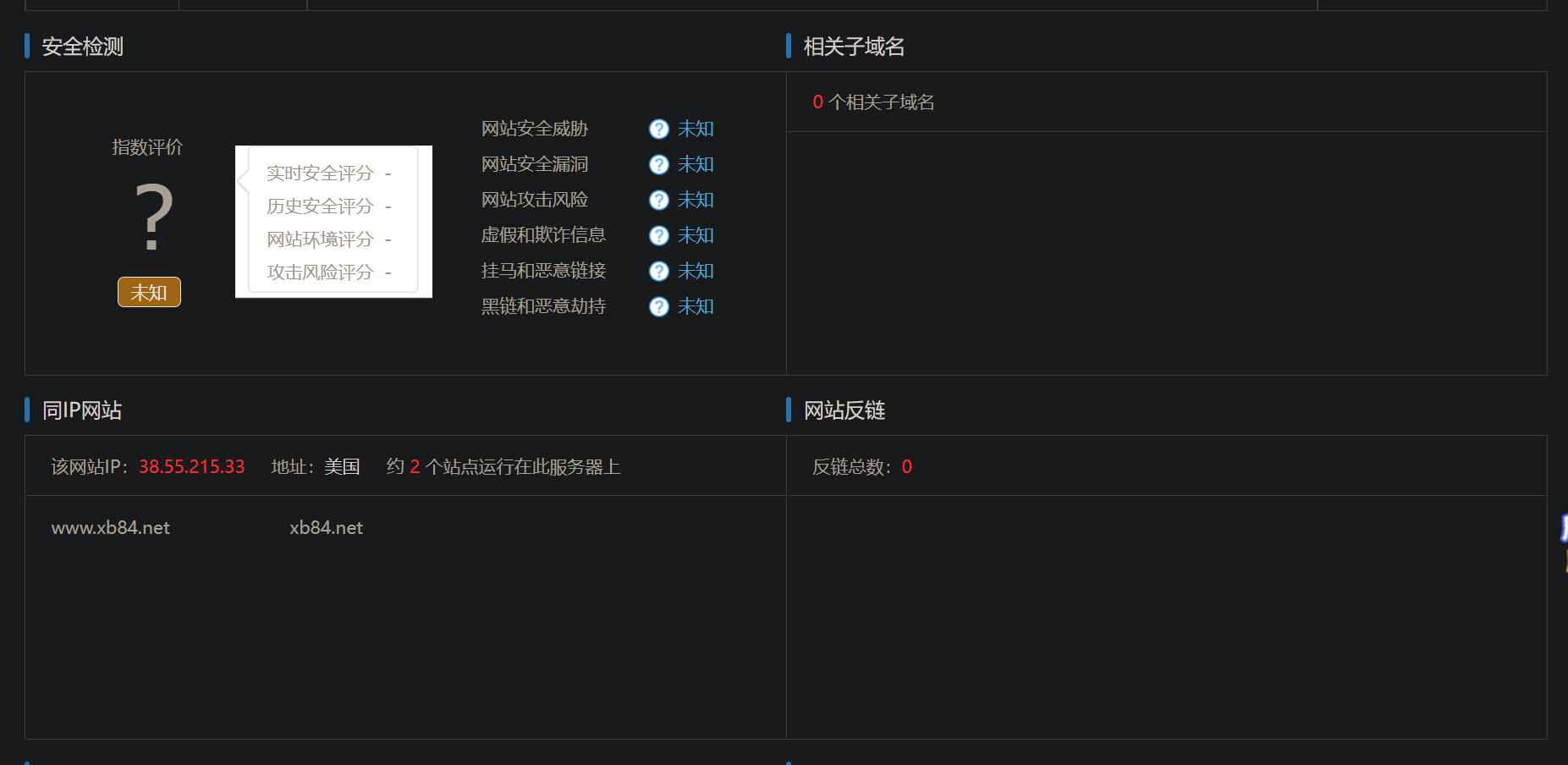
This XML file does not appear to have any style information associated with it. The document tree is shown below. <cross-domain-policy> <allow-access-fromdomain="*.baidu.com"/> <allow-access-fromdomain="*.bdstatic.com"/> <allow-http-request-headers-fromdomain="*.baidu.com"headers="*"/> <allow-http-request-headers-fromdomain="*.bdstatic.com"headers="*"/> </cross-domain-policy>
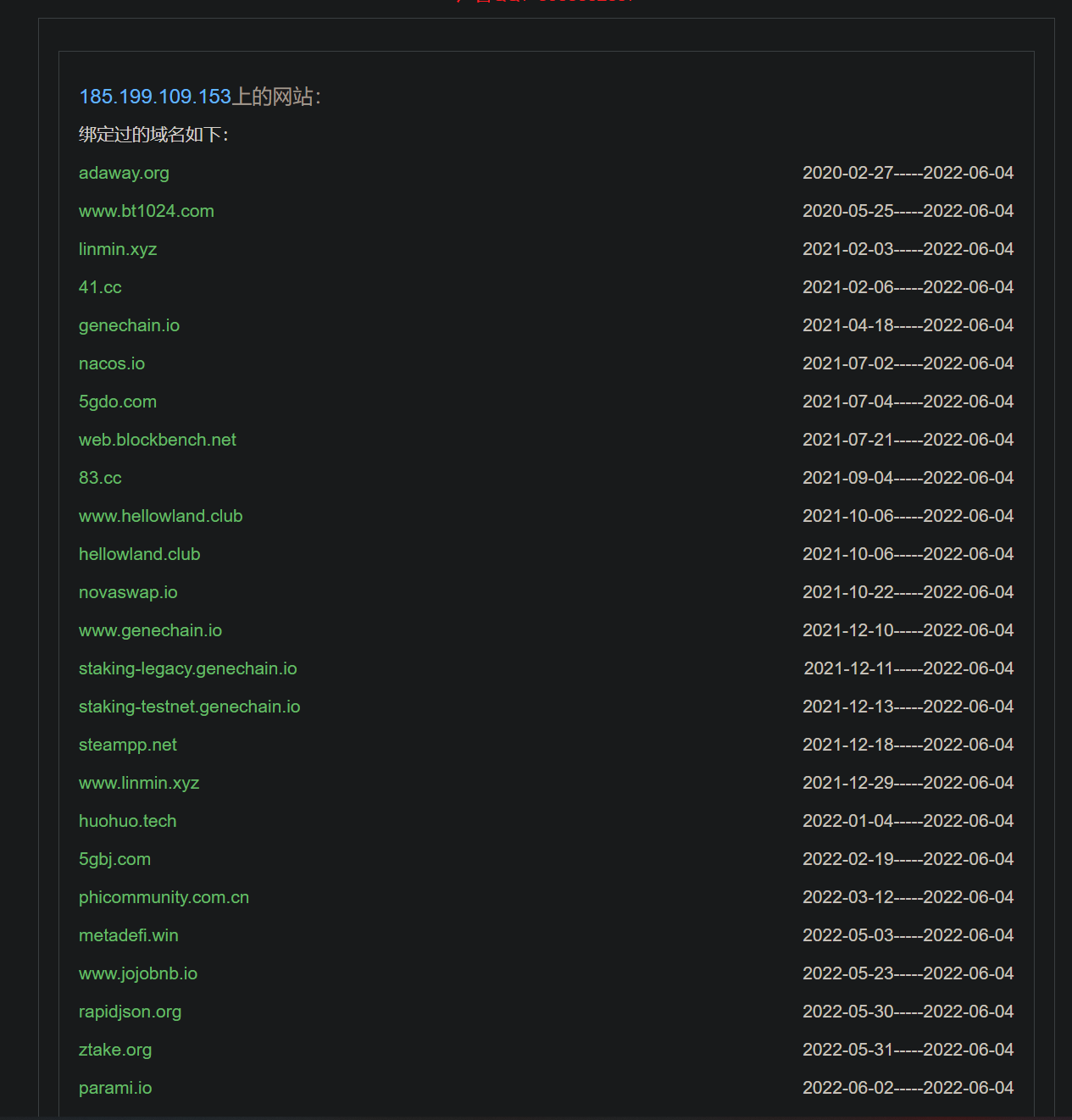
┌──(root㉿Executor)-[/home/kali] └─# nslookup -type=mx stu.xidian.edu.cn main parsing stu.xidian.edu.cn .... Non-authoritative answer: printsection() stu.xidian.edu.cn mail exchanger = 30 mx-edu.icoremail.net.
....
image-20220603232844820
查询NX记录
1
nslookup -type=nx <域名>
查询所有类型
1
nslookup -type=any <域名>
交互模式
1
nslookup
搜索引擎利用
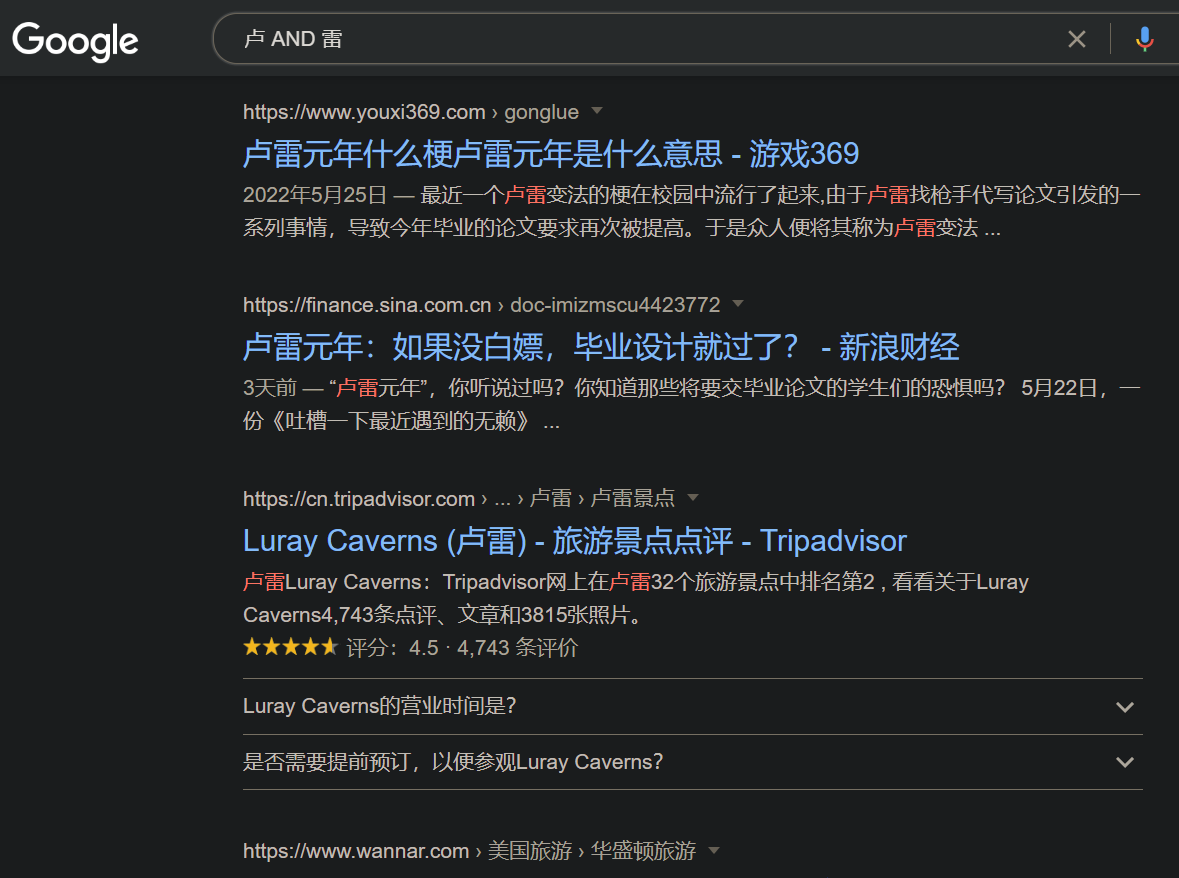
基本搜索
逻辑与AND
image-20220603235155842
逻辑或
image-20220603235313124
逻辑非
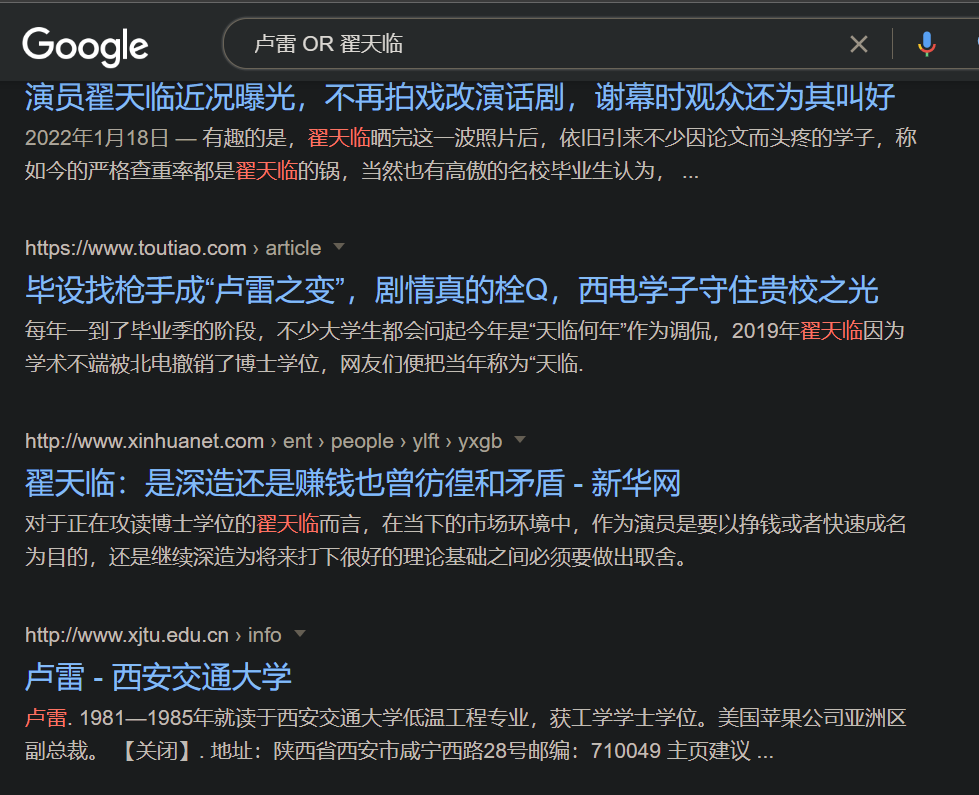
如果搜索"调用约定"时
image-20220603235450822
不想看到CSDN的结果
调用约定 -csdn
image-20220603235527399
通配
使用通配符*
image-20220603235720991
进阶用法
限定站点范围
1
site:<站点>
image-20220603235947419
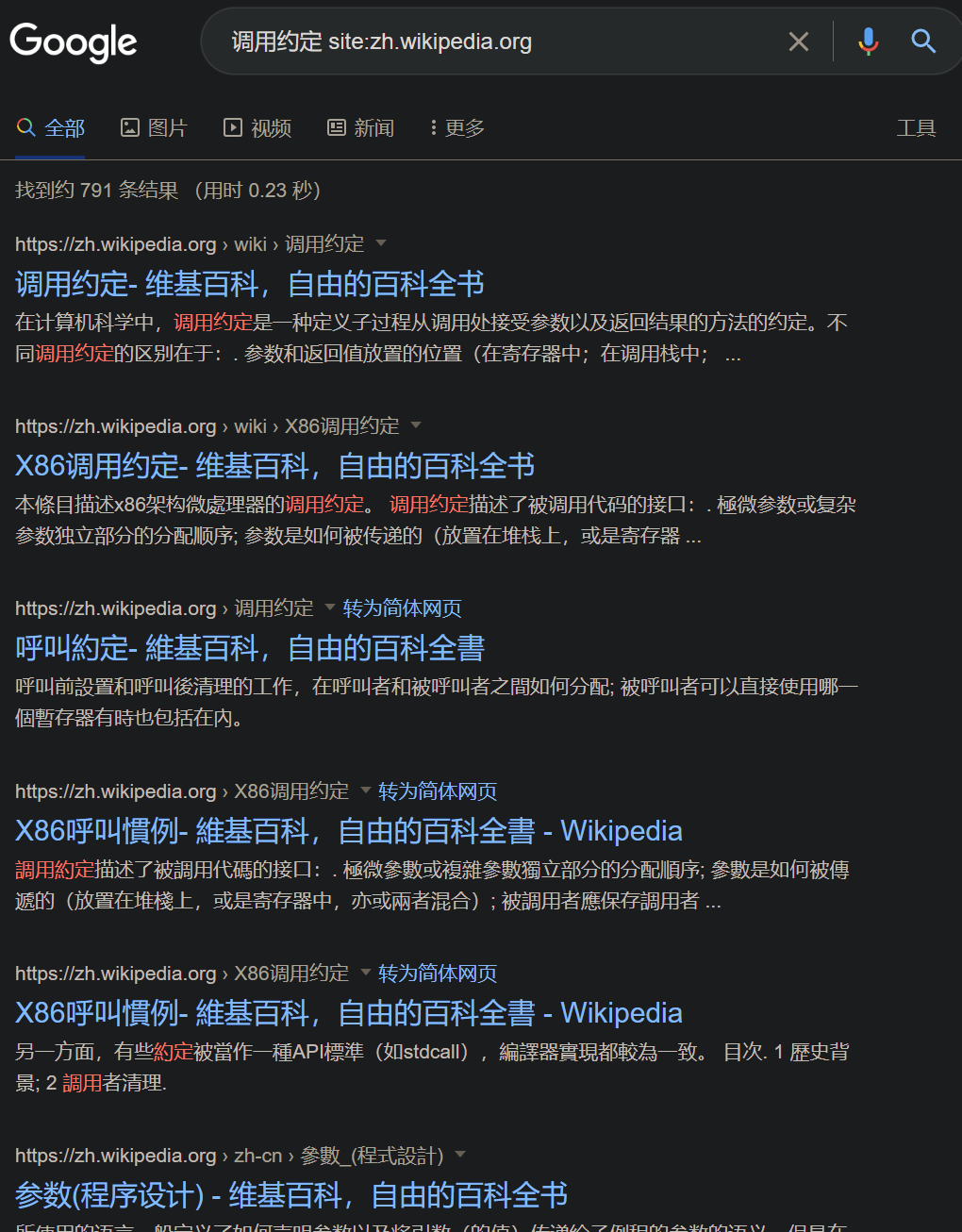
标题含有关键词
1
intitle "<keyword>"
image-20220604000132277
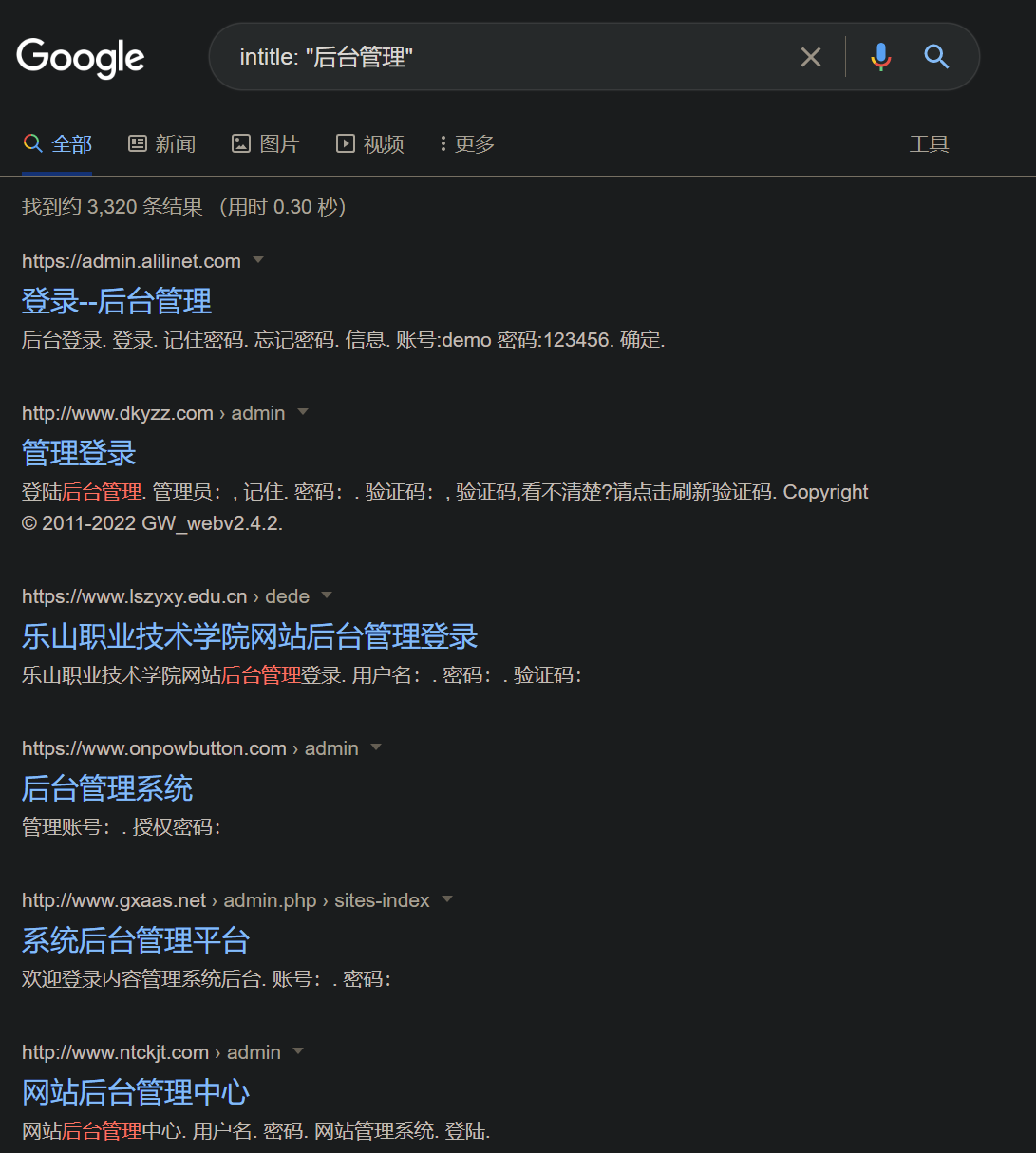
标题含有多组关键词
1
allintitle <keyword1> <keyword2>
image-20220604000632480
所有链接到某个URL地址的网页
1
link: <域名>
image-20220604000822823
含有关键字的url地址
1
inurl: <keyword>
image-20220604001059596
特定拓展名文件
1
filetype: <ex_name>
配合应用
在某网站下搜索含有某关键字标题的页面
image-20220604001749976
主机信息收集
1.主机开放的端口和服务
2.主机操作系统
常见端口及对应服务
image-20220604095959880
nmap
image-20220604100037232
命令行运行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
┌──(root㉿Executor)-[/home/kali] └─# nmap 192.168.43.44 Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-04 10:01 CST Nmap scan report for Executor (192.168.43.44) Host is up (0.00058s latency). Not shown: 996 filtered tcp ports (no-response) PORT STATE SERVICE 80/tcp open http 135/tcp open msrpc 139/tcp open netbios-ssn 445/tcp open microsoft-ds
Nmap done: 1 IP address (1 host up) scanned in 5.04 seconds
┌──(root㉿Executor)-[/home/kali/mydir] └─# nmap -iL list.txt Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-04 10:12 CST Nmap scan report for Executor (192.168.43.44) Host is up (0.00044s latency). Not shown: 996 filtered tcp ports (no-response) PORT STATE SERVICE 80/tcp open http 135/tcp open msrpc 139/tcp open netbios-ssn 445/tcp open microsoft-ds
Nmap scan report for 192.168.43.1 Host is up (0.014s latency). Not shown: 999 closed tcp ports (reset) PORT STATE SERVICE 53/tcp open domain
Nmap done: 3 IP addresses (2 hosts up) scanned in 7.13 seconds
┌──(root㉿Executor)-[/home/kali/mydir] └─# nmap -Pn -iL list.txt Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-04 10:13 CST Nmap scan report for Executor (192.168.43.44) Host is up (0.00029s latency). Not shown: 996 filtered tcp ports (no-response) PORT STATE SERVICE 80/tcp open http 135/tcp open msrpc 139/tcp open netbios-ssn 445/tcp open microsoft-ds
Nmap scan report for 192.168.43.1 Host is up (0.0063s latency). Not shown: 999 closed tcp ports (reset) PORT STATE SERVICE 53/tcp open domain
Nmap scan report for 192.168.43.2 Host is up (0.060s latency). #这里"host is up"是-Pn选项的作用,让nmap认为它在线,但是没有找到任何打开的端口 All 1000 scanned ports on 192.168.43.2 are in ignored states. Not shown: 996 filtered tcp ports (no-response), 4 filtered tcp ports (host-unreach)
