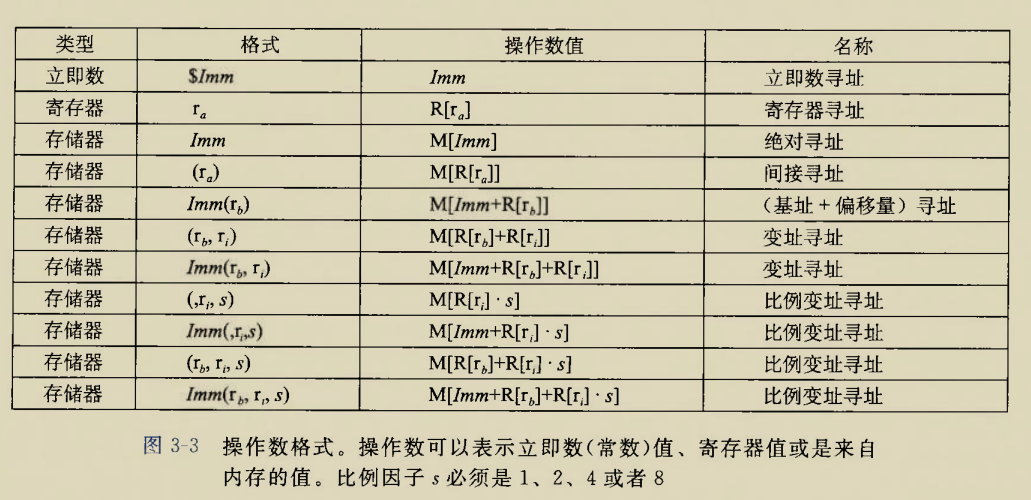
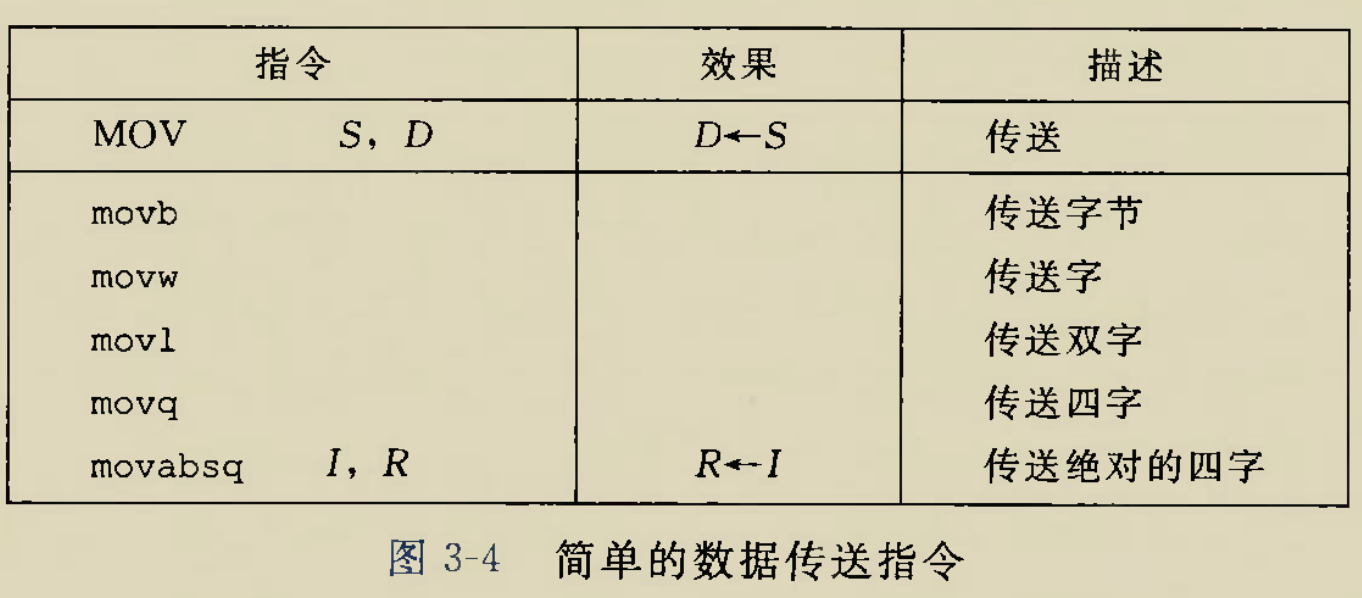
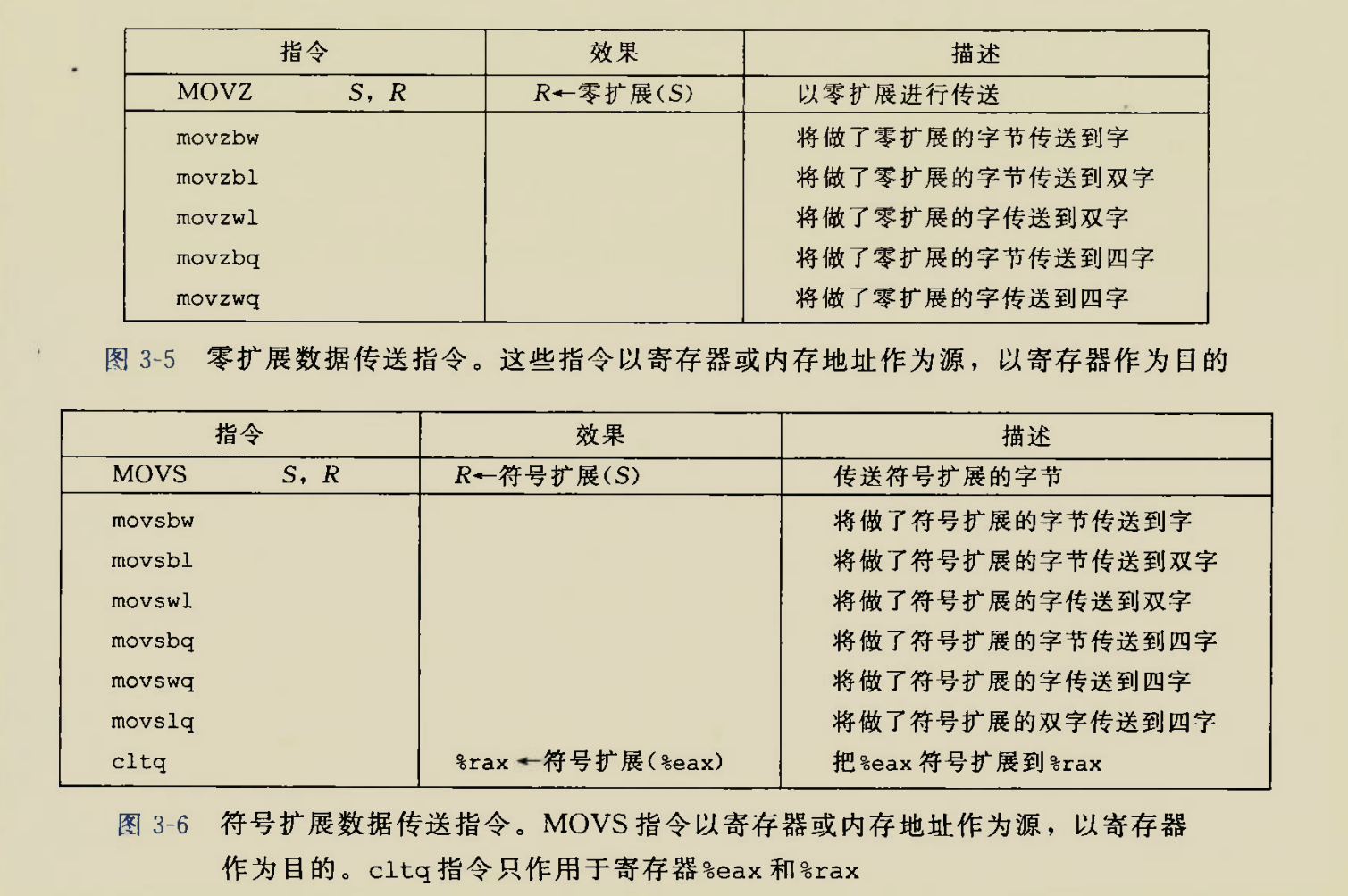
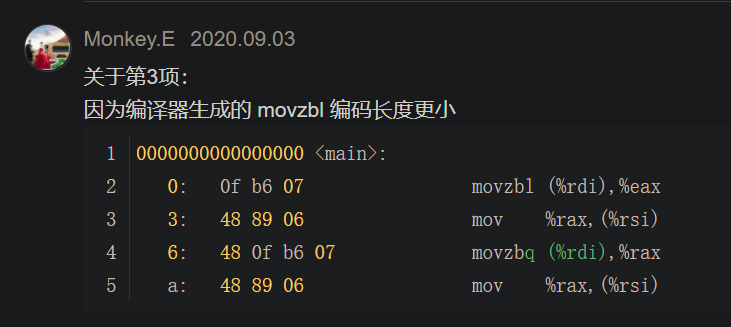
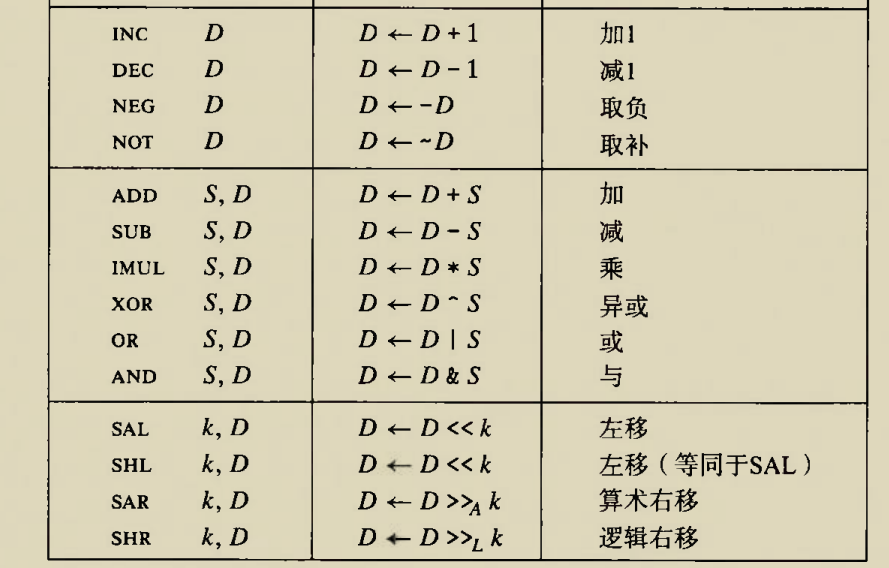
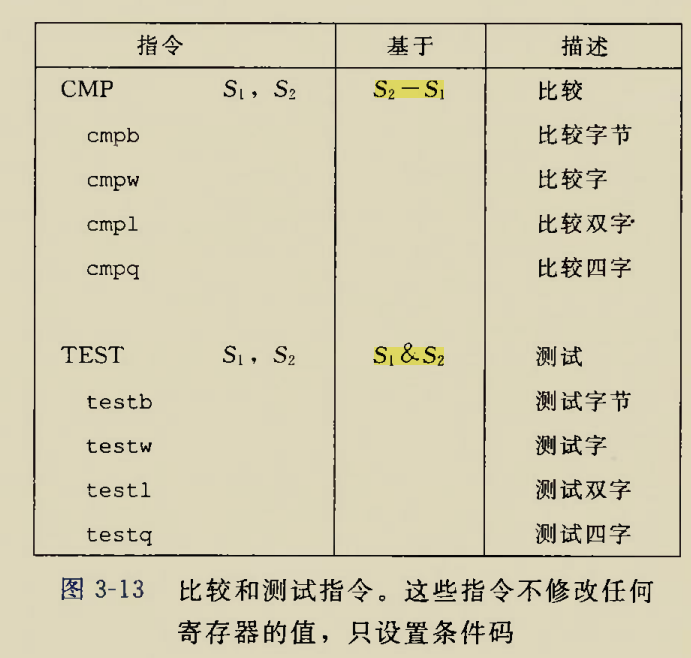
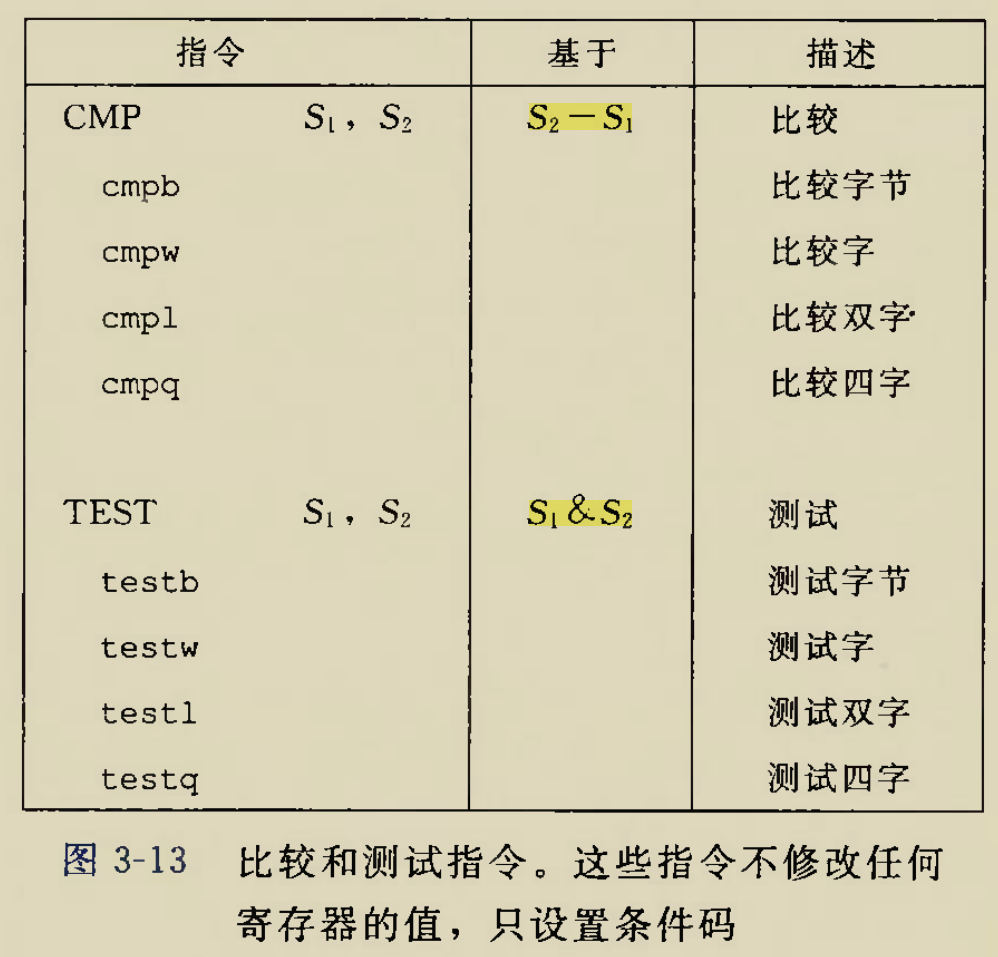
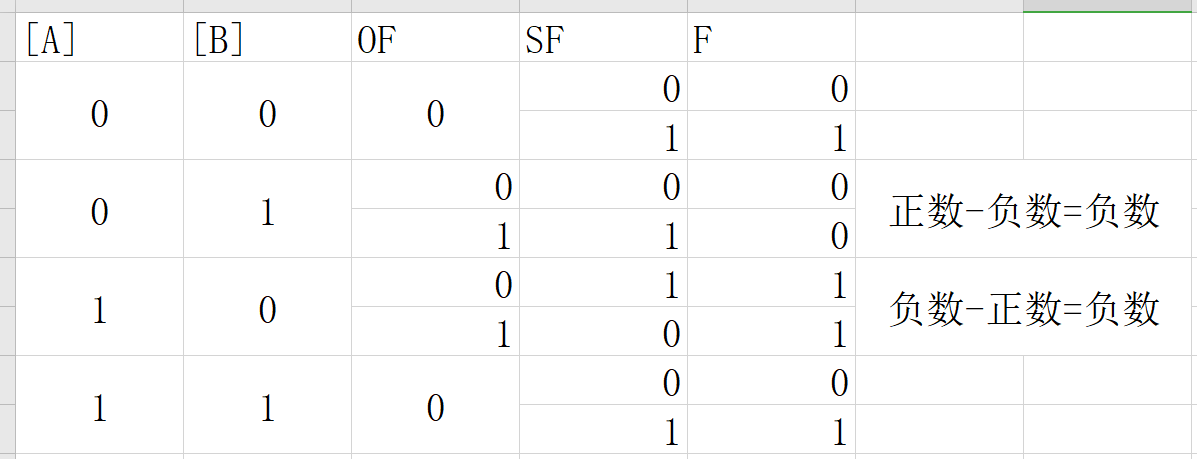
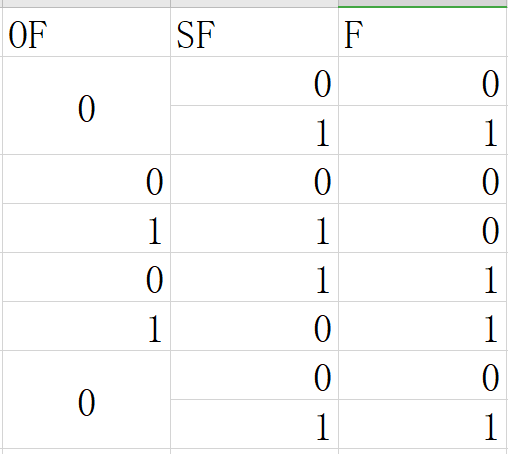
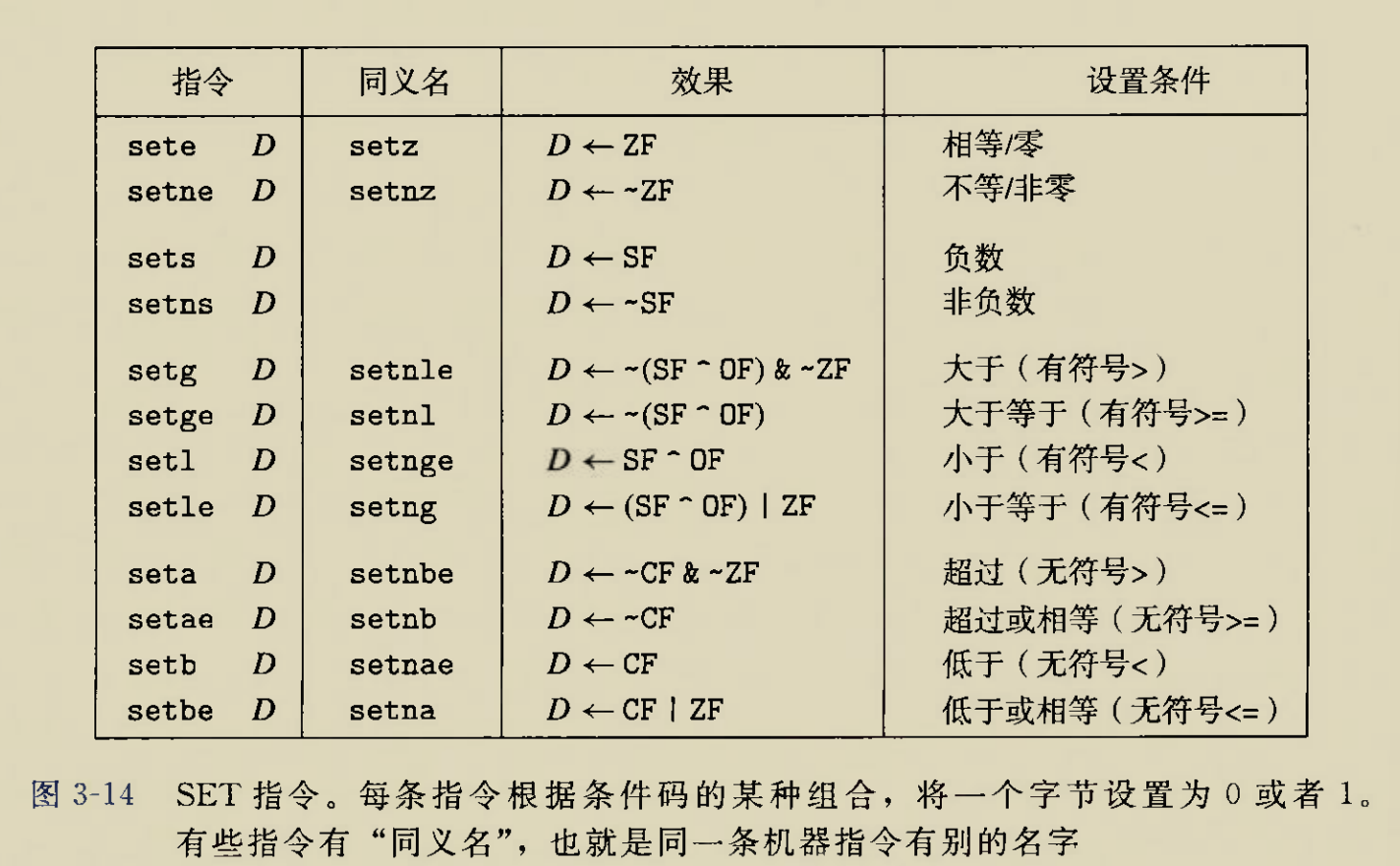
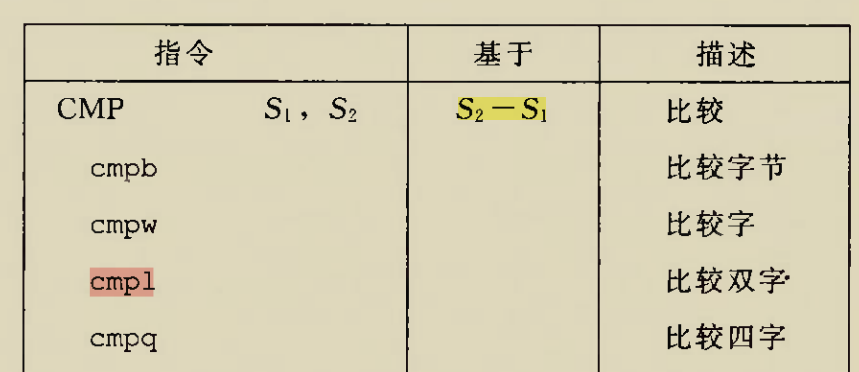
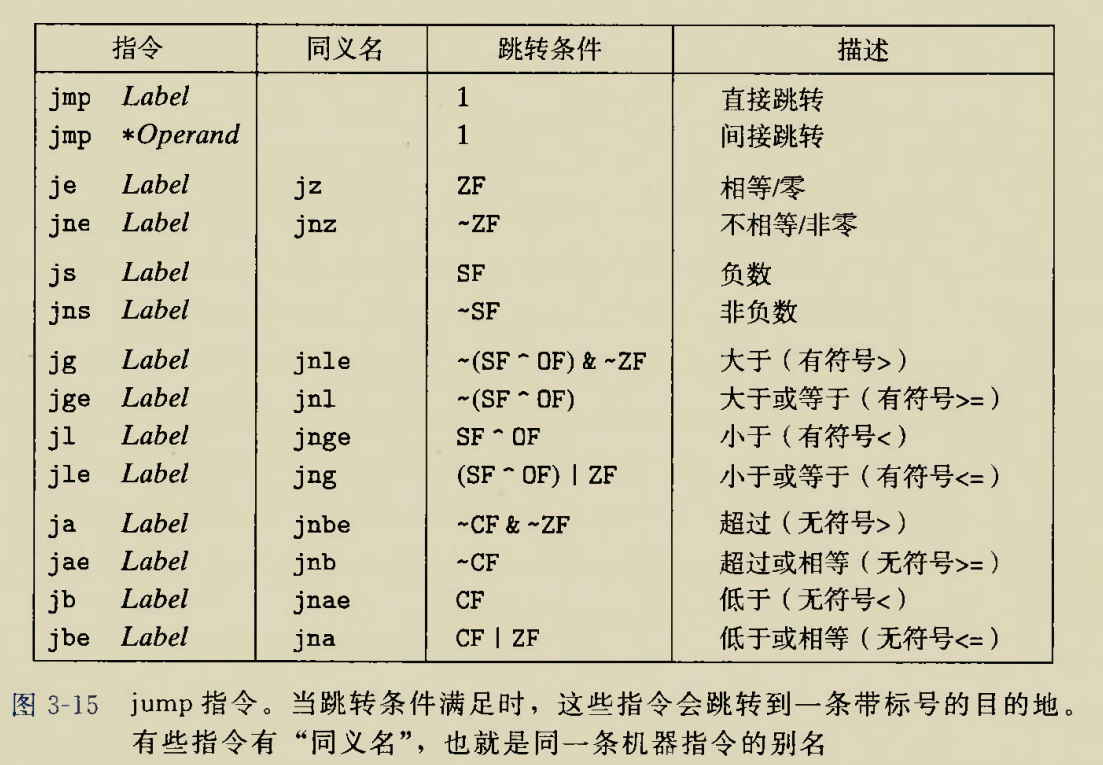
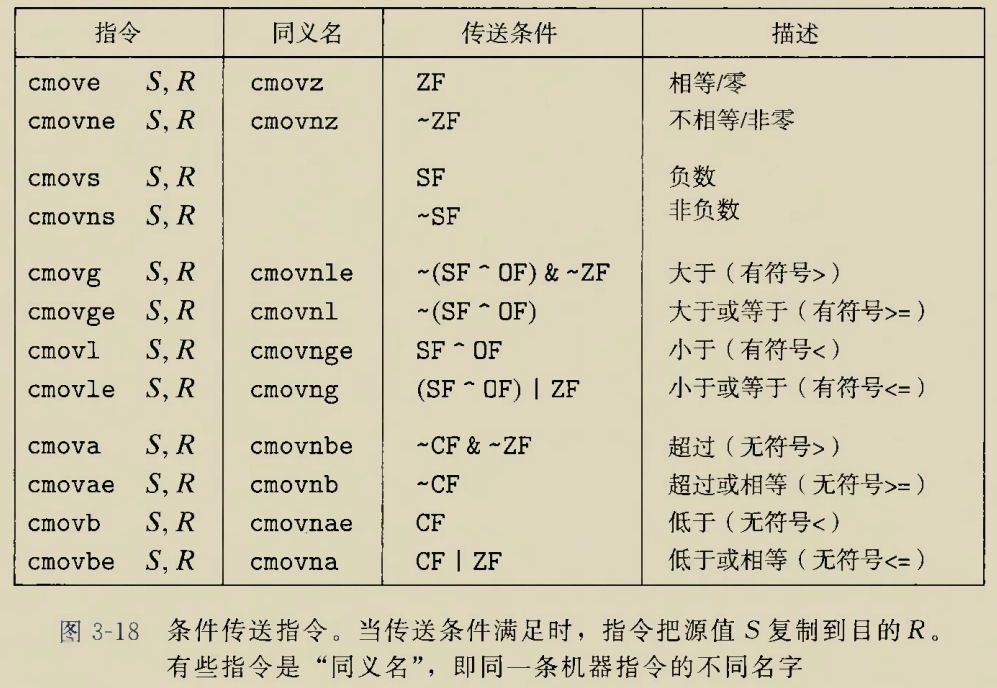
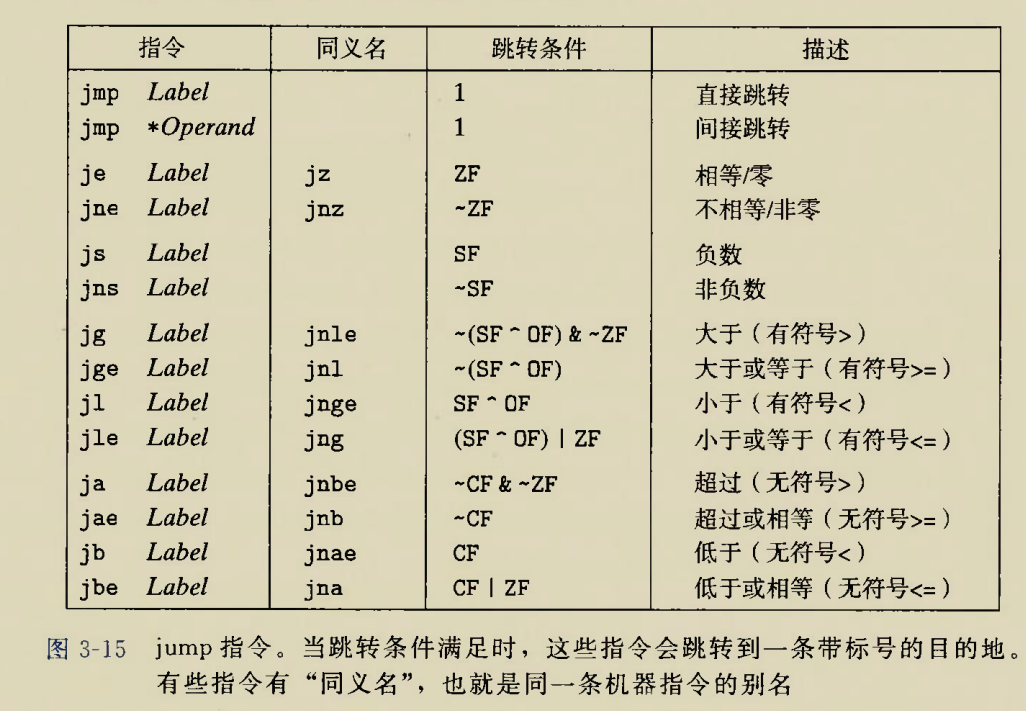
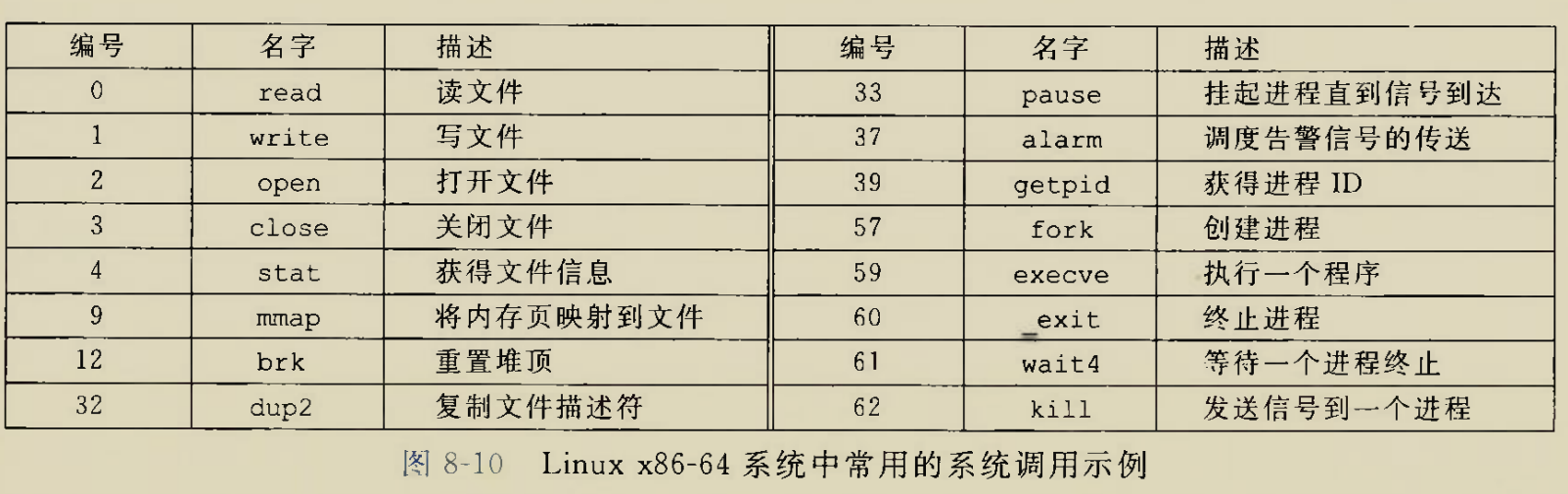
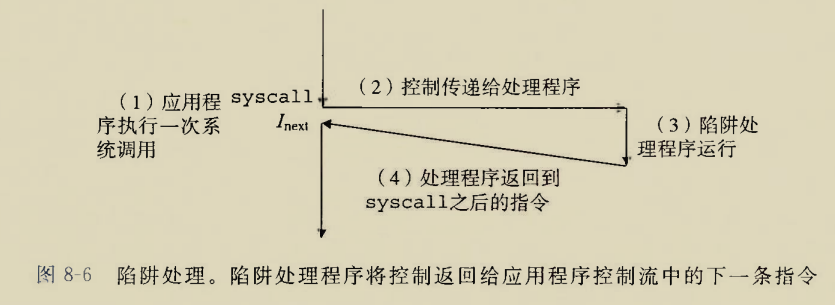
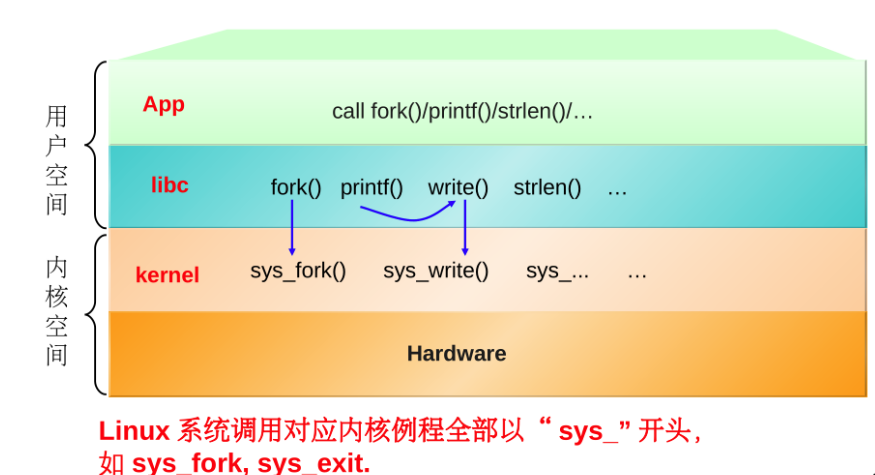
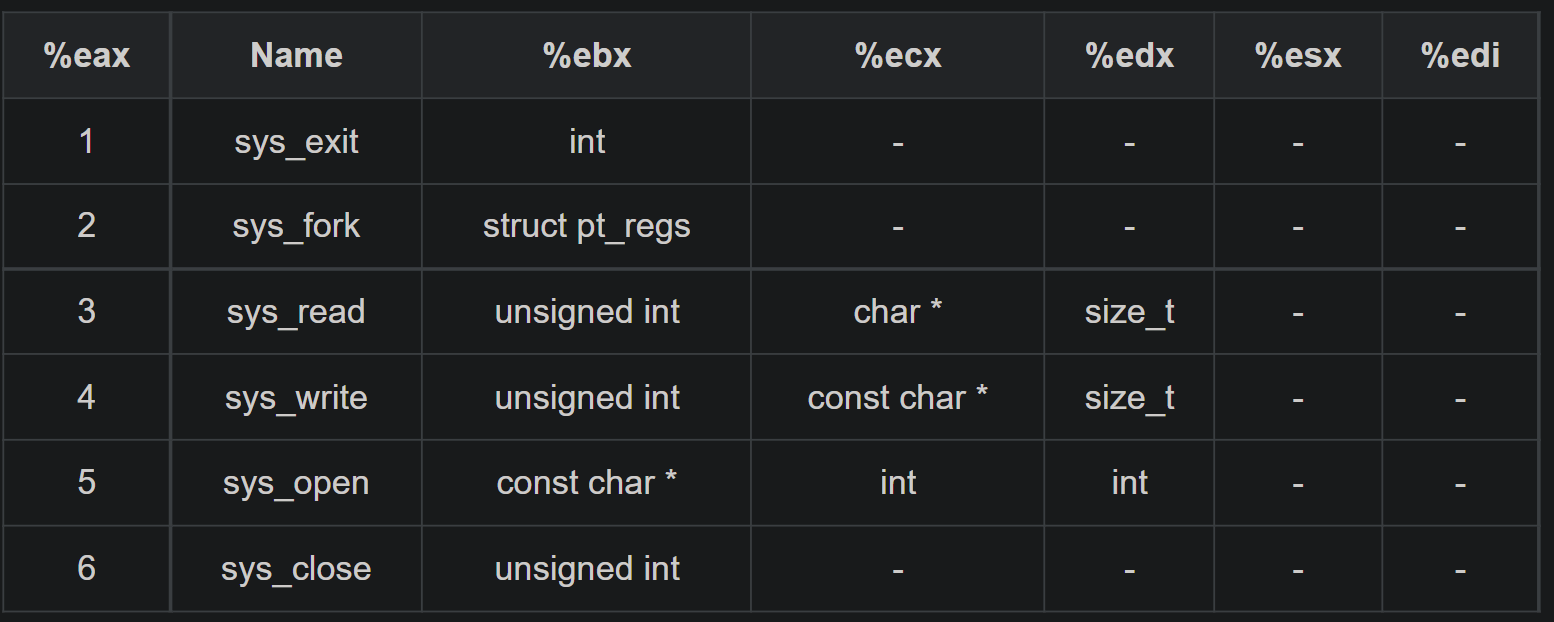
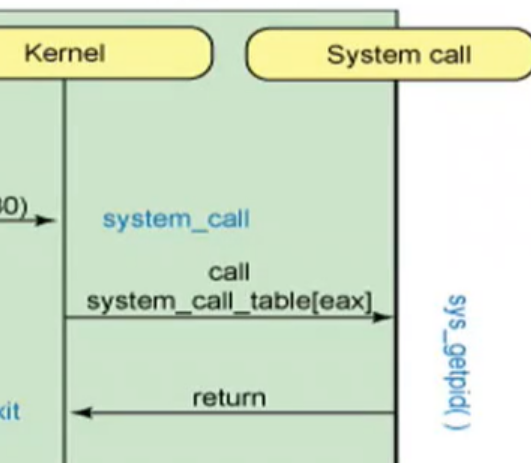
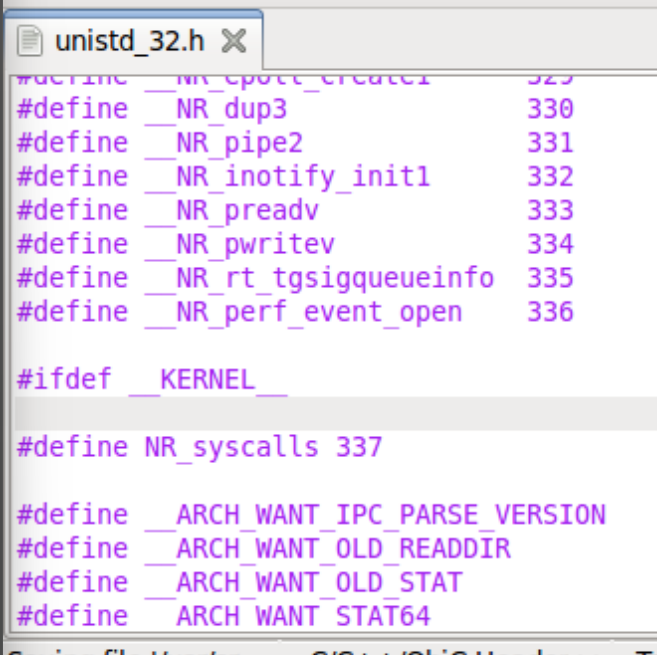
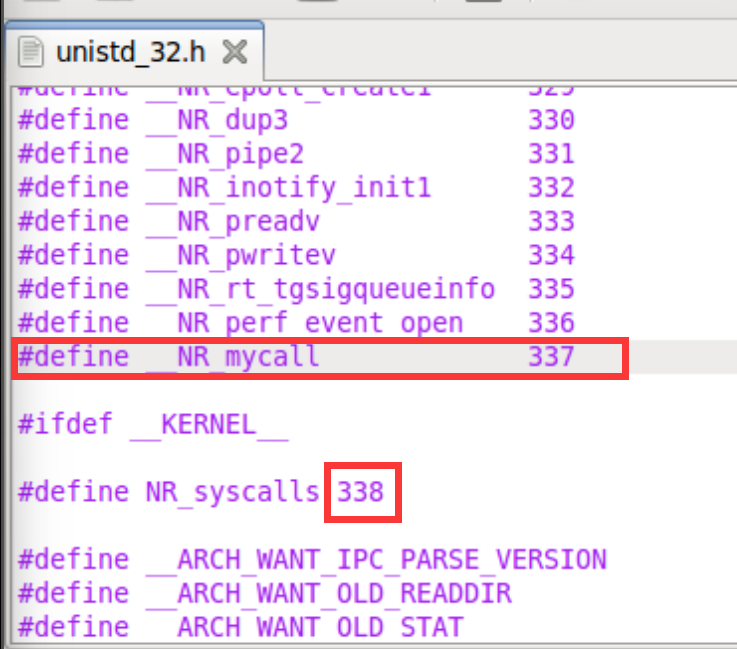
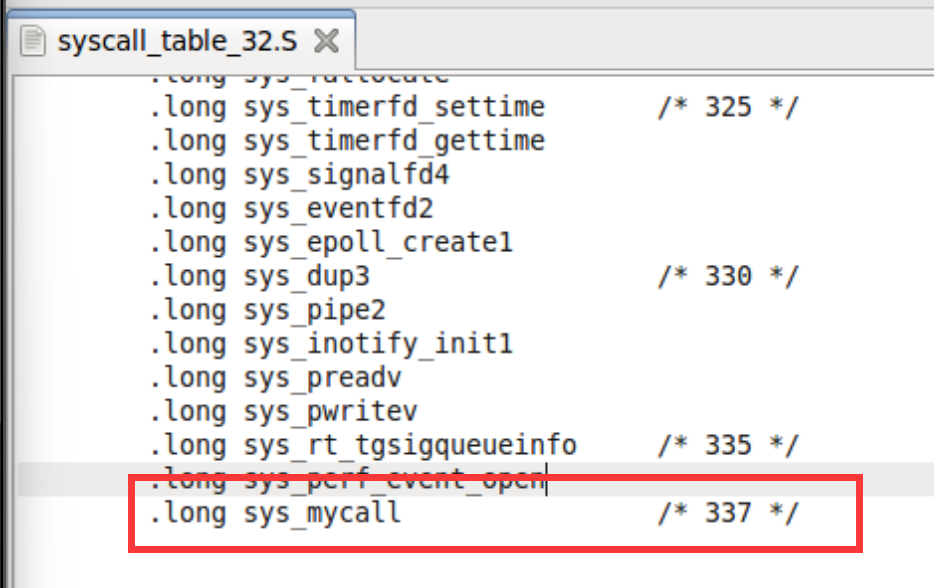
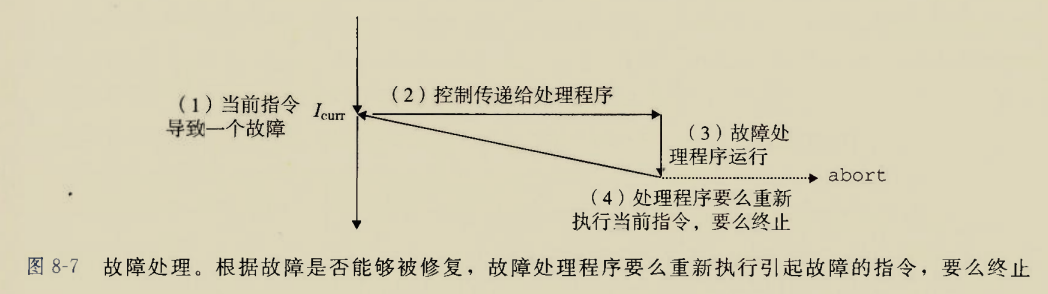
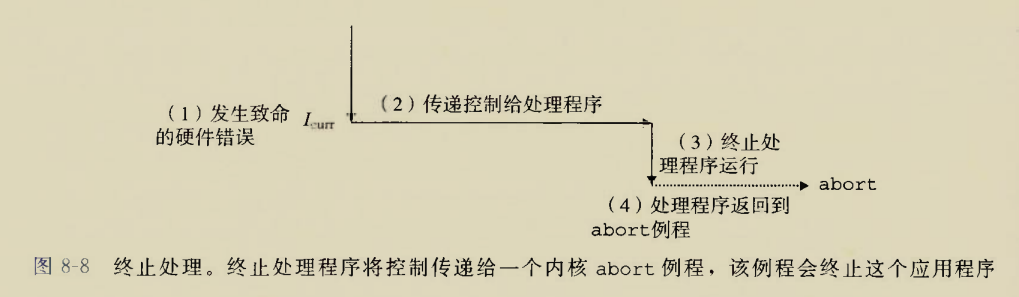
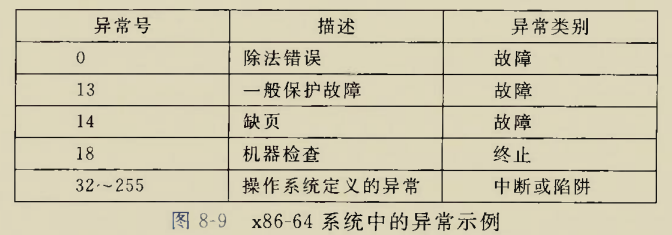
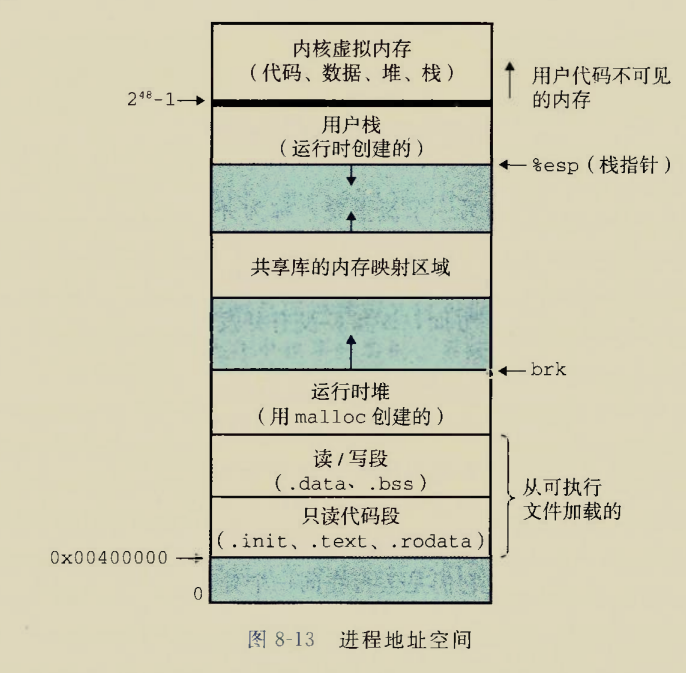
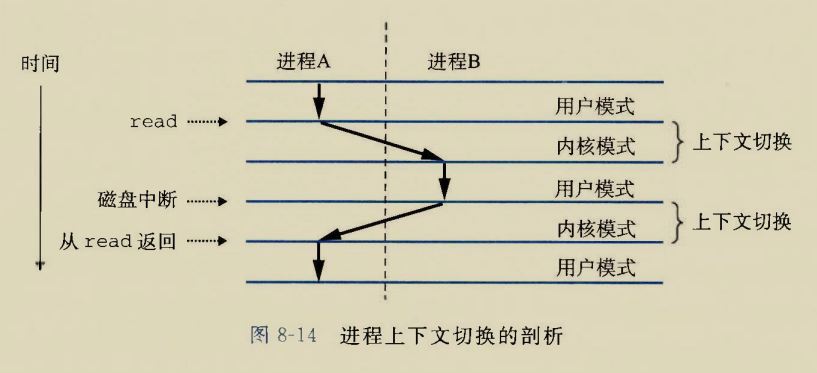
