浮点数的机器级表示
师出有名
1.补上计组网课上摆烂留下的历史问题
2.将浮点数的表示和程序中的行为联系起来,完成CSAPP第二章和第三章最后剩下的浮点数部分
药引子和命根子
从十进制科学计数法说起
一个很长十进制数,成万上亿,在小学的时候我们就知道,可以用科学计数法表示
假设该十进制数按位展开表示成
注意\(d_0.d_{-1}\)中间是小数点
用科学计数法表示
小数点每左移一位,\(10\)的指数就得增加1.
小学时学的科技法的规范形式,小数点左侧只能留下一个非零位,就比如:
为啥要发明科学计数法呢?举个例子
如果要表示两个整亿,不用科计法为\(2'000'000'000\),表示这个数就用了10个十进制位,而其中后面9位都是0,包含了重复信息.
而如果用科技法表示为\(2\times 10^9\)
此时我们只需要保留两个信息,底数\(2\)和指数\(9\),只用了两位
要是不是两个整亿呢?要是\(2'987'654'321\)呢?
此时如果要求保留全精度,科技法表示为\(2.987654321\times 10^9\),相对于普通表示,需要多保存一个9
但是如果要求保留一位有效数字,科技法就可以表示为\(3\times 10^9\),普通方法还得带着一伙子0
在数字很大的时候,我们往往更加关心量级和最高位,低位的数字相对欠重要,很多情况下要舍入
从科计法到二进制
不管是普通表示还是科技表示,二进制和10进制只有一个区别,即每一位的权重,
位权从10改成2就是二进制了
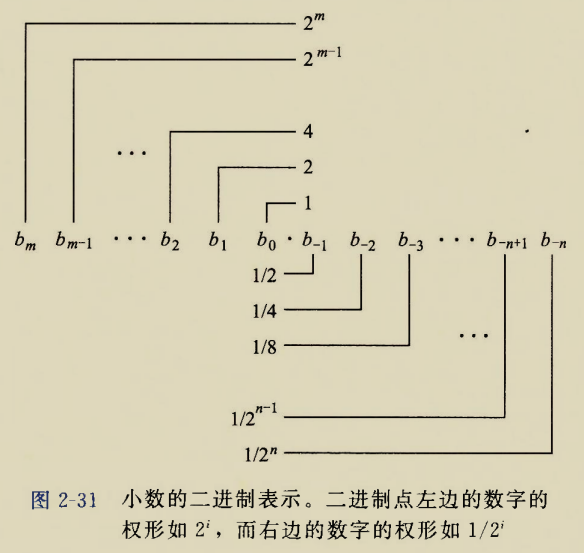
二进制的"科技法"也有一个规范形式,即小数点左侧只能留一个1
比如\(5.125(10)=101.001(2)=1.01001\times 2^2(2科技)\)
十进制科技法的规范形式,小数点左侧只能留下一个非0数
为啥二进制不能说留下一个非零数?
二进制下要么是0要么是1,非零数就是1
并且二进制科技法中,小数点左侧只留下一个1,那么这个1就可以省去不表示,只要是所有人都知道这个协议,他们使用这个科技法的二进制数的时候就会自己添上最前面的1.这样又可以腾出一位来用于精度信息
为什么十进制不能省去小数点左侧的数?因为这个数可能是1~9这9个数任意一个.省去就丢失了信息.二进制科技法中可以省去,是因为小数点左侧一定是1
IEEE754标准
浮点数的手写表示法
IEEE754标准中将一个浮点数表示成这样
s,符号.s=1则系数-1;s=0则系数1
M,尾数,一个二进制小数,其取值范围有两种
\(M\in[1,2)\),规格化数
\(M\in [0,1)\),非规格化数
E,指数
注意这里只是说"表示",真的在计算机中编码实现时不是这样的
真到编码的时候咋编的呢?

左边是高位,右边是低位
最高位是符号位,这和刚才的表示是相同的
然后 exp是"阶码".对于32位的float类型,exp占用8位,对于64位的double类型,exp占用11位.
用k表示exp的位数,对于float来说,k=11
注意这里"阶码"是加了引号的,因为实际存储的时候,这里面存放的不是刚才的表示中的\(E\),但是\(E\)是经过一些手续从\(exp\)换算得到的.这个换算过程是有固定套路的,这是后话
然后是 frac尾数M,占用了23位.这尾数和刚才的"表示"中也是不一样的,也需要分类讨论办点手续
用n表示frac的位数,对于float来说n=23
啥意思呢?举个例子
比如假设一个单精度浮点数float在计算机中的编码为:
\[ 0'0000\ 0001'0000\ 0000\ 0000\ 0000\ 0000\ 001 \]
符号位s exp frac 0 0000 0001 0000 0000 0000 0000 0000 001 如果认为\(E=0000\ 0001,M=1\)去算这个数得到
\[ b=1\times 2^1=10(2)=2(10) \]这就错了,实际上这个数是
\[ 1\frac{1}{2^{23}}\times 2^{-126} \]这里\(1\frac{1}{2^{23}}\)是带分数
为啥会这样呢?为啥不能直来直去,exp就表示E,frac就表示M?