Nmap done: 3 IP addresses (3 hosts up) scanned in 14.64 seconds
-PS/PA/PU/PY使用各种协议方式进行扫描
如果不指定这四个之一,则默认使用TCP和ICMP两种方式分别进行主机发现
1 2 3 4 5 6 7 8
┌──(root㉿Executor)-[/home/kali/mydir] └─# nmap -sn -iL list.txt Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-04 10:50 CST Nmap scan report for Executor (192.168.43.44) Host is up (0.00034s latency). Nmap scan report for 192.168.43.1 Host is up (0.0054s latency). Nmap done: 3 IP addresses (2 hosts up) scanned in 2.55 seconds
image-20220604105103155
-PS使用TCP
SYN方式进行主机发现
1 2 3 4 5 6 7 8
┌──(root㉿Executor)-[/home/kali/mydir] └─# nmap -PS -sn -iL list.txt Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-04 10:16 CST Nmap scan report for Executor (192.168.43.44) Host is up (0.00051s latency). Nmap scan report for 192.168.43.1 Host is up (0.0080s latency). Nmap done: 3 IP addresses (2 hosts up) scanned in 1.51 seconds
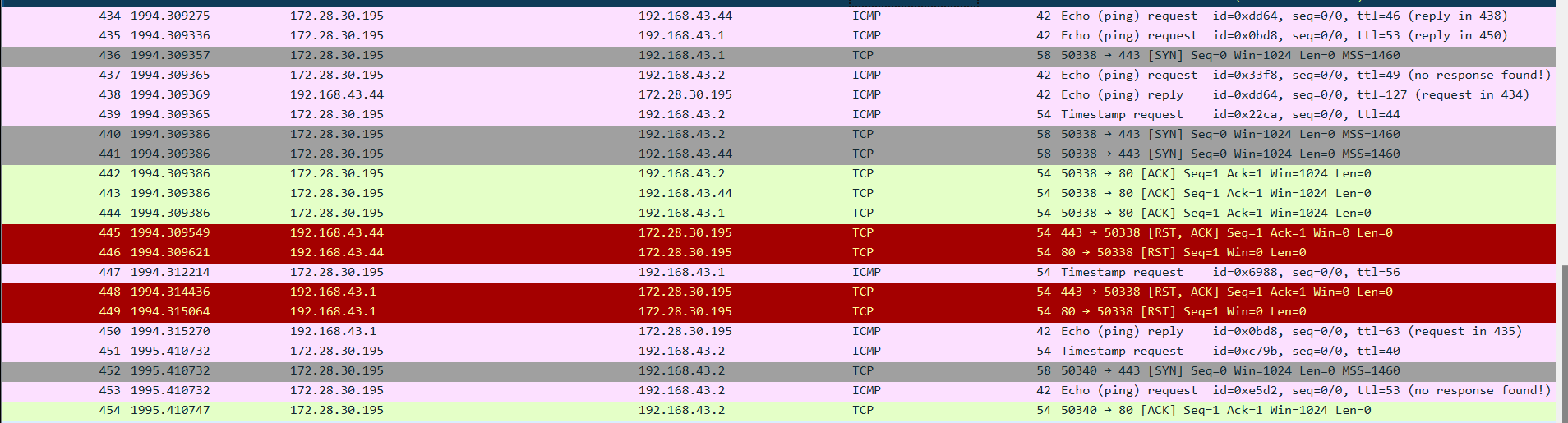
又比如,AB正常建立连接了,正在通讯时,A向B发送了FIN包要求关连接,B发送ACK后,网断了,A通过若干原因放弃了这个连接(例如进程重启)。网通了后,B又开始发数据包,A收到后表示压力很大,不知道这野连接哪来的,就发了个RST包强制把连接关了,B收到后会出现connect
reset
by peer错误。
┌──(root㉿Executor)-[/home/kali/mydir] └─# nmap -PY -sn -iL list.txt Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-04 10:44 CST Nmap done: 3 IP addresses (0 hosts up) scanned in 2.17 seconds
真的太逊了,谁也没发现
image-20220604104524209
全都是kali发往其他ip的SCTP数据报,但是没有收到任何回复
端口扫描
端口状态
image-20220604110513885
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
┌──(root㉿Executor)-[/home/kali/mydir] └─# nmap -p 80 -iL list.txt Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-04 11:04 CST Nmap scan report for Executor (192.168.43.44) Host is up (0.00031s latency).
PORT STATE SERVICE 80/tcp open http
Nmap scan report for 192.168.43.1 Host is up (0.0089s latency).
PORT STATE SERVICE 80/tcp closed http
Nmap done: 3 IP addresses (2 hosts up) scanned in 2.69 seconds
本机192.168.43.44上的80端口就是open状态
192.168.43.1上的80端口就是close状态
netstat -n查看本机端口状态
1 2 3 4 5 6 7 8 9 10 11 12 13
PS C:\Users\86135> netstat -n
活动连接
协议 本地地址 外部地址 状态 TCP 127.0.0.1:28825127.0.0.1:54530 ESTABLISHED TCP 127.0.0.1:28826127.0.0.1:28827 ESTABLISHED TCP 127.0.0.1:28827127.0.0.1:28826 ESTABLISHED TCP 127.0.0.1:54530127.0.0.1:28825 ESTABLISHED TCP 192.168.43.44:2894440.90.189.152:443 ESTABLISHED TCP 192.168.43.44:29072103.212.12.46:3000 ESTABLISHED TCP 192.168.43.44:2991061.150.43.81:443 CLOSE_WAIT ....
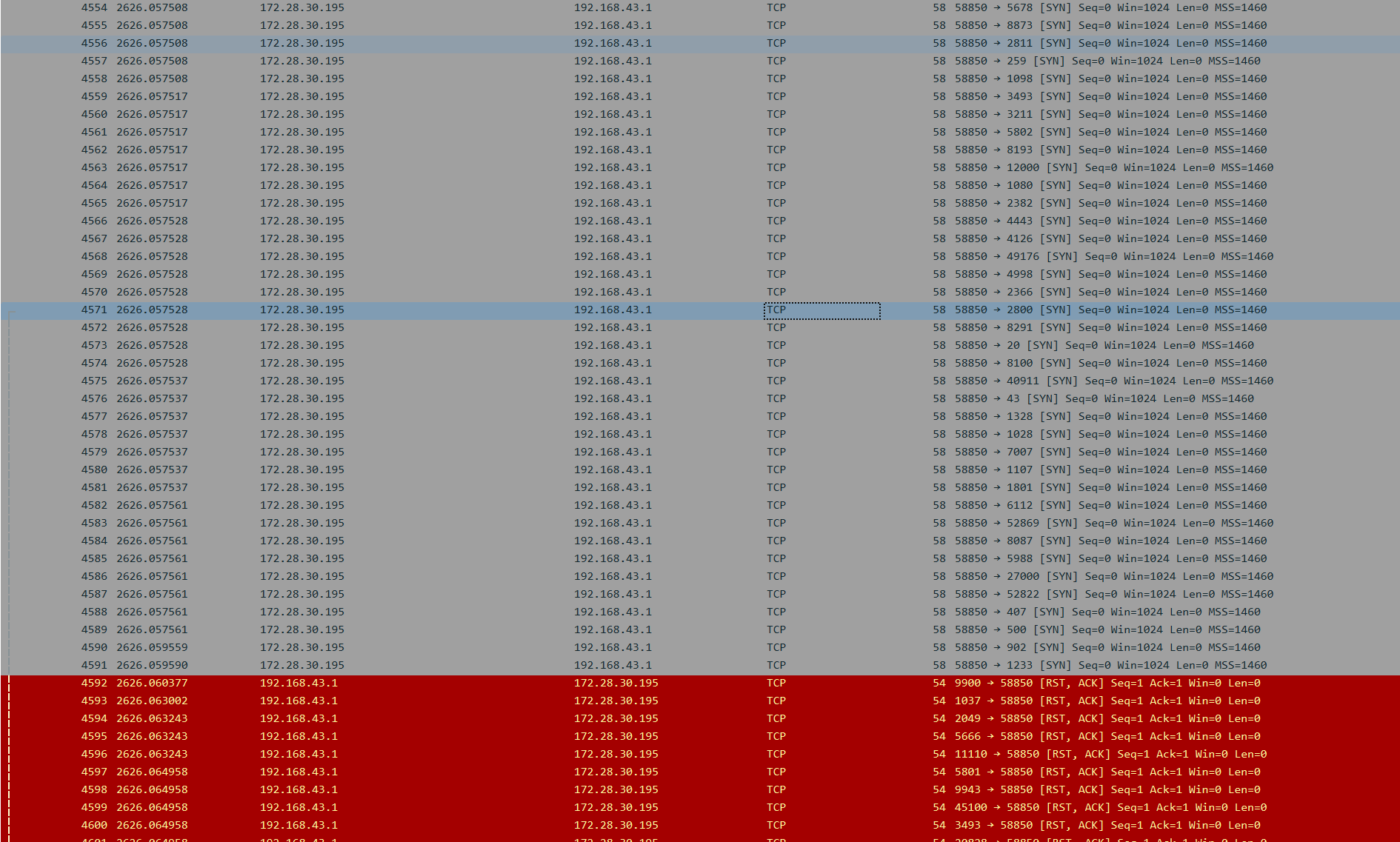
┌──(root㉿Executor)-[/home/kali/mydir] └─# nmap -iL list.txt Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-04 11:00 CST Nmap scan report for Executor (192.168.43.44) Host is up (0.00025s latency). Not shown: 994 closed tcp ports (reset) PORT STATE SERVICE 80/tcp open http 135/tcp open msrpc 139/tcp open netbios-ssn 445/tcp open microsoft-ds 902/tcp open iss-realsecure 912/tcp open apex-mesh
Nmap scan report for 192.168.43.1 Host is up (0.0098s latency). Not shown: 999 closed tcp ports (reset) PORT STATE SERVICE 53/tcp open domain
Nmap done: 3 IP addresses (2 hosts up) scanned in 2.94 seconds
kali nmap对大量端口展开了轰炸
image-20220604110122323
-p <port>扫描指定端口
比如指定扫描list.txt中列出主机的80端口(http服务器端口)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
┌──(root㉿Executor)-[/home/kali/mydir] └─# nmap -p 80 -iL list.txt Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-04 10:53 CST Nmap scan report for Executor (192.168.43.44) Host is up (0.00028s latency).