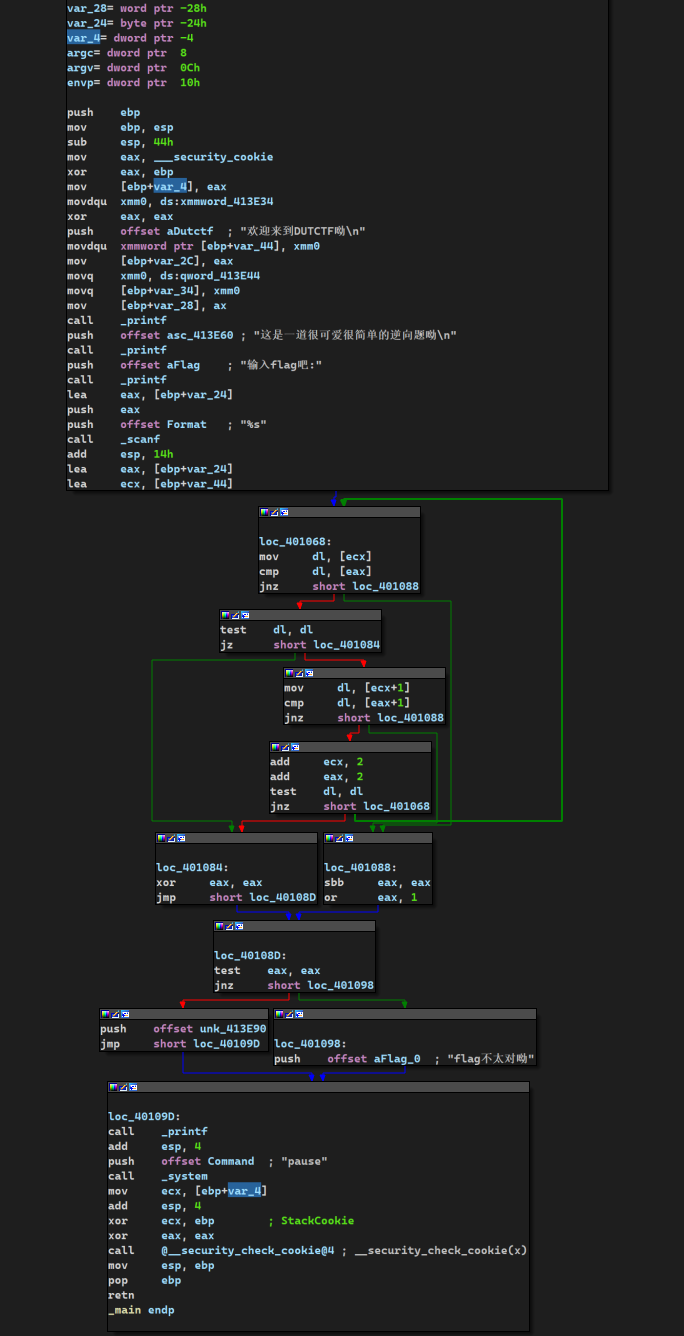
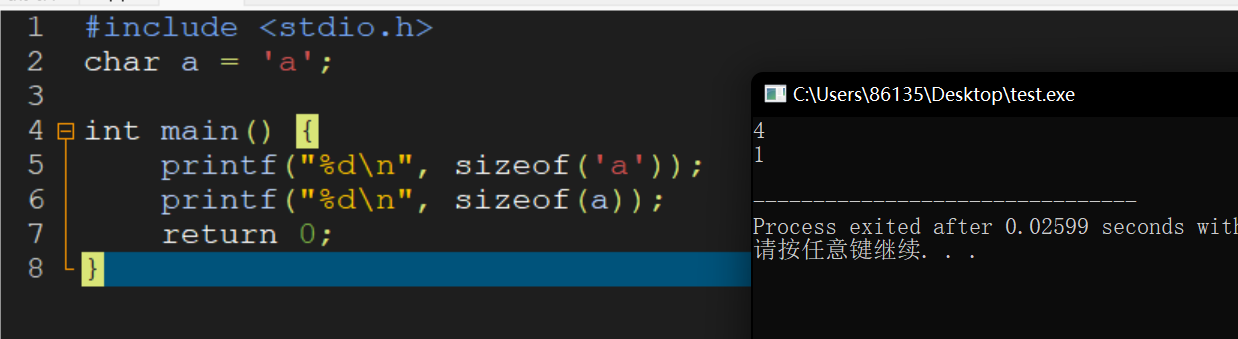
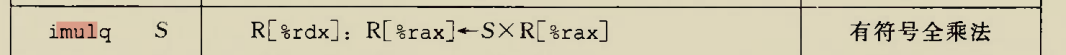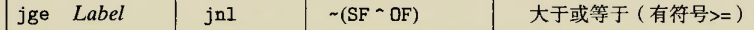Although there is an instruction movzbq, the GCC compiler typically
generates the instruction movzbl for this purpose, relying on the
property that an instruction generating a 4-byte with a register as
destination will fill the upper 4 bytes of the register with zeros.
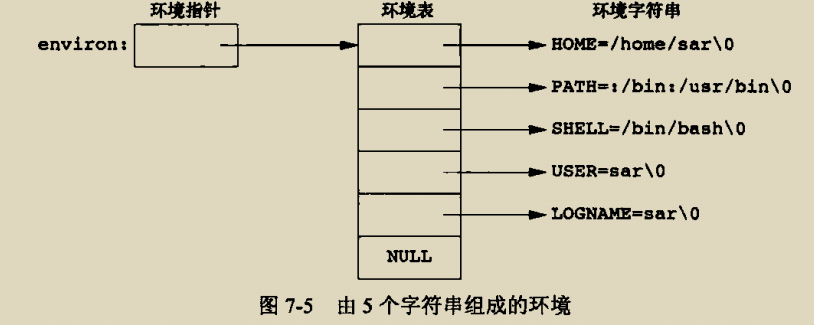
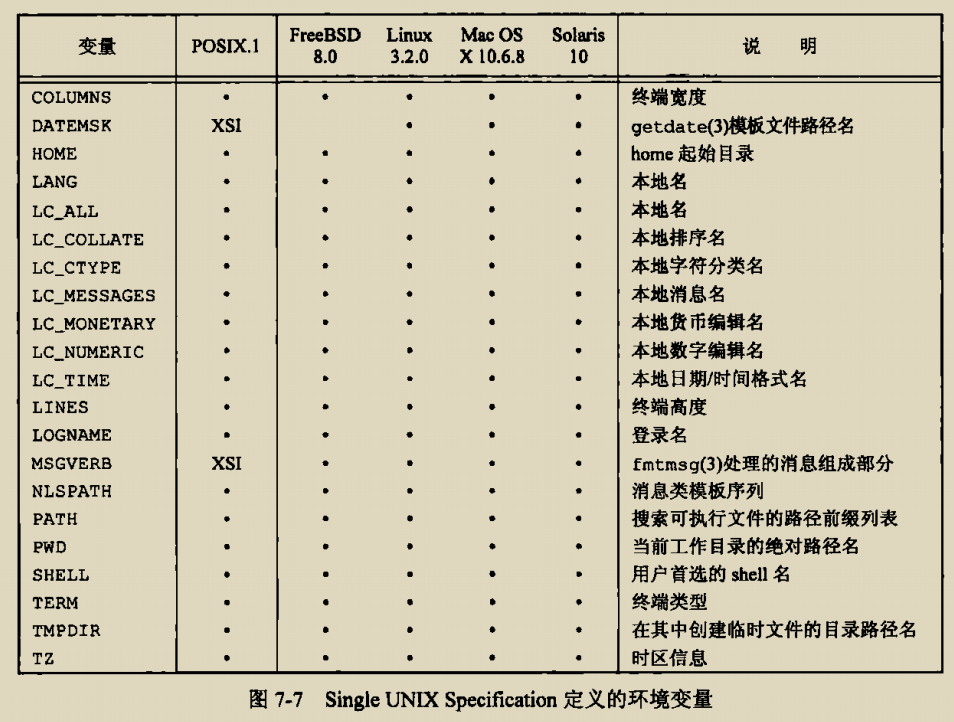
glibc是linux下面c标准库的实现,即GNU C
Library。glibc本身是GNU旗下的C标准库,后来逐渐成为了Linux的标准c库,而Linux下原来的标准c库Linux
libc逐渐不再被维护。Linux下面的标准c库不仅有这一个,如uclibc、klibc,以及上面被提到的Linux
libc,但是glibc无疑是用得最多的。glibc在/lib目录下的.so文件为libc.so.6。
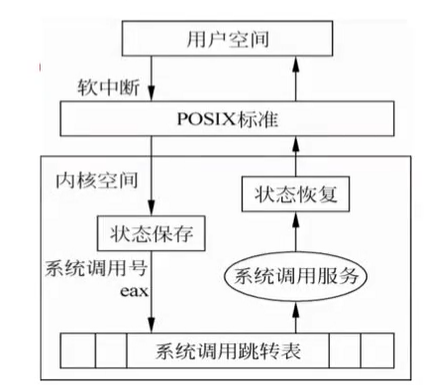
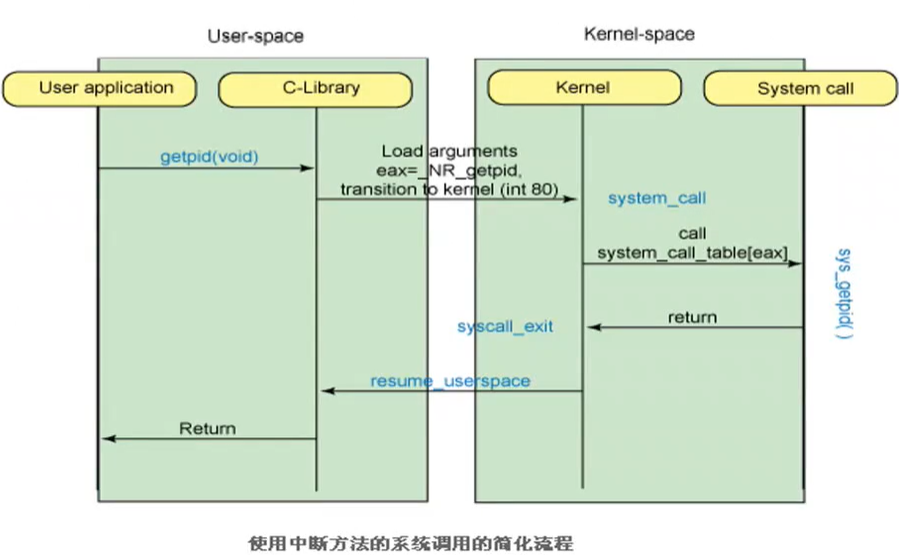
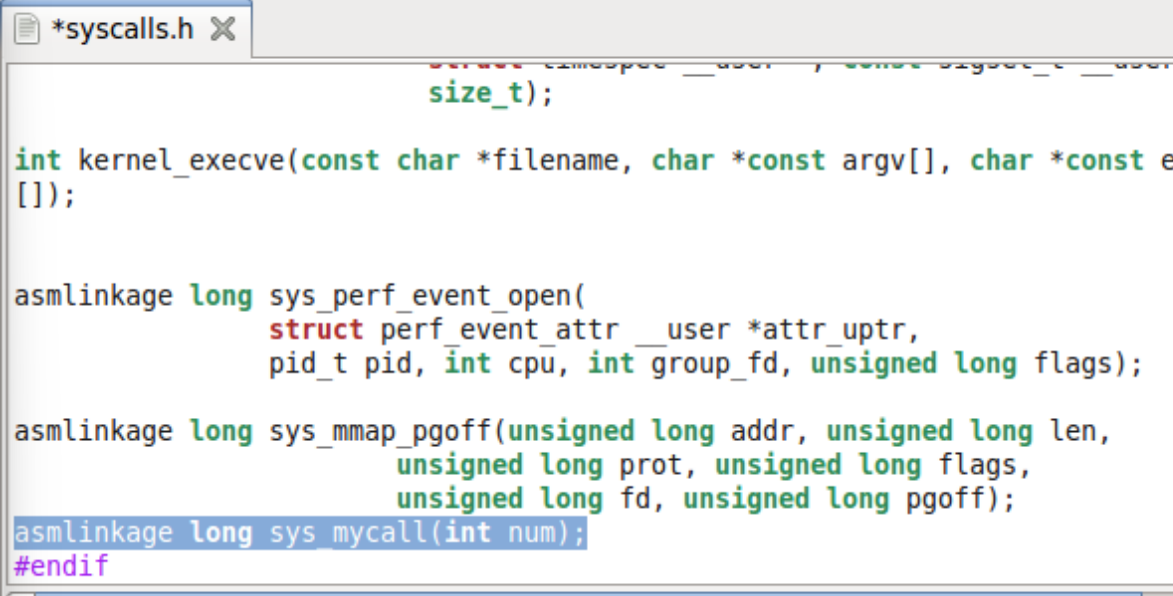
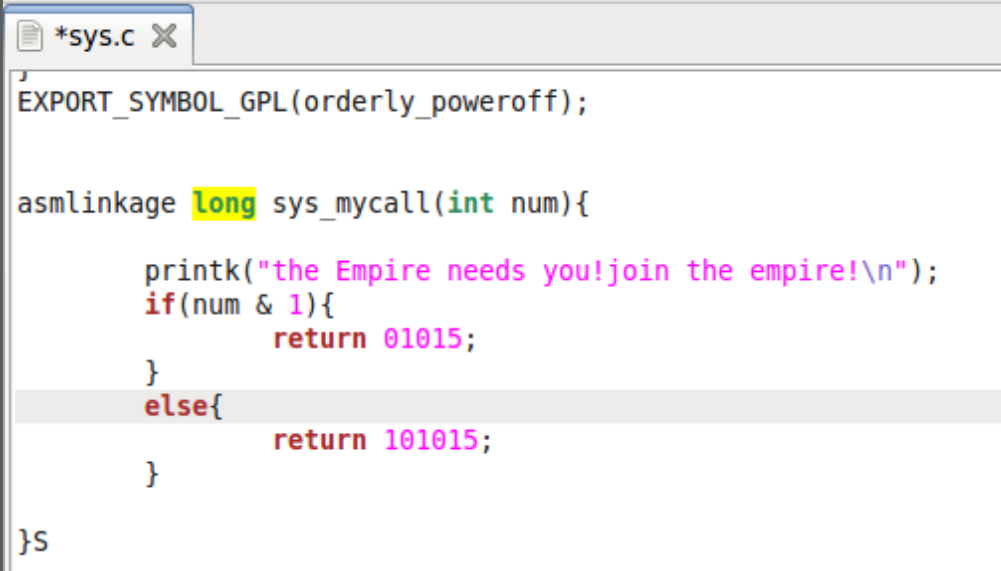
类似位置的修饰符我们见过__cdecl,__fastcall,这里asmlinkage也是一种调用约定的修饰符,试想如果不声明该修饰符,则linux上按照System
V AMD64
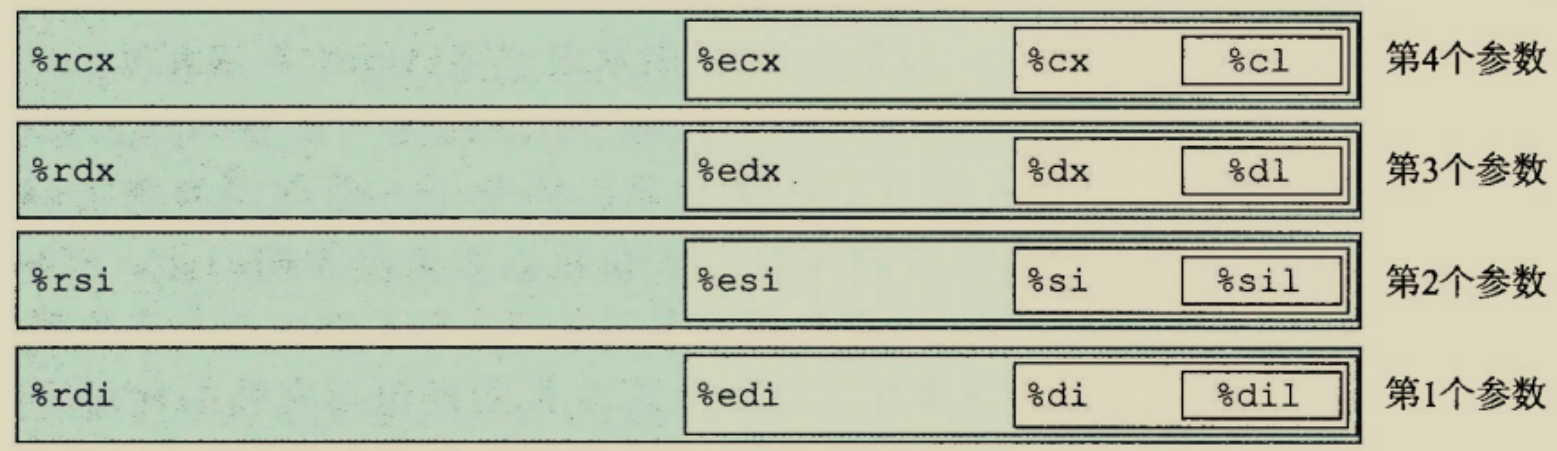
ABI约定的函数传参方法,前六个参数是通过edi,esi,edx,ecx,r8d,r9d这六个寄存器传递的,返回值是通过eax寄存器传递的.