这涉及到排序方便的问题,这是后话.
总之计算机中存储的浮点数直接拿出来并不是s,E,M这样排好的,需要办手续
浮点数的实际存储状态
状态设计
在设计浮点数的存储状态时,鳎们首先规定了几个特殊的状态:
1.正负无限大
2.不是数NAN
给你一个32位数,让你考虑怎么用32个位表示一个数是正负无限大还是不是数还是正常数?
专门用两个状态位标记?比如开头两位,00表示正无限大,01表示负无限大,10表示不是数,11表示正常数.然后剩下30位在正常数时使用?
这样设计有啥意义呢?纯粹是页表状态学傻了,非得用一个标志位标志一下脏不脏是吧?
一个数要是无限大或者根本不是数,那么后面30位不都没有意义了吗?这在数电上就是无关项了.
看看人家IEEE754怎么规定的吧
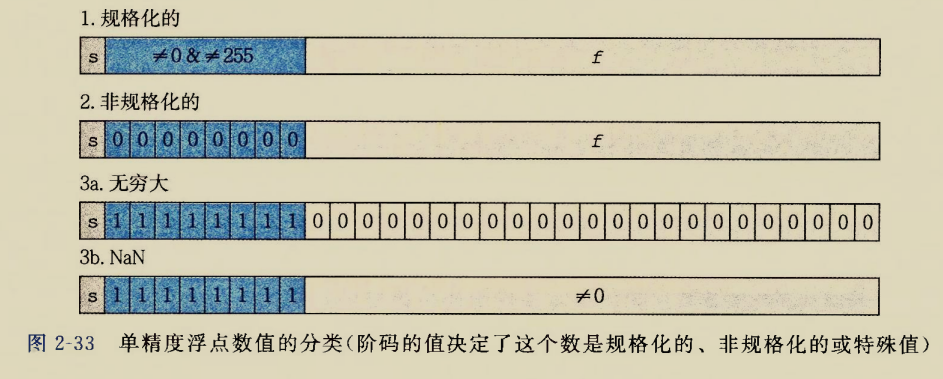
只能说这种规定不流失不蒸发零浪费,把牙膏挤的一滴都不剩了.当看不明白这种定义的蜜汁操作时,使劲往空间利用效率上想就对了
什么个想法呢?
1.符号位站最高位,不管如何符号位总得站一位吧.这里没有异议
2.无穷大,不管是正负,其exp全是1,frac全是0.
为啥要用exp全1,frac全0表示无穷大?这样表示岂不是会占用正常数的地址空间?
确实会占用,但是只占用了一种状态,exp还剩下\(2^8-1=255\)种状态
像比于专门用两个状态位,这样exp还剩下6位,可以表示\(2^6=64\)种状态
显然人家的规定更会挤牙膏
正负无穷大怎么表示的呢?
符号位决定正负,后面的exp全1frac全0表示无穷大
它甚至符号位和正常数都共用
3.NaN,其和无穷大的表示,就是frac是否全0
只要CPU读取一个浮点数,发现exp的8位全是1,他就知道要么是一个无穷大,要么不是数.反正不是好东西.
然后再检查后面frac的23位,要是有一个1就判定为NaN
这又挤了牙膏,设计出无穷大之后,NaN随之而来,甚至设计出无穷大之后再设计NaN都不会占用正常数的地址空间了
4.正常数
正常数分为规格化数和非规格化数
区分两者是通过exp是否全0
至于啥是规格啥是非规格,这是后话,反正实际使用的时候都能用到并且没有显式的开关
规格化数

exp
心里应该时刻悬着一个疑问,exp经过什么手续得到E阶码?
现在给你说这个手续是什么
其中k是exp占用的二进制位数,
对于float来说,\(k=11,Bias=2^{11-1}-1=1023\)
懵逼了吧,Bias是个銱啊?
给一个定义\(Bias=2^{k-1}-1\),跟那该死的谜语人儿似的,不给说为啥这样整.
CSAPP上也是春秋笔法,留个后话,和某些人一样吊人胃口
如果想要保持这层神秘感,那就继续看书,总会有一瞬间恍然大悟
如果急于知道原因,可以这样想:
1.我这样算出来的\(E\),怎么表示正负呢?
虽然我整个数有一个符号s,但是阶码也应该有一个符号啊,\(-1.01\times 2^2\)和\(-1.01\times 2^{-2}\)这两个可不一样啊
按理说E的开头一位应该是符号啊,这样规定,没写符号位啊?
2.\(Bias=2^{k-1}-1\)好大啊,用exp去减Bias不是以卵击石吗?剪完了十有八九是个负数啊?
这样想就在向Bias的设计目的靠拢了
先解决2.