PORT STATE SERVICE 80/tcp open http
Nmap scan report for 192.168.43.1 Host is up (0.062s latency).
PORT STATE SERVICE 80/tcp closed http
Nmap done: 3 IP addresses (2 hosts up) scanned in 2.72 seconds
image-20220604105515492
确实Executor上开着一个Apache服务器,但是192.168.43.1手机上没有
-F快速模式,只扫描nmap-services中列出的端口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
┌──(root㉿Executor)-[/home/kali/mydir] └─# nmap -F -iL list.txt Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-04 11:02 CST Nmap scan report for Executor (192.168.43.44) Host is up (0.00050s latency). Not shown: 96 closed tcp ports (reset) PORT STATE SERVICE 80/tcp open http 135/tcp open msrpc 139/tcp open netbios-ssn 445/tcp open microsoft-ds
Nmap scan report for 192.168.43.1 Host is up (0.010s latency). Not shown: 99 closed tcp ports (reset) PORT STATE SERVICE 53/tcp open domain
Nmap done: 3 IP addresses (2 hosts up) scanned in 2.72 seconds
相对于不使用命令行参数的默认扫描方式,该种方式没有扫描到
1 2
902/tcp open iss-realsecure 912/tcp open apex-mesh
操作系统检测
操作系统检测是基于端口扫描的
如果不指定扫描端口,却进行操作系统检测,是无效的
1 2 3 4
┌──(root㉿Executor)-[/home/kali/mydir] └─# nmap -O -A -sn -iL list.txt WARNING: OS Scan is unreliable without a port scan. You need to use a scan type along with it, such as -sS, -sT, -sF, etc instead of -sn QUITTING!
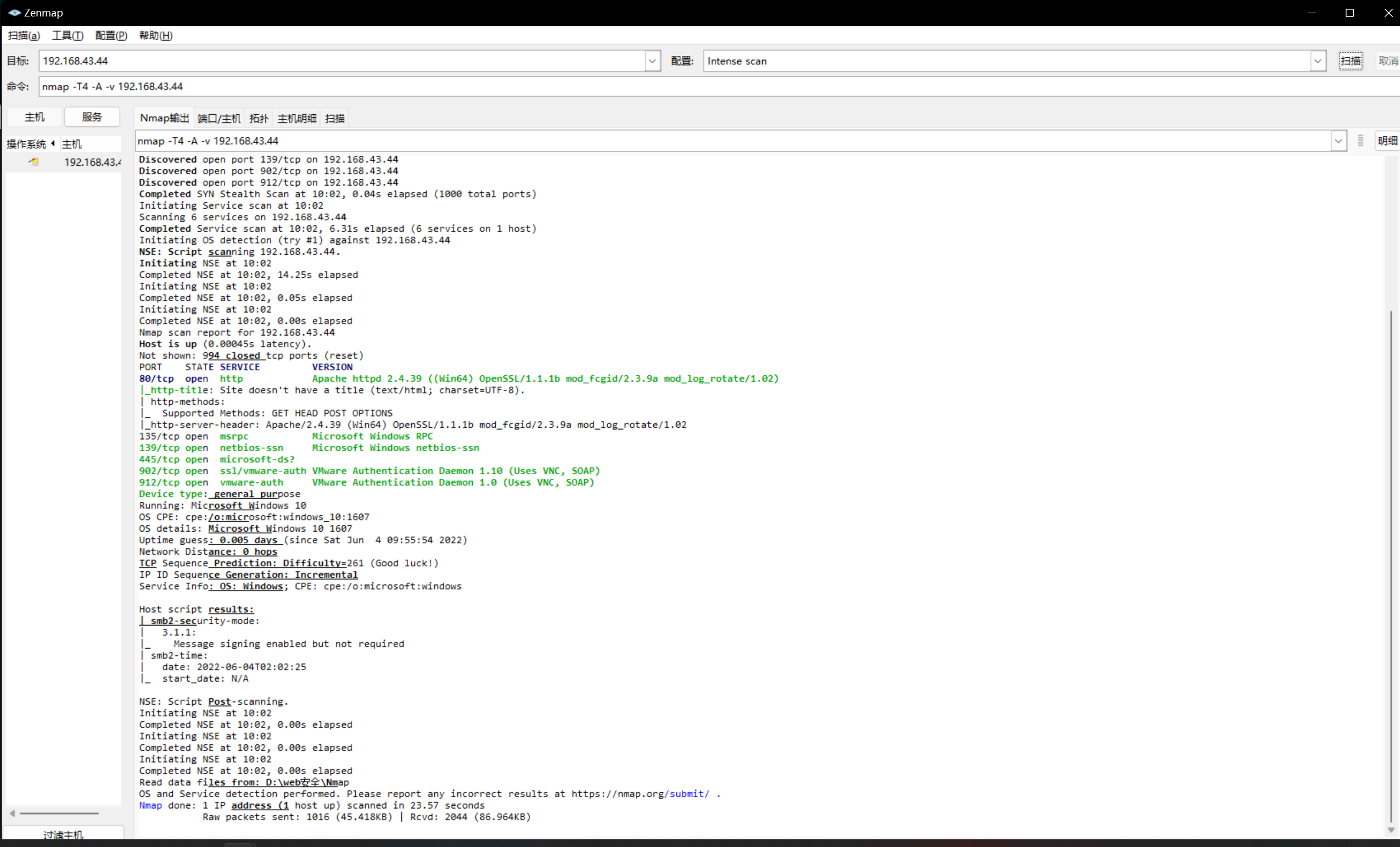
┌──(root㉿Executor)-[/home/kali/mydir] └─# nmap -O -A -iL list.txt Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-04 11:07 CST Nmap scan report for Executor (192.168.43.44) Host is up (0.00038s latency). Not shown: 994 closed tcp ports (reset) PORT STATE SERVICE VERSION 80/tcp open http Apache httpd 2.4.39 ((Win64) OpenSSL/1.1.1b mod_fcgid/2.3.9a mod_log_rotate/1.02) |_http-server-header: Apache/2.4.39 (Win64) OpenSSL/1.1.1b mod_fcgid/2.3.9a mod_log_rotate/1.02 |_http-title: Site doesn't have a title (text/html; charset=UTF-8). 135/tcp open msrpc Microsoft Windows RPC 139/tcp open netbios-ssn Microsoft Windows netbios-ssn 445/tcp open microsoft-ds? 902/tcp open ssl/vmware-auth VMware Authentication Daemon 1.10 (Uses VNC, SOAP) 912/tcp open vmware-auth VMware Authentication Daemon 1.0 (Uses VNC, SOAP) No exact OS matches for host (If you know what OS is running on it, see https://nmap.org/submit/ ). TCP/IP fingerprint: OS:SCAN(V=7.92%E=4%D=6/4%OT=80%CT=1%CU=37312%PV=Y%DS=2%DC=T%G=Y%TM=629ACC98 OS:%P=x86_64-pc-linux-gnu)SEQ(SP=101%GCD=1%ISR=10D%TI=I%CI=I%II=I%SS=S%TS=A OS:)OPS(O1=MFFD7NW8ST11%O2=MFFD7NW8ST11%O3=MFFD7NW8NNT11%O4=MFFD7NW8ST11%O5 OS:=MFFD7NW8ST11%O6=MFFD7ST11)WIN(W1=FFFF%W2=FFFF%W3=FFFF%W4=FFFF%W5=FFFF%W OS:6=FFDC)ECN(R=Y%DF=Y%T=7F%W=FFFF%O=MFFD7NW8NNS%CC=N%Q=)T1(R=Y%DF=Y%T=7F%S OS:=O%A=S+%F=AS%RD=0%Q=)T2(R=Y%DF=Y%T=7F%W=0%S=Z%A=S%F=AR%O=%RD=0%Q=)T3(R=Y OS:%DF=Y%T=7F%W=0%S=Z%A=O%F=AR%O=%RD=0%Q=)T4(R=Y%DF=Y%T=7F%W=0%S=A%A=O%F=R% OS:O=%RD=0%Q=)T5(R=Y%DF=Y%T=7F%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=)T6(R=Y%DF=Y%T=7 OS:F%W=0%S=A%A=O%F=R%O=%RD=0%Q=)T7(R=Y%DF=Y%T=7F%W=0%S=Z%A=S+%F=AR%O=%RD=0% OS:Q=)U1(R=Y%DF=N%T=7F%IPL=164%UN=0%RIPL=G%RID=G%RIPCK=G%RUCK=37DE%RUD=G)IE OS:(R=Y%DFI=N%T=7F%CD=Z)
Network Distance: 2 hops Service Info: OS: Windows; CPE: cpe:/o:microsoft:windows
TRACEROUTE (using port 587/tcp) HOP RTT ADDRESS 10.41 ms Executor.mshome.net (172.28.16.1) 20.43 ms Executor (192.168.43.44)
Nmap scan report for 192.168.43.1 Host is up (0.0065s latency). Not shown: 999 closed tcp ports (reset) PORT STATE SERVICE VERSION 53/tcp open domain dnsmasq 2.51 | dns-nsid: |_ bind.version: dnsmasq-2.51 No exact OS matches for host (If you know what OS is running on it, see https://nmap.org/submit/ ). TCP/IP fingerprint: OS:SCAN(V=7.92%E=4%D=6/4%OT=53%CT=1%CU=35611%PV=Y%DS=2%DC=T%G=Y%TM=629ACC98 OS:%P=x86_64-pc-linux-gnu)SEQ(SP=103%GCD=1%ISR=10C%TI=Z%CI=Z%II=I%TS=A)OPS( OS:O1=M5B4ST11NW9%O2=M5B4ST11NW9%O3=M5B4NNT11NW9%O4=M5B4ST11NW9%O5=M5B4ST11 OS:NW9%O6=M5B4ST11)WIN(W1=FFFF%W2=FFFF%W3=FFFF%W4=FFFF%W5=FFFF%W6=FFFF)ECN( OS:R=Y%DF=Y%T=40%W=FFFF%O=M5B4NNSNW9%CC=Y%Q=)T1(R=Y%DF=Y%T=40%S=O%A=S+%F=AS OS:%RD=0%Q=)T2(R=N)T3(R=N)T4(R=Y%DF=Y%T=40%W=0%S=A%A=Z%F=R%O=%RD=0%Q=)T5(R= OS:Y%DF=Y%T=40%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=)T6(R=Y%DF=Y%T=40%W=0%S=A%A=Z%F= OS:R%O=%RD=0%Q=)T7(R=Y%DF=Y%T=40%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=)U1(R=Y%DF=N%T OS:=40%IPL=164%UN=0%RIPL=G%RID=G%RIPCK=G%RUCK=3EAE%RUD=G)IE(R=Y%DFI=N%T=40% OS:CD=S)
Network Distance: 2 hops
TRACEROUTE (using port 587/tcp) HOP RTT ADDRESS - Hop 1 is the same as for 192.168.43.44 27.82 ms 192.168.43.1
OS and Service detection performed. Please report any incorrect results at https://nmap.org/submit/ . Nmap done: 3 IP addresses (2 hosts up) scanned in 30.29 seconds
这里检测出了192.168.43.44的操作系统
1
Service Info: OS: Windows; CPE: cpe:/o:microsoft:windows
但是没有检测出192.168.43.1的操作系统
1
No exact OS matches for host (If you know what OS is running on it, see https://nmap.org/submit/ ).
┌──(root㉿Executor)-[/home/kali/mydir] └─# masscan -p1-65535 --rate=10000 192.168.43.44 Starting masscan 1.3.2 (http://bit.ly/14GZzcT) at 2022-06-04 03:22:19 GMT Initiating SYN Stealth Scan Scanning 1 hosts [65535 ports/host] Discovered open port 135/tcp on 192.168.43.44 Discovered open port 49664/tcp on 192.168.43.44 Discovered open port 49672/tcp on 192.168.43.44 Discovered open port 49666/tcp on 192.168.43.44 Discovered open port 54260/tcp on 192.168.43.44 Discovered open port 9955/tcp on 192.168.43.44 Discovered open port 902/tcp on 192.168.43.44 Discovered open port 445/tcp on 192.168.43.44 Discovered open port 49667/tcp on 192.168.43.44 Discovered open port 5040/tcp on 192.168.43.44 Discovered open port 49665/tcp on 192.168.43.44 Discovered open port 912/tcp on 192.168.43.44 Discovered open port 49669/tcp on 192.168.43.44 Discovered open port 139/tcp on 192.168.43.44 rate: 0.00-kpps, 100.00% done, waiting 4-secs, found=14
┌──(root㉿Executor)-[/home/kali] └─# nmap -sP 192.168.3.0/24 Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-04 16:22 CST Nmap scan report for 192.168.3.1 Host is up (0.0027s latency). Nmap scan report for host.docker.internal (192.168.3.2) Host is up (0.00026s latency). Nmap scan report for 192.168.3.7 Host is up (0.0060s latency). Nmap done: 256 IP addresses (3 hosts up) scanned in 5.14 seconds
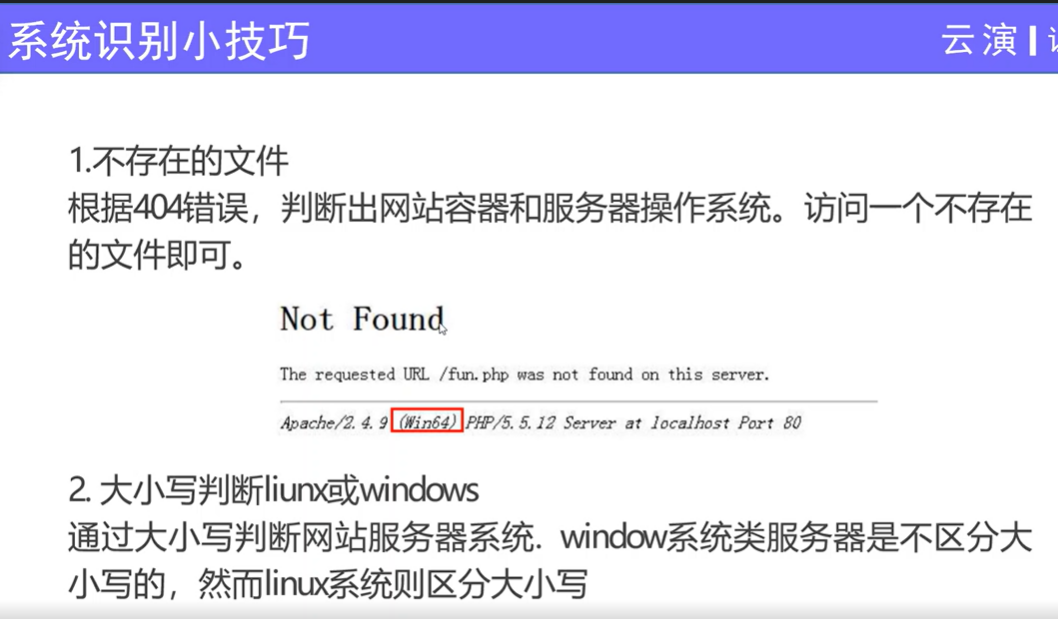
┌──(root㉿Executor)-[/home/kali] └─# nmap -O -A 192.168.43.44 Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-04 19:28 CST Nmap scan report for Executor (192.168.43.44) Host is up (0.00023s latency). Not shown: 994 closed tcp ports (reset) PORT STATE SERVICE VERSION 80/tcp open http Apache httpd 2.4.39 ((Win64) OpenSSL/1.1.1b mod_fcgid/2.3.9a mod_log_rotate/1.02) |_http-title: Site doesn't have a title (text/html; charset=UTF-8). |_http-server-header: Apache/2.4.39 (Win64) OpenSSL/1.1.1b mod_fcgid/2.3.9a mod_log_rotate/1.02 135/tcp open msrpc Microsoft Windows RPC 139/tcp open netbios-ssn Microsoft Windows netbios-ssn 445/tcp open microsoft-ds? 902/tcp open ssl/vmware-auth VMware Authentication Daemon 1.10 (Uses VNC, SOAP) 912/tcp open vmware-auth VMware Authentication Daemon 1.0 (Uses VNC, SOAP) No exact OS matches for host (If you know what OS is running on it, see https://nmap.org/submit/ ). TCP/IP fingerprint: ...