/* * Ugh. To avoid negative return values, "getpriority()" will * not return the normal nice-value, but a negated value that * has been offset by 20 (ie it returns 40..1 instead of -20..19) * to stay compatible. */ SYSCALL_DEFINE2(getpriority, int, which, int, who) { ... }
#include<unistd.h> #include<stdio.h> #include<stdlib.h> intmain(){ printf("in father process 0\n"); //fork之前只会被父进程执行一次 int pid=fork(); //此处子进程和父进程并行 if(pid==0){ //对于子进程来说,它确实有一个正整数进程号,但是fork返回的不是 printf("in son process 1\n"); } if(pid!=0){ printf("in father process 1\n"); } }
运行结果:
1 2 3 4 5
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] └─$ ./proc in father process 0 in father process 1 in son process 1
#include<unistd.h> #include<stdio.h> #include<stdlib.h> int global=10; intmain(){ int local=20; int pid=fork(); if(pid==0){ printf("in son process: "); } else{ printf("in father process: "); } printf("global=%d,local=%d\n",global++,local++);//这里有修改
}
1 2 3 4
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] └─$ ./proc in father process: global=10,local=20 in son process: global=10,local=20 #两个打印相同说明global有两个,local有两个
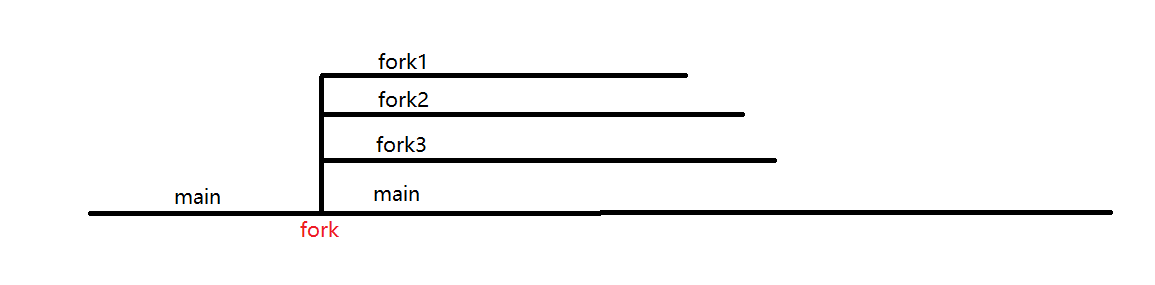
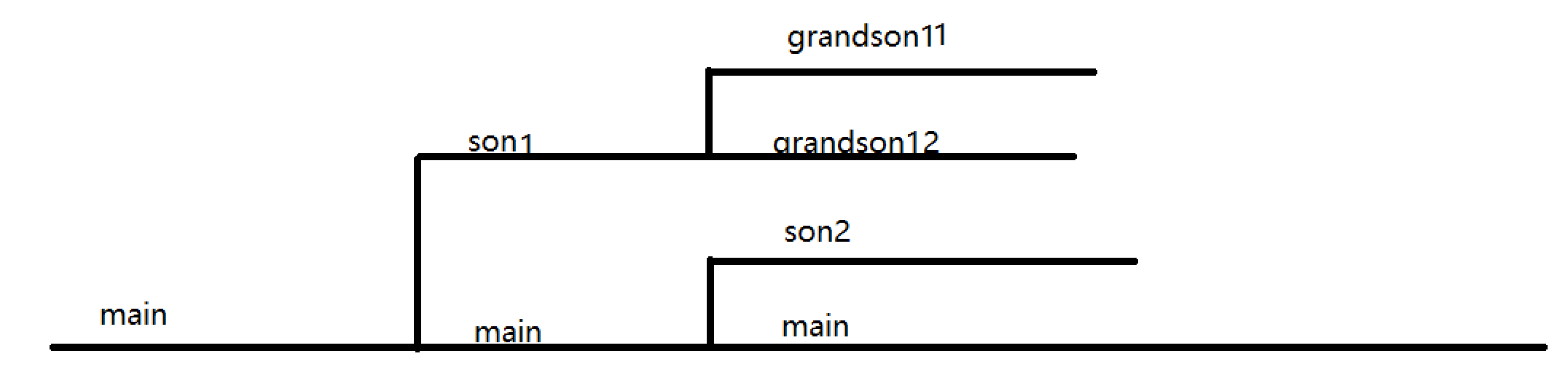
#include<unistd.h> #include<stdio.h> #include<stdlib.h> intmain(){ int pids[5]; int fpid=getpid();//fpid在fork之前先计算好,此后即使所有子进程都拷贝,也只是拷贝的父进程号 if(fpid==getpid()){//getpid在每个进程都不同,只有父进程中才会有fpid=getpid for(int i=0;i<5;++i){ pids[i]=fork();//实际上后来的子进程的pids也会存有数据,原因是父进程在创建第i个子进程时,pids已经写入前i-1个子进程号了 } } if(fpid==getpid()){//getpid在每个进程都不同,只有父进程中才会有fpid=getpid printf("in father process,pid=%d\n",fpid); for(int i=0;i<5;++i){ printf("pid%d=%d,",i,pids[i]); } printf("\n"); } return0;
}
这样实际上的进程图
image-20220519093748088
运行结果:
1 2 3 4
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] └─$ ./proc in father process,pid=222 pid0=223,pid1=224,pid2=226,pid3=230,pid4=235,
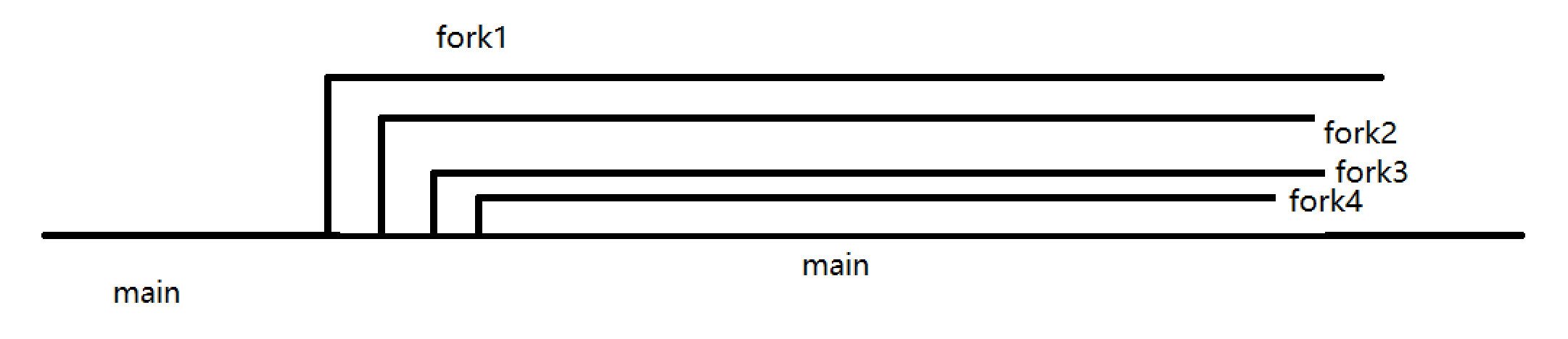
2.main和第一个子进程同时分支
image-20220519093425314
这个很容易实现
1 2
fork(); fork();
fork前后
proc.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
#include<unistd.h> #include<stdio.h> #include<stdlib.h> int global=10; intmain(){ int local=20; int pid0=getpid(); //fork之前getpid int forkid=fork(); //forkid只是用来 int pid1=getpid(); //fork之后getpid if(forkid==0){ printf("in son process,pid0=%d,pid1=%d,forkid=%d\n",pid0,pid1,forkid); } else{ printf("in father process,pid0=%d,pid1=%d,forkid=%d\n",pid0,pid1,forkid); } return0;
}
运行结果:
1 2 3 4
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] └─$ ./proc in father process,pid0=116,pid1=116,forkid=117 in son process,pid0=116,pid1=117,forkid=0
#include<unistd.h> #include<stdio.h> #include<stdlib.h> intmain(){ int forkid=fork(); int pid=getpid(); if(forkid==0){ printf("in son process,pid=%d\n",pid); exit(0); //让子进程结束运行 } else{ printf("in father process,pid=%d\n",pid); }
printf("process %d is still running\n",pid); //此句打印表明还在运行的进程
return0; }
1 2 3 4 5
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] └─$ ./proc in father process,pid=134 process 134 is still running in son process,pid=135
#include<unistd.h> #include<stdio.h> #include<stdlib.h> intmain(){ int fpid=getpid(); int forkid=fork(); if(forkid==0){//子进程中 printf("in son process,id=%d\n",getpid()); int n=1000000; while(n--);//拖延时间 exit(0); } else{//父进程中 printf("in father process,id=%d\n",fpid); waitpid(forkid,0,0);//指定等待唯一的子进程返回 //只指定第一个参数,其他使用缺省值 printf("son process %d exit\n",forkid); } printf("process %d is still running\n",getpid()); return0; }
运行结果:
1 2 3 4 5 6
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] └─$ ./proc in father process,id=273 in son process,id=274 #父进程需要等待子进程完成 son process 274 exit process 273 is still running
#include<unistd.h> #include<stdio.h> #include<stdlib.h> intmain(){ int fpid=getpid(); int forkid=fork();//区分父子进程 if(forkid==0){//子进程中 printf("in son process,id=%d\n",getpid()); int n=1000000; while(n--);//拖延时间 exit(1);//子进程以status=0状态终止 } else{//父进程中 int status=999;//设置status初始值 printf("in father process,id=%d\n",fpid); waitpid(forkid,&status,0);//使用status承载子进程的exit状态值 //缺省第三个参数 printf("son process %d exit with status= %d\n",forkid,status); printf("WIFEXITED(status)=%d\n",WIFEXITED(status)); printf("WEXITSTATUS(status)=%d\n",WEXITSTATUS(status)); printf("WIFSIGNALED(status)=%d\n",WIFSIGNALED(status)); printf("WTERMSIG(status)=%d\n",WTERMSIG(status)); printf("WIFSTOPPED(status)=%d\n",WIFSTOPPED(status)); printf("WSTOPSIG(status)=%d\n",WSTOPSIG(status)); printf("WIFCONTINUED(status)=%d\n",WIFCONTINUED(status)); }
printf("process %d is still running\n",getpid());
return0;
}
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/os] └─$ ./proc in father process,id=41 in son process,id=42 son process 42 exit with status= 256 WIFEXITED(status)=1 WEXITSTATUS(status)=1 #这是exit(status)中的status WIFSIGNALED(status)=0 WTERMSIG(status)=0 WIFSTOPPED(status)=0 WSTOPSIG(status)=1 WIFCONTINUED(status)=0 process 41 is still running
/* Bits in the third argument to `waitpid'. *///waitpid的第三个参数 其中的一些位 #define WNOHANG 1 /* Don't block waiting. *///01 #define WUNTRACED 2 /* Report status of stopped children. *///10
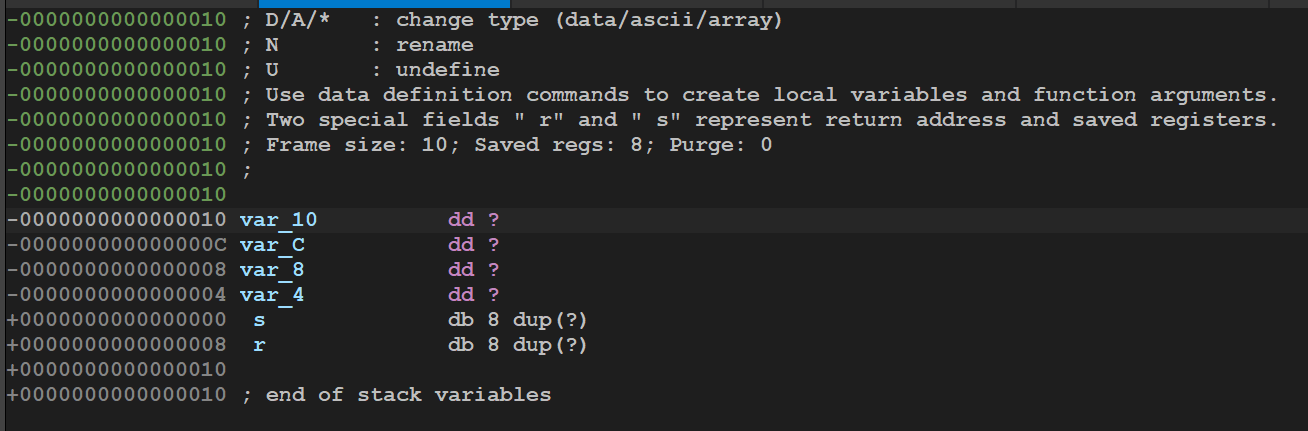
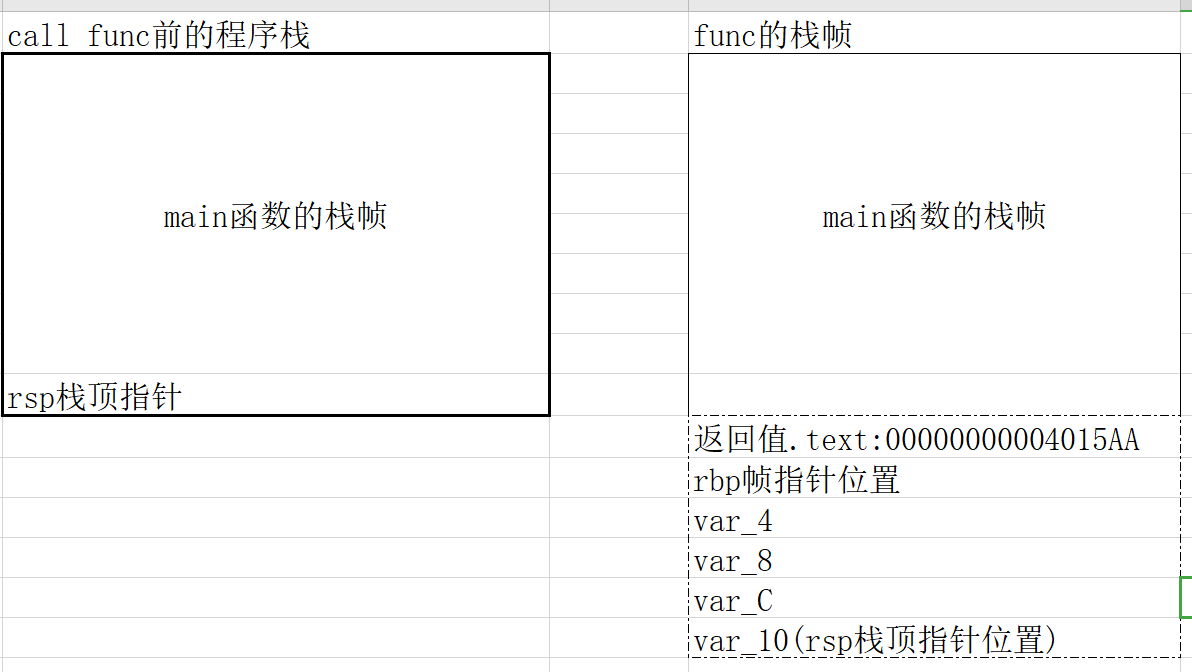
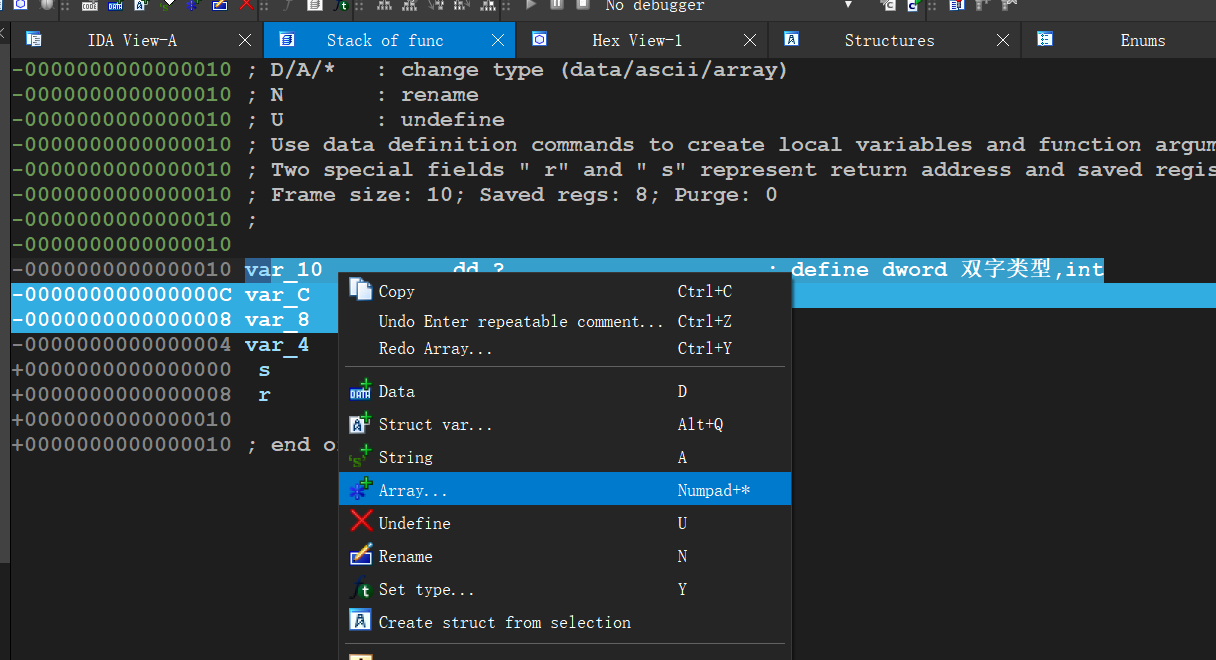
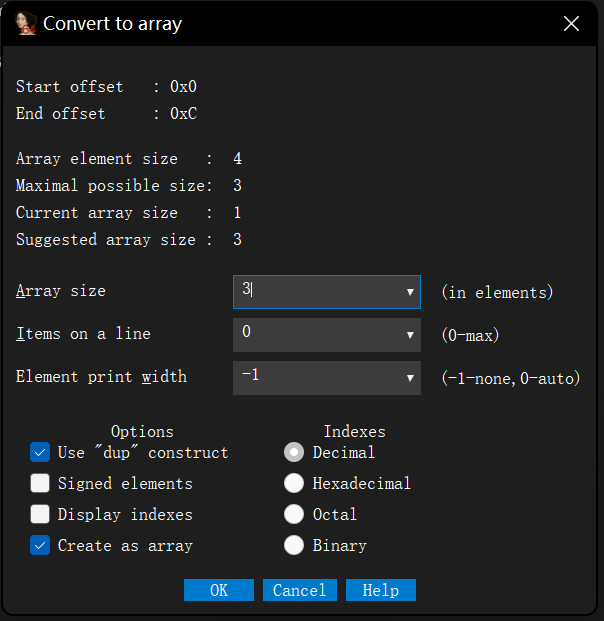
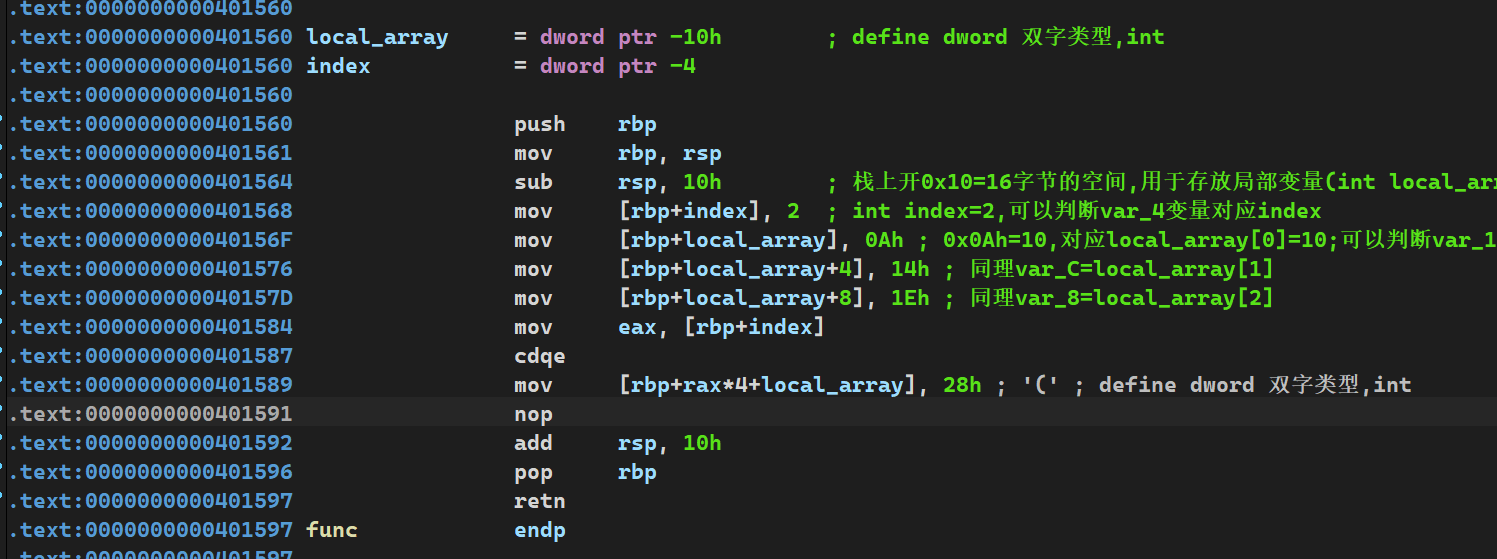
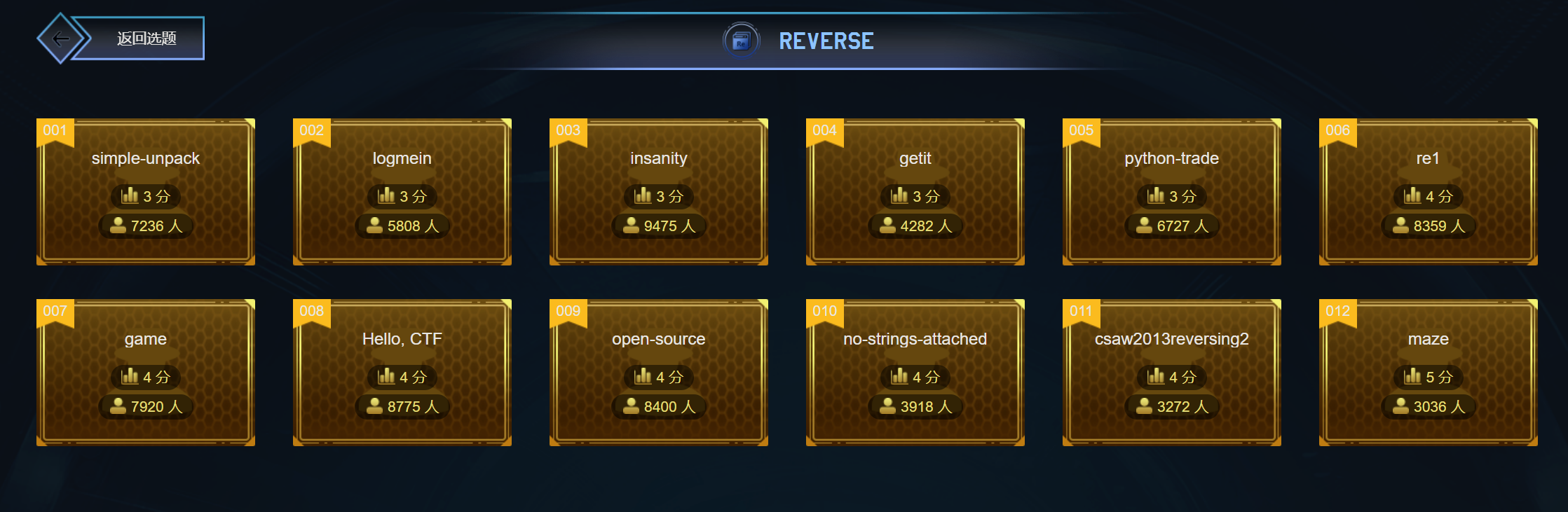
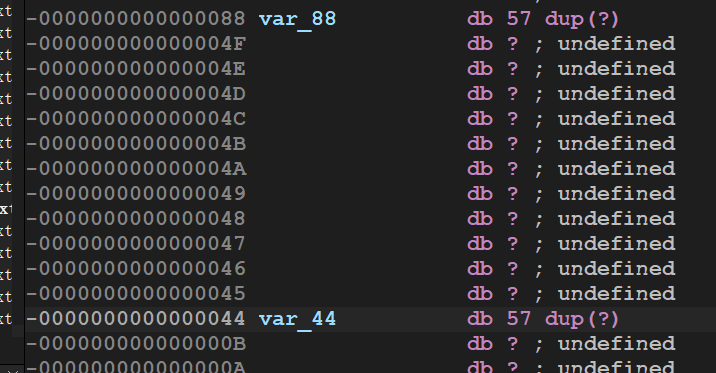
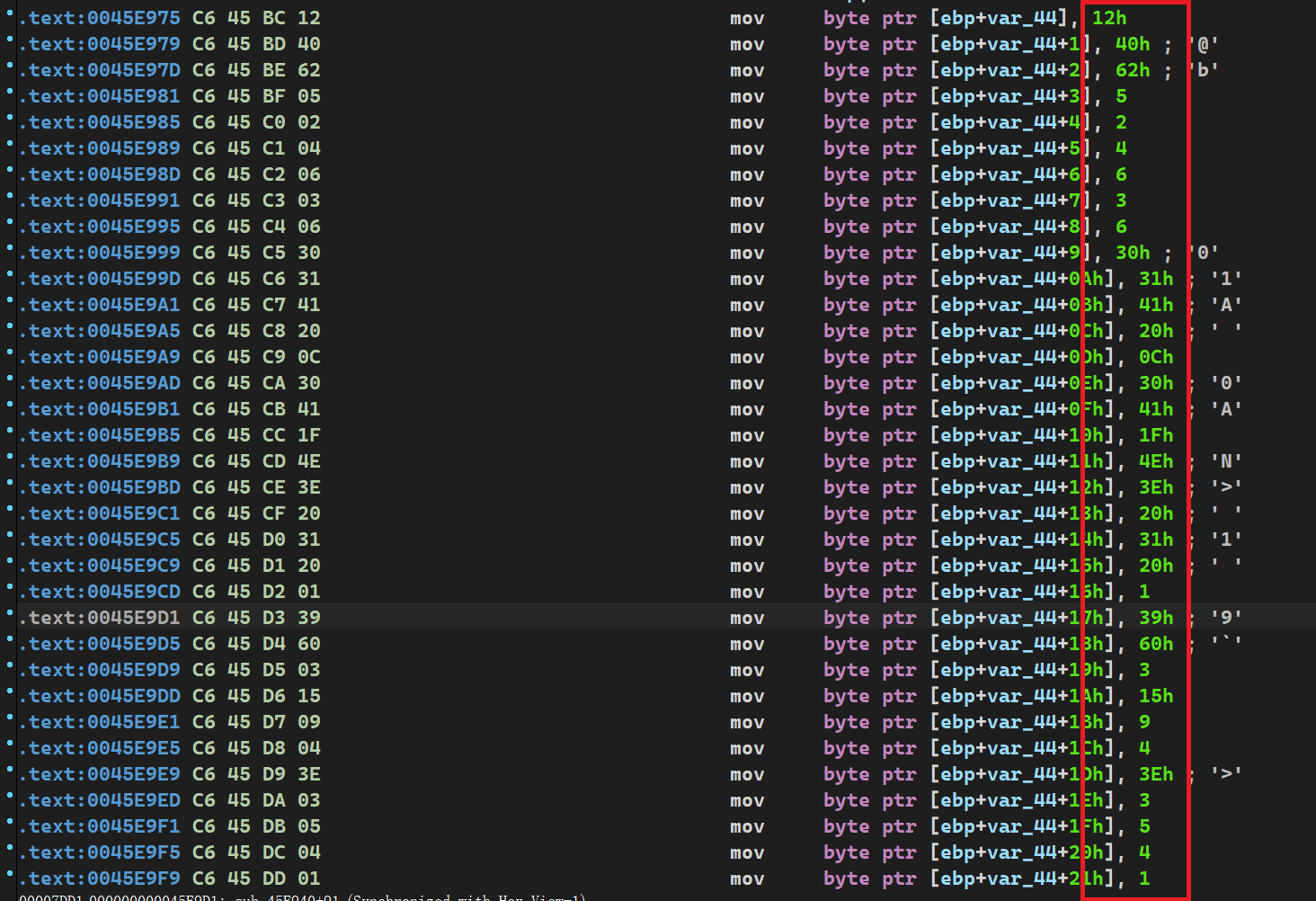
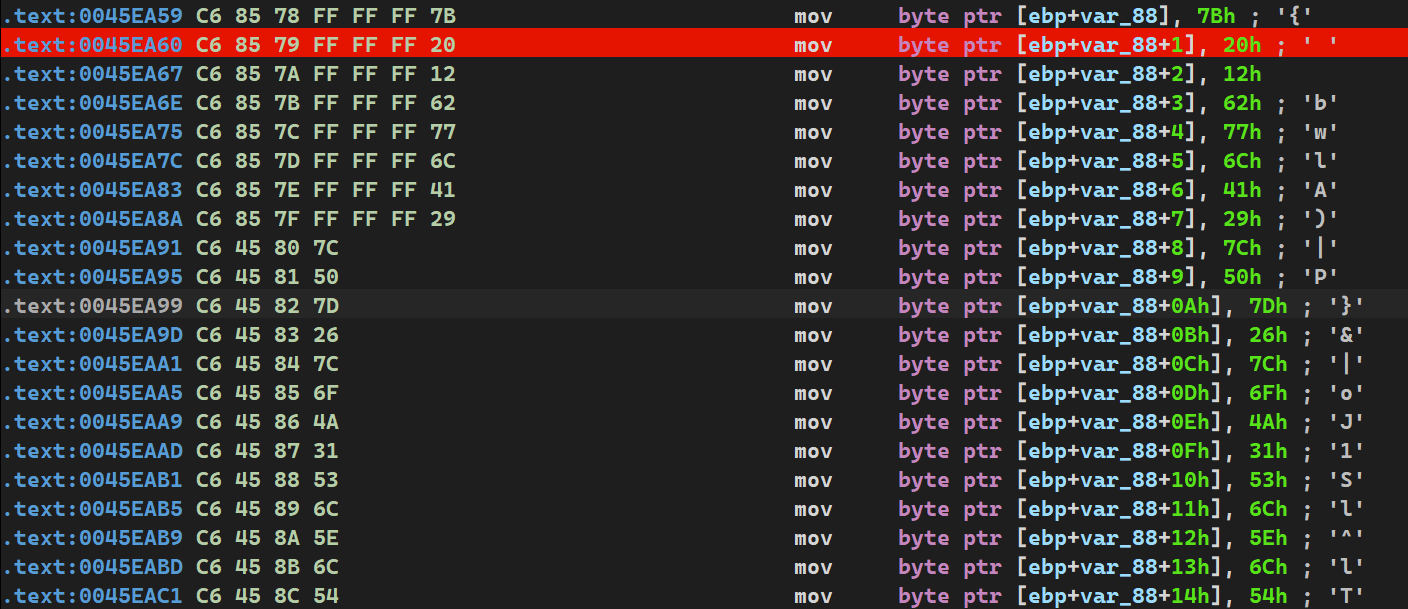
.text:0000000000401560 .text:0000000000401560 ; =============== S U B R O U T I N E ======================================= .text:0000000000401560 .text:0000000000401560 ; Attributes: bp-based frame ;局部变量和参数在栈帧中的地址基于rbp帧指针 .text:0000000000401560 .text:0000000000401560 ; void __fastcall func() .text:0000000000401560 public func .text:0000000000401560 func proc near ; CODE XREF: main+D↓p .text:0000000000401560 .text:0000000000401560 var_4 = dword ptr -4 ;局部变量只有一个,只能对应index .text:0000000000401560 .text:0000000000401560 push rbp .text:0000000000401561 mov rbp, rsp .text:0000000000401564 sub rsp, 10h .text:0000000000401568 mov [rbp+var_4], 2 ;int index=2 .text:000000000040156F lea rax, global_array ;R[rax]=&global_array,将global_array的地址放在rax .text:0000000000401576 mov dword ptr [rax], 0Ah ;寄存器寻址,然后dword ptr指定双字访问内存,global_array[0]=10 .text:000000000040157C lea rax, global_array ;重复R[rax]=&global_array,目的是防止上一次装载和本次之间rax有变化 .text:0000000000401583 mov dword ptr [rax+4], 14h ;寄存器+立即数寻址,双字访问内存 .text:000000000040158A lea rax, global_array .text:0000000000401591 mov dword ptr [rax+8], 1Eh .text:0000000000401598 lea rax, global_array .text:000000000040159F mov edx, [rbp+var_4] ;将var_4的拷贝到edx寄存器中 .text:00000000004015A2 movsxd rdx, edx ;edx有符号拓展到rdx .text:00000000004015A5 mov dword ptr [rax+rdx*4], 28h ; 基址比例变址寻址,然后放入40 .text:00000000004015AC nop .text:00000000004015AD add rsp, 10h .text:00000000004015B1 pop rbp .text:00000000004015B2 retn .text:00000000004015B2 func endp .text:00000000004015B2
问题是global_array貌似没有体现出声明来就直接使用了,左键双击global_array
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
.bss:0000000000407970 public global_array .bss:0000000000407970 global_array db ? ; ; DATA XREF: func+F↑o .bss:0000000000407970 ; func+1C↑o ... .bss:0000000000407971 db ? ; .bss:0000000000407972 db ? ; .bss:0000000000407973 db ? ; .bss:0000000000407974 db ? ; .bss:0000000000407975 db ? ; .bss:0000000000407976 db ? ; .bss:0000000000407977 db ? ; .bss:0000000000407978 db ? ; .bss:0000000000407979 db ? ; .bss:000000000040797A db ? ; .bss:000000000040797B db ? ; .bss:000000000040797C db ? ; .bss:000000000040797D db ? ; .bss:000000000040797E db ? ; .bss:000000000040797F db ? ;
.bss:0000000000407970 public l2 .bss:0000000000407970 l2 db ? ; ; DATA XREF: func+1E↑o .bss:0000000000407971 db ? ; .bss:0000000000407972 db ? ; .bss:0000000000407973 db ? ; .bss:0000000000407974 public l0 .bss:0000000000407974 l0 db ? ; ; DATA XREF: func+4↑o .bss:0000000000407975 db ? ; .bss:0000000000407976 db ? ; .bss:0000000000407977 db ? ; .bss:0000000000407978 public l1 .bss:0000000000407978 l1 db ? ; ; DATA XREF: func+11↑o .bss:0000000000407979 db ? ; .bss:000000000040797A db ? ; .bss:000000000040797B db ? ; .bss:000000000040797C db ? ; .bss:000000000040797D db ? ; .bss:000000000040797E db ? ; .bss:000000000040797F db ? ; .bss:0000000000407980 public __native_startup_state ...