对于float,k=11
\[ Bias=2^{11-1}-1=2^{10}-1=0111\ 1111\ 111\ \]最高位竟然是0,剩下低位全是1
也就是说当\(exp=1XXX\ XXXX\ XXX\),这时候\(exp-Bias\)得到的是正数
而\(exp\)要么表示是\(1XXX\ XXXX\ XXX\),要么是\(0XXX\ XXXX\ XXX\)
这两种情况平分秋色,就算是摇色子也是对半的几率落在两个范围内.
而我们希望阶码的正负数范围也是平分秋色,势均力敌的(差一两个无所谓)
现在就有雏形了
当\(exp=1XXX\ XXXX\ XXX\),\(E=exp-Bias\)得到的就是正数
当\(exp=0XXX\ XXXX\ XXX\),\(E=exp-Bias\)得到的就是负数
这好像和我们平常定义的正负数有出入啊?
通常都是0表示正数,1表示负数啊?这里为啥要倒过来exp最高位为1时表示正数,exp最高位为0时表示负数
这时候就要考虑方便排序比大小了
两个阶码\(E1,E2\)都是经过\(exp1,exp2\)减同一个数得到的,那么\(E1>E2\)则\(exp1>exp2\)
反过来也是这样,如果\(exp1>exp2\)则\(E1>E2\)
如果正数最高位为1负数最高位为0,那么很自然的\(1>0\),正数大于负数.
两个同号的exp比较时就从最高位遍历到最低位一视同仁
那么任意两个exp比较只需要从最高位遍历到最低位,谁的高位有1谁大
这样比较大小顺理成章,不用特判符号位
总结:
Bias这样设计考虑了排序方便,并且减去的这个数正好是区间的一半,相当于\([0,10]-5\Rightarrow[-5,5]\),使得正负数平分秋色.
解决了正负号问题同时附带着解决了大小问题,岂不美哉

frac
前面说过,从frac到真正的尾数M也需要分类讨论办手续
现在就是分类讨论情况1
当exp不全为0也不全为1(即表示一个规格化数时)
即存储时自动忽略了小数点左边的1,计算式要加上
总结
现在我们知道了exp到E的手续还有frac到M的手续,符号s没有手续.
手续齐全了,一个规格化数的表示和存储的关系我们也就明了了
还是以一开始举的例子,假设一个float的存储是这样的
| 符号s | exp | frac |
|---|---|---|
| 0 | 0000 0001 | 0000 0000 0000 0000 0000 001 |
\(Bias=0111\ 1111(2)=127(10)\)
\(E=exp=Bias=1-127=-126(10)\)
\(M=1+frac=1.0000\ 0000\ 0000\ 0000\ 0000\ 001(2)=1+2^{-23}(10)\)
范围
考虑一个exp有k位,frac有n位的规格化数能够表示的数的范围
首先考虑\(exp\)的范围,由于其不能全为0或者全为1,因此有\(exp\in[00...001]\)
即\(exp\in[1,2^{k}-2]\)
那么\(E=exp-Bias=exp-(2^{k-1}-1)\in [2-2^{k-1},2^{k-1}-1]\)
\(frac\in[0,\sum_{i=-1}^{-n}2^i]=[0,1-2^{-n}]\)
\(M=1+frac\in[1,2-2^{-n}]\)
| 符号 | 最大值 | 最小值 |
|---|---|---|
| exp | \(2^k-2\) | 1 |
| E | \(2^{k-1}-1\) | \(2-2^{k-1}\) |
| frac | \(1-2^{-n}\) | 0 |
| M | \(2-2^{-n}\) | 1 |
| 规格化数绝对值 | \((2-2^{-n})\times 2^{2^{k-1}-1}\) | \(2^{2-2^{k-1}}\) |
比如对于float类型,k=11,n=23
| 符号 | 最大值 | 最小值 |
|---|---|---|
| exp | \(2^{11}-2=2046\) | 1 |
| E | \(2^{11-1}-1=1023\) | \(2-2^{11-1}=-1022\) |
| frac | \(1-2^{-n}=1-2^{-23}\) | 0 |
| M | \(2-2^{-n}=2-2^{-23}\) | 1 |
| 规格化数绝对值 | \((2-2^{-23})\times 2^{2^{10}-1}=(2-2^{-23})\times 2^{1023}\) | \(2^{2-2^{11-1}}=2^{-1022}\) |
非规格化数
非规格化数是干啥用的呢?都叫他"非规格化"了,看来不规范,为啥还要用它呢?
现在要存储一个值为0的float.而规格化时我们要求\(M\)左边是1,存储的时候省去
对于0,打死也找不到一个1放在小数点左边啊
exp
当exp全0时,存储的数就是一个非规格化数
这时求\(E\)的手续又有变化\(E=1-Bias\)
\(Bias=2^{k-1}-1\)不变
frac
求尾数M的手续也有变化\(M=frac\),没有隐含的1了
总结
如果一个非规格化数的存储是这样的:
全是0
\(E=1-Bias=1-127=-126\)
\(M=frac=0\)
同理,如果只有符号位为1,由于M为0,我们也可以得到0
这两个0有区别,符号位0的为+0,符号位1的为-0.两者在计算\(1/+0,1/-0\)时分别得到正负无穷大
范围
\(M=frac\in[0,1-2^{-n}]\)
\(E=1-Bias=2-2^{k-1}\)
阶是不变的,只有尾数\(M\)可以变
到此仍然体会不到非规格化数的作用,仍然懵逼的很.不能就因为要表示0就单开一种类型吧?