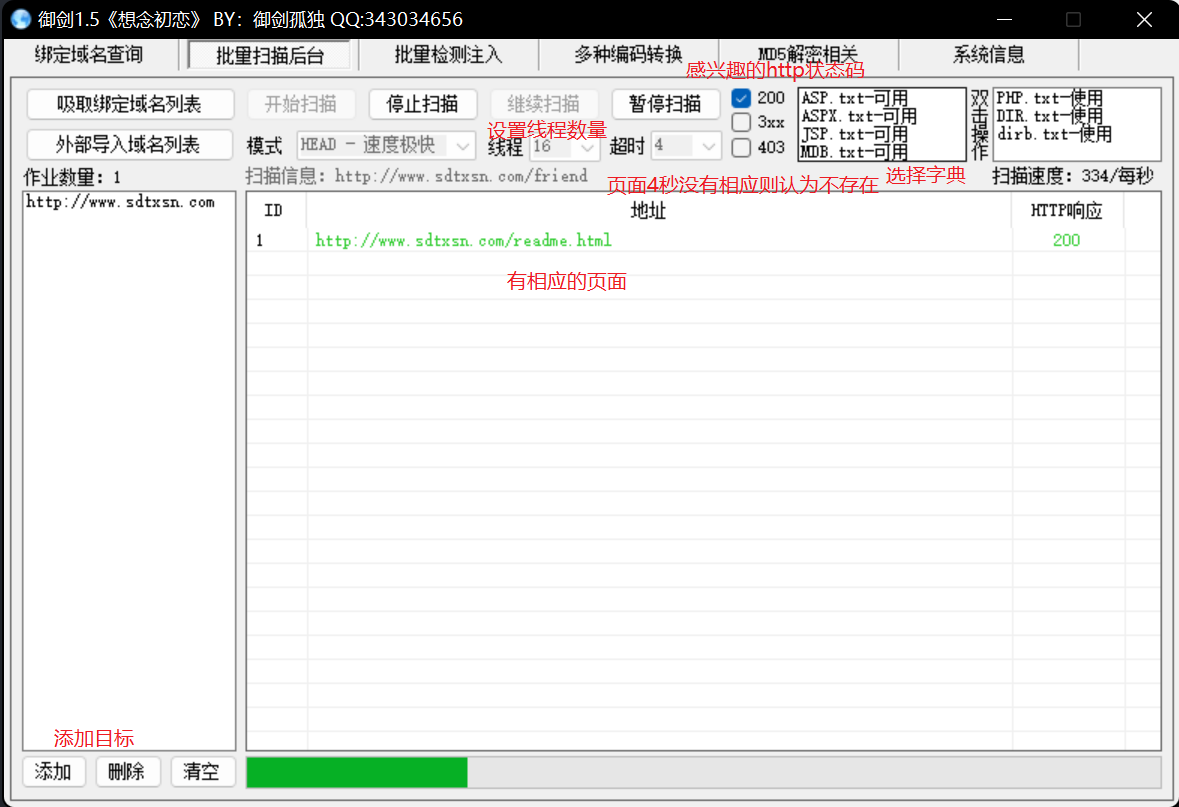
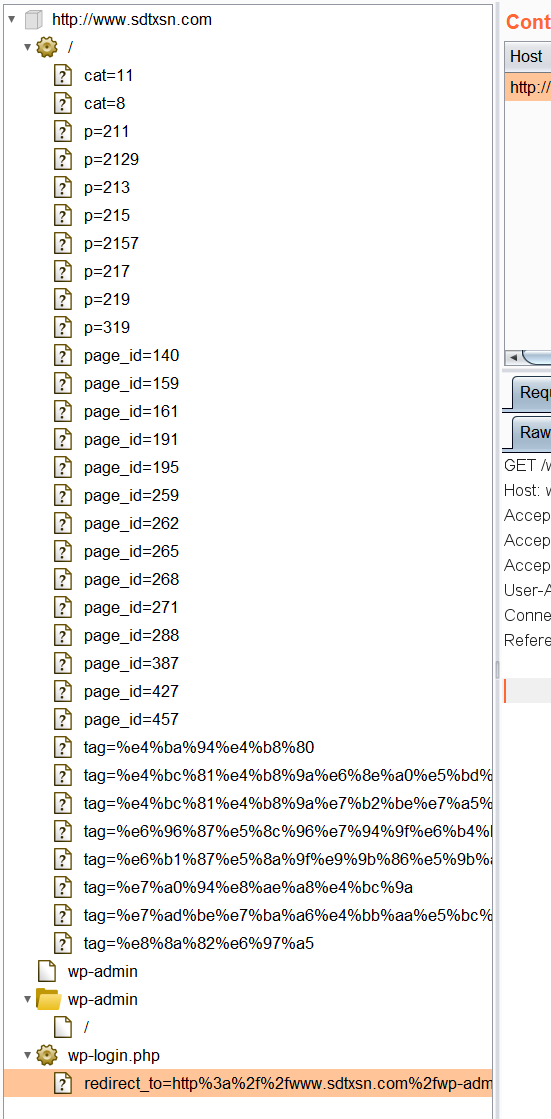
<Usage>: D:\web安全\twoScan\wwwscan.exe <HostName|Ip> [Options] <Options>: -p port : set http/https port -m thread : set max thread -t timeout : tcp timeout in seconds -r rootpath : set root path to scan -ssl : will use ssl <Example>: D:\web安全\twoScan\wwwscan.exe www.target.com -p8080-m10-t16 D:\web安全\twoScan\wwwscan.exe www.target.com -r"/test/"-p80 D:\web安全\twoScan\wwwscan.exe www.target.com -ssl
-p指定目标端口
-m指定线程数
-t指定超时
-r指定次级目录,不写则为根目录
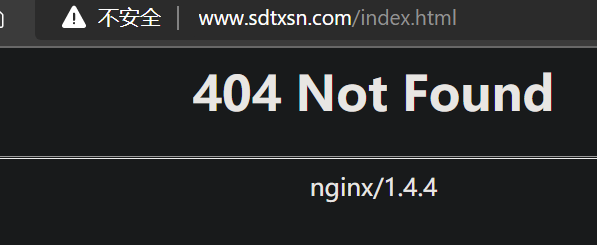
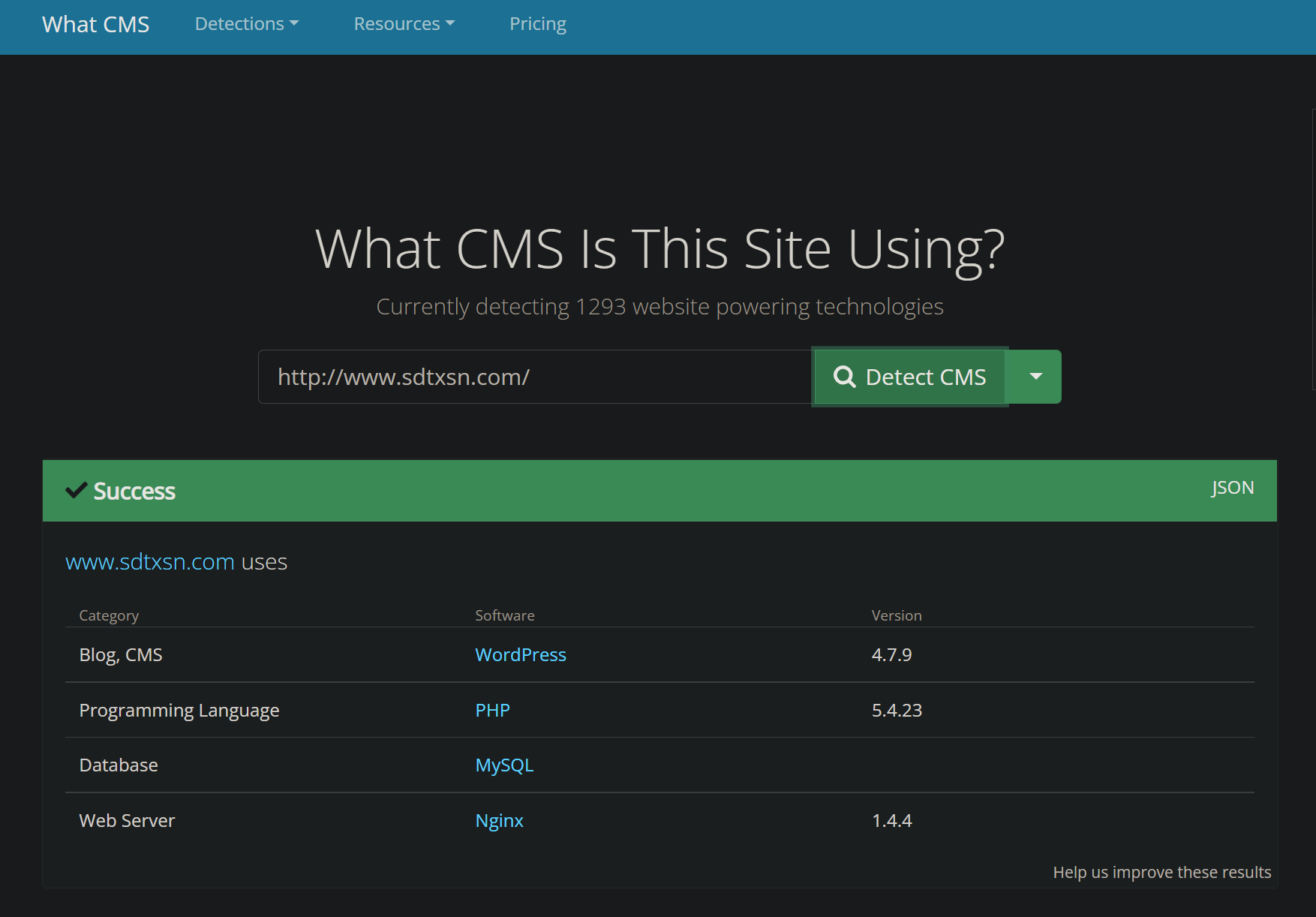
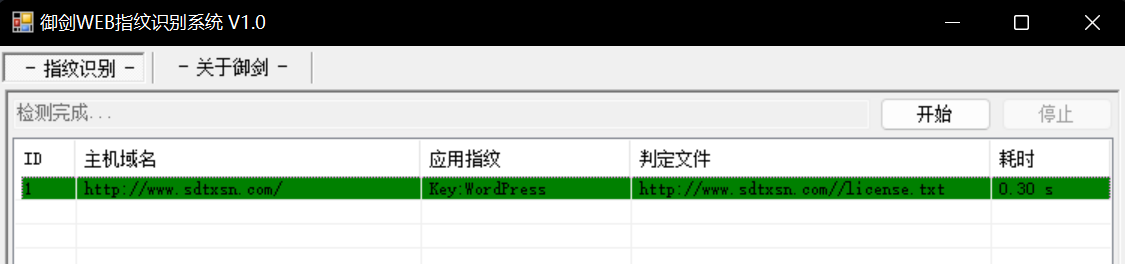
首先使用nmap扫描端口,看看目标的web服务器是不是在80端口开放
1 2 3 4 5 6 7 8 9 10 11 12 13
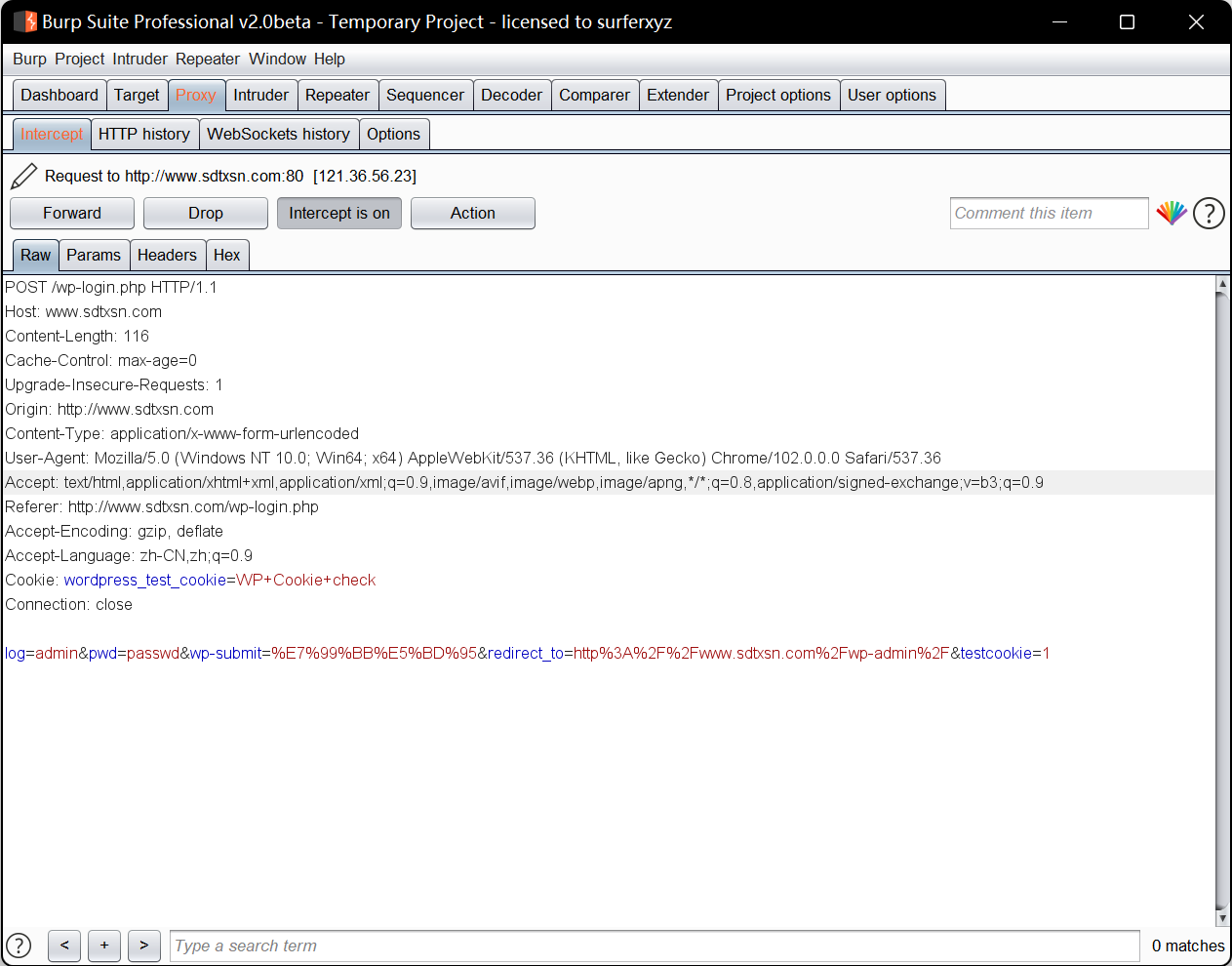
PS C:\Users\86135> nmap www.sdtxsn.com Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-0420:08 中国标准时间 Nmap scan report for www.sdtxsn.com (121.36.56.23) Host is up (0.046s latency). rDNS record for121.36.56.23: ecs-121-36-56-23.compute.hwclouds-dns.com Not shown: 966 filtered tcp ports (no-response), 28 closed tcp ports (reset) PORT STATE SERVICE 22/tcp open ssh 80/tcp open http 1024/tcp open kdm 3306/tcp open mysql 3690/tcp open svn 8888/tcp open sun-answerbook
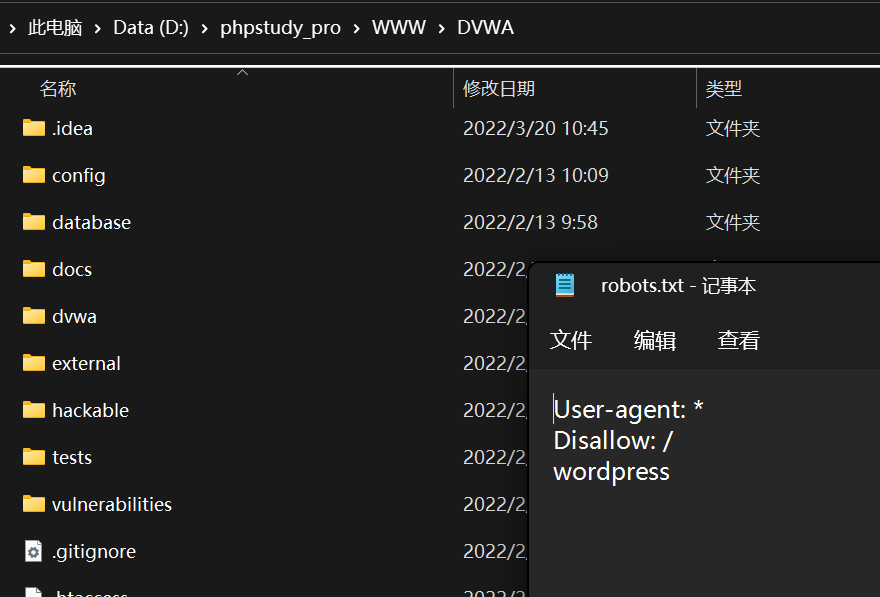
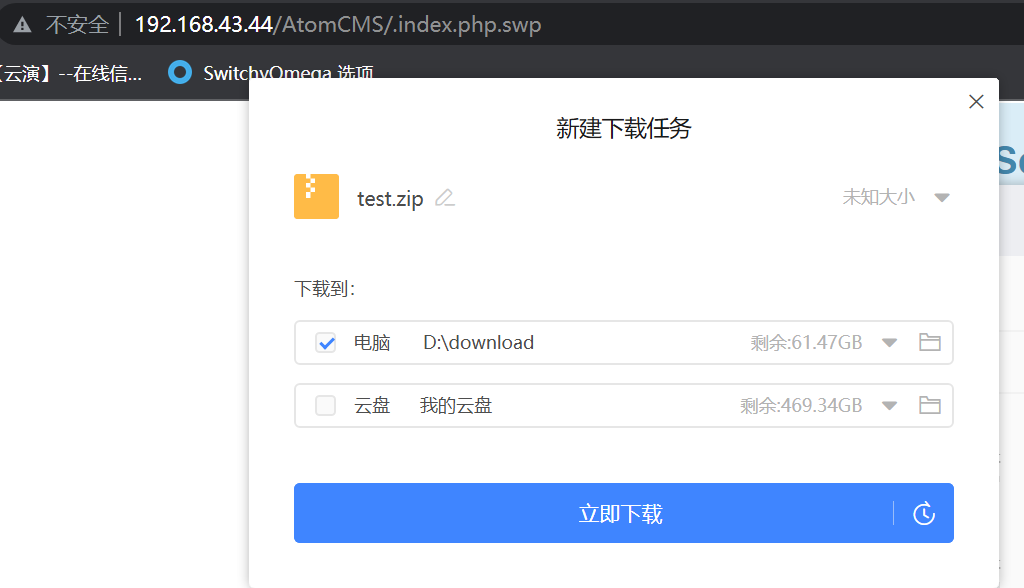
┌──(kali㉿Executor)-[/mnt/d/phpstudy_pro/www/atomcms] └─$ ls -a -l total 36 drwxrwxrwx 1 kali kali 4096 Jun 4 21:18 . drwxrwxrwx 1 kali kali 4096 Apr 26 20:53 .. ... -rwxrwxrwx 1 kali kali 176 Oct 22 2015 index.php -rwxrwxrwx 1 kali kali 4096 Jun 4 21:18 .index.php.swo -rwxrwxrwx 1 kali kali 4096 Jun 4 21:18 .index.php.swp ...