.bss:0000000000407970 public e .bss:0000000000407970 ; Edge e .bss:0000000000407970 e Edge <?> ; DATA XREF: init+4↑o .bss:0000000000407970 ; init+11↑o ... .bss:0000000000407988 public __native_startup_state ...
.bss:0000000000407970 public e .bss:0000000000407970 e db ? ; ; DATA XREF: init+4↑o .bss:0000000000407970 ; init+11↑o ... .bss:0000000000407971 db ? ; .bss:0000000000407972 db ? ; .bss:0000000000407973 db ? ; .bss:0000000000407974 db ? ; .bss:0000000000407975 db ? ; .bss:0000000000407976 db ? ; .bss:0000000000407977 db ? ; .bss:0000000000407978 db ? ; .bss:0000000000407979 db ? ; .bss:000000000040797A db ? ; .bss:000000000040797B db ? ; .bss:000000000040797C db ? ; .bss:000000000040797D db ? ; .bss:000000000040797E db ? ; .bss:000000000040797F db ? ; .bss:0000000000407980 db ? ; .bss:0000000000407981 db ? ; .bss:0000000000407982 db ? ; .bss:0000000000407983 db ? ; .bss:0000000000407984 db ? ; .bss:0000000000407985 db ? ; .bss:0000000000407986 db ? ; .bss:0000000000407987 db ? ; .bss:0000000000407988 public __native_startup_state ...
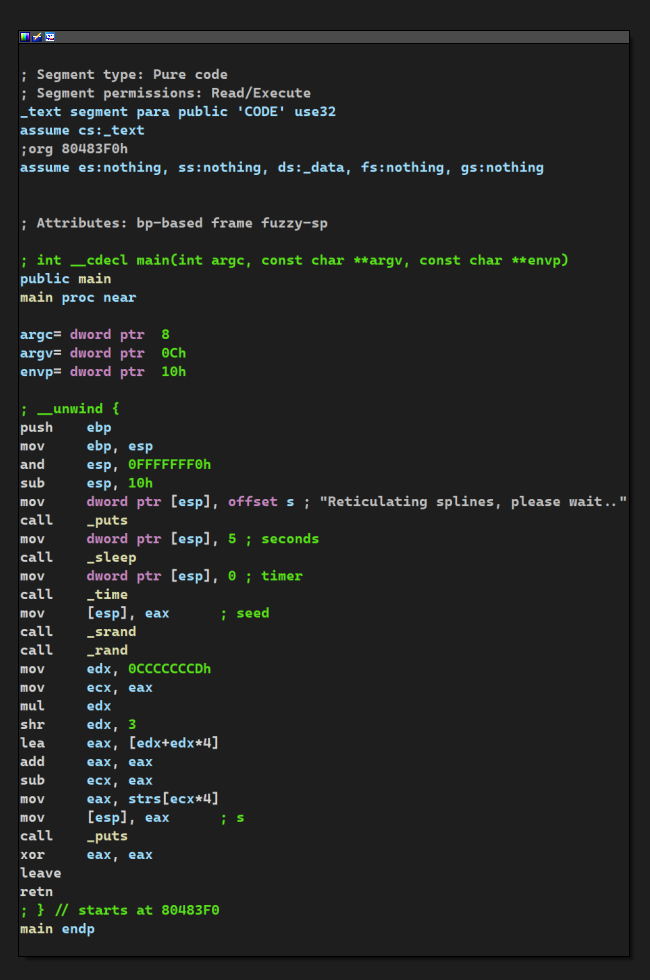
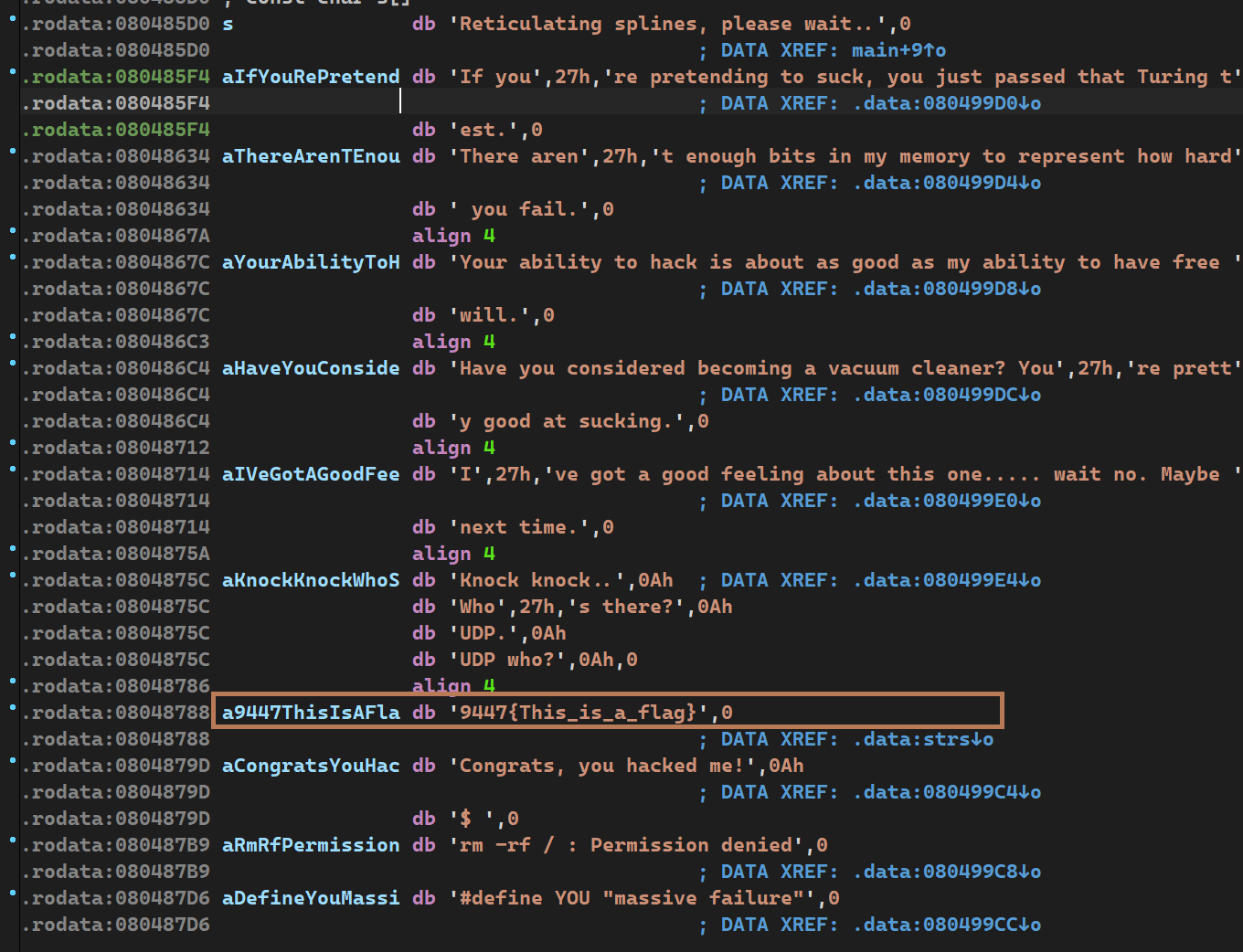
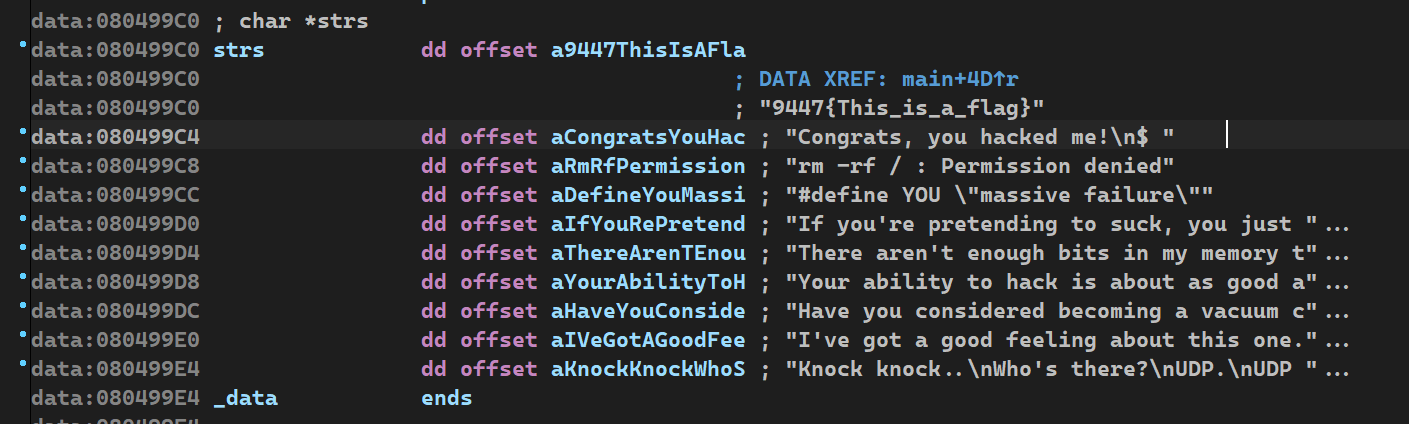
┌──(kali㉿Executor)-[/mnt/c/Users/86135/Desktop/xctf12/insanity] └─$ ./insanity Reticulating splines, please wait.. Your ability to hack is about as good as my ability to have free will.
┌──(kali㉿Executor)-[/mnt/c/Users/86135/Desktop/xctf12/insanity] └─$ ./insanity Reticulating splines, please wait.. I've got a good feeling about this one..... wait no. Maybe next time. ┌──(kali㉿Executor)-[/mnt/c/Users/86135/Desktop/xctf12/insanity] └─$ ./insanity Reticulating splines, please wait.. #define YOU "massive failure" ┌──(kali㉿Executor)-[/mnt/c/Users/86135/Desktop/xctf12/insanity] └─$ ./insanity Reticulating splines, please wait.. Your ability to hack is about as good as my ability to have free will. ┌──(kali㉿Executor)-[/mnt/c/Users/86135/Desktop/xctf12/insanity] └─$ ./insanity Reticulating splines, please wait.. rm -rf / : Permission denied ┌──(kali㉿Executor)-[/mnt/c/Users/86135/Desktop/xctf12/insanity] └─$ ./insanity Reticulating splines, please wait.. Your ability to hack is about as good as my ability to have free will.
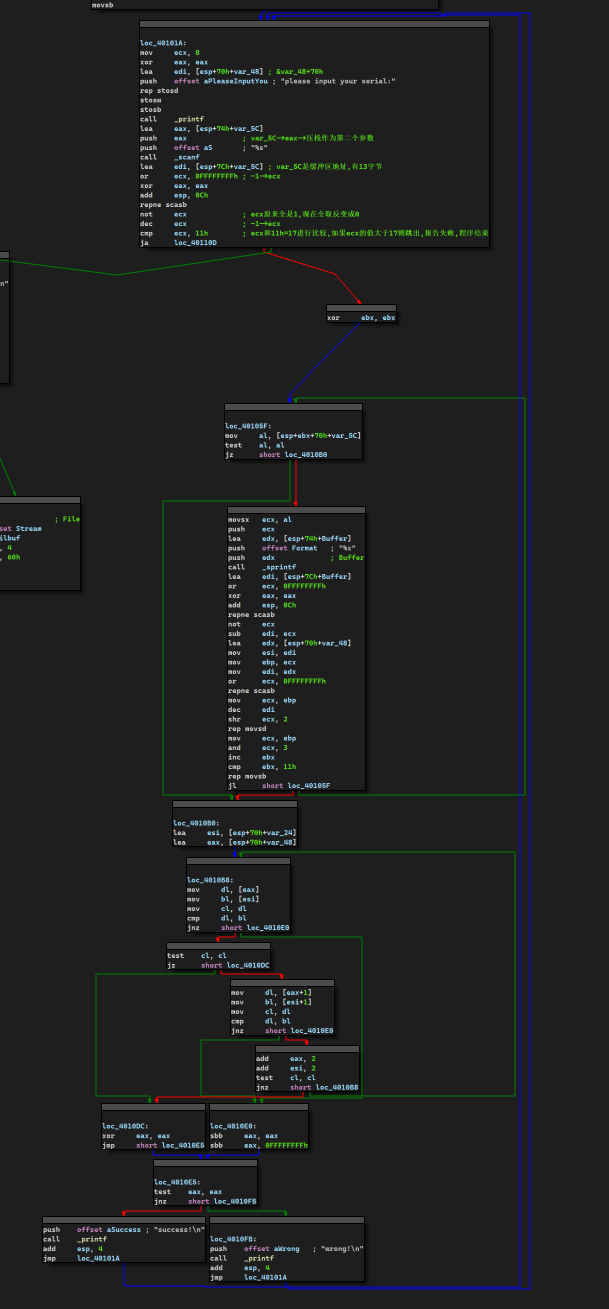
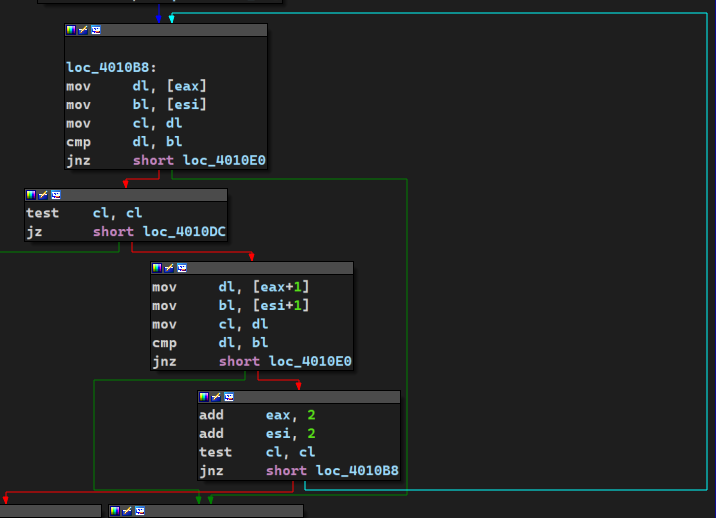
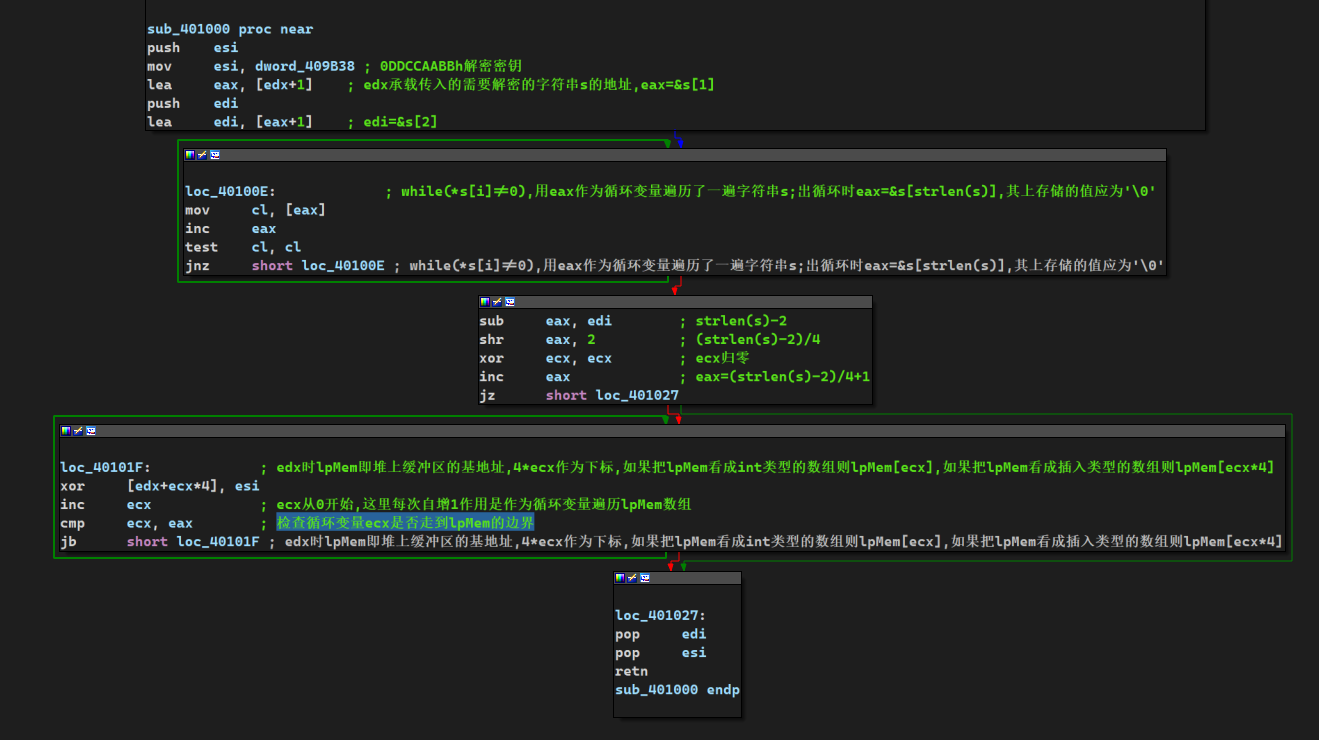
loc_40105F: mov al, [esp+ebx+70h+var_5C] ;在进入循环体之前,loc_40101A最的最后,ebx置零,这里又和var_5C结合使用,可以大胆推测这是一个基址变址寻址,基址是esp+70h+var_5c即&var_5C,变址即偏移量ebx,以后都记作i test al, al jz short loc_4010B0 ;如果var_5c[i]为0即i遍历到var_5c字符串的末尾则跳转loc_4010B0
lea edi, [esp+7Ch+Buffer] ;&Buffer->edi or ecx, 0FFFFFFFFh ;ecx置全1 xor eax, eax ;根据eax置ZF,然后eax置零 add esp, 0Ch repne scasb ;寻找buffer的结束位置 not ecx ;ecx存放buffer的结束字符下标 sub edi, ecx ;edi-ecx之后edi回退到Buffer起始位置
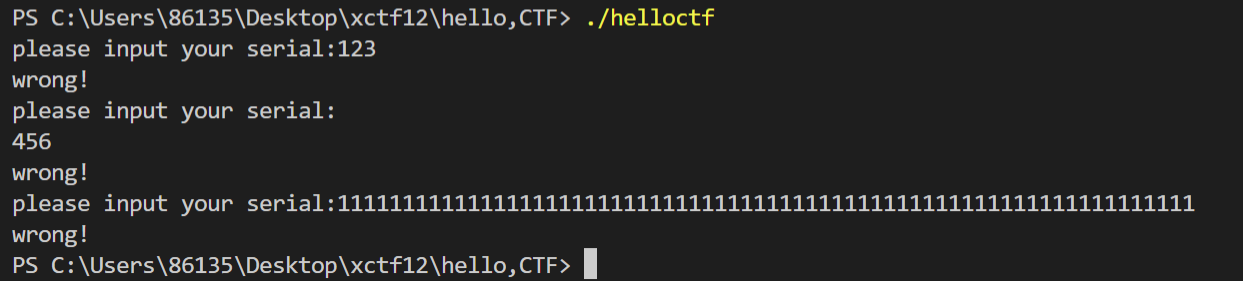
unsignedint first = atoi(argv[1]);//第一个参数转化成字符串 if (first != 0xcafe) {//要求first=51966 printf("you are wrong, sorry.\n"); exit(2); }
unsignedint second = atoi(argv[2]);//second为第二个参数转化成字符串 if (second % 5 == 3 || second % 17 != 8) {//要求second 模5不余三,模17余8 printf("ha, you won't get it!\n"); exit(3); }
if (strcmp("h4cky0u", argv[3])) {//要求argv[3]="h4cky0u",长度为7 printf("so close, dude!\n"); exit(4); }
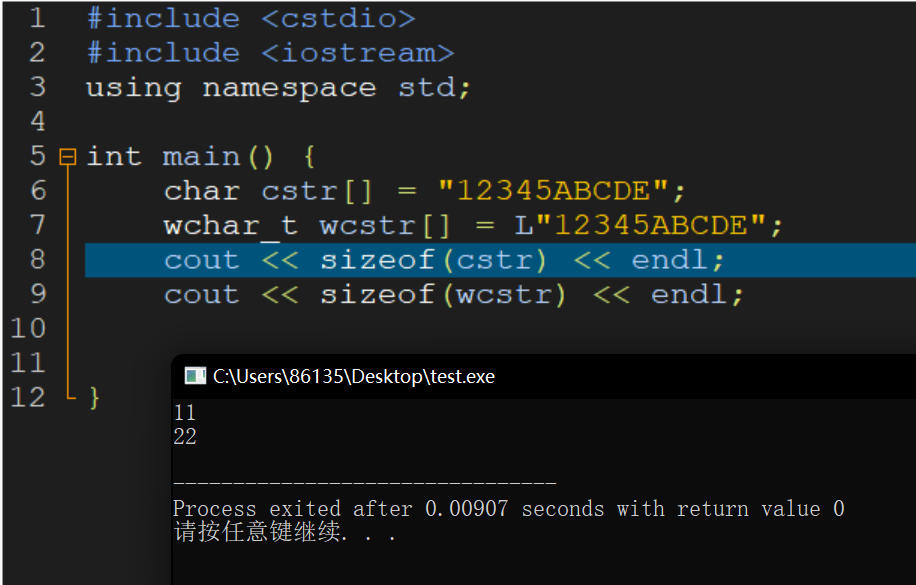
[错误] cannot initialize array of 'wchar_t' 从 a string literal with type array of 'char'
unicode部分码表:
类型
编码(十进制)
编码(十六进制)
小写字母(a~z)
97~122
61~7a
大写字母(A~Z)
65~90
41~5a
左右花括号{}
{123,125}
{7b,7d}
阿拉伯数字
48~57
30~39
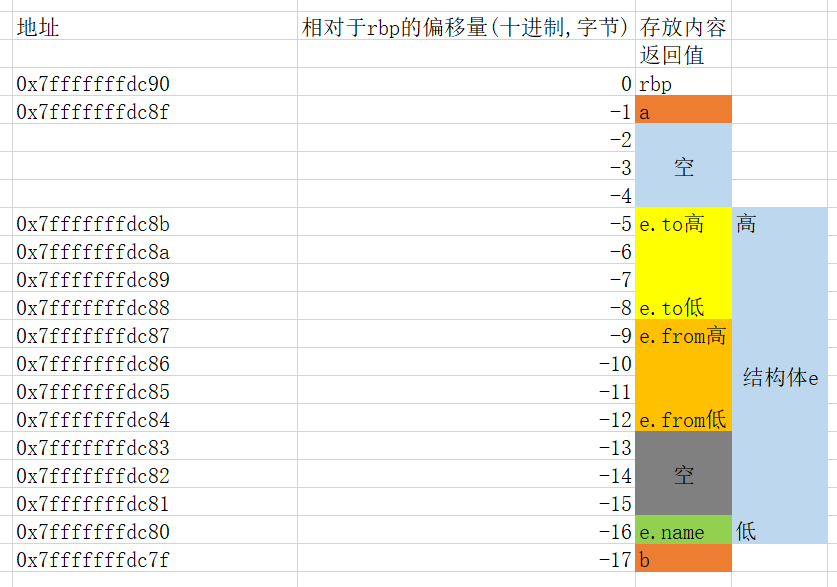
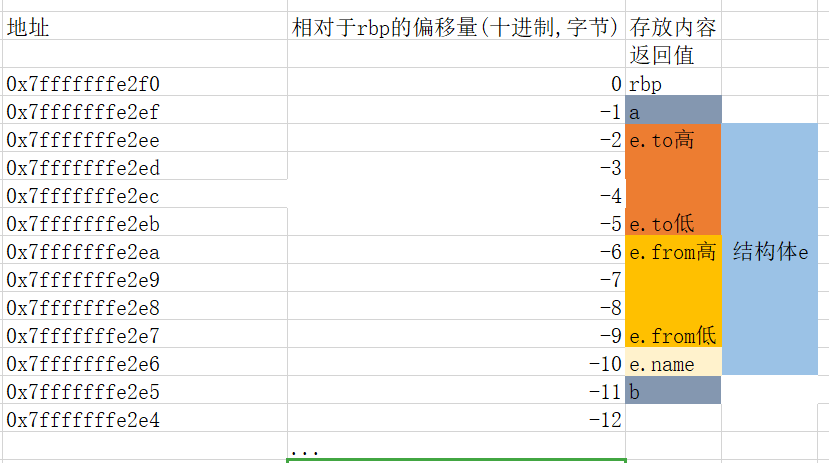
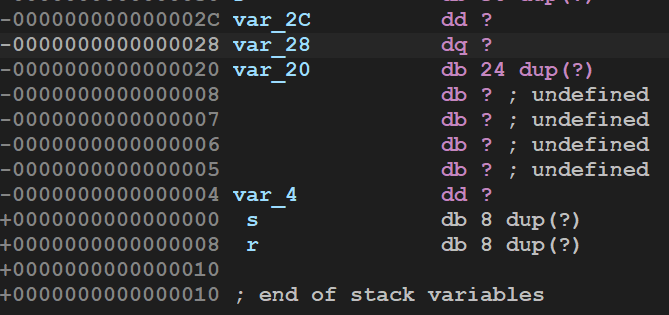
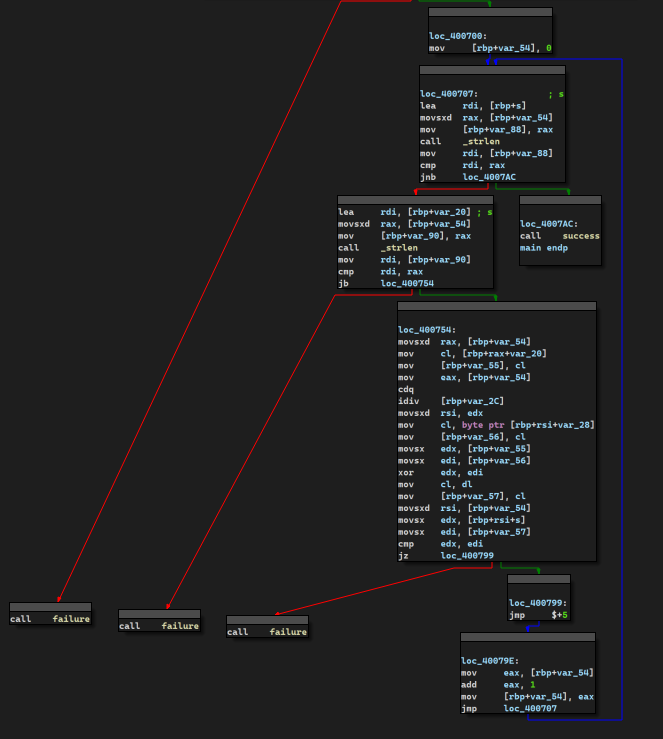
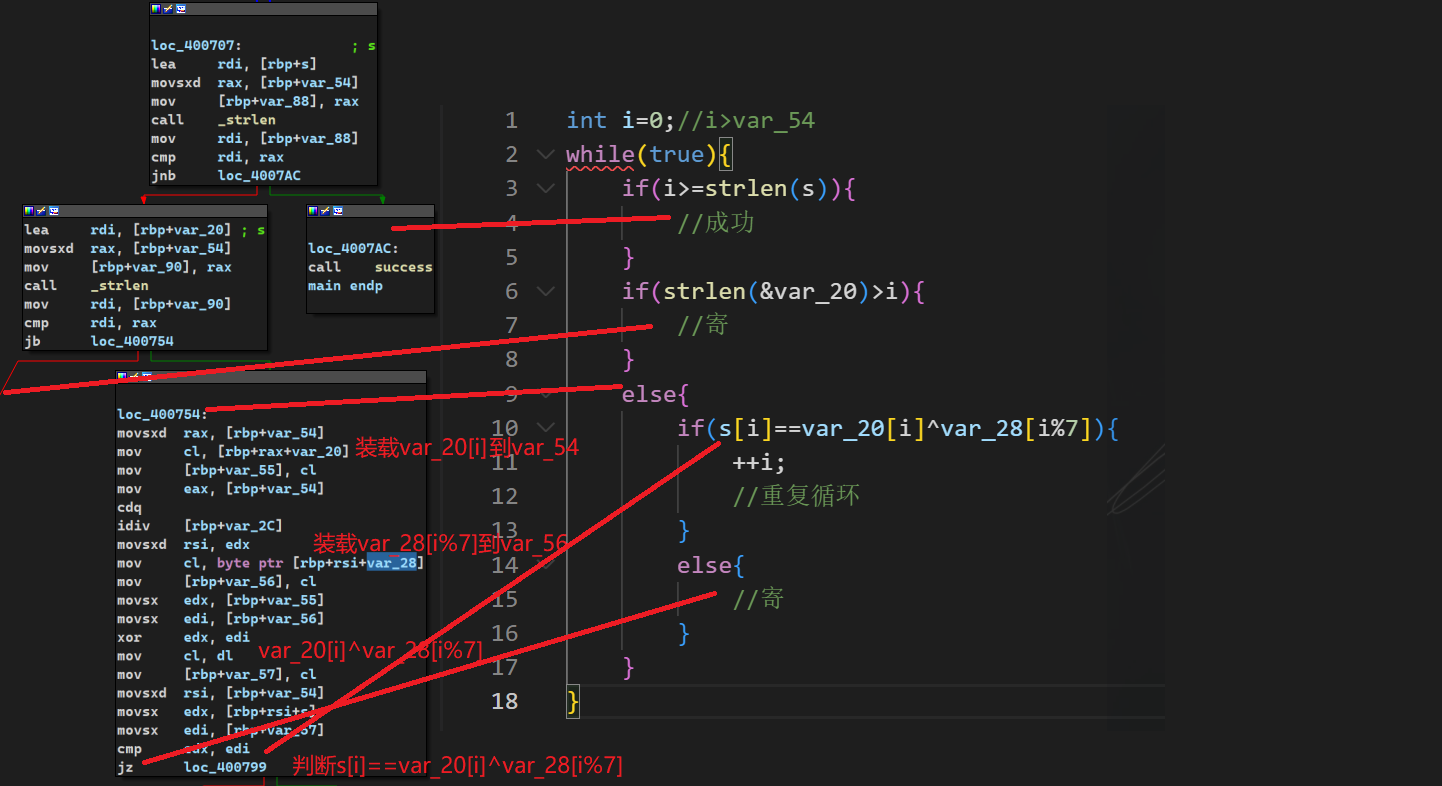
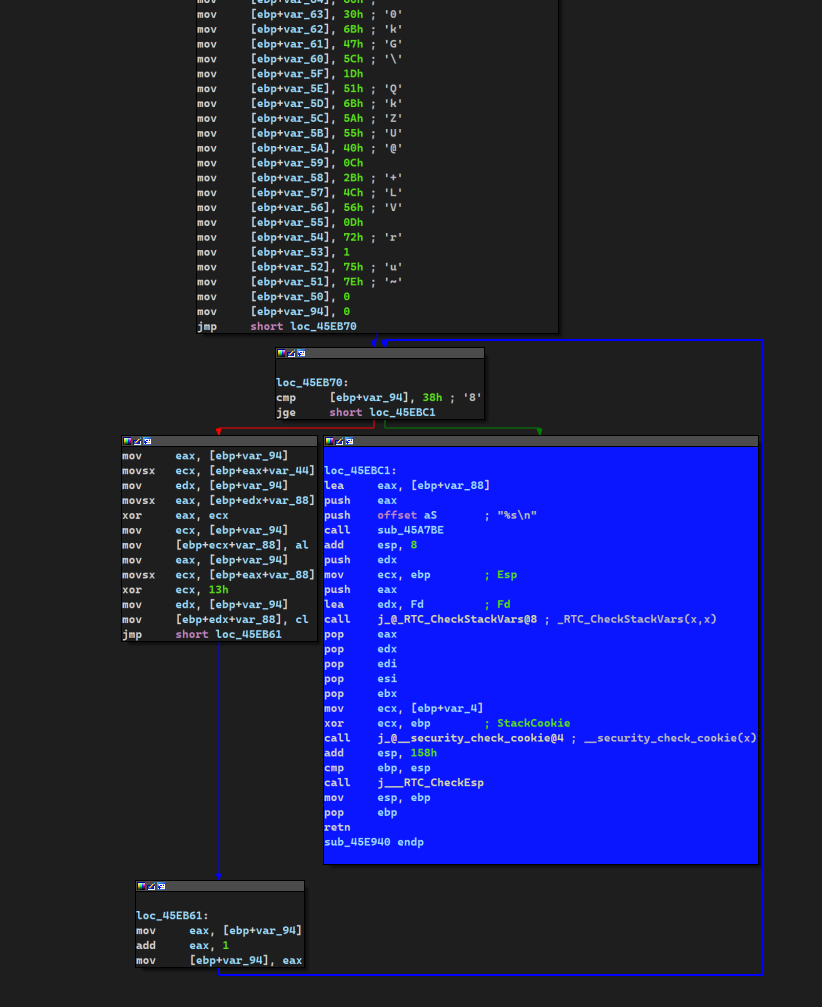
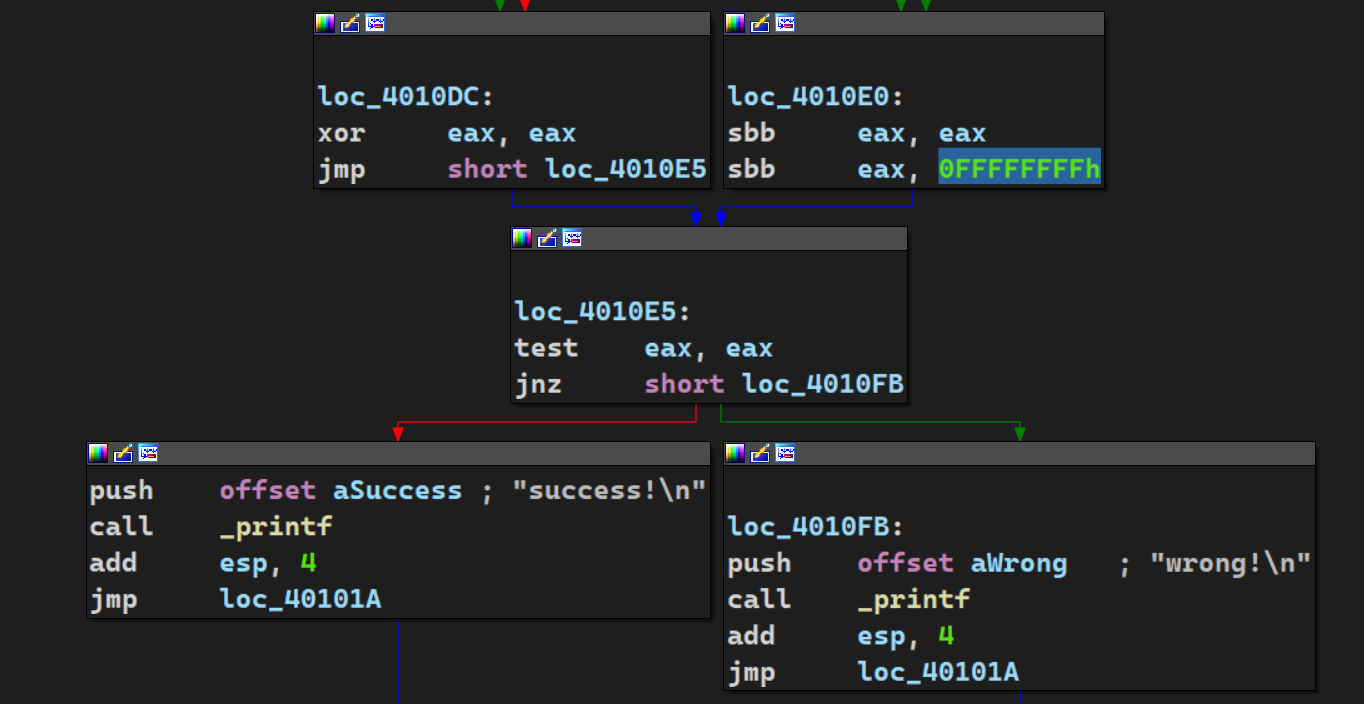
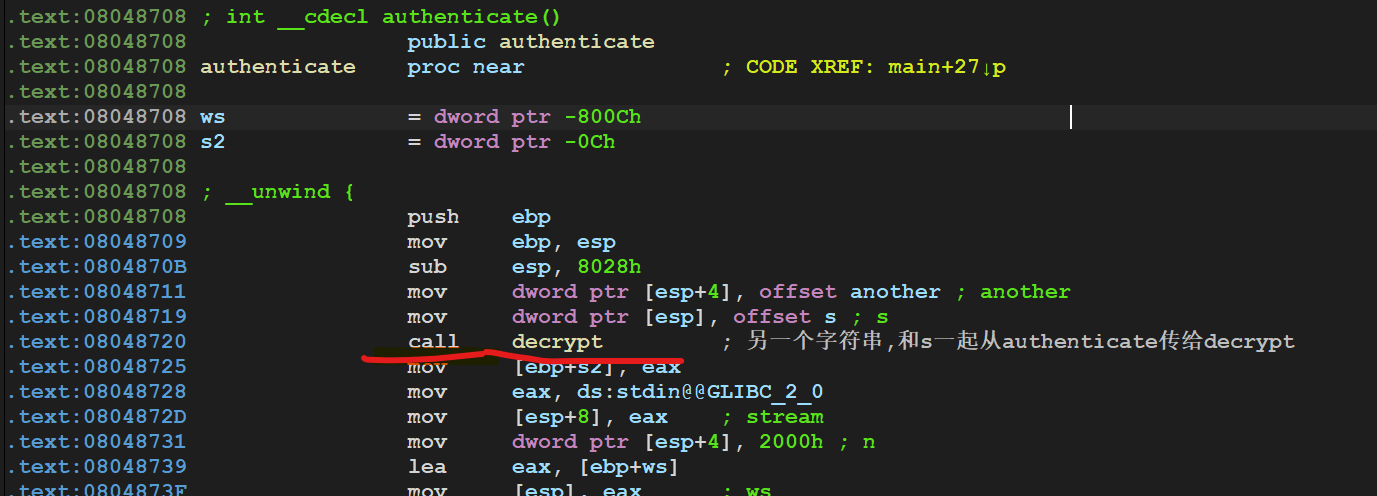
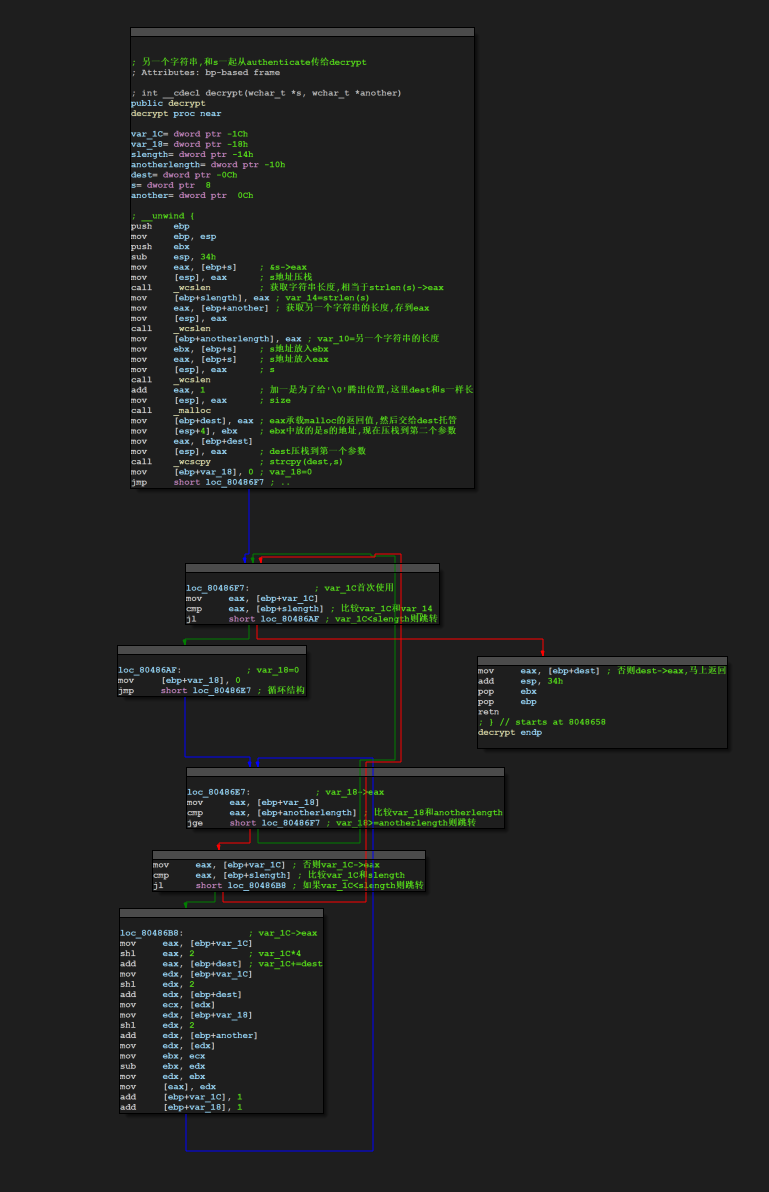
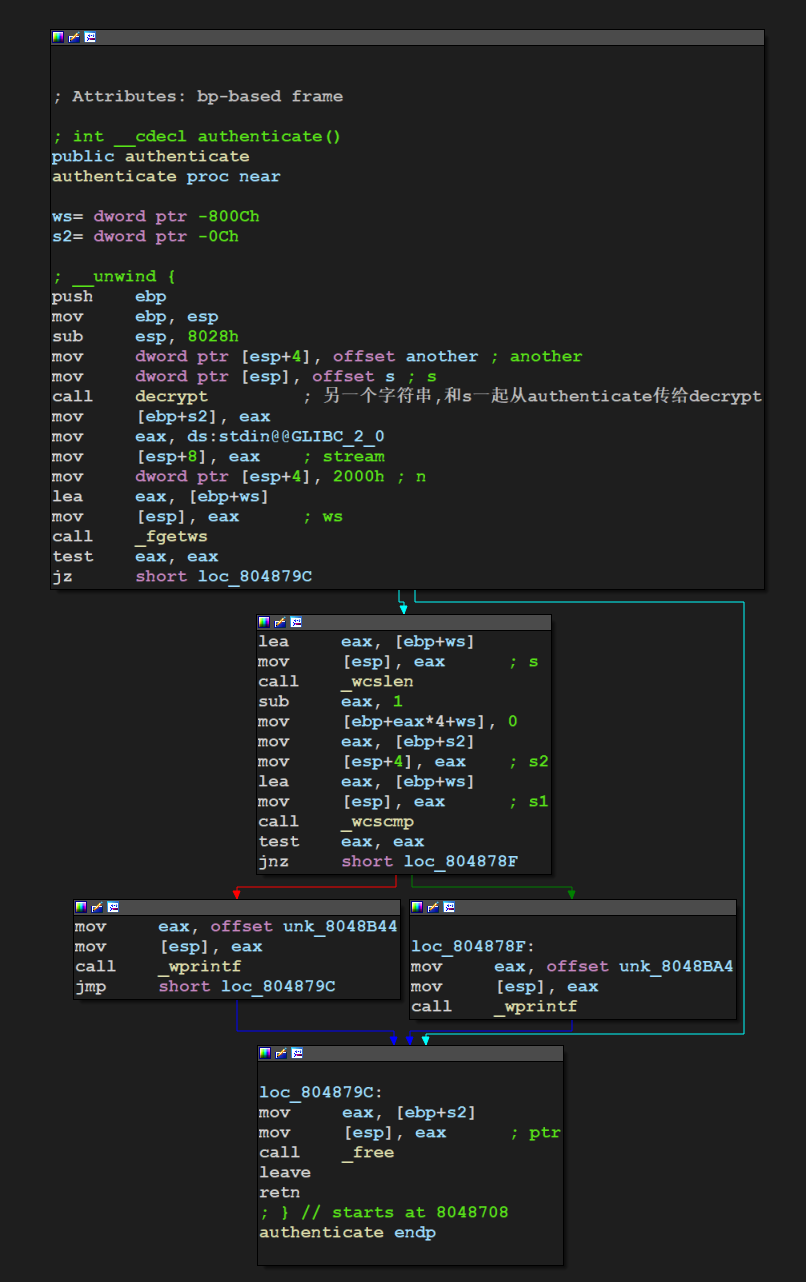
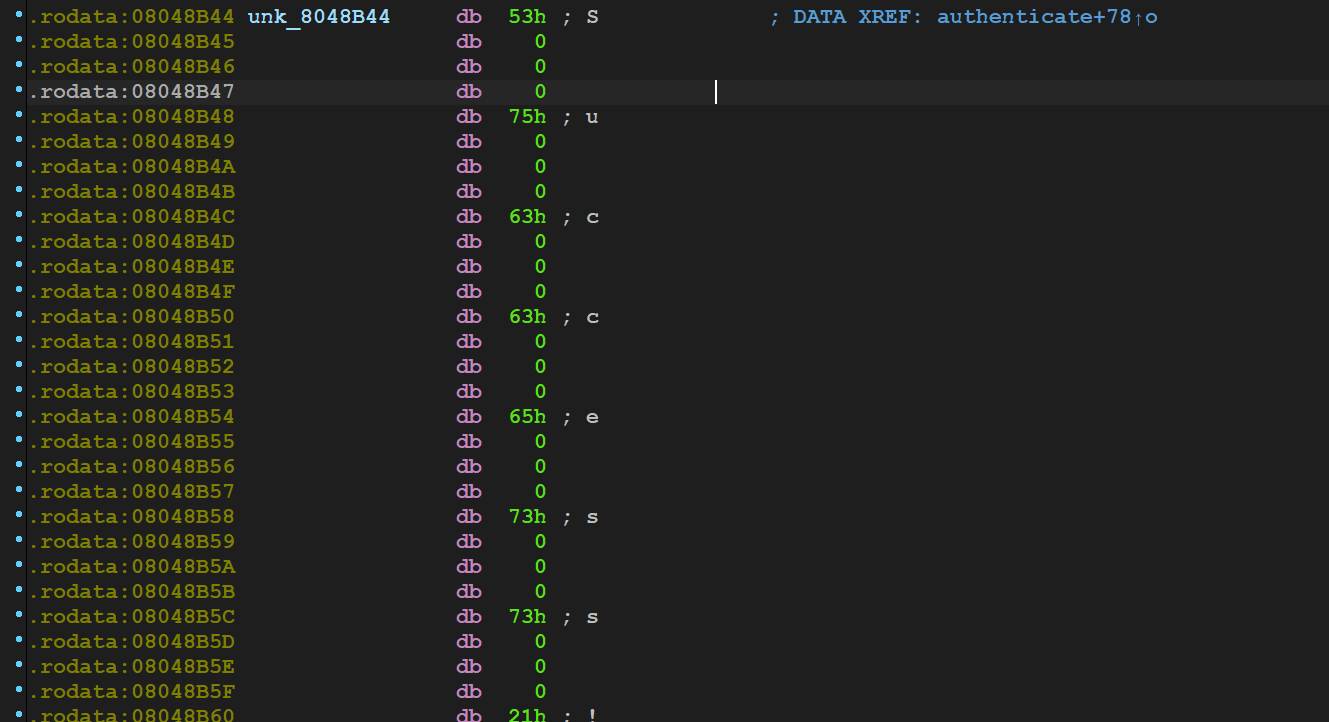
3.事先存在的密文和密钥放在哪里?"Access denied"等字样又放在那里?
在authenticate函数里面双击s观察s的存储
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
.rodata:08048AA8 ; const wchar_t s .rodata:08048AA8 s db 3Ah ; DATA XREF: authenticate+11↑o .rodata:08048AA9 db 14h .rodata:08048AAA db 0 ;蜜汁0 .rodata:08048AAB db 0 ;蜜汁0 .rodata:08048AAC dd 1436h .rodata:08048AB0 db 37h ; 7 .rodata:08048AB1 db 14h .rodata:08048AB2 db 0 ;蜜汁0 .rodata:08048AB3 db 0 .rodata:08048AB4 db 3Bh ; ; .rodata:08048AB5 db 14h .rodata:08048AB6 db 0 .rodata:08048AB7 db 0 .rodata:08048AB8 db 80h .rodata:08048AB9 db 14h .rodata:08048ABA db 0 .rodata:08048ABB db 0 ...