这么说吧,非规格化数还可以表示距离0很近的数.啥意思呢?
注意非规格化数的阶码\(E=2-2^{k-1}\)这个定值正好是规格化数阶码的最小值
再看尾数,规格化数的尾数最小是1,但是非规格化的尾数\(M\in[0,1-2^{-n}]\)永远小于1
规格化数最靠近0的数为\(2^{2-2^{k-1}}\),不能再小了,但是非规格化数可以再通过改变尾数更接近0
即同为正数的 规格化数 一定大于 非规格化数
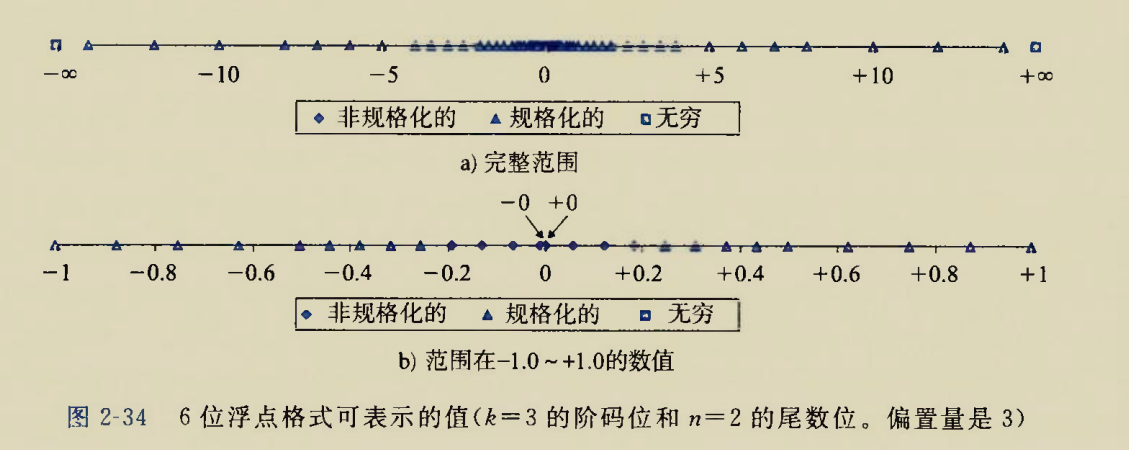
画在数轴上就是CSAPP给出的这幅图
这里"偏置量"就是bias
以八位浮点数为例
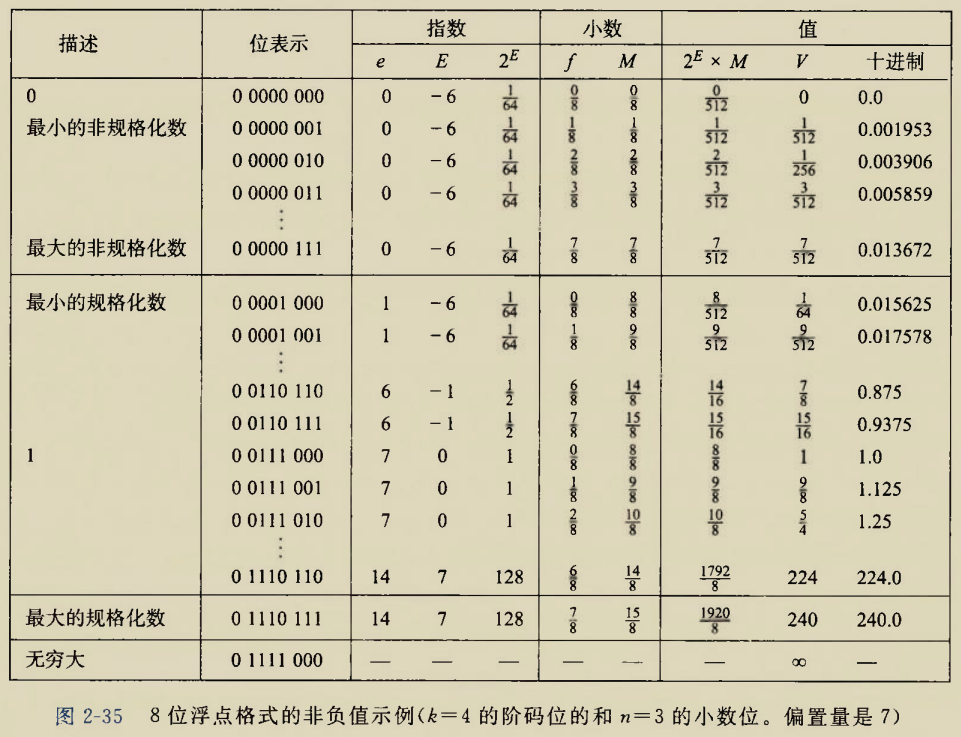
这个表上可以发现很多问题
1.非规格化数呈现等差数列,相邻两项相差\(\frac{1}{512}\),这是为什么?