______ / \ ( W00f! ) \ ____/ ,, __ 404 Hack Not Found |`-.__ / / __ __ /" _/ /_/ \ \ / / *===* / \ \_/ / 405 Not Allowed / )__// \ / /| / /---` 403 Forbidden \\/` \ | / _ \ `\ /_\\_ 502 Bad Gateway / / \ \ 500 Internal Error `_____``-` /_/ \_\ ~ WAFW00F : v2.1.0 ~ The Web Application Firewall Fingerprinting Toolkit [*] Checking http://www.sdtxsn.com/ [+] Generic Detection results: [-] No WAF detected by the generic detection [~] Number of requests: 7
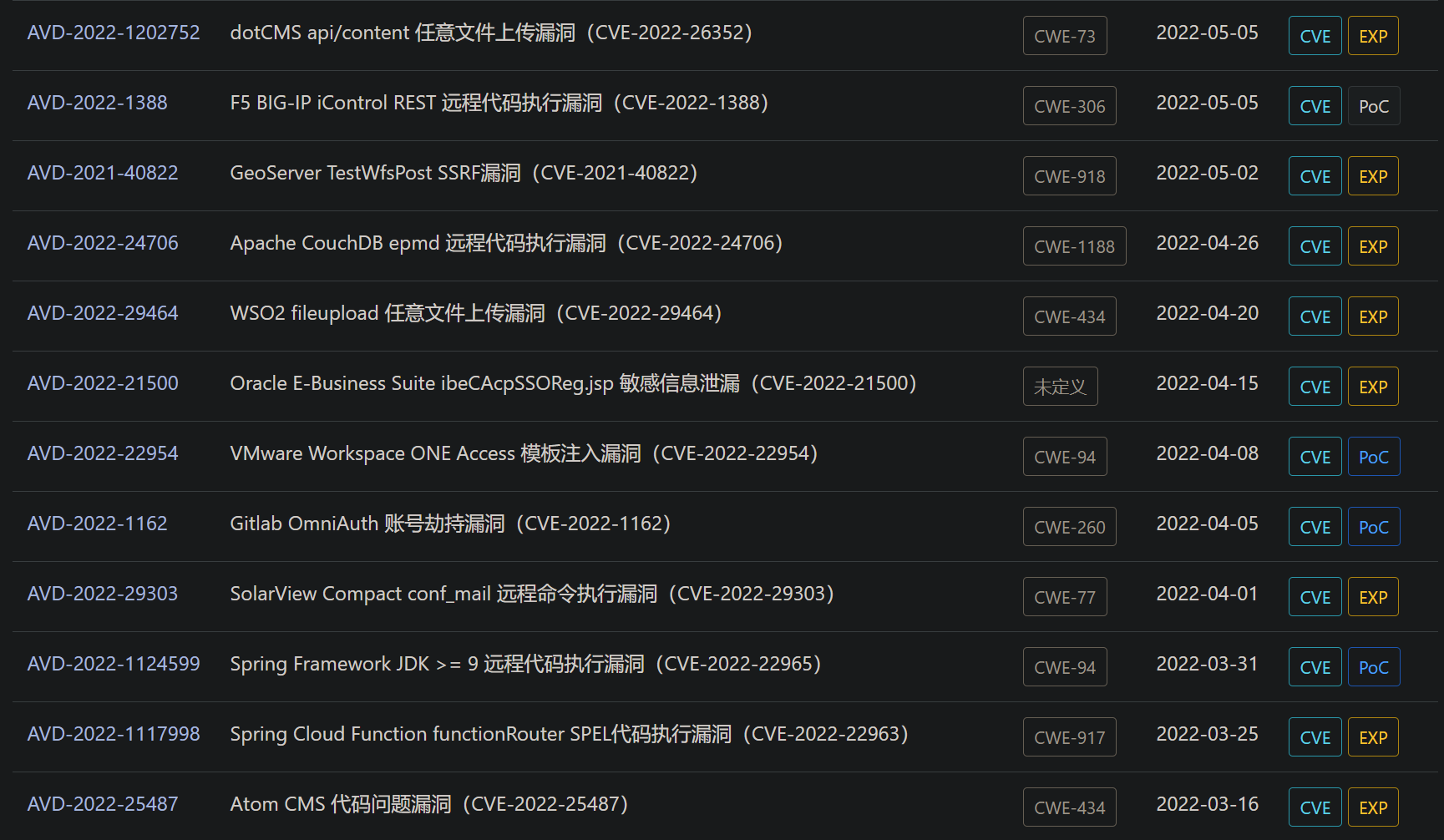
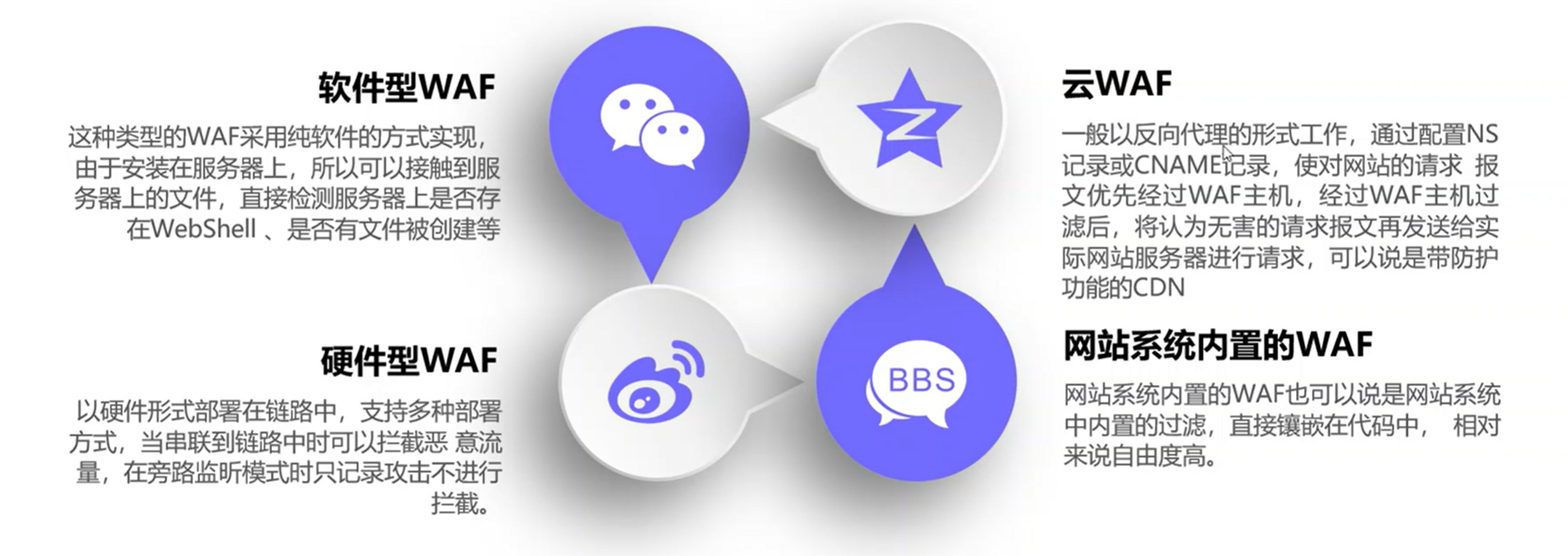
wafw00f没有检测出waf
nmap
测试waf是否存在
1
nmap <目标域名> --script=http-waf-detect.nse
1 2 3 4 5 6 7 8 9 10 11
┌──(root㉿Executor)-[/home/kali] └─# nmap www.sdtxsn.com --script=http-waf-detect.nse -p 80 Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-05 09:33 CST Nmap scan report for www.sdtxsn.com (121.36.56.23) Host is up (0.044s latency). rDNS record for 121.36.56.23: ecs-121-36-56-23.compute.hwclouds-dns.com
PORT STATE SERVICE 80/tcp open http
Nmap done: 1 IP address (1 host up) scanned in 2.29 seconds
这里就没有检测到waf存在
拿学校官网试一下
1 2 3 4 5 6 7 8 9 10 11 12
┌──(root㉿Executor)-[/home/kali] └─# nmap ehall.xidian.edu.cn --script=http-waf-detect.nse -p 80 Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-05 09:34 CST Nmap scan report for ehall.xidian.edu.cn (61.150.43.100) Host is up (0.022s latency).
PORT STATE SERVICE 80/tcp open http | http-waf-detect: IDS/IPS/WAF detected: |_ehall.xidian.edu.cn:80/?p4yl04d3=<script>alert(document.cookie)</script>
Nmap done: 1 IP address (1 host up) scanned in 9.34 seconds
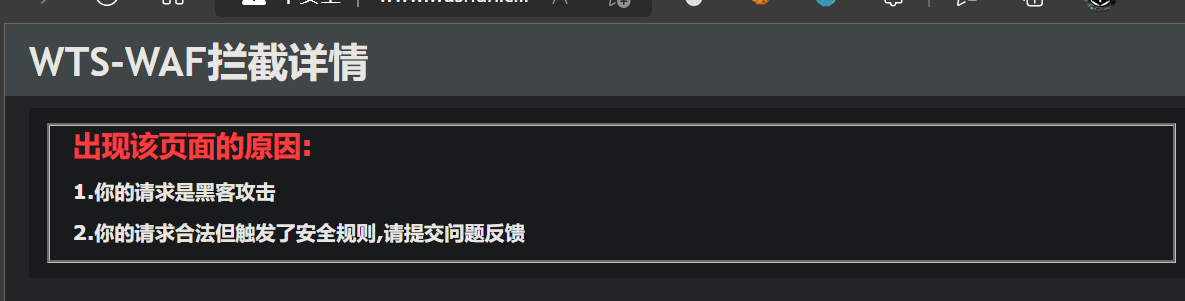
发现是有防火墙存在的,检测方法是在主页上构造xss攻击负载,结果被拦截
判断waf指纹
1
nmap <目标域名> --script=http-waf-fingerprint
1 2 3 4 5 6 7 8 9 10 11
┌──(root㉿Executor)-[/home/kali] └─# nmap ehall.xidian.edu.cn --script=http-waf-fingerprint -p 80,443 Starting Nmap 7.92 ( https://nmap.org ) at 2022-06-05 09:37 CST Nmap scan report for ehall.xidian.edu.cn (61.150.43.100) Host is up (0.027s latency).
PORT STATE SERVICE 80/tcp open http 443/tcp open https
Nmap done: 1 IP address (1 host up) scanned in 6.28 seconds
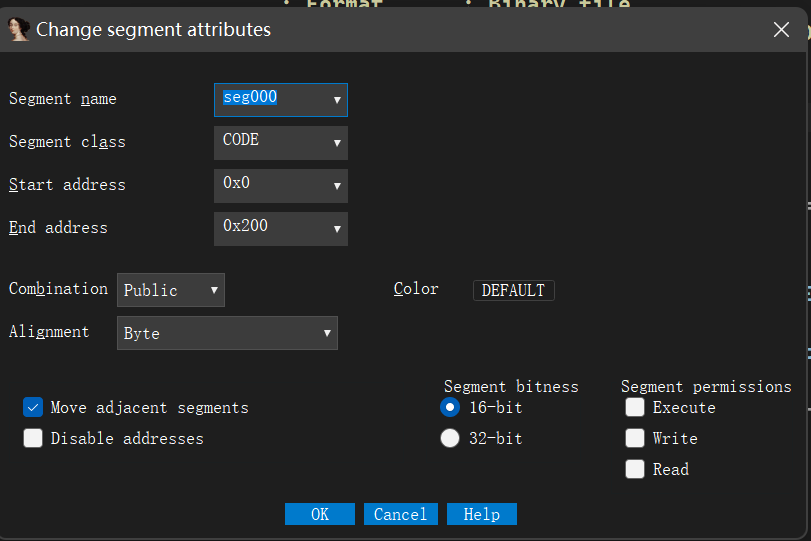
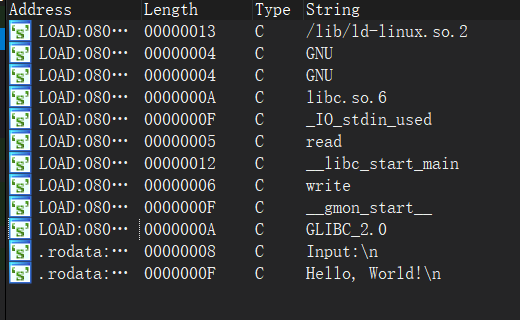
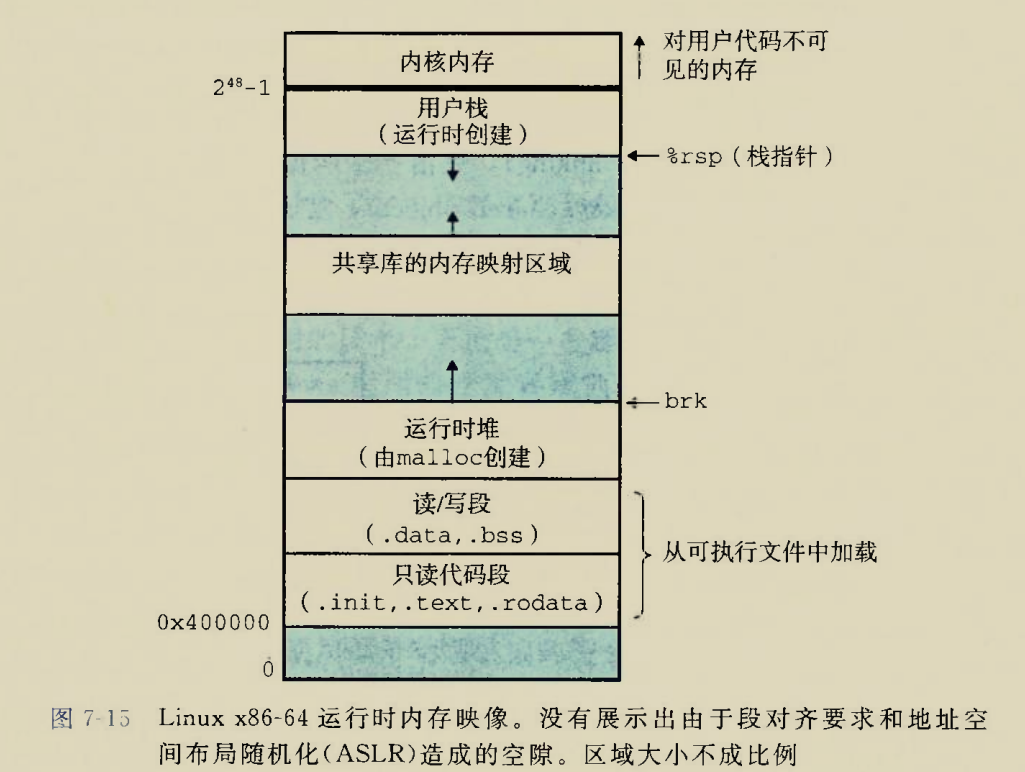
-0000000000000010 -0000000000000010 db ? ; undefined ;后面开出的这一些是为了栈16字节对齐 -000000000000000F db ? ; undefined -000000000000000E db ? ; undefined -000000000000000D db ? ; undefined -000000000000000C db ? ; undefined -000000000000000B db ? ; undefined -000000000000000A db ? ; undefined -0000000000000009 db ? ; undefined -0000000000000008 db ? ; undefined -0000000000000007 db ? ; undefined -0000000000000006 db ? ; undefined -0000000000000005 db ? ; undefined -0000000000000004 db ? ; undefined -0000000000000003 s db 2 dup(?) -0000000000000001 a db ? +0000000000000000 s db 8 dup(?) +0000000000000008 r db 8 dup(?) +0000000000000010 +0000000000000010 ; end of stack variables
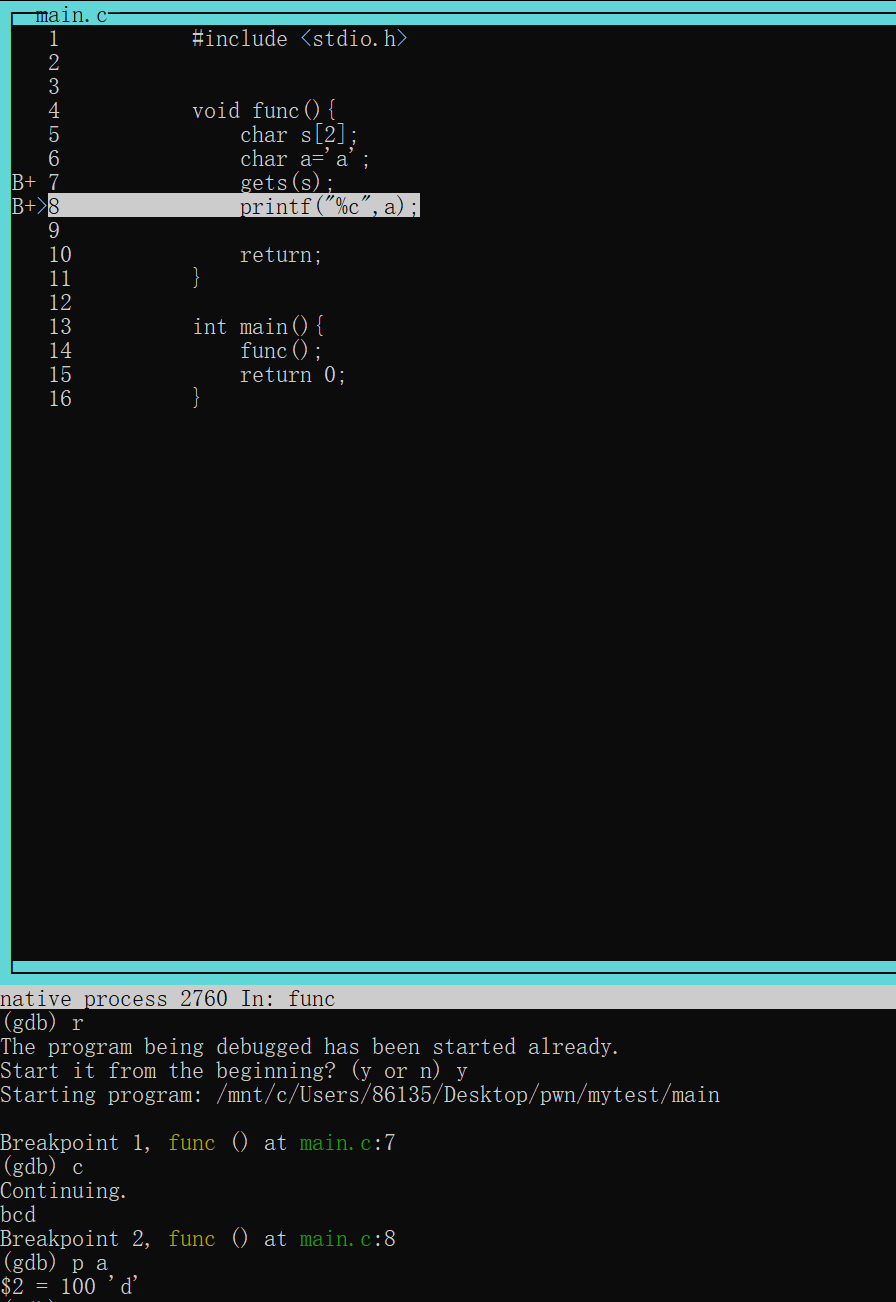
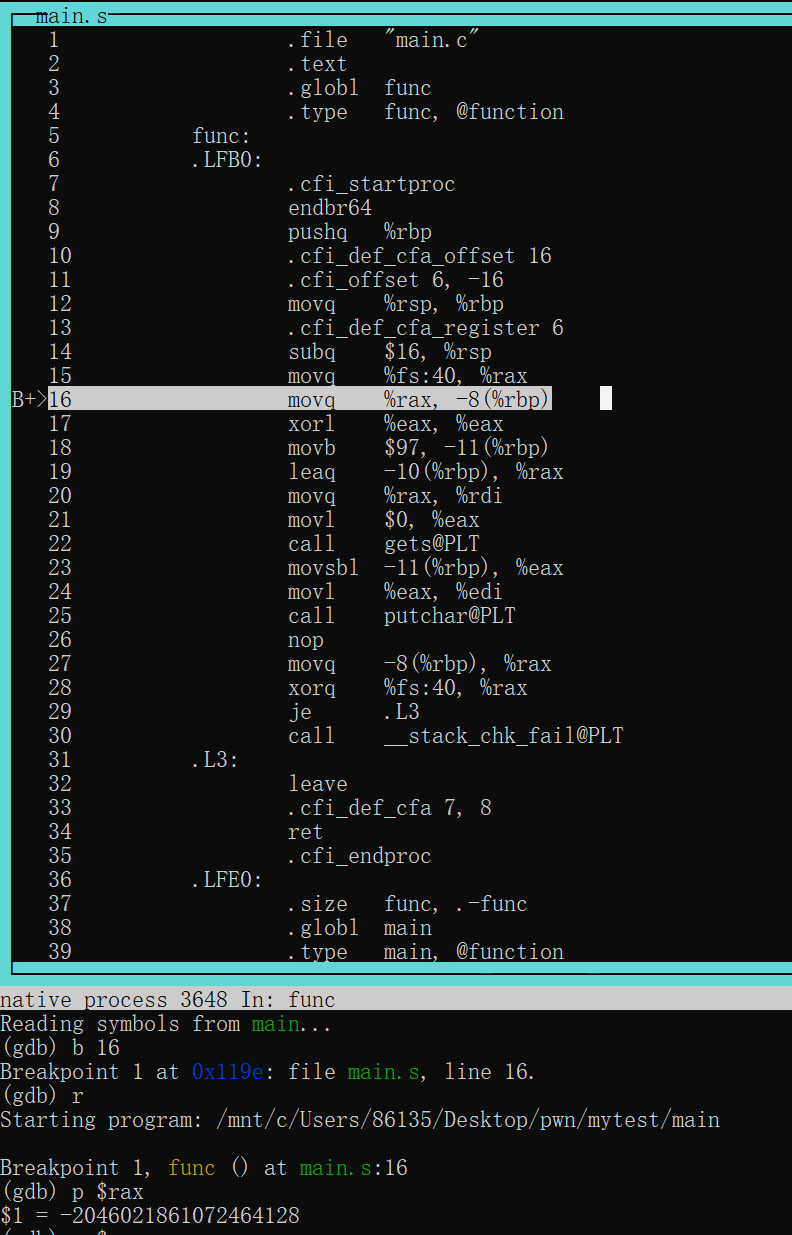
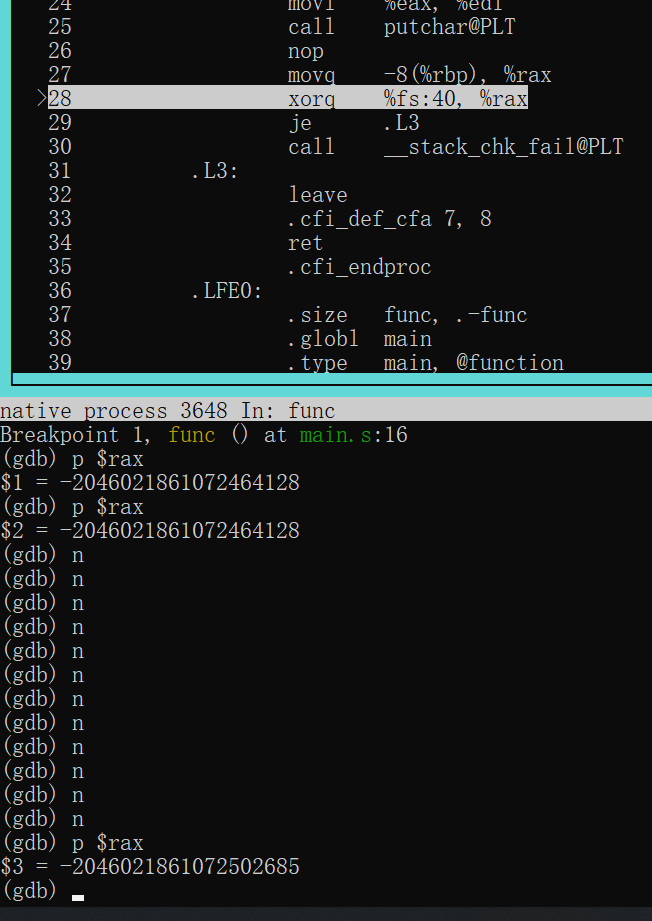
root@Executor:/mnt/c/Users/86135/Desktop/pwn/level0# checksec --file=level0 RELRO STACK CANARY NX PIE RPATH RUNPATH Symbols FORTIFY Fortified Fortifiable FILE No RELRO No canary found NX enabled No PIE No RPATH No RUNPATH 69 Symbols No 0 1 level0
-0000000000000080 buf db 128 dup(?) +0000000000000000 s db 8 dup(?) +0000000000000008 r db 8 dup(?) +0000000000000010 +0000000000000010 ; end of stack variables
[+] Opening connection to 111.200.241.244 on port 58761: Done [*] Switching to interactive mode Hello, World $ ls bin dev flag level0 lib lib32 lib64 $ cat flag cyberpeace{8efeda8a14caa49a15f88847757ca2d0} $
┌──(kali㉿Executor)-[/mnt/c/Users/86135/Desktop/pwn/level2] └─$ python3 exp.py [+] Opening connection to 111.200.241.244 on port 53153: Done [*] Switching to interactive mode Input: $ ls bin dev flag level2 lib lib32 lib64 $ cat flag cyberpeace{37be55c2ba683c43f9410e5e7400e59d}
003guess_num(栈缓冲区溢出改变随机数种子)
1 2 3 4 5 6 7
PS C:\Users\86135\Desktop\pwn\guess_num> checksec guess_num [*] 'C:\\Users\\86135\\Desktop\\pwn\\guess_num\\guess_num' Arch: amd64-64-little RELRO: Partial RELRO Stack: Canary found NX: NX enabled PIE: PIE enabled
-00000018 db ? ; undefined -00000017 db ? ; undefined -00000016 db ? ; undefined -00000015 db ? ; undefined -00000014 dest db 11 dup(?) -00000009 var_9 db ? -00000008 db ? ; undefined -00000007 db ? ; undefined -00000006 db ? ; undefined -00000005 db ? ; undefined -00000004 db ? ; undefined -00000003 db ? ; undefined -00000002 db ? ; undefined -00000001 db ? ; undefined +00000000 s db 4 dup(?) +00000004 r db 4 dup(?) +00000008 s dd ? ; offset +0000000C +0000000C ; end of stack variables
[*] Switching to interactive mode \xc0o\xf7Input: $ ls bin dev flag level3 lib lib32 lib64 $ cat flag cyberpeace{93ceadf23838a0fd793719d215b9876e}
007get_shell(白给)
1 2 3 4 5
┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/pwn/get_shell] └─# ./get_shell OK,this time we will get a shell. # ls get_shell Ponce.cfg
运行即可得到shell
为啥还是7分的题?
008CGfsb(printf格式化字符串漏洞)
printf格式化字符串漏洞,总之就是特别绕
1 2 3 4 5 6 7
PS C:\Users\86135\Desktop\pwn\CGfsb> checksec cgfsb [*] 'C:\\Users\\86135\\Desktop\\pwn\\CGfsb\\cgfsb' Arch: i386-32-little RELRO: Partial RELRO Stack: Canary found ;金丝雀保护,栈溢出困难 NX: NX enabled PIE: No PIE (0x8048000)
信息收集:
1 2 3 4 5 6 7 8 9 10
┌──(kali㉿Executor)-[/mnt/c/Users/86135/Desktop/pwn/CGfsb] └─$ ./cgfsb please tell me your name: 123 leave your message please: 456 hello 123 your message is: 456 Thank you!
.bss:0000000000601068 unk_601068 db ? ; ; DATA XREF: main+3B↑o .bss:0000000000601069 db ? ; .bss:000000000060106A db ? ; .bss:000000000060106B db ? ; .bss:000000000060106C dword_60106C dd ? ; DATA XREF: main+4A↑r
setbuf(stdout, 0LL); alarm(0x3Cu); sub_400996(); v4 = malloc(8uLL); *v4 = 68; v4[1] = 85; puts("we are wizard, we will give you hand, you can not defeat dragon by yourself ..."); puts("we will tell you two secret ..."); printf("secret[0] is %x\n", v4); //&v4的16进制表示 printf("secret[1] is %x\n", v4 + 1); //&v4+1的16进制表示,由于开启栈地址随机化,因此该值每次运行不定 puts("do not tell anyone "); sub_400D72((__int64)v4); //游戏剧情 puts("The End.....Really?"); return0LL; }
v2 = __readfsqword(0x28u); puts(" This is a famous but quite unusual inn. The air is fresh and the"); ... puts("So, where you will go?east or up?:"); while ( 1 ) { _isoc99_scanf("%s", s1); if ( !strcmp(s1, "east") || !strcmp(s1, "east") )//蜜汁操作,两个判断都是strcmp(s1,"east"),当s1为east时跳出循环 break; //当s1!=east一直循环请求输入 puts("hei! I'm secious!"); puts("So, where you will go?:"); } if ( strcmp(s1, "east") ) //蜜汁操作,出了刚才的循环则s1=east,这里的if条件判断一定不会成立,为什么还要设计这么一条路呢? { if ( !strcmp(s1, "up") ) sub_4009DD(); //屑函数,死路 puts("YOU KNOW WHAT YOU DO?"); exit(0); } return __readfsqword(0x28u) ^ v2; }
v4 = __readfsqword(0x28u);//从fs段偏移0x28=40字节读取一个四字 v2 = 0LL; puts("You travel a short distance east.That's odd, anyone disappear suddenly"); puts(", what happend?! You just travel , and find another hole"); puts("You recall, a big black hole will suckk you into it! Know what should you do?"); puts("go into there(1), or leave(0)?:"); _isoc99_scanf("%d", &v1); if ( v1 == 1 ) { puts("A voice heard in your mind"); puts("'Give me an address'"); _isoc99_scanf("%ld", &v2); puts("And, you wish is:"); _isoc99_scanf("%s", format); puts("Your wish is"); printf(format); //此处存在格式化字符串漏洞 puts("I hear it, I hear it...."); } return __readfsqword(0x28u) ^ v4; }
Your wish is AAAAAAAA-0x7f6645ea9743-(nil)-0x7f6645dc8603-0xd-0xffffffffffffff88-0x100000000-0x270f-0x4141414141414141-0x252d70252d70252d-0x2d70252d70252d70-0x70252d70252d7025-0x252d70252d70252d-0x70252d70252d70I hear it, I hear it....
第n个格式化参数
不是格式化参数
1
2
3
4
5
6
7
8
打印内容
AAAAAAAA
0x7f6645ea9743
(nil)
0x7f6645dc8603
0xd
0xffffffffffffff88
0x100000000
0x270f
0x4141414141414141
意义
9999,刚才输入的v2
格式化字符串本身作为一个普通字符串的起始位置
可以判断,输入的v2将会被作为第7个格式化字符串参数
然后我们在前面的交互过程中获取到v4的地址,在give me an address之后输入,作为第七个格式化字符串参数
0x1ccb2a0 .... Your wish is AAAAAAAA-0x7f5c06c84743-(nil)-0x7f5c06ba3603-0xd-0xffffffffffffff88-0x100000000-0x1ccb2a0-0x4141414141414141-0x252d70252d70252d-0x2d70252d70252d70-0x70252d70252d7025-0x252d70252d70252d-0x70252d70252d70I hear it, I hear it....
v3 = __readfsqword(0x28u); puts("Ahu!!!!!!!!!!!!!!!!A Dragon has appeared!!"); puts("Dragon say: HaHa! you were supposed to have a normal"); puts("RPG game, but I have changed it! you have no weapon and "); puts("skill! you could not defeat me !"); puts("That's sound terrible! you meet final boss!but you level is ONE!"); if ( *a1 == a1[1] ) //当a1[0]==a1[1]时就有巫师出手相助,否则嗝屁 { puts("Wizard: I will help you! USE YOU SPELL"); v1 = mmap(0LL, 0x1000uLL, 7, 33, -1, 0LL);//没有和文件描述符关联,则不把任何文件映射到进程的虚拟地址空间 read(0, v1, 0x100uLL); //从标准输入0即键盘读取至多0x100个字符,到v1缓冲区 ((void (__fastcall *)(_QWORD))v1)(0LL); //一个函数指针,但是v1明明是一个虚拟地址空间的指针,强行作为函数指针 } return __readfsqword(0x28u) ^ v3; }
mmap
1
void *mmap(void *start , size_t length, int prot, int flags, int fd, off_t offset);
┌──(root㉿Executor)-[/mnt/c/Users/86135/desktop/pthread] └─# gcc main.c -o main
┌──(root㉿Executor)-[/mnt/c/Users/86135/desktop/pthread] └─# ./main in main,tid=139945163630400 in func,tid=139945163630400
每次运行,tid都是不同的数值,但是main和func两个函数中打印的tid都是相同的
因为func不是新线程执行的,它仍然是main线程执行的.
创建线程pthread_create
pthread.h
1 2 3 4 5 6 7 8
/* Create a new thread, starting with execution of START-ROUTINE getting passed ARG. Creation attributed come from ATTR. The new handle is stored in *NEWTHREAD. */ externintpthread_create( pthread_t *__restrict __newthread, __const pthread_attr_t *__restrict __attr, void *(*__start_routine) (void *), void *__restrict __arg)//到此函数参数表已经结束,后面是Function Attributes修饰 __THROW __nonnull((1, 3));
创建一个新线程,从START_ROUTINE函数,带着ARG参数
开始执行.