intmain() { int index = 0; for (int i = 0; i < 38; i++) { index = i % 5; s[i] -= another[index]; swprintf(&ans[i], L"%s", &s[i]); } printf("%ls", ans); return0; }
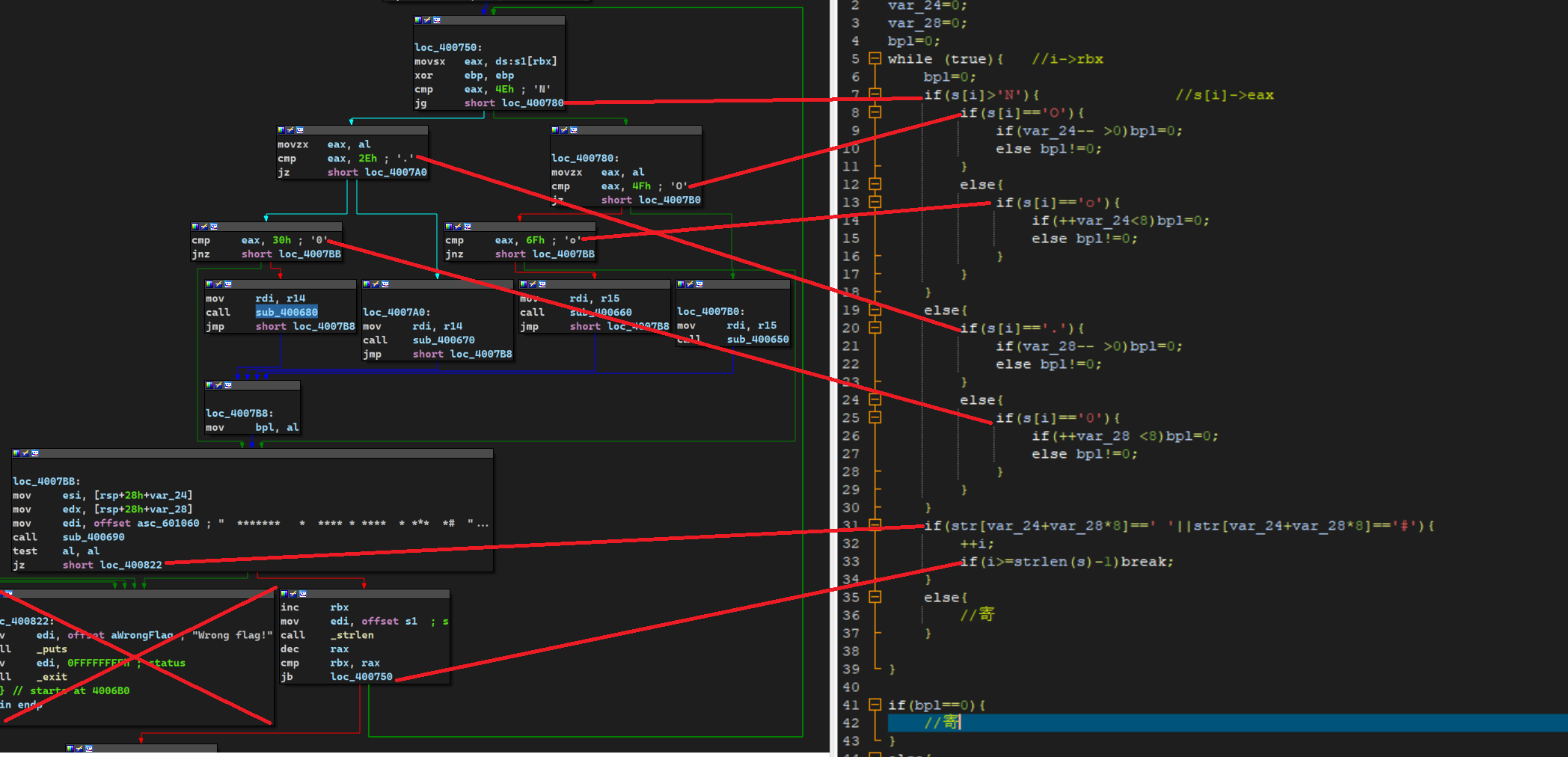
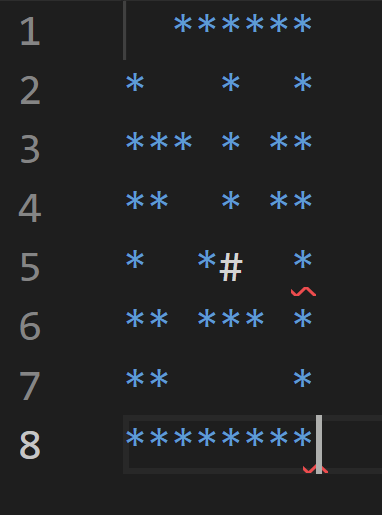
char directors[20];//移动方向 boolDFS(constint &x, constint &y, int depth){
if (x < 0 || x > 8 || y < 0 || y > 8) returnfalse;//粗略条件剪枝 if (visited[x][y]) returnfalse;//记忆化搜索剪枝 visited[x][y] = true;//设置访问过 int sum = x + 8 * y;//计算映射值 if (isLegal(sum) == false) returnfalse;//不合法,剪枝 path[depth].setCoordinate(x, y);//合法,记录路径 if (sum == 36) {//判断映射值是否已经为终点值36 returntrue; }
//向其他状态转移 directors[depth + 1] = 'o';//方向数组,记录转义方向 if (DFS(x + 1, y, depth + 1)) returntrue;
directors[depth + 1] = '0'; if (DFS(x, y + 1, depth + 1)) returntrue;
directors[depth + 1] = 'O'; if (DFS(x - 1, y, depth + 1)) returntrue;
directors[depth + 1] = '.'; if (DFS(x, y - 1, depth + 1)) returntrue; returnfalse; }
intmain(){ if (DFS(0, 0, 0)) {//从x=0,y=0,深度depth=0开始 //如果成功da则打印方向数组 for (int i = 1; i < 20; ++i) { cout << directors[i]; }
The keywords _stdcall and _cdecl specify
32-bit calling conventions. That's why they are not relevant for 64-bit
programs (i.e. x64). On x64, there is only the standard
calling convention and the extended __vectorcall
calling convenction.
Why does x64 use mov rather than push? I
assume it's just more efficient and wasn't available in x86.
That is not the reason. Both of these instructions also exist in x86
assembly language.
效率并且是否可实现不是原因.这两种指令(push和mov)在x86汇编语言中都存在
The reason why your compiler is not emitting a push
instruction for the x64 code is probably because it must adjust the
stack pointer directly anyway, in order to create 32 bytes of "shadow
space" for the called function. See this
link (which was provided by @NateEldredge) for further information
on "shadow space".
rbp is the frame pointer on x86_64. In your generated
code, it gets a snapshot of the stack pointer (rsp) so that
when adjustments are made to rsp (i.e. reserving space for
local variables or pushing values on to the stack), local
variables and function parameters are still accessible from a constant
offset from rbp.
A lot of compilers offer frame pointer omission as an optimization
option; this will make the generated assembly code access variables
relative to rsp instead and free up rbp as
another general purpose register for use in functions.
In the case of GCC, which I'm guessing you're using from the AT&T
assembler syntax, that switch is -fomit-frame-pointer. Try
compiling your code with that switch and see what assembly code you get.
You will probably notice that when accessing values relative to
rsp instead of rbp, the offset from the
pointer varies throughout the function.
The __stdcall calling convention is
used to call Win32 API functions. The callee cleans the stack, so the
compiler makes vararg functions
__cdecl. Functions that use this calling
convention require a function prototype. The
__stdcall modifier is
Microsoft-specific.
By value, unless a pointer or reference
type is passed. 除非参数是指针或者引用类型,否则采用值传递
Stack-maintenance
responsibility 栈维护
Called function pops its own arguments
from the stack. 被调用者自己清理自己用到的栈
Name-decoration
convention 命名修饰规则
An underscore (_) is prefixed
to the name. The name is followed by the at sign (@)
followed by the number of bytes (in decimal) in the argument list.
Therefore, the function declared as
int func( int a, double b ) is decorated as follows:
_func@12 下划线开头,然后@,然后是十进制表示的参数表字节大小. 因此int func(int a,double b)将会被修饰为_func@12(int四个字节+double八个字节)
The Microsoft-specific__thiscall calling convention is used on
C++ class member functions on the x86 architecture. It's the default
calling convention used by member functions that don't use variable
arguments (vararg functions).
Under __thiscall, the callee cleans the
stack, which is impossible for vararg functions. Arguments
are pushed on the stack from right to left. The
this pointer is passed via register ECX,
and not on the stack.
如果函数有__thiscall修饰则被调用者清理自己的栈,因此变参函数难以实现.
函数参数从右向左压栈.this指针通过ECX寄存器传递
On ARM, ARM64, and x64 machines,
__thiscall is accepted and ignored by the
compiler. That's because they use a register-based calling convention by
default.