非规格化数的阶码是固定的,用\(C=2^{2-2^{k-1}}=2^{-6}=\frac{1}{64}\)表示固定的权
尾数\(M\)从\(0\)逐次增加\(\frac{1}{8}\),那么非规格化数序列就是\(0C,\frac{1}{8}C,\frac{2}{8}C...\frac{7}{8}C\)
任意相邻两项差均为\(\frac{1}{8}C\)为定值
2.从最大的非规格化数到最小的规格化数貌似仍然维持了非规格化数的公差,那么规格化数也是等差数列吗?
不是
相邻两个规格化数的增长,既要考虑阶码的增长的可能,又要考虑尾数增长的可能
对于一个固定的阶码,尾数只有\(0,\frac{1}{8},...,\frac{7}{8}\)这8种情况,同一个阶码下的这八项组成等差数列
但是换一个阶码,和刚才的尾数就组不成等差数列了,\(\frac{1}{8}C_1\)和\(\frac{1}{8}C_2\)不一样大
因此规格化数随着阶码增大,在数轴上的距离将会离得越来越远
3.阶码最小的规格化数一定可以和非规格化数"平滑过渡"吗
是的
阶码最小时\(exp=1\)
此时\(exp-Bias=1-Bias\)即阶码最小的规格化数和非规格化数的阶码是相同的
两种数的区别在于尾数前面是否有隐含的1
而非规格化数恰好从0增长到1之前缺一个单元,阶码最小的规格化数尾数恰好从1开始增长,接了非规格化数的班
我们的上述2.3两点在CSAPP给出的插图2-34中得到了验证
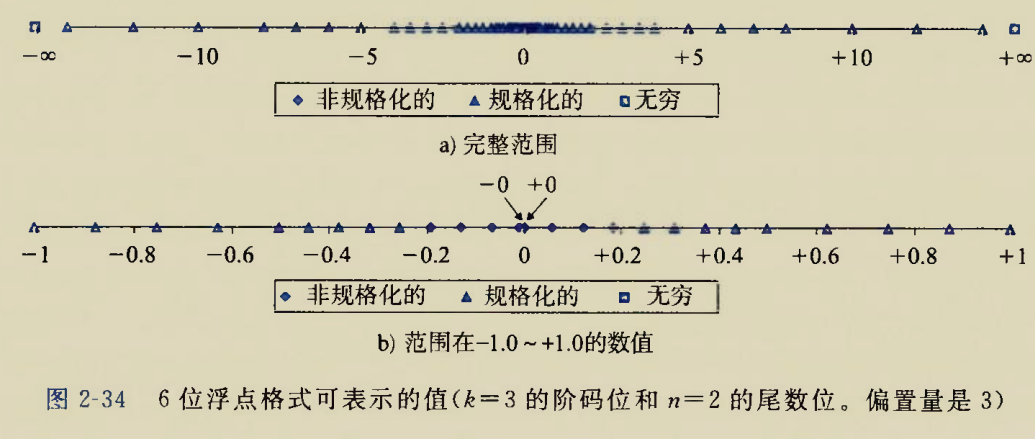
a)中约靠近中心,规格化数之间的距离越近(单调不增),越靠近两头规格化数之间的距离越远(单调不减).
一定范围内规格化数距离相同,是因为该几个规格化数的阶码相同,只有尾数不同
b)中最小的规格化数和非规格化数呈等差数列
舍入问题
向偶数舍入:
不是四舍五入,不是向上向下舍入

在类型转换从浮点数到整数时还是使用向0舍入
向偶舍入是一个浮点数表示不开的时候采用的方法
x86-64上浮点数的机器级表示
16个媒体寄存器

这里媒体寄存器都长的出奇,最短的用法是128位的xmm寄存器
然而一个浮点类型,要么是32位的float,要么是64位的double,
既然常用类型最长64位,为啥要整128甚至256位的寄存器呢?
目前猜测这些寄存器不光有存放浮点类型的作用
否则不会叫做"媒体"寄存器,怎么不改名浮点寄存器
实际上看了后面确实如此,xmm,ymm寄存器可以一次性存放好几个值
\([x_1,x_2,x_3,x_4]\)这种向量,其中每一个x都是一个float,合起来一共128位刚好占用一共xmm寄存器.