线程函数的参数只能有一个,是一个
以参数ATTR为线程属性
新的线程句柄以参数NEWTHREAD返回
如果创建新线程成功则函数返回0,否则返回数字代表错误原因
关于参数的__restrict修饰符
__restrict
Like the __declspec ( restrict
) modifier, the __restrict
keyword (two leading underscores '_') indicates that a symbol isn't
aliased in the current scope
causes the compiler to check that, in calls to
my_memcpy, arguments dest and src are non-null. If the
compiler determines that a null pointer is passed in an argument slot
marked as non-null, and the -Wnonnull option is enabled, a warning is
issued. The compiler may also choose to make optimizations based on the
knowledge that certain function arguments will not be null.
The nothrow attribute is used to inform the compiler
that a function cannot throw an exception. For example, most functions
in the standard C library can be guaranteed not to throw an exception
with the notable exceptions of qsort and
bsearch that take function pointer arguments. The
nothrow attribute is not implemented in GCC versions
earlier than 3.3.
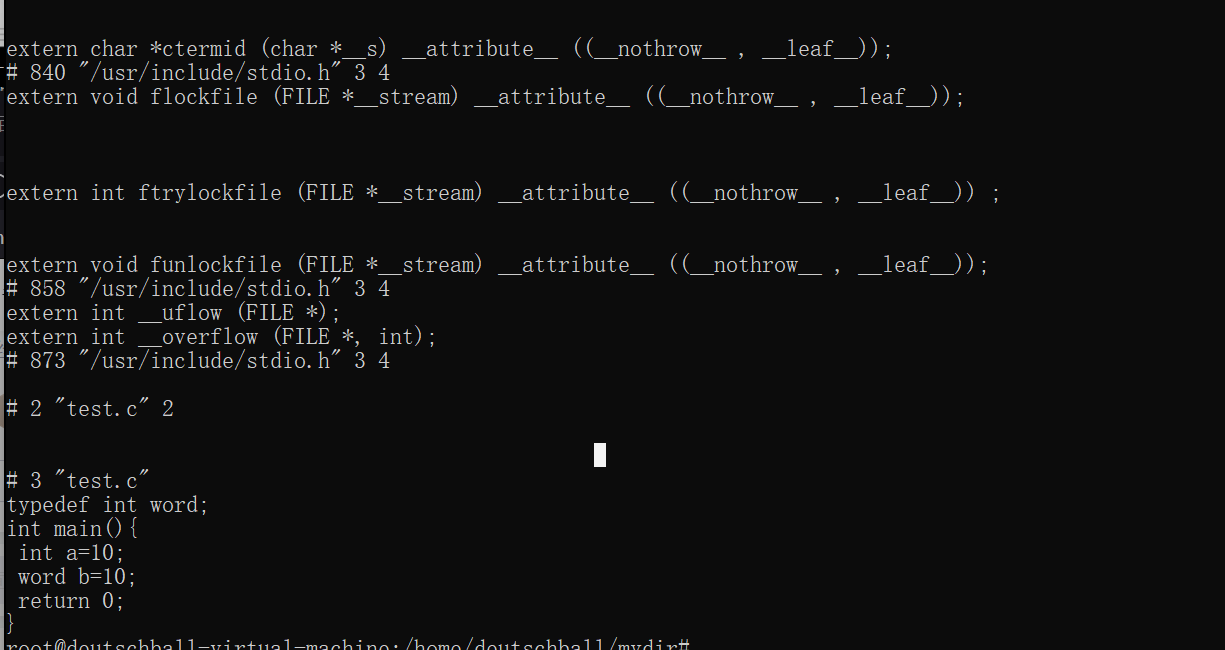
nothrow属性用来通知编译器,函数不会抛出异常
比如,C标准库中的大多数函数都保证不会抛出qsort和bsearch使用函数指针作为参数的错误;
在GCC3.3之前没有该属性
1
leaf
Calls to external functions with this attribute must return to the
current compilation unit only by return or by exception handling. In
particular, leaf functions are not allowed to call callback function
passed to it from the current compilation unit or directly call
functions exported by the unit or longjmp into the unit. Leaf function
might still call functions from other compilation units and thus they
are not necessarily leaf in the sense that they contain no function
calls at all.
The attribute is intended for library functions to improve dataflow
analysis. The compiler takes the hint that any data not escaping the
current compilation unit can not be used or modified by the leaf
function. For example, the sin function is a leaf function,
but qsort is not.
Note that leaf functions might invoke signals and signal handlers
might be defined in the current compilation unit and use static
variables. The only compliant way to write such a signal handler is to
declare such variables volatile.
The attribute has no effect on functions defined within the current
compilation unit. This is to allow easy merging of multiple compilation
units into one, for example, by using the link time optimization. For
this reason the attribute is not allowed on types to annotate indirect
calls.
┌──(root㉿Executor)-[/mnt/c/Users/86135/desktop/pthread] └─# gcc main.c -o main -lpthread
┌──(root㉿Executor)-[/mnt/c/Users/86135/desktop/pthread] └─# ./main in main,tid1=140685510317888 in main,tid2=140685510313536 in func,tid=140685510313536
/* Terminate calling thread. The registered cleanup handlers are called via exception handling so we cannot mark this function with __THROW.*/ externvoidpthread_exit(void *__retval) __attribute__((__noreturn__));
终止线程
清理程序以异常处理进行,因此我们不能将该函数标记为__THROW
返回值通过指针参数void *__retval传递
杀死对等线程pthread_cancel
1 2
/* Cancel THREAD immediately or at the next possibility. */ externintpthread_cancel(pthread_t __th);
/* Make calling thread wait for termination of the thread TH. The exit status of the thread is stored in *THREAD_RETURN, if THREAD_RETURN is not NULL. This function is a cancellation point and therefore not marked with __THROW. */ externintpthread_join(pthread_t __th, void **__thread_return);
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/pthread] └─$ ./main thread 140127873893952 created in func,tid=140127873893952 thread 140127873893952 joined thread 140127873893952 created main exit
/* Indicate that the thread TH is never to be joined with PTHREAD_JOIN. The resources of TH will therefore be freed immediately when it terminates, instead of waiting for another thread to perform PTHREAD_JOIN on it. */ externintpthread_detach(pthread_t __th) __THROW;
pthread_detach函数表明,TH线程将永远不会"加入"调用线程
因此当TH线程结束时,其资源将会被立刻回收,而不必再等待被对等线程调用pthread_join回收
初始化线程pthread_once
1 2 3 4 5 6 7 8 9 10
/* Guarantee that the initialization function INIT_ROUTINE will be called only once, even if pthread_once is executed several times with the same ONCE_CONTROL argument. ONCE_CONTROL must point to a static or extern variable initialized to PTHREAD_ONCE_INIT. The initialization functions might throw exception which is why this function is not marked with __THROW. */ externintpthread_once(pthread_once_t *__once_control, void (*__init_routine) (void)) __nonnull((1, 2));
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/pthread] └─$ gcc -O0 main.c -o main -lpthread
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/pthread] └─$ ./main in main,tid=140195300874048,&global=0x558b84485048 in func,tid=140195300869696,&global=0x558b84485048,&local_in_func=0x7f81c31b7e48,&static_in_func=0x558b8448504c in func,tid=140195292476992,&global=0x558b84485048,&local_in_func=0x7f81c29b6e48,&static_in_func=0x558b8448504c tid=140195300869696 exit tid=140195292476992 exit
/* Initialize semaphore object SEM to VALUE. If PSHARED then share it with other processes. */ externintsem_init(sem_t *__sem, int __pshared, unsignedint __value) __THROW;
信号量以指针sem_t *__sem传参,
int __pshared总是0,
unsigend int __value表示信号量的初始值(最大值)
PV操作sem_wait&sem_post
1 2 3 4 5 6 7
/* Wait for SEM being posted. This function is a cancellation point and therefore not marked with __THROW. */ externintsem_wait(sem_t *__sem); /* Post SEM. */ externintsem_post(sem_t *__sem) __THROW;
typedefstruct{ int *buf; int n; int front; int rear; }Queue; //普通队列,不同步 voidqueue_init(Queue*,int);//初始化一个队列 voidqueue_destroy(Queue*); intempty(Queue*); intfull(Queue*); voidpush(Queue*,int); intpop(Queue*); intlength(Queue*);
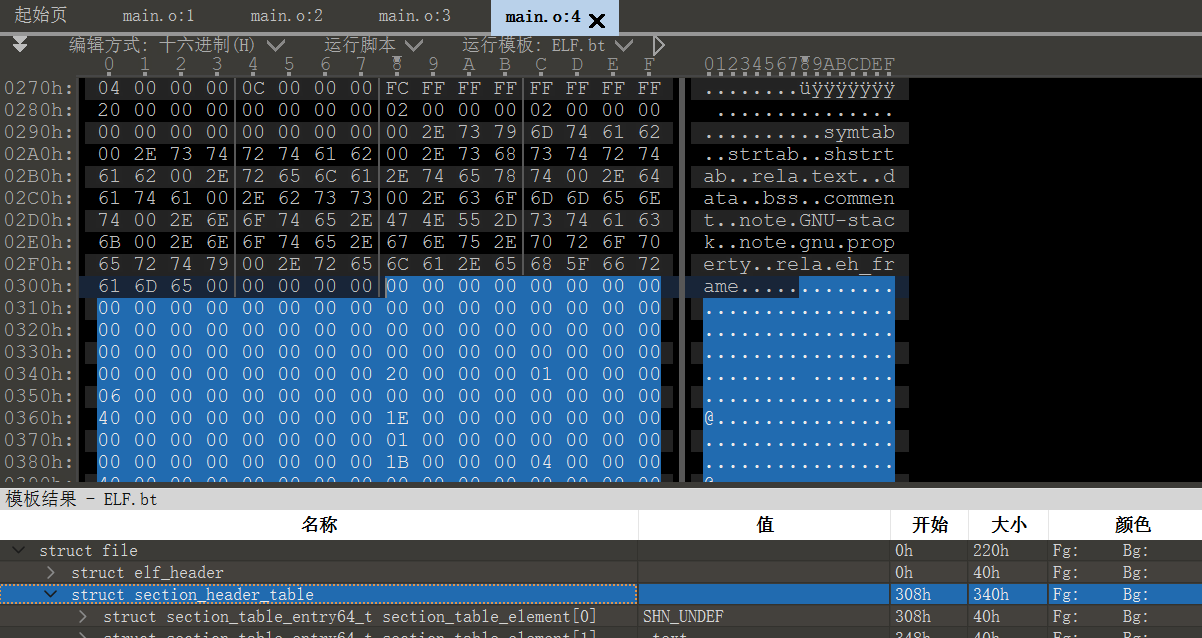
Relocation section '.rela.text' at offset 0x2f0 contains 2 entries: Offset Info Type Sym. Value Sym. Name + Addend 000000000016 000700000002 R_X86_64_PC32 0000000000000000 .rodata - 4 000000000020 001100000004 R_X86_64_PLT32 0000000000000000 printf - 4
Relocation section '.rela.eh_frame' at offset 0x320 contains 1 entry: Offset Info Type Sym. Value Sym. Name + Addend 000000000020 000200000002 R_X86_64_PC32 0000000000000000 .text + 0
Symbol table '.symtab' contains 18 entries: Num: Value Size Type Bind Vis Ndx Name 0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND 1: 0000000000000000 0 FILE LOCAL DEFAULT ABS main.c 2: 0000000000000000 0 SECTION LOCAL DEFAULT 1 3: 0000000000000000 0 SECTION LOCAL DEFAULT 3 4: 0000000000000000 0 SECTION LOCAL DEFAULT 4 5: 0000000000000004 4 OBJECT LOCAL DEFAULT 3 c 6: 0000000000000000 4 OBJECT LOCAL DEFAULT 4 d 7: 0000000000000000 0 SECTION LOCAL DEFAULT 5 8: 0000000000000008 4 OBJECT LOCAL DEFAULT 3 f.2320 9: 0000000000000000 0 SECTION LOCAL DEFAULT 7 10: 0000000000000000 0 SECTION LOCAL DEFAULT 8 11: 0000000000000000 0 SECTION LOCAL DEFAULT 9 12: 0000000000000000 0 SECTION LOCAL DEFAULT 6 13: 0000000000000000 4 OBJECT GLOBAL DEFAULT 3 a 14: 0000000000000004 4 OBJECT GLOBAL DEFAULT COM b 15: 0000000000000000 43 FUNC GLOBAL DEFAULT 1 main 16: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND _GLOBAL_OFFSET_TABLE_ 17: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND printf
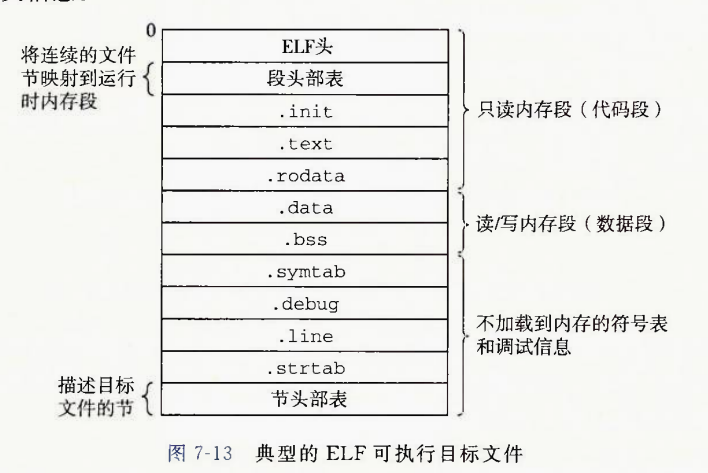
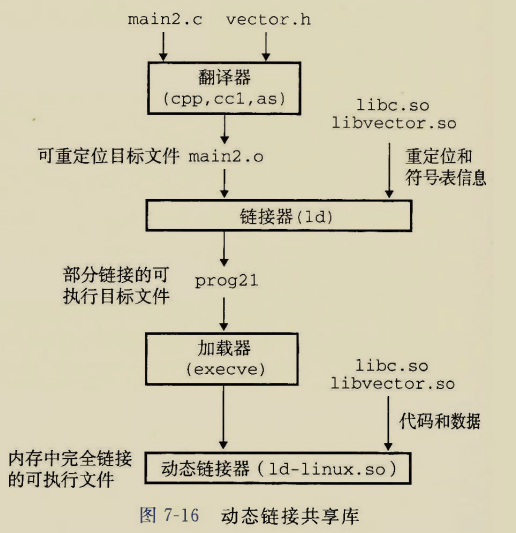
可重定位目标文件的常用节
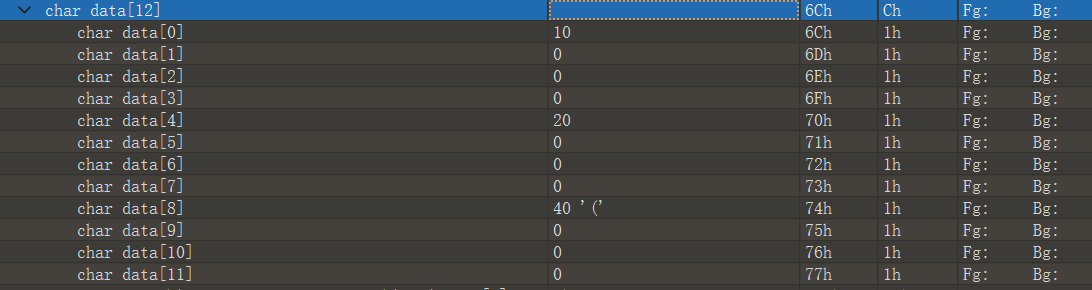
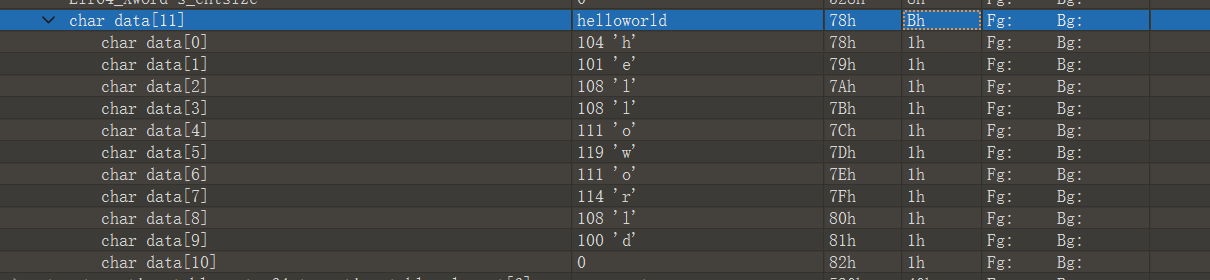
1 2 3 4 5 6 7 8 9 10 11 12
#include<stdio.h> int a=10; int b; staticint c=20; staticint d; intmain(){ int e=30; staticint f=40; printf("helloworld");
Symbol table '.symtab' contains 12 entries: Num: Value Size Type Bind Vis Ndx Name 0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND 1: 0000000000000000 0 FILE LOCAL DEFAULT ABS main.c 2: 0000000000000000 0 SECTION LOCAL DEFAULT 1 3: 0000000000000000 0 SECTION LOCAL DEFAULT 3 4: 0000000000000000 0 SECTION LOCAL DEFAULT 4 5: 0000000000000000 0 SECTION LOCAL DEFAULT 6 6: 0000000000000000 0 SECTION LOCAL DEFAULT 7 7: 0000000000000000 0 SECTION LOCAL DEFAULT 8 8: 0000000000000000 0 SECTION LOCAL DEFAULT 5 9: 0000000000000000 33 FUNC GLOBAL DEFAULT 1 main 10: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND _GLOBAL_OFFSET_TABLE_ 11: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND sum
┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] └─# gcc main.c -c -o main main.c: In function ‘main’: main.c:3:11: warning: implicit declaration of function ‘func’ [-Wimplicit-function-declaration] 3 | int a=func(); | ^~~~
intfunc(){ return510; } intmain(){ int a=func(); return0; }
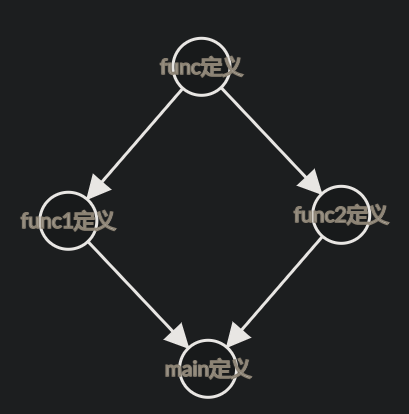
这里不报错的原因是,整个编译链接就涉及到两个模块,并且只有main引用了func,这关系简单明了
可如果这样写呢?