The Microsoft x64 calling convention[18][19]
is followed on Windows
and pre-boot UEFI (for
long mode on x86-64). The first four
arguments are placed onto the registers. That means RCX, RDX, R8, R9 for
integer, struct or pointer arguments (in that order), and XMM0, XMM1,
XMM2, XMM3 for floating point arguments. Additional arguments are pushed
onto the stack (right to left). Integer return values (similar to x86)
are returned in RAX if 64 bits or less. Floating point return values are
returned in XMM0. Parameters less than 64 bits long are not zero
extended; the high bits are not zeroed.
Structs and unions with sizes that match integers are passed and
returned as if they were integers. Otherwise they are replaced with a
pointer when used as an argument. When an oversized struct return is
needed, another pointer to a caller-provided space is prepended as the
first argument, shifting all other arguments to the right by one
place.[20]
When compiling for the x64 architecture in a Windows context (whether
using Microsoft or non-Microsoft tools), stdcall, thiscall, cdecl, and
fastcall all resolve to using this convention.
In the Microsoft x64 calling convention, it is the caller's
responsibility to allocate 32 bytes of "shadow space" on the stack right
before calling the function (regardless of the actual number of
parameters used), and to pop the stack after the call. The shadow space
is used to spill RCX, RDX, R8, and R9,[21]
but must be made available to all functions, even those with fewer than
four parameters.
The registers RAX, RCX, RDX, R8, R9, R10, R11 are considered volatile
(caller-saved).[22]
RAX, RCX, RDX, R8, R9, R10, R11这些寄存器都是volatile修饰的
image-20220428101247431
The registers RBX, RBP, RDI, RSI, RSP, R12, R13, R14, and R15 are
considered nonvolatile (callee-saved).[22]
RBX, RBP, RDI, RSI, RSP, R12, R13, R14, and R15不用volatile修饰
For example, a function taking 5 integer arguments will take the
first to fourth in registers, and the fifth will be pushed on top of the
shadow space. So when the called function is entered, the stack will be
composed of (in ascending order) the return address, followed by the
shadow space (32 bytes) followed by the fifth parameter.
Calls the _main function which will do initializing stuff
that gcc needs. Call will push the current instruction pointer on the
stack and jump to the address of _main
┌──(root㉿Executor)-[/home/kali] └─# gdb GNU gdb (Debian 10.1-2+b1) 10.1.90.20210103-git Copyright (C) 2021 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty"for details. This GDB was configured as "x86_64-linux-gnu". Type "show configuration"for configuration details. For bug reporting instructions, please see: <https://www.gnu.org/software/gdb/bugs/>. Find the GDB manual and other documentation resources online at: <http://www.gnu.org/software/gdb/documentation/>.
For help, type"help". Type "apropos word" to search for commands related to "word". (gdb)
┌──(root㉿Executor)-[/home/kali/mydir] └─# gdb --silent main.out Reading symbols from main.out... (No debugging symbols found in main.out) #报告没有调试信息 (gdb)
(gdb) file /home/kali/mydir/main.out Load new symbol table from "/home/kali/mydir/main.out"? (y or n) y Reading symbols from /home/kali/mydir/main.out...
(gdb) show language The current source language is "auto; currently c".
查看源文件信息info source
1 2 3 4 5 6 7 8 9
(gdb) info source Current source file is main.c Compilation directory is /home/kali/mydir Located in /home/kali/mydir/main.c Contains 10 lines. Source language is c. Producer is GNU C17 11.2.0 -mtune=generic -march=x86-64 -g -Og -fasynchronous-unwind-tables. Compiled with DWARF 2 debugging format. Does not include preprocessor macro info.
查看可以设置的程序语言set language
1 2
(gdb) set language Requires an argument. Valid arguments are auto, local, unknown, ada, asm, c, c++, d, fortran, go, minimal, modula-2, objective-c, opencl, pascal, rust.
查看程序运行状态info program
1 2
(gdb) info prog The program being debugged is not being run.
设置信息
设置命令行参数set args <参数1> <参数2>...
1 2 3
(gdb) set args 1 2 3 (gdb) show args Argument list to give program being debugged when it is started is "1 2 3".
如果在启动时有指定参数,此时再用set指定参数则会覆盖启动时设置的参数
设置语言'set language <语言>'
1
(gdb) set language c
运行
运行程序run
命令行参数使用启动时指定的参数或者set
args设置的参数,如果都没有给定则无参数执行
如果有断点则程序在第一个断点处停止,否则直接运行完.
带参数运行run <参数1> <参数2>...
此参数将会直接作为运行参数,覆盖前面设置的参数
main停止运行start
start相当于在main函数处下了断点然后run,自动在main开始前停下
运行时
断点
设置断点b <行号>
断点可以运行前设置也可以运行时设置
1 2
(gdb) b 6 Breakpoint 6 at 0x555555555142: file main.c, line 6.
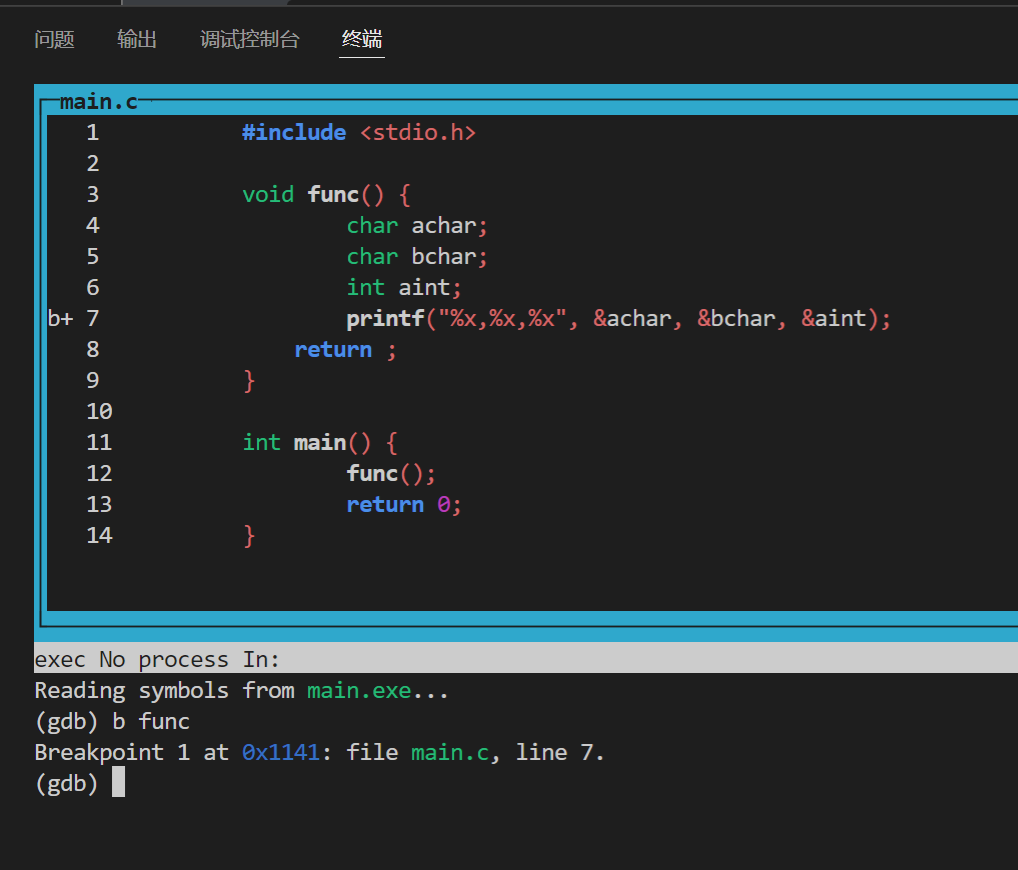
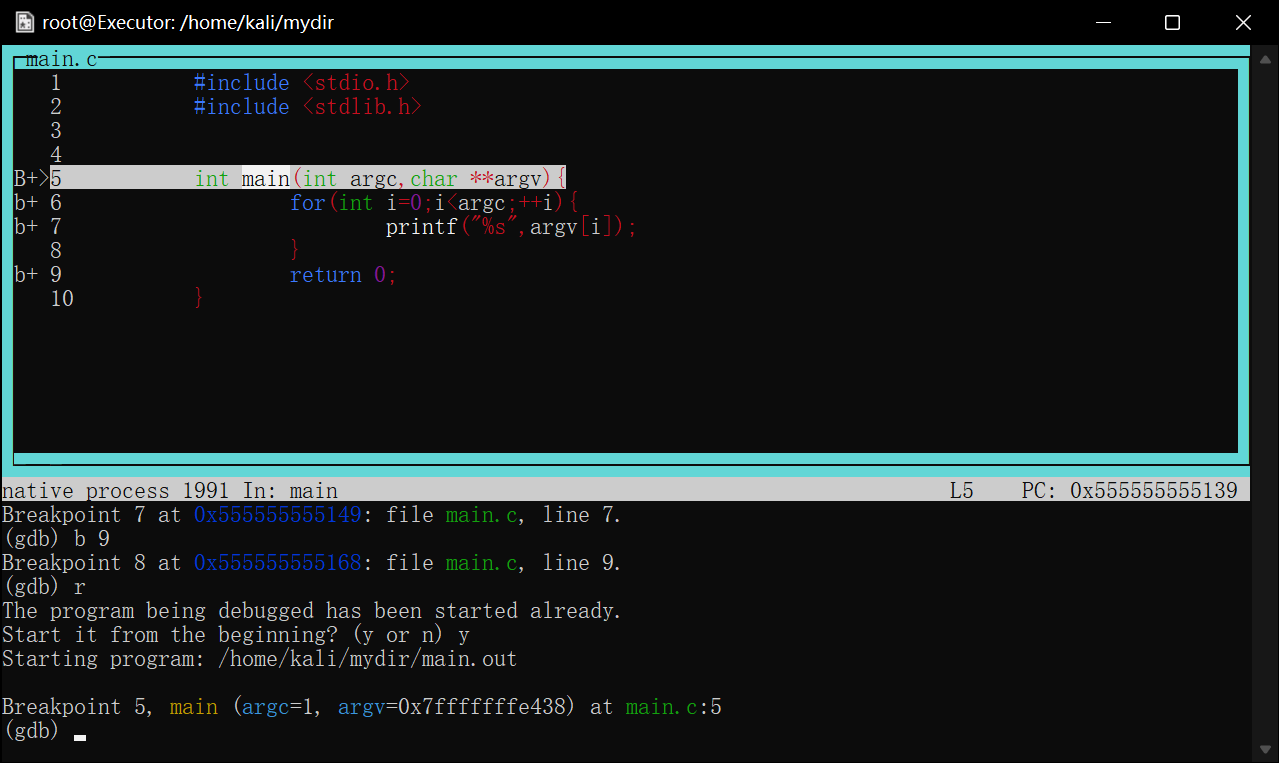
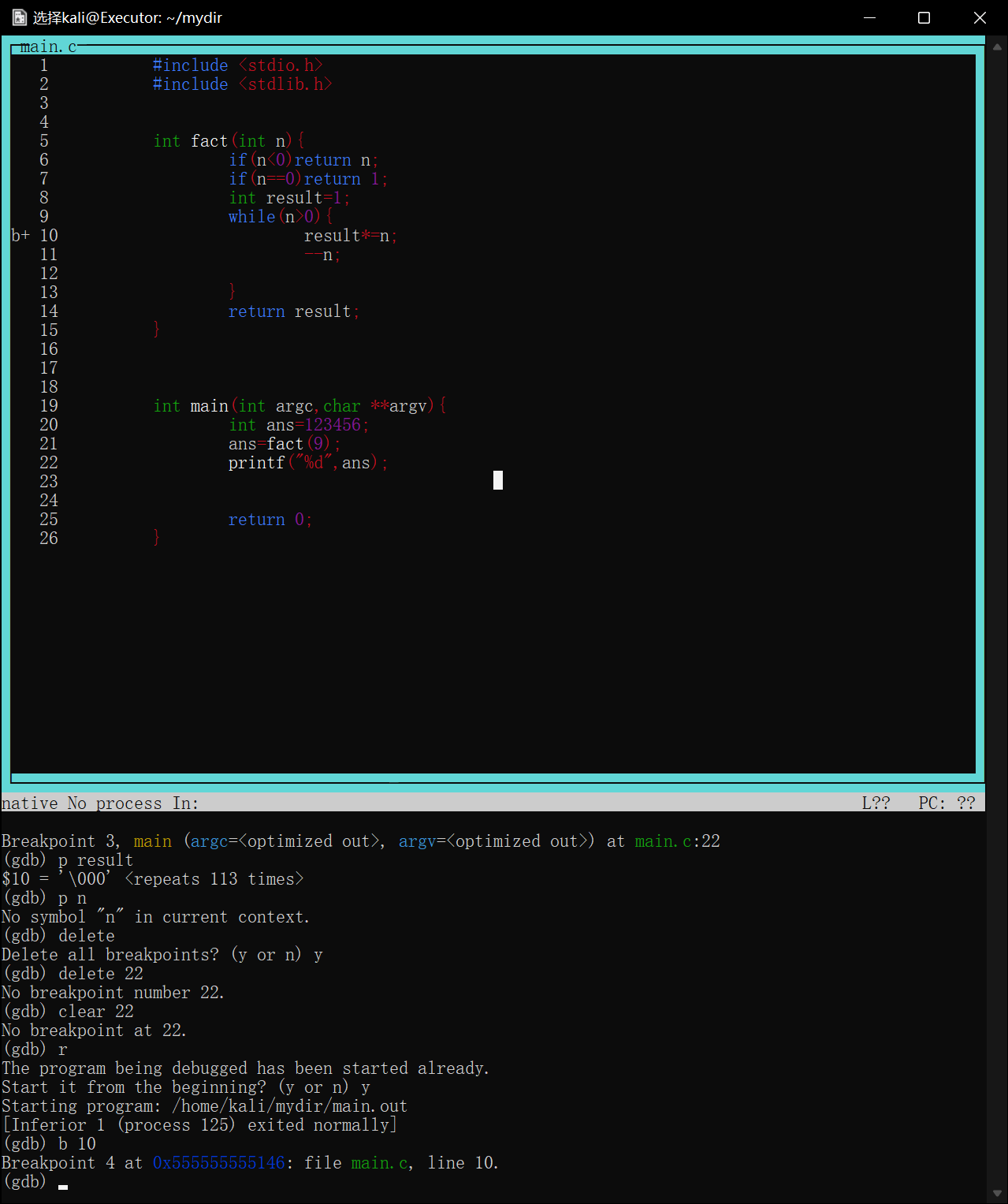
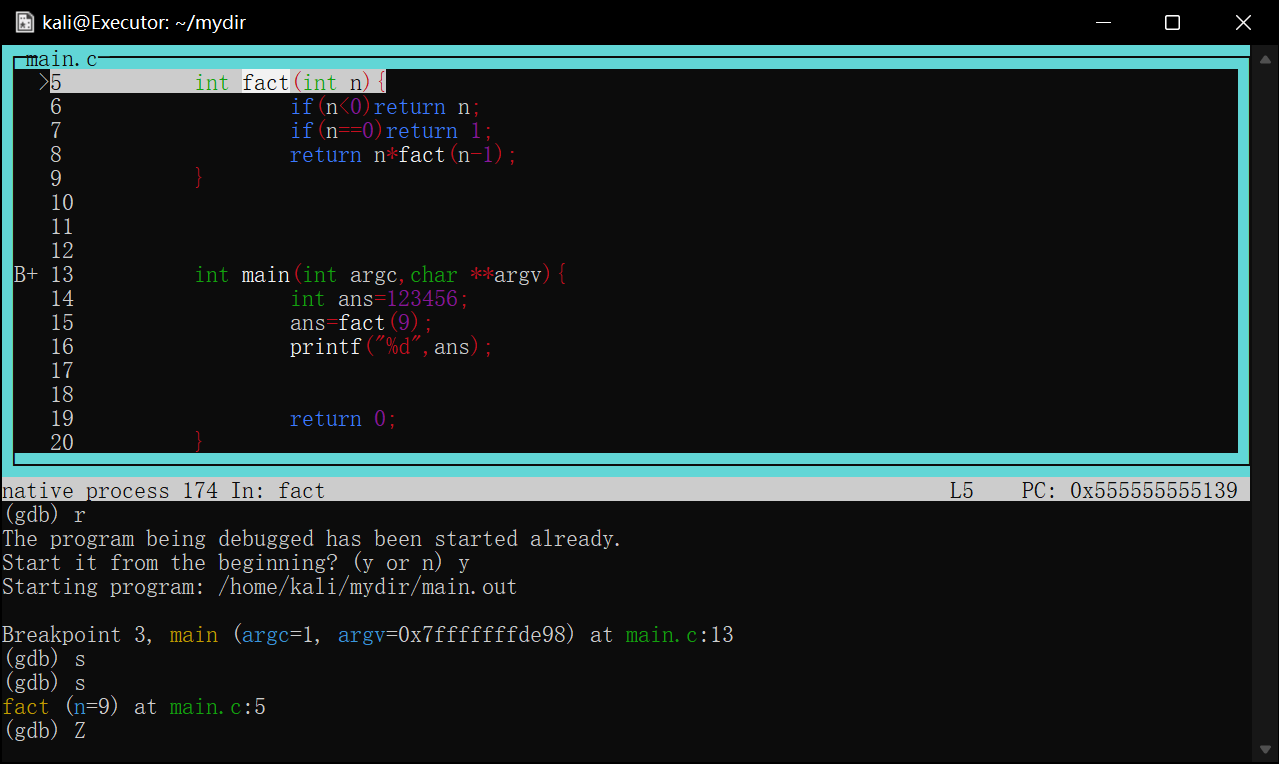
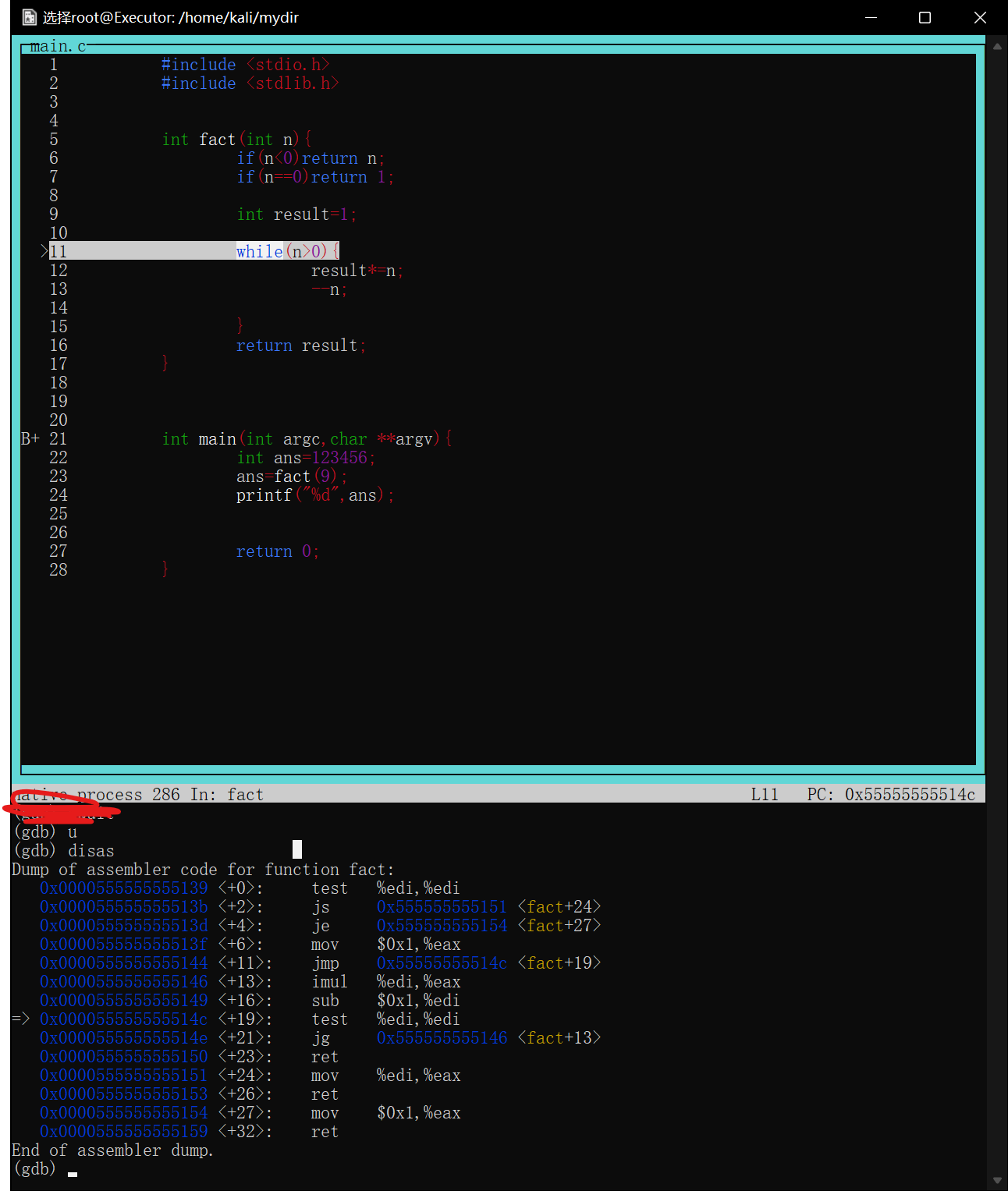
如果以-tui分屏打开,则设置好的断点会显示在行号左侧,大写的B+>意味当前程序暂停的断点
image-20220421213142314
b <函数名>直接给函数下断点
1 2
(gdb) b main Breakpoint 10 at 0x555555555139: file main.c, line 5.
删除断点
delete <断点编号>
注意端点编号不是行号
删除全部断点则不指定编号,直接delete
删除指定行上的断点clear <行号>
条件断点b if <条件>
比如如果没有输入命令行参数时才给main函数下断点
1 2
(gdb) b main if argc==1 #用户没有输入时argc=1,第一个参数是当前程序位置 Breakpoint 11 at 0x555555555139: file main.c, line 5.
查看断点信息info b <断点号>
1 2 3 4 5
Breakpoint 11 at 0x555555555139: file main.c, line 5. (gdb) info b 11 Num Type Disp Enb Address What 11 breakpoint keep y 0x0000555555555139 in main at main.c:5 stop only if argc==1
info b查看所有断点信息
1 2 3 4 5 6
(gdb) info b Num Type Disp Enb Address What 11 breakpoint keep y 0x0000555555555139 in main at main.c:5 stop only if argc==1 12 breakpoint keep y 0x0000555555555142 in main at main.c:6 13 breakpoint keep y 0x0000555555555149 in main at main.c:7
查看信息
print命令
查看函数信息p <函数名>
函数信息也可以在运行前查看
1 2
(gdb) p main $6 = {int (int, char **)} 0x555555555139 <main>
1
{返回值类型(参数1类型,参数2类型)} 函数地址 <函数名>
1 2 3 4
(gdb) whatis main type = int (int, char **) (gdb) ptype main type = int (int, char **)
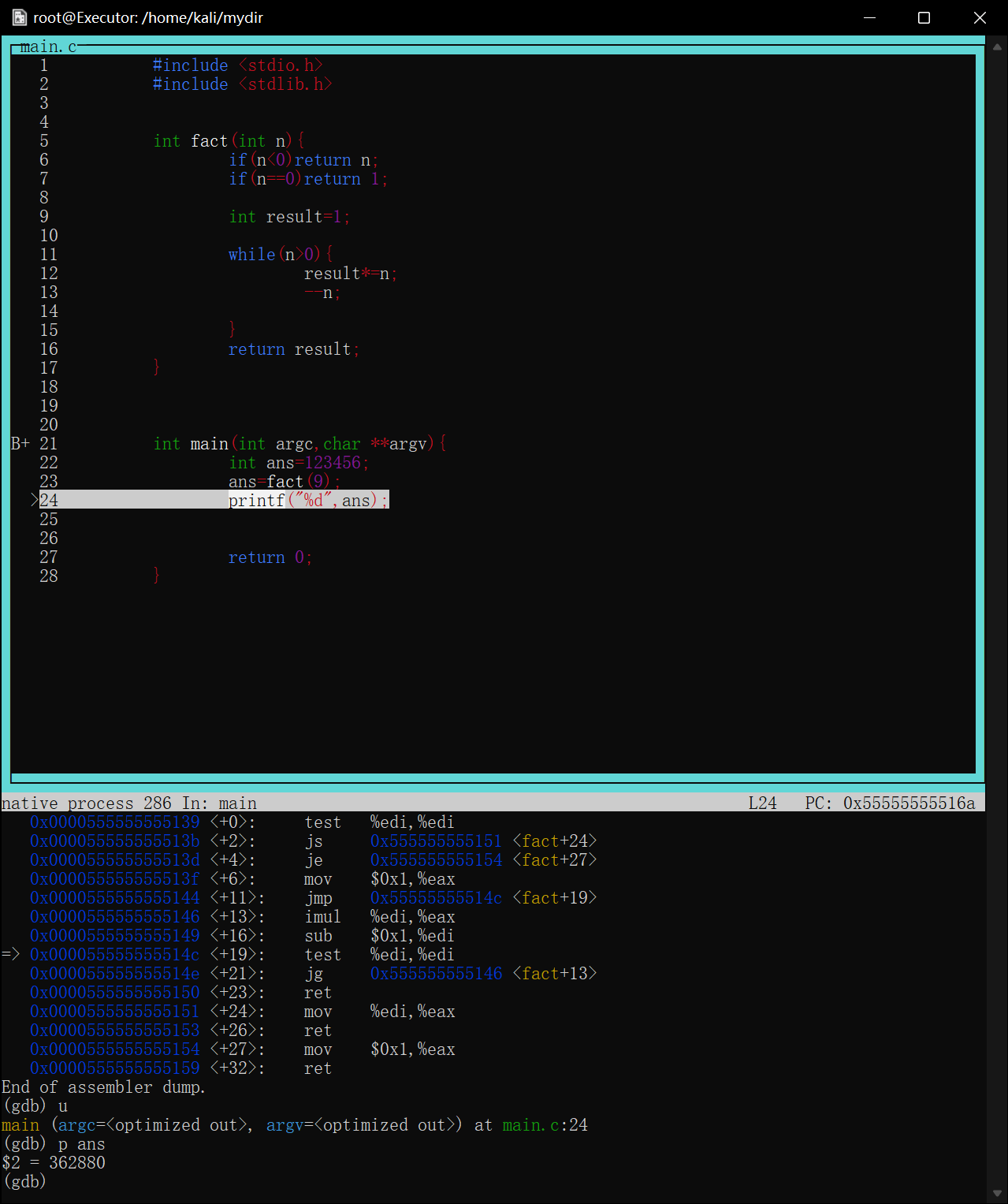
查看变量信息p <变量名>
查看变量信息必须是程序在该变量下文的断点处停下
即当前程序的运行位置必须已经经过变量,并且变量没有消亡
比如函数中的局部变量在函数返回之后就会消亡,只能在函数中断点然后查看断点之前的变量
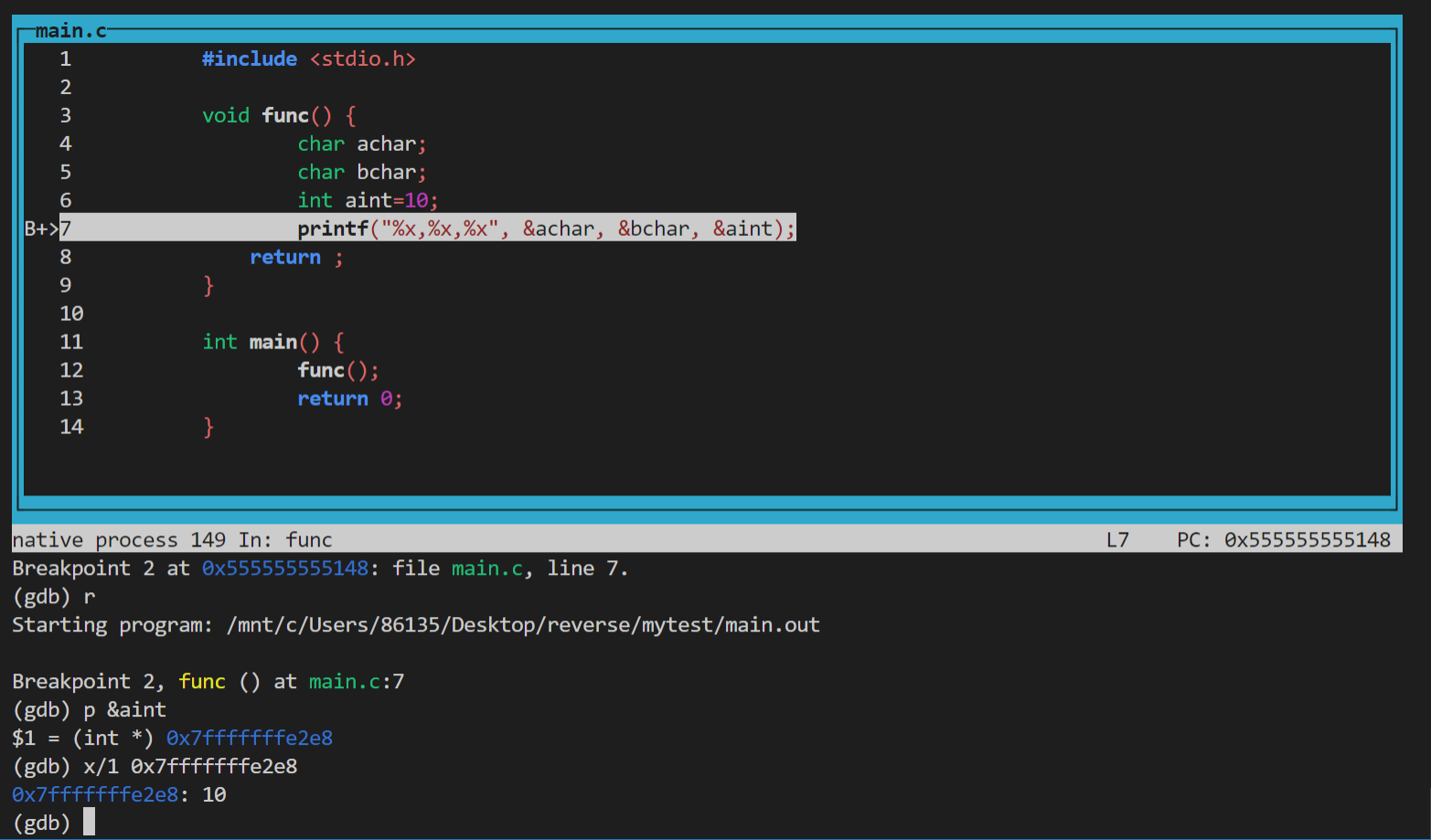
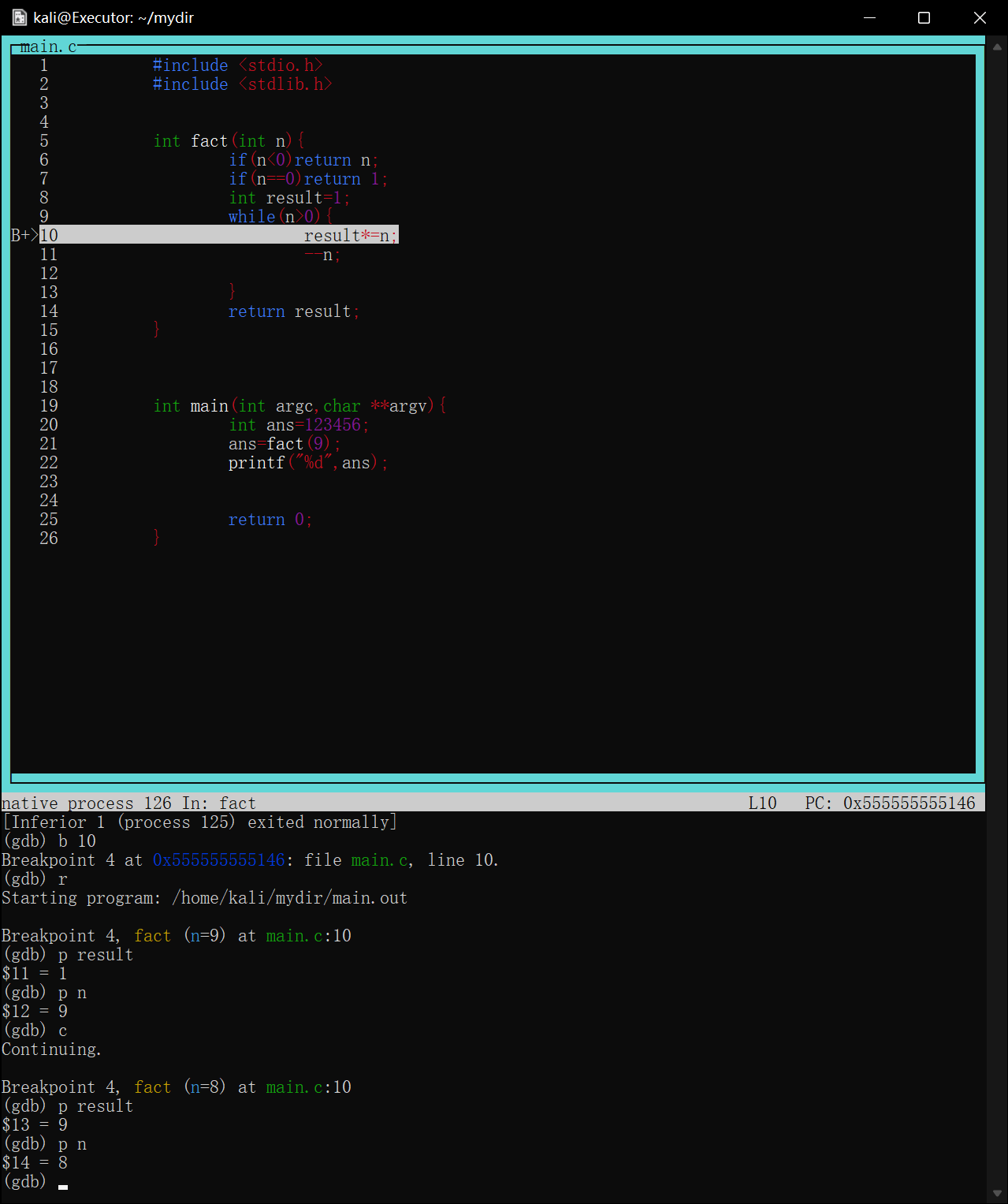
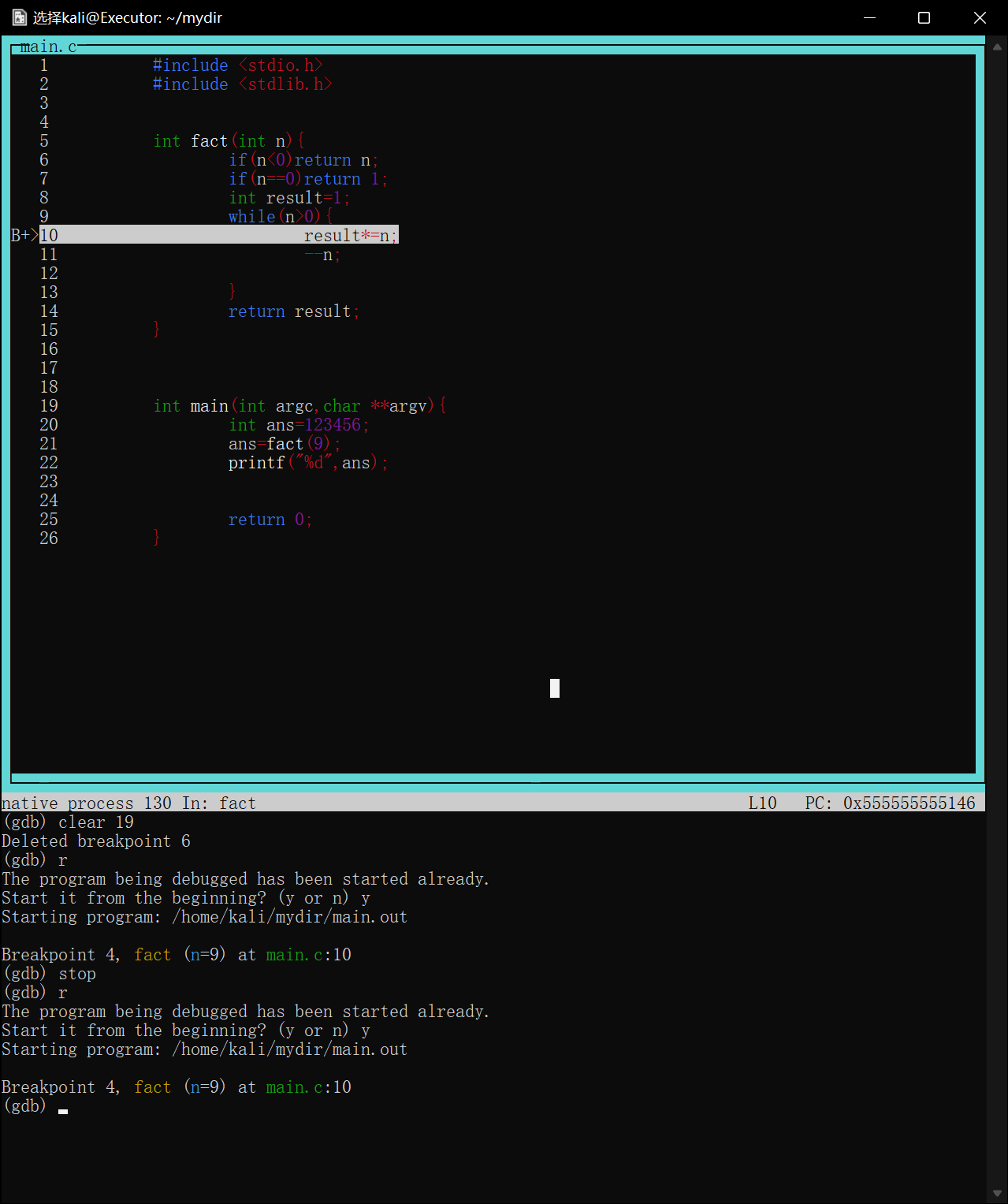
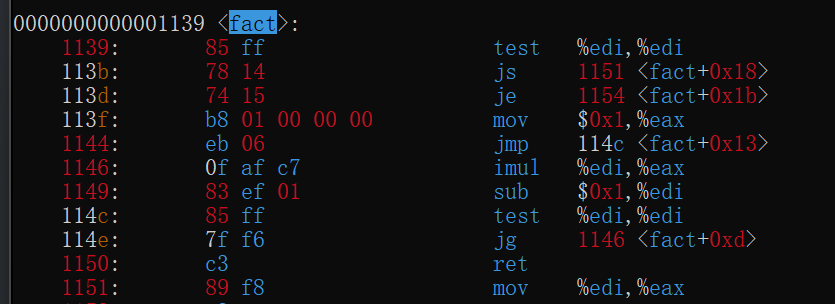
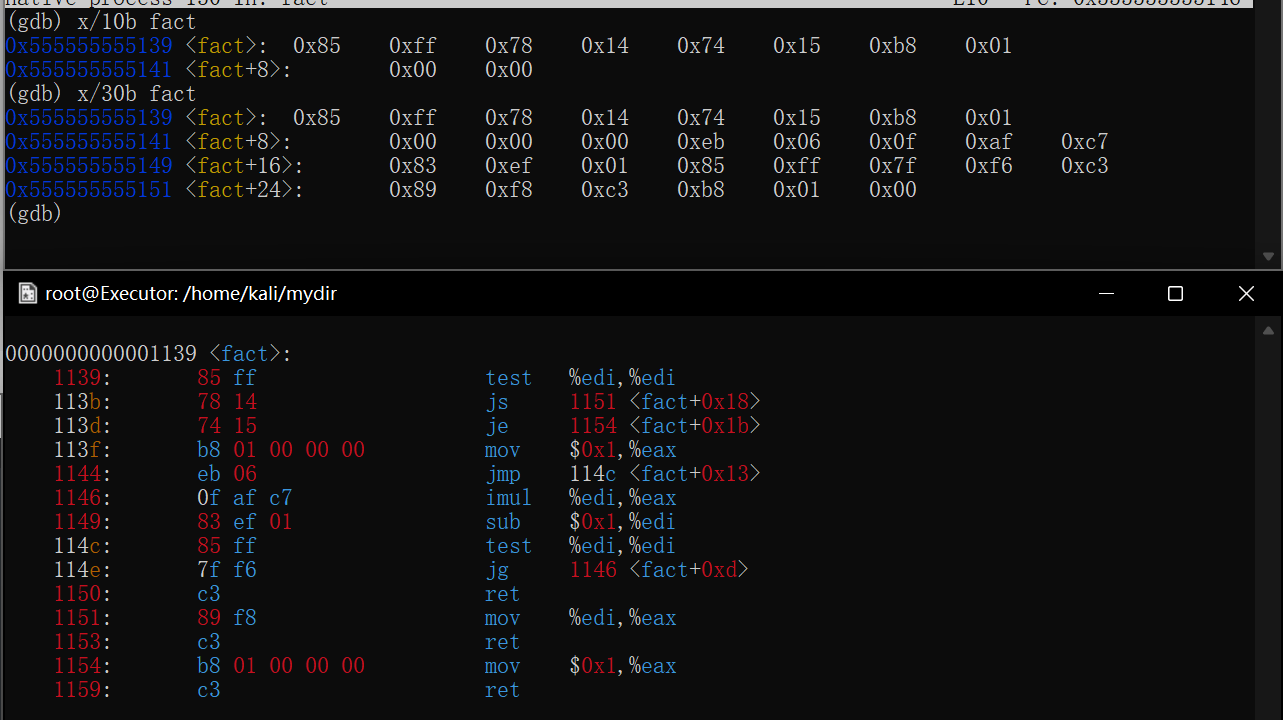
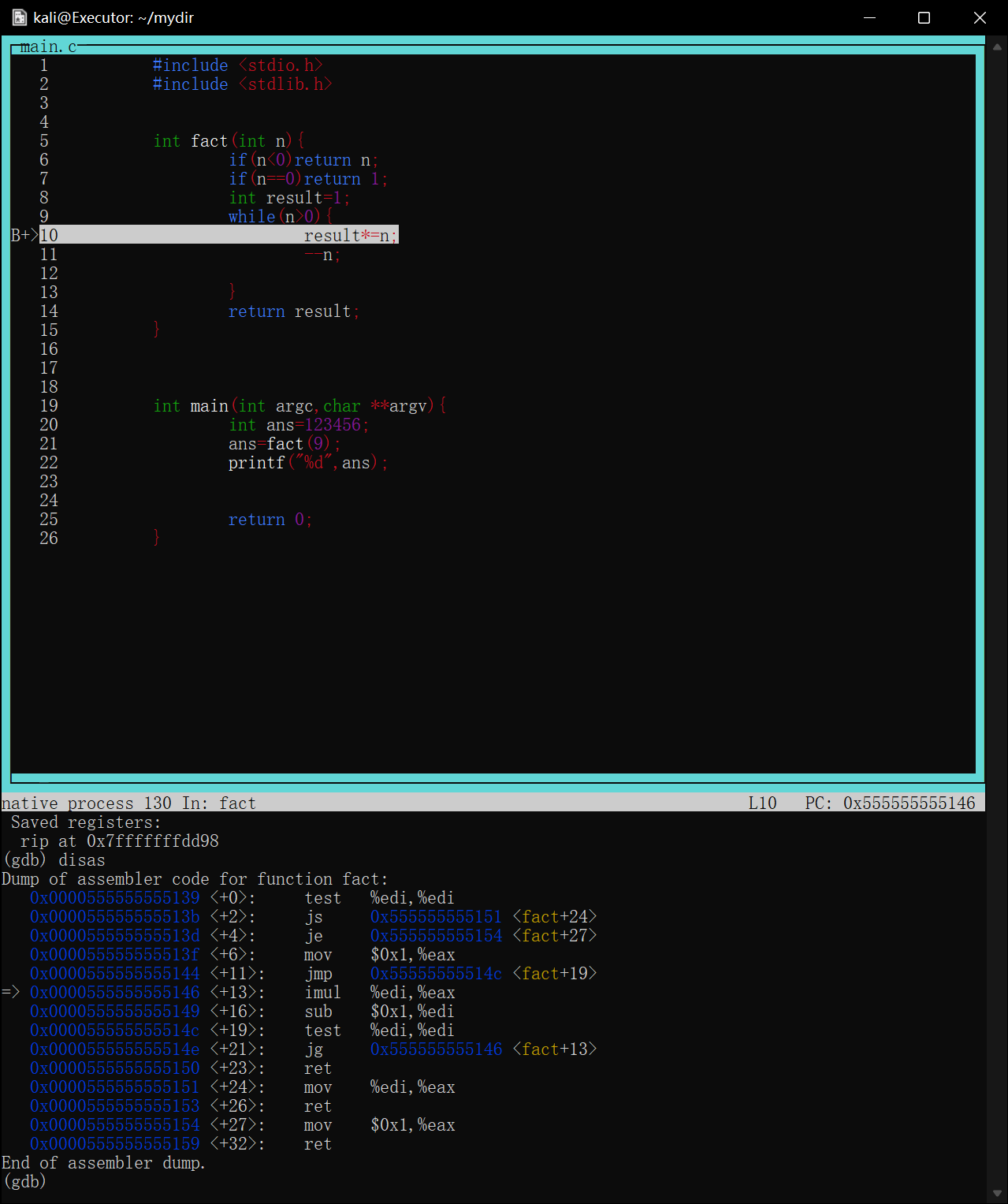
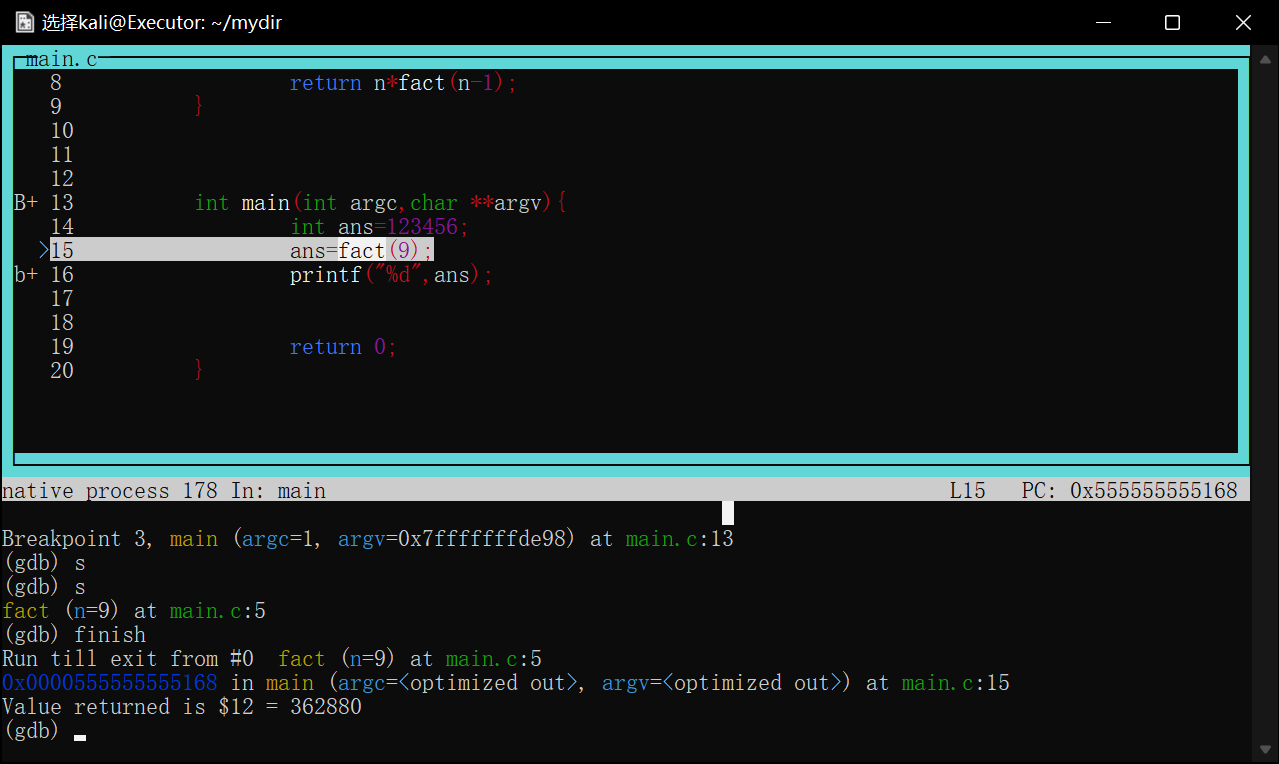
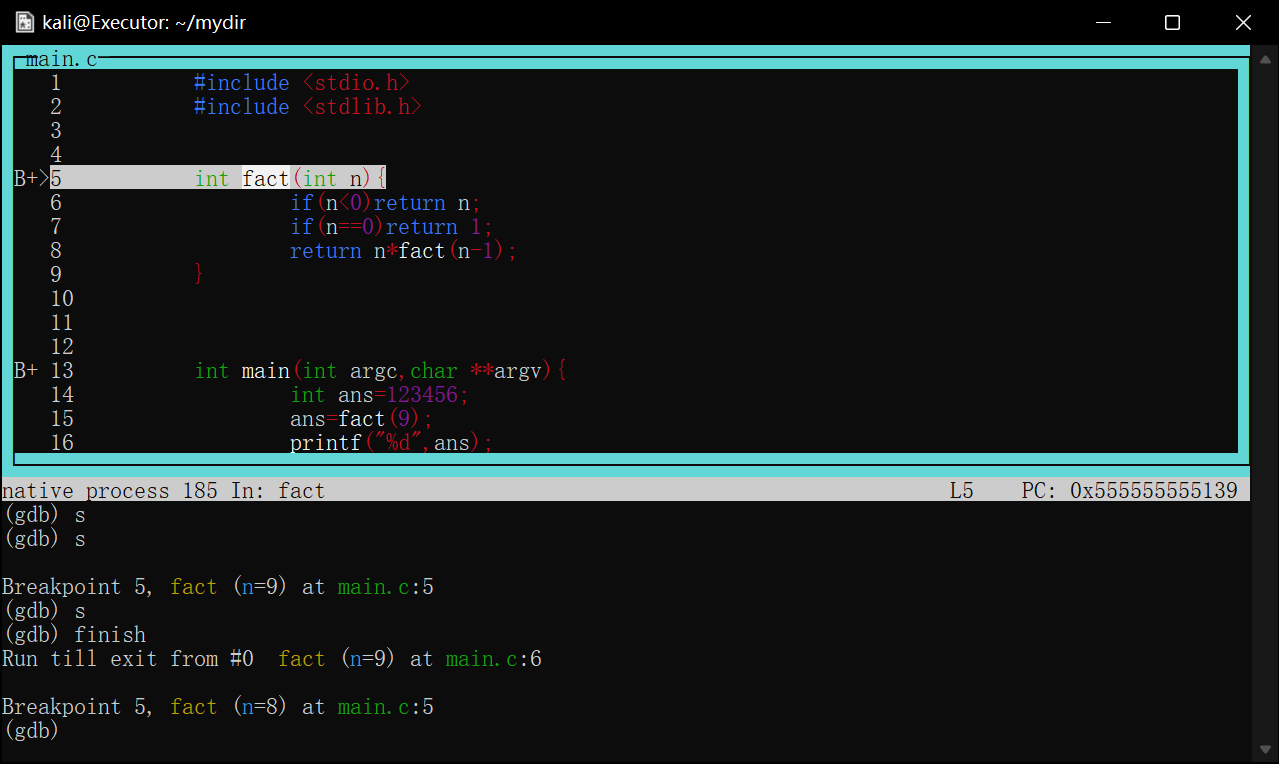
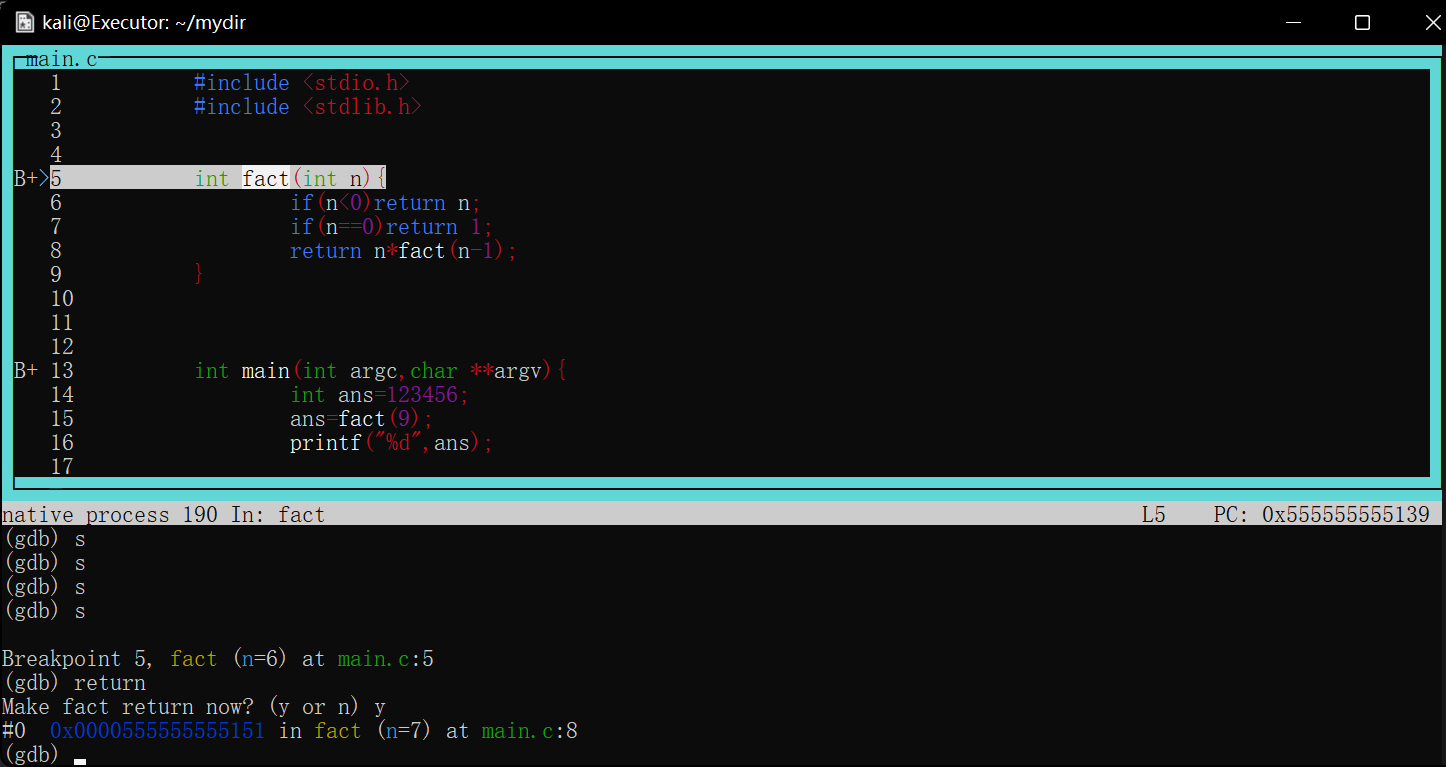
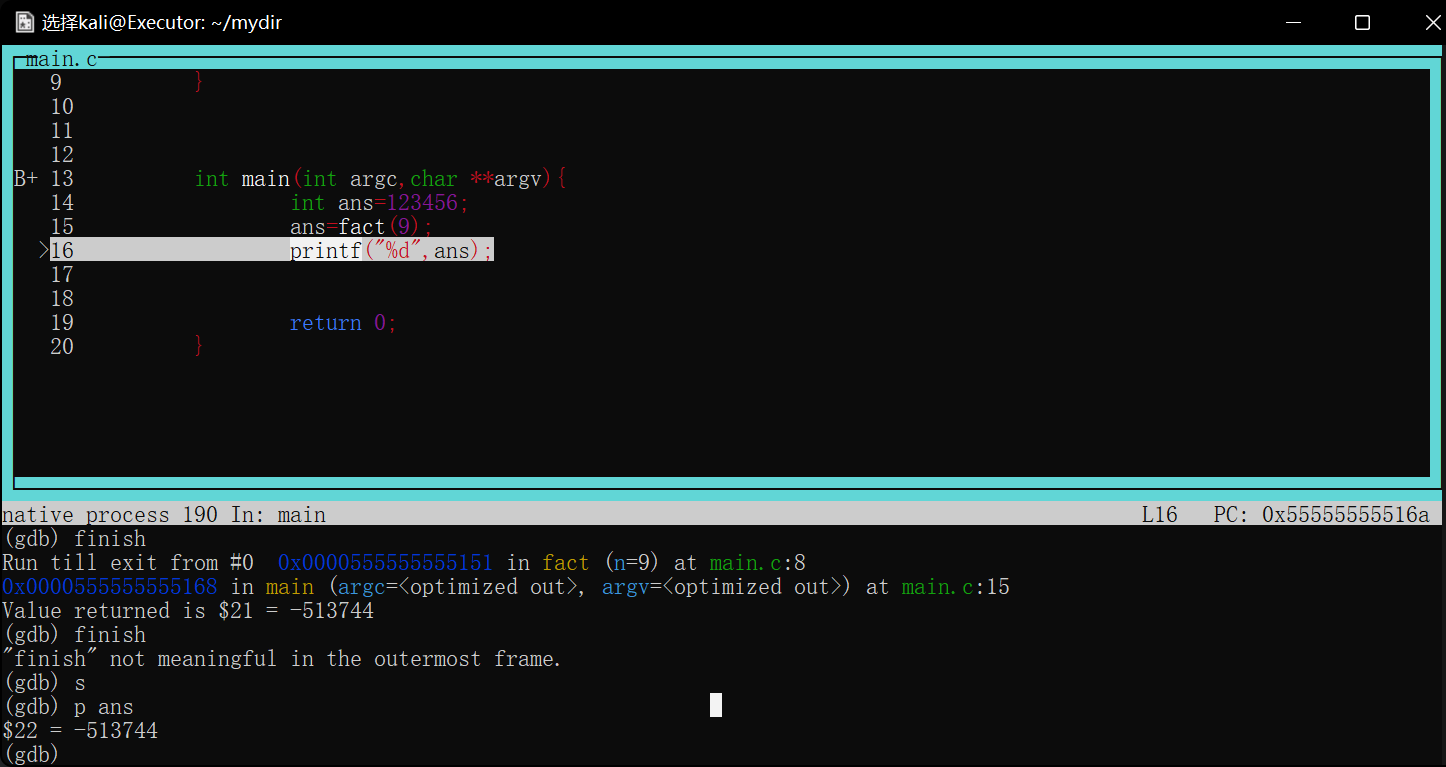
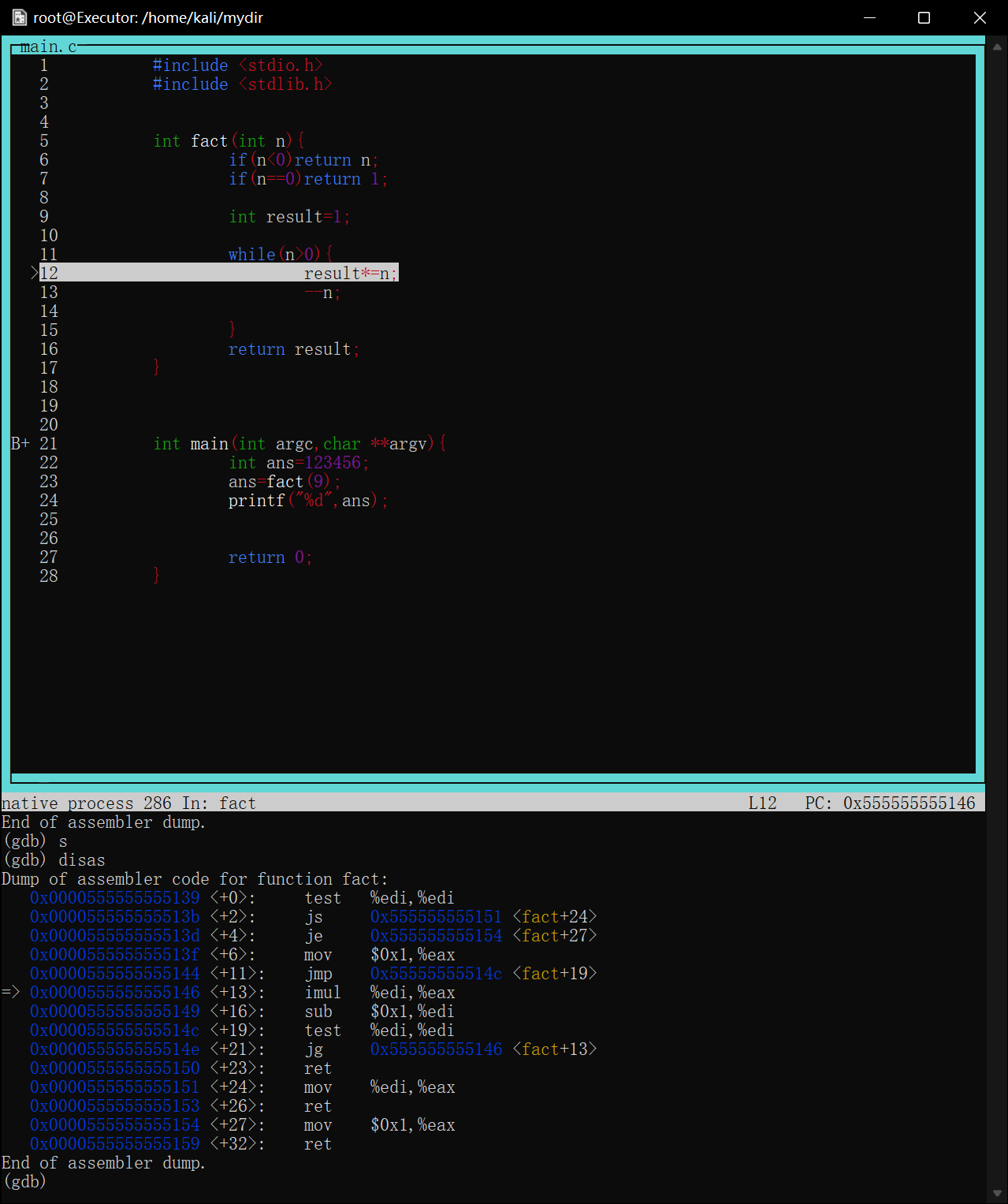
如图调试一个用循环计算阶乘的函数,将断点下在第10行result*=n处
image-20220422175357420
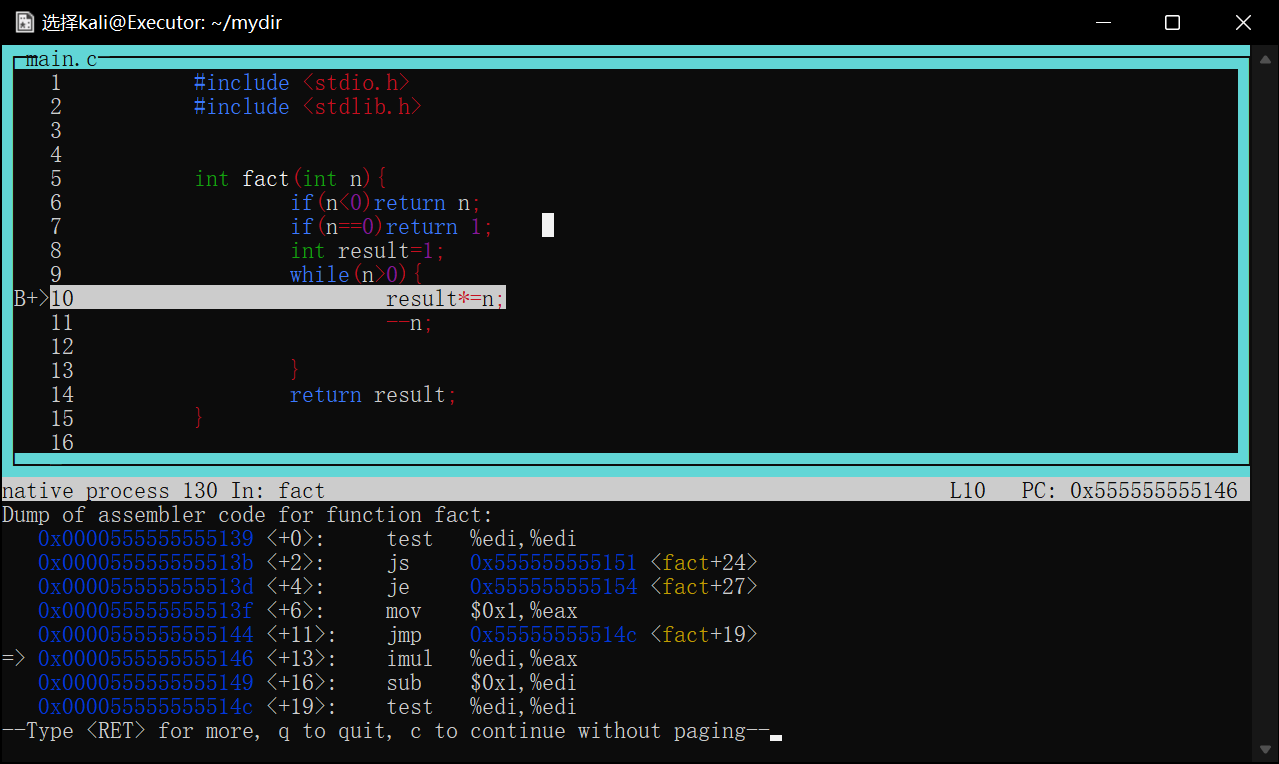
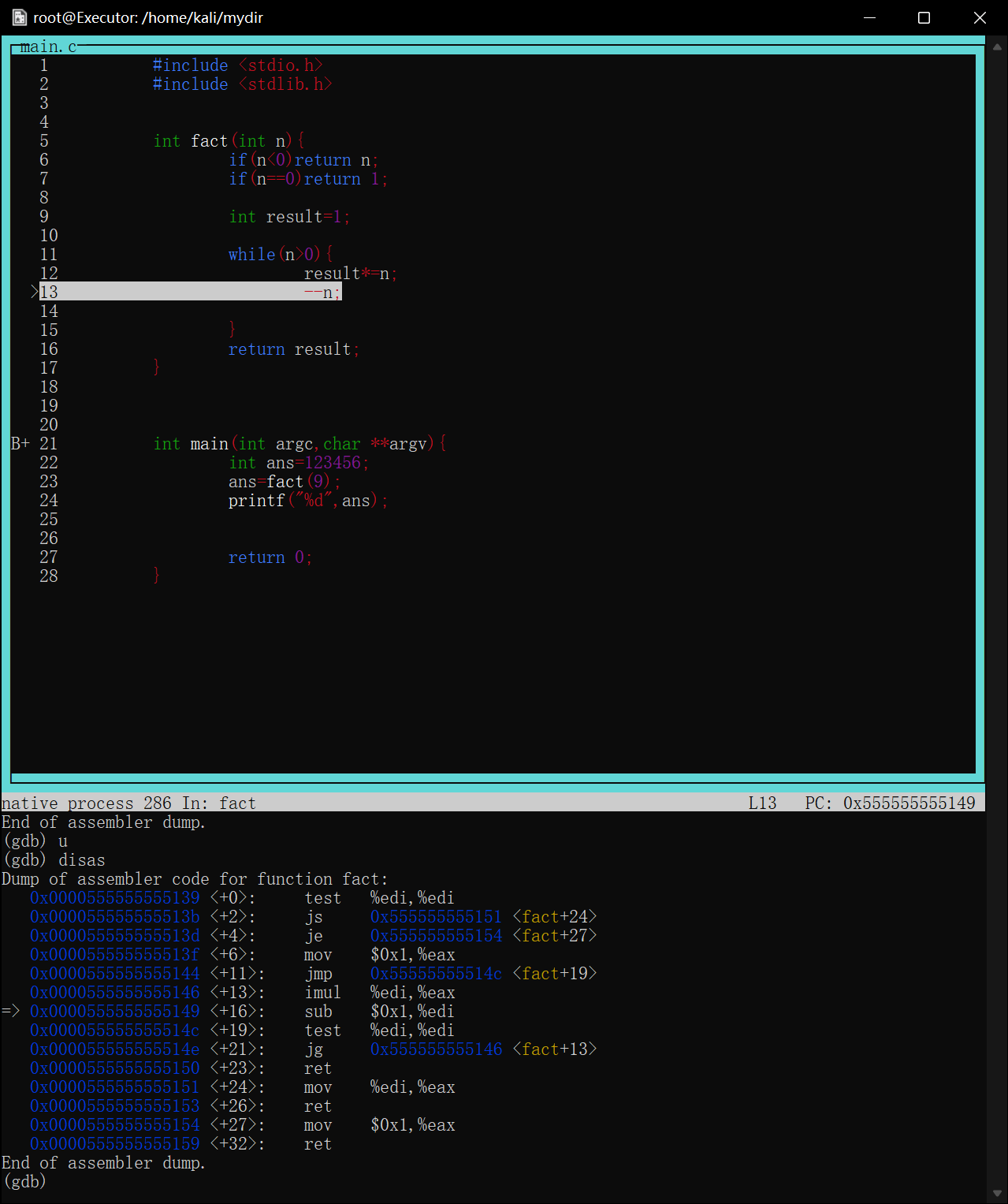
当程序第一次执行到次时会停在result*=n==执行前==的状态
image-20220422175511240
如图第一次在第10行停下,打印result=1
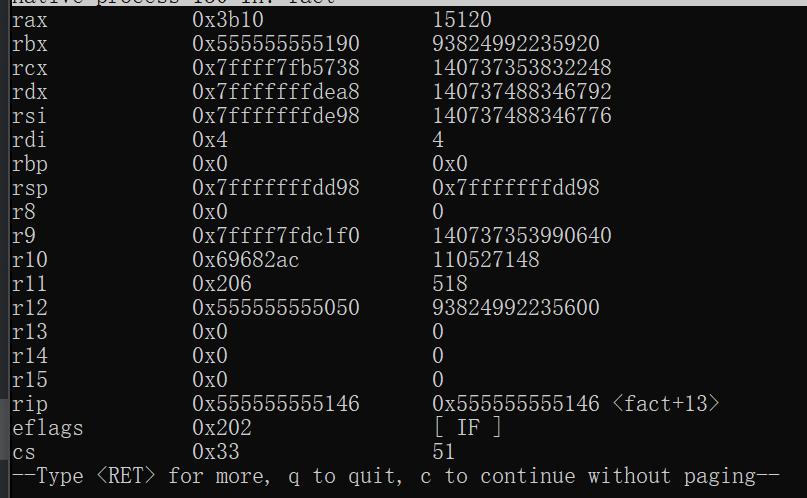
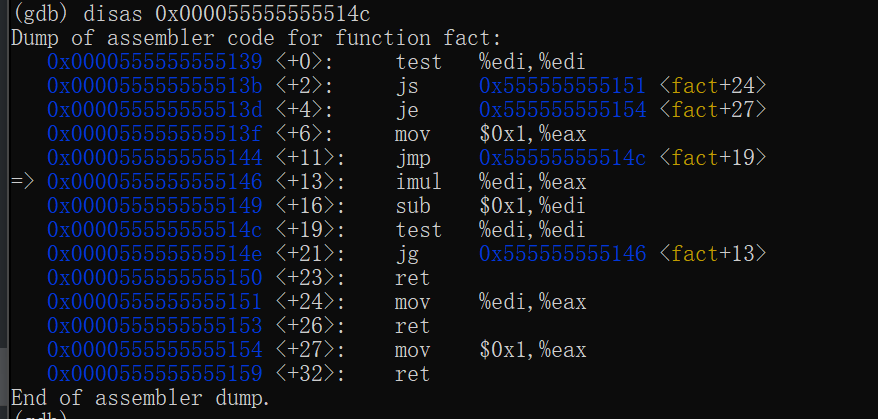
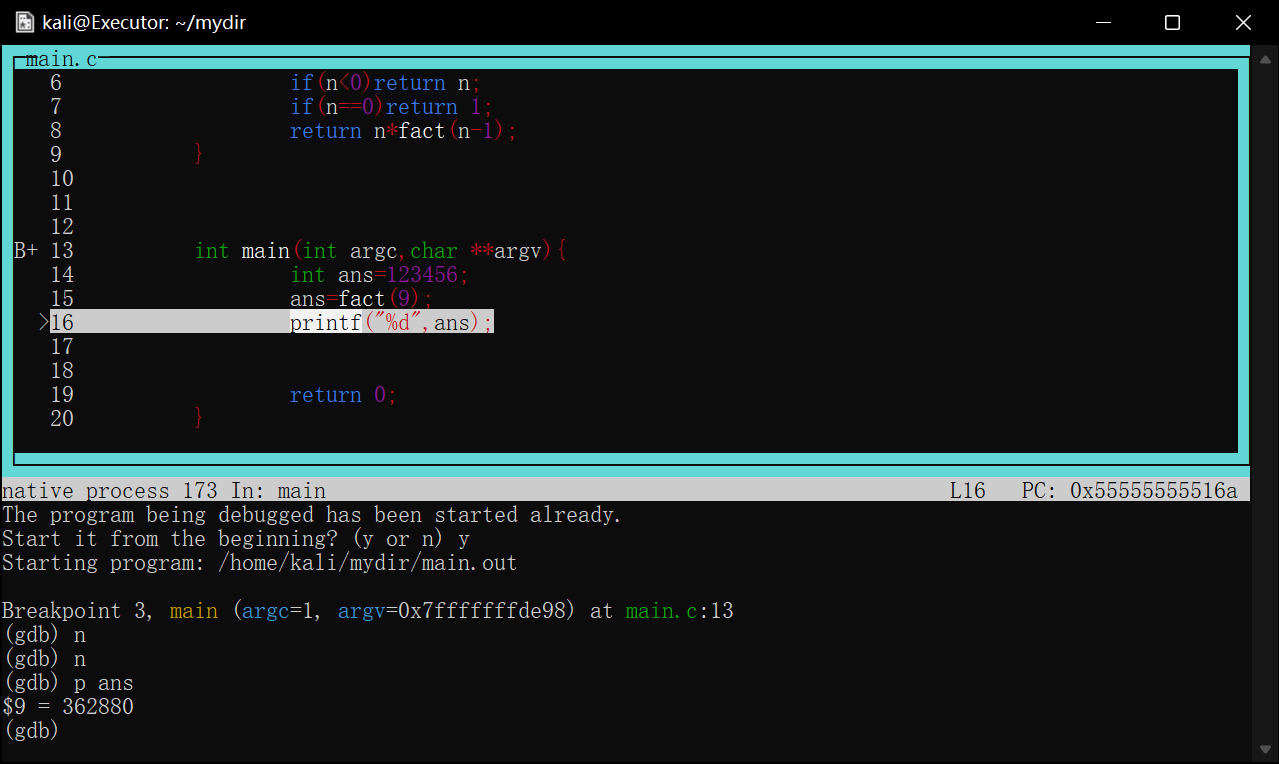
查看寄存器信息p $<寄存器名>
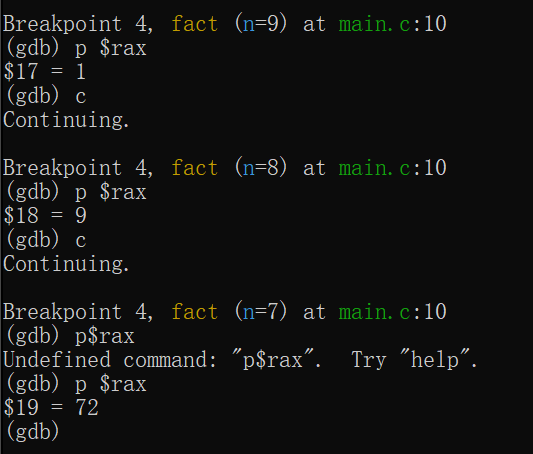
对于刚才的fact循环求阶乘函数,最后返回值是result,可想而知,该值是存放在rax寄存器中的
1 2 3 4 5 6 7 8 9 10 11
intfact(int n){ if(n<0)return n; if(n==0)return1; int result=1; while(n>0){ result*=n; --n;
intexgcd(constint &a, constint &b, int &x, int &y){//拓展欧几里得算法ax+by=1=gcd(a,b) if (b == 0) { x = 1; y = 0; return a; } int x2, y2; int d = exgcd(b, a % b, x2, y2); x = y2; y = x2 - a / b * y2; return d; }
root@deutschball-virtual-machine:/home/deutschball/桌 面# mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 31 Server version: 8.0.27-0ubuntu0.20.04.1 (Ubuntu)
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> CREATE TABLE fleets( -> id INT NOT NULL AUTO_INCREMENT, -> commander VARCHAR(100) NOT NULL, -> PRIMARY KEY(id) -> )ENGINE=InnoDB DEFAULT CHARSET=utf8; Query OK, 0 rows affected, 1 warning (0.02 sec) mysql> insert into fleets(id)values(2); ERROR 1364 (HY000): Field 'commander' doesn't have a default value
+----+-----------+ | id | commander | +----+-----------+ | 2 | soldier1 | | 4 | soldier10 | | 6 | vader | | 8 | vader | | 10 | vader | | 12 | vader | +----+-----------+ 6 rows in set (0.00 sec)
where中使用and指定多个条件
1 2 3 4 5 6 7 8 9