如果是四个double组成的向量则恰好一个ymm寄存器
汇编指令
标量指令
为了理解"标量"这个概念,必须得和"向量"这个概念联系对比
当然这里的向量和标量不是数学物理上的概念
更像是概率论与数理童祭时学的概念
X是一个样本,\(X_i\)是样本成员
这里\(X\)就是一个向量,他是有一群标量\(X_1,X_2,...,X_n\)按照顺序组成的集合
又比如一个有着横纵坐标的二维几何点就可以叫做一个"向量"\(P(X,Y)\)
标量就是一个数据
而向量是一组数据
标量指令对单个数据进行操作,一条标量指令只涉及一个数据的传递等操作
而向量指令可以一条指令完成对多个数据的操作
在接触浮点数的机器表示时,我们没有见过"向量指令"这个说法,是因为之前一直都是标量指令,不涉及向量的概念,当时CSAPP没有必要引入一个概念吓唬初学者
引用内存的指令是标量指令
也就是从寄存器到内存或者从内存到寄存器,只能一次搬一个数据,不能搬多了
那么可以推测,有这么一些指令,可以在xmm寄存器之间一口气搬好几个数据
浮点传送指令
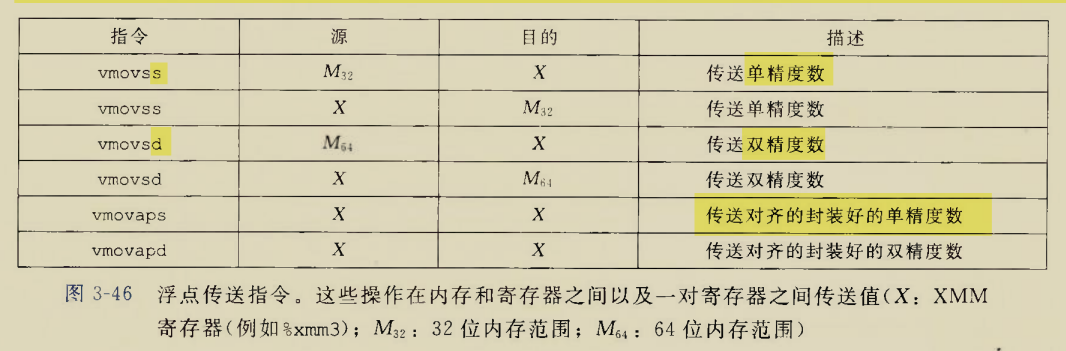
main.c
void func(){
register float a=12;
register float b=a;//使用register修饰提醒编译器使用寄存器存放a变量,但是实际上编译器很可能忽略
float c=a;
float *d=&c;
float e=*d;
}
int main(){
func();
return 0;
}
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/float]
└─$ gcc main.c -O0 -o main
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/float]
└─$ objdump main -d > main.asm
main.asm
0000000000001129 <func>:
1129: 55 push %rbp
112a: 48 89 e5 mov %rsp,%rbp
112d: f3 0f 10 0d cf 0e 00 movss 0xecf(%rip),%xmm1 # 2004 <_IO_stdin_used+0x4>
1134: 00
1135: f3 0f 11 4d f0 movss %xmm1,-0x10(%rbp)
113a: 48 8d 45 f0 lea -0x10(%rbp),%rax
113e: 48 89 45 f8 mov %rax,-0x8(%rbp)
1142: 48 8b 45 f8 mov -0x8(%rbp),%rax
1146: f3 0f 10 00 movss (%rax),%xmm0
114a: f3 0f 11 45 f4 movss %xmm0,-0xc(%rbp)
114f: 90 nop
1150: 5d pop %rbp
1151: c3 ret
这里面 a,b,c,d,e分别以什么形式存储呢?这得联系上下文了
movss 0xecf(%rip),%xmm1从内存rodata区到寄存器使用了 movss指令,对应 register float a=12;,即a存放在xmm1中
movss %xmm1,-0x10(%rbp)从寄存器到内存栈区使用了 movss指令,
可能对应 register float b=a;,因为编译器有可能忽略register修饰,也可能对应 float c=a;
怎么区分这两种情况呢?源代码下文中有对c的地址引用,因此后面如果有对 -0x10(%rbp)的地址引用操作, 那么可以判定为c
lea -0x10(%rbp),%rax,rax中存放刚才搬进栈区的局部变量的地址
mov %rax,-0x8(%rbp)这个地址通过rax中转放到栈上,这一步明显对应 float *d=&c;,
那么可以推出,d放在栈区 -0x8(%rbp),c放在栈区 -0x10(%rbp)
mov -0x8(%rbp),%rax这步实际上没有作用,rax之前就是存的 -0x8(%rbp),只不过 -O0优化显得编译器根傻子一样
movss (%rax),%xmm0,*d放到寄存器xmm0里,
movss %xmm0,-0xc(%rbp) *d通过xmm0中转了一下又放到栈区
显然对应 float e=*d;,e放在了栈区 -0xc(%rbp)
见鬼的是 register float b=a;这句好像没有起作用.为了保证我们没有出现幻觉,源代码中去掉这一句重新编译然后反编译\
void func(){
register float a=12;
// register float b=a;
float c=a;
float *d=&c;
float e=*d;
}
int main(){
func();
return 0;
}
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/float]
└─$ gcc main.c -O0 -o main -g
┌──(kali㉿Executor)-[/mnt/c/Users/86135/desktop/float]
└─$ objdump main -d > main.asm
0000000000001129 <func>:
1129: 55 push %rbp
112a: 48 89 e5 mov %rsp,%rbp
112d: f3 0f 10 0d cf 0e 00 movss 0xecf(%rip),%xmm1 # 2004 <_IO_stdin_used+0x4>
1134: 00
1135: f3 0f 11 4d f0 movss %xmm1,-0x10(%rbp)
113a: 48 8d 45 f0 lea -0x10(%rbp),%rax
113e: 48 89 45 f8 mov %rax,-0x8(%rbp)
1142: 48 8b 45 f8 mov -0x8(%rbp),%rax
1146: f3 0f 10 00 movss (%rax),%xmm0
114a: f3 0f 11 45 f4 movss %xmm0,-0xc(%rbp)
114f: 90 nop
1150: 5d pop %rbp
1151: c3 ret
和刚才一模一样 register float b=a;这句直接被优化掉了
哦上帝啊,-O0的gcc竟然也会有优化