func.h
1 2 3
intfunc(){ return510; }
func1.c
1 2 3 4
#include"func.h" intfunc1(){ return2*func(); }
func2.c
1 2 3 4
#include"func.h" intfunc2(){ return4*func(); }
程序入口这样写:
main.c
1 2 3 4 5 6 7
intfunc1(); intfunc2(); intmain(){ int a=func1(); //要调用func1必然要链接func1.o目标模块 int b=func2(); //要调用func2必然要链接func2.o目标模块 return0; }
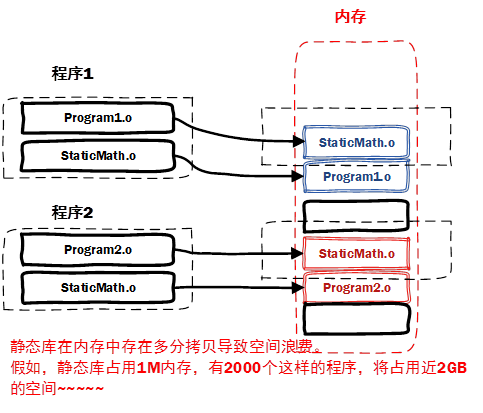
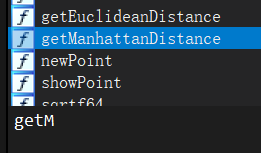
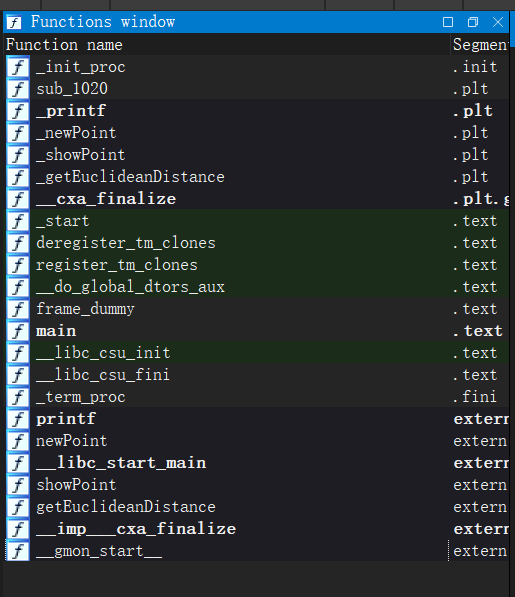
image-20220525202607308
main中相当于有两个func的定义
使用gcc main.c func1.c func2.c -o prog企图编译链接
1 2 3 4 5
┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] └─# gcc main.c func1.c func2.c -o prog /usr/bin/ld: /tmp/ccb95Wtp.o: infunction `func': func2.c:(.text+0x0): multiple definition of `func'; /tmp/ccAEawPN.o:func1.c:(.text+0x0): first defined here collect2: error: ld returned 1 exit status
#include"geometry.h" intmain(){ ... int pi=PI; //试图阔的PI的拷贝 return0; }
结果却报告链接错误了
1 2 3 4 5 6 7
┌──(kali㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] └─$ ./makedynamiclib.sh /usr/bin/ld: /tmp/cc9eI8oy.o:(.rodata+0x0): multiple definition of `PI'; /tmp/cci0ubCp.o:(.rodata+0x0): first defined here collect2: error: ld returned 1 exit status /usr/bin/ld: cannot find ./libgeometry.so: No such file or directory collect2: error: ld returned 1 exit status ./makedynamiclib.sh: line 5: ./prog: No such file or directory
#include<iostream> #define PI 3.14 #define PI 3.142 #define PI 3.1416 #define PI 3.1415926 usingnamespace std; intmain(){ cout << PI; return0; }
运行结果
1
3.14159
但是会报告编译警告
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
testGlobal.c:3: warning: "PI" redefined 3 | #define PI 3.142 | testGlobal.c:2: note: this is the location of the previous definition 2 | #define PI 3.14 | testGlobal.c:4: warning: "PI" redefined 4 | #define PI 3.1416 | testGlobal.c:3: note: this is the location of the previous definition 3 | #define PI 3.142 | testGlobal.c:5: warning: "PI" redefined 5 | #define PI 3.14159 | testGlobal.c:4: note: this is the location of the previous definition 4 | #define PI 3.1416 |
而如果多次宏定义一模一样
1 2 3 4
#define PI 3.14 #define PI 3.14 #define PI 3.14 #define PI 3.14
┌──(kali㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] └─$ ./makedynamiclib.sh /usr/bin/ld: /tmp/ccSIplb4.o: warning: relocation against `PI' in read-only section `.text' /usr/bin/ld: /tmp/ccSIplb4.o: in function `main': main.c:(.text+0xd7): undefined reference to `PI'
┌──(root㉿Executor)-[/mnt/c/Users/86135/Desktop/linkage] └─# ls -l total 4 -rwxrwxrwx 1 kali kali 731 May 25 21:57 geometry.h -rwxrwxrwx 1 kali kali 667 May 25 22:02 line.c -rwxrwxrwx 1 kali kali 285 May 25 21:26 main.c -rwxrwxrwx 1 kali kali 520 May 25 21:57 point.c -rwxrwxrwx 1 kali kali 140 May 25 22:03 shellscript.sh
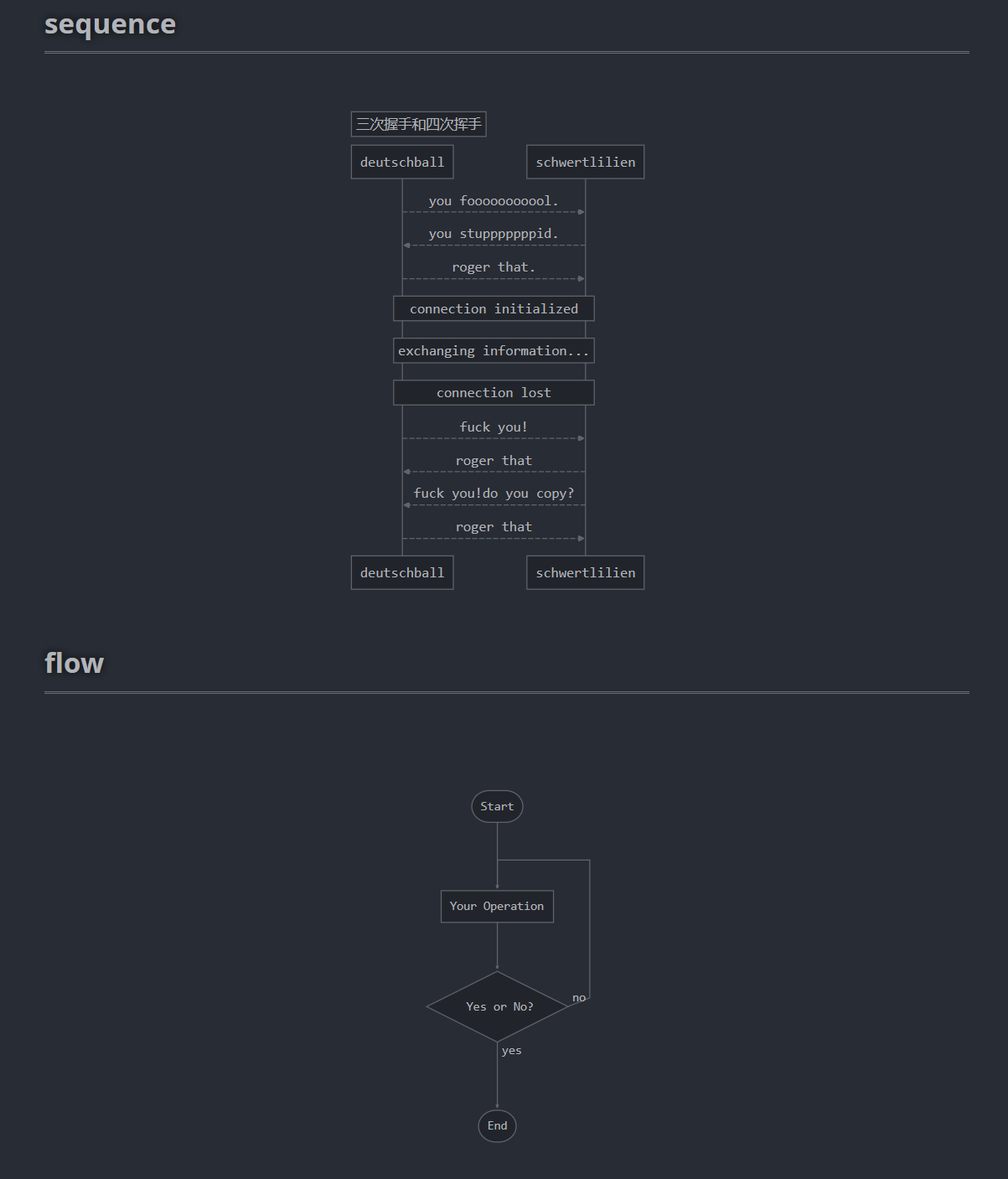
title:三次握手和四次挥手 participant deutschball as d participant schwertlilien as s d-->s:you fooooooooool. s-->d:you stupppppppid. d-->s:roger that. note over d,s:connection initialized note over d,s:exchanging information... note over d,s:connection lost d-->s: fuck you! s-->d: roger that s-->d: fuck you!do you copy? d-->s: roger that
flow
1 2 3 4 5 6 7
st=>start: Start op=>operation: Your Operation cond=>condition: Yes or No? e=>end st->op->cond cond(yes)->e cond(no)->op
mermaid
pie
1 2 3 4 5
pie title 世界人口 "俄国人" : 15 "美国人" : 20 "中国人" : 500
graph
1 2 3 4 5 6
graph TB A[Start] --> B{Is it?}; B -- Yes --> C[OK]; C --> D[Rethink]; D --> B; B -- No ----> E[End];

.jpg/170px-Serial_port_(9-pin).jpg)

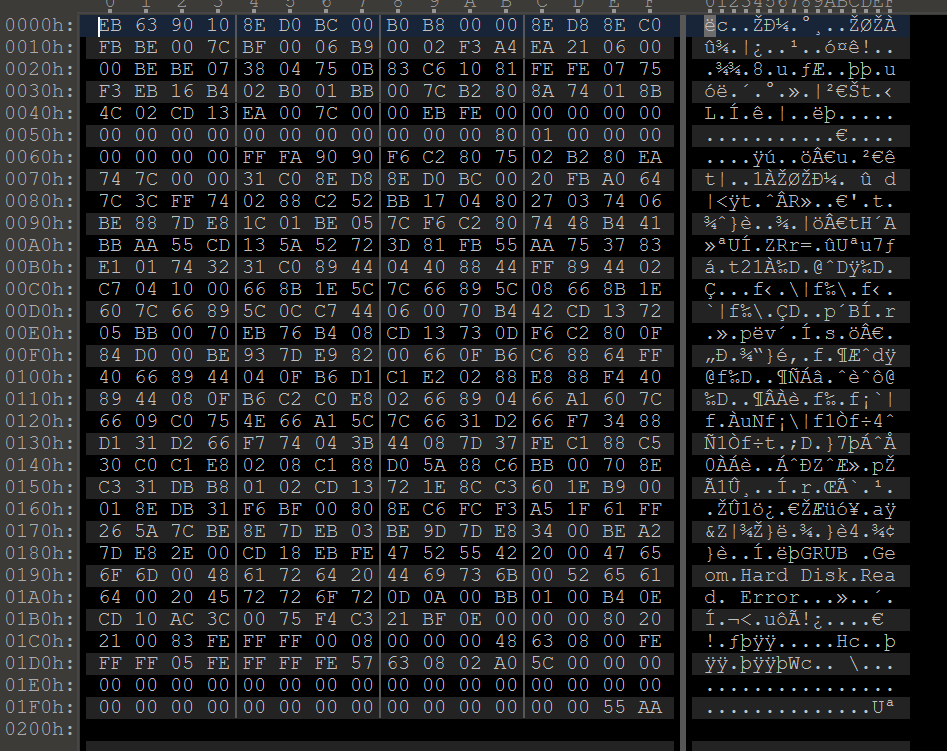
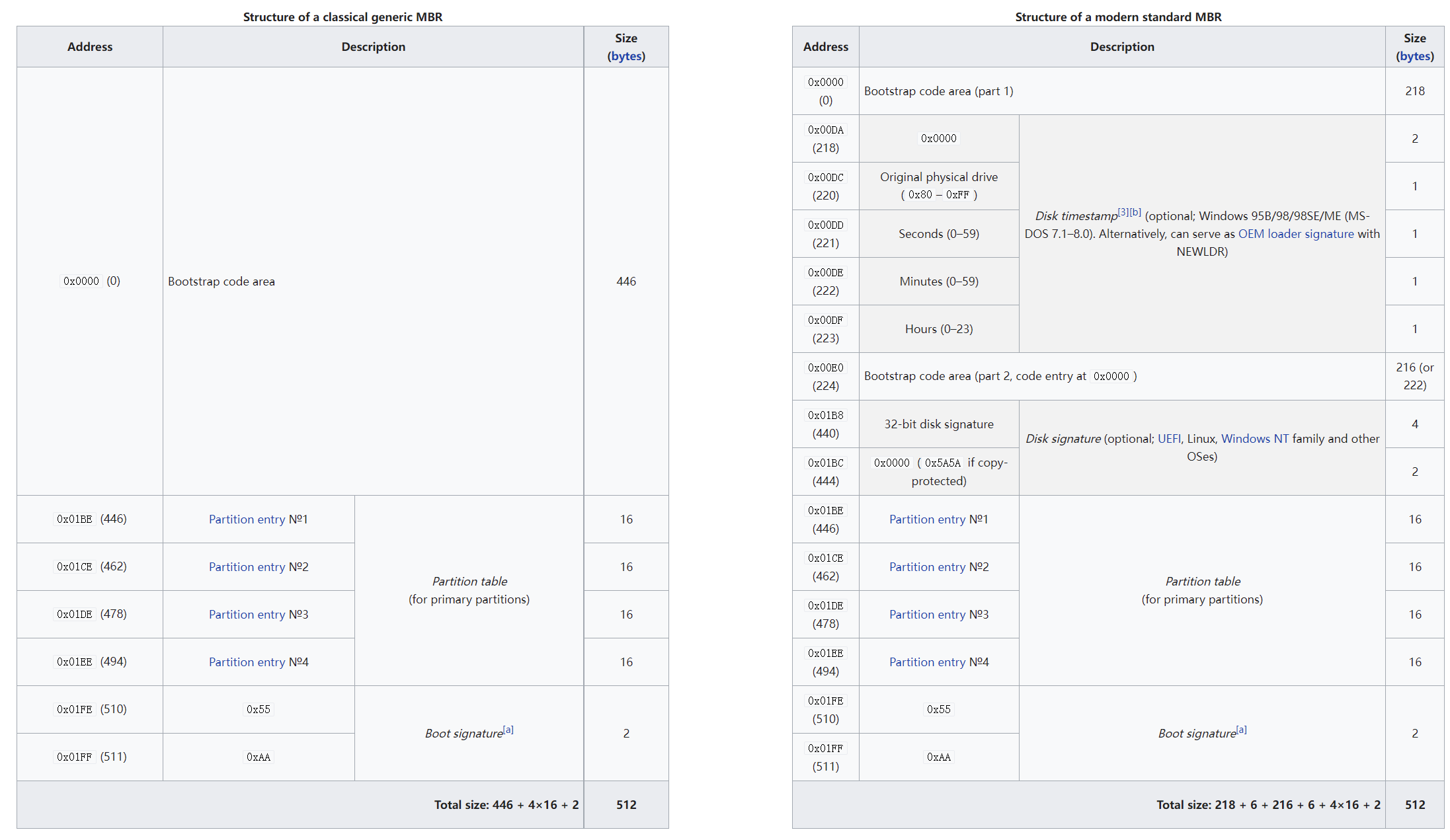 最开始的218个字节就是
最开始的218个字节就是