mysql> select *from fleets where id%2=0 and id%3=0; +----+-----------+ | id | commander | +----+-----------+ | 6 | vader | | 12 | vader | +----+-----------+ 2 rows in set (0.00 sec)
mysql> select *from fleets; +----+-----------+ | id | commander | +----+-----------+ | 1 | vader | | 2 | soldier1 | | 3 | soldier2 | | 4 | soldier10 | | 5 | vader | | 6 | vader | | 7 | vader | | 8 | vader | | 9 | vader | | 10 | vader | | 11 | vader | | 12 | vader | | 13 | Vader | +----+-----------+ 13 rows in set (0.00 sec)
使用binary关键字:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
mysql> select *from fleets where binary commander='vader'; +----+-----------+ | id | commander | +----+-----------+ | 1 | vader | | 5 | vader | | 6 | vader | | 7 | vader | | 8 | vader | | 9 | vader | | 10 | vader | | 11 | vader | | 12 | vader | +----+-----------+ 9 rows in set, 1 warning (0.00 sec)
如果不用binary:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
mysql> select *from fleets where commander='vader'; +----+-----------+ | id | commander | +----+-----------+ | 1 | vader | | 5 | vader | | 6 | vader | | 7 | vader | | 8 | vader | | 9 | vader | | 10 | vader | | 11 | vader | | 12 | vader | | 13 | Vader | +----+-----------+ 10 rows in set (0.00 sec)
数据表更新记录
1 2
UPDATE table_name SET field1=new-value1, field2=new-value2,... [WHERE Clause]
mysql> select * from officers; +----+----------------+------------+ | id | name | title | +----+----------------+------------+ | 1 | Darth Vader | executor | | 2 | Darth Sidious | emperor | | 3 | Wilhuff Tarkin | Grand Moff | +----+----------------+------------+ 3 rows in set (0.00 sec)
mysql> select *from commanders; +----+---------------+---------+ | id | name | title | +----+---------------+---------+ | 1 | Rex | captain | | 2 | Darth Vader | general | | 3 | Darth Sidious | marshal | +----+---------------+---------+ 3 rows in set (0.00 sec)
1.现在统计所有政府官员和军队指挥官一共有多少人(考虑有些人可以集军政大权于一身,需要去重)
1 2 3 4 5 6 7 8 9 10 11 12 13
mysql> select name from officers -> union -> select name from commanders; +----------------+ | name | +----------------+ | Darth Vader | | Darth Sidious | | Wilhuff Tarkin | | Rex | +----------------+ 4 rows in set (0.01 sec)
2.统计名叫Darth Vader的是否身兼数职
1 2 3 4 5 6 7 8 9 10 11
mysql> select *from officers where name='Darth Vader' -> union all -> select *from commanders where name='Darth Vader'; +----+-------------+----------+ | id | name | title | +----+-------------+----------+ | 1 | Darth Vader | executor | | 2 | Darth Vader | general | +----+-------------+----------+ 2 rows in set (0.00 sec)
3.统计==肉眼可见的西斯==担任的职务:
肉眼可见的西斯即Darth开头
1 2 3 4 5 6 7 8 9 10 11 12 13
mysql> select * from officers where name like 'Darth%' -> union all -> select *from commanders where name like 'Darth%'; +----+---------------+----------+ | id | name | title | +----+---------------+----------+ | 1 | Darth Vader | executor | | 2 | Darth Sidious | emperor | | 2 | Darth Vader | general | | 3 | Darth Sidious | marshal | +----+---------------+----------+ 4 rows in set (0.00 sec)
排序
1 2
SELECT field1, field2,...fieldN FROM table_name1, table_name2... ORDER BY field1 [ASC [DESC][默认 ASC]], [field2...] [ASC [DESC][默认 ASC]]
order
by语句中从前到后为关键字优先级,首先按照field1关键字的规则进行排序,然后field1关键字相同项再按照field2关键字进行排序,以此类推
ASC(ascend)升序,默认模式
DESC(descent)降序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
mysql> select *from commanders order by id ASC; +----+---------------+---------+ | id | name | title | +----+---------------+---------+ | 1 | Rex | captain | | 2 | Darth Vader | general | | 3 | Darth Sidious | marshal | +----+---------------+---------+ 3 rows in set (0.00 sec)
mysql> select *from commanders order by id DESC; +----+---------------+---------+ | id | name | title | +----+---------------+---------+ | 3 | Darth Sidious | marshal | | 2 | Darth Vader | general | | 1 | Rex | captain | +----+---------------+---------+ 3 rows in set (0.00 sec)
分组
1 2 3 4
SELECT column_name, function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name;
从某个表中按照某些规则选取某些列,并且按照某列进行同名分组
现有数据库如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
mysql> select * from -> popularity; +----+------+--------+ | id | name | gender | +----+------+--------+ | 1 | Tom | male | | 2 | Tom | male | | 3 | Tom | male | | 4 | Jack | male | | 5 | Jon | famal | | 6 | Mike | male | +----+------+--------+ 6 rows in set (0.00 sec)
要调查人口统计表中人重名的情况
1 2 3 4 5 6 7 8 9 10 11
mysql> select name,count(*) from popularity group by name; +------+----------+ | name | count(*) | +------+----------+ | Tom | 3 | | Jack | 1 | | Jon | 1 | | Mike | 1 | +------+----------+ 4 rows in set (0.01 sec)
WITH ROLLUP
现有彩票获奖名单如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
mysql> select * from Winners; +----+------+-------+ | id | name | prize | +----+------+-------+ | 1 | Mike | 20 | | 2 | Mike | 30 | | 3 | Mike | 10 | | 4 | Mike | 15 | | 5 | Jack | 15 | | 6 | Jack | 18 | | 7 | John | 18 | | 8 | Jack | 19 | | 9 | Mike | 5 | +----+------+-------+ 9 rows in set (0.00 sec)
1.查看每个人一共获奖多少次
1 2 3 4 5 6 7 8 9
mysql> select name,count(*) from Winners group by name; +------+----------+ | name | count(*) | +------+----------+ | Mike | 5 | | Jack | 3 | | John | 1 | +------+----------+ 3 rows in set (0.00 sec)
2.查看每个人一共获奖多少钱
1 2 3 4 5 6 7 8 9 10
mysql> select name,SUM(prize) as tot_prize from Winners group by name with rollup; +------+-----------+ | name | tot_prize | +------+-----------+ | Jack | 52 | | John | 18 | | Mike | 80 | | NULL | 150 | +------+-----------+ 4 rows in set (0.00 sec)
mysql> select coalesce(name,'sum_prize'),SUM(prize) as tot_prize from Winners group by name with rollup; +----------------------------+-----------+ | coalesce(name,'sum_prize') | tot_prize | +----------------------------+-----------+ | Jack | 52 | | John | 18 | | Mike | 80 | | sum_prize | 150 | +----------------------------+-----------+ 4 rows in set (0.00 sec)
mysql> select * from officers; +----+---------+-----------+ | id | name | title | +----+---------+-----------+ | 1 | Mike | Mayor | | 2 | Jack | executor | | 3 | Jackson | candidate | | 4 | John | emperor | | 5 | Tom | minister | +----+---------+-----------+ 5 rows in set (0.00 sec)
mysql> select * from commanders; +----+-------+---------------+ | id | name | military_rank | +----+-------+---------------+ | 1 | Vader | general | | 2 | Rex | captain | | 3 | John | marshal | +----+-------+---------------+ 3 rows in set (0.00 sec)
现在John皇帝不希望军队和政治耦合,希望调查有没有在军政上同时身居要职的大官,
即统计其中身兼数职(比如John既是帝国皇帝又是军队元帅)的人
1 2 3 4 5 6 7
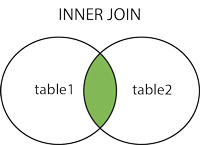
mysql> select a.name,a.title,b.military_rank from officers a inner join commanders b on a.name=b.name; +------+---------+---------------+ | name | title | military_rank | +------+---------+---------------+ | John | emperor | marshal | +------+---------+---------------+ 1 row in set (0.00 sec)
其中
1
mysql> select a.name,a.title,b.military_rank from officers a inner join commanders b on a.name=b.name;
可以翻译为:
保留a表的name和title列,保留b表的military_rank列,
a表即officers表,b表即commanders表,
两表根据name列等值连接
调查完后John皇帝很开心
LEFT JOIN
左合并会保留左侧表的全部数据,不管右侧表有无匹配数据
img
1 2 3 4 5 6 7 8 9 10 11 12
mysql> select a.name,a.title,b.military_rank from officers a left join commanders b on a.name=b.name; +---------+-----------+---------------+ | name | title | military_rank | +---------+-----------+---------------+ | Mike | Mayor | NULL | | Jack | executor | NULL | | Jackson | candidate | NULL | | John | emperor | marshel | | Tom | minister | NULL | +---------+-----------+---------------+ 5 rows in set (0.00 sec)
可以翻译为:
政府官员先都列在表里,然后军队指挥官如果有人也是政府官员则把其军衔也写在表里,否则写NULL
RIGHT JOIN
类比左合并,保留右侧表的全部数据,不管左侧表有无匹配数据
NULL值处理
null值与任何值的任何比较都是null
1 2 3 4 5 6 7 8 9 10 11 12 13 14
mysql> select * from officers; +----+---------+-----------+ | id | name | title | +----+---------+-----------+ | 1 | Mike | Mayor | | 2 | Jack | executor | | 3 | Jackson | candidate | | 4 | John | emperor | | 5 | Tom | minister | +----+---------+-----------+ 5 rows in set (0.00 sec)