浮点转换指令
一看就明白,没必要做实验分析了
其他指令
比较指令,位级运算指令都是按位进行的,类比整数的情形即可
System V 调用约定
参数传递约定
void func(float a,float b,float c,float d,float e,
float f,float g,float h,float i,float j)
{}//传递十个参数
int main(){
func(1,2,3,4,5,6,7,8,9,10);
return 0;
}
┌──(root㉿Executor)-[/mnt/c/Users/86135/desktop/float]
└─# gcc main.c -O0 -o main
┌──(root㉿Executor)-[/mnt/c/Users/86135/desktop/float]
└─# objdump main -d > main.asm
main.asm
main函数
0000000000001158 <main>:
;开端,帧指针压栈保存,帧指针获得此时栈顶指针拷贝
1158: 55 push %rbp
1159: 48 89 e5 mov %rsp,%rbp
;func的参数从右向左压栈,首先安排10的位置
;PC相对寻址,将M[rip+0xea0]放在xmm0寄存器
115c: f3 0f 10 05 a0 0e 00 movss 0xea0(%rip),%xmm0 # 2004 <_IO_stdin_used+0x4>
1163: 00
1164: 48 8d 64 24 f8 lea -0x8(%rsp),%rsp ;rsp=rsp-8,栈上申请8字节空间
1169: f3 0f 11 04 24 movss %xmm0,(%rsp) ;从xmm0搬到M[rsp]上
;重复刚才的过程,压栈从右向左数的第二个参数
116e: f3 0f 10 05 92 0e 00 movss 0xe92(%rip),%xmm0 # 2008 <_IO_stdin_used+0x8>
1175: 00
1176: 48 8d 64 24 f8 lea -0x8(%rsp),%rsp
117b: f3 0f 11 04 24 movss %xmm0,(%rsp)
;此后的八个参数恰好用8个媒体寄存器xmm0~7传递
1180: f3 0f 10 3d 84 0e 00 movss 0xe84(%rip),%xmm7 # 200c <_IO_stdin_used+0xc>
1187: 00
1188: f3 0f 10 35 80 0e 00 movss 0xe80(%rip),%xmm6 # 2010 <_IO_stdin_used+0x10>
118f: 00
1190: f3 0f 10 2d 7c 0e 00 movss 0xe7c(%rip),%xmm5 # 2014 <_IO_stdin_used+0x14>
1197: 00
1198: f3 0f 10 25 78 0e 00 movss 0xe78(%rip),%xmm4 # 2018 <_IO_stdin_used+0x18>
119f: 00
11a0: f3 0f 10 1d 74 0e 00 movss 0xe74(%rip),%xmm3 # 201c <_IO_stdin_used+0x1c>
11a7: 00
11a8: f3 0f 10 15 70 0e 00 movss 0xe70(%rip),%xmm2 # 2020 <_IO_stdin_used+0x20>
11af: 00
11b0: f3 0f 10 0d 6c 0e 00 movss 0xe6c(%rip),%xmm1 # 2024 <_IO_stdin_used+0x24>
11b7: 00
;蜜汁操作,就这个左边的参数搞特殊,非得用eax中转2一下,也是少见的64位机器上用到eax寄存器
11b8: 8b 05 6a 0e 00 00 mov 0xe6a(%rip),%eax # 2028 <_IO_stdin_used+0x28>
11be: 66 0f 6e c0 movd %eax,%xmm0
;参数准备完毕,可以调用函数func
11c2: e8 62 ff ff ff call 1129 <func>
;尾声
11c7: 48 83 c4 10 add $0x10,%rsp ;传递最右侧两个参数时压栈16字节,此时正好退回16个字节.调用者清理参数
;eax存放main函数的返回值0
11cb: b8 00 00 00 00 mov $0x0,%eax
11d0: c9 leave ;leave指令将栈中存放的rbp退还
11d1: c3 ret ;函数返回
;滥竽充数填充字节
11d2: 66 2e 0f 1f 84 00 00 cs nopw 0x0(%rax,%rax,1)
11d9: 00 00 00
11dc: 0f 1f 40 00 nopl 0x0(%rax)
func函数
0000000000001129 <func>:
1129: 55 push %rbp
112a: 48 89 e5 mov %rsp,%rbp
112d: f3 0f 11 45 fc movss %xmm0,-0x4(%rbp)
1132: f3 0f 11 4d f8 movss %xmm1,-0x8(%rbp)
1137: f3 0f 11 55 f4 movss %xmm2,-0xc(%rbp)
113c: f3 0f 11 5d f0 movss %xmm3,-0x10(%rbp)
1141: f3 0f 11 65 ec movss %xmm4,-0x14(%rbp)
1146: f3 0f 11 6d e8 movss %xmm5,-0x18(%rbp)
114b: f3 0f 11 75 e4 movss %xmm6,-0x1c(%rbp)
1150: f3 0f 11 7d e0 movss %xmm7,-0x20(%rbp)
1155: 90 nop
1156: 5d pop %rbp
1157: c3 ret
这里使用媒体寄存器传递的参数又压入栈中,这和前面我们学习过的x64linux使用的System V的整数传参时的约定是相同的
三个问题
1.movss 0xea0(%rip),%xmm0此处的 0xea0(%rip)指向啥东西
使用ida64反编译观察
.text:000000000000115C movss xmm0, cs:dword_2004
...
.rodata:0000000000002004 dword_2004 dd 41200000h ; DATA XREF: main+4↑r
.rodata:0000000000002008 dword_2008 dd 41100000h ; DATA XREF: main+16↑r
.rodata:000000000000200C dword_200C dd 41000000h ; DATA XREF: main+28↑r
.rodata:0000000000002010 dword_2010 dd 40E00000h ; DATA XREF: main+30↑r
.rodata:0000000000002014 dword_2014 dd 40C00000h ; DATA XREF: main+38↑r
.rodata:0000000000002018 dword_2018 dd 40A00000h ; DATA XREF: main+40↑r
.rodata:000000000000201C dword_201C dd 40800000h ; DATA XREF: main+48↑r
.rodata:0000000000002020 dword_2020 dd 40400000h ; DATA XREF: main+50↑r
.rodata:0000000000002024 dword_2024 dd 40000000h ; DATA XREF: main+58↑r
.rodata:0000000000002028 dword_2028 dd 3F800000h ; DATA XREF: main+60↑r
可以发现,该位置在只读变量rodata区,存了这么一个值 0x41200000h
然而我们主函数中传递的是10啊,这存了一个鬼啊?
这就是IEEE754规定的浮点数存储方法了,下面我们可以算他一下
这个16进制数展开成一个32位二进制数为
按照s,exp,frac划分开
| s | exp | frac |
|---|---|---|
| 0 | 1000 0010 | 010 0000 0000 0000 0000 |
对于一个32位的float,其exp占用k=8位,其frac占用n=23位
\(Bias=2^{k-1}-1=2^7-1=127(10)=0111'1111(2)\)
\(E=exp-Bias=1000'0010-0111'1111=0000'0011=3\)
\(M=1+frac=1+2^{-2}=\frac{5}{4}\)
\((-1)^s\times M\times 2^E=1\times \frac{5}{4}\times 2^3=10\)
正好是我们主函数中对func传递的参数中最右边那个
2.在最右侧两个参数压栈传递的时候
1164: 48 8d 64 24 f8 lea -0x8(%rsp),%rsp ;rsp=rsp-8,栈上申请8字节空间
1169: f3 0f 11 04 24 movss %xmm0,(%rsp) ;从xmm0搬到M[rsp]上
为啥每个参数要在栈上开8字节的空间?
后面func中将媒体寄存器中的参数压栈的时候却每个参数占用4字节的空间.
这也是x64Linux上System V的调用约定,参数传递的时候要8字节对齐,不管是int还是long还是double还是float,只要是用栈传递参数,就要每个参数8字节对齐
3.我们在main函数调用func时传递的参数都是立即数 1,2,3,4,5,6,7,8,9,10
但是在汇编层面上为什么没有直接用立即数 $1,$2这种,而是采用PC相对寻址,去.rodata区找变量呢?
115c: f3 0f 10 05 a0 0e 00 movss 0xea0(%rip),%xmm0
这是浮点常数和整数常数的区别
与浮点操作相关的指令,不能以立即数作为操作数,编译器必须为所有常数分配和初始化存储空间
将常数写入内存,然后采用各种寻址方法去找常数
返回值约定
如果一个函数返回值为浮点类型,会使用什么寄存器返回呢?eax还是xmm0?
┌──(root㉿Executor)-[/mnt/c/Users/86135/desktop/float]
└─# gcc main.c -O0 -c -o main.o
┌──(root㉿Executor)-[/mnt/c/Users/86135/desktop/float]
└─# objdump main.o -d > main.s
main.s
0000000000000000 <func>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: f3 0f 10 05 00 00 00 movss 0x0(%rip),%xmm0 # c <func+0xc>
b: 00
c: 5d pop %rbp
d: c3 ret
用的xmm0寄存器传递浮点参数