mysql> select * from officers where null=null or null >null or null<null; Empty set (0.00 sec)
判断NULL
IS NULL,IS NOT NULL,<=>三种方法
现有数据表
1 2 3 4 5 6 7 8 9 10
mysql> select * from officers; +----+------+---------+ | id | name | post | +----+------+---------+ | 1 | John | Mayor | | 2 | Mike | NULL | | 3 | Jack | NULL | | 4 | Tom | emperor | +----+------+---------+ 4 rows in set (0.00 sec)
mysql> select * from officers where post is not null; +----+------+---------+ | id | name | post | +----+------+---------+ | 1 | John | Mayor | | 4 | Tom | emperor | +----+------+---------+ 2 rows in set (0.00 sec)
mysql> select * from officers where post is null; +----+------+------+ | id | name | post | +----+------+------+ | 2 | Mike | NULL | | 3 | Jack | NULL | +----+------+------+ 2 rows in set (0.00 sec)
mysql> select * from officers where post <=> null; +----+------+------+ | id | name | post | +----+------+------+ | 2 | Mike | NULL | | 3 | Jack | NULL | +----+------+------+ 2 rows in set (0.00 sec)
替换NULL
1
ifnull(a,b)
如果a为NULL则返回b的值
1 2 3 4 5 6 7 8
mysql> select * from officers where ifnull(post,'')=''; +----+------+------+ | id | name | post | +----+------+------+ | 2 | Mike | NULL | | 3 | Jack | NULL | +----+------+------+ 2 rows in set (0.00 sec)
一般用于int值替换成0参与计算
正则
在where子句中使用正则表达式,类似于等号和LIKE语句:
1
where 键值 REGEXP <pattern>
现有数据表如下:
1 2 3 4 5 6 7 8 9 10 11
mysql> select * from officers; +----+---------------+----------+ | id | name | post | +----+---------------+----------+ | 1 | John | Mayor | | 2 | Mike | NULL | | 3 | Jack | NULL | | 5 | Darth Vader | executor | | 6 | Darth Sidious | emperor | +----+---------------+----------+ 5 rows in set (0.00 sec)
要查询政府官员中肉眼可见的西斯
1 2 3 4 5 6 7 8
mysql> select * from officers where name regexp '^Darth'; +----+---------------+----------+ | id | name | post | +----+---------------+----------+ | 5 | Darth Vader | executor | | 6 | Darth Sidious | emperor | +----+---------------+----------+ 2 rows in set (0.00 sec)
mysql> select * from officers; +----+---------------+----------+ | id | name | post | +----+---------------+----------+ | 1 | John | Mayor | | 5 | Darth Vader | executor | | 6 | Darth Sidious | emperor | +----+---------------+----------+ 3 rows in set (0.00 sec)
mysql> use empire; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A
Database changed mysql> show columns from officers; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | post | varchar(20) | YES | | NULL | | +-------+-------------+------+-----+---------+----------------+ 3 rows in set (0.02 sec)
mysql> show columns from officers; +---------------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | post | varchar(20) | YES | | NULL | | | military_rank | varchar(10) | NO | | soldier | | +---------------+-------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec)
其中
1
mysql> alter table officers add military_rank varchar(10) not null default 'soldier';
mysql> alter table officers add salary int(10) not null default 3000 after name; Query OK, 0 rows affected, 1 warning (0.04 sec) Records: 0 Duplicates: 0 Warnings: 1
mysql> show columns from officers; +---------------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | salary | int | NO | | 3000 | | | post | varchar(20) | YES | | NULL | | | military_rank | varchar(10) | NO | | soldier | | +---------------+-------------+------+-----+---------+----------------+ 5 rows in set (0.00 sec)
删除字段DROP
1
ALTER TABLE <tablename> DROP <key>;
现在希望删除salary字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14
mysql> alter table officers drop salary; Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0
mysql> show columns from officers; +---------------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | post | varchar(20) | YES | | NULL | | | military_rank | varchar(10) | NO | | soldier | | +---------------+-------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec)
只修改字段属性MODIFY
1 2 3
mysql> alter table officers modify post varchar(10); Query OK, 2 rows affected (0.03 sec) Records: 2 Duplicates: 0 Warnings: 0
修改字段名及属性CHANGE
1
ALTER TABLE <tablename> MODIFY <old key> <new key> <type> ...
现在希望修改post字段为position
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
mysql> alter table officers change post position varchar(10); Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
mysql> show columns from officers; +---------------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | position | varchar(10) | YES | | NULL | | | military_rank | varchar(10) | NO | | soldier | | +---------------+-------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec)
mysql> alter table officers change post position; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '' at line 1
修改字段默认值
1
ALTER TABLE <tablename> ALTER <key> SET <属性> <新属性值>
比如希望修改官员的默认职位为'大臣'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
mysql> alter table officers alter position set default 'minister'; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
mysql> show columns from officers; +---------------+-------------+------+-----+----------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+-------------+------+-----+----------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | position | varchar(10) | YES | | minister | | | military_rank | varchar(10) | NO | | soldier | | +---------------+-------------+------+-----+----------+----------------+ 4 rows in set (0.00 sec)
1.CREATE INDEX <indexname> ON <tablename>(columnname); 2.ALTER TABLE <tablename> ADD INDEX <indexname>(columnname); 3.建表时指定 mysql> create table testIndex( -> id int not null, -> name varchar(20)not null, -> index myindex(name) -> ); Query OK, 0 rows affected (0.02 sec)
删除索引
1
DROP INDEX <indexname> ON <tablename>
1 2 3
mysql> drop index myindex on testIndex; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
唯一索引
建立唯一索引的列不允许有重复数据
建立索引的方法
1 2 3 4 5 6 7 8 9
1.CREATE UNIQUE INDEX <indexname> ON <tablename>(columnname); 2.ALTER TABLEL <tablename> ADD UNIQUE <indexname>(columnname); 3.建表时指定 mysql> create table mytable( -> id int(10)not null, -> name varchar(20)not null, -> unique myindex(name) -> ); Query OK, 0 rows affected, 1 warning (0.01 sec)
1 2 3 4 5 6 7 8 9 10
mysql> create unique index myindex on mytable(id); ERROR 1146 (42S02): Table 'empire.mytable' doesn't exist mysql> create unique index myindex on testIndex(id); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0
CREATE TABLE <target_table_name> LIKE <source_table_name>;//克隆表结构 INSERT INTO <target_table_name> SELECT * FROM <source_table_name>;//克隆表数据 CREATE TABLE <target_table_name> SELECT * FROM <source_table_name>;//一步到位 CREATE TABLE <target_table_name> SELECT * FROM <source_table_name> where 1=2;//克隆表结构
mysql> show columns from officers; +---------------+-------------+------+-----+----------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+-------------+------+-----+----------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | position | varchar(10) | YES | MUL | minister | | | military_rank | varchar(10) | NO | MUL | soldier | | +---------------+-------------+------+-----+----------+----------------+ 4 rows in set (0.00 sec)
mysql> select * from officers; +----+---------------+----------+---------------+ | id | name | position | military_rank | +----+---------------+----------+---------------+ | 5 | Darth Vader | executor | soldier | | 6 | Darth Sidious | emperor | soldier | +----+---------------+----------+---------------+ 2 rows in set (0.00 sec)
mysql> show columns from newOfficers; +---------------+-------------+------+-----+----------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+-------------+------+-----+----------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | position | varchar(10) | YES | MUL | minister | | | military_rank | varchar(10) | NO | MUL | soldier | | +---------------+-------------+------+-----+----------+----------------+ 4 rows in set (0.00 sec)
mysql> select * from newOfficers; Empty set (0.00 sec)